Как практически все клиенты, вы хотите тратить как можно меньше, получая при этом максимальную производительность. Это означает, что вам нужно обратить внимание на соотношение цены и качества. С Амазонка Redshift, ты можешь взять свой торт и съесть его! Amazon Redshift обеспечивает до 4.9 раз более низкую стоимость на одного пользователя и до 7.9 раз лучшее соотношение цены и производительности, чем другие облачные хранилища данных при реальных рабочих нагрузках, используя передовые методы, такие как параллельное масштабирование для поддержки сотен одновременных пользователей, улучшенное кодирование строк для более высокой производительности запросов. , и Amazon Redshift без сервера улучшения производительности. Прочтите, чтобы понять, почему цена-производительность имеет значение и как цена-производительность Amazon Redshift является мерой того, сколько стоит достижение определенного уровня производительности рабочей нагрузки, а именно рентабельности инвестиций в производительность (окупаемости инвестиций).
Поскольку при расчете соотношения цена-качество учитываются и цена, и производительность, существует два подхода к соотношению цена-качество. Первый способ — поддерживать постоянную цену: если у вас есть 1 доллар, какую производительность вы получите от своего хранилища данных? База данных с лучшим соотношением цены и качества обеспечит более высокую производительность на каждый потраченный доллар. Таким образом, при сохранении постоянной цены при сравнении двух хранилищ данных с одинаковой стоимостью база данных с лучшим соотношением цены и производительности будет быстрее выполнять ваши запросы.. Второй способ взглянуть на соотношение цены и качества — поддерживать постоянную производительность: если вам нужно, чтобы ваша рабочая нагрузка завершилась за 10 минут, сколько это будет стоить? База данных с лучшим соотношением цены и производительности позволит выполнить вашу рабочую нагрузку за 10 минут при меньших затратах. Таким образом, при сохранении постоянной производительности при сравнении двух хранилищ данных, размер которых обеспечивает одинаковую производительность, база данных с лучшим соотношением цены и производительности будет стоить меньше и сэкономит вам деньги.
Наконец, еще одним важным аспектом соотношения цены и качества является предсказуемость. Знание того, сколько будет стоить ваше хранилище данных по мере роста числа пользователей хранилища данных, имеет решающее значение для планирования. Он должен не только обеспечивать лучшее соотношение цены и качества на сегодняшний день, но также предсказуемо масштабироваться и обеспечивать наилучшее соотношение цены и качества по мере добавления новых пользователей и рабочих нагрузок. Идеальное хранилище данных должно иметь линейная шкала— масштабирование хранилища данных для увеличения пропускной способности запросов в два раза в идеале должно стоить вдвое дороже (или меньше).
В этой статье мы представляем результаты производительности, чтобы проиллюстрировать, как Amazon Redshift обеспечивает значительно лучшее соотношение цены и качества по сравнению с ведущими альтернативными облачными хранилищами данных. Это означает, что если вы потратите на Amazon Redshift ту же сумму, что и на одно из этих других хранилищ данных, вы получите более высокую производительность с Amazon Redshift. Альтернативно, если вы выберете размер кластера Redshift для обеспечения той же производительности, вы увидите более низкие затраты по сравнению с этими альтернативами.
Цена-производительность для реальных рабочих нагрузок
Вы можете использовать Amazon Redshift для выполнения самых разнообразных рабочих нагрузок: от пакетной обработки сложных отчетов на основе извлечения, преобразования и загрузки (ETL) и потоковой аналитики в реальном времени до информационных панелей бизнес-аналитики (BI) с малой задержкой, которые необходимо обслуживать сотни или даже тысячи пользователей одновременно с временем отклика в доли секунды и всем, что между ними. Один из способов постоянного улучшения соотношения цены и качества для наших клиентов — это постоянный анализ телеметрии производительности программного и аппаратного обеспечения парка Redshift в поисках возможностей и сценариев использования для клиентов, в которых мы можем еще больше улучшить производительность Amazon Redshift.
Некоторые недавние примеры оптимизации производительности, основанные на телеметрии автопарка, включают:
- Оптимизация строковых запросов – Проанализировав, как Amazon Redshift обрабатывает различные типы данных в парке Redshift, мы обнаружили, что оптимизация запросов с большим количеством строк принесет значительную выгоду рабочим нагрузкам наших клиентов. (Подробнее мы обсудим это далее в этой статье.)
- Автоматизированные материализованные представления – Мы обнаружили, что клиенты Amazon Redshift часто выполняют множество запросов, имеющих общие шаблоны подзапросов. Например, несколько разных запросов могут объединять одни и те же три таблицы, используя одно и то же условие соединения. Amazon Redshift теперь может автоматически создавать и поддерживать материализованные представления, а затем прозрачно переписывать запросы для использования материализованных представлений с помощью машинного обучения. автоматизированное материализованное представление функция автономности в Amazon Redshift. Если эта функция включена, автоматические материализованные представления могут прозрачно повысить производительность повторяющихся запросов без какого-либо вмешательства пользователя. (Обратите внимание, что автоматические материализованные представления не использовались ни в одном из результатов тестов, обсуждаемых в этом посте).
