
20 Septembrie, 2023
Modele fundamentale (FM) marchează începutul unei noi ere în învățare automată (ML) și inteligență artificială (AI), ceea ce duce la o dezvoltare mai rapidă a IA care poate fi adaptată la o gamă largă de sarcini din aval și ajustată pentru o serie de aplicații.
Odată cu importanța din ce în ce mai mare a procesării datelor acolo unde se lucrează, servirea modelelor AI la marginea întreprinderii permite predicții aproape în timp real, respectând în același timp cerințele de suveranitate și confidențialitate a datelor. Prin combinarea IBM watsonx capabilitățile platformei de date și AI pentru FM cu edge computing, întreprinderile pot rula sarcini de lucru AI pentru reglarea fină și inferența FM la marginea operațională. Acest lucru permite companiilor să extindă implementările AI la margine, reducând timpul și costurile de implementare cu timpi de răspuns mai rapid.
Asigurați-vă că consultați toate ratele din această serie de postări de blog despre edge computing:
Care sunt modelele de bază?
Modelele fundamentale (FM), care sunt antrenate pe un set larg de date neetichetate la scară, conduc la aplicații de ultimă generație de inteligență artificială (AI). Acestea pot fi adaptate la o gamă largă de sarcini din aval și pot fi reglate fin pentru o gamă largă de aplicații. Modelele moderne de inteligență artificială, care execută sarcini specifice într-un singur domeniu, dau loc FM-urilor, deoarece învață în general și lucrează în domenii și probleme. După cum sugerează și numele, un FM poate fi fundația pentru multe aplicații ale modelului AI.
FM abordează două provocări cheie care au împiedicat întreprinderile să crească adoptarea AI. În primul rând, întreprinderile produc o cantitate mare de date neetichetate, dintre care doar o parte este etichetată pentru formarea modelului AI. În al doilea rând, această sarcină de etichetare și adnotare este extrem de intensivă în oameni, necesitând adesea câteva sute de ore din timpul unui expert în materie (IMM). Acest lucru face ca costurile să fie prohibitive să fie extinse pe mai multe cazuri de utilizare, deoarece ar necesita armate de IMM-uri și experți în date. Prin ingerarea unor cantități mari de date neetichetate și folosind tehnici de auto-supraveghere pentru formarea modelelor, FM au eliminat aceste blocaje și au deschis calea pentru adoptarea pe scară largă a AI în întreaga întreprindere. Aceste cantități masive de date care există în fiecare afacere așteaptă să fie dezlănțuite pentru a genera informații.
Care sunt modelele mari de limbaj?
Modelele de limbaj mari (LLM) sunt o clasă de modele fundamentale (FM) care constau din straturi de rețele neuronale care au fost instruiți cu privire la aceste cantități masive de date neetichetate. Ei folosesc algoritmi de învățare auto-supravegheați pentru a efectua o varietate de prelucrarea limbajului natural (NLP) sarcini în moduri care sunt similare cu modul în care oamenii folosesc limbajul (vezi Figura 1).
