Сгенерировано с помощью Midjourney
На конференции NeurIPS 2023, проходившей в оживленном городе Новый Орлеан с 10 по 16 декабря, особое внимание уделялось генеративному искусственному интеллекту и моделям большого языка (LLM). Учитывая недавние новаторские достижения в этой области, неудивительно, что эти темы доминировали в дискуссиях.
Одной из основных тем конференции этого года был поиск более эффективных систем искусственного интеллекта. Исследователи и разработчики активно ищут способы создания ИИ, который не только обучается быстрее, чем нынешние LLM, но и обладает расширенными способностями к рассуждению, потребляя при этом меньше вычислительных ресурсов. Это стремление имеет решающее значение в гонке за созданием искусственного общего интеллекта (AGI), цели, которая кажется все более достижимой в обозримом будущем.
Приглашенные доклады на NeurIPS 2023 стали отражением этих динамичных и быстро развивающихся интересов. Докладчики из различных областей исследований в области искусственного интеллекта поделились своими последними достижениями, открыв окно в передовые разработки в области искусственного интеллекта. В этой статье мы углубляемся в эти переговоры, извлекая и обсуждая ключевые выводы и выводы, которые необходимы для понимания текущих и будущих ландшафтов инноваций в области искусственного интеллекта.
NextGenAI: Иллюзия масштабирования и будущее генеративного ИИ
In его речьБьорн Оммер, руководитель группы компьютерного зрения и обучения в Мюнхенском университете Людвига-Максимилиана, рассказал, как его лаборатория пришла к разработке стабильной диффузии, несколько уроков, которые они извлекли из этого процесса, и недавние разработки, в том числе то, как мы можем объединить модели диффузии с сопоставление потоков, увеличение извлечения и аппроксимации LoRA, среди прочего.
Программа вебинара:
- В эпоху генеративного искусственного интеллекта мы перешли от акцента на восприятии в моделях зрения (т. е. распознавании объектов) к прогнозированию недостающих частей (например, генерации изображений и видео с помощью диффузионных моделей).
- В течение 20 лет компьютерное зрение было сосредоточено на эталонных исследованиях, которые помогли сосредоточиться на наиболее важных проблемах. В генеративном искусственном интеллекте у нас нет никаких критериев для оптимизации, что открыло поле для того, чтобы каждый мог идти в своем направлении.
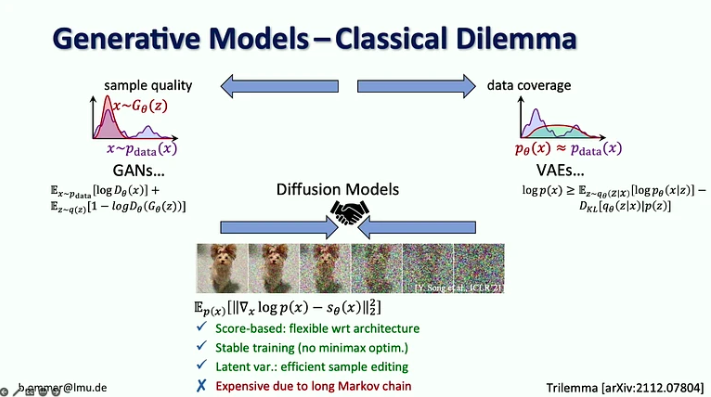
- Диффузионные модели сочетают в себе преимущества предыдущих генеративных моделей, основанных на оценке, стабильной процедуре обучения и эффективном редактировании выборки, но они дороги из-за своей длинной цепи Маркова.
- Проблема с моделями сильного правдоподобия заключается в том, что большая часть битов уходит на детали, которые едва заметны человеческому глазу, в то время как кодирование семантики, которая имеет наибольшее значение, занимает всего несколько битов. Масштабирование само по себе не решит эту проблему, поскольку спрос на вычислительные ресурсы растет в 9 раз быстрее, чем предложение графических процессоров.
- Предлагаемое решение состоит в том, чтобы объединить сильные стороны моделей диффузии и свёрточных сетей, в частности эффективность свёрток для представления локальных деталей и выразительность моделей диффузии для контекста на больших расстояниях.
- Бьорн Оммер также предлагает использовать подход согласования потоков, чтобы обеспечить синтез изображений с высоким разрешением на основе небольших моделей скрытой диффузии.
