С запуском функции нейронного поиска для Сервис Amazon OpenSearch в OpenSearch 2.9 теперь легко интегрироваться с моделями AI/ML для обеспечения семантического поиска и других вариантов использования. Служба OpenSearch поддерживает как лексический, так и векторный поиск с момента появления функции k-ближайшего соседа (k-NN) в 2020 году; однако для настройки семантического поиска потребовалось создание инфраструктуры для интеграции моделей машинного обучения (ML) для приема и поиска. Функция нейронного поиска облегчает преобразование текста в вектор во время приема и поиска. Когда вы используете нейронный запрос во время поиска, запрос преобразуется в векторное вложение, и k-NN используется для возврата ближайших векторных вложений из корпуса.
Чтобы использовать нейронный поиск, необходимо настроить модель машинного обучения. Мы рекомендуем настроить коннекторы AI/ML для сервисов AWS AI и ML (например, Создатель мудреца Амазонки or Коренная порода Амазонки) или сторонние альтернативы. Начиная с версии 2.9 в OpenSearch Service, коннекторы AI/ML интегрируются с нейронным поиском, чтобы упростить и реализовать перевод вашего массива данных и запросов в векторные внедрения, тем самым устраняя большую часть сложности векторной гидратации и поиска.
В этом посте мы покажем, как настроить соединители AI/ML для внешних моделей через консоль OpenSearch Service.
Обзор решения
В частности, в этом посте вы узнаете, как подключиться к модели в SageMaker. Затем мы покажем вам, как использовать соединитель для настройки семантического поиска в службе OpenSearch в качестве примера варианта использования, который поддерживается через подключение к модели машинного обучения. Интеграции Amazon Bedrock и SageMaker в настоящее время поддерживаются в пользовательском интерфейсе консоли OpenSearch Service, и список собственных и сторонних интеграций, поддерживаемых пользовательским интерфейсом, будет продолжать расти.
