Введение
Трансформеры и модели большого языка покорили мир после того, как они были представлены в области Обработка естественного языка (НЛП). С момента своего создания эта область быстро развивалась благодаря инновациям и исследованиям, которые делают эти LLM более эффективными. К ним относятся LoRA (адаптация низкого ранга), Flash Attention, Quantization и недавний подход известных LLM к слиянию. В этом руководстве мы рассмотрим новый подход к слиянию LLM (Solar 10.7B), представленный ИИ Upstage.

Цели обучения
- Познакомьтесь с уникальной архитектурой Solar 10.7B и ее инновационным «глубинным масштабированием».
- Изучите процесс предварительного обучения модели и разнообразные данные, которые она потребляет.
- Проанализируйте впечатляющие показатели производительности Solar 10.7B при выполнении различных задач НЛП.
- Сравните Solar 10.7B с другими известными LLM, такими как Mixtral MoE.
- Узнайте, как получить доступ к Solar 10.7B и работать с ним в своих проектах.
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
Что такое СОЛНЕЧНАЯ 10.7B?
Upstange AI представила новую модель SOLAR 10.7B с 10.7 миллиардами параметров. Эта модель является результатом слияния двух моделей с 7 миллиардами параметров, в частности двух моделей Llama 2 7 Billion, которые были предварительно обучены для создания SOLAR 10.7B. Уникальным аспектом этого слияния является применение нового подхода под названием Depth Up-Scaling (DUS), в отличие от метода Mixtral, в котором задействовано несколько экспертов.
Новая модель 10.7B превзошла по характеристикам Mistral 7B, Qwen 14B. Была выпущена версия Instruct под названием SOLAR 10.7B Instruct, и после ее выпуска она возглавила таблицу лидеров, превзойдя как Qwen 72B, так и большую языковую модель Mixtral 8x7B. Несмотря на то, что модель SOLAR имеет 10.7 миллиардов параметров, она смогла превзойти LLM, которые в несколько раз больше ее размера.
Что такое масштабирование глубины?
Давайте разберемся, как все началось, и формирование SOLAR 10.7B. Все начинается с одной базовой модели. The Upstage выбрала Llama 2, содержащую 32 слоя трансформера, для своей базовой модели из-за более широкого круга участников с открытым исходным кодом. Затем была создана копия этой базовой модели.

Затем мы получаем две базовые модели. Что касается грузов, Upstage взял предварительно обученные веса от Mistral 7B, поскольку на тот момент он показал лучшие результаты. Теперь приступаем к масштабированию в глубину. Каждая из базовых моделей содержит 32 слоя. Из этих 32 слоев мы удаляем m слоев, то есть последние m слоев исходной модели и первые m слоев из ее копии. В результате в каждом из них получается до 24 слоев. Затем мы объединяем эти две модели:
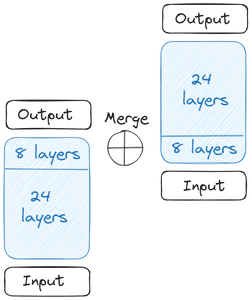
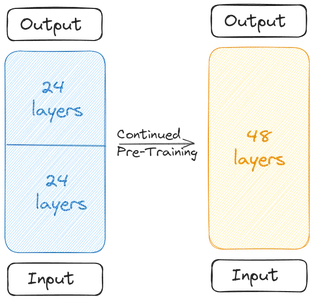
Две базовые модели объединяются для формирования масштабированной модели. Масштабированная модель теперь содержит 48 слоев. Масштабированная модель работает плохо из-за слияния. Следовательно, масштабированная модель проходит предварительное обучение. Это глубинное масштабирование, сопровождаемое продолжающейся предварительной тренировкой, вместе образует масштабирование глубины (DUS).
Обучение SOLAR 10.7B
Масштабированную модель необходимо предварительно обучить из-за снижения производительности из-за слияния. Создатели заявили, что производительность быстро повышается при предварительной тренировке. Предварительная подготовка/тонкая настройка включала два этапа.
