Введение
Объединение искусственный интеллект (ИИ) и артистизм открывают новые возможности в творческом цифровом искусстве, в первую очередь за счет диффузионных моделей. Эти модели выделяются среди творческого поколения искусств искусственного интеллекта, предлагая подход, отличный от традиционных нейронных сетей. Эта статья отправит вас в исследовательское путешествие в глубины моделей диффузии, объясняя их уникальный механизм создания визуально потрясающих и творчески богатых произведений искусства. Изучите нюансы моделей распространения и узнайте их роль в переосмыслении художественного самовыражения через призму передовых технологий искусственного интеллекта.

Цели обучения
- Понимать фундаментальные концепции моделей диффузии в ИИ.
- Изучите разницу между моделями диффузии и традиционными нейронными сетями в создании произведений искусства.
- Проанализируйте процесс создания искусства, используя модели диффузии.
- Оцените творческое и эстетическое значение ИИ в цифровом искусстве.
- Обсудите этические аспекты произведений искусства, созданных с помощью ИИ.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
Понимание моделей диффузии

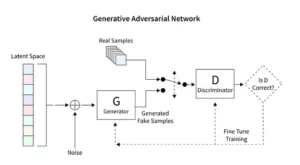
Модели диффузии произвели революцию в генеративном искусственном интеллекте, представляя уникальный метод создания изображений, отличный от традиционных методов, таких как генеративно-состязательные сети (GAN). Начиная со случайного шума, эти модели постепенно совершенствуют его, напоминая художника, настраивающего картину, в результате чего получаются сложные и связные изображения.
Этот процесс постепенного уточнения отражает методическую природу распространения. Здесь каждая итерация слегка меняет шум, приближая его к окончательному художественному замыслу. Результат — это не просто продукт случайности, а развитое произведение искусства, отличающееся своим развитием и завершением.
Кодирование диффузионных моделей требует глубокого понимания нейронных сетей и фреймворков машинного обучения, таких как TensorFlow или PyTorch. Получающийся в результате код является сложным и требует обширного обучения на обширных наборах данных для достижения тонких эффектов, наблюдаемых в искусстве, созданном ИИ.
Применение стабильной диффузии в искусстве
Появление генераторов искусств искусственного интеллекта, таких как модели стабильной диффузии, требует сложного кодирования на таких платформах, как TensorFlow или PyTorch. Эти модели выделяются своей способностью методично превращать случайность в структуру, подобно тому, как художник превращает предварительный эскиз в яркий шедевр.
Модели стабильной диффузии меняют художественную сцену ИИ, формируя упорядоченные изображения из случайности, избегая конкурентной динамики, характерной для GAN. Они преуспевают в интерпретации концептуальных подсказок в визуальном искусстве, способствуя синергетическому танцу между возможностями ИИ и человеческой изобретательностью. Используя PyTorch, мы наблюдаем, как эти модели итеративно превращают хаос в ясность, отражая путь художника от зарождающейся идеи до отточенного творения.
Экспериментируем с искусством, созданным искусственным интеллектом
Эта демонстрация погружает в увлекательный мир искусства, созданного искусственным интеллектом, с использованием сверточной нейронной сети, называемой Модель ConvDiffusionModel. Эта модель обучена на разнообразных художественных изображениях, включая рисунки, картины, скульптуры и гравюры, взятые из этот набор данных Kaggle. Наша цель — изучить способность модели улавливать и воспроизводить сложную эстетику этих произведений искусства.
Модельная архитектура и обучение
Архитектурный дизайн
По своей сути ConvDiffusionModel представляет собой чудо нейронной инженерии, обладающее сложной архитектурой кодировщика-декодера, адаптированной к требованиям создания произведений искусства. Структура модели представляет собой сложную нейронную сеть, объединяющую усовершенствованные механизмы кодирования-декодера, специально отточенные для создания произведений искусства. Благодаря дополнительным сверточным слоям и пропускаемым соединениям, которые имитируют художественную интуицию, модель может анализировать и собирать произведения искусства, тонко понимая композицию и стиль.