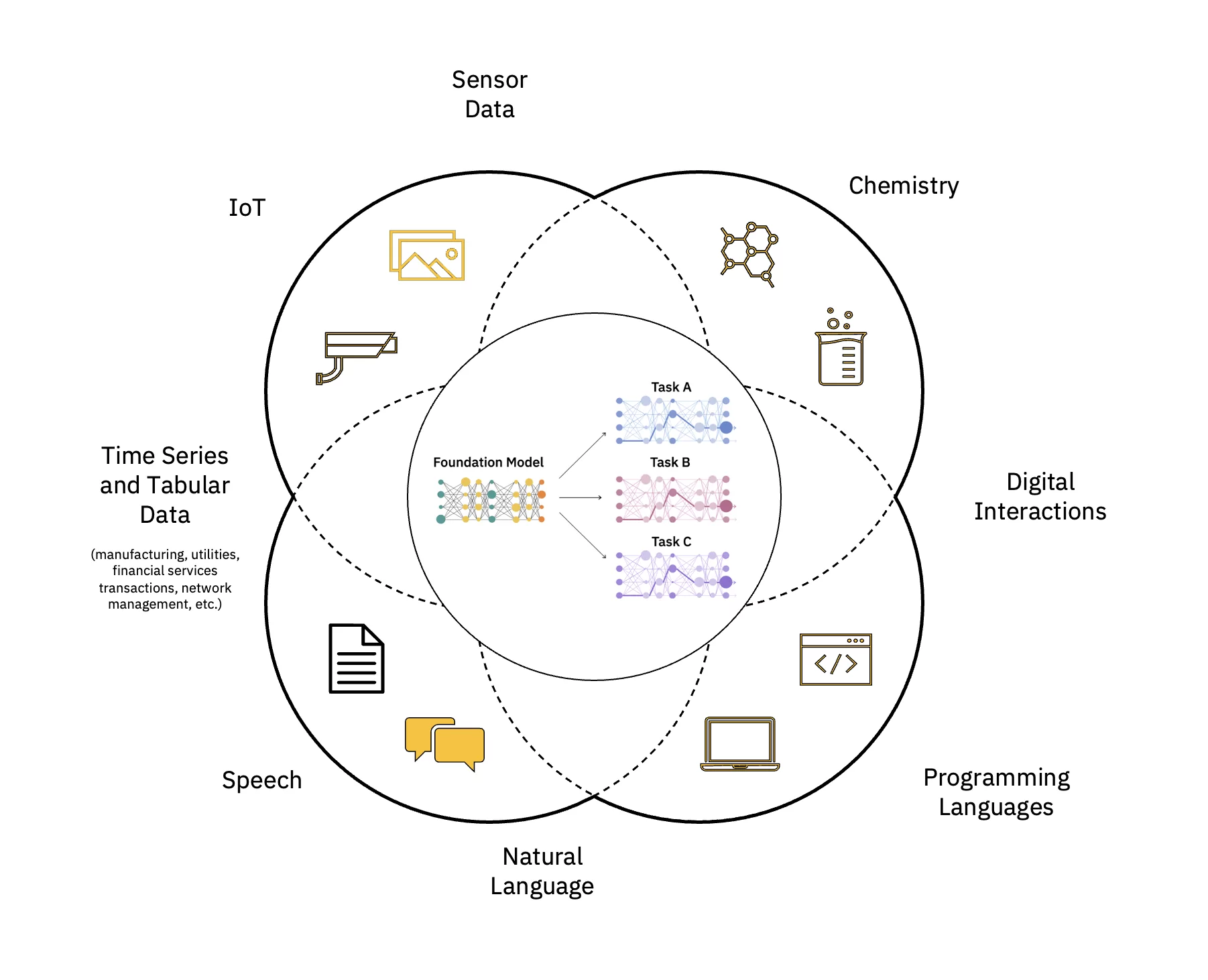
Scalați și accelerați impactul AI
Există mai mulți pași pentru construirea și implementarea unui model de bază (FM). Acestea includ asimilarea de date, selecția datelor, preprocesarea datelor, pregătirea prealabilă FM, ajustarea modelului la una sau mai multe sarcini din aval, servirea inferențelor și guvernanța modelului de date și AI și managementul ciclului de viață - toate acestea pot fi descrise ca FMOps.
Pentru a ajuta la toate acestea, IBM oferă întreprinderilor instrumentele și capabilitățile necesare pentru a valorifica puterea acestor FM-uri prin IBM watsonx, o platformă de date și AI pregătită pentru întreprindere, concepută pentru a multiplica impactul AI într-o întreprindere. IBM watsonx este format din următoarele:
- IBM watsonx.ai aduce noi AI generativă capabilități — alimentate de FM și învățarea automată tradițională (ML) — într-un studio puternic care acoperă ciclul de viață AI.
- IBM watsonx.data este un depozit de date potrivit pentru scop, construit pe o arhitectură deschisă lakehouse pentru a scala sarcinile de lucru AI pentru toate datele dvs., oriunde.
- IBM watsonx.guvernare este un set de instrumente de guvernare a ciclului de viață automatizat de la capăt la capăt al AI, care este construit pentru a permite fluxuri de lucru AI responsabile, transparente și explicabile.