- Другой подход к повышению эффективности синтеза изображений — сосредоточиться на композиции сцены, используя при этом дополнительные возможности поиска для заполнения деталей.
- Наконец, он представил подход iPoke для управляемого стохастического синтеза видео.
Если этот подробный контент полезен для вас, подпишитесь на нашу рассылку AI быть предупрежденным, когда мы выпустим новый материал.
Многоликий ответственный ИИ
In ее презентацияЛора Аройо, научный сотрудник Google Research, выделила ключевое ограничение традиционных подходов машинного обучения: их зависимость от двоичной категоризации данных в качестве положительных или отрицательных примеров. По ее мнению, такое чрезмерное упрощение упускает из виду сложную субъективность, присущую реальным сценариям и контенту. На примере различных вариантов использования Аройо продемонстрировал, как двусмысленность контента и естественное расхождение во взглядах людей часто приводят к неизбежным разногласиям. Она подчеркнула важность рассмотрения этих разногласий как значимых сигналов, а не просто шума.

Вот ключевые выводы из разговора:
- Разногласия между людьми могут быть продуктивными. Вместо того, чтобы рассматривать все ответы как правильные или неправильные, Лора Аройо ввела «истину через несогласие» — подход распределительной истины для оценки надежности данных путем использования разногласий оценщиков.
- Качество данных затруднено даже у экспертов, потому что эксперты расходятся во мнениях так же, как и эксперты. Эти разногласия могут быть гораздо более информативными, чем ответы одного эксперта.
- В задачах по оценке безопасности эксперты расходятся во мнениях по 40% примеров. Вместо того, чтобы пытаться разрешить эти разногласия, нам нужно собрать больше таких примеров и использовать их для улучшения моделей и показателей оценки.
- Лора Аройо также представила свои Безопасность с разнообразием метод тщательного изучения данных с точки зрения того, что в них содержится и кто их аннотировал.
- Этот метод позволил получить базовый набор данных с различиями в суждениях о безопасности LLM среди различных демографических групп оценщиков (всего 2.5 миллиона оценок).
- В 20% разговоров было трудно решить, был ли ответ чат-бота безопасным или небезопасным, поскольку примерно равное количество респондентов назвало их безопасными или небезопасными.
- Разнообразие оценщиков и данных играет решающую роль в оценке моделей. Неспособность признать широкий спектр человеческих точек зрения и двусмысленность, присутствующую в содержании, может помешать привести эффективность машинного обучения в соответствие с реальными ожиданиями.
- 80% усилий по обеспечению безопасности ИИ уже достаточно хороши, но оставшиеся 20% требуют удвоения усилий для решения пограничных случаев и всех вариантов в бесконечном пространстве разнообразия.
Статистика согласованности, собственный опыт и почему молодые люди намного умнее современного ИИ
In ее разговорЛинда Смит, заслуженный профессор Университета Индианы в Блумингтоне, исследовала тему нехватки данных в процессах обучения младенцев и детей раннего возраста. Она специально сосредоточилась на распознавании объектов и изучении имен, углубившись в то, как статистика самостоятельного опыта младенцев предлагает потенциальные решения проблемы разреженности данных.
Программа вебинара:
- К трем годам у детей развивается способность самостоятельно обучаться в различных областях. Менее чем за 16,000 1,000 часов бодрствования до своего четвертого дня рождения им удается выучить более XNUMX категорий объектов, освоить синтаксис родного языка и усвоить культурные и социальные нюансы окружающей среды.
- Доктор Линда Смит и ее команда обнаружили три принципа человеческого обучения, которые позволяют детям извлечь так много из таких скудных данных:
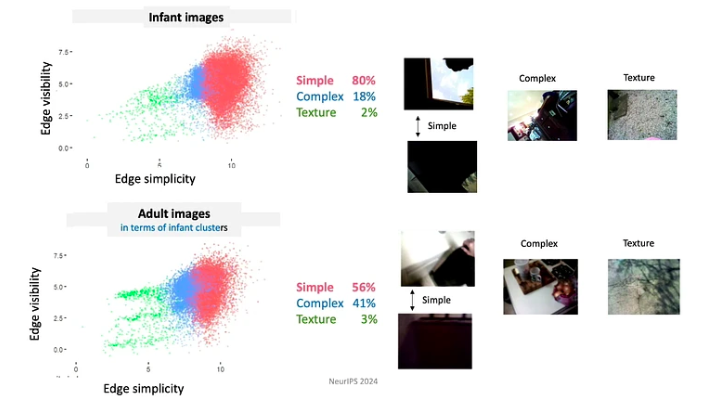
- Обучающиеся контролируют вводимые данные, каждый момент они формируют и структурируют вводимые данные. Например, в течение первых нескольких месяцев жизни младенцы склонны больше смотреть на предметы с простыми краями.
