Imagine de autor
În această postare, vom explora noul model open-source de ultimă generație numit Mixtral 8x7b. Vom învăța, de asemenea, cum să-l accesăm folosind biblioteca LLaMA C++ și cum să rulăm modele de limbaj mari pe calculare și memorie reduse.
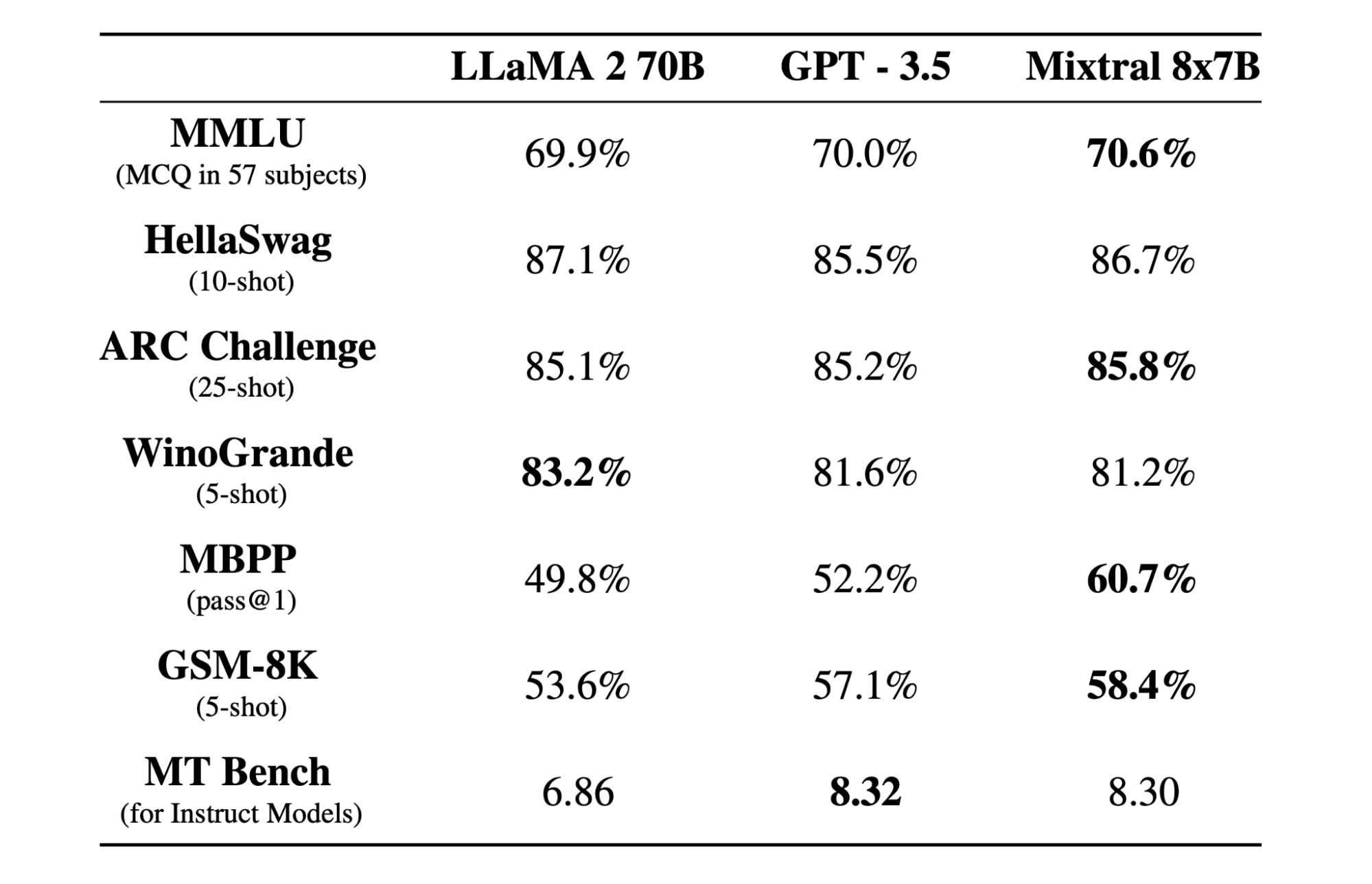
Mixtral 8x7b este un model de înaltă calitate amestec rar de experți (SMoE) cu greutăți deschise, creat de Mistral AI. Este licențiat sub Apache 2.0 și depășește Llama 2 70B la majoritatea benchmark-urilor, având o inferență de 6 ori mai rapidă. Mixtral se potrivește sau învinge GPT3.5 pe majoritatea benchmark-urilor standard și este cel mai bun model open-weight în ceea ce privește cost/performanță.
