
Pe măsură ce AI migrează de la cloud la Edge, vedem că tehnologia este utilizată într-o varietate în continuă extindere de cazuri de utilizare – de la detectarea anomaliilor la aplicații, inclusiv cumpărături inteligente, supraveghere, robotică și automatizare a fabricilor. Prin urmare, nu există o soluție unică. Dar, odată cu creșterea rapidă a dispozitivelor compatibile cu camere, AI a fost adoptată cel mai pe scară largă pentru analiza datelor video în timp real pentru a automatiza monitorizarea video pentru a spori siguranța, a îmbunătăți eficiența operațională și a oferi clienților experiențe mai bune, câștigând în cele din urmă un avantaj competitiv în industriile lor. . Pentru a susține mai bine analiza video, trebuie să înțelegeți strategiile de optimizare a performanței sistemului în implementările edge AI.
- Selectarea motoarelor de calcul dimensionate pentru a atinge sau depăși nivelurile de performanță necesare. Pentru o aplicație AI, aceste motoare de calcul trebuie să îndeplinească funcțiile întregii conducte de viziune (adică, pre- și post-procesare video, deducere a rețelei neuronale).
Poate fi necesar un accelerator AI dedicat, indiferent dacă este discret sau integrat într-un SoC (spre deosebire de rularea inferenței AI pe un CPU sau GPU).
- Înțelegerea diferenței dintre debit și latență; prin care debitul este rata cu care datele pot fi procesate într-un sistem, iar latența măsoară întârzierea procesării datelor prin sistem și este adesea asociată cu capacitatea de răspuns în timp real. De exemplu, un sistem poate genera date de imagine la 100 de cadre pe secundă (debit), dar este nevoie de 100 ms (latență) pentru ca o imagine să treacă prin sistem.
- Luând în considerare capacitatea de a scala cu ușurință performanța AI în viitor pentru a se adapta nevoilor în creștere, cerințelor în schimbare și tehnologiilor în evoluție (de exemplu, modele AI mai avansate pentru funcționalitate și acuratețe sporite). Puteți realiza scalarea performanței folosind acceleratoare AI în format modul sau cu cipuri suplimentare de accelerare AI.
Cerințele reale de performanță depind de aplicație. De obicei, ne putem aștepta ca, pentru analiza video, sistemul trebuie să proceseze fluxurile de date care vin de la camere la 30-60 de cadre pe secundă și cu o rezoluție de 1080p sau 4k. O cameră compatibilă cu AI ar procesa un singur flux; un dispozitiv edge ar procesa mai multe fluxuri în paralel. În ambele cazuri, sistemul edge AI trebuie să accepte funcțiile de preprocesare pentru a transforma datele senzorului camerei într-un format care să corespundă cerințelor de intrare ale secțiunii de inferență AI (Figura 1).
Funcțiile de preprocesare preiau datele brute și efectuează sarcini precum redimensionarea, normalizarea și conversia spațiului de culoare, înainte de a introduce intrarea în modelul care rulează pe acceleratorul AI. Preprocesarea poate folosi biblioteci eficiente de procesare a imaginilor, cum ar fi OpenCV, pentru a reduce timpii de preprocesare. Postprocesarea implică analiza rezultatului inferenței. Utilizează sarcini precum suprimarea non-maximum (NMS interpretează rezultatul majorității modelelor de detectare a obiectelor) și afișarea imaginilor pentru a genera informații utile, cum ar fi casete de delimitare, etichete de clasă sau scoruri de încredere.

Figura 1. Pentru inferența modelului AI, funcțiile de pre- și post-procesare sunt de obicei efectuate pe un procesor de aplicații.
Inferența modelului AI poate avea provocarea suplimentară de a procesa mai multe modele de rețele neuronale pe cadru, în funcție de capacitățile aplicației. Aplicațiile de viziune computerizată implică de obicei mai multe sarcini AI care necesită o serie de modele multiple. În plus, rezultatul unui model este adesea intrarea următorului model. Cu alte cuvinte, modelele dintr-o aplicație depind adesea unele de altele și trebuie executate secvenţial. Setul exact de modele de executat poate să nu fie static și poate varia dinamic, chiar și cadru cu cadru.
