Amazon RedShift este un depozit de date cloud complet gestionat și la scară de petabyți, care este folosit de zeci de mii de clienți pentru a procesa exaocteți de date în fiecare zi pentru a-și alimenta volumul de lucru de analiză. Puteți să vă structurați datele, să măsurați procesele de afaceri și să obțineți rapid informații valoroase, folosind un model dimensional. Amazon Redshift oferă funcții încorporate pentru a accelera procesul de modelare, orchestrare și raportare dintr-un model dimensional.
În această postare, discutăm despre cum să implementăm un model dimensional, în special Metodologia Kimball. Discutăm despre implementarea dimensiunilor și faptelor în Amazon Redshift. Arătăm cum să efectuăm extragerea, transformarea și încărcarea (ELT), un proces de integrare axat pe obținerea datelor brute dintr-un lac de date într-un strat de staging pentru a realiza modelarea. În general, postarea vă va oferi o înțelegere clară a modului de utilizare a modelării dimensionale în Amazon Redshift.
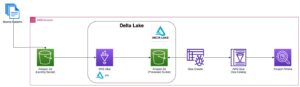
Prezentare generală a soluțiilor
Următoarea diagramă ilustrează arhitectura soluției.

În secțiunile următoare, discutăm și demonstrăm mai întâi aspectele cheie ale modelului dimensional. După aceea, creăm un data mart folosind Amazon Redshift cu un model de date dimensionale care include tabele de dimensiuni și de fapte. Datele sunt încărcate și puse în scenă folosind COPIE comanda, datele din dimensiuni sunt încărcate folosind MERGE afirmația și faptele vor fi asociate cu dimensiunile din care sunt derivate perspectivele. Programăm încărcarea dimensiunilor și faptelor folosind Editorul de interogări Amazon Redshift V2. În cele din urmă, folosim Amazon QuickSight pentru a obține informații despre datele modelate sub forma unui tablou de bord QuickSight.
Pentru această soluție, folosim un set de date eșantion (normalizat) furnizat de Amazon Redshift pentru vânzarea biletelor la eveniment. Pentru această postare, am restrâns setul de date din motive de simplitate și demonstrație. Următoarele tabele prezintă exemple de date pentru vânzările de bilete și locații.


Potrivit Metodologia modelării dimensionale Kimball, există patru pași cheie în proiectarea unui model dimensional:
- Identificați procesul de afaceri.
- Declarați granulația datelor dvs.
- Identificați și implementați dimensiunile.
- Identificați și implementați faptele.
În plus, adăugăm un al cincilea pas în scop demonstrativ, care este raportarea și analizarea evenimentelor de afaceri.
Cerințe preliminare
Pentru această prezentare generală, ar trebui să aveți următoarele condiții prealabile:
Identificați procesul de afaceri
În termeni simpli, identificarea procesului de afaceri înseamnă identificarea unui eveniment măsurabil care generează date în cadrul unei organizații. De obicei, companiile au un fel de sistem sursă operațional care își generează datele în format brut. Acesta este un bun punct de plecare pentru a identifica diverse surse pentru un proces de afaceri.
Procesul de afaceri este apoi continuat ca a date mart sub formă de dimensiuni și fapte. Privind la setul nostru de date eșantionul menționat mai devreme, putem vedea clar că procesul de afaceri este vânzările realizate pentru un anumit eveniment.
O greșeală comună făcută este utilizarea departamentelor unei companii ca proces de afaceri. Datele (procesul de afaceri) trebuie să fie integrate în diferite departamente, în acest caz, marketingul poate accesa datele de vânzări. Identificarea procesului corect de afaceri este esențială - greșirea acestui pas poate avea un impact asupra întregului data mart (poate duce la duplicarea cerealelor și la valori incorecte în rapoartele finale).
Declarați granulația datelor dvs
Declararea cerealelor este actul de identificare unică a unei înregistrări în sursa dvs. de date. Cereale este folosită în tabelul de fapte pentru a măsura cu precizie datele și pentru a vă permite să rulați mai departe. În exemplul nostru, acesta ar putea fi un element rând în procesul de afaceri de vânzări.