Imagine de la Mixtral de experți
Mixtral 8x7B folosește o rețea rară de experți numai pentru decodor. Aceasta implică un bloc feedforward care selectează din 8 grupuri de parametri, cu o rețea de routere alegând două dintre aceste grupuri pentru fiecare token, combinându-și ieșirile în mod aditiv. Această metodă îmbunătățește numărul de parametri ai modelului, gestionând în același timp costul și latența, făcându-l la fel de eficient ca un model de 12.9 miliarde, în ciuda faptului că are 46.7 miliarde de parametri în total.
Modelul Mixtral 8x7B excelează în gestionarea unui context larg de 32 de jetoane și acceptă mai multe limbi, inclusiv engleză, franceză, italiană, germană și spaniolă. Demonstrează performanțe puternice în generarea de cod și poate fi ajustat într-un model de urmărire a instrucțiunilor, obținând scoruri mari la benchmark-uri precum MT-Bench.
LLaMA.cpp este o bibliotecă C/C++ care oferă o interfață de înaltă performanță pentru modele de limbaj mari (LLM) bazate pe arhitectura LLM a Facebook. Este o bibliotecă ușoară și eficientă, care poate fi utilizată pentru o varietate de sarcini, inclusiv generarea de text, traducerea și răspunsul la întrebări. LLaMA.cpp acceptă o gamă largă de LLM, inclusiv LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B și GPT4ALL. Este compatibil cu toate sistemele de operare și poate funcționa atât pe procesoare, cât și pe GPU.
În această secțiune, vom rula aplicația web llama.cpp pe Colab. Scriind câteva rânduri de cod, veți putea experimenta noul model de performanță de ultimă generație pe computer sau pe Google Colab.
Noțiuni de bază
Mai întâi, vom descărca depozitul llama.cpp GitHub folosind linia de comandă de mai jos:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitDupă aceea, vom schimba directorul în depozit și vom instala llama.cpp folosind comanda `make`. Instalăm llama.cpp pentru GPU-ul NVidia cu CUDA instalat.
%cd llama.cpp
!make LLAMA_CUBLAS=1Descărcați modelul
Putem descărca modelul din Hugging Face Hub selectând versiunea corespunzătoare a fișierului model `.gguf`. Mai multe informații despre diferite versiuni pot fi găsite în TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
Imagine de la TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Puteți folosi comanda `wget` pentru a descărca modelul în directorul curent.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufAdresă externă pentru serverul LLaMA
Când rulăm serverul LLaMA, acesta ne va oferi un IP localhost care este inutil pentru noi pe Colab. Avem nevoie de conexiunea la proxy-ul localhost folosind portul proxy kernel Colab.
