Aceasta este o postare pentru invitați scrisă împreună cu Raghu Boppanna de la Vanguard.
At Avangardă, linia de afaceri Enterprise Advice îmbunătățește rezultatele investitorilor prin acces digital la sfaturi financiare superioare, personalizate și accesibile. Ei au făcut acest lucru posibil, parțial, prin generarea de economii de scară pe tot globul pentru investitorii cu o platformă tehnică foarte rezistentă și eficientă. Vanguard a optat pentru o arhitectură cu mai multe regiuni pentru acest volum de lucru pentru a ajuta la protejarea împotriva deficiențelor serviciilor regionale. În scopuri de înaltă disponibilitate, este nevoie de a face datele utilizate de volumul de lucru disponibile nu doar în regiunea primară, ci și în regiunea secundară, cu un decalaj minim de replicare. În cazul unei deteriorări a serviciului în Regiunea primară, soluția ar trebui să poată trece la nivelul Regiunii secundare, cu o pierdere cât mai mică de date și cu capacitatea de a relua absorbția de date.
Vanguard Cloud Technology Office și AWS s-au asociat pentru a construi o soluție de infrastructură pe AWS care să îndeplinească cerințele lor de reziliență. Soluția multi-regiune permite un mecanism robust de fail-over, cu observabilitate și recuperare încorporate. Soluția acceptă, de asemenea, transmiterea de date din mai multe surse către diferite fluxuri de date Kinesis. Soluția este în prezent în curs de desfășurare în diferitele linii de echipe de afaceri pentru a îmbunătăți postura de rezistență a sarcinilor lor de lucru.
Cazul de utilizare discutat aici necesită Change Data Capture (CDC) pentru a transmite date de la o sursă de date la distanță (mainframe DB2) către Fluxuri de date Amazon Kinesis, deoarece capacitatea de afaceri depinde de aceste date. Kinesis Data Streams este un serviciu de streaming complet gestionat, masiv scalabil, durabil și cu costuri reduse, care poate capta și transmite continuu cantități mari de date din mai multe surse și face datele disponibile pentru consum în câteva milisecunde. Serviciul este construit pentru a fi foarte rezistent și utilizează mai multe zone de disponibilitate pentru a procesa și stoca date.
Soluția discutată în această postare explică modul în care AWS și Vanguard au inovat pentru a construi o arhitectură rezistentă pentru a-și îndeplini obiectivele de înaltă disponibilitate.
Prezentare generală a soluțiilor
Soluția folosește AWS Lambdas pentru a replica datele din fluxurile de date Kinesis din regiunea primară într-o regiune secundară. În cazul oricărei deteriorări ale serviciului care afectează conducta CDC, procesul de failover promovează regiunea secundară la primară pentru producători și consumatori. Folosim Tabelele globale Amazon DynamoDB pentru punctele de control de replicare care permite reluarea fluxului de date de la punctul de control și, de asemenea, menține un flag de configurare a regiunii primar care împiedică o buclă infinită de replicare a acelorași date înainte și înapoi.
Soluția oferă, de asemenea, flexibilitatea consumatorilor Kinesis Data Streams de a utiliza regiunea principală sau orice regiune secundară în cadrul aceluiași cont AWS.
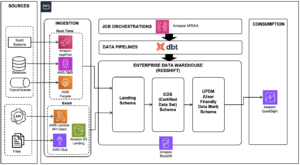
Următoarea diagramă ilustrează arhitectura de referință.