- Кодер: Кодер — это аналитический глаз модели, тщательно изучающий мельчайшие детали каждого входного изображения. По мере того как изображения проходят через сверточные слои кодера, они постепенно сжимаются в скрытое пространство — компактное закодированное представление исходного произведения искусства. Наш кодер не только тщательно изучает входные изображения, но теперь делает это с повышенной глубиной восприятия благодаря дополнительным слоям и методам пакетной нормализации. Это расширенное исследование позволяет получить более богатое и сжатое представление скрытого пространства, отражающее глубокое созерцание предмета художником.
- декодер: Напротив, декодер служит творческой рукой модели, беря абстрактные эскизы из кодера и вдыхая в них жизнь. Он реконструирует произведение искусства из скрытого пространства, слой за слоем, деталь за деталью, пока не возникнет целостное изображение. Наш декодер использует преимущества пропуска соединений и может восстанавливать изображения с большей точностью. Он пересматривает абстрактную суть входных данных и постепенно украшает их, добиваясь более точного воспроизведения исходного материала. Улучшенные слои работают согласованно, гарантируя, что окончательное изображение станет ярким и сложным произведением, отражающим артистизм входных данных.
Учебный процесс
Обучение ConvDiffusionModel — это путешествие по художественному ландшафту, охватывающему 150 эпох. Каждая эпоха представляет собой полный проход через весь набор данных, при этом модель стремится уточнить свое понимание и повысить точность создаваемых изображений.
- Гибридная функция потерь: В основе обучения лежит функция потерь среднеквадратической ошибки (MSE). Эта функция количественно определяет разницу между оригинальным шедевром и воссозданной моделью, обеспечивая четкую метрику для минимизации. Мы введем компонент перцепционных потерь, полученный из предварительно обученной сети VGG, который дополняет метрику среднеквадратической ошибки (MSE). Эта стратегия двойной потери позволяет модели сохранять художественную целостность оригиналов, одновременно совершенствуя техническое воспроизведение их деталей.
- Оптимизатор: Благодаря тому, что скорость обучения динамически регулируется планировщиком, оптимизатор Адама управляет обучением модели с большей точностью. Этот адаптивный подход гарантирует, что прогресс модели в обучении воспроизведению и обновлению искусства будет стабильным и устойчивым.
- Итерация и уточнение: Итерации обучения — это танец между сохранением художественной сути и стремлением к техническому воспроизведению. С каждым циклом модель приближается к синтезу точности и креативности.
- Визуализация прогресса: изображения сохраняются через регулярные промежутки времени во время обучения, чтобы визуализировать прогресс модели.. Эти снимки открывают окно в кривую обучения модели, демонстрируя, как развивается созданное ею искусство, становясь более ясным, детальным и художественно последовательным с каждой эпохой.



Вышеупомянутое демонстрируется с помощью следующего фрагмента кода:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
Визуализация созданного изображения
Проявление артистизма, созданного искусственным интеллектом
Теперь, когда ConvDiffusionModel полностью обучена, фокус смещается от абстрактного к конкретному — от потенциала к реализации искусства, созданного ИИ. Последующий фрагмент кода материализует изученные художественные способности модели, преобразуя входные данные в цифровой холст выражения.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()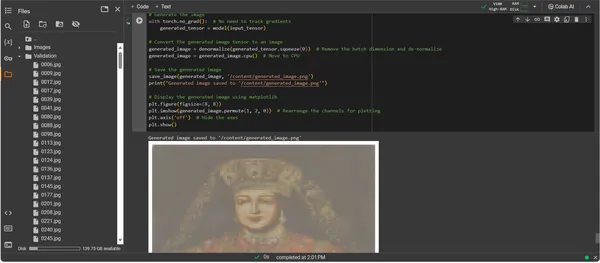

Пошаговое руководство по коду создания иллюстраций
- Модель Воскресения: Первым шагом в создании изображения является возрождение нашей обученной модели ConvDiffusionModel. Изученные веса модели загружаются и переводятся в режим оценки, подготавливая почву для создания без дальнейшего изменения ее параметров.
- Преобразование изображения: Чтобы обеспечить согласованность с режимом обучения, входные изображения обрабатываются с помощью одной и той же последовательности преобразований. Это включает в себя изменение размера в соответствии с входными размерами модели, преобразование тензоров для совместимости с PyTorch и нормализацию на основе статистического профиля обучающих данных.