- Рабочие нагрузки с высоким параллелизмом – Мы наблюдаем растущий вариант использования Amazon Redshift для обслуживания рабочих нагрузок, подобных информационным панелям. Эти рабочие нагрузки характеризуются желаемым временем ответа на запрос, составляющим однозначные секунды или меньше, при этом десятки или сотни одновременных пользователей выполняют запросы одновременно с резким и часто непредсказуемым шаблоном использования. Прототипическим примером этого является панель BI на базе Amazon Redshift, в которой наблюдается всплеск трафика по утрам в понедельник, когда большое количество пользователей начинает свою неделю.
Рабочие нагрузки с высоким уровнем параллелизма, в частности, имеют очень широкое применение: большинство рабочих нагрузок хранилищ данных работают в параллельном режиме, и сотни или даже тысячи пользователей нередко одновременно выполняют запросы в Amazon Redshift. Amazon Redshift был разработан, чтобы обеспечить предсказуемое и быстрое время ответа на запросы. Redshift Serverless делает это автоматически, добавляя и удаляя вычислительные ресурсы по мере необходимости, чтобы обеспечить быстрое и предсказуемое время ответа на запросы. Это означает, что панель управления с поддержкой Redshift Serverless, которая загружается быстро, когда к ней обращаются один или два пользователя, будет продолжать быстро загружаться, даже если многие пользователи загружают ее одновременно.
Для моделирования этого типа рабочей нагрузки мы использовали тест, полученный из TPC-DS, с набором данных объемом 100 ГБ. TPC-DS — это стандартный отраслевой тест, включающий множество типичных запросов к хранилищу данных. При этом относительно небольшом масштабе в 100 ГБ запросы в этом тесте выполняются на Redshift Serverless в среднем за несколько секунд, что соответствует ожиданиям пользователей, загружающих интерактивную панель BI. Мы провели от 1 до 200 одновременных тестов этого теста, моделируя от 1 до 200 пользователей, пытающихся одновременно загрузить панель мониторинга. Мы также повторили тест на нескольких популярных альтернативных облачных хранилищах данных, которые также поддерживают автоматическое масштабирование (если вы знакомы с постом Amazon Redshift продолжает лидировать по соотношению цена-качество, мы не включили конкурента А, поскольку он не поддерживает автоматическое масштабирование). Мы измерили среднее время ответа на запрос, то есть, как долго пользователь будет ждать завершения своих запросов (или загрузки панели управления). Результаты показаны на следующей диаграмме.