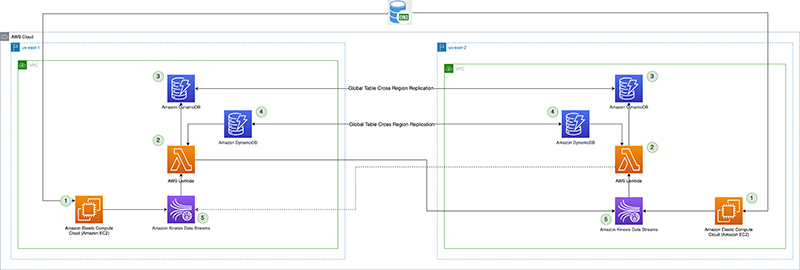
Să ne uităm la fiecare componentă în detaliu:
- procesor CDC (producător) – În această arhitectură de referință, producătorul este implementat Cloud Elastic de calcul Amazon (Amazon EC2) atât în regiunea principală, cât și în cea secundară și este activă în regiunea principală și în modul de așteptare în regiunea secundară. Captează date CDC din sursa externă de date (cum ar fi o bază de date DB2, așa cum se arată în arhitectura de mai sus) și transmite fluxuri către Kinesis Data Streams din regiunea principală. Vanguard folosește un 3rd instrumentul de partid Qlik Replicate ca procesor CDC. Produce o sarcină utilă bine formată, inclusiv marcajul de timp de comitere DB2 în fluxul de date Kinesis, în plus față de datele de rând reale de la sursa de date la distanță. (
example-stream-1în acest exemplu). Următorul cod este un exemplu de încărcare utilă care conține doar cheia principală a înregistrării care s-a modificat și marcajul de timp al comenzii (pentru simplitate, restul datelor din rândurile tabelului nu sunt afișate mai jos):{ "eventSource": "aws:kinesis", "kinesis": { "ApproximateArrivalTimestamp": "Mon July 18 20:00:00 UTC 2022", "SequenceNumber": "49544985256907370027570885864065577703022652638596431874", "PartitionKey": "12349999", "KinesisSchemaVersion": "1.0", "Data": "eyJLZXkiOiAxMjM0OTk5OSwiQ29tbWl0VGltZXN0YW1wIjogIjIwMjItMDctMThUMjA6MDA6MDAifQ==" }, "eventId": "shardId-000000000000:49629136582982516722891309362785181370337771525377097730", "invokeIdentityArn": "arn:aws:iam::6243876582:role/kds-crr-LambdaRole-1GZWP67437SD", "eventName": "aws:kinesis:record", "eventVersion": "1.0", "eventSourceARN": "arn:aws:kinesis:us-east-1:6243876582:stream/kds-stream-1/consumer/kds-crr:6243876582", "awsRegion": "us-east-1" }Valoarea decodificată Base64 a
Dataeste după cum urmează. Înregistrarea Kinesis reală ar conține datele întregii rânduri ale rândului tabelului care s-a modificat, în plus față de cheia primară și marcajul de timp al comenzii.{"Key": 12349999,"CommitTimestamp": "2022-07-18T20:00:00"}CommitTimestampînDatacâmpul este utilizat în punctul de control al replicarii și este esențial pentru a urmări cu exactitate cât de mult din datele fluxului au fost replicate în regiunea secundară. Punctul de control poate fi apoi utilizat pentru a facilita failover-ul unui procesor CDC (producător) și pentru a relua cu exactitate producerea datelor de la marcajul de timp al punctului de control al replicarii în continuare.Alternativa la utilizarea unei surse de date la distanță
CommitTimestamp(dacă nu este disponibil) este să utilizațiApproximateArrivalTimestamp(care este marcajul de timp când înregistrarea este de fapt scrisă în fluxul de date). - Funcția Lambda de replicare între regiuni – Funcția este implementată atât în regiunile primare, cât și în cele secundare. Este configurat cu o mapare a sursei de evenimente la fluxul de date care conține date CDC. Aceeași funcție poate fi utilizată pentru a replica datele mai multor fluxuri. Este invocat cu un lot de înregistrări din Kinesis Data Streams și replic lotul într-o regiune de replicare țintă (care este furnizată prin mediul de configurare Lambda). Pentru considerente de cost, dacă datele CDC sunt produse în mod activ doar în Regiunea primară, concurența rezervată a funcției în Regiunea secundară poate fi setată la zero și modificată în timpul transferului regional la failover. Funcția are Gestionarea identității și accesului AWS (IAM) permisiuni pentru a face următoarele:
- Citiți și scrieți în tabelele globale DynamoDB utilizate în această soluție, în cadrul aceluiași cont.
- Citiți și scrieți în Kinesis Data Streams în ambele regiuni în cadrul aceluiași cont.
- Publicați valori personalizate în Amazon CloudWatch în ambele regiuni în cadrul aceluiași cont.
