Generat cu Midjourney
Conferința NeurIPS 2023, desfășurată în vibrantul oraș New Orleans între 10 și 16 decembrie, a pus un accent deosebit pe IA generativă și pe modelele de limbaj mari (LLM). În lumina recentelor progrese inovatoare în acest domeniu, nu a fost surprinzător faptul că aceste subiecte au dominat discuțiile.
Una dintre temele de bază ale conferinței din acest an a fost căutarea unor sisteme AI mai eficiente. Cercetătorii și dezvoltatorii caută în mod activ modalități de a construi IA care nu numai că învață mai repede decât LLM-urile actuale, ci și posedă capacități de raționament îmbunătățite, consumând în același timp mai puține resurse de calcul. Această urmărire este crucială în cursa către atingerea Inteligenței Generale Artificiale (AGI), un obiectiv care pare din ce în ce mai atins în viitorul apropiat.
Discuțiile invitate la NeurIPS 2023 au fost o reflectare a acestor interese dinamice și în evoluție rapidă. Prezentatori din diverse sfere de cercetare AI și-au împărtășit cele mai recente realizări, oferind o fereastră către evoluțiile de ultimă oră în IA. În acest articol, ne aprofundăm în aceste discuții, extragând și discutând principalele concluzii și învățăminte, care sunt esențiale pentru înțelegerea peisajului actual și viitor al inovației AI.
NextGenAI: Iluzia scalarii și viitorul IA generativă
In vorbirea lui, Björn Ommer, șeful grupului de viziune și învățare computerizată la Universitatea Ludwig Maximilian din München, a împărtășit cum a ajuns laboratorul său să dezvolte Stable Diffusion, câteva lecții pe care le-au învățat din acest proces și evoluțiile recente, inclusiv modul în care putem combina modelele de difuzie cu potrivirea fluxului, creșterea recuperării și aproximările LoRA, printre altele.
Purtări cheie:
- În era IA generativă, am trecut de la concentrarea asupra percepției în modelele de viziune (adică recunoașterea obiectelor) la prezicerea părților lipsă (de exemplu, generarea de imagini și videoclipuri cu modele de difuzie).
- Timp de 20 de ani, viziunea computerizată s-a concentrat pe cercetarea de referință, care a ajutat să se concentreze asupra celor mai proeminente probleme. În IA generativă, nu avem puncte de referință pentru care să optimizăm, ceea ce a deschis câmpul pentru ca fiecare să meargă în propria direcție.
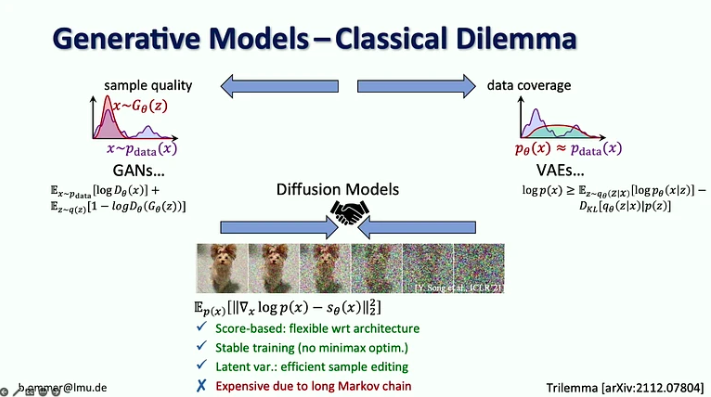
- Modelele de difuzie combină avantajele modelelor generative anterioare, fiind bazate pe scor cu o procedură de antrenament stabilă și o editare eficientă a mostrelor, dar sunt costisitoare datorită lanțului lor lung Markov.
- Provocarea cu modelele de probabilitate puternică este că majoritatea biților intră în detalii care sunt greu perceptibile de ochiul uman, în timp ce codificarea semantică, care contează cel mai mult, durează doar câțiva biți. Scalarea singură nu ar rezolva această problemă, deoarece cererea de resurse de calcul crește de 9 ori mai rapid decât oferta GPU.