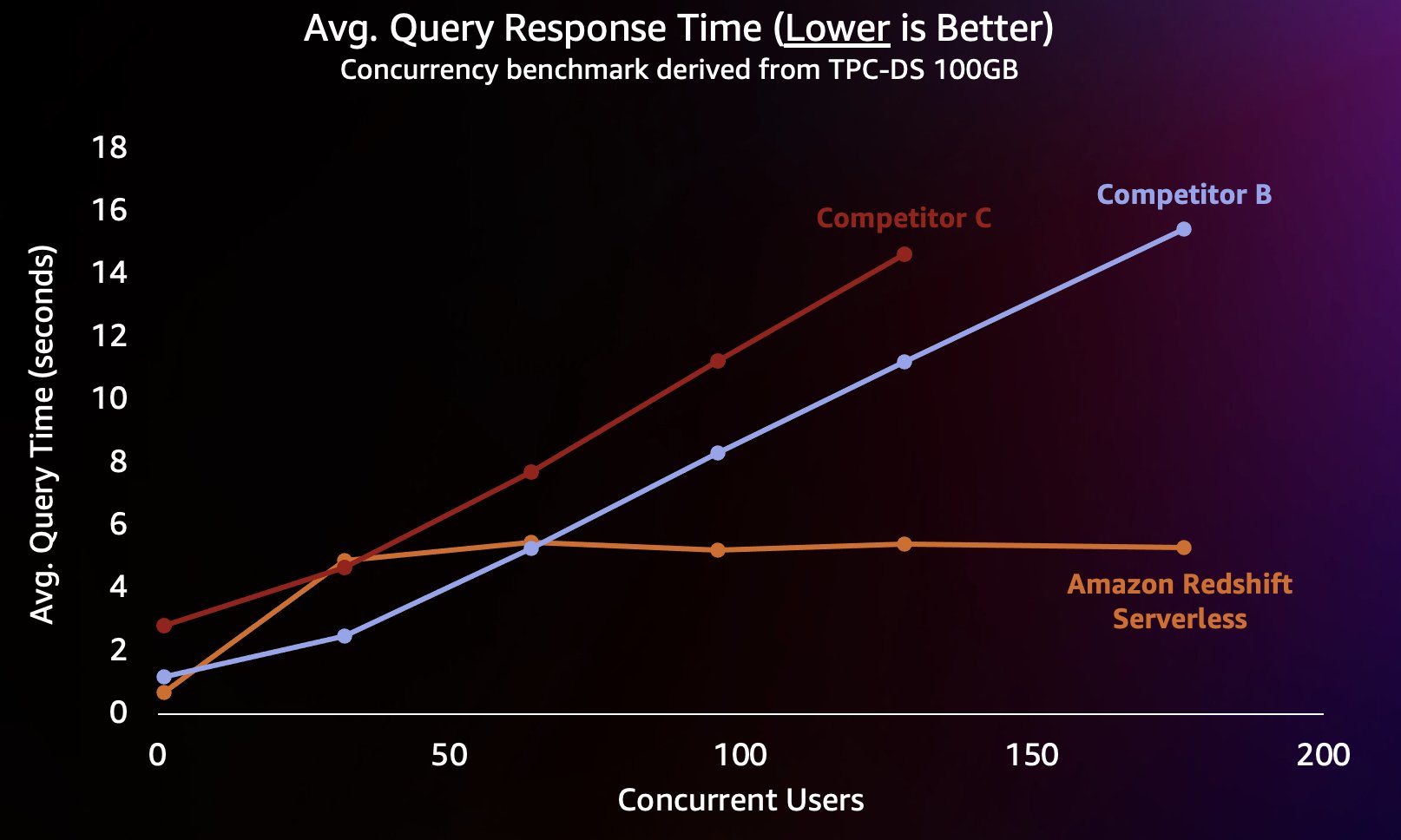
Конкурент Б хорошо масштабируется примерно до 64 одновременных запросов, после чего он не может обеспечить дополнительные вычисления и запросы начинают стоять в очереди, что приводит к увеличению времени ответа на запрос. Хотя конкурент C может масштабироваться автоматически, он масштабируется для более низкой пропускной способности запросов, чем Amazon Redshift и конкурент B, и не может поддерживать низкое время выполнения запросов. Кроме того, он не поддерживает запросы в очередь, когда у него заканчиваются вычислительные ресурсы, что не позволяет ему масштабироваться за пределы 128 одновременных пользователей. Отправка дополнительных запросов сверх этого отклоняется системой.
Здесь Redshift Serverless способен поддерживать относительно постоянное время ответа на запрос — около 5 секунд, даже когда сотни пользователей одновременно выполняют запросы. Среднее время ответа на запросы для конкурентов B и C постоянно увеличивается по мере увеличения нагрузки на хранилища, в результате чего пользователям приходится дольше (до 16 секунд) ждать ответа на свои запросы, когда хранилище данных занято. Это означает, что если пользователь пытается обновить информационную панель (которая при перезагрузке может даже отправить несколько одновременных запросов), Amazon Redshift сможет обеспечить гораздо более единообразное время загрузки информационной панели, даже если панель загружается десятками или сотнями других пользователей. пользователей одновременно.
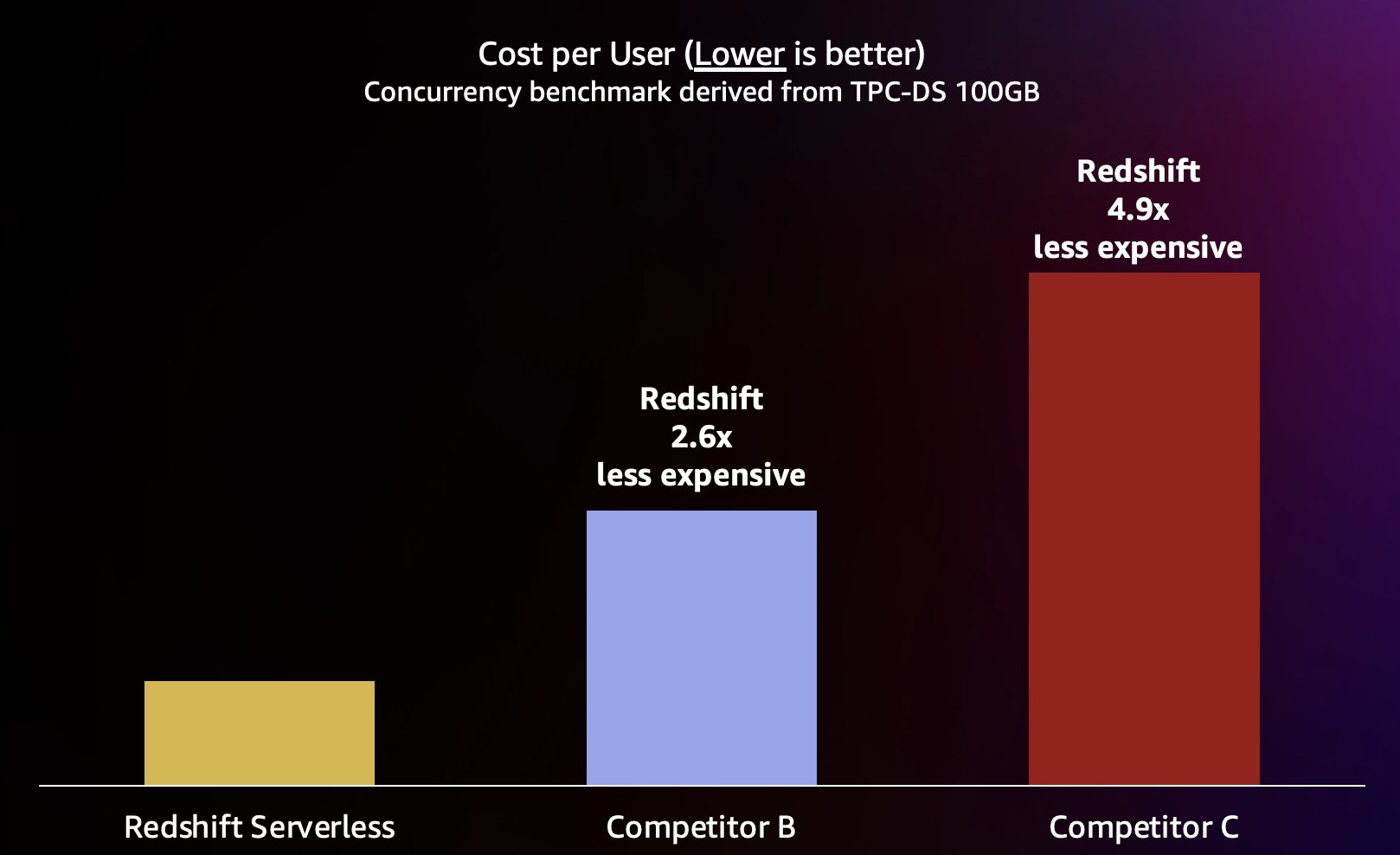
Поскольку Amazon Redshift способен обеспечить очень высокую пропускную способность для коротких запросов (как мы писали в Amazon Redshift продолжает лидировать по соотношению цена-качество), он также способен обрабатывать более высокий уровень параллелизма при более эффективном масштабировании и, следовательно, со значительно меньшими затратами. Чтобы количественно оценить это, мы смотрим на соотношение цена-качество, используя опубликованные данные. ценообразование по требованию для каждого из складов в предыдущем тесте, как показано на следующей диаграмме. Стоит отметить, что использование Зарезервированные экземпляры (RI), особенно трехлетние зарезервированные инстансы, приобретенные с возможностью полной предоплаты, имеют минимальные затраты на запуск Amazon Redshift в подготовленных кластерах, что приводит к наилучшему соотношению цены и производительности по сравнению с вариантами зарезервированных инстансов по требованию или другими вариантами зарезервированных инстансов.

