Клей-студия AWS теперь интегрирован с AWS Glue Data Brew. AWS Glue Studio — это графический интерфейс, упрощающий создание, запуск и мониторинг заданий извлечения, преобразования и загрузки (ETL) в Клей AWS. DataBrew — это визуальный инструмент подготовки данных, который позволяет очищать и нормализовать данные без написания кода. Более 200 преобразований, которые он обеспечивает, теперь доступны для использования в визуальном задании AWS Glue Studio.
В DataBrew рецепт представляет собой набор шагов преобразования данных, которые вы можете создавать в интерактивном режиме в интуитивно понятном визуальном интерфейсе. В этом посте вы увидите, как использовать сборку рецепта в DataBrew, а затем применить его как часть визуального задания ETL в AWS Glue Studio.
Существующие пользователи DataBrew также выиграют от этой интеграции — теперь вы можете запускать свои рецепты как часть более крупного визуального рабочего процесса со всеми другими компонентами, предоставляемыми AWS Glue Studio, в дополнение к возможности использовать расширенную конфигурацию заданий и последнюю версию ядра AWS Glue. .
Эта интеграция дает определенные преимущества существующим пользователям обоих инструментов:
- У вас есть централизованное представление в AWS Glue Studio всей схемы ETL от начала до конца.
- Вы можете интерактивно определить рецепт, просматривая значения, статистику и распределение в консоли DataBrew, а затем повторно использовать проверенную и проверенную логику обработки в визуальных заданиях AWS Glue Studio.
- Вы можете организовать несколько рецептов DataBrew в задании AWS Glue ETL или даже несколько заданий, используя рабочие процессы AWS Glue.
- Рецепты DataBrew теперь могут использовать функции заданий AWS Glue, такие как закладки для дополнительной обработки данных, автоматические повторные попытки, автоматическое масштабирование или группирование небольших файлов для большей эффективности.
Обзор решения
В нашем вымышленном примере использования требование состоит в том, чтобы очистить синтетический набор данных медицинских заявлений, созданный для этой публикации, в котором есть некоторые проблемы с качеством данных, введенные специально для демонстрации возможностей DataBrew по подготовке данных. Затем данные о претензиях вводятся в каталог (чтобы они были видны аналитикам) после его обогащения некоторыми важными сведениями о соответствующих поставщиках медицинских услуг, поступающими из отдельного источника.
Решение состоит из визуального задания AWS Glue Studio, которое считывает два CSV-файла с утверждениями и поставщиками соответственно. Задание применяет рецепт первого для решения проблем с качеством, выбирает столбцы из второго, объединяет оба набора данных и, наконец, сохраняет результат в Простой сервис хранения Amazon (Amazon S3), создавая таблицу в каталоге, чтобы выходные данные могли использоваться другими инструментами, такими как Амазонка Афина.
Создание рецепта DataBrew
Начните с регистрации хранилища данных для файла утверждений. Это позволит вам создать рецепт в его интерактивном редакторе, используя фактические данные, чтобы вы могли оценить результат преобразований по мере их определения.
- Загрузите CSV-файл претензий, используя следующую ссылку: alabama_claims_data_Jun2023.csv.
- На консоли DataBrew выберите Datasets в области навигации, затем выберите Подключить новый набор данных.
- Выберите опцию загрузка файлов.
- Что касается Имя набора данных, войти
Alabama claims. - Что касается Выберите файл для загрузки, выберите файл, который вы только что загрузили на свой компьютер.
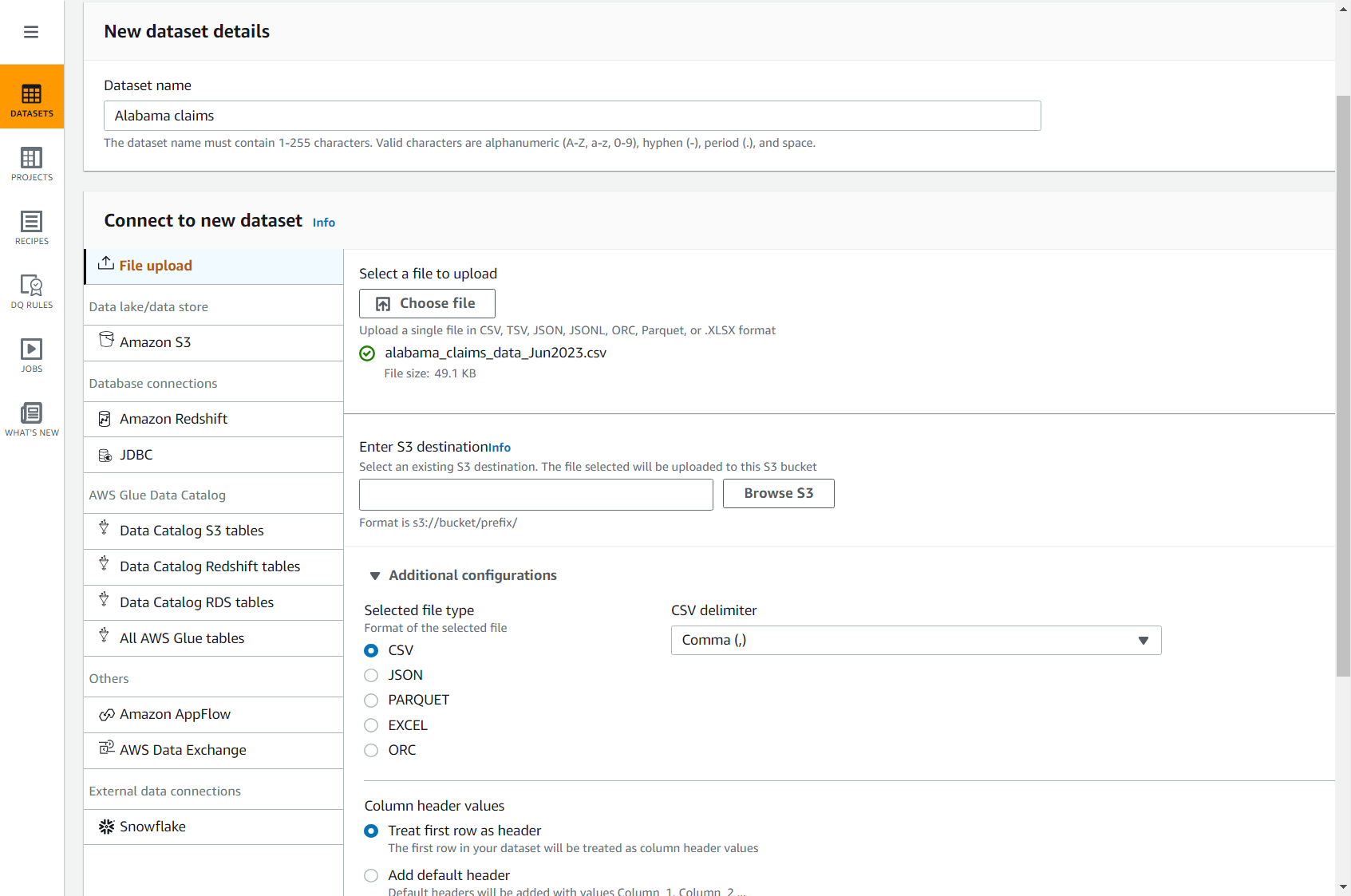
- Что касается Введите пункт назначения S3, введите или перейдите к корзине в своей учетной записи и регионе.
- Оставьте остальные параметры по умолчанию (CSV через запятую и с заголовком) и завершите создание набора данных.
- Выберите Проект в области навигации, затем выберите Создать проект.
- Что касается Название проекта, назови это
ClaimsCleanup. - Под Детали рецепта, Для Прикрепленный рецепт, выберите Создать новый рецепт, назови это
ClaimsCleanup-recipe, и выберитеAlabama claimsнабор данных, который вы только что создали.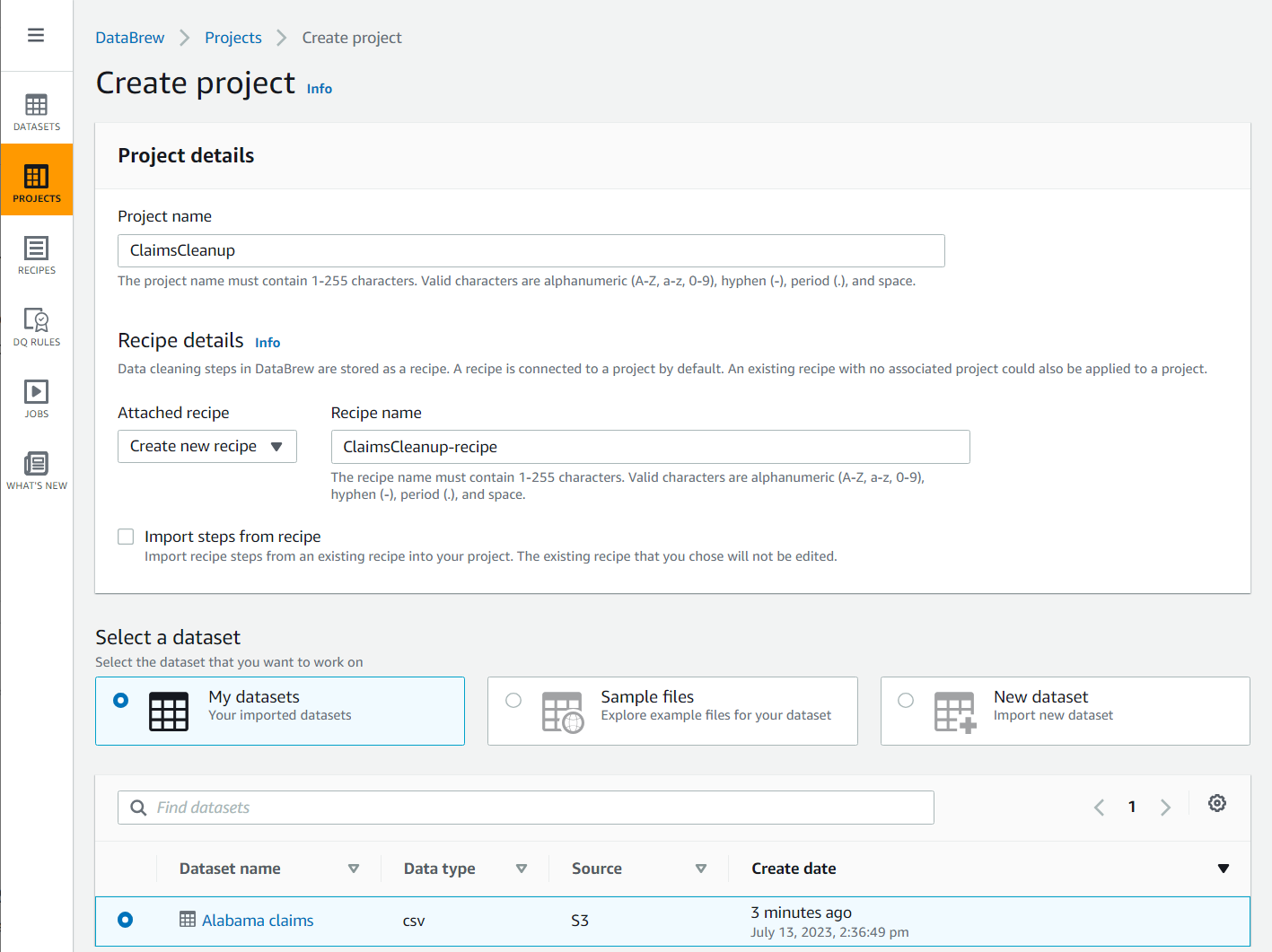
- Выберите роль подходит для DataBrew или создайте новый и завершите создание проекта.