Provocarea de a rula mai multe modele în mod dinamic necesită un accelerator AI extern cu memorie dedicată și suficient de mare pentru a stoca modelele. Adesea, acceleratorul AI integrat în interiorul unui SoC nu poate gestiona volumul de lucru cu mai multe modele din cauza constrângerilor impuse de subsistemul de memorie partajată și de alte resurse din SoC.
De exemplu, urmărirea obiectelor bazată pe predicția mișcării se bazează pe detectări continue pentru a determina un vector care este utilizat pentru a identifica obiectul urmărit într-o poziție viitoare. Eficacitatea acestei abordări este limitată deoarece îi lipsește capacitatea reală de reidentificare. Cu predicția mișcării, traseul unui obiect se poate pierde din cauza detectărilor ratate, a ocluziilor sau a părăsirii obiectului din câmpul vizual, chiar și pentru moment. Odată pierdut, nu există nicio modalitate de a reasocia urma obiectului. Adăugarea reidentificării rezolvă această limitare, dar necesită încorporarea unui aspect vizual (adică, o amprentă a imaginii). Înglobarea aspectului necesită o a doua rețea pentru a genera un vector caracteristic prin procesarea imaginii conținute în interiorul cutiei de delimitare a obiectului detectat de prima rețea. Această încorporare poate fi folosită pentru a reidentifica obiectul din nou, indiferent de timp sau spațiu. Deoarece înglobările trebuie generate pentru fiecare obiect detectat în câmpul vizual, cerințele de procesare cresc pe măsură ce scena devine mai aglomerată. Urmărirea obiectelor cu reidentificare necesită o analiză atentă între efectuarea detectării de înaltă precizie/rezoluție înaltă/rată de cadre ridicate și rezervarea unei supraîncărcări suficiente pentru scalabilitatea înglobărilor. O modalitate de a rezolva cerința de procesare este utilizarea unui accelerator AI dedicat. După cum am menționat mai devreme, motorul AI al SoC poate suferi de lipsa resurselor de memorie partajată. Optimizarea modelului poate fi folosită și pentru a reduce cerințele de procesare, dar ar putea afecta performanța și/sau acuratețea.
Într-o cameră inteligentă sau un dispozitiv edge, SoC integrat (adică, procesorul gazdă) achiziționează cadrele video și efectuează pașii de preprocesare pe care i-am descris mai devreme. Aceste funcții pot fi efectuate cu nucleele CPU sau GPU ale SoC (dacă este disponibil), dar pot fi realizate și de acceleratoare hardware dedicate în SoC (de exemplu, procesor de semnal de imagine). După ce acești pași de preprocesare sunt finalizați, acceleratorul AI care este integrat în SoC poate accesa direct această intrare cuantificată din memoria sistemului sau, în cazul unui accelerator AI discret, intrarea este apoi livrată pentru inferență, de obicei peste Interfață USB sau PCIe.
Un SoC integrat poate conține o serie de unități de calcul, inclusiv procesoare, GPU-uri, accelerator AI, procesoare de viziune, codificatoare/decodore video, procesor de semnal de imagine (ISP) și multe altele. Toate aceste unități de calcul partajează aceeași magistrală de memorie și, în consecință, au acces la aceeași memorie. În plus, procesorul și GPU-ul ar putea avea, de asemenea, să joace un rol în inferență, iar aceste unități vor fi ocupate să execute alte sarcini într-un sistem implementat. Aceasta este ceea ce înțelegem prin overhead la nivel de sistem (Figura 2).