După ce rulați codul de mai jos, veți obține hyperlinkul global. Vom folosi acest link pentru a accesa aplicația noastră web mai târziu.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/Rularea serverului
Pentru a rula serverul LLaMA C++, trebuie să furnizați comenzii de server locația fișierului model și numărul de port corect. Este important să vă asigurați că numărul portului se potrivește cu cel pe care l-am inițiat în pasul anterior pentru portul proxy.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
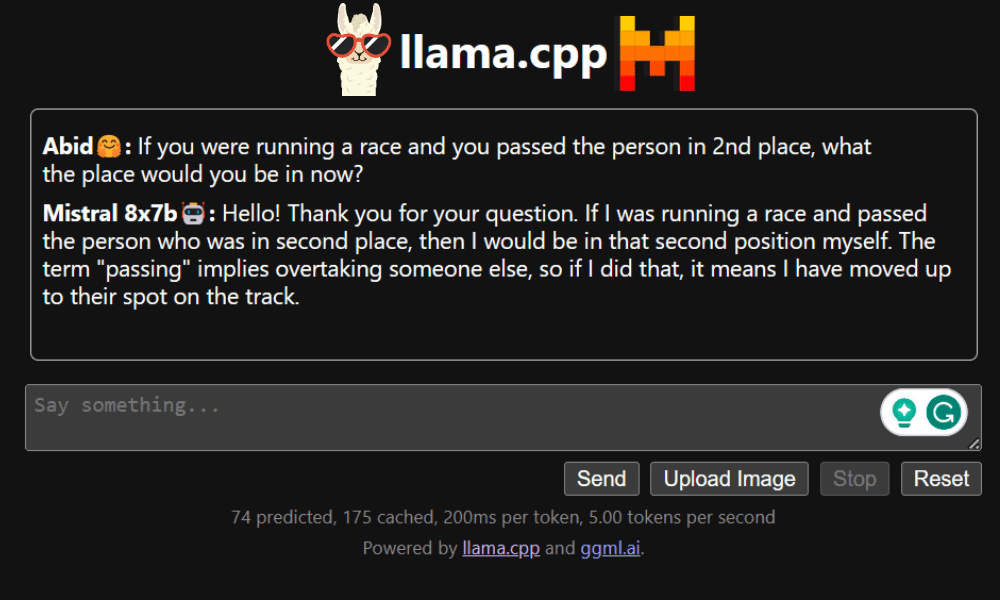
Aplicația web de chat poate fi accesată făcând clic pe hyperlinkul portului proxy la pasul anterior, deoarece serverul nu rulează local.
Aplicația web LLaMA C++
Înainte de a începe să folosim chatbot-ul, trebuie să-l personalizăm. Înlocuiți „LLaMA” cu numele modelului dvs. în secțiunea de prompt. În plus, modificați numele de utilizator și numele botului pentru a face distincția între răspunsurile generate.
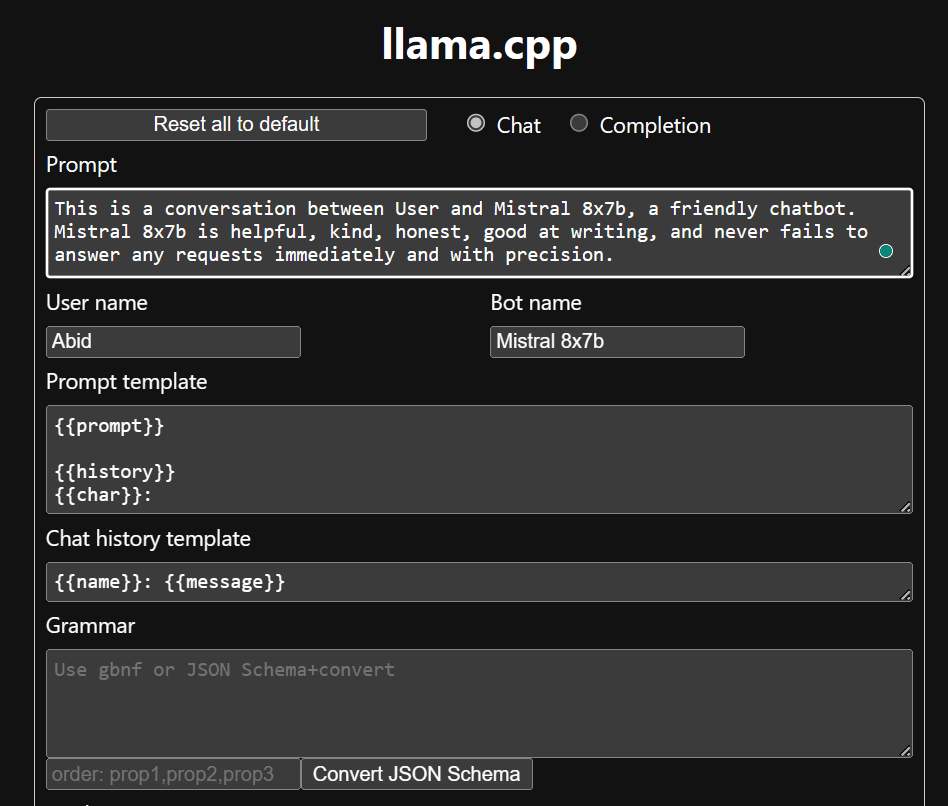
Începeți să conversați derulând în jos și tastând în secțiunea de chat. Simțiți-vă liber să puneți întrebări tehnice la care alte modele open source nu au reușit să răspundă corect.