Это создаст сеанс с использованием настраиваемого подмножества данных. После инициализации сеанса вы можете заметить, что в некоторых ячейках есть недопустимые или отсутствующие значения.
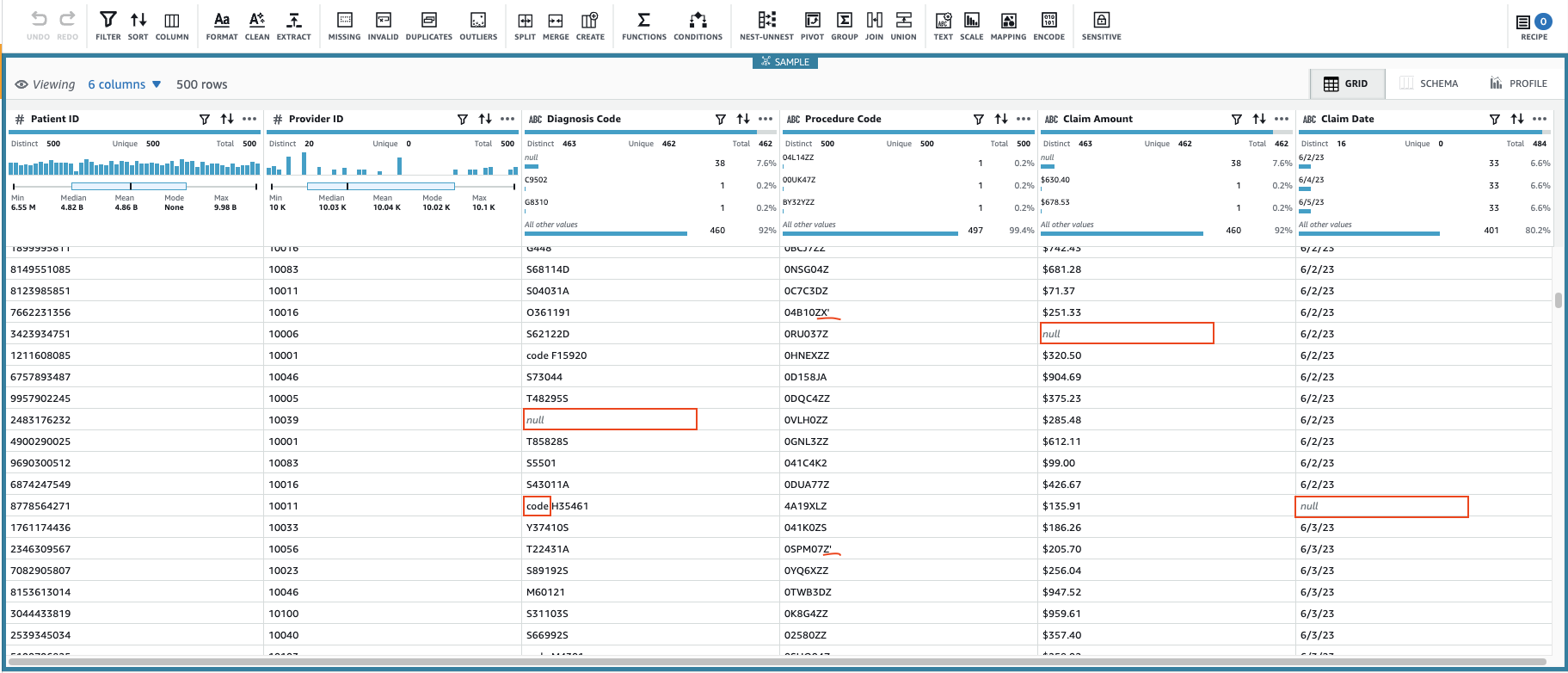
В дополнение к отсутствующим значениям в столбцах Код диагностики, Сумма претензиии Дата претензии, некоторые значения в данных содержат дополнительные символы: Код диагностики значения иногда имеют префикс «код» (включая пробел) и Код процедуры значения иногда заключаются в одинарные кавычки.
Сумма претензии значения, скорее всего, будут использоваться для некоторых расчетов, поэтому преобразуйте их в числа и Претензия данных должны быть преобразованы в тип даты.
Теперь, когда мы определили проблемы с качеством данных, которые необходимо решить, нам нужно решить, как действовать в каждом случае.
Есть несколько способов добавить этапы рецепта, в том числе с помощью контекстного меню столбца, панели инструментов вверху или из сводки рецепта. Используя последний метод, вы можете найти указанный тип шага, чтобы воспроизвести рецепт, созданный в этом посте.
Сумма претензии имеет важное значение для этого варианта использования, и решение состоит в том, чтобы удалить такие строки.
- Добавьте шаг Удалить пропущенные значения.
- Что касается Исходный столбец, выберите Сумма претензии.
- Оставьте действие по умолчанию Удалить строки с отсутствующими значениями , а затем выбрать Применить чтобы сохранить его.
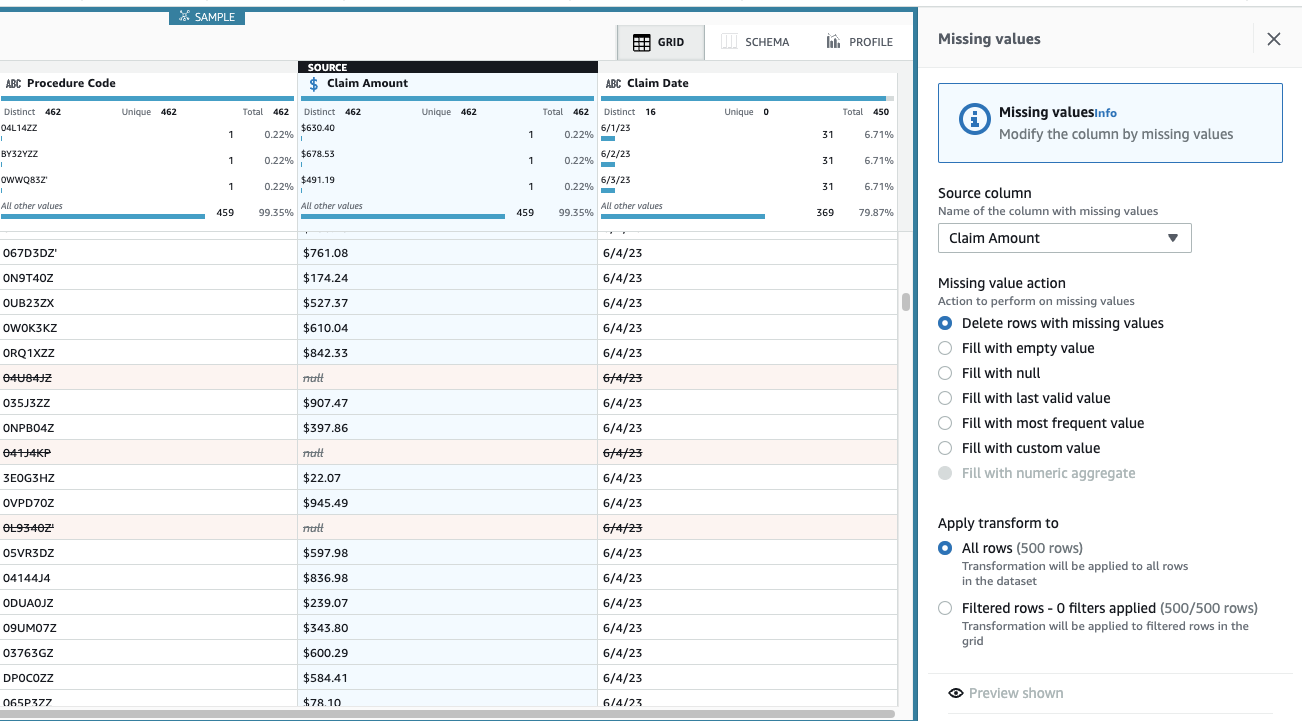
Представление теперь обновлено, чтобы отразить пошаговое приложение, и строк с отсутствующими суммами больше нет.
Код диагностики может быть пустым, поэтому это принимается, но в случае Дата претензии, мы хотим иметь разумную оценку. Строки в данных отсортированы в хронологическом порядке, поэтому вы можете заменить отсутствующие даты, используя допустимые значения предварительного просмотра из предыдущих строк. Предполагая, что каждый день есть заявки, самой большой ошибкой было бы присвоить ее дню предварительного просмотра, если бы это была первая заявка в этот день, в которой отсутствует дата; для наглядности допустим эту потенциальную ошибку.