Mulți dezvoltatori evaluează în mod eronat performanța acceleratorului AI încorporat în SoC, fără a lua în considerare efectul supraîncărcării la nivel de sistem asupra performanței totale. De exemplu, luați în considerare rularea unui benchmark YOLO pe un accelerator 50 TOPS AI integrat într-un SoC, care ar putea obține un rezultat de referință de 100 de inferențe/secundă (IPS). Dar într-un sistem desfășurat cu toate celelalte unități de calcul active, acele 50 de TOPS s-ar putea reduce la ceva de genul 12 TOPS, iar performanța generală ar produce doar 25 IPS, presupunând un factor de utilizare generos de 25%. Suprafața sistemului este întotdeauna un factor dacă platforma procesează continuu fluxuri video. Alternativ, cu un accelerator AI discret (de exemplu, Kinara Ara-1, Hailo-8, Intel Myriad X), utilizarea la nivel de sistem ar putea fi mai mare de 90%, deoarece odată ce SoC gazdă inițiază funcția de inferență și transferă intrarea modelului AI date, acceleratorul rulează autonom utilizând memoria sa dedicată pentru accesarea greutăților și parametrilor modelului.
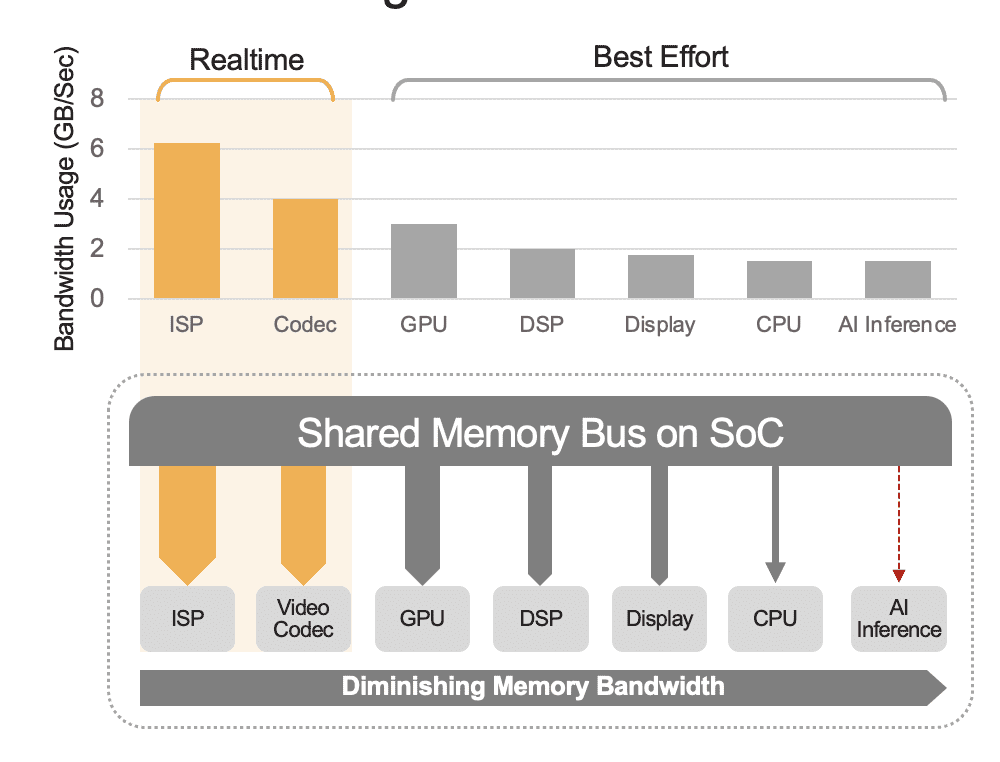
Figura 2. Bus-ul de memorie partajată va guverna performanța la nivel de sistem, prezentată aici cu valori estimate. Valorile reale vor varia în funcție de modelul de utilizare a aplicației și de configurația unității de calcul a SoC.
Până în acest moment, am discutat despre performanța AI în termeni de cadre pe secundă și TOPS. Dar latența scăzută este o altă cerință importantă pentru a oferi un sistem de răspuns în timp real. De exemplu, în jocuri, latența scăzută este esențială pentru o experiență de joc perfectă și receptivă, în special în jocurile controlate prin mișcare și sistemele de realitate virtuală (VR). În sistemele de conducere autonomă, latența scăzută este vitală pentru detectarea obiectelor în timp real, recunoașterea pietonilor, detectarea benzii și recunoașterea semnelor de circulație pentru a evita compromiterea siguranței. Sistemele de conducere autonomă necesită, de obicei, o latență de la capăt la capăt de mai puțin de 150 ms de la detectare la acțiunea reală. În mod similar, în producție, latența scăzută este esențială pentru detectarea defectelor în timp real, recunoașterea anomaliilor și ghidarea robotizată depind de analiza video cu latență scăzută pentru a asigura o funcționare eficientă și pentru a minimiza timpul de oprire a producției.