- Soluția sugerată este de a combina punctele forte ale modelelor de difuzie și ale rețelelor ConvNet, în special eficiența convoluțiilor pentru reprezentarea detaliilor locale și expresivitatea modelelor de difuzie pentru contextul pe distanță lungă.
- Björn Ommer sugerează, de asemenea, utilizarea unei abordări de potrivire a fluxului pentru a permite sinteza imaginilor de înaltă rezoluție din modele mici de difuzie latentă.
- O altă abordare pentru creșterea eficienței sintezei imaginii este să se concentreze pe compoziția scenei în timp ce se folosește creșterea de recuperare pentru a completa detaliile.
- În cele din urmă, el a introdus abordarea iPoke pentru sinteza video stocastică controlată.
Dacă acest conținut aprofundat vă este util, abonați-vă la lista noastră de corespondență AI pentru a fi avertizați atunci când lansăm material nou.
Multe fețe ale IA responsabilă
In prezentarea ei, Lora Aroyo, cercetător la Google Research, a evidențiat o limitare cheie în abordările tradiționale de învățare automată: dependența lor de categorizările binare ale datelor ca exemple pozitive sau negative. Această simplificare excesivă, a susținut ea, trece cu vederea subiectivitatea complexă inerentă scenariilor și conținutului din lumea reală. Prin diverse cazuri de utilizare, Aroyo a demonstrat cum ambiguitatea conținutului și variația naturală a punctelor de vedere umane duc adesea la dezacorduri inevitabile. Ea a subliniat importanța de a trata aceste dezacorduri ca semnale semnificative, mai degrabă decât ca un simplu zgomot.

Iată principalele concluzii din discuție:
- Dezacordul dintre laboratorii umani poate fi productiv. În loc să trateze toate răspunsurile ca fiind corecte sau greșite, Lora Aroyo a introdus „adevărul prin dezacord”, o abordare a adevărului distribuțional pentru a evalua fiabilitatea datelor prin valorificarea dezacordului evaluatorului.
- Calitatea datelor este dificilă chiar și în cazul experților, deoarece experții nu sunt la fel de mult de acord ca laboratorii de mulțime. Aceste dezacorduri pot fi mult mai informative decât răspunsurile unui singur expert.
- În sarcinile de evaluare a siguranței, experții nu sunt de acord cu 40% dintre exemple. În loc să încercăm să rezolvăm aceste dezacorduri, trebuie să colectăm mai multe astfel de exemple și să le folosim pentru a îmbunătăți modelele și valorile de evaluare.
- Lora Aroyo le-a prezentat și ea Siguranță cu diversitate metodă de examinare a datelor în ceea ce privește ceea ce se află în ele și cine le-a adnotat.
- Această metodă a produs un set de date de referință cu variabilitatea judecăților de siguranță LLM în diferite grupuri demografice de evaluatori (2.5 milioane de evaluări în total).
- Pentru 20% dintre conversații, a fost dificil de decis dacă răspunsul chatbot a fost sigur sau nesigur, deoarece a existat un număr aproximativ egal de respondenți care le etichetau ca fiind sigure sau nesigure.
- Diversitatea evaluatorilor și a datelor joacă un rol crucial în evaluarea modelelor. Eșecul de a recunoaște gama largă de perspective umane și ambiguitatea prezentă în conținut poate împiedica alinierea performanței învățării automate cu așteptările din lumea reală.
- 80% din eforturile de siguranță AI sunt deja destul de bune, dar restul de 20% necesită dublarea efortului de a aborda cazurile marginale și toate variantele din spațiul infinit al diversității.
Statistici de coerență, experiență autogenerată și de ce oamenii tineri sunt mult mai inteligenți decât AI actuală
In vorbirea ei, Linda Smith, profesor distins la Universitatea din Indiana Bloomington, a explorat subiectul lipsei de date în procesele de învățare ale sugarilor și copiilor mici. Ea s-a concentrat în mod special pe recunoașterea obiectelor și învățarea numelor, aprofundând în modul în care statisticile experiențelor auto-generate de către sugari oferă soluții potențiale la provocarea lipsei de date.