Первым этапом была доработка инструкций. В этом типе точной настройки модель проходила обучение на наборах данных для соответствия инструкциям. Процесс тонкой настройки включал работу с популярными наборами данных с открытым исходным кодом, такими как Alpaca-GPT4 и OpenOrca. В документе отмечается, что для точной настройки объединенной модели использовалась только часть набора данных. Помимо данных из открытого исходного кода, Upstage даже обучил его некоторым математическим данным из закрытого источника.
На втором этапе выполняется настройка выравнивания. В ходе настройки выравнивания мы переходим к первой стадии точной настройки модели и далее дорабатываем ее, чтобы она была более согласована с людьми или мощными искусственными интеллектами, такими как GPT4. Это было сделано с помощью DPOTrainer (прямая оптимизация предпочтений), методики, подобной RLHF (обучение с подкреплением с обратной связью с человеком).
В прямой оптимизации предпочтений у нас есть набор данных, содержащий три столбца: подсказку, столбец предпочтительного ответа и столбец отклоненного ответа. Затем это используется для обучения масштабированной модели, чтобы она генерировала ответы, которые нам нужны. Здесь используются те же наборы данных, которые были обучены для точной настройки инструкций.
Результаты оценки и сравнительного анализа
Таблица лидеров Hugging Face OpenLLM использует несколько тестов для оценки возможностей моделей большого языка (LLM). Каждый тест оценивает различные аспекты эффективности LLM:
- ARC (Задание на рассуждение AI2): Этот тест проверяет способность магистратуры отвечать на научные вопросы элементарного уровня, обеспечивая понимание модели и обоснование научных концепций.
- MMLU (Массовое многозадачное понимание языка): MMLU — это разнообразный тест, охватывающий 57 различных задач, включая вопросы, связанные с базовой математикой, историей, правом, информатикой и другими. Он оценивает способность LLM обрабатывать и понимать информацию по нескольким дисциплинам.
- ХеллаСваг: Целью программы HellaSwag является проверка здравого смысла студентов-магистрантов, позволяющих им применять повседневную логику к различным сценариям, оценивая их способность выносить интуитивные суждения, аналогичные человеческим мыслительным процессам.
- Виногранде: Этот тест, аналогичный HellaSwag, фокусируется на здравом смысле, но имеет другие нюансы по сравнению с HellaSwag. Это требует от LLM продемонстрировать высокий уровень понимания и логического рассуждения.
- ПравдивыйQA: TruthfulQA оценивает точность и достоверность информации, предоставляемой LLM. Он включает в себя вопросы из разных областей, включая науку, право, политику и т. д., проверяя способность модели генерировать правдивые и основанные на фактах ответы.
- GSM8К: Программа GSM8K, специально разработанная для проверки математических способностей, включает в себя многоэтапные математические задачи, требующие логических рассуждений и вычислительного мышления, что дает возможность магистрантам оценить свои навыки решения математических задач.
Базовая модель SOLAR 10.7B превзошла по производительности такие модели, как модель Mistral 7B Instruct v0.2 и модель Qwen 14B. Версия SOLAR 10.7B для Instruct смогла превзойти даже очень большие языковые модели, такие как Mistral 8x7B, Qwen 72B, Falcon 180B и другие огромные модели большого языка. Он опередил все модели в бенчмарке ARC и TruthfulQA.
Начало работы с SOLAR 10.7B
Модель SOLAR 10.7B легко доступна в HuggingFace Hub для работы с библиотекой трансформаторов. Доступны для работы даже квантовые модели SOLAR 10.7B. В этом разделе мы загрузим квантованную версию, попробуем ввести модель с различными задачами и увидеть сгенерированный результат.
Для тестирования квантованной версии SOLAR 10.7B мы будем работать с библиотекой Python llama_cpp_python, которая позволяет нам запускать квантованные модели большого языка. В этой демонстрации мы будем работать с бесплатной версией Google Colab.