- Утилита денормализации: Пользовательская функция меняет эффекты предварительной обработки, повторно масштабируя тензор до цветового диапазона исходного изображения. Этот шаг важен для преобразования сгенерированных результатов в визуально точное представление.
- Подготовка ввода: Изображение загружается и подвергается вышеупомянутым преобразованиям. Очень важно отметить, что это изображение служит музой, из которой ИИ будет черпать вдохновение — тихий шепот воспламеняет синтетическое воображение модели.
- Синтез произведений искусства: В тонком танце прямого распространения модель интерпретирует входной тензор, позволяя ее слоям сотрудничать в создании нового художественного видения. Выполните этот процесс, не отслеживая градиенты, поскольку сейчас мы находимся в области применения, а не обучения.
- Преобразование изображения: Тензорный вывод модели, который теперь содержит цифровое произведение искусства, денормализуется, переводя творение модели обратно в знакомое пространство цвета и света, которое могут оценить наши глаза.
- Откровение произведения искусства: Преобразованный тензор размещается на цифровом холсте, после чего сохраняется файл изображения. Этот файл — окно в творческую душу ИИ, статическое эхо динамического процесса, давшего ему жизнь.
- Поиск произведений искусства: Скрипт завершает сохранение сгенерированного изображения по указанному пути и объявляет о его завершении. Сохраненный образ, синтез изученных художественных принципов и зарождающегося творчества, готов к показу и созерцанию.
Анализ вывода
Выходные данные ConvDiffusionModel представляют собой фигуру с явным намеком на историческое искусство. Изображение, облаченное в изысканный наряд, созданное с помощью искусственного интеллекта, повторяет величие классических портретов, но с отчетливым современным оттенком. Одежда модели богата текстурами, сочетая изученные модели модели с новой интерпретацией. Нежные черты лица и тонкая игра света и тени демонстрируют тонкое понимание ИИ традиционных техник искусства. Это произведение искусства является свидетельством сложной подготовки модели и отражает элегантный синтез исторического искусства через призму передового машинного обучения. По сути, это цифровая дань прошлому, созданная с использованием алгоритмов настоящего.
Проблемы и этические соображения
Внедрение моделей диффузии для создания произведений искусства сопряжено с рядом проблем и этических соображений, которые вам следует учитывать:
- Происхождение данных: Наборы обучающих данных должны подходить ответственно. Крайне важно убедиться, что данные, используемые для обучения моделей распространения, не содержат произведений, защищенных авторским правом или защищенных без надлежащего разрешения.
- Предвзятость и представительство: Модели ИИ могут сохранять предвзятость в своих обучающих данных. Обеспечение разнообразных и инклюзивных наборов данных важно, чтобы избежать усиления стереотипов в искусстве, создаваемом искусственным интеллектом.
- Контроль над выходом: Поскольку модели распространения могут генерировать широкий спектр результатов, необходимо установить границы, чтобы предотвратить создание неуместного или оскорбительного контента.
- Правовые рамки: Отсутствие прочной правовой базы для учета нюансов использования ИИ в творческом процессе представляет собой проблему. Законодательство должно развиваться, чтобы защитить права всех вовлеченных сторон.
Заключение
Появление диффузионных моделей в искусственном интеллекте и искусстве знаменует собой эпоху преобразований, объединяющую точность вычислений с эстетическими исследованиями. Их путешествие в мир искусства подчеркивает значительный инновационный потенциал, но сопряжено со сложностями. Баланс между оригинальностью, влиянием, этичным творчеством и уважением к существующим произведениям является неотъемлемой частью художественного процесса.
Основные выводы
- Модели диффузии находятся в авангарде преобразующего сдвига в творчестве искусства. Они предлагают новые цифровые инструменты, которые расширяют возможности художественного самовыражения за пределы традиционных границ.
- В искусстве, улучшенном искусственным интеллектом, приоритет этического сбора обучающих данных и уважение интеллектуальной собственности создателей являются обязательными для поддержания целостности цифрового искусства.