- Punct de control pentru replicare – Punctul de control de replicare utilizează tabelul global DynamoDB atât în regiunea primară, cât și în cea secundară. Este folosit de funcția Lambda de replicare pe mai multe regiuni pentru a persista marcajul de timp al ultimei înregistrări de replicare ca punct de control al replicarii pentru fiecare flux care este configurat pentru replicare. Pentru această postare, creăm și folosim un tabel global numit
kdsReplicationCheckpoint. - Configurare regiune activă – Regiunea activă utilizează tabelul global DynamoDB atât în Regiunea primară, cât și în cea secundară. Utilizează capacitatea nativă de replicare între regiuni a tabelului global pentru a replica configurația. Este pre-populat cu date despre care este regiunea principală pentru un flux, pentru a preveni replicarea înapoi în regiunea principală de către funcția Lambda din regiunea de așteptare. Această configurație poate să nu fie necesară dacă funcția Lambda din Regiunea de așteptare are o concurență rezervată setată la zero, dar poate servi ca o verificare de siguranță pentru a evita bucla infinită de replicare a datelor. Pentru această postare, creăm un tabel global numit
kdsActiveRegionConfigși puneți un articol cu următoarele date:{ "stream-name": "example-stream-1", "active-region" : "us-east-1" } - Fluxuri de date Kinesis – Fluxul către care procesorul CDC produce datele. Pentru această postare, folosim un flux numit
example-stream-1în ambele regiuni, cu aceeași configurație de shard și politici de acces.
Secvența pașilor în replicarea între regiuni
Să ne uităm pe scurt la modul în care este exercitată arhitectura folosind următoarea diagramă de secvență.

Secvența constă din pașii următori:
- Procesorul CDC (în
us-east-1) citește datele CDC de la sursa de date la distanță. - Procesorul CDC (în
us-east-1) transmite datele CDC către Kinesis Data Streams (înus-east-1). - Funcția Lambda de replicare între regiuni (în us-east-1) consumă datele din fluxul de date (în
us-east-1). Modelul de fan-out îmbunătățit este recomandat pentru un randament dedicat și crescut pentru replicarea pe mai multe regiuni. - Funcția Lambda replicator (în
us-east-1) își validează Regiunea curentă cu configurația Regiune activă pentru fluxul care se consumă, cu ajutorulkdsActiveRegionConfigTabel global DynamoDB Următorul cod exemplu (în Java) poate ajuta la ilustrarea condiției care este evaluată:// Fetch the current AWS Region from the Lambda function’s environment String currentAWSRegion = System.getenv(“AWS_REGION”); // Read the stream name from the first Kinesis Record once for the entire batch being processed. This is done because we are reusing the same Lambda function for replicating multiple streams. String currentStreamNameConsumed = kinesisRecord.getEventSourceARN().split(“:”)[5].split(“/”)[1]; // Build the DynamoDB query condition using the stream name Map<String, Condition> keyConditions = singletonMap(“streamName”, Condition.builder().comparisonOperator(EQ).attributeValueList(AttributeValue.builder().s(currentStreamNameConsumed).build()).build()); // Query the DynamoDB Global Table QueryResponse queryResponse = ddbClient.query(QueryRequest.builder().tableName("kdsActiveRegionConfig").keyConditions(keyConditions).attributesToGet(“ActiveRegion”).build()); - Funcția evaluează răspunsul de la DynamoDB cu următorul cod:
// Evaluate the response if (queryResponse.hasItems()) { AttributeValue activeRegionForStream = queryResponse.items().get(0).get(“ActiveRegion”); return currentAWSRegion.equalsIgnoreCase(activeRegionForStream.s()); } - În funcție de răspuns, funcția efectuează următoarele acțiuni:
- Dacă răspunsul este
true, funcția de replicare produce înregistrările către Kinesis Data Streams înus-east-2într-o manieră secvenţială.- Dacă există o eroare, numărul de secvență al înregistrării este urmărit și iterația este întreruptă. Funcția returnează lista numerelor de secvență nereușite. Prin returnarea numărului de secvență eșuat, soluția folosește caracteristica de Punct de control lambda pentru a putea relua procesarea unui lot de înregistrări cu erori parțiale. Acest lucru este util atunci când se gestionează orice defecțiuni ale serviciului, în care funcția încearcă să reproducă datele în regiuni pentru a asigura paritatea fluxului și nicio pierdere de date.
- Dacă nu există erori, este returnată o listă goală, care indică faptul că lotul a avut succes.