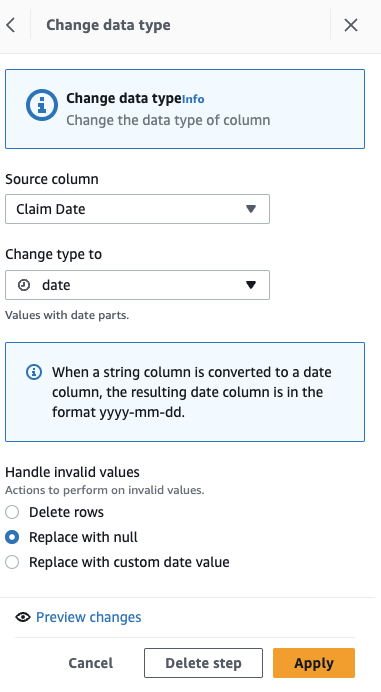
Сначала преобразуйте столбец из строки в тип даты.
- Добавьте шаг Изменить тип.
- Выберите Дата претензии как колонна и даты в качестве типа, затем выберите Применить.
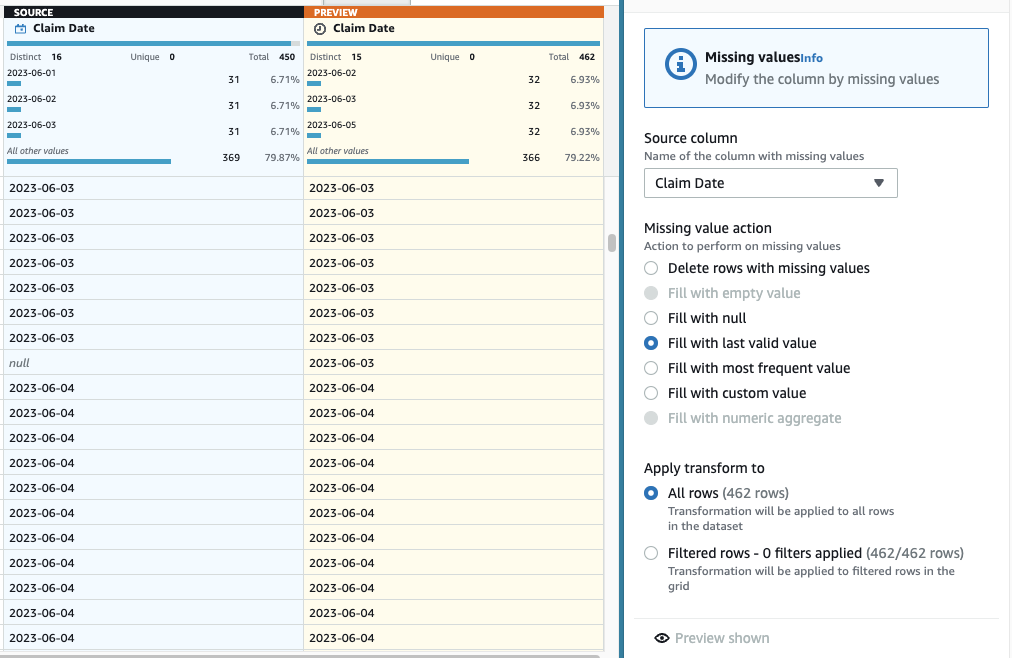
- Теперь, чтобы выполнить вменение отсутствующих дат, добавьте шаг Заполнить или заменить пропущенные значения.
- Выберите Заполнить последним допустимым значением в качестве действия и выберите Дата претензии как источник
- Выберите Предварительный просмотр изменений чтобы подтвердить его, затем выберите Применить чтобы сохранить шаг.
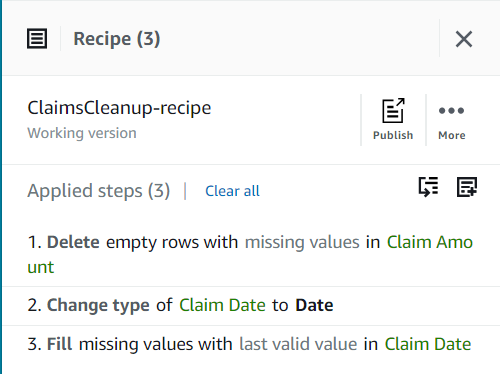
Пока ваш рецепт должен состоять из трех шагов, как показано на следующем снимке экрана.
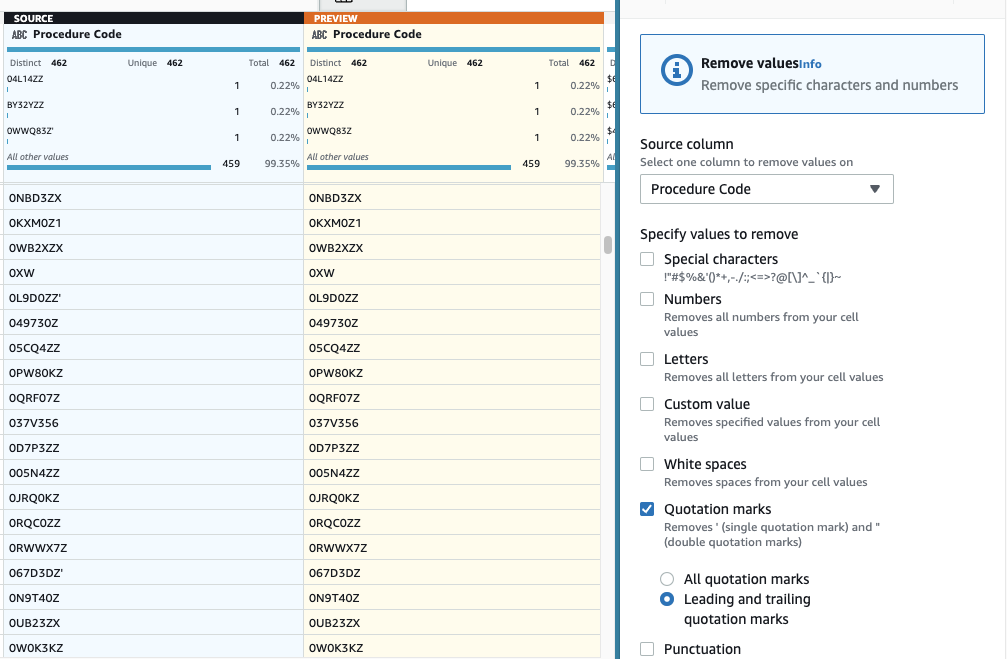
- Далее добавляем шаг Удалить кавычки.
- Выберите Код процедуры столбец и выберите Начальные и конечные кавычки.
- Предварительный просмотр, чтобы убедиться, что это дает желаемый эффект, и применить новый шаг.
- Добавьте шаг Удалить специальные символы.
- Выберите Сумма претензии столбец и, чтобы быть более конкретным, выберите Пользовательские специальные символы и введите
$для Введите специальные символы.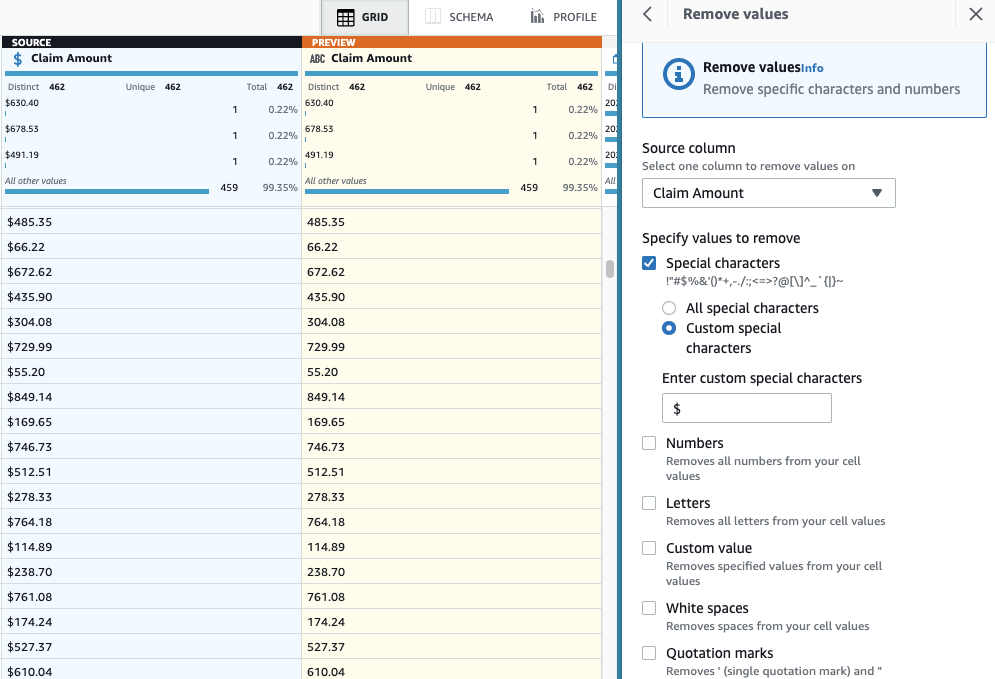
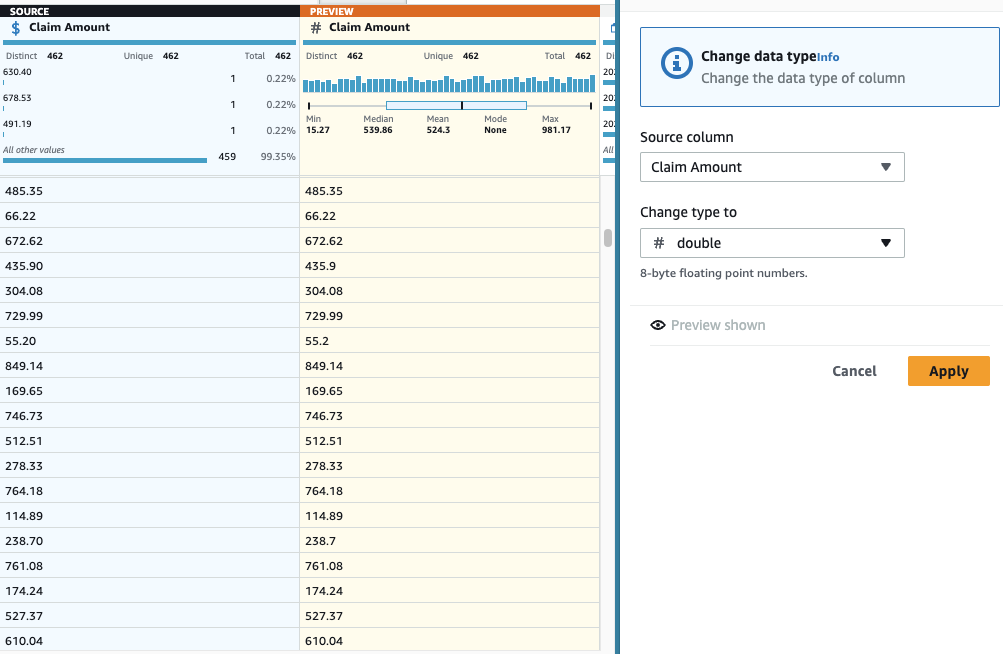
- Добавить Изменить тип наступить на колонну Сумма претензии , а затем выбрать двойной как тип.