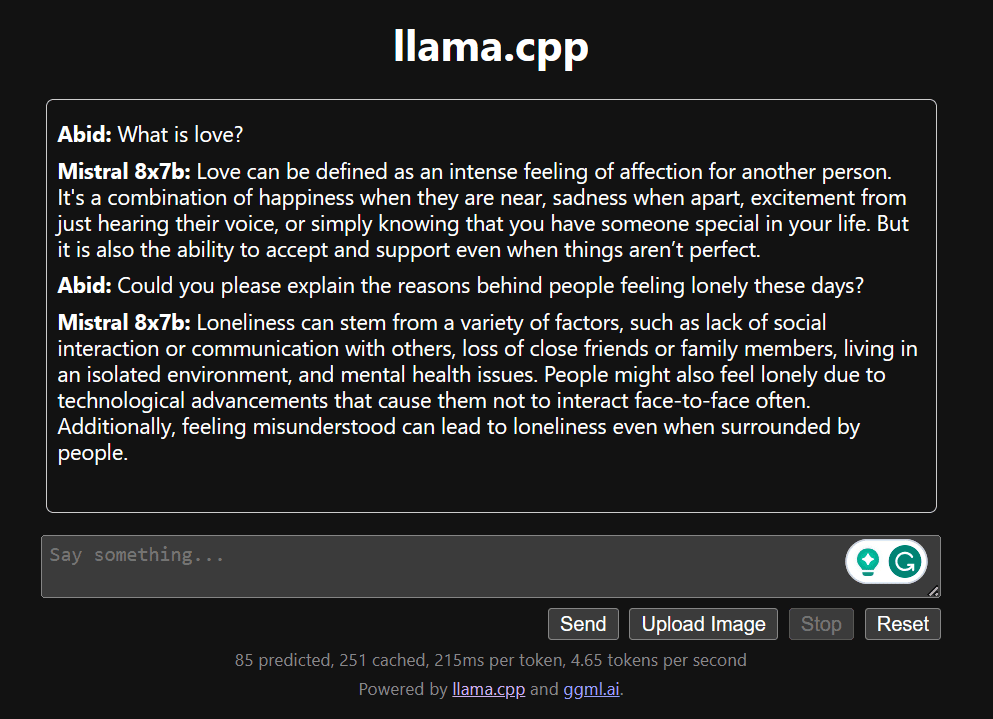
Dacă întâmpinați probleme cu aplicația, puteți încerca să o rulați pe cont propriu folosind Google Colab: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
Acest tutorial oferă un ghid cuprinzător despre cum să rulați modelul avansat open-source, Mixtral 8x7b, pe Google Colab folosind biblioteca LLaMA C++. În comparație cu alte modele, Mixtral 8x7b oferă performanțe și eficiență superioare, făcându-l o soluție excelentă pentru cei care doresc să experimenteze cu modele de limbaj mari, dar nu au resurse de calcul extinse. Îl puteți rula cu ușurință pe laptop sau pe un cloud compute gratuit. Este ușor de utilizat și puteți chiar să implementați aplicația dvs. de chat pentru ca alții să o folosească și să experimenteze.
Sper că ați găsit utilă această soluție simplă pentru rularea modelului mare. Caut mereu variante simple și mai bune. Dacă aveți o soluție și mai bună, vă rog să-mi spuneți și o voi acoperi data viitoare.