- Dacă răspunsul este
false, funcția de replicator revine fără a efectua nicio replicare. Pentru a reduce costul invocărilor Lambda, puteți seta concurența rezervată a funcției în Regiunea DR (us-east-2) la zero. Acest lucru va împiedica invocarea funcției. Când treceți la failover, puteți actualiza această valoare la un număr corespunzător pe baza debitului CDC și puteți seta concurența rezervată a funcției înus-east-1la zero pentru a preveni executarea inutil.
- Dacă răspunsul este
- După ce toate înregistrările sunt produse în Kinesis Data Streams în
us-east-2, funcția replicator face puncte de control cătrekdsReplicationCheckpointTabel global DynamoDB (înus-east-1) cu următoarele date:{ "streamName": "example-stream-1", "lastReplicatedTimestamp": "2022-07-18T20:00:00" } - Funcția revine după procesarea cu succes a lotului de înregistrări.
Considerații privind performanța
Așteptările de performanță ale soluției trebuie înțelese în raport cu următorii factori:
- Selectarea regiunii – Latența de replicare este direct proporțională cu distanța parcursă de date, așa că înțelegeți selectarea Regiunii
- Viteză – Viteza de intrare a datelor sau volumul de date care sunt replicate
- Dimensiunea sarcinii utile – Mărimea încărcăturii utile care este replicată
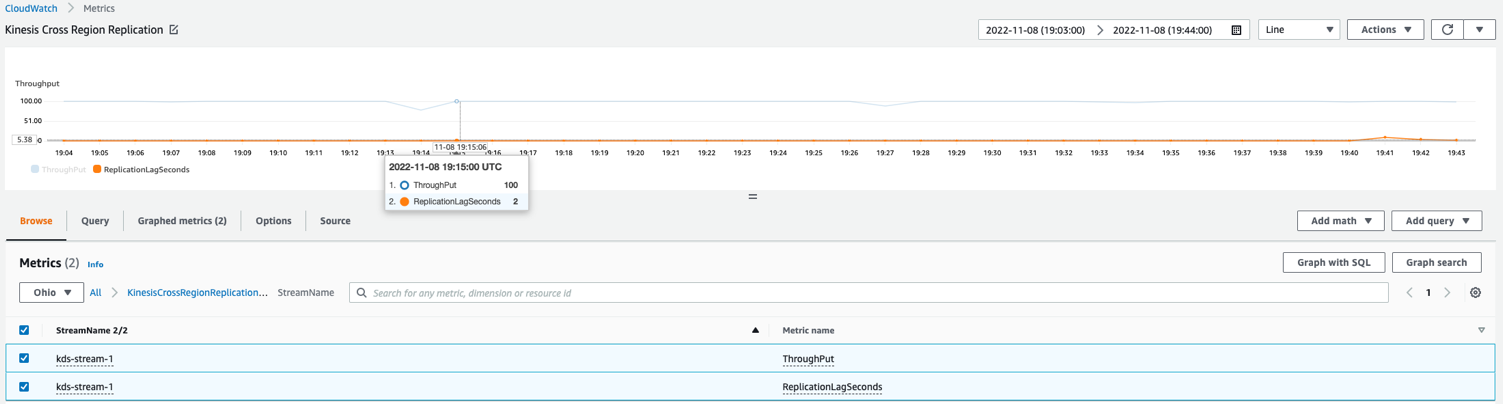
Monitorizați replicarea între regiuni
Se recomandă să urmăriți și să observați replicarea pe măsură ce se întâmplă. Puteți personaliza funcția Lambda pentru a publica valori personalizate pe CloudWatch cu următoarele valori la sfârșitul fiecărei invocări. Publicarea acestor valori atât în regiunea principală, cât și în cea secundară vă ajută să vă protejați de deficiențe care afectează observabilitatea în regiunea principală.
- tranzitată – Mărimea actuală a lotului de invocare Lambda
- ReplicationLagSeconds – Diferența dintre marcajul de timp actual (după procesarea tuturor înregistrărilor) și
ApproximateArrivalTimestampdin ultima înregistrare care a fost replicată
Următorul exemplu de grafic al valorii CloudWatch arată că întârzierea medie a replicării a fost de 2 secunde cu un debit de 100 de înregistrări replicate de la us-east-1 la us-east-2.