- В качестве последнего шага, чтобы удалить лишний префикс «код», добавьте Заменить значение или шаблон шаг.
- Выберите столбец Код диагностики, А для Введите пользовательское значение, войти
code(с пробелом в конце).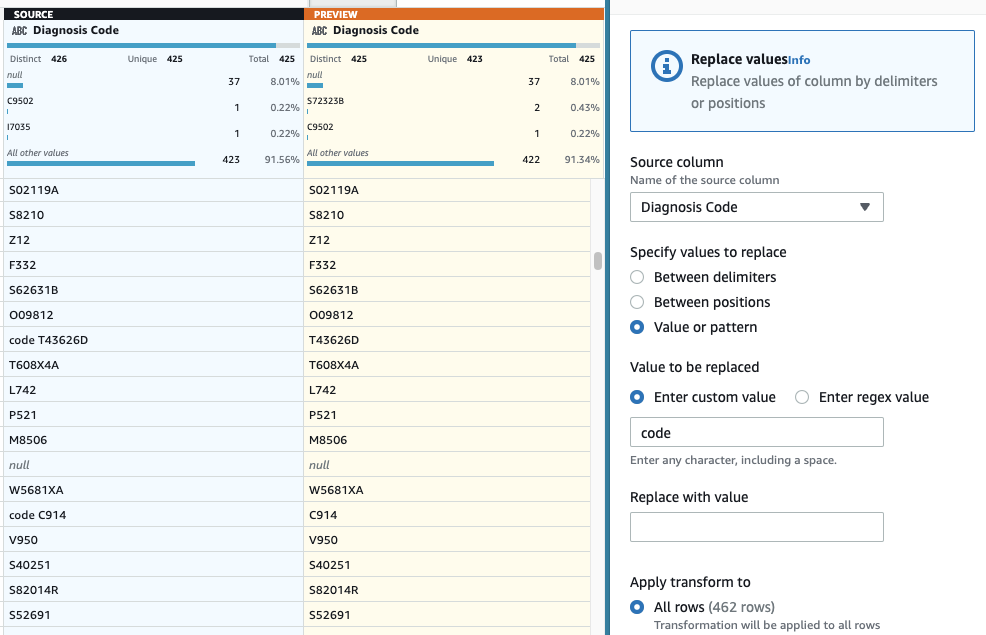
Теперь, когда вы устранили все проблемы с качеством данных, выявленные в образце, опубликуйте проект как рецепт.
- Выберите Опубликовать в Разработка введите необязательное описание и завершите публикацию.
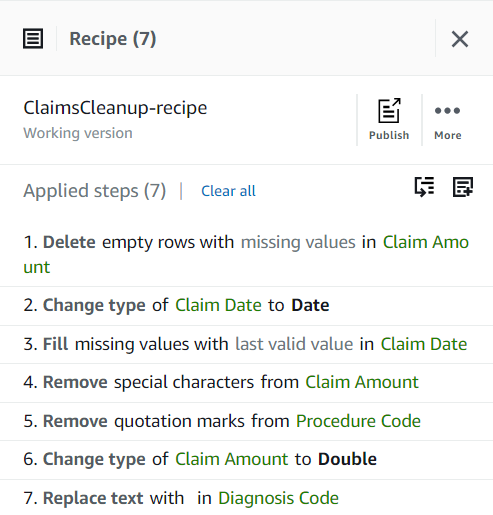
Каждый раз, когда вы публикуете, будет создаваться другая версия рецепта. Позже вы сможете выбрать, какую версию рецепта использовать.
Создание визуального задания ETL в AWS Glue Studio
Затем вы создаете задание, использующее этот рецепт. Выполните следующие шаги:
- На консоли AWS Glue Studio выберите Визуальный ETL в навигационной панели.
- Выберите Визуальный с пустым холстом и создайте визуальную работу.
- В верхней части задания замените «Задание без названия» на имя по вашему выбору.
- На Сведения о задании на вкладке укажите роль, которую будет использовать задание.
Это должно быть Управление идентификацией и доступом AWS (Я) роль, подходящая для AWS Glue с разрешениями на Amazon S3 и каталог данных AWS Glue. Обратите внимание, что роль, использовавшаяся ранее для DataBrew, не может использоваться для выполнения заданий, поэтому она не будет указана в списке. Роль IAM выпадающее меню здесь.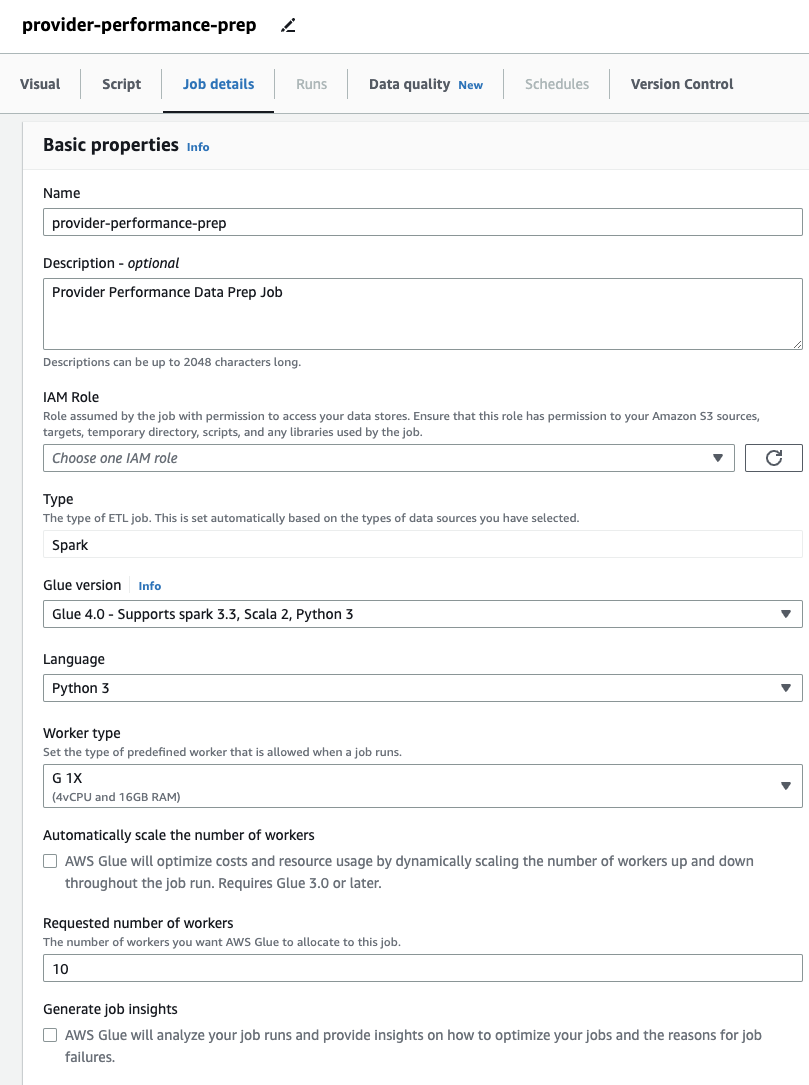
Если вы раньше использовали только задания DataBrew, обратите внимание, что в AWS Glue Studio вы можете выбирать параметры производительности и стоимости, включая размер исполнителя, автоматическое масштабирование и Гибкое исполнение, а также используйте новейшую среду выполнения AWS Glue 4.0 и пользуйтесь значительными улучшениями производительности, которые она обеспечивает. Для этой работы вы можете использовать настройки по умолчанию, но уменьшите запрошенное количество работников в интересах экономии. Для этого примера подойдут два рабочих. - На визуальный вкладку, добавьте источник S3 и назовите его
Providers. - Что касается URL-адрес S3, войти
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.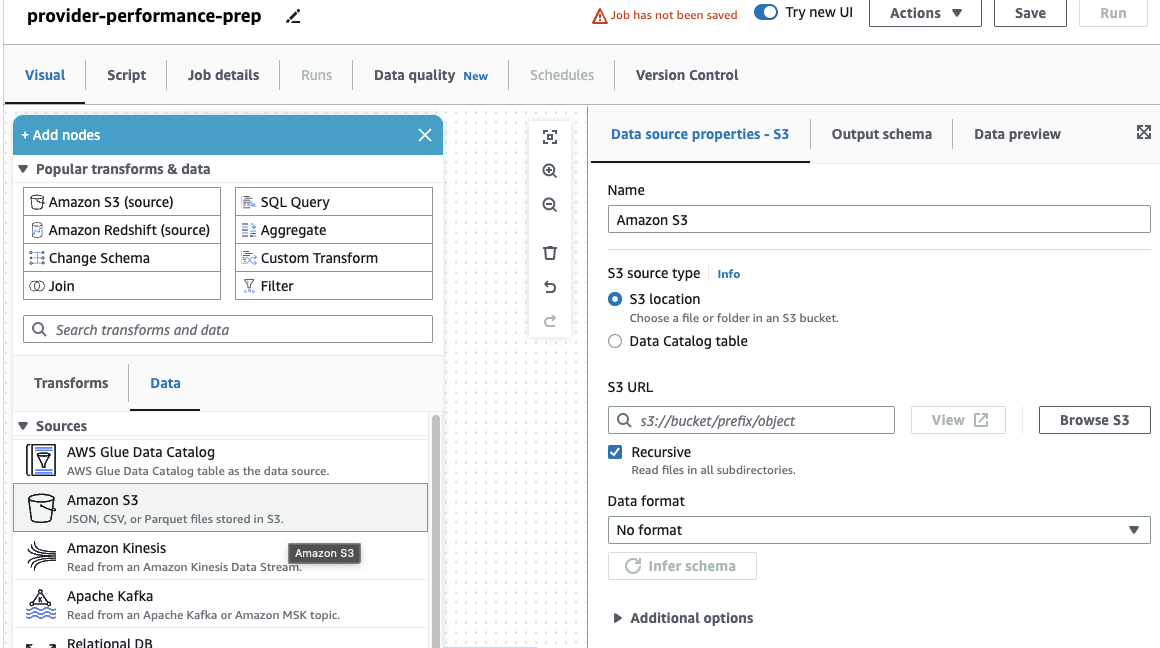
- Выберите формат как CSV , а затем выбрать Вывод схемы.
