Агенты суммирования, созданные с помощью инструмента генерации изображений AI Dall-E.
Вы относитесь к числу людей, которые оставляют отзывы на картах Google каждый раз, когда посещаете новый ресторан?
Или, может быть, вы из тех, кто делится своим мнением о покупках на Amazon, особенно когда вас провоцирует некачественный продукт?
Не волнуйся, я не буду тебя винить — у всех бывают моменты!
В современном мире данных мы все по-разному вносим свой вклад в поток данных. Одним из типов данных, который я нахожу особенно интересным из-за его разнообразия и сложности интерпретации, являются текстовые данные, такие как бесчисленные обзоры, которые публикуются в Интернете каждый день. Вы когда-нибудь задумывались о важности стандартизации и сжатия текстовых данных? Добро пожаловать в мир агентов суммирования!
Агенты суммирования легко интегрировались в нашу повседневную жизнь, собирая информацию и обеспечивая быстрый доступ к соответствующему контенту во множестве приложений и платформ.
В этой статье мы рассмотрим использование ChatGPT в качестве мощного агента суммирования для наших пользовательских приложений. Благодаря способности моделей больших языков (LLM) обрабатывать и понимать тексты, они могут помочь в чтении текстов и создании точных резюме или стандартизации информации. Однако важно знать, как раскрыть их потенциал при выполнении такой задачи, а также признать их ограничения.
Самое большое ограничение для обобщения? LLM часто терпят неудачу, когда дело доходит до соблюдения ограничений на конкретные символы или слова. в их резюме.
Давайте рассмотрим лучшие практики создания сводок с помощью ChatGPT. для нашего пользовательского приложения, а также причины его ограничений и способы их преодоления!
Агенты суммирования используются во всем Интернете. Например, веб-сайты используют агенты обобщения, чтобы предложить краткие сводки статей, что позволяет пользователям получить быстрый обзор новостей, не погружаясь во все содержимое. Платформы социальных сетей и поисковые системы также делают это.
От агрегаторов новостей и платформ социальных сетей до веб-сайтов электронной коммерции агенты обобщения стали неотъемлемой частью нашего цифрового ландшафта.. А с появлением LLM некоторые из этих агентов теперь используют ИИ для более эффективного суммирования результатов.
ChatGPT может быть хорошим союзником при создании приложения с использованием агентов суммирования для ускорения чтения и классификации текстов. Например, представьте, что у нас есть бизнес электронной коммерции, и мы заинтересованы в обработке всех отзывов наших клиентов. ChatGPT может помочь нам резюмировать любой отзыв в нескольких предложениях, привести его к общему формату, определить настроение обзора и классификация это соответственно.
Хотя это правда, что мы могли бы просто отправить обзор в ChatGPT, есть список лучших практик. — и чего следует избегать — чтобы использовать возможности ChatGPT в этой конкретной задаче.
Давайте рассмотрим варианты, воплотив этот пример в жизнь!
Пример: обзоры электронной торговли
Гифка самодельная.
Рассмотрим приведенный выше пример, в котором мы заинтересованы в обработке всех обзоров для данного продукта на нашем веб-сайте электронной коммерции. Мы были бы заинтересованы в обработке таких отзывов о нашем звездном продукте, как следующий: первый компьютер для детей!
prod_review = """
I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlier
than expected, so I got to play with it myself before I gave it to him. """
В этом случае мы хотели бы, чтобы ChatGPT:
Классифицировать отзыв на положительный или отрицательный.
Сделайте краткое изложение обзора в 20 слов.
Выведите ответ с конкретной структурой, чтобы стандартизировать все отзывы в одном формате.
Замечания по реализации
Вот базовая структура кода, которую мы могли бы использовать для запроса ChatGPT из нашего пользовательского приложения. Также даю ссылку на Jupyter Notebook со всеми примерами, использованными в этой статье.
import openai
import os openai.api_key_path = "/path/to/key" def get_completion(prompt, model="gpt-3.5-turbo"): """
This function calls ChatGPT API with a given prompt
and returns the response back. """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0 ) return response.choices[0].message["content"] user_text = f"""
<Any given text> """ prompt = f"""
<Any prompt with additional text> """{user_text}""" """ # A simple call to ChatGPT
response = get_completion(prompt)
Функция get_completion() вызывает API ChatGPT с заданным подсказка. Если приглашение содержит дополнительные пользовательский текст, например сам обзор в нашем случае, отделяется от остального кода тройными кавычками.
Давайте использовать get_completion() функция запроса ChatGPT!