Strategie comună de failover
În timpul oricăror deteriorări care afectează conducta CDC în regiunea principală, nevoile de continuitate a afacerii sau de recuperare în caz de dezastru pot dicta o transferare a conductei în regiunea secundară (în așteptare). Aceasta înseamnă că trebuie făcute câteva lucruri ca parte a acestui proces de failover:
- Dacă este posibil, opriți toate sarcinile CDC din instrumentul procesor CDC în
us-east-1. - Procesorul CDC trebuie să fie transferat la regiunea secundară, astfel încât să poată citi datele CDC de la sursa de date la distanță în timp ce funcționează în afara regiunii de așteptare.
-
kdsActiveRegionConfigTabelul global DynamoDB trebuie actualizat. De exemplu, pentru fluxexample-stream-1folosit în exemplul nostru, Regiunea activă este schimbată înus-east-2:
{ "stream-name": "example-stream-1", "active-Region" : "us-east-2"
}- Toate punctele de control ale fluxului trebuie citite din
kdsReplicationCheckpointTabel global DynamoDB (înus-east-2), iar marcajele de timp de la fiecare dintre punctele de control sunt folosite pentru a începe sarcinile CDC în instrumentul de producție înus-east-2Regiune. Acest lucru minimizează șansele de pierdere a datelor și reia cu acuratețe transmiterea datelor CDC de la sursa de date la distanță de la marcajul de timp al punctului de control. - Dacă utilizați concurența rezervată pentru a controla invocările Lambda, setați valoarea la zero în regiunea principală (
us-east-1) și la o valoare adecvată diferită de zero în regiunea secundară (us-east-2).
Strategia de failover în mai mulți pași a Vanguard
Unele dintre instrumentele terțe pe care le utilizează Vanguard au un proces CDC în doi pași de transmitere a datelor de la o sursă de date de la distanță la o destinație. Instrumentul ales de Vanguard pentru procesorul CDC urmează această abordare în doi pași:
- Primul pas implică configurarea unei sarcini de flux de jurnal care citește datele din sursa de date de la distanță și persistă într-o locație de transfer.
- Al doilea pas implică configurarea sarcinilor individuale ale consumatorilor care citesc datele din locația de punere în scenă, care ar putea fi activată. Sistem de fișiere elastice Amazon (Amazon EFS) sau Amazon FSx, de exemplu — și transmiteți-l în flux la destinație. Flexibilitatea aici constă în faptul că fiecare dintre aceste sarcini de consum poate fi declanșată pentru a fi transmisă în flux din diferite marcaje de timp de comitere. Sarcina fluxului de jurnal începe, de obicei, să citească date din minimul tuturor marcajelor de timp de comitere utilizate de sarcinile consumatorului.
Să ne uităm la un exemplu pentru a explica scenariul:
- Sarcina de consumator A transmite date de la un marcaj de timp de comitere începând cu 2022-07-19T20:00:00 către
example-stream-1. - Sarcina de consum B transmite date de la un marcaj de timp de comitere începând cu 2022-07-19T21:00:00 către
example-stream-2. - În această situație, fluxul de jurnal ar trebui să citească date de la sursa de date la distanță din minimul de marcaje temporale utilizate de sarcinile consumatorului, care este 2022-07-19T20:00:00.
Următoarea diagramă de secvență demonstrează pașii exacti pe care trebuie să-i rulați în timpul unei transferări la erori us-east-2 (regiunea standby).

Pașii sunt după cum urmează:
- Procesul de failover este declanșat în regiunea de așteptare (
us-east-2în acest exemplu) când este necesar. Rețineți că declanșatorul poate fi automatizat utilizând verificări complete de sănătate ale conductei din regiunea principală. - Procesul de failover actualizează tabelul global kdsActiveRegionConfig DynamoDB cu noua valoare pentru regiune ca
us-east-2pentru toate numele fluxurilor. - Următorul pas este să preluați toate punctele de control ale fluxului de la
kdsReplicationCheckpointTabel global DynamoDB (înus-east-2). - După ce informațiile punctului de control sunt citite, procesul de failover găsește minimul dintre toate
lastReplicatedTimestamp. - Sarcina de flux de jurnal din instrumentul procesor CDC este pornită în
us-east-2cu marcajul de timp găsit la Pasul 4. Începe să citească datele CDC de la sursa de date la distanță începând cu acest marcaj de timp și le păstrează în locația de realizare pe AWS. - Următorul pas este să porniți toate sarcinile consumatorului pentru a citi datele de la locația de punere în scenă și a transmite în fluxul de date de destinație. Acesta este locul în care fiecare sarcină de consumator este furnizată cu marcajul de timp corespunzător de la
kdsReplicationCheckpointtabel conformstreamNamecătre care sarcina transmite datele.