Теперь схема указана на Выходная схема tab, используя заголовок файла.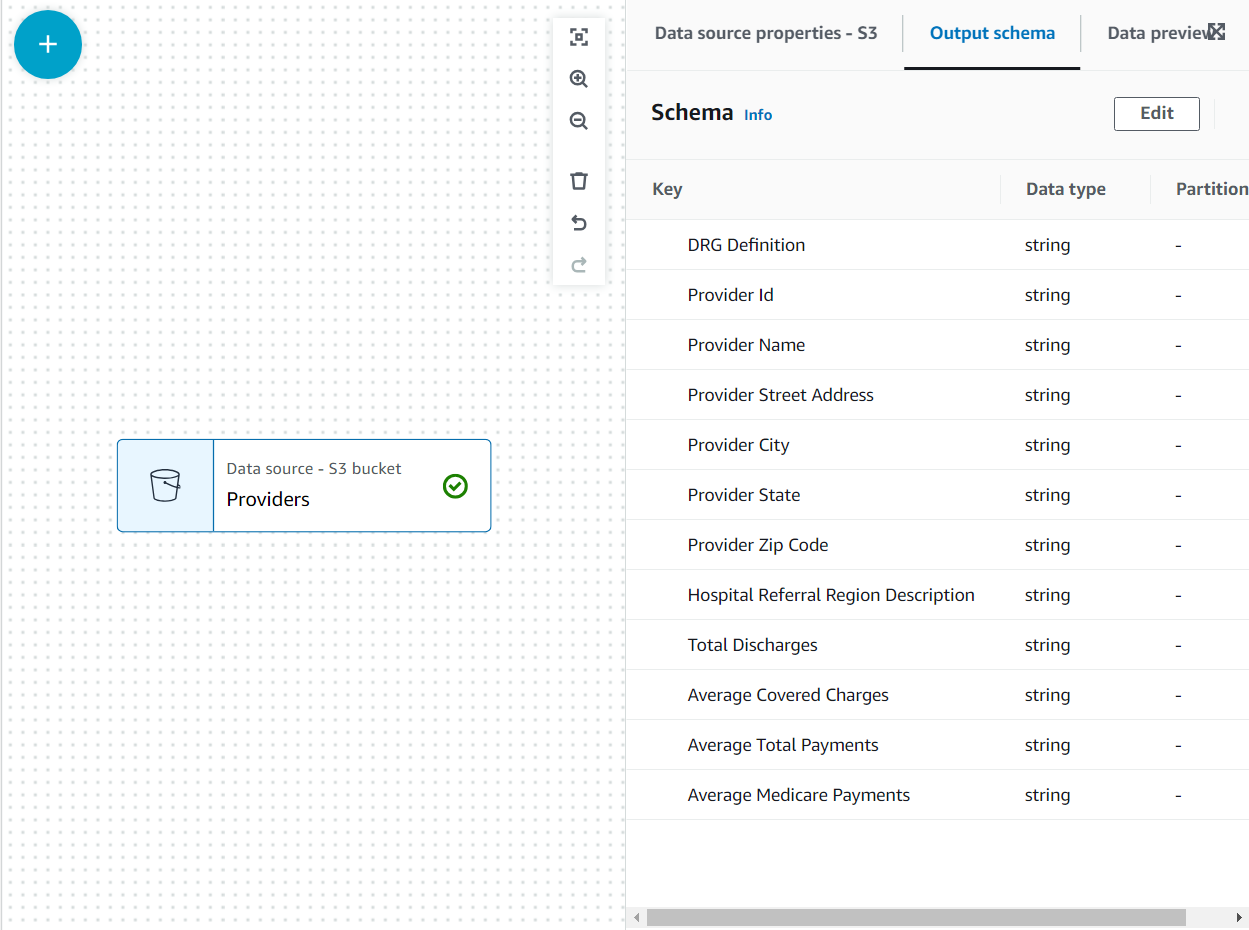
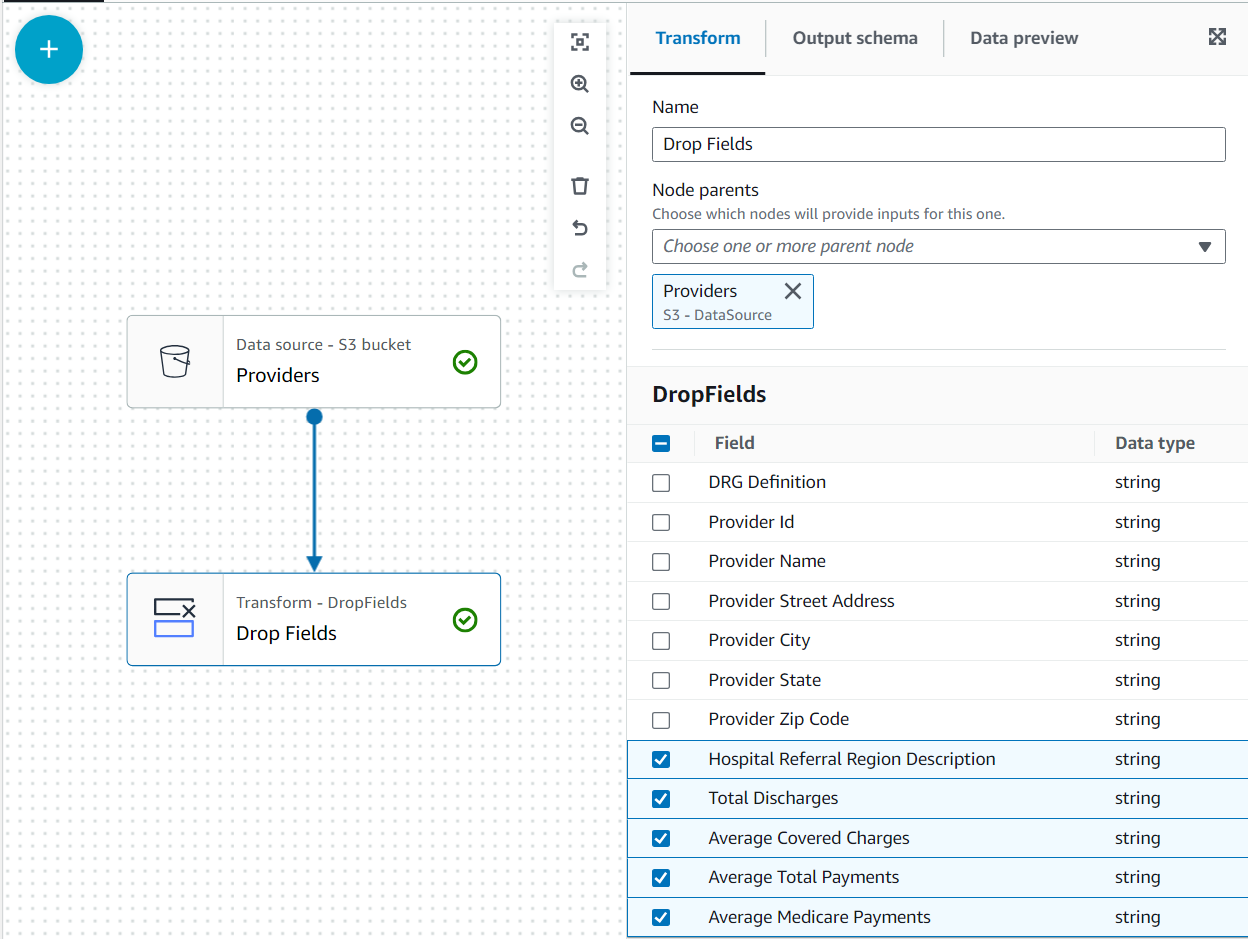
В этом случае решение состоит в том, что не все столбцы в наборе данных провайдеров необходимы, поэтому мы можем отбросить остальные.
- Для Провайдеры выбранный узел, добавьте Перетащите поля преобразование (если вы не выбрали родительский узел, у него его не будет; в этом случае назначьте родительский узел вручную).
- Выберите все поля после Почтовый индекс провайдера.
Позже к этим данным добавятся заявки на штат Алабама с использованием провайдера; однако этот второй набор данных не имеет указанного состояния. Мы можем использовать знание данных для оптимизации соединения, фильтруя данные, которые нам действительно нужны.
- Добавить ФИЛЬТР превратиться в ребенка Перетащите поля.