Un alt vector cheie este importanța din ce în ce mai mare a calculului la marginea întreprinderii, cum ar fi locații industriale, etaje de producție, magazine de vânzare cu amănuntul, site-uri de la marginea telecomunicațiilor etc. Mai precis, AI la marginea întreprinderii permite procesarea datelor unde se lucrează pentru analiză aproape în timp real. Marginea întreprinderii este locul în care sunt generate cantități mari de date ale întreprinderii și unde AI poate oferi informații valoroase, oportune și aplicabile asupra afacerii.
Servirea modelelor AI la margine permite predicții aproape în timp real, respectând în același timp cerințele de suveranitate și confidențialitate a datelor. Acest lucru reduce semnificativ latența asociată adesea cu achiziția, transmiterea, transformarea și procesarea datelor de inspecție. Lucrul la margine ne permite să protejăm datele sensibile ale întreprinderii și să reducem costurile de transfer de date cu timpi de răspuns mai rapid.
Cu toate acestea, scalarea implementărilor AI la margine nu este o sarcină ușoară pe fondul provocărilor legate de date (eterogenitate, volum și reglementare) și resurse limitate (calculator, conectivitate la rețea, stocare și chiar competențe IT). Acestea pot fi descrise în linii mari în două categorii:
- Timp/cost de implementare: Fiecare implementare constă din mai multe straturi de hardware și software care trebuie instalate, configurate și testate înainte de implementare. Astăzi, un profesionist de service poate dura până la o săptămână sau două pentru instalare la fiecare locație, limitând sever cât de rapid și rentabil întreprinderile pot extinde implementările în organizația lor.
- Managementul zilei 2: Numărul mare de margini desfășurate și locația geografică a fiecărei implementări ar putea face adesea să fie extrem de costisitoare pentru a oferi suport IT local în fiecare locație pentru a monitoriza, întreține și actualiza aceste implementări.
Implementări Edge AI
IBM a dezvoltat o arhitectură de vârf care abordează aceste provocări aducând un model de dispozitiv hardware/software integrat (HW/SW) la implementările de IA de vârf. Acesta constă din mai multe paradigme cheie care ajută la scalabilitatea implementărilor AI:
- Furnizare bazată pe politici, fără atingere a întregii stive de software.
- Monitorizarea continuă a sănătății sistemului edge
- Capacități de a gestiona și de a împinge actualizări de software/securitate/configurație în numeroase locații marginale — toate dintr-o locație centrală bazată pe cloud pentru gestionarea a doua zi.
O arhitectură distribuită hub-and-spoke poate fi utilizată pentru a scala implementările AI ale întreprinderii la margine, în care un cloud central sau un centru de date al companiei acționează ca un hub, iar dispozitivul edge-in-a-box acționează ca o spiță într-o locație de margine.. Acest model hub and spoke, care se extinde în medii hibride cloud și edge, ilustrează cel mai bine echilibrul necesar pentru a utiliza în mod optim resursele necesare pentru operațiunile FM (vezi Figura 2).