Скачать пакет
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python
!pip3 install huggingface-hub- Ассоциация CMAKE_ARGS="-DLLAMA_CUBLAS=вкл" и FORCE_CMAKE=1, позволит llama_cpp_python для работы с графическим процессором Nvidia, доступным в бесплатной версии Colab
- Затем мы устанавливаем llama_cpp_python пакет через pip3
- Мы даже скачиваем хаб для лица, с помощью которого мы будем загружать квантованную модель SOLAR 10.7B
Для работы с моделью SOLAR 10.7B нам необходимо сначала загрузить ее квантованную версию. Чтобы загрузить его, мы запустим следующий код:
from huggingface_hub import hf_hub_download
# specifying the model name
model_name = "TheBloke/SOLAR-10.7B-Instruct-v1.0-GGUF"
# specifying the type of quantization of the model
model_file = "solar-10.7b-instruct-v1.0.Q2_K.gguf"
# download the model by specifying the model name and quantized model name
model_path = hf_hub_download(model_name, filename=model_file)
Работа с Hugging Face Hub
Здесь мы работаем с Hugging_face_hub чтобы загрузить квантованную модель. Для этого мы импортируем hf_hub_download который принимает следующие параметры
- название модели: Это тип модели, которую мы хотим загрузить. Здесь мы хотим скачать модель SOLAR 10.7B Instruct GGUF.
- файл_модели: Здесь мы сообщаем, какую квантованную версию мы хотим скачать. Здесь мы загрузим 2-битную квантованную версию инструкции SOLAR 10.7B.
- Затем мы передаем эти параметры в hf_hub_download, который принимает эти параметры и загружает указанную модель. После загрузки возвращает путь, по которому загружается модель.
- Возвращенный путь сохраняется в папке модель_путь переменная
Теперь мы можем загрузить эту модель через ламу_cpp_python библиотека. Код для загрузки модели будет такой, как показано ниже.
from llama_cpp import Llama
llm = Llama(
model_path=model_path,
n_ctx=512, # the number of i/p tokens the model can take
n_threads=8, # the number of threads to use
n_gpu_layers=110 # how many layers of the model to offload to the GPU
)
Импортируйте класс ламы
Мы импортируем класс Llama из llama_cpp, который принимает следующие параметры
- путь_модели: Эта переменная принимает путь, по которому хранится наша модель. У нас есть путь из предыдущего шага, который мы предоставим здесь.
- n_ctx: Здесь мы указываем длину контекста для модели. На данный момент мы предоставляем 512 токенов для длины контекста.
- n_threads: Здесь мы упоминаем количество потоков, которые будет использовать класс Llama. На данный момент мы передаем 8, потому что у нас 4-ядерный процессор, где каждое ядро может выполнять 2 потока одновременно.
- n_gpu_layers: Мы даем это, если у нас есть работающий графический процессор, что мы и делаем, потому что работаем с бесплатным Colab. Для этого мы передаем 110, что говорит о том, что мы хотим выгрузить всю модель в графический процессор и не хотим, чтобы какая-то ее часть запускалась в системной оперативной памяти.
- Наконец, мы создаем объект из этого класса Llama и передаем его переменной llm.
Запуск этого кода загрузит квантованную модель SOLAR 10.7B в графический процессор и установит соответствующую длину контекста. Теперь пришло время сделать некоторые выводы по этой модели. Для этого мы работаем с приведенным ниже кодом
output = llm(
"### User:nWho are you?nn### Assistant:", # User Prompt
max_tokens=512, # the number of output tokens generated
stop=["</s>"], # the token which tells the LLM to stop
)
print(output['choices'][0]['text']) # llm generated text
Сделайте вывод о модели
Чтобы вывести модель, мы передаем в LLM следующие параметры:
- Шаблон подсказки/чата: Это шаблон, необходимый для общения с моделью. Вышеупомянутый шаблон (### User:n{user_prompt}?nn### Assistant:) подходит для модели SOLAR 10.7B. В шаблоне предложение после Информация о пользователе — это приглашение пользователя, и генерация будет сгенерирована после помощник
- макс_токены: Это максимальное количество токенов, которое может вывести модель большого языка при подсказке. На данный момент мы ограничиваем его 512 токенами.