- Поскольку дети постоянно развивают свои знания и способности, они следуют строго ограниченной учебной программе. Данные, с которыми они сталкиваются, организованы очень важным образом. Например, дети до 4 месяцев проводят большую часть времени, глядя на лица, примерно 15 минут в час, тогда как дети старше 12 месяцев сосредотачиваются в основном на руках, наблюдая за ними около 20 минут в час.
- Эпизоды обучения состоят из серии взаимосвязанных событий. Пространственные и временные корреляции создают связность, что, в свою очередь, способствует формированию устойчивых воспоминаний об одноразовых событиях. Например, когда детям предлагают случайный набор игрушек, они часто сосредотачиваются на нескольких «любимых» игрушках. Они взаимодействуют с этими игрушками, используя повторяющиеся шаблоны, что помогает быстрее изучить объекты.
- Преходящие (рабочие) воспоминания сохраняются дольше, чем сенсорная информация. Свойства, улучшающие процесс обучения, включают мультимодальность, ассоциации, прогностические отношения и активацию прошлых воспоминаний.
- Для быстрого обучения вам необходим союз между механизмами, генерирующими данные, и механизмами, которые обучаются.
Создание эскизов: основные инструменты, расширение возможностей обучения и адаптивная надежность.
Джелани Нельсон, профессор электротехники и компьютерных наук Калифорнийского университета в Беркли, представил концепцию «эскизов» данных – сжатое в памяти представление набора данных, которое по-прежнему позволяет отвечать на полезные запросы. Хотя доклад был довольно техническим, в нем был представлен отличный обзор некоторых фундаментальных инструментов создания эскизов, включая последние достижения.
Ключевые выводы:
- CountSketch, основной инструмент для создания эскизов, был впервые представлен в 2002 году для решения проблемы «сильных нападающих», предоставляя небольшой список наиболее частых элементов из данного потока элементов. CountSketch был первым известным сублинейным алгоритмом, использованным для этой цели.
- Два непотоковых приложения тяжелых нападающих включают в себя:
- Метод внутренних точек (IPM), который дает асимптотически самый быстрый из известных алгоритмов линейного программирования.
- Метод HyperAttention, который решает вычислительную проблему, возникающую из-за растущей сложности длинных контекстов, используемых в LLM.
- Большая часть недавних работ была сосредоточена на разработке эскизов, устойчивых к адаптивному взаимодействию. Основная идея — использовать идеи адаптивного анализа данных.
За пределами панели масштабирования
Эта отличная панель по большим языковым моделям Модератором выступил Александр Раш, доцент Корнеллского технологического института и исследователь Hugging Face. Среди других участников были:
- Ааканкша Чоудхери — научный сотрудник Google DeepMind с исследовательскими интересами в области систем, предварительной подготовки к магистратуре и мультимодальности. Она была частью команды, разрабатывающей PaLM, Gemini и Pathways.
- Анджела Фан — научный сотрудник Meta Generative AI, занимающийся исследовательскими интересами в области согласования, центров обработки данных и многоязычия. Она участвовала в разработке Llama-2 и Meta AI Assistant.
- Перси Лян – профессор Стэнфордского университета, исследующий создателей, открытый исходный код и генеративные агенты. Он является директором Центра исследований моделей фундамента (CRFM) в Стэнфорде и основателем Together AI.
Обсуждение сосредоточилось на четырех ключевых темах: (1) архитектура и проектирование, (2) данные и согласование, (3) оценка и прозрачность и (4) создатели и участники.