În cazul nostru de utilizare, o vânzare poate fi identificată în mod unic analizând momentul tranzacției când a avut loc vânzarea; acesta va fi nivelul cel mai atomic.

Identificați și implementați dimensiunile
Tabelul de dimensiuni descrie tabelul de fapte și atributele acestuia. Când identificați contextul descriptiv al procesului dvs. de afaceri, stocați textul într-un tabel separat, ținând cont de granul tabelului de fapte. Când conectați tabelul de dimensiuni la tabelul de fapte, ar trebui să existe doar un singur rând asociat tabelului de fapte. În exemplul nostru, folosim următorul tabel pentru a fi separat într-un tabel de dimensiuni; aceste câmpuri descriu faptele pe care le vom măsura.
Când proiectați structura modelului dimensional (schema), puteți fie să creați o stea or fulg de nea schemă. Structura ar trebui să se alinieze îndeaproape cu procesul de afaceri; prin urmare, o schemă în stea este cea mai potrivită pentru exemplul nostru. Următoarea figură arată diagrama noastră de relații între entități (ERD).

În secțiunile următoare, detaliem pașii pentru implementarea dimensiunilor.
Stadiază datele sursă
Înainte de a putea crea și încărca tabelul de dimensiuni, avem nevoie de date sursă. Prin urmare, punem datele sursă într-un tabel temporar sau temporar. Aceasta este adesea denumită strat de punere în scenă, care este copia brută a datelor sursă. Pentru a face acest lucru în Amazon Redshift, folosim Comanda COPIE pentru a încărca datele din compartimentul public S3 de modelare dimensională-în-amazon-redshift situat pe us-east-1 Regiune. Rețineți că comanda COPY folosește un Gestionarea identității și accesului AWS (IAM) rol cu acces la Amazon S3. Rolul trebuie să fie asociat cu clusterul. Parcurgeți următorii pași pentru a pune în scenă datele sursă:
- Creați
venuetabel sursă:
- Încărcați datele locației:
- Creați
salestabel sursă:
- Încărcați datele sursei de vânzări:
- Creați
calendarmasa:
- Încărcați datele din calendar:
Creați tabelul de dimensiuni
Proiectarea tabelului de dimensiuni poate depinde de cerințele dvs. de afaceri – de exemplu, trebuie să urmăriți modificările date în timp? Sunt șapte tipuri de dimensiuni diferite. Pentru exemplul nostru, folosim Tipul 1 pentru că nu trebuie să urmărim schimbările istorice. Pentru mai multe despre tipul 2, consultați Simplificați încărcarea datelor în dimensiunile de tip 2 care se schimbă lent în Amazon Redshift. Tabelul de dimensiuni va fi denormalizat cu o cheie primară, o cheie surogat și câteva câmpuri adăugate pentru a indica modificările aduse tabelului. Vezi următorul cod:
Câteva note despre crearea tabelului de dimensiuni:
- Numele câmpurilor sunt transformate în nume prietenoase pentru afaceri
- Cheia noastră principală este
VenueID, pe care îl folosim pentru a identifica în mod unic un loc în care a avut loc vânzarea - Vor fi adăugate două rânduri suplimentare, indicând când a fost inserată și actualizată o înregistrare (pentru a urmări modificările)
- Folosim un Stilul de distributie AUTO pentru a acorda Amazon Redshift responsabilitatea de a alege și ajusta stilul de distribuție
Un alt factor important de luat în considerare în modelarea dimensională este utilizarea chei surogat. Cheile surogat sunt chei artificiale care sunt utilizate în modelarea dimensională pentru a identifica în mod unic fiecare înregistrare dintr-un tabel de dimensiuni. Acestea sunt de obicei generate ca un întreg secvenţial și nu au nicio semnificaţie în domeniul afacerii. Ele oferă mai multe beneficii, cum ar fi asigurarea unicității și îmbunătățirea performanței în îmbinări, deoarece sunt de obicei mai mici decât cheile naturale și, ca chei surogat, nu se schimbă în timp. Acest lucru ne permite să fim consecvenți și să unim fapte și dimensiuni mai ușor.