Purtări cheie:
- Până la vârsta de trei ani, copiii și-au dezvoltat capacitatea de a învăța în mod unic în diferite domenii. În mai puțin de 16,000 de ore de trezire până la a patra aniversare, ei reușesc să învețe peste 1,000 de categorii de obiecte, să stăpânească sintaxa limbii lor materne și să absoarbă nuanțele culturale și sociale ale mediului lor.
- Dr. Linda Smith și echipa ei au descoperit trei principii ale învățării umane care le permit copiilor să capteze atât de multe din date atât de rare:
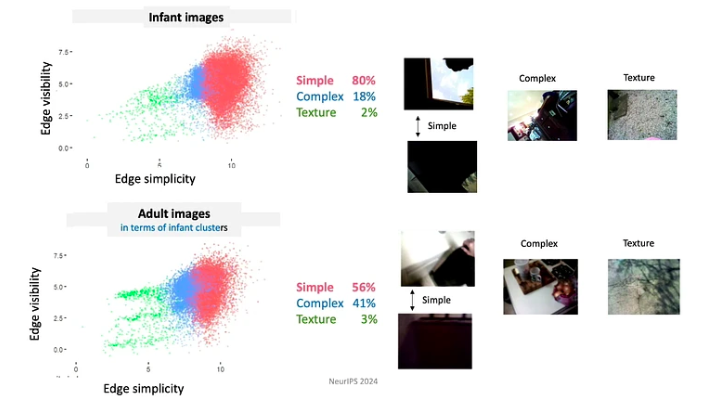
- Cursanții controlează intrarea, moment în moment ei modelează și structurează intrarea. De exemplu, în primele luni de viață, bebelușii tind să se uite mai mult la obiecte cu margini simple.
- Deoarece bebelușii evoluează continuu în cunoștințele și capacitățile lor, ei urmează un curriculum foarte restrâns. Datele la care sunt expuși sunt organizate în moduri profund semnificative. De exemplu, bebelușii sub 4 luni petrec cel mai mult timp privind fețele, aproximativ 15 minute pe oră, în timp ce cei mai mari de 12 luni se concentrează în primul rând pe mâini, observându-le aproximativ 20 de minute pe oră.
- Episoadele de învățare constau dintr-o serie de experiențe interconectate. Corelațiile spațiale și temporale creează coerență, care, la rândul său, facilitează formarea de amintiri durabile din evenimente unice. De exemplu, atunci când li se prezintă un sortiment aleatoriu de jucării, copiii se concentrează adesea pe câteva jucării „preferate”. Ei se angajează cu aceste jucării folosind modele repetitive, ceea ce ajută la o învățare mai rapidă a obiectelor.
- Amintirile tranzitorii (de lucru) persistă mai mult decât intrarea senzorială. Proprietățile care îmbunătățesc procesul de învățare includ multimodalitate, asocieri, relații predictive și activarea amintirilor din trecut.
- Pentru o învățare rapidă, aveți nevoie de o alianță între mecanismele care generează datele și mecanismele care învață.
Schițare: instrumente de bază, creșterea învățării și robustețe adaptivă
Jelani Nelson, profesor de inginerie electrică și științe informatice la UC Berkeley, a introdus conceptul de „schițe” de date – o reprezentare comprimată în memorie a unui set de date care permite încă răspunsul la întrebări utile. Deși discuția a fost destul de tehnică, a oferit o imagine de ansamblu excelentă a unor instrumente fundamentale de schiță, inclusiv progrese recente.
Elemente cheie:
- CountSketch, instrumentul de bază de schiță, a fost introdus pentru prima dată în 2002 pentru a aborda problema „lovitorilor grei”, raportând o listă mică a articolelor cele mai frecvente din fluxul de articole dat. CountSketch a fost primul algoritm subliniar cunoscut folosit în acest scop.
- Două aplicații non-streaming ale lovitorilor grei includ:
- Metodă bazată pe puncte interioare (IPM) care oferă un algoritm asimptotic cel mai rapid cunoscut pentru programarea liniară.