- Сближение художественного видения и технологических инноваций открывает двери для симбиотических отношений между художниками и разработчиками ИИ. Создайте среду сотрудничества, которая может дать начало новаторскому искусству.
- Жизненно важно обеспечить, чтобы искусство, созданное ИИ, представляло широкий спектр точек зрения. Включайте разнообразный спектр данных, отражающих богатство различных культур и точек зрения, способствуя тем самым инклюзивности.
- Растущий интерес к искусству, созданному с помощью ИИ, требует создания прочной правовой базы. Эти рамки должны разъяснять вопросы авторского права, признавать вклад и регулировать коммерческое использование произведений искусства, созданных ИИ.
Зарождение этой художественной эволюции открывает путь, полный творческого потенциала, но требующий внимательной опеки. На нас лежит обязанность создать среду, в которой процветает слияние искусственного интеллекта и искусства, руководствуясь ответственными и учитывающими культурные особенности практиками.
Часто задаваемые вопросы
А. Диффузионные модели — это генеративные алгоритмы машинного обучения, которые создают изображения, начиная с образца случайного шума и постепенно превращая его в связную картину. Этот процесс подобен тому, как художник начинает с чистого холста и медленно добавляет слои деталей.
A. GAN, диффузионные модели не требуют отдельной сети для оценки результатов. Они работают, итеративно добавляя и удаляя шум, что часто приводит к более детальным и детальным изображениям.
О. Да, модели диффузии могут создавать оригинальные произведения искусства, обучаясь на наборе данных изображений. Однако на оригинальность влияет разнообразие и объем обучающих данных. Продолжаются споры об этичности использования существующих произведений искусства для обучения этих моделей.
A. Этические проблемы включают предотвращение нарушения авторских прав на произведения искусства, созданные ИИ. Уважать оригинальность людей-художников, предотвращать сохранение предвзятости и обеспечивать прозрачность творческого процесса ИИ.
Ответ: Будущее искусства, созданного искусственным интеллектом, выглядит многообещающим: модели диффузии предлагают новые инструменты для художников и творцов. По мере развития технологий мы можем ожидать увидеть более сложные и замысловатые произведения искусства. Однако творческое сообщество должно руководствоваться этическими соображениями и работать над созданием четких руководящих принципов и лучших практик.
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :является
- :нет
- :куда
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- способность
- О нас
- выше
- АБСТРАКТ НАЯ
- точный
- Достигать
- достижение
- Адам
- адаптивный
- добавить
- дополнительный
- адрес
- Отрегулированный
- продвинутый
- авансы
- приход
- состязательный
- AI
- ай искусство
- родственный
- алгоритмы
- Все
- Позволяющий
- позволяет
- an
- Аналитические фармацевтические услуги
- аналитика
- Аналитика Видхья
- и
- объявляющий
- Применение
- ценить
- подхода
- архитектура
- МЫ
- Искусство
- гайд
- художник
- художественный
- художественно
- артистичность
- Специалисты ELAN
- произведение искусства
- Картины
- AS
- At
- дополненная
- разрешение
- доступен
- проспекты
- избежать
- избегающий
- ОСИ
- назад
- Плохой
- Балансировка
- основанный
- BE
- становление
- Преимущества
- ЛУЧШЕЕ
- лучшие практики
- между
- Beyond
- смещение
- предубеждения
- пустой
- смешивание
- блогатон
- рожденный
- изоферменты печени
- Границы
- дыхание
- наполненный до краев
- Приносит
- широкий
- принес
- растущий
- но
- by
- вычислять
- под названием
- CAN
- холст
- возможности
- возможности
- захватить
- вызов
- проблемы
- каналы
- Chaos
- характеристика
- проверка
- контроль
- зажим
- ясность
- класс
- Очистить
- понятнее
- ближе
- код
- Кодирование
- ПОСЛЕДОВАТЕЛЬНЫЙ
- сотрудничать
- совместный
- цвет
- выходит
- коммерческая
- сообщество
- компактный
- совместимость
- конкурентоспособный
- полный
- завершение
- комплекс
- сложности