În Amazon Redshift, cheile surogat sunt create de obicei folosind cuvântul cheie IDENTITY. De exemplu, instrucțiunea CREATE anterioară creează un tabel de dimensiuni cu a VenueSkey cheie surogat. The VenueSkey coloana este completată automat cu valori unice pe măsură ce noi rânduri sunt adăugate în tabel. Această coloană poate fi apoi utilizată pentru a alătura tabelul locației la FactSaleTransactions tabel.
Câteva sfaturi pentru proiectarea cheilor surogat:
- Utilizați un tip de date mic, cu lățime fixă pentru cheia surogat. Acest lucru va îmbunătăți performanța și va reduce spațiul de stocare.
- Utilizați cuvântul cheie IDENTITY sau generați cheia surogat folosind o valoare secvenţială sau GUID. Acest lucru va asigura că cheia surogat este unică și nu poate fi schimbată.
Încărcați tabelul dim folosind MERGE
Există numeroase moduri de a vă încărca masa slabă. Trebuie luați în considerare anumiți factori, de exemplu, performanța, volumul de date și, probabil, timpii de încărcare SLA. Cu MERGE declarație, efectuăm un upsert fără a fi nevoie să specificăm mai multe comenzi de inserare și actualizare. Puteți configura MERGE declarație în a procedură stocată pentru a popula datele. Apoi programați procedura stocată să ruleze programatic prin intermediul editorului de interogări, pe care îl demonstrăm mai târziu în postare. Următorul cod creează o procedură stocată numită SalesMart.DimVenueLoad:
Câteva note despre încărcarea dimensiunilor:
- Când o înregistrare este inserată pentru prima dată, data inserată și data actualizată vor fi populate. Când orice valoare se modifică, datele sunt actualizate, iar data actualizată reflectă data la care a fost modificată. Data introdusă rămâne.
- Deoarece datele vor fi folosite de utilizatorii de afaceri, trebuie să înlocuim valorile NULL, dacă există, cu valori mai adecvate pentru afaceri.
Identificați și implementați faptele
Acum că am declarat că cerealele noastre sunt evenimentul unei vânzări care a avut loc la un moment dat, tabelul nostru de fapte va stoca datele numerice pentru procesul nostru de afaceri.
Am identificat următoarele fapte numerice de măsurat:
- Cantitatea de bilete vândute pe vânzare
- Comision pentru vânzare
Implementarea faptului
Sunt trei tipuri de tabele de fapte (tabel de fapte de tranzacție, tabel de fapte instantanee periodice și tabel de fapte de instantanee de acumulare). Fiecare oferă o viziune diferită asupra procesului de afaceri. Pentru exemplul nostru, folosim un tabel de fapte de tranzacție. Parcurgeți următorii pași:
- Creați tabelul de fapte
Se adaugă o dată inserată cu o valoare implicită, indicând dacă și când a fost încărcată o înregistrare. Puteți utiliza acest lucru atunci când reîncărcați tabelul de fapte pentru a elimina datele deja încărcate pentru a evita duplicarea.
Încărcarea tabelului de fapte constă într-o instrucțiune simplă de inserare care unește dimensiunile asociate. Ne alăturăm din DimVenue tabelul care a fost creat, care descrie faptele noastre. Este cea mai bună practică, dar opțional data calendaristică dimensiuni, care permit utilizatorului final să navigheze în tabelul de fapte. Datele pot fi fie încărcate atunci când există o nouă vânzare, fie zilnic; aici este utilă data introdusă sau data încărcării.
Încărcăm tabelul de fapte folosind o procedură stocată și folosim un parametru de dată.