- Назови это
Alabama providersи добавьте условие, что состояние должно соответствоватьAL.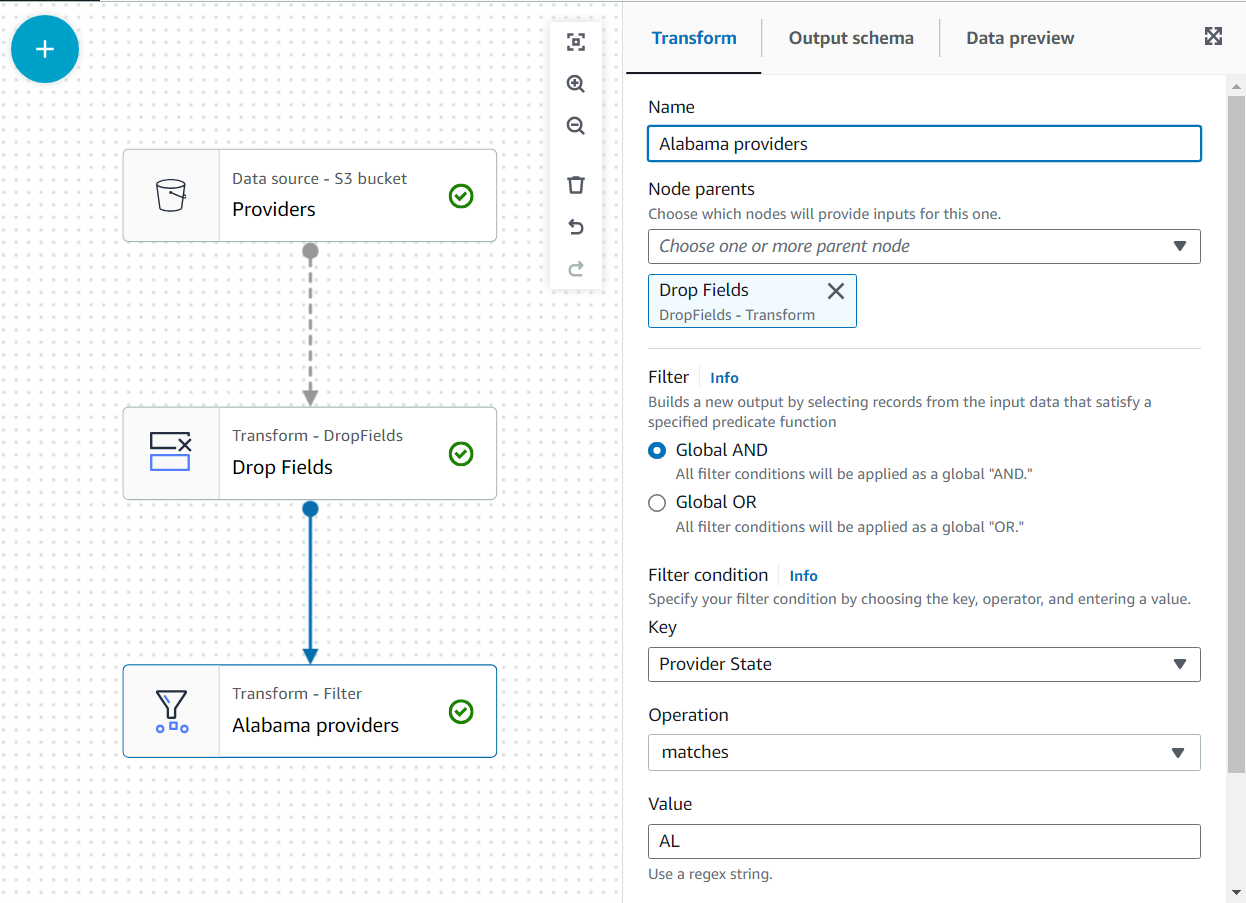
- Добавьте второй источник (новый источник S3) и назовите его.
Alabama claims. - Чтобы ввести URL-адрес S3, откройте DataBrew на отдельной вкладке браузера, выберите «Наборы данных» на панели навигации и в таблице скопируйте расположение, указанное в таблице, для претензии Алабамы (скопируйте текст, начинающийся с s3://, а не связанную ссылку http). Затем вернитесь к визуальному заданию, вставьте его как URL-адрес S3; если это правильно, вы увидите в Выходная схема вкладку перечисленных полей данных.
- Выберите формат CSV и сделайте вывод о схеме, как вы сделали с другим источником.
- Как дочерний элемент этого источника, выполните поиск в Добавить узлы меню для
recipe, а затем выбрать Рецепт подготовки данных.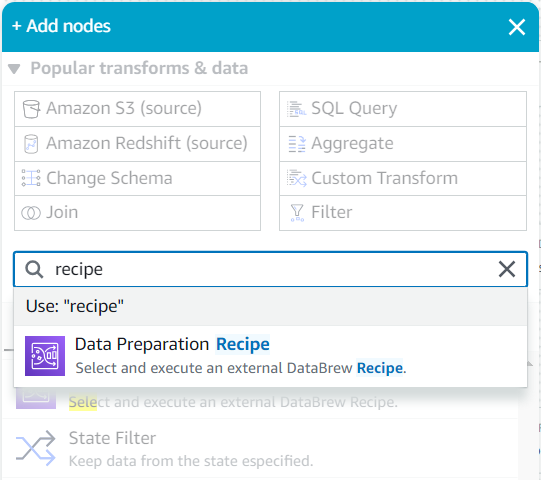
- В свойствах этого нового узла дайте ему имя
Claim cleanup recipeи выберите рецепт и версию, которую вы опубликовали ранее. - Вы можете просмотреть шаги рецепта здесь и использовать ссылку на DataBrew, чтобы внести изменения, если это необходимо.
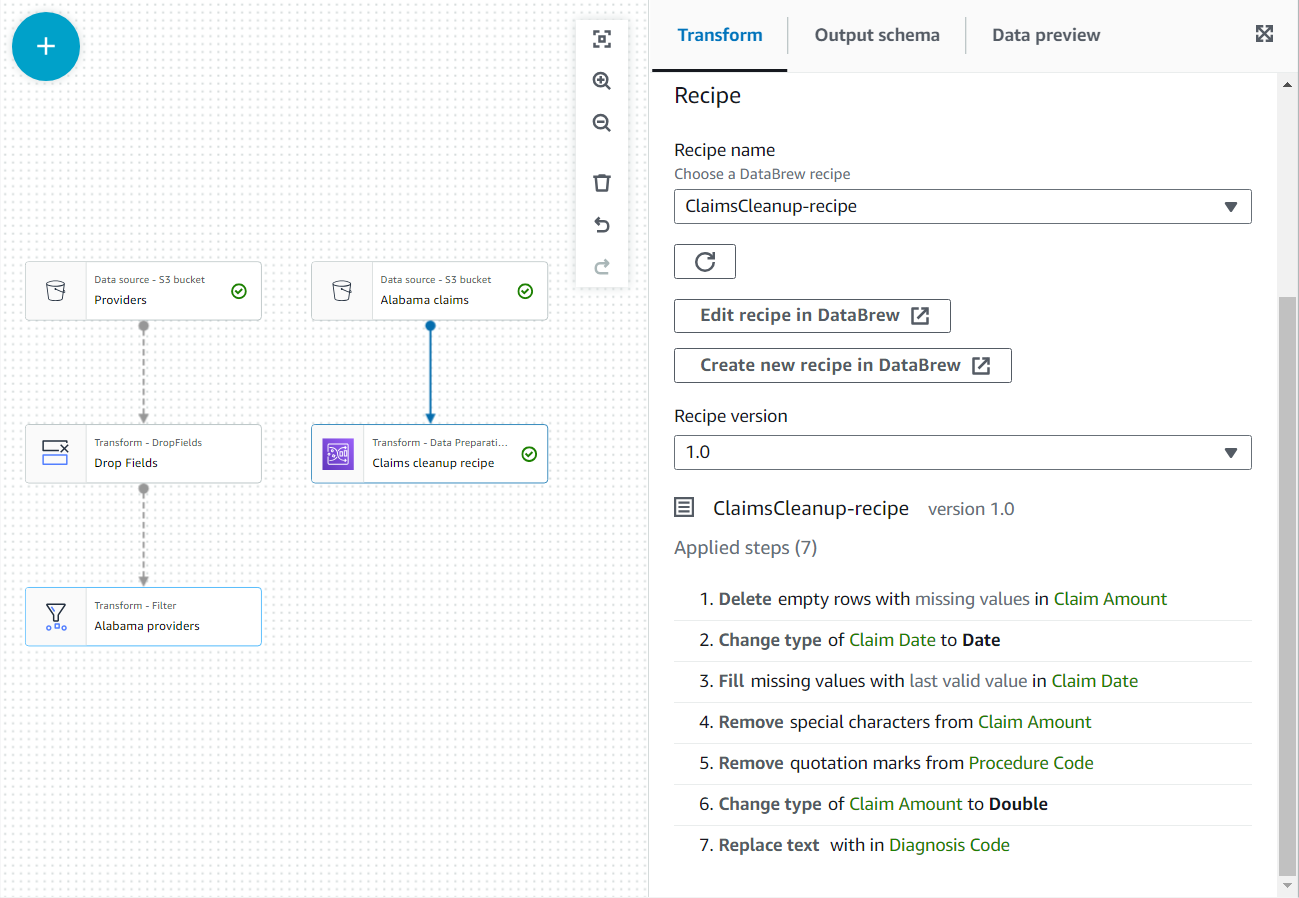
- Добавить Присоединиться узел и выберите оба провайдеры Алабамы и Требуйте рецепты очистки как родитель.
- Добавьте условие соединения, соответствующее идентификатору поставщика из обоих источников.
- В качестве последнего шага добавьте узел S3 в качестве цели (обратите внимание, что первый узел в списке при поиске является источником; убедитесь, что вы выбрали версию, указанную в качестве цели).
- В конфигурации узла оставьте формат JSON по умолчанию и введите URL-адрес S3, на запись которого у роли задания есть разрешение.
Кроме того, сделайте вывод данных доступным в виде таблицы в каталоге.
- В Параметры обновления каталога данных раздел, выберите второй вариант Создайте таблицу в каталоге данных и при последующих запусках обновите схему и добавьте новые разделы., затем выберите базу данных, в которой у вас есть разрешение на создание таблиц.