Любые модели, не поддерживаемые через пользовательский интерфейс, можно настроить с помощью доступных API и Проекты машинного обучения. Для получения дополнительной информации см. Введение в модели OpenSearch. Схемы каждого разъема можно найти в Репозиторий ML Commons на GitHub.
Предпосылки
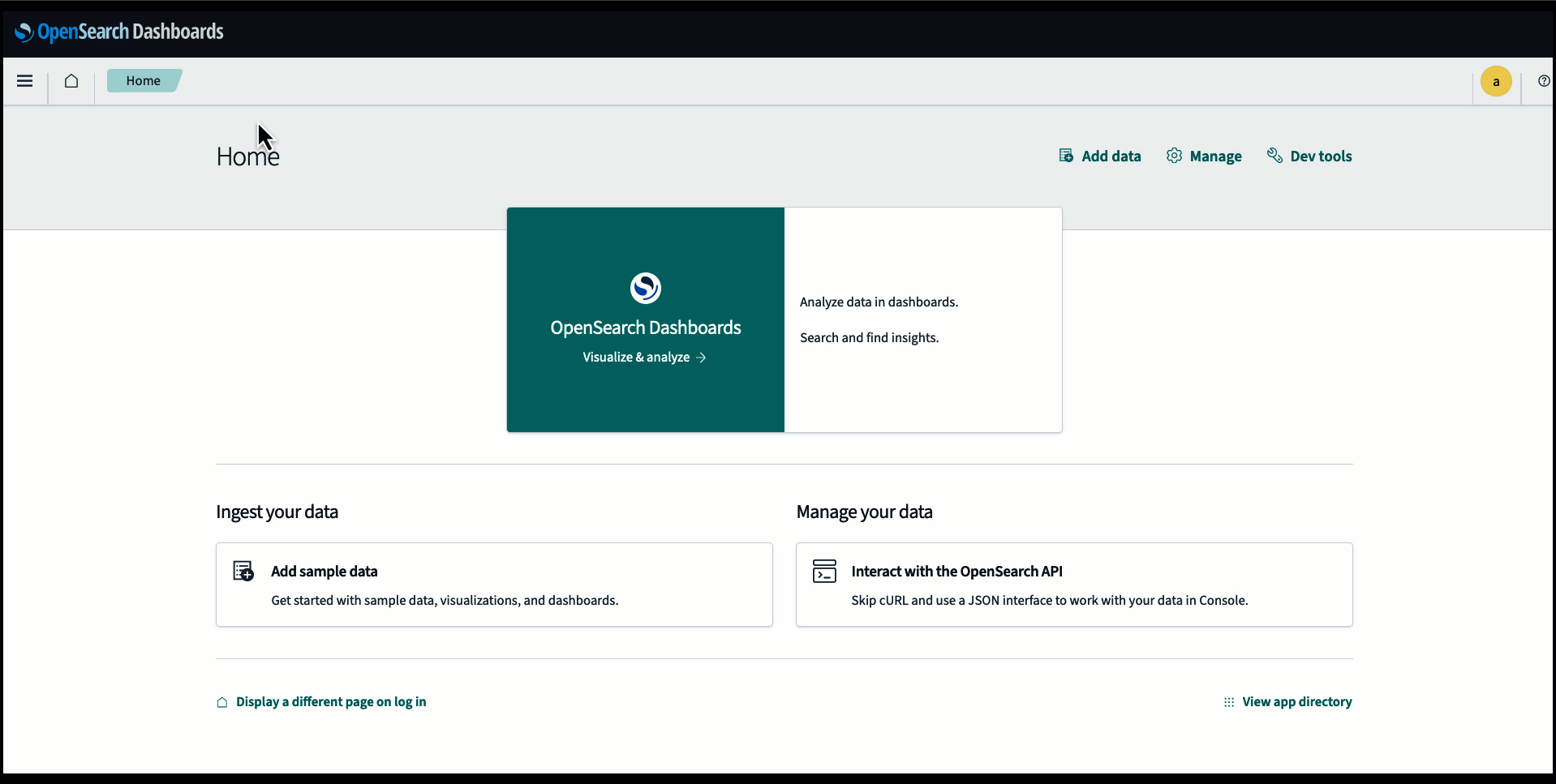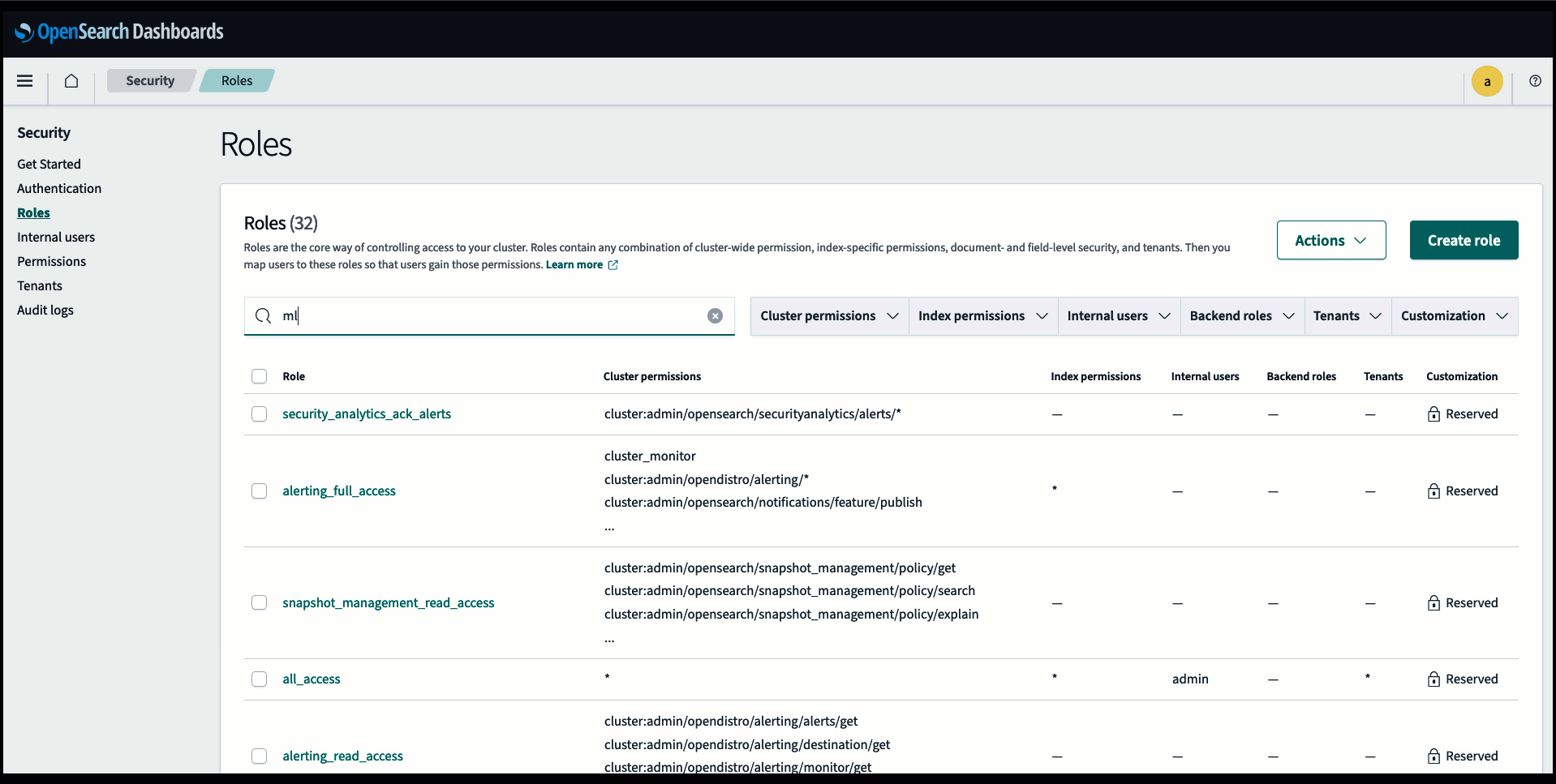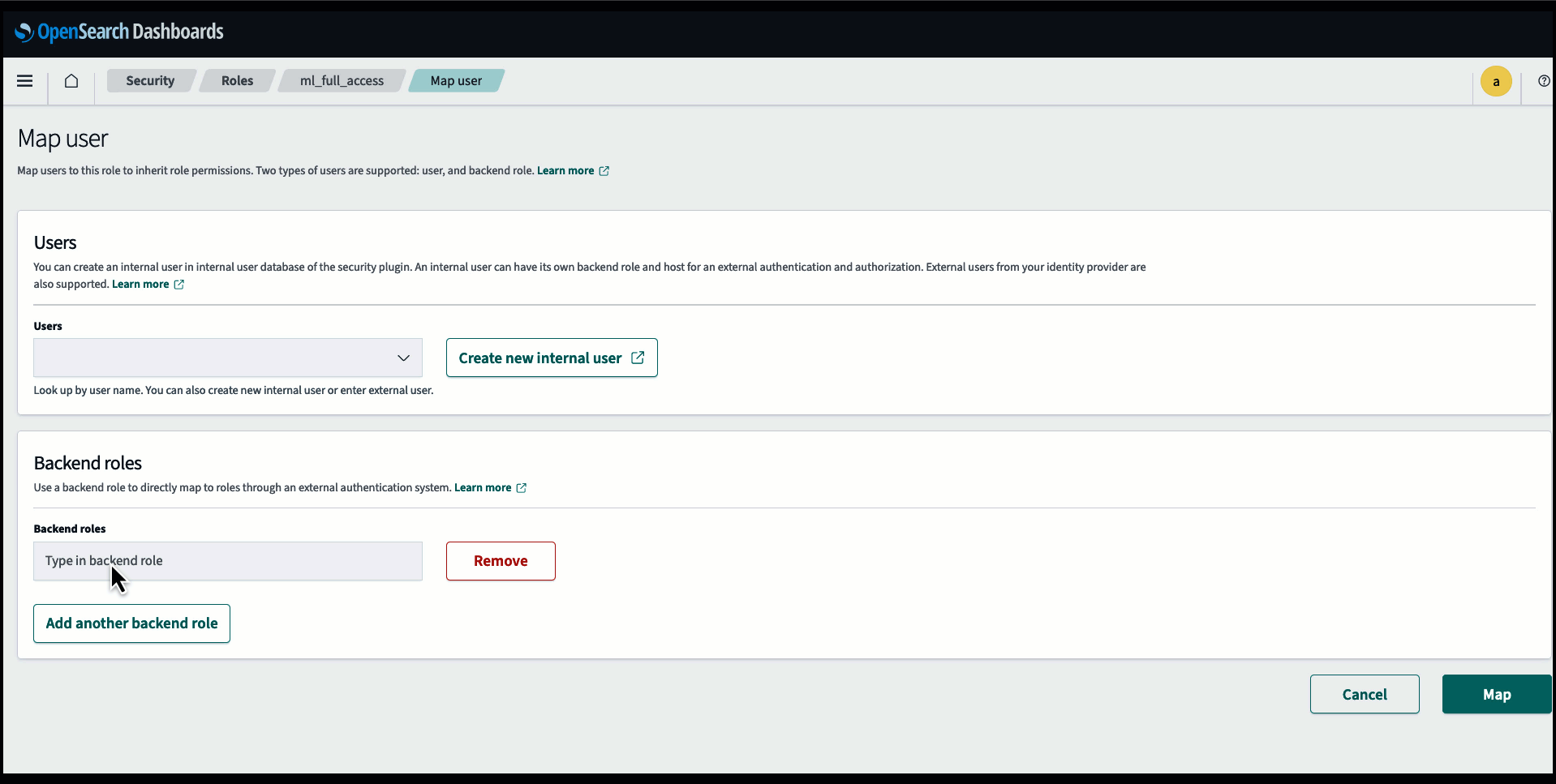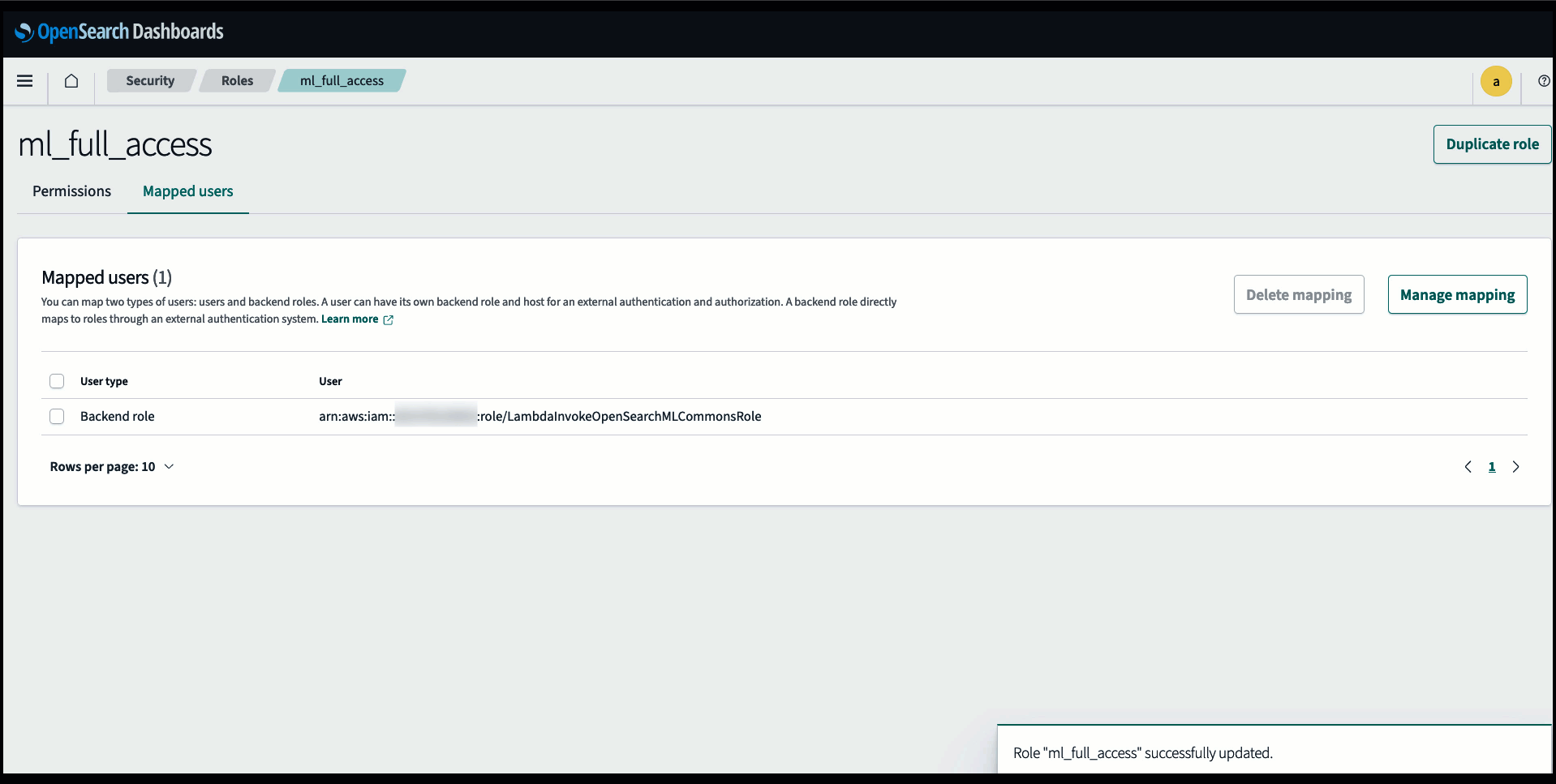
Прежде чем подключать модель через консоль OpenSearch Service, создайте домен OpenSearch Service. Составьте карту Управление идентификацией и доступом AWS (IAM) роль по имени LambdaInvokeOpenSearchMLCommonsRole в качестве серверной роли на ml_full_access роль с помощью плагина безопасности на панелях мониторинга OpenSearch, как показано в следующем видео. Рабочий процесс интеграции OpenSearch Service предварительно заполнен для использования LambdaInvokeOpenSearchMLCommonsRole Роль IAM по умолчанию для создания соединителя между доменом службы OpenSearch и моделью, развернутой в SageMaker. Если вы используете настраиваемую роль IAM при интеграции с консолью OpenSearch Service, убедитесь, что настраиваемая роль сопоставлена как серверная роль с помощью ml_full_access разрешения перед развертыванием шаблона.