- Creați procedura stocată cu următorul cod. Pentru a păstra aceeași integritate a datelor pe care am aplicat-o în încărcarea dimensiunii, înlocuim valorile NULL, dacă există, cu valori mai adecvate pentru afaceri:
- Încărcați datele apelând procedura cu următoarea comandă:
Programați încărcarea datelor
Acum putem automatiza procesul de modelare prin programarea procedurilor stocate în Amazon Redshift Query Editor V2. Parcurgeți următorii pași:
- Mai întâi numim sarcina de dimensiune și după ce încărcarea de dimensiune rulează cu succes, începe încărcarea de fapt:
Dacă sarcina de dimensiune eșuează, încărcarea de fapt nu va rula. Acest lucru asigură coerența datelor deoarece nu dorim să încărcăm tabelul de fapte cu dimensiuni învechite.
- Pentru a programa încărcarea, alegeți Program în Editorul de interogări V2.

- Programăm interogarea să ruleze în fiecare zi la ora 5:00 AM.
- Opțional, puteți adăuga notificări de eșec activând Serviciul de notificare simplă Amazon notificări (Amazon SNS).

Raportați și analizați datele în Amazon Quicksight
QuickSight este un serviciu de business intelligence care facilitează furnizarea de informații. Ca serviciu complet gestionat, QuickSight vă permite să creați și să publicați cu ușurință tablouri de bord interactive care pot fi apoi accesate de pe orice dispozitiv și încorporate în aplicațiile, portalurile și site-urile dvs. web.
Ne folosim data mart pentru a prezenta vizual faptele sub forma unui tablou de bord. Pentru a începe și a configura QuickSight, consultați Crearea unui set de date folosind o bază de date care nu este descoperită automat.
După ce vă creați sursa de date în QuickSight, unim datele modelate (data mart) împreună pe baza cheii noastre surogat skey. Folosim acest set de date pentru a vizualiza data mart.

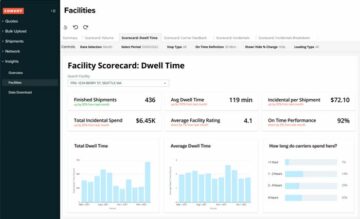
Tabloul nostru de bord final va conține informații despre data mart și va răspunde la întrebări critice de afaceri, cum ar fi comisionul total pe locație și datele cu cele mai mari vânzări. Următoarea captură de ecran arată produsul final al data mart-ului.

A curăța
Pentru a evita costurile viitoare, ștergeți toate resursele pe care le-ați creat ca parte a acestei postări.
Concluzie
Acum am implementat cu succes un data mart folosind sistemul nostru DimVenue, DimCalendar, și FactSaleTransactions Mese. Depozitul nostru nu este complet; pe măsură ce putem extinde data mart cu mai multe fapte și putem implementa mai multe magazine și pe măsură ce procesul de afaceri și cerințele cresc în timp, la fel va crește și depozitul de date. În această postare, am oferit o viziune completă despre înțelegerea și implementarea modelării dimensionale în Amazon Redshift.
Începeți cu dvs Amazon RedShift model dimensional astăzi.
Despre Autori
 Bernard Verster este un inginer cloud cu experiență, cu ani de experiență în crearea de modele de date scalabile și eficiente, definirea strategiilor de integrare a datelor și asigurarea guvernanței și securității datelor. Este pasionat de utilizarea datelor pentru a genera perspective, aliniindu-se în același timp la cerințele și obiectivele de afaceri.
Bernard Verster este un inginer cloud cu experiență, cu ani de experiență în crearea de modele de date scalabile și eficiente, definirea strategiilor de integrare a datelor și asigurarea guvernanței și securității datelor. Este pasionat de utilizarea datelor pentru a genera perspective, aliniindu-se în același timp la cerințele și obiectivele de afaceri.
 Abhishek Pan este un specialist WWSO SA-Analytics care lucrează cu clienții din sectorul public AWS India. El interacționează cu clienții pentru a defini o strategie bazată pe date, pentru a oferi sesiuni de scufundare profundă asupra cazurilor de utilizare a analizei și pentru a proiecta aplicații analitice scalabile și performante. Are 12 ani de experiență și este pasionat de baze de date, analiză și AI/ML. Este un călător pasionat și încearcă să surprindă lumea prin obiectivul camerei sale.