- стоп: Это стоп-токен. Токен остановки сообщает модели большого языка, что ей необходимо прекратить генерацию дальнейших токенов. Для SOLAR 10.7B стоп-токен —
Запустив это, результаты будут сохранены в выходной переменная. Полученный результат аналогичен вызову API OpenAI. Следовательно, мы можем получить доступ к генерации через данный оператор печати, что аналогично тому, как мы получаем доступ к генерации из ответов OpenAI. Полученный результат можно увидеть ниже.

Сгенерированное предложение кажется достаточно хорошим, без появления крупных грамматических ошибок. Давайте попробуем часть модели, основанную на здравом смысле, предоставив следующие подсказки.
output = llm(
"### User:nHow many eggs can a monkey lay in its lifetime?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

output = llm(
"### User:nHow many smartphones can a human eat?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Здесь мы видим два примера, связанных со здравым смыслом, и, на удивление, SOLAR 10.7B справляется с ними очень хорошо. Модель большого языка смогла дать правильные ответы с полезным содержанием. Давайте попробуем проверить математические и рассуждения модели с помощью следующих подсказок.
output = llm(
"### User:nLook at this series: 80, 10, 70, 15, 60, ...
What number should come next?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])
output = llm(
"### User:nJohn runs faster than Ken. Magnus runs faster than John.
Does Ken run faster than Magnus?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

Судя по подсказкам данного примера, SOLAR 10.7B дал хороший ответ. Он умел правильно отвечать на заданные математические и логические рассуждения и даже на вопросы, связанные со здравым смыслом. В целом мы можем заключить, что большая языковая модель SOLAR 10.7B вызывает хорошие отзывы.
SOLAR 10.7B против Mixtral MoE
Mixtral 8x7B MoE создан Mistral AI с архитектурой Mixture of Experts. Короче говоря, эта смесь экспертов, Мистраль, использует 8 моделей по 7 миллиардов параметров. В каждой из этих моделей некоторые сети прямого распространения заменены другими слоями, называемыми экспертами. Следовательно, считается, что Mixtral 8x7B имеет 8 экспертов. И для каждого, кого модель принимает во входном приглашении, будет механизм пропуска, который выбирает только 2 из этих экспертов из 8. Затем эти 2 эксперта принимают это входное приглашение и генерируют окончательные выходные токены. Итак, мы видим, что в этом типе слияния есть некоторая сложность: нам приходится заменять слои прямой связи другими слоями и вводить механизм пропуска, который выбирает между этими экспертами.
В то время как модель SOLAR 10.7B от Upstage использует метод увеличения глубины. При увеличении глубины мы просто удаляем некоторое количество начальных слоев из базовой модели и такое же количество финальных слоев из ее копии. Затем мы просто объединяем модели, накладывая одну поверх другой. И всего за несколько эпох тонкой настройки объединенная модель может показать быстрый рост производительности. Здесь мы не заменяем существующие слои какими-то другими слоями. Также здесь у нас нет литникового механизма. В целом, увеличение глубины — это простой и эффективный способ объединения моделей, не требующий каких-либо сложностей.
Также сравнивая характеристики, масштабирование глубины, хотя, просто объединив две 7 миллиардов моделей, SOLAR 10.7B смог явно превзойти Mixtral 8x7B, который по сравнению с ним является гораздо более крупной моделью. Это доказывает эффективность простого метода слияния по сравнению со сложным, таким как Mixtral of Experts.
Ограничения и соображения
- Исследование гиперпараметров: Важнейшим ограничением является недостаточное исследование гиперпараметров в подходе DUS. Из-за аппаратных ограничений 8 слоев были удалены с обоих концов базовой модели без проверки, является ли это число оптимальным для достижения наилучшей производительности. Будущая работа направлена на проведение более строгих экспериментов и анализ для решения этой проблемы.
- Вычислительные требования: Модель требует огромного количества вычислительных ресурсов для обучения и вывода. Это может ограничить его использование, в основном для тех, у кого ограничены вычислительные возможности.
- Предвзятости в обучающих данных. Как и все модели машинного обучения, она подвержена предвзятости, присутствующей в обучающих данных, что потенциально может привести к искажению результатов в определенных сценариях.
- Воздействие на окружающую среду: Даже потребление энергии, необходимое для обучения и эксплуатации модели, вызывает экологические проблемы, подчеркивая важность устойчивого развития ИИ.