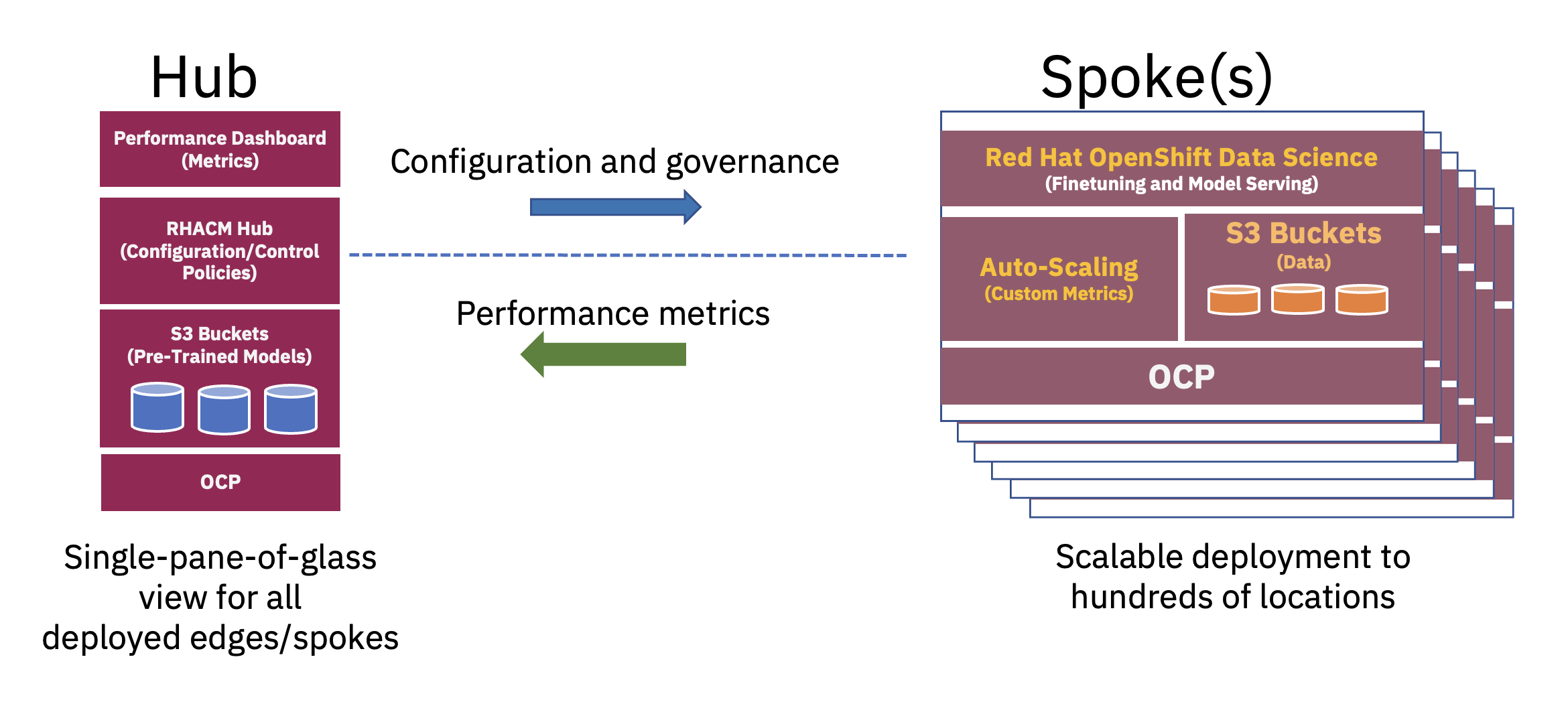
Preinstruirea acestor modele de limbă mari de bază (LLM) și a altor tipuri de modele de bază folosind tehnici auto-supravegheate pe seturi de date vaste neetichetate necesită adesea resurse semnificative de calcul (GPU) și se realizează cel mai bine într-un hub. Resursele de calcul practic nelimitate și grămezile mari de date stocate adesea în cloud permit pregătirea prealabilă a modelelor cu parametri mari și îmbunătățirea continuă a preciziei acestor modele de bază de bază.
Pe de altă parte, reglarea acestor FM de bază pentru sarcini în aval – care necesită doar câteva zeci sau sute de eșantioane de date etichetate și servire de inferență – poate fi realizată cu doar câteva GPU-uri la marginea întreprinderii. Acest lucru permite ca datele sensibile etichetate (sau datele bijuterie ale companiei) să rămână în siguranță în mediul operațional al întreprinderii, reducând în același timp costurile de transfer de date.
Folosind o abordare full-stack pentru implementarea aplicațiilor la margine, un cercetător de date poate efectua reglarea fină, testarea și implementarea modelelor. Acest lucru poate fi realizat într-un singur mediu, reducând în același timp ciclul de viață de dezvoltare pentru a oferi noilor modele AI utilizatorilor finali. Platforme precum Red Hat OpenShift Data Science (RHODS) și anunțul recent Red Hat OpenShift AI oferă instrumente pentru dezvoltarea și implementarea rapidă a modelelor AI pregătite pentru producție în cloud distribuit și medii de margine.