Abhishek Pan este un specialist WWSO SA-Analytics care lucrează cu clienții din sectorul public AWS India. El interacționează cu clienții pentru a defini o strategie bazată pe date, pentru a oferi sesiuni de scufundare profundă asupra cazurilor de utilizare a analizei și pentru a proiecta aplicații analitice scalabile și performante. Are 12 ani de experiență și este pasionat de baze de date, analiză și AI/ML. Este un călător pasionat și încearcă să surprindă lumea prin obiectivul camerei sale.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. Automobile/VE-uri, carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- BlockOffsets. Modernizarea proprietății de compensare a mediului. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :are
- :este
- :nu
- :Unde
- $UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Despre Noi
- accelera
- acces
- accesate
- precis
- peste
- act
- adăuga
- adăugat
- Suplimentar
- După
- AI / ML
- alinia
- alinierea
- permite
- permite
- deja
- am
- Amazon
- Amazon Web Services
- an
- analiză
- Analitic
- Google Analytics
- analiza
- și
- răspunde
- Orice
- aplicatii
- aplicat
- adecvat
- arhitectură
- SUNT
- artificial
- AS
- aspecte
- asociate
- At
- atribute
- Auto
- automatizarea
- în mod automat
- evita
- AWS
- b
- bazat
- BE
- deoarece
- începe
- Beneficiile
- CEL MAI BUN
- construit-in
- afaceri
- business intelligence
- Procesul de afaceri
- procesele de afaceri
- dar
- by
- Calendar
- apel
- denumit
- apel
- aparat foto
- CAN
- captura
- caz
- cazuri
- Provoca
- sigur
- Schimbare
- si-a schimbat hainele;
- Modificări
- schimbarea
- caracter
- taxe
- Alege
- clar
- clar
- îndeaproape
- Cloud
- cod
- Coloană
- vine
- comision
- Comun
- Companii
- companie
- Completă
- Lua în considerare
- consistent
- constă
- context
- corecta
- ar putea
- crea
- a creat
- creează
- Crearea
- creaţie
- critic
- clienţii care
- zilnic
- tablou de bord
- tablouri de bord
- de date
- integrarea datelor
- Lacul de date
- depozit de date
- Pe bază de date
- Strategie bazată pe date
- Baza de date
- baze de date
- Data
- Date
- datetime
- zi
- adânc
- scufundare adâncă
- Mod implicit
- definire
- livra
- demonstra
- departamente
- Derivat
- descrie
- Amenajări
- proiect
- detaliu
- dispozitiv
- diferit
- Dimensiune
- Dimensiuni
- discuta
- distinct
- distribuire
- do
- domeniu
- făcut
- Dont
- jos
- conduce
- duplicate
- fiecare
- Mai devreme
- cu ușurință
- uşor
- editor
- eficient
- oricare
- încorporat
- permite
- permițând
- capăt
- un capăt la altul
- se angajează
- inginer
- asigura
- asigură
- asigurare
- Întreg
- entitate
- Eter (ETH)
- eveniment
- evenimente
- Fiecare
- in fiecare zi
- exemplu
- exemple
- Extinde
- experienţă
- cu experienţă
- Expunere
- extrage
- fapt
- factor
- factori
- fapte
- eșuează
- Eșec
- DESCRIERE
- puțini
- camp
- Domenii
- a cincea
- Figura
- filtru
- final
- First
- prima dată
- potrivi
- concentrat
- următor
- Pentru
- formă
- format
- patru
- din
- complet
- mai mult
- viitor
- Câştig
- genera
- generată
- generează
- obține
- obtinerea
- Da
- dat
- bine
- guvernare
- Crește
- la indemana
- Avea