După ce toate sarcinile de consum sunt pornite, datele sunt produse în fluxurile de date Kinesis din us-east-2. De aici încolo, procesul de replicare între regiuni este același cu cel descris mai devreme – funcția Lambda de replicare în us-east-2 începe replicarea datelor în fluxul de date în us-east-1.
Se așteaptă că aplicațiile consumatorilor care citesc date din fluxuri vor fi idempotente pentru a putea gestiona duplicatele. Duplicatele pot fi introduse în flux din mai multe motive, dintre care unele sunt menționate mai jos.
- Producătorul sau procesorul CDC introduce duplicate în flux în timp ce redă datele CDC în timpul unei reluări.
- DynamoDB Global Table utilizează replicarea asincronă a datelor în regiuni și dacă
kdsReplicationCheckpointdatele din tabel au o întârziere de replicare, procesul de failover poate utiliza un marcaj de timp mai vechi al punctului de control pentru a reda datele CDC.
De asemenea, aplicațiile consumatorilor ar trebui să pună punct de control CommitTimestamp al ultimei înregistrări care a fost consumată. Acest lucru este pentru a facilita o mai bună monitorizare și recuperare.
Calea către maturitate: recuperare automată
Starea ideală este automatizarea completă a procesului de failover, reducând timpul de recuperare și îndeplinirea obiectivului de reziliență la nivel de serviciu (SLO). Cu toate acestea, în cele mai multe organizații, decizia de a renunța la eșec, de a renunța și de a declanșa reluarea la failover necesită intervenție manuală în evaluarea situației și în deciderea rezultatului. Crearea automatizării prin script pentru a efectua failover-ul care poate fi rulat de un om este un loc bun de început.
Vanguard a automatizat toți pașii de failover, dar oamenii iau totuși decizia când să o invoce. Puteți personaliza soluția pentru a răspunde nevoilor dvs. și în funcție de instrumentul de procesor CDC pe care îl utilizați în mediul dumneavoastră.
Concluzie
În această postare, am descris modul în care Vanguard a inovat și a construit o soluție pentru replicarea datelor în regiuni în Kinesis Data Streams pentru a face datele foarte disponibile. Am demonstrat, de asemenea, o strategie robustă de punct de control pentru a facilita o failover regională a procesului de replicare atunci când este necesar. Soluția a ilustrat, de asemenea, cum să utilizați tabelele globale DynamoDB pentru urmărirea punctelor de control și a configurației de replicare. Cu această arhitectură, Vanguard a reușit să implementeze încărcături de lucru în funcție de datele CDC în mai multe regiuni, pentru a satisface nevoile afacerii de disponibilitate ridicată în fața deficiențelor serviciului care afectează conductele CDC în regiunea principală.
Dacă aveți feedback, vă rugăm să lăsați un comentariu în secțiunea de comentarii de mai jos.
Despre autori
 Raghu Boppanna lucrează ca arhitect de întreprindere la Biroul Tehnologic al Vanguard. Raghu este specializat în analiza datelor, migrarea/replicarea datelor, inclusiv conductele CDC, recuperare în caz de dezastru și baze de date. El a obținut mai multe certificări AWS, inclusiv AWS Certified Security – Speciality și AWS Certified Data Analytics – Speciality.
Raghu Boppanna lucrează ca arhitect de întreprindere la Biroul Tehnologic al Vanguard. Raghu este specializat în analiza datelor, migrarea/replicarea datelor, inclusiv conductele CDC, recuperare în caz de dezastru și baze de date. El a obținut mai multe certificări AWS, inclusiv AWS Certified Security – Speciality și AWS Certified Data Analytics – Speciality.
 Parameswaran V Vaidyanathan este arhitect senior de rezistență în cloud cu Amazon Web Services. El ajută companiile mari să atingă obiectivele de afaceri prin arhitectura și construirea de soluții scalabile și rezistente pe AWS Cloud.
Parameswaran V Vaidyanathan este arhitect senior de rezistență în cloud cu Amazon Web Services. El ajută companiile mari să atingă obiectivele de afaceri prin arhitectura și construirea de soluții scalabile și rezistente pe AWS Cloud.