În cele din urmă, deservirea modelului AI reglat la marginea întreprinderii reduce semnificativ latența asociată adesea cu achiziția, transmiterea, transformarea și procesarea datelor. Decuplarea antrenamentului prealabil în cloud de reglajul fin și inferența pe margine scade costul operațional general prin reducerea timpului necesar și a costurilor de mișcare a datelor asociate cu orice sarcină de inferență (vezi Figura 3).
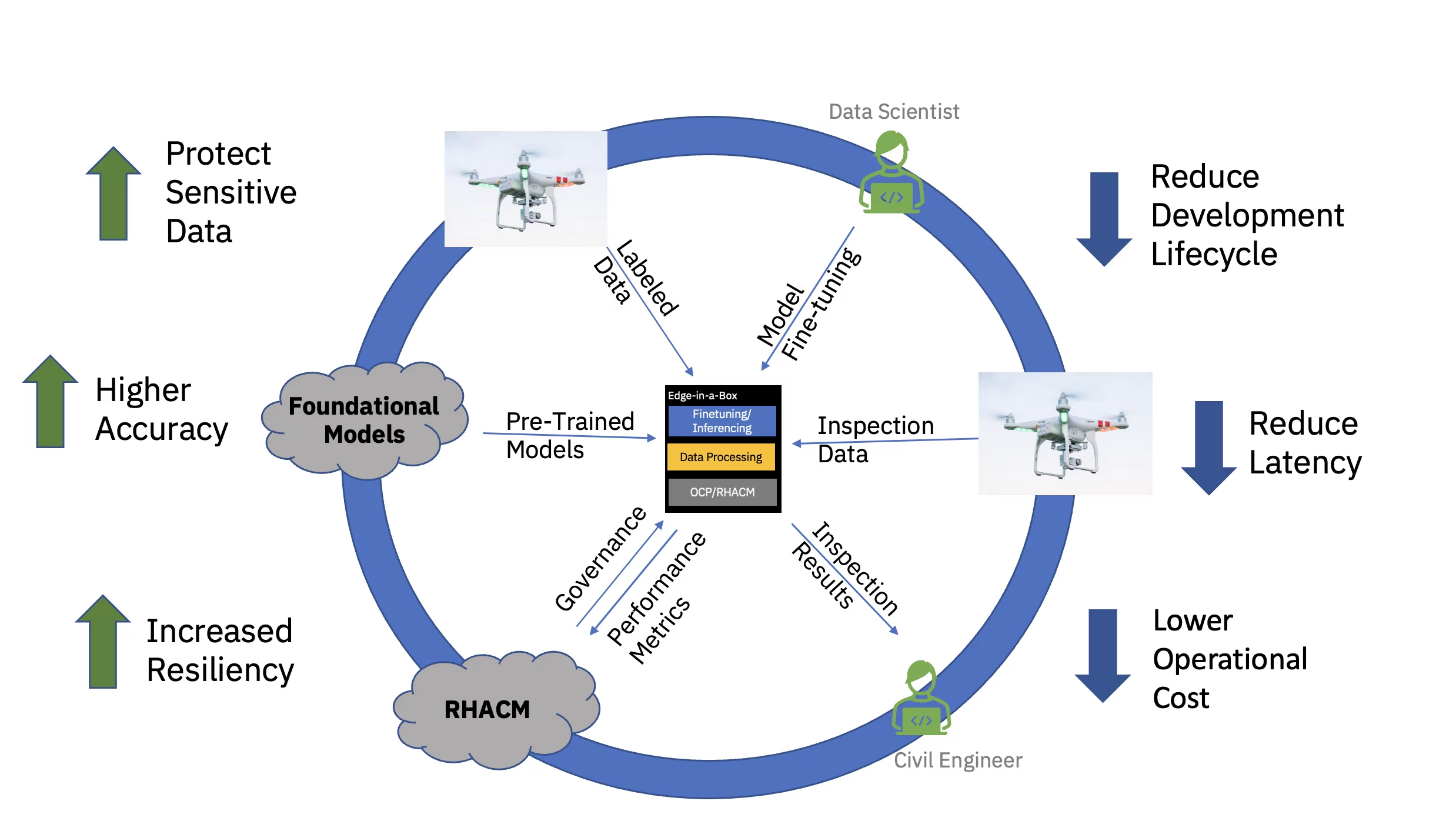
Pentru a demonstra această propunere de valoare de la capăt la capăt, un model de fundație exemplar bazat pe transformator de viziune pentru infrastructura civilă (preformat folosind seturi de date publice și personalizate specifice industriei) a fost reglat fin și implementat pentru inferență pe o margine cu trei noduri. (spoke) cluster. Stiva de software a inclus Red Hat OpenShift Container Platform și Red Hat OpenShift Data Science. Acest cluster edge a fost, de asemenea, conectat la o instanță a hub-ului Red Hat Advanced Cluster Management for Kubernetes (RHACM) care rulează în cloud.