Таким образом, Amazon Redshift не только способен обеспечить более высокую производительность при более высоком уровне параллелизма, но и при значительно меньших затратах. Каждая точка данных на диаграмме «цена-производительность» эквивалентна стоимости запуска эталонного теста при указанном параллелизме. Поскольку соотношение цены и производительности является линейным, мы можем разделить затраты на выполнение теста при любой параллельности на параллельность (количество одновременных пользователей на этой диаграмме), чтобы узнать, сколько стоит добавление каждого нового пользователя для этого конкретного теста.
Предыдущие результаты легко повторить. Все запросы, использованные в тесте, доступны в нашем Репозиторий GitHub а производительность измеряется путем запуска хранилища данных, включения параллельного масштабирования в Amazon Redshift (или соответствующей функции автоматического масштабирования в других хранилищах), загрузки данных «из коробки» (без ручной настройки или настройки для конкретной базы данных), а затем запуска параллельный поток запросов с числом параллелизма от 1 до 200 с шагом 32 в каждом хранилище данных. Тот же репозиторий GitHub ссылается на предварительно сгенерированные (и немодифицированные) данные TPC-DS в Простой сервис хранения Amazon (Amazon S3) в различных масштабах с использованием официального комплекта генерации данных TPC-DS.
Оптимизация строковых рабочих нагрузок
Как упоминалось ранее, команда Amazon Redshift постоянно ищет новые возможности, чтобы обеспечить еще лучшее соотношение цены и качества для наших клиентов. Недавно мы выпустили одно из усовершенствований, которое значительно повысило производительность. Это оптимизация, ускоряющая выполнение запросов к строковым данным. Например, вы можете найти общий доход, полученный от розничных магазинов, расположенных в Нью-Йорке, с помощью запроса типа SELECT sum(price) FROM sales WHERE city = ‘New York’. Этот запрос применяет предикат к строковым данным (city = ‘New York’). Как вы понимаете, обработка строковых данных широко распространена в приложениях хранилищ данных.