- Более широкие последствия модели: Несмотря на то, что модель демонстрирует улучшенную производительность при выполнении инструкций, она по-прежнему требует точной настройки для достижения оптимальной производительности в специализированных приложениях. Этот процесс тонкой настройки является ресурсоемким и не всегда может быть эффективным.
Заключение
В этом руководстве мы рассмотрели недавно выпущенную модель SOLAR с 10.7 миллиардами параметров, разработанную Upstage AI. Upstage AI применил новый подход к объединению и масштабированию моделей. В документе использовался новый подход под названием «Увеличение глубины» для объединения двух моделей Llama-2 с 7 миллиардами параметров путем удаления некоторых начальных и конечных слоев преобразователя. После этого компания доработала модель на наборах данных с открытым исходным кодом и протестировала ее в таблице лидеров OpenLLM, получив наивысший балл H6 и возглавив таблицу лидеров.
Основные выводы
- SOLAR 10.7B представляет масштабирование глубины, уникальный подход слияния, бросающий вызов традиционным методам и демонстрирующий достижения в архитектуре моделей.
- Несмотря на свои 10.7 миллиардов параметров, SOLAR 10.7B превосходит более крупные модели, превосходя Mistral 7B, Qwen 14B и даже возглавляя таблицы лидеров с такими версиями, как SOLAR 10.7B Instruct.
- Двухэтапный процесс тонкой настройки, включающий настройку инструкций и выравнивания, обеспечивает адаптируемость модели к различным задачам, что делает ее очень хорошей в следовании инструкциям и в соответствии с предпочтениями человека.
- SOLAR 10.7B превосходно справляется с различными тестами, тем самым демонстрируя свою компетентность в решении самых разных задач: от базовой математики и понимания языка до здравого смысла и оценки правдивости.
- SOLAR 10.7B, доступный на HuggingFace Hub, предоставляет разработчикам и исследователям эффективный и доступный инструмент для приложений языковой обработки.
- Вы можете точно настроить модель, используя обычные методы, используемые для точной настройки больших языковых моделей. Например, вы можете использовать контролируемый тренажер точной настройки (SFTrainer) от Hugging Face для точной настройки модели SOLAR 10.7B.
Часто задаваемые вопросы
A. SOLAR 10.7B — это модель с 10.7 миллиардами параметров, разработанная Upstage AI и использующая уникальную технику слияния под названием Depth Up-Scaling. Он отличается тем, что превосходит более крупные LLM и демонстрирует достижения в области слияния моделей.
A. Глубинное масштабирование включает две базовые модели. Этот процесс включает в себя непосредственное объединение этих двух базовых моделей путем наложения их друг на друга. Прежде чем произойдет объединение, удаляются начальные слои одной модели и конечные слои другой модели.
A. SOLAR 10.7B проходит двухэтапный процесс предварительной подготовки. Точная настройка инструкций включает в себя обучение модели на наборах данных с упором на следование инструкциям. Настройка выравнивания уточняет соответствие модели предпочтениям человека с помощью метода, называемого оптимизацией прямых предпочтений (DPO).
О. SOLAR 10.7B превосходит другие тесты, включая ARC (AI2 Reasoning Challenge), MMLU (Massive MultiTask Language понимания), HellaSwag, Winogrande, TruthfulQA и GSM8K. Он получает высокие баллы, демонстрируя свою универсальность в решении различных языковых задач.
О. SOLAR 10.7B превосходит такие модели, как Mistral 7B и Qwen 14B, демонстрируя превосходные характеристики, несмотря на меньшее количество параметров. Инструктированная версия даже конкурирует и превосходит очень большие модели, включая Mistral 8x7B и Qwen 72B, в различных тестах.