Разверните модель с помощью AWS CloudFormation.
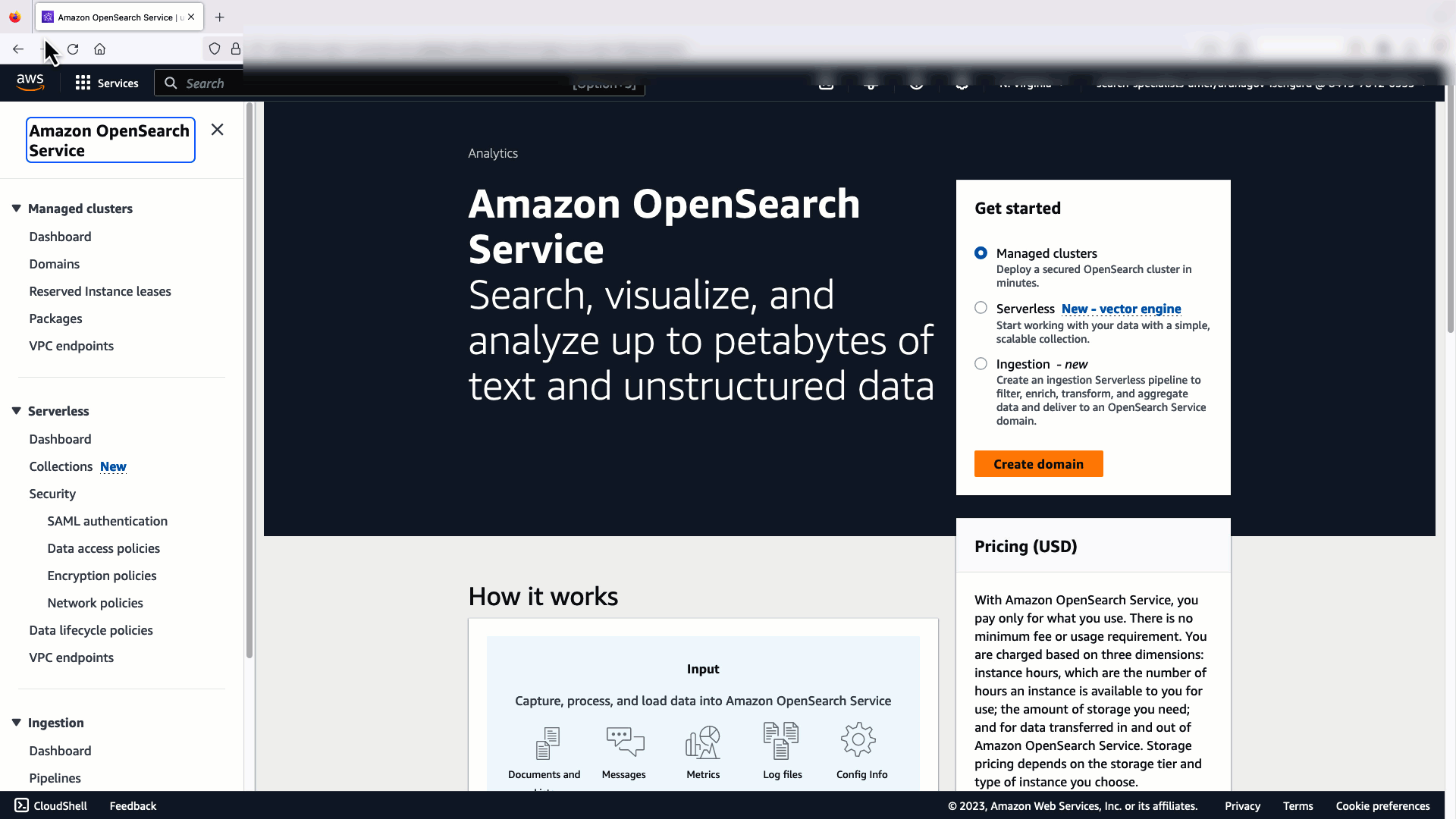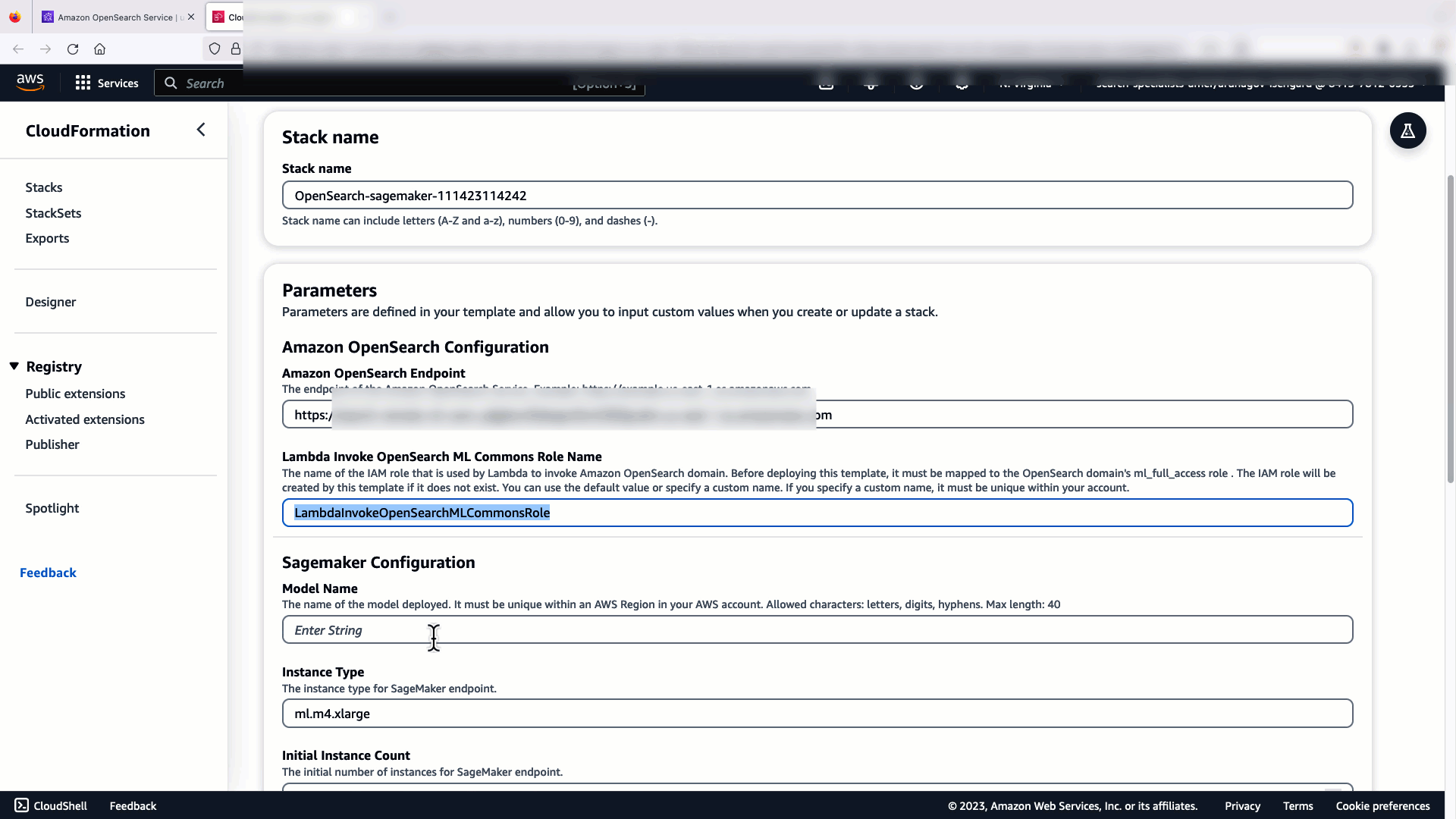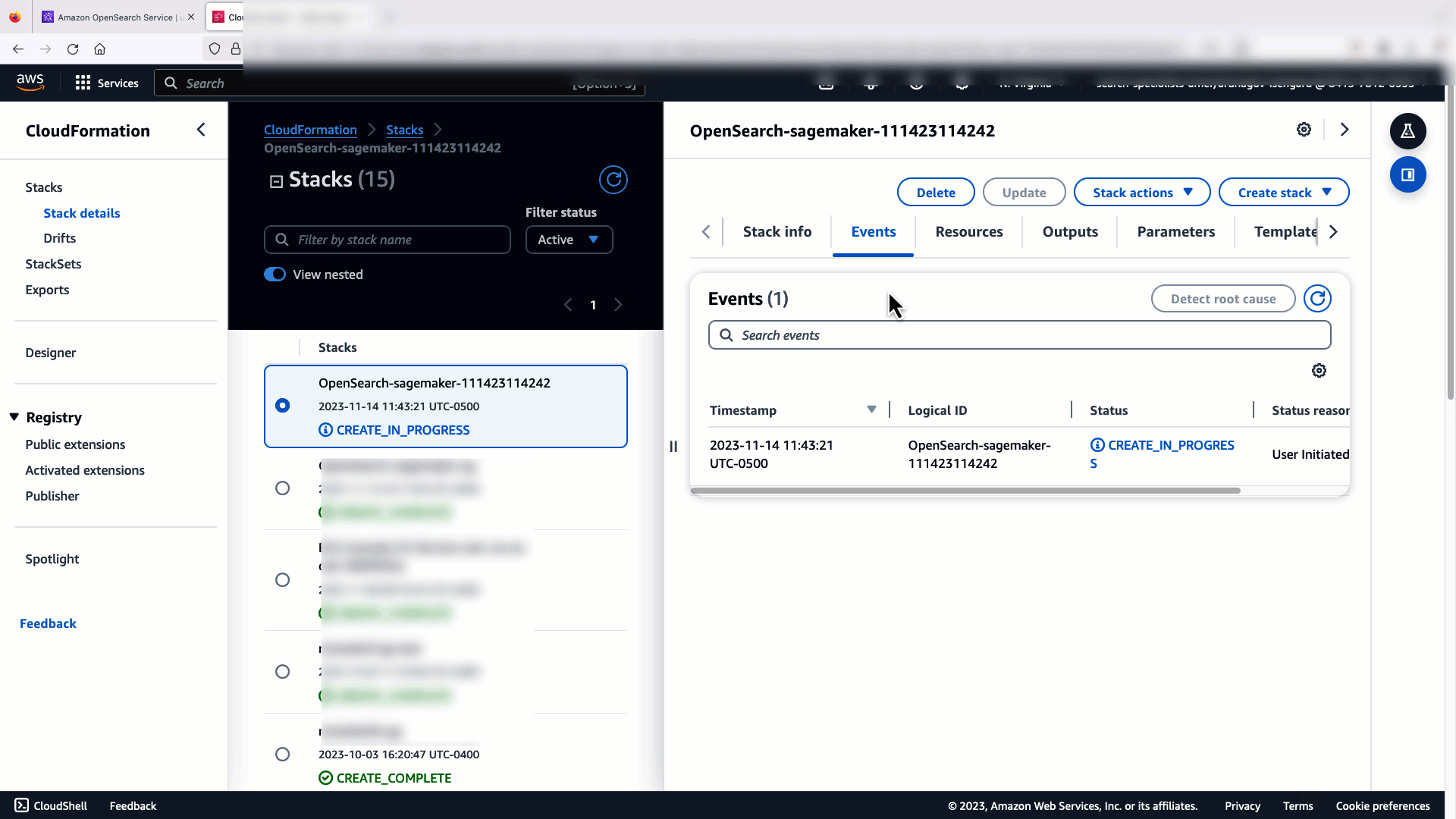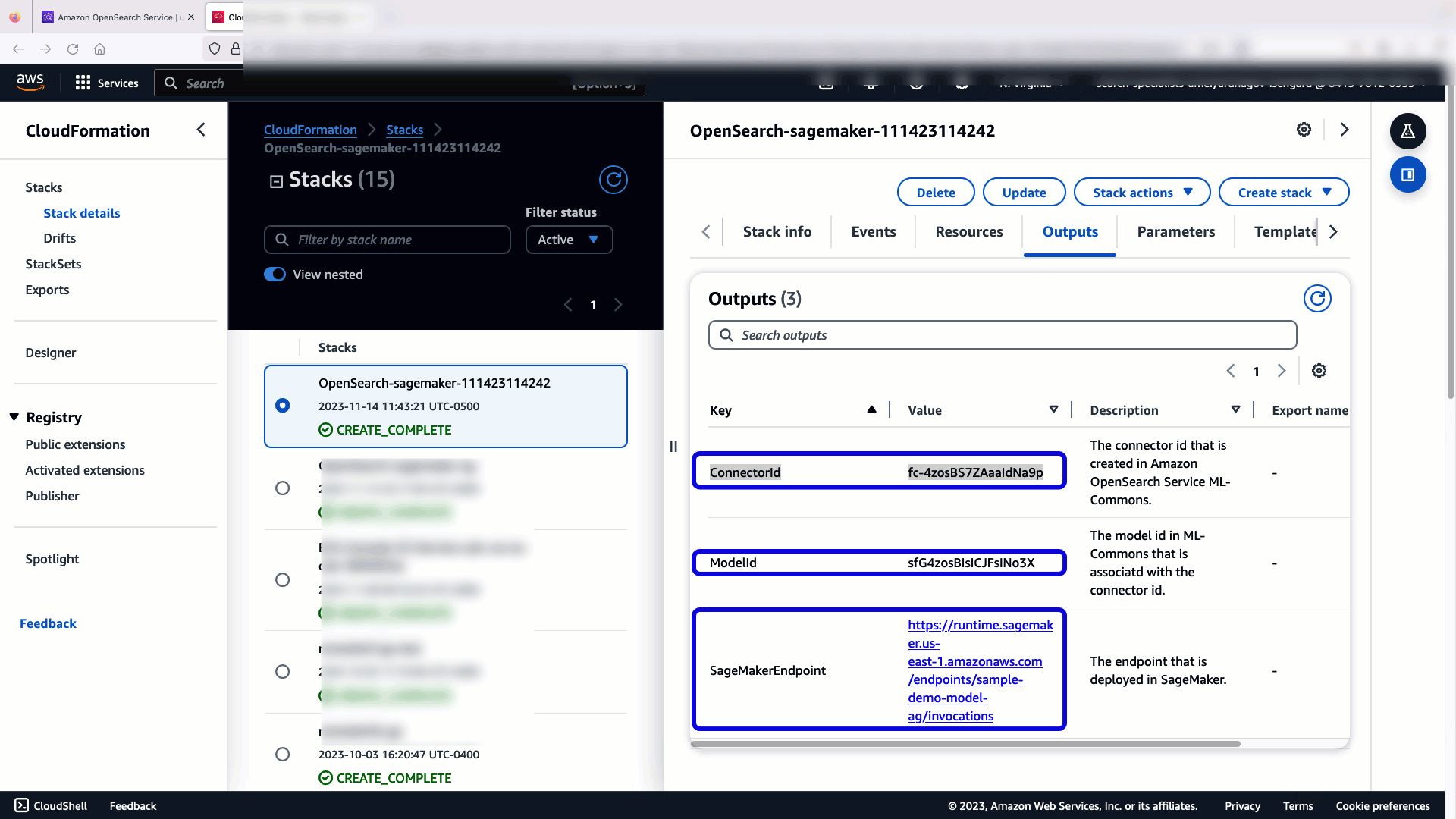
В следующем видеоролике показаны шаги по использованию консоли OpenSearch Service для развертывания модели в Amazon SageMaker за считанные минуты и создания идентификатора модели через коннекторы AI. Первый шаг – выбрать Интеграции в панели навигации консоли OpenSearch Service AWS, которая ведет к списку доступных интеграций. Интеграция настраивается через пользовательский интерфейс, который предложит вам ввести необходимые данные.
Чтобы настроить интеграцию, вам нужно только указать конечную точку домена службы OpenSearch и имя модели, чтобы однозначно идентифицировать соединение модели. По умолчанию в шаблоне используется модель преобразователей предложений Hugging Face. djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
Когда вы выбираете Создать стек, вы будете перенаправлены на AWS CloudFormation консоль. Шаблон CloudFormation развертывает архитектуру, подробно описанную на следующей диаграмме.

Стек CloudFormation создает AWS Lambda приложение, которое развертывает модель из Простой сервис хранения Amazon (Amazon S3), создает соединитель и генерирует идентификатор модели в выходных данных. Затем вы можете использовать этот идентификатор модели для создания семантического индекса.
Если модель MiniLM-L6-v2 по умолчанию не соответствует вашим целям, вы можете развернуть любую модель внедрения текста по вашему выбору на выбранном хосте модели (SageMaker или Amazon Bedrock), предоставив артефакты вашей модели в виде доступного объекта S3. Альтернативно, вы можете выбрать один из следующих предварительно обученные языковые модели и разверните его в SageMaker. Инструкции по настройке конечной точки и моделей см. Доступные образы Amazon SageMaker.