Чтобы количественно оценить, как часто рабочие нагрузки клиентов обращаются к строкам, мы провели подробный анализ использования строкового типа данных с использованием телеметрии парка десятков тысяч клиентских кластеров, управляемых Amazon Redshift. Наш анализ показывает, что в 90% кластеров строковые столбцы составляют не менее 30% всех столбцов, а в 50% кластеров строковые столбцы составляют не менее 50% всех столбцов. Более того, большинство всех запросов, выполняемых на платформе облачного хранилища данных Amazon Redshift, обращаются как минимум к одному строковому столбцу. Еще одним важным фактором является то, что строковые данные очень часто имеют низкую мощность, то есть столбцы содержат относительно небольшой набор уникальных значений. Например, хотя orders таблица, представляющая данные о продажах, может содержать миллиарды строк, order_status Столбец в этой таблице может содержать лишь несколько уникальных значений в этих миллиардах строк, например pending, in processи completed.
На момент написания этой статьи большинство строковых столбцов в Amazon Redshift сжимаются с помощью ЛЗО or ЗСТД алгоритмы. Это хорошие алгоритмы сжатия общего назначения, но они не предназначены для использования строковых данных с низкой мощностью. В частности, они требуют, чтобы данные были распакованы перед операцией, и менее эффективно используют пропускную способность аппаратной памяти. Для данных с низкой мощностью существует другой тип кодирования, который может быть более оптимальным: БАЙТЕДИКТ. В этом кодировании используется схема словарного кодирования, которая позволяет ядру базы данных работать непосредственно со сжатыми данными без необходимости предварительной их распаковки.
Чтобы еще больше улучшить соотношение цены и качества для рабочих нагрузок с большим количеством строк, Amazon Redshift теперь представляет дополнительные улучшения производительности, которые ускоряют сканирование и оценку предикатов по сравнению со строковыми столбцами с низкой мощностью, закодированными как BYTEDICT, в 5–63 раза быстрее (см. результаты в следующий раздел) по сравнению с альтернативными кодировками сжатия, такими как LZO или ZSTD. Amazon Redshift достигает такого повышения производительности за счет векторизации сканирования по легким, эффективно использующим ЦП строковым столбцам с низкой мощностью, закодированным BYTEDICT. Эти оптимизации обработки строк позволяют эффективно использовать пропускную способность памяти, предоставляемую современным оборудованием, позволяя проводить анализ строковых данных в реальном времени. Эти новые возможности производительности оптимальны для строковых столбцов с низкой мощностью (до нескольких сотен уникальных строковых значений).
Вы можете автоматически извлечь выгоду из этого нового усовершенствования высокопроизводительных строк, включив автоматическая оптимизация стола в вашем хранилище данных Amazon Redshift. Если у вас не включена автоматическая оптимизация таблиц, вы можете получать рекомендации от Советник Amazon Redshift в консоли Amazon Redshift о пригодности строкового столбца для кодирования BYTEDICT. Вы также можете определить новые таблицы со строковыми столбцами с низкой мощностью и кодировкой BYTEDICT. Улучшения строк в Amazon Redshift теперь доступны во всех регионах AWS, где Amazon Redshift доступен.
Результаты
Чтобы измерить влияние наших улучшений строк на производительность, мы создали набор данных объемом 10 ТБ (терабайт), который состоял из строковых данных с низкой мощностью. Мы сгенерировали три версии данных, используя короткие, средние и длинные строки, соответствующие 25-му, 50-му и 75-му процентилю длин строк из телеметрии парка Amazon Redshift. Мы дважды загрузили эти данные в Amazon Redshift, закодировав их в одном случае с помощью сжатия LZO, а в другом — с помощью сжатия BYTEDICT. Наконец, мы измерили производительность запросов с большим объемом сканирования, которые возвращают много строк (90% таблицы), среднее количество строк (50% таблицы) и несколько строк (1% таблицы) по сравнению с этими низкими значениями. Наборы строковых данных -мощность. Результаты производительности представлены в следующей таблице.

Запросы с предикатами, которые соответствуют высокому проценту строк, показали улучшение в 5–30 раз при использовании новой векторизованной кодировки BYTEDICT по сравнению с LZO, тогда как запросы с предикатами, которые соответствуют низкому проценту строк, показали улучшения в 10–63 раза в этом внутреннем тесте.
Redshift Serverless цена-качество
В дополнение к результатам производительности с высоким уровнем параллелизма, представленным в этой статье, мы также использовали тест Cloud Data Warehouse на основе TPC-DS, чтобы сравнить соотношение цены и производительности Redshift Serverless с другими хранилищами данных, использующими больший набор данных объемом 3 ТБ. Мы выбрали хранилища данных с одинаковой ценой, в данном случае в пределах 10% от 32 долларов США в час с использованием общедоступных цен по требованию. Эти результаты показывают, что, как и инстансы Amazon Redshift RA3, Redshift Serverless обеспечивает лучшее соотношение цены и качества по сравнению с другими ведущими облачными хранилищами данных. Как всегда, эти результаты можно воспроизвести с помощью наших SQL-скриптов в нашей программе. Репозиторий GitHub.