În general, există trei componente ale latenței într-o aplicație de analiză video (Figura 3):
- Latența de captare a datelor este timpul de la senzorul camerei care captează un cadru video până la disponibilitatea cadrului către sistemul de analiză pentru procesare. Puteți optimiza această latență alegând o cameră cu un senzor rapid și procesor cu latență scăzută, selectând rate optime de cadre și utilizând formate eficiente de compresie video.
- Latența transferului de date este timpul în care datele video capturate și comprimate se deplasează de la cameră la dispozitivele de vârf sau serverele locale. Aceasta include întârzierile de procesare a rețelei care apar la fiecare punct final.
- Latența de procesare a datelor se referă la timpul în care dispozitivele de vârf pentru a efectua sarcini de procesare video, cum ar fi decompresia cadrelor și algoritmii de analiză (de exemplu, urmărirea obiectelor bazată pe predicția mișcării, recunoașterea feței). După cum sa subliniat mai devreme, latența de procesare este și mai importantă pentru aplicațiile care trebuie să ruleze mai multe modele AI pentru fiecare cadru video.
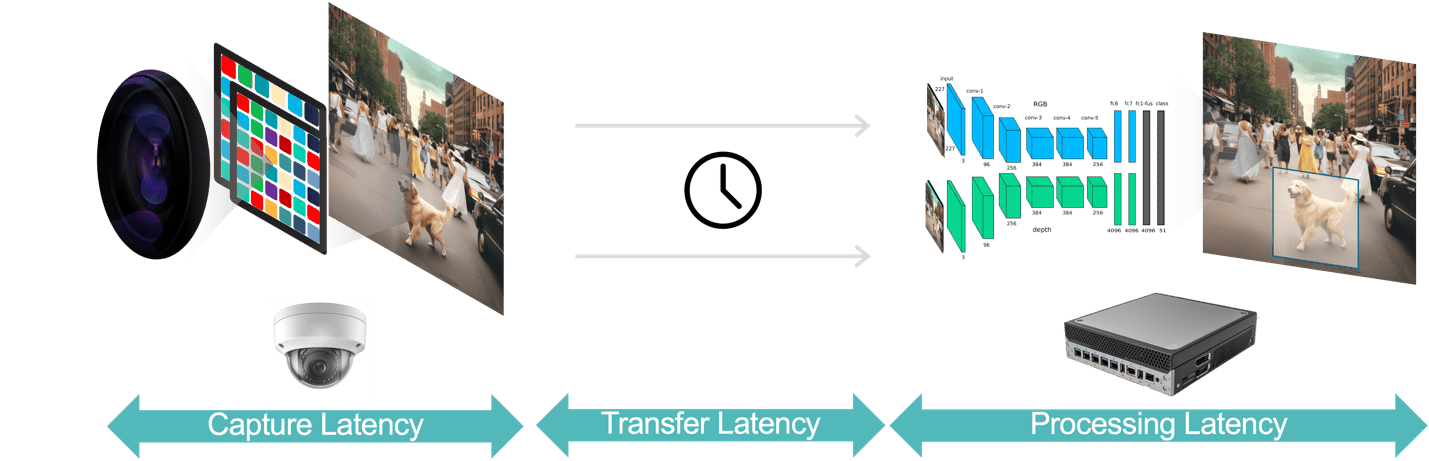
Figura 3. Conducta de analiză video constă din captarea datelor, transferul și procesarea datelor.