 Richa Kaul este un lider senior în soluții pentru clienți care deservește clienții serviciilor financiare. Are sediul în New York. Ea are o experiență vastă în transformarea cloud la scară largă, excelența angajaților și soluțiile digitale de următoarea generație. Ea și echipa ei se concentrează pe optimizarea valorii cloud prin construirea de soluții performante, rezistente și agile. Lui Richa îi plac multe sporturi, cum ar fi triatlonul, muzica și învăța despre noile tehnologii.
Richa Kaul este un lider senior în soluții pentru clienți care deservește clienții serviciilor financiare. Are sediul în New York. Ea are o experiență vastă în transformarea cloud la scară largă, excelența angajaților și soluțiile digitale de următoarea generație. Ea și echipa ei se concentrează pe optimizarea valorii cloud prin construirea de soluții performante, rezistente și agile. Lui Richa îi plac multe sporturi, cum ar fi triatlonul, muzica și învăța despre noile tehnologii.
 Mithil Prasad este manager principal de soluții pentru clienți cu Amazon Web Services. În rolul său, Mithil lucrează cu Clienții pentru a stimula realizarea valorii în cloud, pentru a oferi leadership gândit pentru a ajuta companiile să atingă viteză, agilitate și inovație.
Mithil Prasad este manager principal de soluții pentru clienți cu Amazon Web Services. În rolul său, Mithil lucrează cu Clienții pentru a stimula realizarea valorii în cloud, pentru a oferi leadership gândit pentru a ajuta companiile să atingă viteză, agilitate și inovație.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/how-vanguard-made-their-technology-platform-resilient-and-efficient-by-building-cross-region-replication-for-amazon-kinesis-data-streams/
- 1
- 100
- 2022
- 28
- a
- capacitate
- Capabil
- Despre Noi
- mai sus
- acces
- Conform
- Cont
- precis
- Obține
- peste
- acțiuni
- activ
- activ
- de fapt
- plus
- sfat
- care afectează
- accesibil
- După
- împotriva
- agil
- TOATE
- permite
- alternativă
- Amazon
- Amazon EC2
- Amazon Kinesis
- Amazon Web Services
- Sume
- Google Analytics
- și
- aplicatii
- abordare
- adecvat
- arhitectură
- automatizarea
- Automata
- Automatizare
- disponibilitate
- disponibil
- in medie
- AWS
- Certificat AWS
- înapoi
- bazat
- deoarece
- fiind
- de mai jos
- Mai bine
- între
- scurt
- Spart
- construi
- Clădire
- construit
- construit-in
- afaceri
- continuitatea afacerii
- întreprinderi
- denumit
- captura
- capturi
- caz
- CDC
- certificări
- Certificate
- șansele
- Schimbare
- verifica
- Verificări
- şef
- alegere
- Cloud
- TEHNOLOGIA CLOUD
- cod
- comentariu
- comentarii
- comite
- component
- cuprinzător
- Calcula
- condiție
- Configuraţie
- Considerații
- consumate
- consumator
- Consumatorii
- consum
- continuu
- Control
- A costat
- ar putea
- Cuplu
- crea
- Crearea
- critic
- Curent
- În prezent
- personalizat
- client
- Soluții pentru clienți
- clienţii care
- personaliza
- de date
- Analiza datelor
- pierderi de date
- Baza de date
- baze de date
- Decidând
- decizie
- dedicat
- demonstrat
- demonstrează
- În funcție
- depinde de
- implementa
- dislocate
- descris
- destinație
- detaliu
- diferenţă
- diferit
- digital
- direct
- dezastru
- discutat
- distanţă
- conduce
- conducere
- duplicate
- în timpul
- fiecare
- Mai devreme
- câștigat
- economii
- Economie de scară
- eficient
- Angajat
- permite
- sporită
- asigura
- Afacere
- Companii
- Întreg
- Mediu inconjurator
- Eter (ETH)
- evalua
- evaluat
- eveniment
- Fiecare
- exemplu