Вот некоторые выводы из этой панели:
- Обучение современным языковым моделям по своей сути не представляет сложности. Основная проблема при обучении такой модели, как Llama-2-7b, заключается в требованиях к инфраструктуре и необходимости координации между несколькими графическими процессорами, центрами обработки данных и т. д. Однако, если количество параметров достаточно мало, чтобы позволить обучение на одном графическом процессоре, даже студент может справиться с этим.
- Хотя модели авторегрессии обычно используются для генерации текста, а модели диффузии — для создания изображений и видео, были эксперименты по изменению этих подходов. В частности, в проекте Gemini для генерации изображений используется авторегрессионная модель. Также проводились исследования по использованию моделей диффузии для генерации текста, но они еще не оказались достаточно эффективными.
- Учитывая ограниченную доступность англоязычных данных для моделей обучения, исследователи изучают альтернативные подходы. Одной из возможностей является обучение мультимодальных моделей на сочетании текста, видео, изображений и аудио с ожиданием, что навыки, полученные с помощью этих альтернативных модальностей, могут быть перенесены в текст. Другой вариант – использование синтетических данных. Важно отметить, что синтетические данные часто смешиваются с реальными данными, но эта интеграция не является случайной. Текст, публикуемый в Интернете, обычно подвергается проверке и редактированию человеком, что может повысить ценность обучения моделей.
- Модели открытого фундамента часто рассматриваются как полезные для инноваций, но потенциально вредные для безопасности ИИ, поскольку они могут быть использованы злоумышленниками. Однако доктор Перси Лян утверждает, что открытые модели также положительно влияют на безопасность. Он утверждает, что, будучи доступными, они предоставляют большему количеству исследователей возможности проводить исследования безопасности ИИ и проверять модели на предмет потенциальных уязвимостей.
- Сегодня аннотирование данных требует значительно большего опыта в области аннотирования по сравнению с пятью годами ранее. Однако, если ИИ-помощники в будущем будут работать так, как ожидается, мы будем получать более ценные данные обратной связи от пользователей, что уменьшит зависимость от обширных данных от аннотаторов.
Системы для фундаментальных моделей и фундаментальные модели для систем
In этот разговорКристофер Ре, доцент кафедры компьютерных наук Стэнфордского университета, показывает, как фундаментальные модели изменили системы, которые мы создаем. Он также исследует, как эффективно создавать базовые модели, заимствуя идеи из исследований систем баз данных, и обсуждает потенциально более эффективные архитектуры для базовых моделей, чем Transformer.
Вот основные выводы из этого выступления:
- Модели фундамента эффективны в решении проблемы «смерти от 1000 сокращений», когда каждая отдельная задача может быть относительно простой, но сама широта и разнообразие задач представляют собой серьезную проблему. Хорошим примером этого является проблема очистки данных, которую теперь LLM могут помочь решить гораздо эффективнее.
- Поскольку ускорители становятся быстрее, память часто становится узким местом. Это проблема, которую исследователи баз данных решают уже несколько десятилетий, и мы можем перенять некоторые из их стратегий. Например, подход Flash Attention сводит к минимуму потоки ввода-вывода за счет блокировки и агрессивного слияния: всякий раз, когда мы получаем доступ к фрагменту информации, мы выполняем с ним как можно больше операций.
- Существует новый класс архитектур, основанный на обработке сигналов, который может быть более эффективным, чем модель Transformer, особенно при обработке длинных последовательностей. Обработка сигналов обеспечивает стабильность и эффективность, закладывая основу для таких инновационных моделей, как S4.
Онлайн-обучение с подкреплением в сфере цифрового здравоохранения
In ее разговорСьюзен Мерфи, профессор статистики и информатики Гарвардского университета, поделилась первыми решениями некоторых проблем, с которыми они сталкиваются при разработке онлайн-алгоритмов RL для использования в цифровых вмешательствах в здравоохранении.
Вот несколько выводов из презентации:
- Доктор Сьюзан Мерфи рассказала о двух проектах, над которыми она работает:
- HeartStep, где действия были предложены на основе данных со смартфонов и носимых трекеров, и
- Оралитика для коучинга по вопросам здоровья полости рта, где вмешательства основывались на данных взаимодействия, полученных с помощью электронной зубной щетки.