SageMaker — это полностью управляемый сервис, объединяющий широкий набор инструментов для обеспечения высокопроизводительного и недорогого машинного обучения для любого варианта использования, предоставляющий такие ключевые преимущества, как мониторинг моделей, бессерверный хостинг и автоматизация рабочих процессов для непрерывного обучения и развертывания. SageMaker позволяет размещать и управлять жизненным циклом моделей внедрения текста, а также использовать их для обеспечения семантических поисковых запросов в OpenSearch Service. При подключении SageMaker размещает ваши модели, а служба OpenSearch используется для запросов на основе результатов вывода из SageMaker.
Просмотрите развернутую модель через панели мониторинга OpenSearch.
Чтобы убедиться, что шаблон CloudFormation успешно развернул модель в домене OpenSearch Service, и получить идентификатор модели, вы можете использовать API REST GET ML Commons через инструменты разработки OpenSearch Dashboards.
API REST GET _plugins теперь предоставляет дополнительные API для просмотра состояния модели. Следующая команда позволяет увидеть состояние удаленной модели:
Как показано на следующем снимке экрана, DEPLOYED Статус в ответе указывает, что модель успешно развернута в кластере OpenSearch Service.

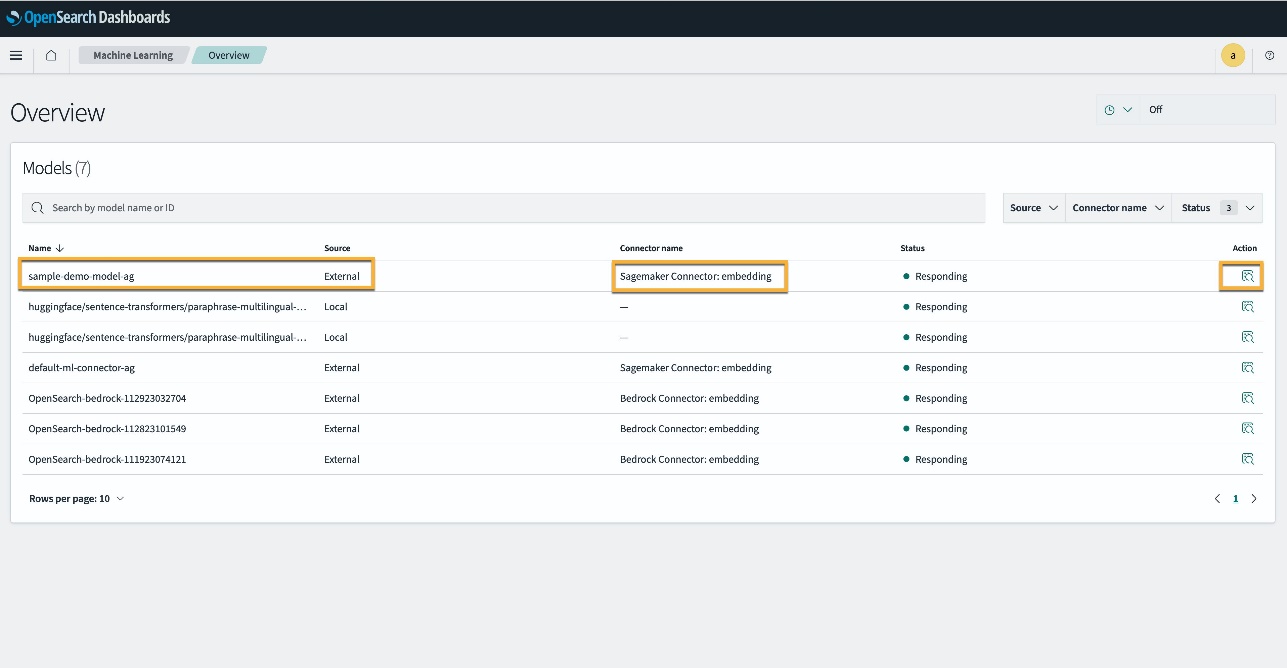
Кроме того, вы можете просмотреть модель, развернутую в вашем домене службы OpenSearch, с помощью Машинное обучение страница панелей мониторинга OpenSearch.

На этой странице перечислены сведения о модели и состояния всех развернутых моделей.

Создайте нейронный конвейер, используя идентификатор модели.
Когда статус модели отображается как DEPLOYED в Dev Tools или зеленый и Реагирование в OpenSearch Dashboards вы можете использовать идентификатор модели для построения нейронного конвейера приема. Следующий конвейер приема запускается в инструментах разработчика OpenSearch Dashboards вашего домена. Обязательно замените идентификатор модели уникальным идентификатором, созданным для модели, развернутой в вашем домене.

Создайте индекс семантического поиска, используя нейронный конвейер в качестве конвейера по умолчанию.
Теперь вы можете определить сопоставление индекса с помощью конвейера по умолчанию, настроенного для использования нового нейронного конвейера, созданного на предыдущем шаге. Убедитесь, что векторные поля объявлены как knn_vector и размеры соответствуют модели, развернутой в SageMaker. Если вы сохранили конфигурацию по умолчанию для развертывания модели MiniLM-L6-v2 в SageMaker, сохраните следующие настройки как есть и запустите команду в Dev Tools.

Прием образцов документов для создания векторов
Для этой демонстрации вы можете использовать образец каталога продукции розничного демо-магазина к новому semantic_demostore индекс. Замените имя пользователя, пароль и конечную точку домена информацией о своем домене и загрузите необработанные данные в службу OpenSearch:

Проверьте новый индекс semantic_demostore.
Теперь, когда вы добавили свой набор данных в домен службы OpenSearch, проверьте, генерируются ли требуемые векторы, с помощью простого поиска для получения всех полей. Проверьте, определены ли поля как knn_vectors иметь необходимые векторы.

Сравните лексический поиск и семантический поиск на основе нейронного поиска с помощью инструмента «Сравнить результаты поиска».
Ассоциация Инструмент сравнения результатов поиска на OpenSearch Dashboards доступен для производственных рабочих нагрузок. Вы можете перейти к Сравните результаты поиска страницу и сравните результаты запроса между лексическим поиском и нейронным поиском, настроенным на использование идентификатора модели, сгенерированного ранее.