Latența de procesare a datelor poate fi optimizată folosind un accelerator AI cu o arhitectură concepută pentru a minimiza mișcarea datelor pe cip și între calcul și diferite niveluri ale ierarhiei memoriei. De asemenea, pentru a îmbunătăți latența și eficiența la nivel de sistem, arhitectura trebuie să suporte timp de comutare zero (sau aproape de zero) între modele, pentru a susține mai bine aplicațiile cu mai multe modele despre care am discutat mai devreme. Un alt factor atât pentru performanța îmbunătățită, cât și pentru latența se referă la flexibilitatea algoritmică. Cu alte cuvinte, unele arhitecturi sunt concepute pentru un comportament optim numai pe anumite modele AI, dar odată cu mediul AI în schimbare rapidă, apar noi modele pentru performanță mai mare și precizie mai bună în ceea ce pare la două zile. Prin urmare, selectați un procesor AI de vârf fără restricții practice privind topologia modelului, operatori și dimensiune.
Există mulți factori care trebuie luați în considerare în maximizarea performanței într-un dispozitiv AI de vârf, inclusiv cerințele de performanță și latență și supraîncărcarea sistemului. O strategie de succes ar trebui să ia în considerare un accelerator AI extern pentru a depăși limitările de memorie și performanță din motorul AI al SoC.
CH Chee este un director de marketing și management al produselor, Chee are o experiență vastă în promovarea produselor și soluțiilor în industria semiconductoarelor, concentrându-se pe AI, conectivitate și interfețe video bazate pe viziune pentru mai multe piețe, inclusiv întreprinderi și consumatori. Ca antreprenor, Chee a co-fondat două start-up-uri de semiconductori video care au fost achiziționate de o companie publică de semiconductori. Chee a condus echipe de marketing de produse și îi place să lucreze cu o echipă mică care se concentrează pe obținerea de rezultate excelente.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :are
- :este
- :nu
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- capacitate
- accelerator
- acceleratoare
- acces
- accesarea
- găzdui
- realiza
- precizie
- realizarea
- dobândite
- achiziţionează
- peste
- Acțiune
- activ
- curent
- adăugare
- Suplimentar
- adoptată
- avansat
- După
- din nou
- AI
- Motor AI
- Modele AI
- algoritmică
- algoritmi
- TOATE
- de asemenea
- mereu
- an
- analiză
- Google Analytics
- analiza
- și
- detectarea anomaliilor
- O alta
- aplicație
- aplicatii
- abordare
- arhitectură
- SUNT
- AS
- asociate
- At
- automatizarea
- Automatizare
- autonom
- autonom
- disponibilitate
- disponibil
- evita
- bazat
- bază
- BE
- deoarece
- devine
- fost
- înainte
- fiind
- Benchmark
- Mai bine
- între
- atât
- Cutie
- Dulapuri
- construit-in
- luați autobuzul
- ocupat
- dar
- by
- aparat foto
- camere video
- CAN
- capacități
- capacitate
- captura
- capturat
- capturarea
- atent
- caz
- cazuri
- contesta
- schimbarea
- cip
- Chips
- alegere
- clasă
- Cloud
- culoare
- venire
- companie
- competitiv
- Terminat
- componente
- compromisor
- calcul
- de calcul
- Calcula
- calculator
- Computer Vision
- Aplicații de viziune pe computer
- încredere
- Configuraţie
- Suport conectare
- prin urmare
- Lua în considerare
- considerare
- luate în considerare
- luand in considerare
- constă
- constrângeri
- consumator
- conţine
- conținute
- continuu
- continuu
- Convertire
- ar putea
- Procesor
- critic
- client
- de date
- de prelucrare a datelor
- zi
- dedicat
- întârziere
- întârzieri
- livra
- livrate
- Dependent/ă
- În funcție
- dislocate
- implementări
- descris
- proiectat
- detectat
- Detectare
- Determina