- Metoda HyperAttention care abordează provocarea de calcul reprezentată de complexitatea tot mai mare a contextelor lungi utilizate în LLM.
- Multe lucrări recente s-au concentrat pe proiectarea de schițe care sunt robuste pentru interacțiunea adaptivă. Ideea principală este să folosiți informații din analiza adaptivă a datelor.
Dincolo de Panoul de scalare
Acest panou grozav despre modele mari de limbaj a fost moderată de Alexander Rush, profesor asociat la Cornell Tech și cercetător la Hugging Face. Ceilalți participanți au inclus:
- Aakanksha Chowdhery – cercetător de știință la Google DeepMind cu interese de cercetare în sisteme, preformare LLM și multimodalitate. Ea a făcut parte din echipa care a dezvoltat PaLM, Gemeni și Pathways.
- Angela Fan – cercetător la Meta Generative AI cu interese de cercetare în aliniere, centre de date și multilingvitate. Ea a participat la dezvoltarea Llama-2 și Meta AI Assistant.
- Percy Liang – Profesor la Stanford care cercetează creatori, sursă deschisă și agenți generativi. El este directorul Centrului de Cercetare a Modelelor Fundației (CRFM) la Stanford și fondatorul Together AI.
Discuția sa concentrat pe patru subiecte cheie: (1) arhitecturi și inginerie, (2) date și aliniere, (3) evaluare și transparență și (4) creatori și colaboratori.
Iată câteva dintre concluziile din acest panou:
- Formarea modelelor lingvistice actuale nu este în mod inerent dificilă. Principala provocare în antrenarea unui model precum Llama-2-7b constă în cerințele de infrastructură și necesitatea coordonării între mai multe GPU-uri, centre de date etc. Cu toate acestea, dacă numărul de parametri este suficient de mic pentru a permite antrenamentul pe un singur GPU, chiar și un student de licență o poate gestiona.
- În timp ce modelele autoregresive sunt de obicei utilizate pentru generarea de text și modelele de difuzare pentru generarea de imagini și videoclipuri, au existat experimente cu inversarea acestor abordări. Mai exact, în proiectul Gemini, este utilizat un model autoregresiv pentru generarea de imagini. Au existat, de asemenea, explorări în utilizarea modelelor de difuzie pentru generarea de text, dar acestea nu s-au dovedit încă suficient de eficiente.
- Având în vedere disponibilitatea limitată a datelor în limba engleză pentru modelele de formare, cercetătorii explorează abordări alternative. O posibilitate este formarea modelelor multimodale pe o combinație de text, video, imagini și audio, cu așteptarea ca abilitățile învățate din aceste modalități alternative să se transfere în text. O altă opțiune este utilizarea datelor sintetice. Este important de reținut că datele sintetice se îmbină adesea cu date reale, dar această integrare nu este întâmplătoare. Textele publicate online sunt supuse de obicei procesării și editării umane, ceea ce ar putea adăuga valoare suplimentară pentru formarea modelelor.
- Modelele de fundație deschisă sunt adesea văzute ca fiind benefice pentru inovare, dar potențial dăunătoare pentru siguranța AI, deoarece pot fi exploatate de actori rău intenționați. Cu toate acestea, dr. Percy Liang susține că modelele deschise contribuie, de asemenea, în mod pozitiv la siguranță. El susține că, fiind accesibile, oferă mai multor cercetători oportunități de a efectua cercetări privind siguranța AI și de a revizui modelele pentru potențiale vulnerabilități.
- Astăzi, adnotarea datelor necesită mult mai multă experiență în domeniul adnotărilor, comparativ cu acum cinci ani. Cu toate acestea, dacă asistenții AI performează conform așteptărilor în viitor, vom primi date de feedback mai valoroase de la utilizatori, reducând dependența de date extinse de la adnotatori.
Sisteme pentru modele de fundație și modele de fundație pentru sisteme
In această discuție, Christopher Ré, profesor asociat la Departamentul de Informatică de la Universitatea Stanford, arată cum modelele de fundație au schimbat sistemele pe care le construim. El explorează, de asemenea, cum să construiți eficient modele de fundație, împrumutând informații din cercetarea sistemelor de baze de date și discută despre arhitecturi potențial mai eficiente pentru modelele de fundație decât Transformer.