- компонент
- композиция
- вычислительный
- Вычисление
- понятия
- концептуальный
- Обеспокоенность
- концерт
- заключает
- Коммутация
- Рассматривать
- соображения
- содержать
- содержание
- контраст
- взносы
- обычный
- Сближение
- Конверсия
- преобразование
- сверточная нейронная сеть
- авторское право
- нарушение авторского права
- Основные
- и коррумпированных лиц
- ЦП
- проработаны
- Создайте
- Создающий
- создание
- творческий
- Творчески
- креативность
- Создатели
- решающее значение
- кульминационным
- Культивировать
- культурно
- Куратор
- кривая
- изготовленный на заказ
- цикл
- танец
- данным
- Наборы данных
- дебаты
- глубоко
- определяющий
- запросы
- убивают
- глубина
- Глубины
- Производный
- назначенный
- подробность
- подробный
- подробнее
- застройщиков
- устройство
- отличаться
- разница
- различный
- Вещание
- Интернет
- цифровое искусство
- цифровой
- Размеры
- размеры
- усмотрение
- Дисплей
- отображать
- отчетливый
- различие
- Разное
- Разнообразие
- do
- приносит
- Двери
- рисовать
- Чертежи
- в течение
- динамический
- динамично
- динамика
- e
- каждый
- эхо
- отголоски
- эффекты
- Разрабатывать
- еще
- возникает
- закодированный
- охватывала
- охватывая
- Проект и
- расширение
- обеспечивать
- обеспечивает
- обеспечение
- Весь
- Окружающая среда
- эпоха
- эпохи
- Эпоха
- ошибка
- сущность
- существенный
- создание
- Эфир (ETH)
- этический
- этика
- оценка
- Каждая
- эволюция
- развивается
- эволюционировали
- эволюционирует
- экспертиза
- Excel
- Кроме
- существующий
- Расширьте
- экспансивный
- ожидать
- исследование
- Больше
- выражение
- расширенная
- обширный
- Глаза
- Глаза
- лицевой
- верный
- ложный
- знакомый
- увлекательный
- Особенности
- Показывая
- верность
- фигура
- Файл
- Файлы
- окончательный
- окончание
- Во-первых,
- Фокус
- после
- Что касается
- Передний край
- вперед
- Способствовать
- содействие
- Рамки
- каркасы
- от
- полностью
- функция
- функциональная
- фундаментальный
- далее
- слияние
- будущее
- Gain
- Gans
- сбор
- дал
- порождать
- генерируется
- порождающий
- поколение
- генеративный
- генеративные состязательные сети
- Генеративный ИИ
- генераторы
- Дайте
- цель
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- градиенты
- постепенно
- величие
- схватывание
- большой
- новаторским
- управляемый
- методические рекомендации
- Гиды
- рука
- Освоение
- Сердце
- здесь
- Спрятать
- основной момент
- исторический
- проведение
- почтение
- честь
- Как
- Однако
- HTTPS
- человек
- i
- идея
- if
- зажигает
- изображение
- изображений
- воображение
- императив
- Осуществляющий
- последствия
- Импортировать
- важную
- улучшать
- in
- включает в себя
- включительно
- Сопричастность
- включать
- расширились
- дополнительный
- возложенный
- повлиять
- влияние
- нарушение
- изобретательность
- обновлять
- Инновации
- вход
- затраты
- понимание
- рефлексологии
- Интегрируя
- целостность
- интеллектуальный
- интеллектуальная собственность
- интерес
- интерпретация
- в
- запутанный
- вводить
- интуиция
- вовлеченный
- вопросы
- IT
- итерация
- итерации
- ЕГО
- путешествие
- JPG
- судья
- Отсутствие
- пейзаж
- слой
- слоев
- узнали
- изучение
- Юр. Информация
- правовые рамки
- Законодательство
- объектив
- лежит
- ЖИЗНЬЮ
- легкий
- такое как
- погрузка
- ВЗГЛЯДЫ
- от
- потери
- машина
- обучение с помощью машины
- поддерживать
- чудо
- шедевр
- Совпадение
- материала
- Matplotlib
- значить
- механизм
- механизмы
- Медиа
- просто
- объединение
- метод
- методический
- метрический
- минимизировать
- минут
- зеркальное отображение
- ML
- Алгоритмы машинного обучения
- режим
- модель
- Модели
- Модерн
- модуль
- БОЛЕЕ
- двигаться
- много
- MUSE
- должен
- имена
- рождающийся
- природа
- Откройте
- необходимо
- потребности
- сеть
- сетей
- нервный
- Нейронная инженерия
- нейронной сети
- нейронные сети
- Новые
- Шум
- в своих размышлениях
- роман
- сейчас
- нюансы
- наблюдать
- наблюдается
- of
- от
- наступление
- предлагают
- предлагающий
- Предложения
- .