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2024/01/solar-10-7b-comparing-its-performance-to-other-notable-llms/
- :имеет
- :является
- :нет
- :куда
- $UP
- 10
- 110
- 12
- 15%
- 16
- 24
- 300
- 32
- 60
- 7
- 70
- 8
- 80
- 9
- a
- способности
- способность
- в состоянии
- доступ
- точность
- Достигает
- достижение
- через
- адрес
- Добавляет
- достижения
- После
- впереди
- AI
- AI2
- Нацеленный
- Цель
- выравнивать
- выровненный
- выравнивание
- выравнивание
- Все
- позволять
- вдоль
- причислены
- всегда
- количество
- an
- анализ
- аналитика
- Аналитика Видхья
- и
- Другой
- ответ
- ответы
- API
- Применение
- Приложения
- Применить
- подхода
- соответствующий
- Arc
- архитектура
- МЫ
- области
- гайд
- AS
- внешний вид
- аспекты
- оценивает
- Оценка
- помощник
- At
- внимание
- доступен
- Использование темпера с изогнутым основанием
- основной
- BE
- бить
- , так как:
- было
- до
- начал
- не являетесь
- ниже
- эталонный тест
- тесты
- ЛУЧШЕЕ
- между
- предубеждения
- миллиард
- Немного
- блогатон
- изоферменты печени
- шире
- но
- by
- призывают
- под названием
- CAN
- возможности
- определенный
- вызов
- проблемы
- сложные
- чат
- выбор
- выбранный
- класс
- явно
- закрыто
- код
- Column
- Колонки
- комбинируя
- как
- Общий
- Здравый смысл
- сравнить
- сравненный
- сравнив
- сравнение
- соревнуется
- комплекс
- сложности
- сложность
- вычислительный
- компьютер
- Информатика
- понятия
- Обеспокоенность
- вывод
- Проводить
- считается
- потребление
- содержит
- содержание
- контекст
- продолжающийся
- контраст
- вкладчики
- Основные
- правильно
- может
- чехлы
- ЦП
- Создайте
- создали
- решающее значение
- данным
- Наборы данных
- снижение
- доставить
- запросы
- Демо
- демонстрировать
- демонстрирующий
- глубина
- предназначенный
- Несмотря на
- застройщиков
- Развитие
- различный
- направлять
- непосредственно
- дисциплин
- усмотрение
- отличает
- Разное
- do
- приносит
- сделанный
- скачать
- загрузок
- два
- каждый
- есть
- Эффективный
- эффективность
- эффективный
- яйца
- подчеркивающий
- занятых
- работает
- окончания поездки
- энергетика
- Энергопотребление
- достаточно
- обеспечивает
- Весь
- окружающий
- охраны окружающей среды
- эпохи
- Эфир (ETH)
- оценивать
- оценки
- Даже
- повседневный
- все члены
- развивается
- пример
- Примеры
- существующий
- Эксперименты
- эксперты
- исследование
- Face
- Фактический
- сокол
- далеко
- быстрее
- Обратная связь
- несколько
- меньше
- поле
- окончательный
- Во-первых,
- Flash
- фокусируется
- следует
- после
- Что касается
- форма
- образование
- Бесплатно
- от
- далее
- будущее
- порождать
- генерируется
- порождающий
- поколение
- получить
- получающий
- Дайте
- данный
- Отдаете
- хорошо
- есть
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- Рост
- инструкция
- Ручки
- Управляемость
- Аппаратные средства
- Есть
- имеющий
- следовательно
- здесь
- High
- наивысший
- выделив
- история
- Как
- How To
- HTTPS
- хаб
- огромный
- ОбниматьЛицо
- человек
- Людей
- if
- Влияние
- последствия
- Импортировать
- значение
- впечатляющий
- улучшенный
- in
- начало
- включают
- включает в себя
- В том числе
- информация
- начальный
- инновации
- инновационный
- вход
- размышления
- устанавливать
- пример
- инструкции
- в
- вводить
- выпустили
- Представляет
- интуитивный
- включать в себя
- вовлеченный
- включает в себя
- с участием
- IT
- ЕГО
- саму трезвость
- John
- суждения
- всего
- Кумар
- язык
- большой
- больше
- закон
- лежать
- слоев
- лидеров
- ведущий
- изучение
- Длина
- Lets
- уровень
- рычаги
- Библиотека
- продолжительность жизни
- такое как
- ОГРАНИЧЕНИЯ
- ограничение
- недостатки
- Ограниченный
- Лама
- загрузка
- погрузка
- логика
- логический
- посмотреть
- машина
- обучение с помощью машины
- в основном
- основной
- сделать
- Makers
- ДЕЛАЕТ
- Создание
- многих
- массивный
- математике
- математический
- математика
- макс-ширина
- максимальный
- максимальная сумма
- Май..