Iată principalele concluzii din această discuție:
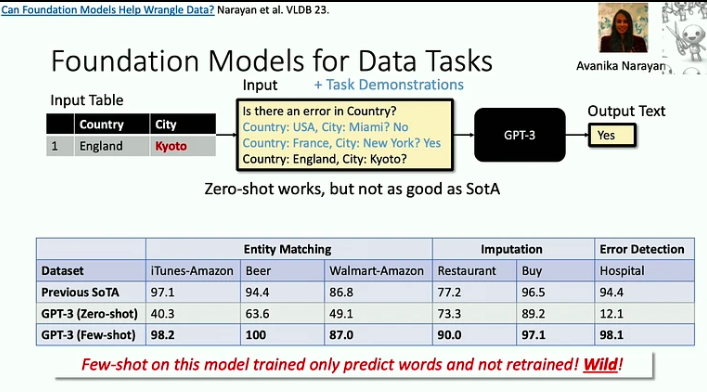
- Modelele de fundație sunt eficiente în abordarea problemelor „moarte la 1000 de tăieturi”, în care fiecare sarcină individuală ar putea fi relativ simplă, dar amploarea și varietatea sarcinilor reprezintă o provocare semnificativă. Un bun exemplu în acest sens este problema curățării datelor, pe care LLM-urile o pot ajuta acum să o rezolve mult mai eficient.
- Pe măsură ce acceleratoarele devin mai rapide, memoria apare adesea ca un blocaj. Aceasta este o problemă pe care cercetătorii bazelor de date o abordează de zeci de ani și putem adopta unele dintre strategiile lor. De exemplu, abordarea Flash Attention minimizează fluxurile de intrare-ieșire prin blocare și fuziune agresivă: ori de câte ori accesăm o informație, efectuăm cât mai multe operațiuni asupra acesteia.
- Există o nouă clasă de arhitecturi, înrădăcinate în procesarea semnalului, care ar putea fi mai eficientă decât modelul Transformer, în special la manipularea secvențelor lungi. Procesarea semnalului oferă stabilitate și eficiență, punând bazele modelelor inovatoare precum S4.
Învățare de consolidare online în intervenții în sănătate digitală
In vorbirea ei, Susan Murphy, profesor de statistică și știință informatică la Universitatea Harvard, a împărtășit primele soluții la unele dintre provocările cu care se confruntă în dezvoltarea algoritmilor RL online pentru utilizare în intervenții digitale în sănătate.
Iată câteva concluzii din prezentare:
- Dr. Susan Murphy a discutat despre două proiecte la care a lucrat:
- HeartStep, unde activitățile au fost sugerate pe baza datelor de pe smartphone-uri și trackere portabile și
- Oralitice pentru coaching pentru sănătatea orală, în care intervențiile s-au bazat pe datele de implicare primite de la o periuță de dinți electronică.
- În dezvoltarea unei politici de comportament pentru un agent AI, cercetătorii trebuie să se asigure că este autonomă și poate fi implementată în mod fezabil în sistemul de sănătate mai larg. Aceasta presupune asigurarea faptului că timpul necesar pentru angajamentul unei persoane este rezonabil și că acțiunile recomandate sunt atât solide din punct de vedere etic, cât și plauzibile din punct de vedere științific.
- Principalele provocări în dezvoltarea unui agent RL pentru intervențiile digitale în sănătate includ abordarea nivelurilor ridicate de zgomot, deoarece oamenii își duc viața și este posibil să nu fie întotdeauna capabili să răspundă la mesaje, chiar dacă doresc, precum și gestionarea efectelor negative puternice și întârziate. .
După cum puteți vedea, NeurIPS 2023 a oferit o privire iluminatoare asupra viitorului AI. Discuțiile invitate au evidențiat o tendință către modele mai eficiente, conștiente de resurse și explorarea unor arhitecturi noi dincolo de paradigmele tradiționale.