- on
- постоянный
- только
- Откроется
- Оптимизировать
- or
- оригинал
- оригинальность
- Оригиналы
- OS
- Другое
- наши
- внешний
- выходной
- выходы
- за
- принадлежащих
- Картина
- Картины
- параметр
- параметры
- часть
- Стороны
- pass
- мимо
- путь
- шаблон
- паттеранами
- восприятие
- совершенствование
- выполнять
- перспективы
- картина
- кусок
- штук
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- портреты
- потенциал
- практиками
- Точность
- предварительный
- представить
- разрабатывает
- консервирование
- предотвращать
- предупреждение
- Принципы
- печать
- приоритезация
- процесс
- обрабатываемых
- производства
- Продукт
- Профиль
- глубокий
- Прогресс
- прогрессия
- постепенно
- многообещающий
- Содействие
- наводящие
- распространение
- правильный
- собственность
- для защиты
- защищенный
- происхождение
- обеспечение
- опубликованный
- преследующий
- pytorch
- количественно
- случайный
- хаотичность
- ассортимент
- Обменный курс
- готовый
- область
- признавать
- переосмысление
- совершенствовать
- рафинированный
- отражающий
- отражает
- режим
- регулярный
- отношения
- удаление
- оказание
- копирование
- представление
- представляет
- воспроизводство
- требовать
- требуется
- похожий
- перекроить
- уважение
- относительно
- ответственный
- ответственно
- в результате
- возвращают
- откровение
- Возрождать
- революционизировать
- RGB
- Богатые
- правые
- Рост
- надежный
- Роли
- то же
- сохраняются
- экономия
- сцена
- Наука
- сфера
- скрипт
- посмотреть
- SELF
- чувствительный
- отдельный
- Последовательность
- служит
- набор
- установка
- установка
- несколько
- Shadow
- формирование
- сдвиг
- Смены
- должен
- демонстрации
- Showcasing
- показанный
- значительный
- с
- Медленно
- отрывок
- So
- сложный
- Soul
- Источник
- источников
- Space
- напряженность
- конкретно
- Спектр
- В квадрате
- стабильный
- Этап
- стоять
- Начало
- статистический
- устойчивый
- Шаг
- Стратегия
- устремление
- Структура
- Ошеломляющий
- стиль
- предмет
- последующее
- такие
- Symbiotic
- синергистический
- синтез
- синтетический
- с учетом
- принимает
- с
- цель
- Технический
- снижения вреда
- технологический
- технологии
- Технологии
- tensorflow
- воли
- который
- Ассоциация
- Будущее
- Источник
- их
- Их
- Там.
- Эти
- они
- этой
- процветает
- Через
- Таким образом
- в
- инструменты
- факел
- Торчвидение
- трогать
- к
- Отслеживание
- традиционный
- Train
- специалистов
- Обучение
- Transform
- трансформация
- преобразований
- преобразующей
- преобразован
- превращение
- прообразы
- Прозрачность
- правда
- стараться
- понимать
- понимание
- созданного
- до
- Представляет
- обновление
- на
- us
- использование
- используемый
- через
- утилита
- действительный
- проверка
- с помощью
- просмотр
- точки зрения
- видение
- визуальный
- визуальное искусство
- визуализация
- визуализации
- визуально
- жизненный
- законопроект
- we
- WebP
- Что
- Что такое
- , которые
- в то время как
- Whisper
- КТО
- широкий
- Широкий диапазон
- будете
- окно
- в
- без
- Работа
- работает
- Мир
- X
- Да
- еще
- являетесь
- зефирнет
- нуль