Мы рекомендуем вам попробовать Amazon Redshift, используя свои собственные доказательство концепции рабочих нагрузок как лучший способ увидеть, как Amazon Redshift может удовлетворить ваши потребности в анализе данных.
Найдите лучшее соотношение цены и качества для ваших рабочих нагрузок
Тесты, используемые в этой статье, основаны на стандартном тесте TPC-DS и имеют следующие характеристики:
- Схема и данные используются без изменений из TPC-DS.
- Запросы генерируются с использованием официального набора TPC-DS, а параметры запроса генерируются с использованием случайного начального числа по умолчанию набора TPC-DS. Варианты запроса, одобренные TPC, используются для хранилища, если хранилище не поддерживает диалект SQL запроса TPC-DS по умолчанию.
- Тест включает 99 запросов TPC-DS SELECT. Он не включает этапы обслуживания и пропускной способности.
- Для одного теста параллелизма объемом 3 ТБ было выполнено три прогона мощности, и для каждого хранилища данных выбирался лучший прогон.
- Цена-производительность для запросов TPC-DS рассчитывается как стоимость часа (в долларах США), умноженная на время выполнения теста в часах, что эквивалентно стоимости запуска теста. Для всех хранилищ данных используются последние опубликованные цены по требованию, а не цены на зарезервированные экземпляры, как отмечалось ранее.
Мы называем это тестом облачного хранилища данных, и вы можете легко воспроизвести результаты предыдущего теста, используя сценарии, запросы и данные, доступные в нашем Репозиторий GitHub. Он получен на основе тестов TPC-DS, описанных в этом посте, и поэтому не сопоставим с опубликованными результатами TPC-DS, поскольку результаты наших тестов не соответствуют официальной спецификации.
Заключение
Amazon Redshift стремится обеспечить лучшее в отрасли соотношение цены и качества для самого широкого спектра рабочих нагрузок. Redshift Serverless масштабируется линейно, обеспечивая лучшее (наименьшее) соотношение цены и качества, поддерживая сотни одновременных пользователей, сохраняя при этом постоянное время ответа на запросы. Судя по результатам испытаний, обсуждаемых в этой статье, Amazon Redshift имеет в 2.6 раза лучшее соотношение цены и производительности при том же уровне параллелизма по сравнению с ближайшим конкурентом (конкурентом B). Как упоминалось ранее, использование зарезервированных инстансов с возможностью предоплаты на 3 года дает вам минимальные затраты на запуск Amazon Redshift, что приводит к еще лучшему соотношению цены и производительности по сравнению с ценами на инстансы по требованию, которые мы использовали в этом посте. Наш подход к постоянному повышению производительности включает в себя уникальное сочетание стремления клиентов понять сценарии использования клиентов и связанные с ними узкие места масштабируемости в сочетании с непрерывным анализом данных парка техники для выявления возможностей значительной оптимизации производительности.
Каждая рабочая нагрузка имеет уникальные характеристики, поэтому, если вы только начинаете, доказательство концепции — лучший способ понять, как Amazon Redshift может снизить ваши затраты, одновременно повысив производительность. При проверке собственной концепции важно сосредоточиться на правильных показателях — пропускной способности запросов (количество запросов в час), времени ответа и соотношении цена-качество. Вы можете принять решение на основе данных, проведя проверку концепции самостоятельно или с помощью из AWS или партнер по системной интеграции и консалтингу.
Чтобы быть в курсе последних событий в Amazon Redshift, следуйте инструкциям Что нового в Amazon Redshift кормить.
Об авторах
 Стефан Громолл — старший инженер по производительности в команде Amazon Redshift, где он отвечает за измерение и улучшение производительности Redshift. В свободное время он любит готовить, играть со своими тремя сыновьями и рубить дрова.
Стефан Громолл — старший инженер по производительности в команде Amazon Redshift, где он отвечает за измерение и улучшение производительности Redshift. В свободное время он любит готовить, играть со своими тремя сыновьями и рубить дрова.
 Рави Аними является старшим руководителем управления продуктами в команде Amazon Redshift и управляет несколькими функциональными областями службы облачного хранилища данных Amazon Redshift, включая производительность, пространственный анализ, стратегии приема потоковой передачи и миграции. У него есть опыт работы с реляционными и многомерными базами данных, технологиями Интернета вещей, услугами хранения и вычислительной инфраструктуры, а в последнее время он является основателем стартапа, использующего искусственный интеллект/глубокое обучение, компьютерное зрение и робототехнику.