Bucurați-vă de acest articol? Înscrieți-vă pentru mai multe actualizări ale cercetării AI.
Vă vom anunța când vom lansa mai multe articole sumare ca acesta.
Legate de
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.topbots.com/neurips-2023-invited-talks/
- :are
- :este
- :nu
- :Unde
- $UP
- 000
- 1
- 10
- 10
- 11
- 110
- 12
- 12 luni
- 125
- 13
- 14
- 15%
- 154
- 16
- 16
- 17
- 20
- ani 20
- 2023
- 32
- 35%
- 41
- 58
- 65
- 7
- 70
- 710
- 8
- 9
- a
- capacitate
- Capabil
- Despre Noi
- acceleratoare
- acces
- accesibil
- realizările
- realizarea
- recunoaște
- peste
- acțiuni
- Activarea
- activ
- activităţi de
- actori
- adaptivă
- adăuga
- Suplimentar
- adresa
- adrese
- adresare
- adopta
- progresele
- Avantajele
- vârstă
- Agent
- agenţi
- agresiv
- AGI
- în urmă
- AI
- Asistent AI
- cercetare ai
- Sisteme AI
- SIDA
- Alexander
- Algoritmul
- algoritmi
- aliniere
- TOATE
- Alianță
- permite
- singur
- deja
- de asemenea
- alternativă
- Cu toate ca
- mereu
- Ambiguitate
- printre
- an
- analiză
- și
- O alta
- Orice
- aplicatii
- abordare
- abordari
- aproximativ
- SUNT
- a susținut
- susține
- articol
- bunuri
- artificial
- inteligență generală artificială
- AS
- evaluarea
- Asistent
- asistenți
- Avocat Colaborator
- asociaţii
- sortiment
- At
- accesibil
- atenţie
- audio
- autonom
- disponibilitate
- bazat
- BE
- deoarece
- deveni
- fost
- comportament
- fiind
- Benchmark
- valori de referință
- benefică
- Berkeley
- între
- Dincolo de
- Amesteca
- amestecuri
- blocarea
- Imprumut
- atât
- lăţime
- mai larg
- construi
- dar
- by
- a venit
- CAN
- capacități
- captura
- cazuri
- categorii
- Centru
- Centre
- lanţ
- contesta
- provocări
- si-a schimbat hainele;
- chatbot
- Copii
- Christopher
- Oraș
- clasă
- Curățenie
- coaching-ul
- colecta
- combinaţie
- combina
- comparație
- complex
- complexitate
- compoziție
- de calcul
- calculator
- Informatică
- Computer Vision
- tehnica de calcul
- concept
- Conduce
- Conferință
- construi
- conţinut
- context
- contexte
- continuu
- a contribui
- contribuitori
- Control
- controlată
- conversații
- coordona
- Nucleu
- Cornell
- corecta
- corelații
- ar putea
- crea
- Creatorii
- mulţime
- crucial
- cultural
- custozi
- Curent
- Curriculum
- ultima generație
- de date
- analiza datelor
- centre de date
- Baza de date
- abuzive
- zeci de ani
- decembrie
- decide
- DeepMind
- Întârziat
- se îngropa
- Cerere
- cererile
- demografic
- demonstrat
- Departament
- proiect
- detaliu
- detalii
- dezvolta
- dezvoltat
- Dezvoltatorii
- în curs de dezvoltare
- Dezvoltare
- evoluții
- dificil
- difuziune
- digital
- Sănătate digitală
- direcţie
- Director
- a descoperit
- discutat
- discutarea
- discuţie
- discuții
- Distins
- Diversitate
- domeniu
- domenii
- dominată
- Dont
- dublare
- dr
- două
- în timpul
- dinamic
- e
- fiecare
- Margine
- editare
- Eficace
- efecte
- eficiență
- eficient
- eficient
- efort