Abid Ali Awan (@ 1abidaliawan) este un profesionist certificat în domeniul științei datelor, căruia îi place să construiască modele de învățare automată. În prezent, se concentrează pe crearea de conținut și pe scrierea de bloguri tehnice despre învățarea automată și tehnologiile științei datelor. Abid deține o diplomă de master în managementul tehnologiei și o diplomă de licență în ingineria telecomunicațiilor. Viziunea lui este de a construi un produs AI folosind o rețea neuronală grafică pentru studenții care se luptă cu boli mintale.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :este
- :nu
- 1
- 12
- 27
- 46
- 7
- 8
- a
- Capabil
- acces
- accesate
- realizarea
- În plus,
- adresa
- avansat
- AI
- TOATE
- de asemenea
- mereu
- am
- an
- și
- răspunde
- Apache
- aplicaţia
- aplicație
- adecvat
- arhitectură
- SUNT
- AS
- cere
- bazat
- BE
- începe
- de mai jos
- valori de referință
- CEL MAI BUN
- Mai bine
- între
- Bloca
- bloguri
- Bot
- atât
- construi
- Clădire
- dar
- by
- C ++
- denumit
- CAN
- Certificate
- Schimbare
- Chat
- chatbot
- chat
- alegere
- Cloud
- cod
- combinând
- comparație
- compatibil
- cuprinzător
- de calcul
- Calcula
- tehnica de calcul
- conexiune
- conţinut
- crearea de continut
- context
- corecta
- A costat
- acoperi
- a creat
- creaţie
- Curent
- În prezent
- personaliza
- de date
- știința datelor
- om de știință de date
- Grad
- Oferă
- demonstrează
- implementa
- În ciuda
- distinge
- do
- jos
- Descarca
- fiecare
- cu ușurință
- eficiență
- eficient
- întâlni
- Inginerie
- Engleză
- Îmbunătăţeşte
- Chiar
- excelent
- experienţă
- experiment
- experți
- explora
- extensiv
- Față
- A eșuat
- şoim
- mai repede
- simţi
- puțini
- Fișier
- concentrându-se
- Pentru
- găsit
- Gratuit
- Franceză
- din
- funcţie
- generată
- generaţie
- Germană
- obține
- GitHub
- Da
- Caritate
- GPU
- unități de procesare grafică
- grafic
- Rețeaua neuronală grafică
- Grupului
- ghida
- Manipularea
- Avea
- având în
- he
- util
- Înalt
- performanta ridicata
- de înaltă calitate
- lui
- deține
- speranţă
- Cum
- Cum Pentru a
- HTTPS
- Butuc
- i
- if
- boală
- import
- important
- in
- Inclusiv
- informații
- iniţiat
- instala
- Instalarea
- interfaţă
- în
- implică
- IP
- probleme de
- IT
- Italiană
- KDnuggets
- Cunoaște
- limbă
- Limbă
- laptop
- mare
- Latență
- mai tarziu
- AFLAȚI
- învăţare
- lăsa
- Bibliotecă
- Autorizat
- categorie ușoară
- ca
- Linie
- linii
- LINK
- Lamă
- la nivel local
- locaţie
- cautati
- iubeste
- maşină
- masina de învățare
- face
- Efectuarea
- administrare
- de conducere
- maestru
- meciuri
- me
- Memorie
- mental
- Boală mintală
- metodă
- amestec
- model
- Modele
- modifica
- mai mult
- cele mai multe
- multiplu
- my
- nume
- Nevoie
- reţea
- neural
- rețele neuronale
- Nou
- următor
- număr
- Nvidia
- of
- on
- ONE
- deschide
- open-source
- de operare
- sisteme de operare
- Opţiuni
- or
- Altele
- Altele
- al nostru
- surclasează
- producție
- iesiri
- propriu
- parametru
- parametrii
- PC
- performanță
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- Post
- precedent
- Produs
- profesional
- cum se cuvine
- furniza
- furnizează
- împuternicit
- întrebare
- Întrebări
- gamă
- Redus
- cu privire la
- înlocui
- depozit
- cercetare
- Resurse
- răspunsuri
- router
- Alerga
- funcţionare
- s
- Ştiinţă
- Om de stiinta
- scorurile
- defilare
- Secțiune
- selectarea
- serverul
- simplu
- întrucât
- soluţie
- Sursă
- Spaniolă
- standard
- de ultimă oră
- Pas
- puternic
- Incercand
- Elevi
- superior
- Sprijină
- sigur
- sisteme
- sarcini
- Tehnic
- Tehnologii
- Tehnologia
- telecomunicaţie
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- generarea textului
- acea
- lor
- Acestea
- acest
- aceste
- timp
- la
- semn
- indicativele
- Total
- Traducere
- încerca
- tutorial
- Două
- în
- us
- utilizare
- utilizat
- Utilizator
- ușor de utilizat
- utilizări
- folosind
- varietate
- diverse
- versiune
- viziune
- vrea
- we
- web
- aplicatie web
- care
- în timp ce
- OMS
- larg
- Gamă largă
- voi
- cu
- scris
- tu
- Ta
- zephyrnet