Aprovizionare fără atingere
Provizionarea bazată pe politici, fără atingere, a fost realizată cu Red Hat Advanced Cluster Management for Kubernetes (RHACM) prin politici și etichete de plasare, care leagă anumite clustere de margine la un set de componente și configurații software. Aceste componente software – extinzându-se pe întregul stivă și acoperind calculul, stocarea, rețeaua și sarcina de lucru AI – au fost instalate folosind diverși operatori OpenShift, furnizarea serviciilor de aplicații necesare și S3 Bucket (stocare).
Modelul de bază pregătit (FM) pentru infrastructura civilă a fost ajustat cu ajutorul unui Jupyter Notebook în cadrul Red Hat OpenShift Data Science (RHODS) folosind date etichetate pentru a clasifica șase tipuri de defecte găsite pe podurile de beton. Servirea de inferență a acestui FM reglat fin a fost, de asemenea, demonstrată folosind un server Triton. În plus, monitorizarea stării de sănătate a acestui sistem edge a fost posibilă prin agregarea valorilor de observabilitate de la componentele hardware și software prin intermediul Prometheus la tabloul de bord central RHACM din cloud. Întreprinderile de infrastructură civilă pot implementa aceste FM în locațiile lor marginale și pot folosi imaginile dronei pentru a detecta defectele aproape în timp real, accelerând timpul până la perspectivă și reducând costul deplasării unor volume mari de date de înaltă definiție către și dinspre Cloud.
Rezumat
Combinând IBM watsonx Capacitățile platformei de date și AI pentru modele de bază (FM) cu un dispozitiv edge-in-a-box permit întreprinderilor să ruleze sarcini de lucru AI pentru reglarea fină și inferența FM la marginea operațională. Acest dispozitiv poate gestiona cazuri de utilizare complexe imediate și construiește cadrul centralizat pentru management centralizat, automatizare și autoservire. Implementările Edge FM pot fi reduse de la săptămâni la ore cu succes repetabil, rezistență și securitate mai mari.
Aflați mai multe despre modelele de bază
Asigurați-vă că consultați toate ratele din această serie de postări de blog despre edge computing:
Mai multe de la Cloud




- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :are
- :este
- :nu
- :Unde
- $UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- Despre Noi
- accelera
- acces
- realizat
- precizie
- achiziție
- peste
- Acte
- adaptate
- În plus,
- adresa
- adrese
- Adoptare
- avansat
- progresele
- Promovare
- AI
- Adopție AI
- Modele AI
- Platforma AI
- Ajutorul
- algoritmi
- TOATE
- permite
- permite
- de asemenea
- În mijlocul
- sumă
- Sume
- amp
- an
- analiză
- Google Analytics
- și
- a anunțat
- Orice
- oriunde
- aplicație
- aplicatii
- abordare
- arhitectură
- SUNT
- Mulțime
- articol
- artificial
- inteligență artificială
- Inteligența artificială (AI)
- AS
- asociate
- At
- autor
- Automata
- Automatizare
- disponibil
- Bulevard
- înapoi
- Sold
- Bancă
- Băncile
- de bază
- BE
- deoarece
- deveni
- devenire
- fost
- Început
- fiind
- Crede
- CEL MAI BUN
- lega
- Blog
- Blog
- bloguri
- atât
- Cutie
- poduri
- Aducere
- Aduce
- larg
- in linii mari
- Clădire
- construiește
- construit
- afaceri
- by
- CAN
- capacități