- Eforturile
- oricare
- Inginerie Electrică
- Electronic
- apare
- accent
- accentuat
- permite
- permite
- codare
- angaja
- angajament
- Inginerie
- spori
- sporită
- suficient de
- asigura
- asigurare
- Mediu inconjurator
- episoadele
- egal
- mai ales
- esenţial
- etc
- Eter (ETH)
- evaluarea
- evaluare
- Chiar
- evenimente
- toată lumea
- evolua
- evoluție
- exemplu
- exemple
- excelent
- aşteptare
- aşteptări
- de aşteptat
- scump
- experienţă
- Experiențe
- experimente
- expert
- expertiză
- experți
- exploatat
- explorare
- explorat
- Explorează
- Explorarea
- expus
- extensiv
- ochi
- Față
- fete
- facilitează
- în lipsa
- ventilator
- mai repede
- cel mai rapid
- feedback-ul
- puțini
- mai puține
- camp
- umple
- First
- cinci
- bliț
- debit
- fluxurilor
- Concentra
- concentrat
- urma
- Pentru
- previzibil
- formare
- Fundație
- fondator
- patru
- Al patrulea
- frecvent
- frecvent
- din
- fundamental
- fuziune
- viitor
- Viitorul AI
- zodia Gemeni
- General
- inteligenta generala
- genera
- generator
- generaţie
- generativ
- AI generativă
- dat
- oferă
- licărire
- Go
- scop
- bine
- GPU
- unități de procesare grafică
- inovatoare
- grup
- Grupului
- În creştere
- HAD
- Manipularea
- mâini
- nociv
- Cablaje
- harvard
- Universitatea Harvard
- Avea
- he
- cap
- Sănătate
- de asistență medicală
- greu
- Held
- ajutor
- a ajutat
- ei
- Înalt
- Rezoluție înaltă
- Evidențiat
- extrem de
- împiedica
- lui
- oră
- ORE
- Cum
- Cum Pentru a
- Totuși
- http
- HTTPS
- uman
- Oamenii
- i
- idee
- if
- iluminator
- imagine
- generarea imaginii
- imagini
- implementat
- importanță
- important
- îmbunătăţi
- in
- în profunzime
- include
- inclus
- Inclusiv
- crescând
- tot mai mult
- Indiana
- individ
- inevitabil
- informații
- informativ
- Infrastructură
- inerent
- în mod inerent
- Inovaţie
- inovatoare
- intrare
- perspective
- instanță
- in schimb
- integrare
- Inteligență
- interacţiune
- interconectate
- interese
- intervenții
- în
- introdus
- invitat
- IT
- articole
- jpg
- judecăți
- Cheie
- Cunoaște
- cunoştinţe
- cunoscut
- de laborator
- etichetarea
- limbă
- mare
- durată
- Ultimele
- ouătoare
- conduce
- conducere
- AFLAȚI
- învățat
- elevi
- învăţare
- Moştenire
- mai puțin
- Lectii
- lăsa
- nivelurile de
- se află
- ușoară
- ca
- probabilitate
- limitare
- Limitat
- linda
- Listă
- Locuiește
- local
- Lung
- mai lung
- Uite
- cautati
- maşină
- masina de învățare
- discuții
- Principal
- administra
- de conducere
- multe
- maestru
- potrivire
- material
- materie
- max-width
- Mai..
- semnificativ
- mecanisme
- Amintiri
- Memorie
- Mers
- mesaje
- meta
- metodă
- Metrici
- ar putea
- milion
- minimizează
- minute
- dispărut
- modalități
- model
- Modele
- moment
- luni
- mai mult
- mai eficient
- cele mai multe
- mutat
- mult
- multiplu
- Munchen
- trebuie sa
- nume
- nativ
- Natural
- Nevoie
- negativ
- NeurIPS
- Nou
- New Orleans
- Nu.