- механизм
- Медиа
- упомянуть
- идти
- объединение
- метод
- методы
- ошибки
- смесь
- модель
- Модели
- БОЛЕЕ
- более эффективным
- с разными
- имя
- необходимо
- Необходимость
- необходимый
- потребности
- сетей
- Новые
- следующий
- НЛП
- примечательный
- отметил,
- сейчас
- нюансы
- номер
- Nvidia
- объект
- of
- on
- ONE
- только
- открытый
- с открытым исходным кодом
- OpenAI
- операционный
- оптимальный
- оптимизация
- or
- оригинал
- Другое
- Другое
- наши
- внешний
- Результаты
- опережать
- превзошел
- превосходя
- Превосходит
- выходной
- за
- общий
- принадлежащих
- бумага & картон
- параметр
- параметры
- часть
- pass
- путь
- выполнять
- производительность
- выступления
- выполнены
- выполнения
- выполняет
- Часть
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- политика
- Популярное
- представляет
- потенциально
- мощный
- предпочтения
- привилегированный
- представить
- предыдущий
- Печать / PDF
- решение проблем
- проблемам
- процесс
- Процессы
- наводящие
- доказывает
- при условии
- приводит
- обеспечение
- опубликованный
- Питон
- Вопросы
- быстро
- ранжирование
- быстро
- легко
- последний
- недавно
- регулярный
- усиление обучения
- Отклоненный..
- Связанный
- освободить
- выпустил
- надежность
- удаление
- удален
- удаление
- замещать
- заменить
- требуется
- исследованиям
- исследователи
- ресурсоемкий
- Полезные ресурсы
- ответ
- ответы
- результат
- Итоги
- Возвращает
- правую
- тщательный
- Risen
- Run
- Бег
- работает
- Сказал
- то же
- сохраняются
- Шкала
- масштабирование
- Сценарии
- Наука
- научный
- Гол
- множество
- Во-вторых
- Раздел
- посмотреть
- видя
- кажется
- видел
- смысл
- предложение
- Серии
- набор
- несколько
- должен
- показывать
- Showcasing
- показ
- показанный
- Шоу
- аналогичный
- просто
- с
- одинарной
- навыки
- смартфоны
- So
- солнечный
- некоторые
- сложный
- Источник
- специализированный
- конкретно
- указанный
- штабелирования
- Этап
- стоять
- Начало
- и политические лидеры
- Начало
- начинается
- заявление
- Шаг
- По-прежнему
- Stop
- магазин
- хранить
- буря
- такие
- топ
- превосходит
- превосходящие
- восприимчивый
- комфортного
- SVG
- система
- взять
- приняты
- принимает
- задачи
- техника
- сказать
- говорит
- шаблон
- тестXNUMX
- проверенный
- Тестирование
- тестов
- текст
- чем
- который
- Ассоциация
- мир
- их
- Их
- тогда
- Там.
- Эти
- они
- мышление
- этой
- те
- хоть?
- мысль
- три
- Через
- Таким образом
- время
- раз
- в
- вместе
- знак
- Лексемы
- инструментом
- топ
- увенчанный
- традиционный
- Train
- специалистов
- Обучение
- трансформатор
- трансформеры
- стараться
- два
- напишите
- подвергается
- понимать
- понимание
- Прошел
- созданного
- на
- us
- Применение
- использование
- используемый
- полезный
- Информация о пользователе
- использования
- через
- использовать
- использовать
- Использующий
- переменная
- разнообразие
- различный
- проверка
- многосторонность
- версия
- очень
- vs
- хотеть
- законопроект
- Путь..
- we
- WebP
- ЧТО Ж
- были
- Что
- Что такое
- когда
- , которые
- в то время как
- Шире
- будете
- без
- Работа
- работает
- работает
- Мир
- являетесь
- ВАШЕ
- зефирнет