Вот подсказка, отвечающая требованиям, описанным выше:
prompt = f"""
Your task is to generate a short summary of a product review from an e-commerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """
response = get_completion(prompt)
print(response)
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Как видно из результатов, обзор точен и хорошо структурирован, хотя в нем отсутствует некоторая информация, которая могла бы заинтересовать нас как владельцев электронной коммерции., такие как информация о доставке продукта.
Подведите итоги с акцентом на
Мы можем многократно улучшать нашу подсказку, прося ChatGPT сосредоточиться на определенных вещах в сводке.. В этом случае нас интересуют любые данные об отгрузке и доставке:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words and focusing on any aspects that mention shipping and delivery of the product. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
На этот раз ответ ChatGPT следующий:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Теперь обзор намного полнее. Предоставление подробной информации о важной направленности исходного обзора имеет решающее значение, чтобы ChatGPT не пропускал некоторую информацию, которая может быть полезна для нашего варианта использования..
Вы заметили, что, хотя во втором испытании содержится информация о доставке, в нем пропущен единственный негативный аспект первоначального обзора?
Давайте исправим это!
«Извлечь» вместо «Обобщить»
Исследуя задачи на обобщение, я выяснил, что суммирование может быть сложной задачей для LLM, если подсказка пользователя недостаточно точна..
При запросе ChatGPT предоставить краткое изложение данного текста, он может пропустить информацию, которая может быть важна для нас. — как мы недавно испытали — или он будет придавать одинаковое значение всем темам в тексте, предоставляя только обзор основных моментов.
Эксперты в LLM используют термин извлечение и дополнительную информацию об их фокусах вместо суммировать при выполнении таких задач помогают эти типы моделей.
В то время как обобщение направлено на предоставление краткого обзора основных моментов текста, включая темы, не связанные с рассматриваемой темой, извлечение информации направлено на получение конкретных деталей. и может дать нам то, что мы именно ищем. Давайте попробуем тогда с извлечением!
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. From the review below, delimited by triple quotes extract the information relevant to shipping and delivery. Use 100 characters. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
В этом случае, используя извлечение, мы получаем информацию только по интересующей нас теме: Shipping: Arrived a day earlier than expected.
Автоматизация
Эта система работает для одного обзора. Тем не менее, при разработке подсказки для конкретного приложения, важно протестировать его на нескольких примерах, чтобы мы могли обнаружить любые выбросы или неправильное поведение в модели..
В случае обработки нескольких обзоров, вот пример структуры кода Python, который может помочь.
reviews = [ "The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!", "I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.", "The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.", "I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.", "The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
] prompt = f""" Your task is to generate a short summary of each product review from an e-commerce site. Extract positive and negative information from each of the given reviews below, delimited by triple backticks in at most 20 words each. Extract information about the delivery, if included. Review: ```{reviews}``` """
Вот резюме нашей серии обзоров:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
⚠️ Обратите внимание, что, хотя ограничение слов в наших резюме было достаточно четким в наших подсказках, мы легко можем видеть, что это ограничение слов не выполняется ни в одной из итераций.
Это несоответствие в подсчете слов происходит потому, что LLM не имеют точного представления о подсчете слов или символов. Причина этого зависит от одного из основных важных компонентов их архитектуры: токенизатор.
Токенизатор
LLM, такие как ChatGPT, предназначены для генерации текста на основе статистических шаблонов, извлеченных из огромного количества языковых данных. Хотя они очень эффективны для создания плавного и связного текста, им не хватает точного контроля над количеством слов..
В приведенных выше примерах, когда мы давали инструкции по очень точному подсчету слов, ChatGPT изо всех сил пытался удовлетворить эти требования. Вместо этого он сгенерировал текст, который на самом деле короче указанного количества слов.
В других случаях он может генерировать более длинные тексты или просто слишком многословный или недостаточно подробный текст. Кроме того, ChatGPT может отдавать приоритет другим факторам, таким как согласованность и релевантность, а не строгому соблюдению количества слов.. Это может привести к тому, что текст будет высокого качества с точки зрения содержания и согласованности, но не будет точно соответствовать требованиям по количеству слов.
Токенизатор — это ключевой элемент архитектуры ChatGPT, который явно влияет на количество слов в генерируемом выводе..
Гифка самодельная.
Архитектура токенизатора
Токенизатор — это первый шаг в процессе генерации текста. Он отвечает за разбиение фрагмента текста, который мы вводим в ChatGPT, на отдельные элементы. — жетоны —, которые затем обрабатываются языковой моделью для создания нового текста.
Когда токенизатор разбивает фрагмент текста на токены, он делает это на основе набора правил, предназначенных для идентификации значимых единиц целевого языка. Однако эти правила не всегда безупречны, и могут быть случаи, когда токенизатор разделяет или объединяет токены таким образом, что это влияет на общее количество слов в тексте..