- Zgomot
- Nici unul
- nota
- roman
- acum
- umbrire
- număr
- obiect
- obiecte
- of
- oferi
- oferind
- promoții
- de multe ori
- mai în vârstă
- on
- ONE
- on-line
- afară
- deschide
- open-source
- deschis
- Operațiuni
- Oportunităţi
- Optimizați
- Opțiune
- or
- oral
- Sănătatea orală
- Organizat
- Orleans
- Altele
- Alți participanți
- Altele
- al nostru
- peste
- Prezentare generală
- propriu
- palmier
- panou
- paradigme
- parametrii
- parte
- participanţi
- a participat
- special
- în special
- piese
- trecut
- cai
- modele
- oameni
- pentru
- percepţie
- efectua
- performanță
- perspective
- bucată
- Plato
- Informații despre date Platon
- PlatoData
- plauzibil
- joacă
- Politica
- pozat
- pozitiv
- pozitiv
- posedă
- posibilitate
- posibil
- potenţial
- potenţial
- estimarea
- predictivă
- prezenta
- prezentare
- prezentat
- precedent
- în primul rând
- primar
- Principiile
- Problemă
- probleme
- procedură
- proces
- procese
- prelucrare
- Produs
- productiv
- Profesor
- profund
- Programare
- proiect
- Proiecte
- proeminent
- proprietăţi
- dovedit
- furniza
- prevăzut
- publicat
- scop
- urmărire
- calitate
- interogări
- căutare
- cu totul
- Rasă
- aleator
- gamă
- rapid
- repede
- mai degraba
- evaluări
- real
- lumea reală
- rezonabil
- a primi
- primit
- recent
- recunoaştere
- recomandat
- reducerea
- reflecţie
- Consolidarea învățării
- relaţii
- relativ
- eliberaţi
- încredere
- încredere
- rămas
- repetitiv
- Raportarea
- reprezentare
- reprezentând
- necesita
- necesar
- Cerinţe
- cercetare
- cercetător
- cercetători
- rezolvă
- Resurse
- Răspunde
- respondenți
- răspuns
- răspunsuri
- responsabil
- revizuiască
- robust
- Rol
- înrădăcinat
- aproximativ
- grăbi
- sigur
- Siguranţă
- scalare
- scenarii
- scenă
- Ştiinţă
- ȘTIINȚE
- Om de stiinta
- vedea
- caută
- pare
- văzut
- semantică
- serie
- fasonarea
- comun
- ea
- Emisiuni
- semna
- Semnal
- semnalele
- semnificativ
- semnificativ
- simplu
- singur
- aptitudini
- mic
- mai inteligent
- smartphone-uri
- fierar
- So
- Social
- soluţie
- soluţii
- REZOLVAREA
- unele
- Suna
- Sursă
- Spaţiu
- spațial
- specific
- petrece
- Stabilitate
- stabil
- stanford
- Universitatea Stanford
- statistică
- Încă
- strategii
- curent
- puncte forte
- puternic
- structurarea
- astfel de
- sugerează
- REZUMAT
- livra
- surpriză
- Susan
- sintaxă
- sinteză
- sintetic
- date sintetice
- sistem
- sisteme
- Takeaways
- ia
- Vorbi
- Tratative
- Sarcină
- sarcini
- echipă
- tech
- Tehnic
- Tind
- termeni
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- generarea textului
- decât
- acea
- Viitorul
- lor
- Lor
- tematică
- Acolo.
- Acestea
- ei
- acest
- aceste
- trei
- Prin
- timp
- la
- împreună
- instrument
- Unelte
- TOPBOTS
- subiect
- subiecte
- Total
- față de
- trackere
- tradiţional
- Pregătire
- transfer
- transformator
- Transparență
- tratare
- tendință
- Adevăr
- încercat
- ÎNTORCĂ
- Două
- tipic
- în
- este supus
- înţelegere
- universitate
- actualizări
- utilizare
- utilizat
- utilizatorii
- folosind
- obișnuit
- utilizate
- Valoros
- valoare
- varietate
- diverse
- vibrant
- Video
- Video
- puncte de vedere
- viziune
- Vulnerabilitățile
- W3
- a fost
- modalități de
- we
- purtabil
- BINE
- au fost
- Ce
- cand
- oricând
- întrucât
- dacă
- care
- în timp ce
- OMS
- de ce
- larg
- Gamă largă
- voi
- fereastră
- cu
- Apartamente
- de lucru
- Greșit
- ani
- încă
- tu
- tineri
- zephyrnet