Рави Аними является старшим руководителем управления продуктами в команде Amazon Redshift и управляет несколькими функциональными областями службы облачного хранилища данных Amazon Redshift, включая производительность, пространственный анализ, стратегии приема потоковой передачи и миграции. У него есть опыт работы с реляционными и многомерными базами данных, технологиями Интернета вещей, услугами хранения и вычислительной инфраструктуры, а в последнее время он является основателем стартапа, использующего искусственный интеллект/глубокое обучение, компьютерное зрение и робототехнику.
 Аамер Шах — старший инженер в команде Amazon Redshift Service.
Аамер Шах — старший инженер в команде Amazon Redshift Service.
 Санкет Хасэ — менеджер по разработке программного обеспечения в команде Amazon Redshift Service.
Санкет Хасэ — менеджер по разработке программного обеспечения в команде Amazon Redshift Service.
 Орестис Полихрониу — главный инженер в команде Amazon Redshift Service.
Орестис Полихрониу — главный инженер в команде Amazon Redshift Service.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :имеет
- :является
- :нет
- :куда
- $UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- в состоянии
- О нас
- ускоряет
- доступ
- Доступ
- Достигает
- через
- добавленный
- добавить
- дополнение
- дополнительный
- продвинутый
- плюс
- дает
- против
- алгоритмы
- Все
- позволяет
- причислены
- альтернатива
- альтернативы
- Несмотря на то, что
- всегда
- Amazon
- Amazon Web Services
- количество
- an
- анализ
- аналитика
- анализ
- и
- Другой
- любой
- Приложения
- Применение
- подхода
- МЫ
- области
- около
- AS
- внешний вид
- связанный
- At
- внимание
- автоматический
- Автоматизированный
- Автоматический
- автоматически
- доступен
- в среднем
- AWS
- b
- Пропускная способность
- основанный
- BE
- , так как:
- до
- начинать
- не являетесь
- эталонный тест
- тесты
- польза
- ЛУЧШЕЕ
- Лучшая
- между
- Beyond
- миллиарды
- изоферменты печени
- узкие
- Коробка
- приносить
- широкий
- бизнес
- бизнес-аналитика
- занятый
- но
- by
- CAKE
- рассчитанный
- расчет
- призывают
- CAN
- возможности
- случаев
- случаев
- характеристика
- отличающийся
- График
- рубящий
- выбрал
- Город
- облако
- Кластер
- Column
- Колонки
- сочетание
- привержен
- Общий
- сравнимый
- сравнить
- сравненный
- сравнив
- конкурент
- конкурентов
- комплекс
- соблюдать
- Вычисление
- компьютер
- Компьютерное зрение
- сама концепция
- параллельный
- состояние
- проводятся
- последовательный
- Консоли
- постоянная
- постоянно
- составлять
- консалтинг
- содержать
- беспрестанно
- продолжать
- продолжается
- (CIJ)
- непрерывно
- приготовление
- соответствующий
- Цена
- Расходы
- соединенный
- Создайте
- решающее значение
- клиент
- Клиенты
- приборная панель
- щитки
- данным
- анализ данных
- Анализ данных
- обработка данных
- набор данных
- информационное хранилище
- хранилища данных
- управляемых данными
- База данных
- базы данных
- Наборы данных
- Время
- решение
- По умолчанию
- определять
- доставить
- доставки
- обеспечивает
- Производный
- описано
- предназначенный
- желанный
- подробность
- подробный
- Развитие
- события
- различный
- непосредственно
- обсуждать
- обсуждается
- Разнообразие
- делить
- do
- приносит
- не
- Dont
- управляемый
- каждый
- Ранее
- легко
- есть
- Эффективный
- эффективный
- эффективно
- включен
- позволяет
- поощрять
- Двигатель
- инженер
- расширение
- усиление
- улучшения
- Enter
- Эквивалент
- особенно
- Эфир (ETH)
- оценки
- Даже
- многое
- пример
- Примеры
- ожидать
- опыт
- извлечение
- фактор
- знакомый
- далеко
- БЫСТРО
- быстрее
- Особенность
- несколько
- в заключение
- Найдите
- окончание
- Во-первых,
- ФЛОТ
- Фокус
- следовать
- после
- Что касается
- найденный
- основатель
- от
- функциональная
- далее
- общее назначение
- генерируется
- поколение
- получить
- получающий
- GitHub
- дает
- будет
- хорошо
- Рост
- Растет
- обрабатывать
- Аппаратные средства
- Есть
- имеющий
- he
- High
- высший
- его
- держать
- проведение
- час
- ЧАСЫ
- Как
- HTML
- HTTP
- HTTPS
- сто
- Сотни
- идеальный
- Идеально
- определения
- if
- иллюстрировать
- картина
- Влияние
- важную
- важный аспект
- улучшать
- улучшенный
- улучшение
- улучшение
- улучшение
- in
- включают
- включает в себя
- В том числе
- Увеличение
- расширились
- Увеличивает
- указывает
- отрасли
- Инфраструктура
- пример
- случаев
- интеграции.