Убирать
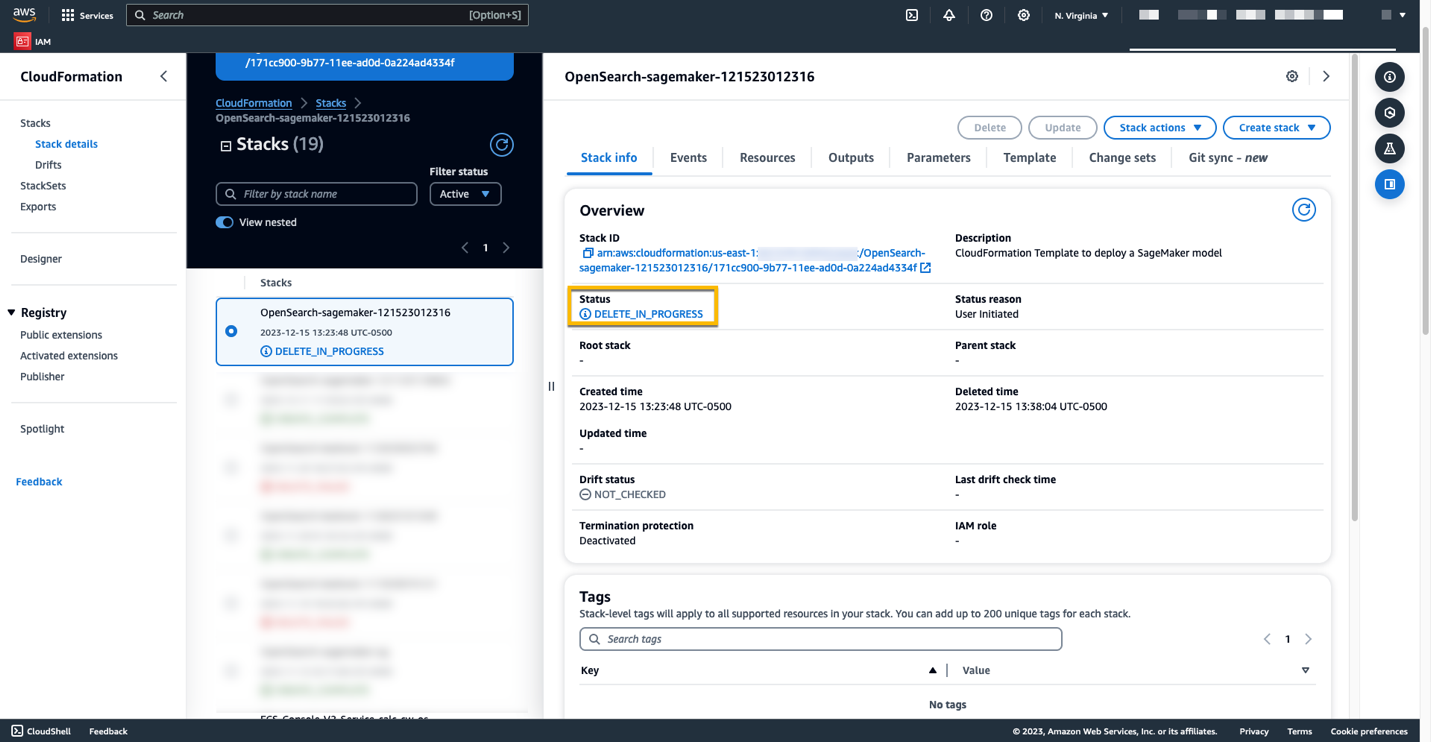
Вы можете удалить ресурсы, созданные вами, следуя инструкциям в этом посте, удалив стек CloudFormation. Это приведет к удалению ресурсов Lambda и корзины S3, содержащих модель, развернутую в SageMaker. Выполните следующие шаги:
- В консоли AWS CloudFormation перейдите на страницу сведений о своем стеке.
- Выберите Удалить.

- Выберите Удалить , чтобы подтвердить действие.

За ходом удаления стека можно следить в консоли AWS CloudFormation.
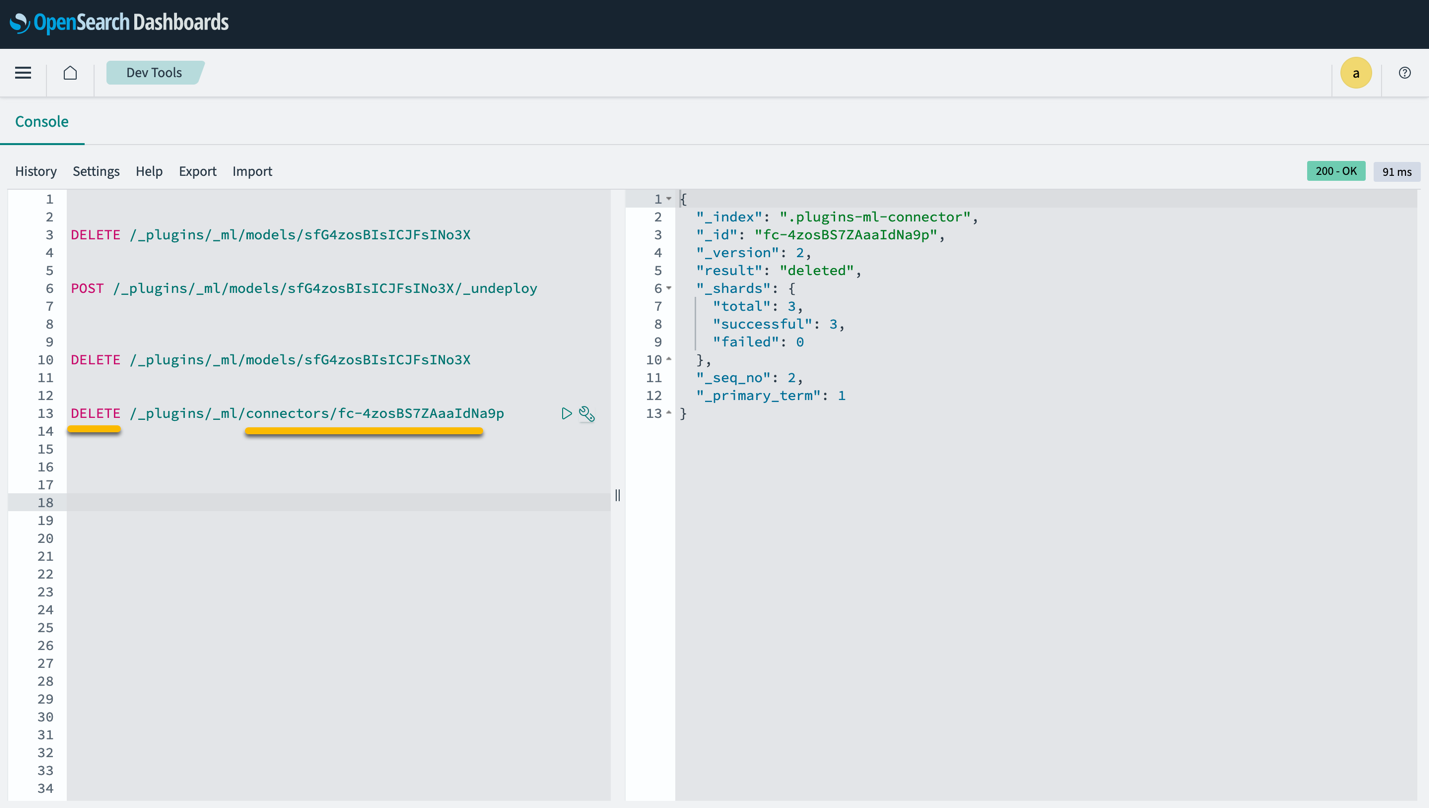
Обратите внимание: удаление стека CloudFormation не удаляет модель, развернутую в домене SageMaker, и созданный соединитель AI/ML. Это связано с тем, что эти модели и соединитель могут быть связаны с несколькими индексами в домене. Чтобы удалить модель и связанный с ней соединитель, используйте API-интерфейсы модели, как показано на следующих снимках экрана.