- Назначать
alabama_claimsкак имя и выберите Дата претензии в качестве ключа секции (это для иллюстрации; такая крошечная таблица, как эта, на самом деле не нуждается в секциях, если дополнительные данные не будут добавлены позже).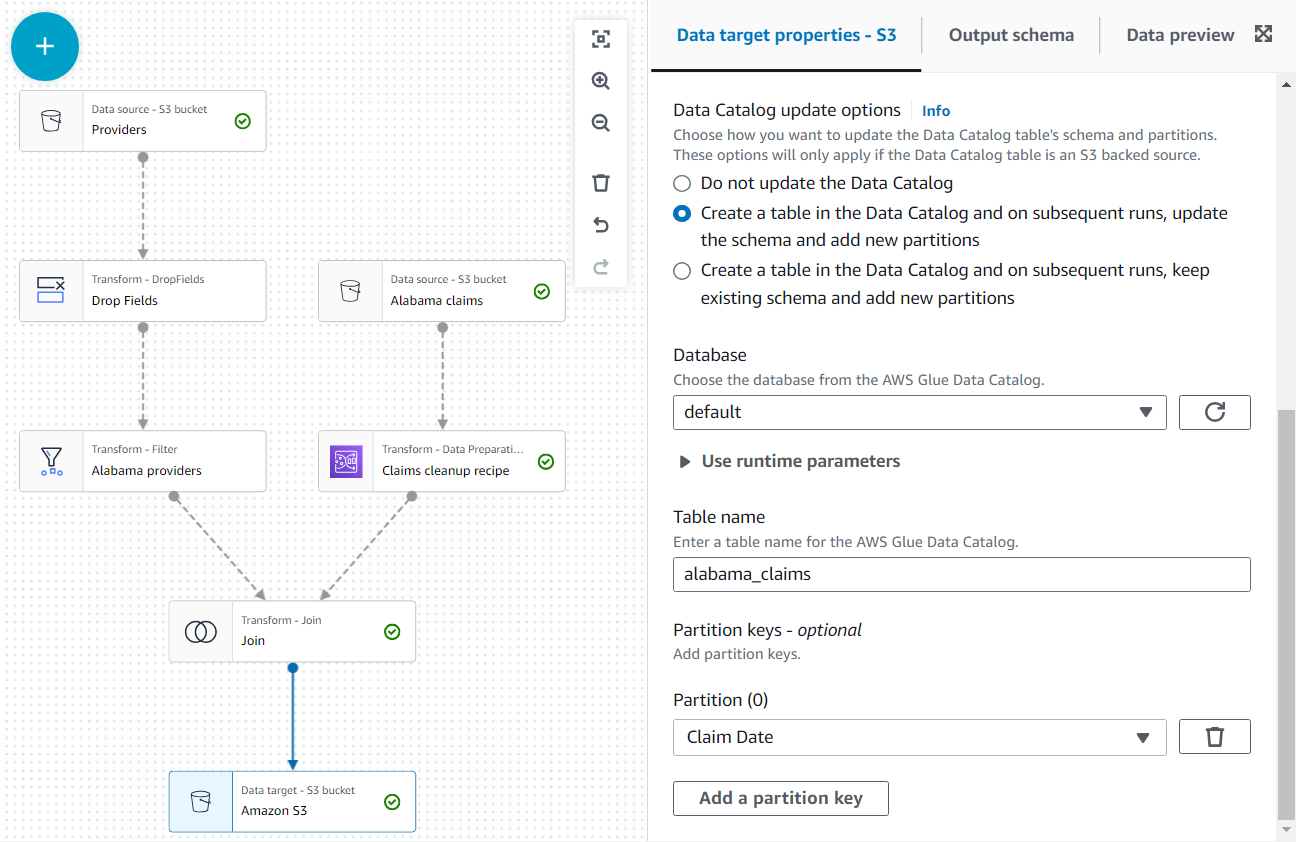
- Теперь вы можете сохранить и запустить задание.
- На Работает на вкладке вы можете отслеживать процесс и просматривать подробные показатели работы, используя ссылку идентификатора работы.
Работа должна занять несколько минут.
- По завершении задания перейдите к консоли Athena.
- Поиск таблицы
alabama_claimsв выбранной вами базе данных и с помощью контекстного меню выберите Таблица предварительного просмотра, который запустит простую инструкцию SELECT * SQL для таблицы.
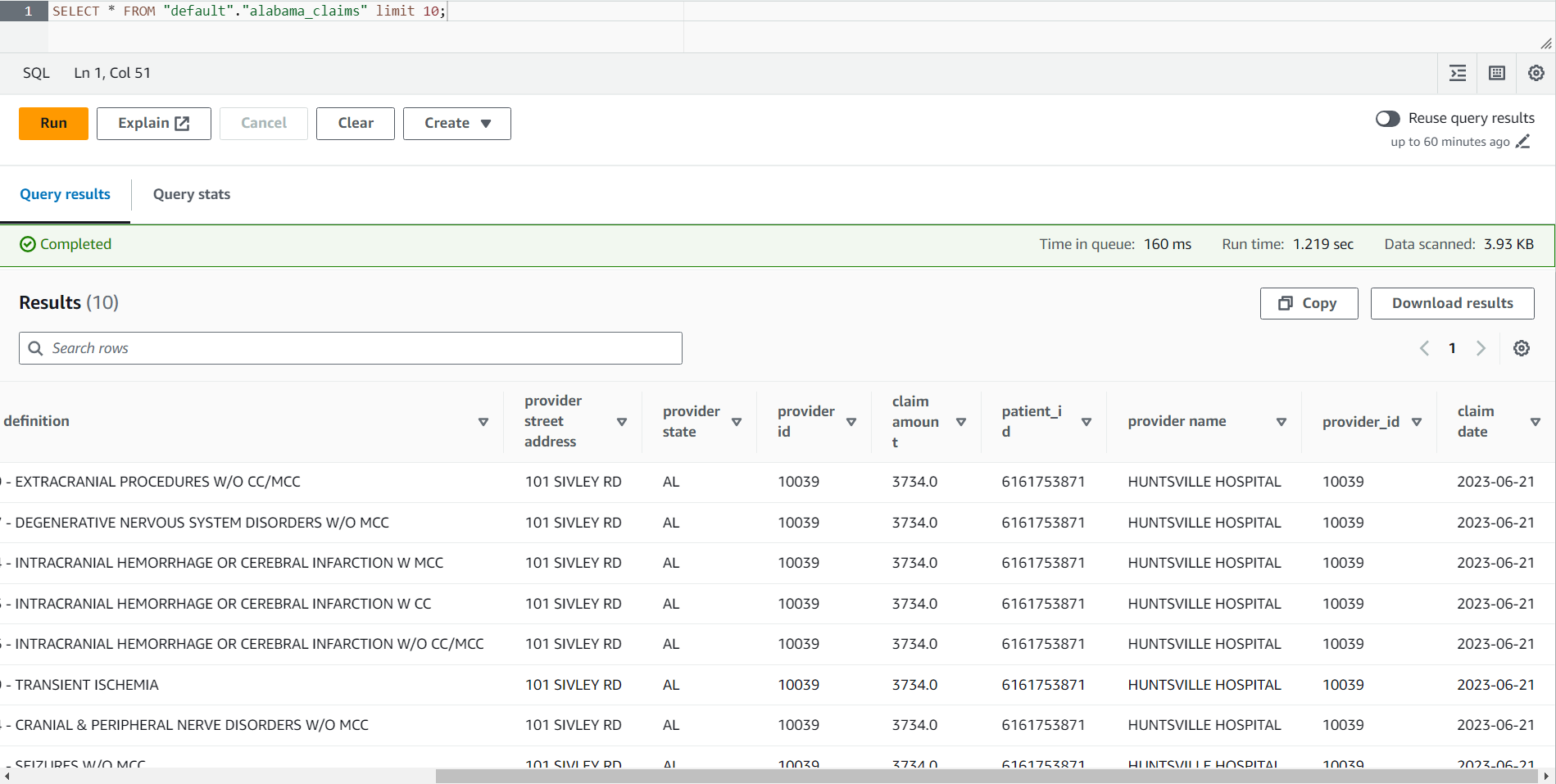
В результате работы видно, что данные были очищены рецептом DataBrew и обогащены соединением AWS Glue Studio.
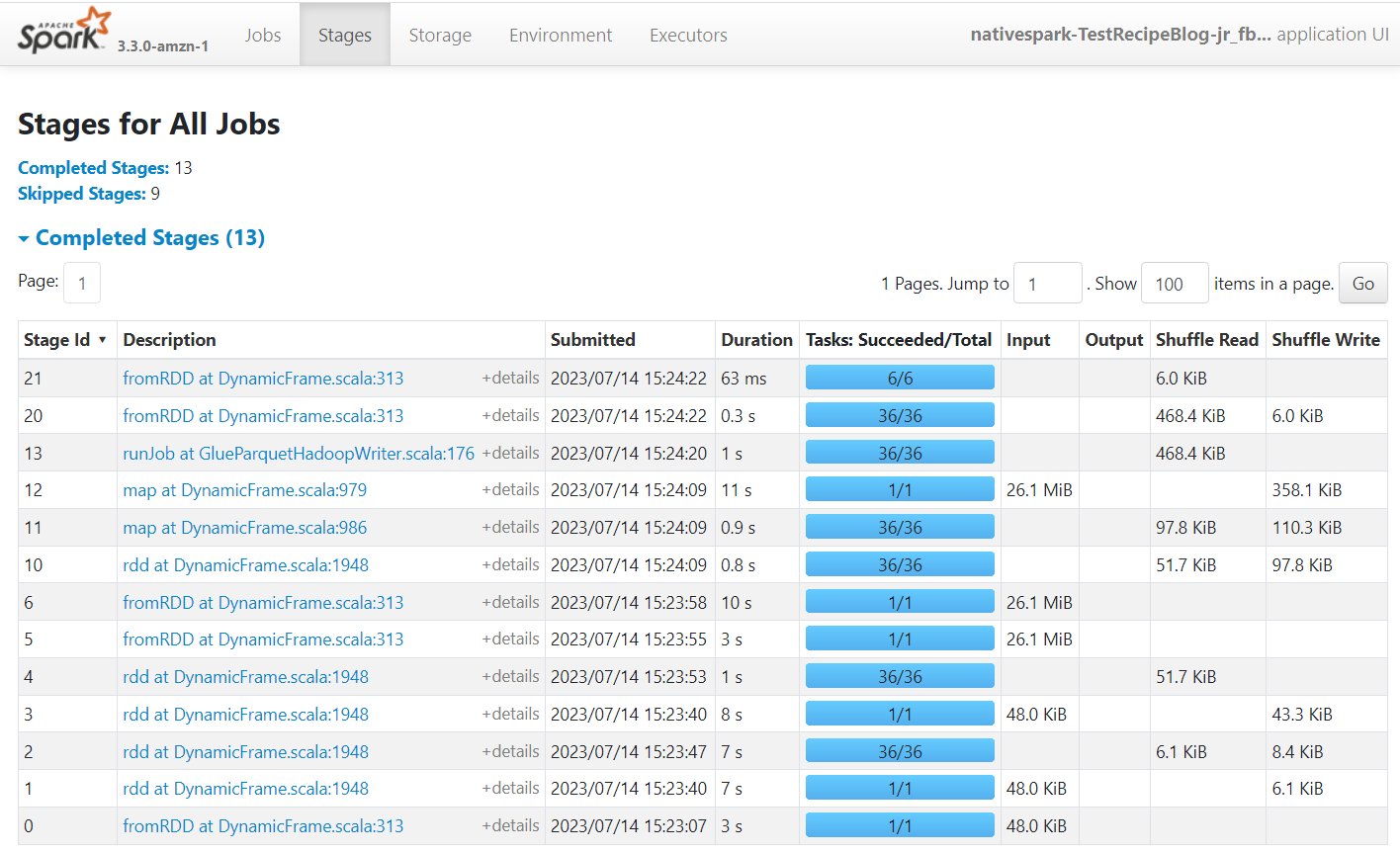
Apache Spark — это механизм, который запускает задания, созданные в AWS Glue Studio. Используя пользовательский интерфейс Spark в журналах событий, которые он создает, вы можете просматривать информацию о плане задания и выполнении, что может помочь вам понять, как выполняется ваше задание, и потенциальные узкие места производительности. Например, для этого задания с большим набором данных вы можете использовать его, чтобы сравнить влияние явной фильтрации состояния поставщика перед выполнением соединения или определить, можете ли вы извлечь выгоду из добавления преобразования автобаланса для улучшения параллелизма.