- Разрабатывая политику поведения для агента ИИ, исследователи должны убедиться, что она автономна и может быть реально реализована в более широкой системе здравоохранения. Это предполагает обеспечение того, чтобы время, необходимое для участия человека, было разумным, а рекомендуемые действия были этически обоснованными и научно обоснованными.
- Основные проблемы при разработке агента RL для вмешательства в цифровое здравоохранение включают борьбу с высокими уровнями шума, поскольку люди ведут свою жизнь и не всегда могут реагировать на сообщения, даже если они этого хотят, а также управление сильными, отсроченными негативными последствиями. .
Как видите, NeurIPS 2023 предоставил проясняющий взгляд на будущее искусственного интеллекта. Приглашенные доклады подчеркнули тенденцию к более эффективным, ресурсосберегающим моделям и исследованию новых архитектур за пределами традиционных парадигм.
Наслаждайтесь этой статьей? Подпишитесь на дополнительные исследования ИИ исследований.
Мы сообщим вам, когда мы выпустим больше кратких статей, подобных этой.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.topbots.com/neurips-2023-invited-talks/
- :имеет
- :является
- :нет
- :куда
- $UP
- 000
- 1
- 10
- 10
- 11
- 110
- 12
- 12 месяцев
- 125
- 13
- 14
- 15%
- 154
- 16
- 16
- 17
- 20
- 20 лет
- 2023
- 32
- 35%
- 41
- 58
- 65
- 7
- 70
- 710
- 8
- 9
- a
- способность
- в состоянии
- О нас
- ускорители
- доступ
- доступной
- достижения
- достижение
- признавать
- через
- действия
- Активация
- активно
- активно
- актеры
- адаптивный
- Добавить
- дополнительный
- адрес
- адреса
- адресация
- принять
- достижения
- Преимущества
- возраст
- Агент
- агенты
- агрессивный
- AGI
- тому назад
- AI
- Помощник АИ
- ай исследование
- Системы искусственного интеллекта
- пособие
- Alexander
- алгоритм
- алгоритмы
- выравнивание
- Все
- Альянс
- позволять
- в одиночестве
- уже
- причислены
- альтернатива
- Несмотря на то, что
- всегда
- Двусмысленность
- среди
- an
- анализ
- и
- Другой
- любой
- Приложения
- подхода
- подходы
- примерно
- МЫ
- продемонстрировав тем самым
- Утверждает
- гайд
- статьи
- искусственный
- искусственный общий интеллект
- AS
- Оценка
- помощник
- помощники
- Юрист
- ассоциации
- ассортимент
- At
- Достижимый
- внимание
- аудио
- автономный
- свободных мест
- основанный
- BE
- , так как:
- становиться
- было
- поведение
- не являетесь
- эталонный тест
- тесты
- полезный
- Беркли
- между
- Beyond
- Бленд
- смеси
- блокирование
- Заимствование
- изоферменты печени
- ширина
- шире
- строить
- но
- by
- пришел
- CAN
- возможности
- захватить
- случаев
- категории
- Центр
- Центры
- цепь
- вызов
- проблемы
- менялась
- Chatbot
- Дети
- Кристофер
- Город
- класс
- Уборка
- тренировка
- собирать
- сочетание
- объединять
- сравненный
- комплекс
- сложность
- композиция
- вычислительный
- компьютер
- Информатика
- Компьютерное зрение
- вычисление
- сама концепция
- Проводить
- Конференция
- строить
- содержание
- контекст
- контексты
- беспрестанно
- способствовать
- вкладчики
- контроль
- контроль
- Беседы
- координировать
- Основные
- Cornell
- исправить
- корреляции
- может
- Создайте
- Создатели
- толпа
- решающее значение
- культурный
- курирование
- Текущий
- Учебный план
- передовой
- данным
- анализ данных
- центров обработки данных
- База данных
- занимавшийся
- десятилетия
- Декабрь
- решать
- DeepMind
- Задерживается
- копаться
- Спрос
- запросы
- демографический
- убивают
- Кафедра
- проектирование
- подробность
- подробнее
- развивать
- развитый
- застройщиков
- развивающийся
- Развитие