- capital
- capturarea
- carbon
- card
- Carduri
- cazuri
- CAT
- categorii
- Provoca
- Centru
- central
- Banca centrala
- valute digitale ale băncii centrale
- centralizat
- lanţ
- provocări
- Schimbare
- schimbarea
- verifica
- alegeri
- cerc
- CSI
- civil
- clasă
- Clasifica
- clar
- clientii
- îndeaproape
- Cloud
- Grup
- culoare
- colorat
- combinând
- competitiv
- complex
- complexitate
- conformitate
- componente
- Calcula
- tehnica de calcul
- Configuraţie
- configurat
- legat
- Suport conectare
- constă
- Recipient
- continua
- Control
- A costat
- Cheltuieli
- ar putea
- acoperire
- cryptocurrency
- CSS
- Moneda
- personalizat
- client
- experienta clientului
- clienţii care
- tablou de bord
- de date
- Data Center
- Platforma de date
- știința datelor
- om de știință de date
- seturi de date
- Data
- dedicat
- Mod implicit
- Definitii
- livra
- demonstra
- demonstrat
- implementa
- dislocate
- Implementarea
- desfășurarea
- implementări
- descris
- descriere
- proiectat
- dezvolta
- dezvoltat
- Dezvoltare
- digital
- monedele digitale
- digitizare
- Ruptură
- brizant
- disruptive
- distribuite
- cartier
- domeniu
- domenii
- făcut
- conduce
- conducere
- zbârnâi
- fiecare
- uşor
- ecosistem
- Margine
- marginea de calcul
- ELEVATE
- elevat
- permite
- permite
- capăt
- un capăt la altul
- inginer
- Inginerie
- Intrați
- Afacere
- Companii
- care sosește
- Mediu inconjurator
- medii
- Eră
- mai ales
- etc
- Eter (ETH)
- Chiar
- evenimente
- Fiecare
- evoluat
- examinator
- exemple
- a executa
- exista
- Ieşire
- scump
- experienţă
- experți
- AI explicabilă
- explicând
- extindere
- extrem
- factori
- FAST
- mai repede
- puțini
- camp
- Figura
- financiar
- Institutii financiare
- finanțare
- First
- etaje
- urma
- următor
- fonturi
- Pentru
- frunte
- găsit
- Fundație
- fracțiune
- Cadru
- din
- Complet
- Stivă completă
- În plus
- în general
- generată
- generator
- geografice
- Geopolitică
- Oferirea
- Caritate
- Comert global
- guvernare
- GPU
- unități de procesare grafică
- Grilă
- mână
- manipula
- Piese metalice
- pălărie
- Avea
- Sănătate
- înălțime
- ajutor
- ajutor
- ajută
- de înaltă definiție
- superior
- extrem de
- istorie
- gazdă
- ORE
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- Butuc
- Oamenii
- sute
- Hibrid
- Hibrid cloud
- IBM
- IBM Cloud
- ICO
- ICON
- ilustrează
- imagine
- Impactul
- importanță
- îmbunătățire
- in
- include
- inclus
- crescând
- tot mai mult
- index
- industrial
- industrii
- industrie
- specifice industriei
- inflaţiei
- de inflexiune
- Punct de inflexiune
- influențat
- Infrastructură
- Inițiativă
- Inovaţie
- inovatoare
- intrări
- perspective
- instanță
- instituții
- integrate
- Inteligență
- intrinsec
- introducerea
- IT
- Suport IT
- călătoriile
- jpg
- a sari
- Jupiter Notebook
- doar
- doar unul
- ținut
- Cheie
- Kubernetes
- etichetarea
- limbă
- mare
- în mare măsură
- Latență
- Ultimele
- straturi
- conducere
- AFLAȚI
- învăţare
- Pârghie
- ciclu de viață
- ca
- nelimitat
- linux
- local
- localizare
- locaţie
- Locații
- Lung
- Uite
- maşină
- masina de învățare
- făcut
- menține
- face
- FACE
- administra
- administrare
- de fabricaţie
- multe