По умолчанию задание будет хранить журналы событий Apache Spark по пути s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Для просмотра заданий необходимо установить сервер истории с помощью один из доступных способов.
Убирать
Если вам больше не нужно это решение, вы можете удалить файлы, созданные в Amazon S3, таблицу, созданную заданием, рецепт DataBrew и задание AWS Glue.
Заключение
В этом посте мы показали, как можно использовать AWS DataBrew для создания рецепта с помощью предоставленного интерактивного редактора, а затем использовать опубликованный рецепт как часть визуального задания ETL в AWS Glue Studio. Мы включили несколько примеров распространенных задач, которые требуются при подготовке данных и добавлении данных в таблицы каталога AWS Glue.
В этом примере используется один рецепт в визуальном задании, но можно использовать несколько рецептов в разных частях процесса ETL, а также повторно использовать один и тот же рецепт в нескольких заданиях.
Эти решения AWS Glue позволяют эффективно создавать расширенные конвейеры ETL, которые легко создавать и поддерживать без написания кода. Вы можете начать создавать решения, сочетающие оба инструмента уже сегодня.
Об авторах
 Михаил Смирнов является старшим инженером по разработке программного обеспечения в команде AWS Glue и частью команды разработчиков AWS Glue DataBrew. Помимо работы, его интересы включают обучение игре на гитаре и путешествия с семьей.
Михаил Смирнов является старшим инженером по разработке программного обеспечения в команде AWS Glue и частью команды разработчиков AWS Glue DataBrew. Помимо работы, его интересы включают обучение игре на гитаре и путешествия с семьей.
 Гонсало Эррерос является старшим архитектором больших данных в команде AWS Glue. Находясь в Дублине, Ирландия, он помогает клиентам добиться успеха с решениями для больших данных на основе AWS Glue. В свободное время любит настольные игры и катается на велосипеде.
Гонсало Эррерос является старшим архитектором больших данных в команде AWS Glue. Находясь в Дублине, Ирландия, он помогает клиентам добиться успеха с решениями для больших данных на основе AWS Glue. В свободное время любит настольные игры и катается на велосипеде.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Автомобили / электромобили, Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- Смещения блоков. Модернизация права собственности на экологические компенсации. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- :имеет
- :является
- :нет
- $UP
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- в состоянии
- О нас
- приемлемый
- принятый
- доступ
- Учетная запись
- Действие
- фактического соединения
- Добавить
- добавленный
- добавить
- дополнение
- адрес
- продвинутый
- После
- Алабама
- Все
- позволять
- причислены
- Amazon
- Amazon Web Services
- суммы
- an
- Аналитики
- и
- любой
- апаш
- Apache Spark
- Применение
- Применить
- МЫ
- AS
- связанный
- At
- автор
- автоматический
- Автоматический
- доступен
- AWS
- Клей AWS
- назад
- основанный
- BE
- до
- не являетесь
- польза
- Преимущества
- большой
- Big Data
- пустой
- доска
- Настольные игры
- закладки
- изоферменты печени
- Приносит
- браузер
- строить
- но
- by
- CAN
- возможности
- случаев
- каталог
- Клетки
- централизованная
- изменение
- изменения
- символы
- ребенок
- выбор
- Выберите
- утверждать
- требования
- код
- Column
- Колонки
- объединять
- приход
- Общий
- сравнить
- полный
- компоненты
- компьютер
- состояние
- Конфигурация
- Рассматривать
- состоит
- Консоли
- контекст
- конвертировать
- переделанный
- исправить
- соответствующий
- Цена
- может
- Создайте
- создали
- Создающий
- создание
- изготовленный на заказ
- Клиенты
- данным
- Подготовка данных
- обработка данных
- Качество данных
- База данных
- Наборы данных
- Время
- Финики
- день
- сделка
- решать
- решение
- По умолчанию
- демонстрировать
- описание
- желанный
- подробный
- подробнее
- Дев
- Развитие
- Команда разработчиков
- DID
- различный
- отчетливый
- распределение
- do
- не
- дело
- Доллар
- двойной
- Падение
- Дублин
- каждый
- легко
- редактор
- эффект
- фактически
- позволяет
- конец
- Двигатель
- инженер
- обогащенный
- обогащение
- Enter
- ошибка
- существенный
- Эфир (ETH)
- оценивать
- Даже
- События
- Каждая
- каждый день
- пример
- Примеры
- существующий
- дополнительно
- извлечение
- семья
- далеко
- Особенности
- несколько
- Поля
- Файл
- Файлы
- заполнять
- фильтр
- фильтрация
- в заключение
- Во-первых,
- следует
- после
- Что касается
- формат
- от
- далее
- Игры
- генерируется
- Дайте
- большой
- Есть
- he
- помощь
- помогает
- здесь
- его
- история
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- IAM
- ID
- идентифицированный
- определения
- Личность
- if
- Влияние
- улучшать
- улучшение
- in
- включают
- включены
- В том числе
- указанный
- вход
- размышления
- устанавливать
- пример
- интегрированный
- интеграции.
- интерактивный
- интерес
- интересы
- Интерфейс
- в
- выпустили
- интуитивный
- Ирландия
- вопросы
- IT
- ЕГО
- работа
- Джобс
- присоединиться
- присоединился
- JPG
- JSON
- всего
- Сохранить
- Основные
- знания
- большой
- больше
- крупнейших
- Фамилия
- новее
- последний
- изучение
- Оставлять
- такое как
- Вероятно
- LINK
- Включенный в список
- загрузка
- расположение
- логика
- дольше
- поддерживать
- сделать
- ДЕЛАЕТ
- вручную
- Совпадение
- основным медицинским
- Меню
- метод
- методы
- Метрика
- минут
- отсутствующий
- монитор
- БОЛЕЕ
- с разными
- должен
- имя
- Откройте
- Навигация
- Необходимость
- необходимый
- потребности
- Новые
- нет
- узел
- Уведомление..
- сейчас
- номер
- of
- on
- ONE
- только
- открытый
- Оптимизировать
- Опция
- Опции
- or
- заказ
- Другое
- наши
- выходной
- внешнюю
- за
- общий
- хлеб
- часть
- части
- путь
- производительность
- выполнения
- разрешение
- Разрешения
- план
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- возможное
- После
- потенциал
- подготовка
- предварительный просмотр
- Превью
- процесс
- обработка
- производит
- Проект
- свойства
- при условии
- Недвижимости
- поставщики
- приводит
- Публикация
- публиковать
- опубликованный
- цель
- целей
- кавычки
- на самом деле
- разумный
- рецепт
- Рецепты
- уменьшить
- отражать
- область
- регистрирующий
- соответствующие
- удаление
- замещать
- просил
- обязательный
- требование
- соответственно
- ОТДЫХ
- результат
- Итоги
- снова использовать
- обзоре
- Роли
- Run
- работает
- то же
- Сохранить
- Шкала
- масштабирование
- Поиск
- Во-вторых
- Раздел
- посмотреть
- видя
- выбранный
- отдельный
- Услуги
- Сессия
- набор
- настройки
- должен
- показал
- показанный
- подпись
- значительный
- просто
- одинарной
- Размер
- небольшой
- So
- уже
- Software
- Решение
- Решения
- некоторые
- Источник
- Источники
- Space
- Искриться
- особый
- конкретный
- указанный
- SQL
- Начало
- Начало
- Область
- заявление
- статистике
- Шаг
- Шаги
- диск
- магазин
- простой
- строка
- студия
- последующее
- быть успешными
- такие
- подходящее
- РЕЗЮМЕ
- Убедитесь
- синтетический
- ТАБЛИЦЫ
- взять
- цель
- задачи
- команда
- проверенный
- который
- Ассоциация
- Источник
- Государство
- Их
- тогда
- Там.
- этой
- три
- время
- в
- сегодня
- инструментом
- инструменты
- топ
- трек
- Transform
- трансформация
- преобразований
- Путешествие
- два
- напишите
- ui
- под
- понимать
- Обновление ПО
- обновление
- URL
- годный к употреблению
- использование
- прецедент
- используемый
- пользователей
- использования
- через
- VALIDATE
- ценностное
- Наши ценности
- проверить
- версия
- Вид
- видимый
- хотеть
- законопроект
- способы
- we
- Web
- веб-сервисы
- ЧТО Ж
- были
- когда
- , которые
- будете
- без
- Работа
- работник
- рабочие
- рабочий
- бы
- записывать
- письмо
- являетесь
- ВАШЕ
- зефирнет
- ZIP