- Excelență
- executând
- aşteptări
- de aşteptat
- experienţă
- Explica
- explică
- extensiv
- extern
- Față
- facilita
- factori
- FAIL
- A eșuat
- Eșec
- Caracteristică
- feedback-ul
- camp
- Fișier
- financiar
- Servicii financiare
- descoperiri
- First
- Flexibilitate
- Concentra
- următor
- urmează
- pentru investitori
- găsit
- din
- complet
- funcţie
- generaţie
- Caritate
- glob
- Goluri
- bine
- grafic
- Oaspete
- Vizitator Mesaj
- manipula
- Manipularea
- se întâmplă
- Sănătate
- ajutor
- ajută
- aici
- Înalt
- extrem de
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- uman
- Oamenii
- IAM
- ideal
- Identitate
- deteriorare
- îmbunătăţi
- îmbunătăţeşte
- in
- Inclusiv
- Intrare
- a crescut
- indică
- individ
- informații
- Infrastructură
- Inovaţie
- instanță
- intervenţie
- introdus
- Prezintă
- investitor
- Investitori
- IT
- repetare
- Java
- iulie
- Cheie
- Fluxuri de date Kinesis
- mare
- Nume
- Latență
- lider
- Conducere
- învăţare
- Părăsi
- Nivel
- Linie
- linii
- Listă
- mic
- locaţie
- Uite
- de pe
- făcut
- susține
- face
- FACE
- gestionate
- manager
- manieră
- manual
- multe
- cartografiere
- masiv
- scadență
- mijloace
- mecanism
- Întâlni
- Reuniunea
- metric
- Metrici
- minim
- minim
- mod
- modificată
- Monitorizarea
- cele mai multe
- Multicolor
- multiplu
- Muzică
- nume
- nume
- nativ
- Nevoie
- necesar
- nevoilor
- Nou
- Noi tehnologii
- New York
- următor
- număr
- numere
- obiectiv
- observa
- Birou
- de operare
- optimizarea
- organizații
- Rezultat
- paritate
- parte
- parteneriat
- parte
- Model
- efectua
- performanță
- efectuarea
- permisiuni
- persistă
- Personalizat
- conducte
- Loc
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- Politicile
- posibil
- Post
- potenţial
- împiedica
- primar
- Principal
- proces
- prelucrare
- procesor
- Produs
- producător
- Producătorii
- promovează
- proteja
- furniza
- prevăzut
- furnizează
- publica
- Editare
- scopuri
- pune
- Citeste
- Citind
- realizare
- motive
- recomandat
- record
- înregistrări
- Recupera
- recuperare
- reduce
- reducerea
- regiune
- regional
- regiuni
- la distanta
- replicat
- replică
- replică
- necesar
- Cerinţe
- Necesită
- rezervat
- elasticitate
- elastic
- răspuns
- REST
- relua
- reveni
- revenind
- Returnează
- robust
- Rol
- Produse laminate
- RÂND
- Alerga
- Siguranţă
- acelaşi
- scalabil
- Scară
- scenariu
- Al doilea
- secundar
- secunde
- Secțiune
- securitate
- senior
- Secvenţă
- servi
- serviciu
- Servicii
- servire
- set
- instalare
- câteva
- să
- indicat
- Emisiuni
- simplitate
- situație
- Mărimea
- So
- soluţie
- soluţii
- unele
- Sursă
- Surse
- specializată
- Specialitate
- viteză
- Sportul
- înscenare
- Începe
- început
- începe
- Stat
- Pas
- paşi
- Încă
- Stop
- stoca
- Strategie
- curent
- de streaming
- serviciul de streaming
- fluxuri
- de succes
- Reușit
- potrivit
- superior
- furnizat
- Sprijină
- sistem
- tabel
- ia
- Ţintă
- Sarcină
- sarcini
- echipă
- echipe
- Tehnic
- Tehnologii
- Tehnologia
- lor
- lucruri
- terț
- gândit
- conducerea gândirii
- Prin
- debit
- timp
- timestamp-ul
- la
- instrument
- Unelte
- urmări
- Urmărire
- Transformare
- călătorit
- declanşa
- a declanșat
- înţelege
- înțeles
- inutil
- Actualizează
- actualizat
- actualizări
- utilizare
- carcasa de utilizare
- obișnuit
- UTC
- valoare
- Avangardă
- Viteză
- de
- volum
- web
- servicii web
- care
- în timp ce
- voi
- în
- fără
- fabrică
- ar
- scrie
- scris
- Ta
- te
- zephyrnet
- zero
- zone