- события
- трудный
- Вещание
- Интернет
- Цифровое здоровье
- направление
- директор
- открытый
- обсуждается
- обсуждающий
- обсуждение
- обсуждение
- Выдающийся
- Разнообразие
- домен
- доменов
- доминируют
- Dont
- удвоившись
- dr
- два
- в течение
- динамический
- e
- каждый
- Edge
- редактирование
- Эффективный
- эффекты
- затрат
- эффективный
- эффективно
- усилие
- усилия
- или
- электротехника
- Электронный
- возникает
- акцент
- подчеркнул
- включить
- позволяет
- кодирование
- заниматься
- обязательство
- Проект и
- повышать
- расширение
- достаточно
- обеспечивать
- обеспечение
- Окружающая среда
- Эпизоды
- равный
- особенно
- существенный
- и т.д
- Эфир (ETH)
- оценки
- оценка
- Даже
- События
- все члены
- развивается
- развивается
- пример
- Примеры
- отлично
- ожидание
- ожидания
- ожидаемый
- дорогим
- опыт
- Впечатления
- Эксперименты
- эксперту
- опыта
- эксперты
- Эксплуатируемый
- исследование
- Разведанный
- исследует
- Исследование
- подвергаться
- обширный
- Глаза
- Face
- лица
- облегчает
- отсутствии
- вентилятор
- быстрее
- быстрый
- Обратная связь
- несколько
- меньше
- поле
- заполнять
- First
- 5
- Flash
- поток
- Потоки
- Фокус
- внимание
- следовать
- Что касается
- предвидимый
- образование
- Год основания
- основатель
- 4
- Четвертый
- частое
- часто
- от
- фундаментальный
- слияние
- будущее
- Будущее ИИ
- Gemini
- Общие
- общий интеллект
- порождать
- порождающий
- поколение
- генеративный
- Генеративный ИИ
- данный
- дает
- проблеск
- Go
- цель
- хорошо
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- Графические процессоры
- новаторским
- группы
- Группы
- Рост
- было
- Управляемость
- Руки
- вредный
- Освоение
- Гарвардский
- Гарвардский университет
- Есть
- he
- Медицина
- здравоохранение
- тяжелый
- Герой
- помощь
- помог
- ее
- High
- высокое разрешение
- Выделенные
- очень
- препятствовать
- его
- час
- ЧАСЫ
- Как
- How To
- Однако
- HTTP
- HTTPS
- человек
- Людей
- i
- идея
- if
- осветительный
- изображение
- генерация изображения
- изображений
- в XNUMX году
- значение
- важную
- улучшать
- in
- углубленный
- включают
- включены
- В том числе
- повышение
- все больше и больше
- Индиана
- individual
- неизбежный
- информация
- информативный
- Инфраструктура
- свойственный
- по существу
- Инновации
- инновационный
- вход
- размышления
- пример
- вместо
- интеграции.
- Интеллекта
- взаимодействие
- взаимосвязано
- интересы
- вмешательства
- в
- выпустили
- приглашенный
- IT
- пункты
- JPG
- суждения
- Основные
- Знать
- знания
- известный
- лаборатория
- маркировка
- язык
- большой
- прочный
- последний
- укладка
- вести
- ведущий
- УЧИТЬСЯ
- узнали
- учащихся
- изучение
- Наследие
- Меньше
- Уроки
- позволять
- уровни
- лежит
- легкий
- такое как
- вероятность
- ограничение
- Ограниченный
- Линда
- Список
- Живет
- локальным
- Длинное
- дольше
- посмотреть
- искать
- машина
- обучение с помощью машины
- рассылки
- Главная
- управлять
- управления
- многих
- мастер
- согласование
- материала
- Вопросы
- макс-ширина
- Май..
- значимым
- механизмы
- памяти
- Память
- меров
- Сообщения
- Мета
- метод
- Метрика
- может быть
- миллиона
- сводит к минимуму
- минут
- отсутствующий
- модальности
- модель
- Модели
- момент
- месяцев
- БОЛЕЕ
- более эффективным
- самых
- переехал
- много
- с разными
- Мюнхен
- должен
- имя
- родной
- натуральный
- Необходимость
- отрицательный
- НейриПС
- Новые
- Жители Нового Орлеана
- нет
- Шум
- Ничто
- в своих размышлениях
- роман
- сейчас
- нюансы
- номер
- объект
- объекты
- of
- предлагают
- предлагающий
- Предложения
- .