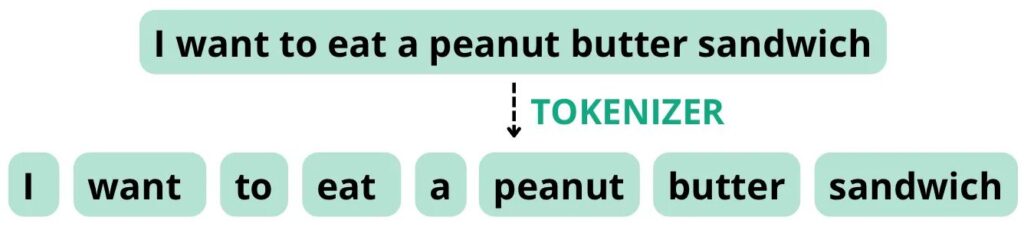
Например, рассмотрим следующее предложение: «Я хочу съесть бутерброд с арахисовым маслом». Если токенизатор настроен на разделение токенов на основе пробелов и знаков препинания, он может разбить это предложение на следующие токены с общим количеством слов 8, равным количеству токенов.
Самодельный образ.
Однако, если токенизатор настроен на обработку "арахисовое масло" как сложное слово, оно может разбить предложение на следующие токены: с общим количеством слов 8, но количеством токенов 7.
Таким образом, способ настройки токенизатора может повлиять на общее количество слов в тексте., и это может повлиять на способность LLM следовать инструкциям по точному подсчету слов. Хотя некоторые токенизаторы предлагают варианты настройки токенизации текста, этого не всегда достаточно для обеспечения точного соблюдения требований к количеству слов. Для ChatGPT в данном случае мы не можем контролировать эту часть его архитектуры..
Из-за этого ChatGPT не так хорошо справляется с ограничением символов или слов, но вместо этого можно попробовать использовать предложения, поскольку токенизатор не влияет на количество предложений, но их длина.
Знание этого ограничения может помочь вам создать подсказку, наиболее подходящую для вашего приложения. Имея эти знания о том, как работает подсчет слов в ChatGPT, давайте сделаем последнюю итерацию с нашей подсказкой для приложения электронной коммерции!
Подведение итогов: обзоры электронной коммерции
Давайте объединим наши выводы из этой статьи в финальную подсказку! В этом случае мы будем запрашивать результаты в HTML формат для более приятного вывода:
from IPython.display import display, HTML prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department and generic feedback from the product. From the review below, delimited by triple quotes construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and delivery. Review: ```{prod_review}``` """ response = get_completion(prompt)
display(HTML(response))
И вот окончательный вывод из ChatGPT:
Скриншот, сделанный своими руками Jupyter Notebook с примерами, использованными в этой статье.
Обзор
В этой статье, мы обсудили лучшие практики использования ChatGPT в качестве агента суммирования для нашего пользовательского приложения..
Мы видели, что при создании приложения чрезвычайно сложно придумать идеальную подсказку, которая соответствует требованиям вашего приложения в первой пробной версии. Я думаю, что хорошее сообщение на вынос состоит в том, чтобы думать о подсказке как об итеративном процессе где вы уточняете и моделируете свое приглашение, пока не получите точно желаемый результат.
Повторно улучшая приглашение и применяя его к пакету примеров перед развертыванием в рабочей среде, вы можете убедиться, выходные данные согласуются между несколькими примерами и охватывают выпадающие ответы. В нашем примере могло случиться так, что кто-то предоставил случайный текст вместо отзыва. Мы можем указать ChatGPT также иметь стандартизированный вывод, чтобы исключить эти выпадающие ответы..
Кроме того, при использовании ChatGPT для конкретной задачи также рекомендуется узнать о плюсах и минусах использования LLM для нашей целевой задачи. Так мы пришли к выводу, что задачи извлечения более эффективны, чем суммирование, когда нам нужна общая, человеческая сводка вводимого текста. Мы также узнали, что фокусирование резюме может быть игра-чейнджер относительно созданного контента.
Наконец, хотя LLM могут быть очень эффективными при генерации текста, они не идеальны для следования точным инструкциям по количеству слов или другим конкретным требованиям к форматированию.. Для достижения этих целей может потребоваться придерживаться подсчета предложений или использовать другие инструменты или методы, такие как ручное редактирование или более специализированное программное обеспечение.
Эта статья изначально была опубликована в На пути к науке о данных и повторно опубликовано в TOPBOTS с разрешения автора.
Наслаждайтесь этой статьей? Подпишитесь на дополнительные исследования ИИ исследований.
Мы сообщим вам, когда мы выпустим больше кратких статей, подобных этой.