- he
- cea mai mare
- lui
- istoric
- Vacanță
- Cum
- Cum Pentru a
- HTML
- http
- HTTPS
- IAM
- identificat
- identifica
- identificarea
- Identitate
- if
- ilustrează
- Impactul
- punerea în aplicare a
- implementat
- Punere în aplicare a
- important
- îmbunătăţi
- îmbunătățirea
- in
- Inclusiv
- India
- indica
- indicând
- info
- perspective
- integrate
- integrare
- integritate
- Inteligență
- interactiv
- în
- IT
- ESTE
- alătura
- alăturat
- aderarea
- Se alătură
- jpg
- A pastra
- păstrare
- Cheie
- chei
- lac
- limbă
- mai tarziu
- Ultimele
- strat
- stânga
- Obiectiv
- Permite
- Nivel
- Linie
- încărca
- încărcare
- loturile
- situat
- cautati
- făcut
- FACE
- gestionate
- Marketing
- potrivire
- sens
- măsura
- menționat
- Îmbina
- Metrici
- minte
- greşeală
- model
- modelare
- modelare
- Modele
- Lună
- mai mult
- cele mai multe
- multiplu
- nume
- Natural
- Navigaţi
- Nevoie
- au nevoie
- nevoilor
- Nou
- notițe
- notificare
- notificări
- acum
- numeroși
- Obiectivele
- of
- oferi
- de multe ori
- on
- afară
- operațional
- or
- organizație
- al nostru
- peste
- global
- parametru
- parte
- pasionat
- pentru
- efectua
- performanță
- poate
- periodic
- Loc
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- populat
- Post
- putere
- practică
- premise
- prezenta
- primar
- procedură
- Proceduri
- proces
- procese
- Produs
- furniza
- prevăzut
- furnizează
- public
- publica
- scopuri
- Întrebări
- repede
- ridica
- Crud
- date neprelucrate
- record
- înregistrări
- reduce
- menționat
- reflectă
- regiune
- relaţie
- rămășițe
- scoate
- înlocui
- raportează
- Raportarea
- Rapoarte
- Cerinţe
- Resurse
- responsabilitate
- Rol
- sul
- RÂND
- Alerga
- ruleaza
- sare
- de vânzări
- acelaşi
- Exemplu de set de date
- scalabil
- programa
- programare
- secțiuni
- sector
- securitate
- vedea
- distinct
- servește
- serviciu
- Servicii
- Sesiunile
- set
- câteva
- să
- Arăta
- Emisiuni
- simplu
- simplitate
- singur
- Încet
- mic
- mai mici
- Instantaneu
- So
- vândut
- soluţie
- unele
- Sursă
- Surse
- Spaţiu
- specialist
- specific
- specific
- Etapă
- înscenare
- Stea
- început
- Pornire
- Declarație
- Pas
- paşi
- depozitare
- stoca
- stocate
- strategii
- Strategie
- structura
- de succes
- Reușit
- astfel de
- sistem
- tabel
- temporar
- zeci
- termeni
- decât
- acea
- Sursa
- lumea
- lor
- apoi
- Acolo.
- prin urmare
- Acestea
- ei
- acest
- mii
- Prin
- bilet
- vânzări de bilete
- bilete
- timp
- ori
- timestamp-ul
- Sfaturi
- la
- astăzi
- împreună
- a luat
- Total
- urmări
- tranzacție
- Transforma
- transformat
- călător
- tip
- Tipuri
- tipic
- înţelegere
- unic
- unic
- unicitate
- necunoscut
- Actualizează
- actualizat
- us
- Folosire
- utilizare
- carcasa de utilizare
- utilizat
- utilizatorii
- utilizări
- folosind
- obișnuit
- Valoros
- valoare
- Valori
- diverse
- Locatia evenimentului
- locuri
- de
- Vizualizare
- volum
- walkthrough
- vrea
- Depozit
- a fost
- modalități de
- we
- web
- servicii web
- site-uri web
- săptămână
- cand
- care
- în timp ce
- voi
- cu
- în
- fără
- de lucru
- lume
- Greșit
- an
- ani
- tu
- Ta
- zephyrnet