- старший
- on
- ONE
- онлайн
- только
- открытый
- с открытым исходным кодом
- открытый
- Операционный отдел
- Возможности
- Оптимизировать
- Опция
- or
- оральный
- Здоровье полости рта
- Организованный
- орлеан
- Другое
- Другие участники
- Другое
- наши
- за
- обзор
- собственный
- ладонь
- панель
- парадигмы
- параметры
- часть
- новыми участниками
- участие
- особый
- особенно
- части
- мимо
- пути
- паттеранами
- Люди
- для
- восприятие
- выполнять
- производительность
- перспективы
- кусок
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- правдоподобный
- играет
- политика
- поставленный
- положительный
- положительно
- обладает
- возможность
- возможное
- потенциал
- потенциально
- прогнозирования
- интеллектуального
- представить
- presentation
- представлены
- предыдущий
- в первую очередь
- первичный
- Принципы
- Проблема
- проблемам
- процедуры
- процесс
- Процессы
- обработка
- Произведенный
- производительный
- Профессор
- глубоко
- Программирование
- Проект
- проектов
- видный
- свойства
- доказанный
- обеспечивать
- при условии
- опубликованный
- цель
- преследование
- Запросы
- поиск
- вполне
- Гонки
- случайный
- ассортимент
- быстро
- быстро
- скорее
- рейтинги
- реальные
- реальный мир
- разумный
- Получать
- получила
- последний
- признание
- Управление по борьбе с наркотиками (DEA)
- снижение
- отражение
- усиление обучения
- отношения
- относительно
- освободить
- надежность
- опора
- осталось
- повторяющийся
- Reporting
- представление
- представляющий
- требовать
- обязательный
- Требования
- исследованиям
- исследователь
- исследователи
- решение
- Полезные ресурсы
- Реагируйте
- респондентов
- ответ
- ответы
- ответственный
- обзоре
- надежный
- Роли
- укоренившийся
- грубо
- торопить
- безопасный
- Сохранность
- масштабирование
- Сценарии
- сцена
- Наука
- НАУКА
- Ученый
- посмотреть
- поиск
- кажется
- видел
- семантика
- Серии
- формирование
- общие
- она
- Шоу
- подпись
- сигнал
- сигналы
- значительный
- существенно
- просто
- одинарной
- навыки
- небольшой
- умнее
- смартфоны
- кузнец
- So
- Соцсети
- Решение
- Решения
- РЕШАТЬ
- некоторые
- Звук
- Источник
- Space
- пространственный
- конкретно
- тратить
- Стабильность
- стабильный
- Стэнфорд
- Стэнфордский университет
- статистика
- По-прежнему
- стратегий
- поток
- сильные
- сильный
- структурирующий
- такие
- Предлагает
- РЕЗЮМЕ
- поставка
- сюрприз
- Сьюзен
- синтаксис
- синтез
- синтетический
- синтетические данные
- система
- системы
- Takeaways
- принимает
- Говорить
- переговоры
- Сложность задачи
- задачи
- команда
- технологии
- Технический
- Тенденцию
- terms
- текст
- генерация текста
- чем
- который
- Ассоциация
- Будущее
- их
- Их
- темы
- Там.
- Эти
- они
- этой
- те
- три
- Через
- время
- в
- вместе
- инструментом
- инструменты
- ТОП-БОТЫ
- тема
- Темы
- Всего
- к
- трекеры
- традиционный
- Обучение
- перевод
- трансформатор
- Прозрачность
- лечения
- тенденция
- Правда
- пытается
- ОЧЕРЕДЬ
- два
- типично
- под
- подвергается
- понимание
- Университет
- Updates
- использование
- используемый
- пользователей
- через
- обычно
- использовать
- ценный
- ценностное
- разнообразие
- различный
- яркие
- Видео
- Видео
- точки зрения
- видение
- Уязвимости
- W3
- законопроект
- способы
- we
- пригодный для носки
- ЧТО Ж
- были
- Что
- когда
- когда бы ни
- в то время как
- будь то
- который
- в то время как
- КТО
- зачем
- широкий
- Широкий диапазон
- будете
- окно
- Работа
- работает
- Неправильно
- лет
- еще
- являетесь
- молодой
- зефирнет