- Интеллекта
- интерактивный
- в нашей внутренней среде,
- вмешательство
- в
- выпустили
- введение
- инвестиций
- включает в себя
- КАТО
- IT
- ЕГО
- присоединиться
- JPG
- всего
- Сохранить
- комплект
- знание
- большой
- больше
- новее
- последний
- последние разработки
- запустили
- запуск
- лидер
- ведущий
- изучение
- наименее
- Меньше
- уровень
- легкий
- такое как
- мало
- загрузка
- погрузка
- грузы
- расположенный
- Длинное
- дольше
- посмотреть
- искать
- Низкий
- ниже
- низший
- поддерживать
- сохранение
- техническое обслуживание
- Большинство
- сделать
- управляемого
- управление
- менеджер
- управляет
- руководство
- многих
- Совпадение
- Вопросы
- Май..
- смысл
- означает
- проводить измерение
- измеренный
- измерение
- средний
- Встречайте
- Память
- упомянутый
- может быть
- миграция
- минут
- Модерн
- понедельник
- деньги
- БОЛЕЕ
- Более того
- самых
- много
- а именно
- Необходимость
- необходимый
- потребности
- Новые
- New York
- Нью-Йорк
- вновь
- следующий
- нет
- в своих размышлениях
- отметил,
- отметив,
- сейчас
- номер
- of
- Официальный представитель в Грузии
- .
- on
- On-Demand
- ONE
- только
- работать
- работать
- Возможности
- оптимальный
- оптимизация
- оптимизирующий
- Опция
- Опции
- or
- Другое
- наши
- внешний
- за
- собственный
- параметры
- особый
- шаблон
- паттеранами
- ОПЛАТИТЬ
- оплата
- для
- процент
- производительность
- планирование
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игры
- Точка
- Популярное
- возможное
- После
- мощностью
- предсказуемый
- представлены
- предотвращает
- цена
- цены
- Основной
- обрабатываемых
- обработка
- Продукт
- Управление продуктом
- доказательство
- доказательство концепции
- обеспечивать
- публично
- опубликованный
- купленный
- Запросы
- быстро
- случайный
- Читать
- реальный мир
- реального времени
- Получать
- последний
- недавно
- рекомендаций
- Рекомендации
- районы
- Отклоненный..
- относительный
- относительно
- удаление
- повторный
- повторяющийся
- реплицируются
- Отчеты
- представитель
- представляющий
- требовать
- зарезервированный
- ответ
- ответственный
- в результате
- Итоги
- розничный
- возвращают
- доходы
- обзоре
- правую
- робототехника
- ROI
- Run
- Бег
- работает
- главная
- то же
- Сохранить
- видел
- Масштабируемость
- Шкала
- Весы
- масштабирование
- сканирует
- схема
- скрипты
- Во-вторых
- секунды
- Раздел
- посмотреть
- семя
- старший
- служить
- Serverless
- обслуживание
- Услуги
- набор
- установка
- несколько
- Поделиться
- Короткое
- должен
- показывать
- показанный
- значительный
- существенно
- Аналогичным образом
- просто
- одновременно
- одинарной
- Размер
- размера
- небольшой
- So
- Software
- разработка программного обеспечения
- пространственный
- Спецификация
- указанный
- скорость
- тратить
- потраченный
- шип
- SQL
- Начало
- и политические лидеры
- ввод в эксплуатацию
- оставаться
- неуклонно
- Шаги
- диск
- магазины
- простой
- стратегий
- поток
- потоковый
- строка
- отправить
- такие
- пригодность
- поддержка
- поддержки
- система
- ТАБЛИЦЫ
- взять
- приняты
- команда
- снижения вреда
- технологии
- сказать
- десятки
- тестXNUMX
- тестов
- чем
- который
- Ассоциация
- их
- тогда
- Там.
- следовательно
- Эти
- они
- think
- этой
- те
- тысячи
- три
- пропускная способность
- время
- раз
- в
- сегодня
- Всего
- трафик
- Transform
- прозрачно
- стараться
- пытается
- Дважды
- два
- напишите
- Типы
- типичный
- вездесущий
- не в состоянии
- Обычный
- понимать
- созданного
- непредсказуемый
- до
- us
- Применение
- USD
- использование
- прецедент
- используемый
- Информация о пользователе
- пользователей
- использования
- через
- Наши ценности
- разнообразие
- различный
- очень
- Просмотры
- фактически
- видение
- ждать
- хотеть
- Склады
- законопроект
- Путь..
- способы
- we
- Web
- веб-сервисы
- неделя
- ЧТО Ж
- были
- Что
- когда
- в то время как
- , которые
- в то время как
- зачем
- широкий
- будете
- в
- без
- стоимость
- бы
- письмо
- писал
- йорк
- являетесь
- ВАШЕ
- зефирнет