Первое undeploy модель из памяти домена OpenSearch Service:

Затем вы можете удалить модель из индекса модели:

Наконец, удалите соединитель из индекса соединителя:
Заключение
В этом посте вы узнали, как развернуть модель в SageMaker, создать соединитель AI/ML с помощью консоли OpenSearch Service и построить индекс нейронного поиска. Возможность настройки соединителей AI/ML в OpenSearch Service упрощает процесс векторной гидратации, делая интеграцию с внешними моделями естественной. Вы можете создать индекс нейронного поиска за считанные минуты, используя нейронный конвейер приема и нейронный поиск, которые используют идентификатор модели для генерации векторного внедрения на лету во время приема и поиска.
Дополнительные сведения об этих разъемах AI/ML см. AI-коннекторы Amazon OpenSearch Service для сервисов AWS, Интеграция шаблонов AWS CloudFormation для семантического поискаи Создание коннекторов для сторонних платформ машинного обучения.
Об авторах
 Аруна Говиндараю является специалистом по архитектуре решений Amazon OpenSearch и работал со многими коммерческими поисковыми системами и поисковыми системами с открытым исходным кодом. Она увлечена поиском, релевантностью и пользовательским опытом. Ее опыт в сопоставлении сигналов конечных пользователей с поведением поисковых систем помог многим клиентам улучшить качество поиска.
Аруна Говиндараю является специалистом по архитектуре решений Amazon OpenSearch и работал со многими коммерческими поисковыми системами и поисковыми системами с открытым исходным кодом. Она увлечена поиском, релевантностью и пользовательским опытом. Ее опыт в сопоставлении сигналов конечных пользователей с поведением поисковых систем помог многим клиентам улучшить качество поиска.
 Дэгни Браун — главный менеджер по продукту в AWS, специализирующийся на OpenSearch.
Дэгни Браун — главный менеджер по продукту в AWS, специализирующийся на OpenSearch.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :имеет
- :является
- :нет
- $UP
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- способность
- О нас
- доступ
- доступной
- дополнительный
- AI
- AI / ML
- Все
- позволяет
- причислены
- альтернативы
- Amazon
- Создатель мудреца Амазонки
- Amazon Web Services
- an
- и
- любой
- API
- API
- Применение
- соответствующий
- архитектура
- МЫ
- AS
- связанный
- At
- автоматизация
- доступен
- AWS
- AWS CloudFormation
- Backend
- основанный
- BE
- , так как:
- поведение
- Преимущества
- между
- изоферменты печени
- Приносит
- широкий
- строить
- Строительство
- by
- CAN
- случаев
- случаев
- каталог
- выбор
- Выберите
- выбранный
- Кластер
- коммерческая
- Commons
- сравнить
- полный
- сложность
- Конфигурация
- настроить
- настройка
- подтвердить
- подключенный
- Соединительный
- связи
- Консоли
- содержать
- продолжать
- (CIJ)
- коррелирующий
- Создайте
- создали
- создает
- В настоящее время
- изготовленный на заказ
- Клиенты
- щитки
- данным
- По умолчанию
- определять
- определенный
- доставки
- Демо
- демонстрировать
- демонстрирует
- развертывание
- развернуть
- развертывание
- развертывание
- развертывает
- описание
- подробный
- подробнее
- Дев
- Размеры
- размеры
- Документация
- не
- домен
- в течение
- каждый
- Ранее
- легкий
- или
- вложения
- включить
- Конечная точка
- Двигатель
- Двигатели
- обеспечивать
- Эфир (ETH)
- пример
- опыт
- опыта
- и, что лучший способ
- Face
- облегчает
- Особенность
- Поля
- Найдите
- First
- внимание
- после
- Что касается
- Рамки
- от
- полностью
- порождать
- генерируется
- генерирует
- получить
- GIF
- GitHub
- Зелёная
- Расти
- инструкция
- Есть
- помог
- ее
- высокая производительность
- кашель
- хостинг
- хостов
- Как
- How To
- Однако
- HTML
- HTTP
- HTTPS
- ОбниматьЛицо
- гидратация
- IAM
- ID
- определения
- Личность
- if
- улучшать
- in
- индекс
- Индексы
- указывает
- информация
- затраты
- вместо
- инструкции
- интегрировать
- интеграции.
- интеграций
- в
- Введение
- IT
- ЕГО
- JPG
- JSON
- Сохранить
- Основные
- язык
- запуск
- УЧИТЬСЯ
- узнали
- изучение
- Жизненный цикл
- Список
- Списки
- бюджетный
- машина
- обучение с помощью машины
- сделать
- Создание
- управлять
- управляемого
- менеджер
- многих
- карта
- отображение
- Память
- метод
- минут
- ML
- модель
- Модели
- монитор
- Мониторинг
- БОЛЕЕ
- много
- с разными
- должен
- имя
- родной
- Откройте
- Навигация
- необходимо
- Необходимость
- нервный
- Новые
- сейчас
- объект
- of
- on
- ONE
- только
- открытый
- с открытым исходным кодом
- or
- Другое
- выходной
- страница
- хлеб
- страстный
- Пароль
- Разрешения
- трубопровод
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- плагин
- После
- мощностью
- Питание
- предыдущий
- Основной
- Предварительный
- процесс
- процессоры
- Продукт
- Менеджер по продукции
- Производство
- Прогресс
- свойства
- обеспечивать
- приводит
- обеспечение
- цель
- Запросы
- Сырье
- необработанные данные
- рекомендовать
- относиться
- удаленные
- удаление
- замещать
- обязательный
- Полезные ресурсы
- ответ
- ОТДЫХ
- Итоги
- розничный
- сохраняется
- возвращают
- Роли
- маршруты
- Run
- sagemaker
- скриншоты
- Поиск
- Поисковая система
- Поисковые системы
- безопасность
- посмотреть
- выберите
- служить
- Serverless
- обслуживание
- Услуги
- набор
- настройки
- она
- показанный
- Шоу
- сигналы
- просто
- упрощает
- упростить
- с
- Решения
- Источник
- специалист
- конкретно
- стек
- Начало
- Статус:
- Шаг
- Шаги
- диск
- Успешно
- такие
- Поддержанный
- Убедитесь
- шаблон
- текст
- который
- Ассоциация
- их
- Их
- тогда
- тем самым
- Эти
- сторонние
- этой
- Через
- в
- вместе
- инструменты
- Обучение
- трансформация
- Переводы
- правда
- напишите
- ui
- созданного
- общественного.
- использование
- прецедент
- используемый
- Информация о пользователе
- Пользовательский опыт
- через
- VALIDATE
- проверить
- версия
- с помощью
- Видео
- Вид
- прогулки
- законопроект
- we
- Web
- веб-сервисы
- когда
- который
- будете
- в
- работавший
- рабочий
- автоматизации технологических процессов
- являетесь
- ВАШЕ
- зефирнет