- marcare
- masiv
- maestru
- materie
- max-width
- mecanisme
- Metode
- Metrici
- minute
- minimizând
- minute
- ML
- Mobil
- model
- Modele
- Modern
- modernizare
- moderniza
- monitor
- Monitorizarea
- mai mult
- mişcare
- în mişcare
- nume
- Navigare
- În apropiere
- necesar
- Nevoie
- necesar
- nevoilor
- reţea
- Nou
- următor
- nlp
- caiet
- nimic
- acum
- număr
- numeroși
- of
- oferind
- de multe ori
- on
- ONE
- afară
- deschide
- deschis
- operațional
- Operațiuni
- Operatorii
- optimizate
- or
- organizație
- Altele
- al nostru
- afară
- global
- ofertele
- pagină
- parametru
- plată
- Metode de plata
- plăți
- efectua
- efectuată
- PHP
- plasare
- platformă
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- conecteaza
- Punct
- Politicile
- Politica
- poziţie
- posibil
- Post
- postări
- potenţial
- putere
- puternic
- Predictii
- anterior
- intimitate
- privat
- probleme
- prelucrare
- produce
- profesional
- propunere
- furniza
- public
- Împinge
- gamă
- repede
- Citind
- în timp real
- recent
- record
- înregistrare
- Roșu
- Red Hat
- reduce
- Redus
- reduce
- reducerea
- regulament
- Autoritățile de reglementare
- autoritățile de reglementare
- legate de
- îndepărtat
- repetabil
- necesita
- necesar
- Cerinţe
- necesar
- cercetare
- Resurse
- răspuns
- responsabil
- sensibil
- cu amănuntul
- Ridica
- roboţi
- Alerga
- funcţionare
- în siguranță
- acelaşi
- scalabilitate
- Scară
- scara ai
- scalare
- Ştiinţă
- Om de stiinta
- Ecran
- script-uri
- Al doilea
- în siguranță,
- securitate
- vedea
- vedere
- selecţie
- Autoservire
- sensibil
- SEO
- Septembrie
- serie
- serverul
- serviciu
- Servicii
- servire
- sesiune
- Sesiunile
- set
- câteva
- Distribuie
- Arăta
- semnificativ
- semnificativ
- asemănător
- întrucât
- Singapore
- singur
- mediu unic
- teren
- Centre de cercetare
- SIX
- aptitudini
- mic
- EMS
- IMM-urile
- Software
- componente software
- soluţie
- suveranitate
- Spaţiu
- tensiune
- specific
- specific
- Sponsorizat
- stivui
- Începe
- de ultimă oră
- şedere
- paşi
- depozitare
- stoca
- stocate
- magazine
- Furtună
- studio
- subiect
- succes
- astfel de
- sugerează
- livra
- lanțului de aprovizionare
- a sustine
- sigur
- sistem
- Lua
- luate
- Sarcină
- sarcini
- tehnici de
- Tehnologia
- Telco
- Temenos
- zeci
- Terraform
- testat
- Testarea
- acea
- lor
- temă
- Acolo.
- Acestea
- ei
- acest
- Prin
- timp
- oportun
- ori
- Titlu
- la
- astăzi
- împreună
- Toolkit
- Unelte
- top
- comerţului
- tradiţional
- Tren
- dresat
- Pregătire
- transfer
- Transforma
- Transformare
- transformări
- transparent
- Triton
- stare de nervozitate
- Două
- tip
- Tipuri
- dezlănțuit
- Actualizează
- actualizări
- URL-ul
- us
- utilizare
- utilizat
- utilizatorii
- folosind
- folosi
- utilizate
- Valoros
- valoare
- valoare propunere
- varietate
- diverse
- Fixă
- de
- Vizualizare
- practic
- volum
- volume
- W
- Aşteptare
- Portofel
- a fost
- Val
- Cale..
- modalități de
- we
- săptămână
- săptămâni
- Ce
- Ce este
- cand
- care
- în timp ce
- OMS
- de ce
- larg
- Gamă largă
- cu
- în
- femeie
- WordPress
- Apartamente
- fluxuri de lucru
- de lucru
- ar
- scris
- Ta
- zephyrnet