- Dezvoltatorii
- Dispozitive
- diferenţă
- direct
- discutat
- Afişa
- nefuncționare
- conducere
- două
- dinamic
- e
- fiecare
- Mai devreme
- cu ușurință
- Margine
- efect
- eficacitate
- eficiență
- eficiență
- eficient
- oricare
- Încorporarea
- capăt
- un capăt la altul
- Motor
- Motoare
- spori
- asigura
- Afacere
- Întreg
- Antreprenor
- Mediu inconjurator
- esenţial
- estimativ
- evalua
- Chiar
- Fiecare
- evoluție
- exemplu
- depăși
- a executa
- executat
- executiv
- aștepta
- experienţă
- Experiențe
- extensiv
- Experiență vastă
- extern
- Față
- recunoașterea feței
- factor
- factori
- fabrică
- FAST
- Caracteristică
- hrănire
- camp
- Figura
- amprentă digitală
- First
- Flexibilitate
- se concentrează
- concentrându-se
- Pentru
- format
- FRAME
- din
- funcţie
- funcționalitate
- funcții
- În plus
- viitor
- câștigă
- Jocuri
- jocuri
- experiență de joc
- General
- genera
- generată
- generos
- Go
- GPU
- unități de procesare grafică
- mare
- mai mare
- În creştere
- Creștere
- îndrumare
- Piese metalice
- Avea
- prin urmare
- aici
- ierarhie
- Înalt
- superior
- gazdă
- HTTPS
- i
- identifica
- if
- imagine
- Impactul
- important
- impusă
- îmbunătăţi
- îmbunătățit
- in
- În altele
- include
- Inclusiv
- Crește
- a crescut
- industrii
- industrie
- Initiaza
- intrare
- în interiorul
- perspective
- integrate
- Intel
- interfaţă
- interfeţe
- în
- implica
- implică
- indiferent
- ISP
- IT
- ESTE
- KDnuggets
- etichete
- lipsă
- Bandă
- mare
- Latență
- lăsând
- Led
- mai puțin
- nivelurile de
- biblioteci
- ca
- limitare
- limitări
- Limitat
- local
- pierdut
- Jos
- LOWER
- administra
- administrare
- de fabricaţie
- multe
- Marketing
- pieţe
- Maximaliza
- maximizarea
- Mai..
- însemna
- măsuri
- Întâlni
- Memorie
- menționat
- ar putea
- ratat
- model
- Modele
- modul
- Monitorizarea
- mai mult
- cele mai multe
- mişcare
- mişcare
- multiplu
- trebuie sa
- imensitate
- În apropiere
- nevoilor
- reţea
- neural
- rețele neuronale
- Nou
- următor
- Nu.
- obiect
- Detectarea obiectelor
- avea loc
- of
- de multe ori
- on
- dată
- ONE
- afară
- OpenCV
- operaţie
- operațional
- Operatorii
- opus
- optimă
- optimizare
- Optimizați
- optimizate
- optimizarea
- or
- Altele
- afară
- producție
- peste
- global
- Învinge
- Paralel
- parametrii
- în special
- pentru
- efectua
- performanță
- efectuată
- efectuarea
- efectuează
- conducte
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- Joaca
- Punct
- poziţie
- post-procesare
- Practic
- prezicere
- proces
- prelucrate
- prelucrare
- procesor
- procesoare
- Produs
- producere
- Produse
- Promovarea
- furniza
- public
- gamă
- variind
- rapid
- repede
- rată
- tarife
- Crud
- date neprelucrate
- real
- în timp real
- Realitate
- recunoaştere
- reduce
- se referă
- necesita
- necesar
- cerință
- Cerinţe
- Necesită
- Rezoluţie
- Resurse
- sensibil
- restricții
- rezultat
- REZULTATE
- robotica
- Rol
- Alerga
- funcţionare
- ruleaza
- Siguranţă
- acelaşi
- scalabilitate
- Scară
- scara ai
- scalare
- scenă
- scorurile
- fără sudură
- Al doilea
- Secțiune
- vedea
- pare
- selectarea
- semiconductor
- set
- Distribuie
- comun
- Cumpărături
- să
- indicat
- semna
- Semnal
- asemănător
- întrucât
- singur
- Mărimea
- mic
- inteligent
- soluţie
- soluţii
- REZOLVAREA
- rezolvă
- unele
- ceva
- Spaţiu
- specific
- start-up-uri
- paşi
- stoca
- strategii
- Strategie
- curent
- fluxuri
- de succes
- astfel de
- suficient
- a sustine
- suprimarea
- supraveghere
- sistem
- sisteme
- Lua
- ia
- sarcini
- echipă
- echipe
- Tehnologii
- Tehnologia
- termeni
- decât
- acea
- Viitorul
- lor
- apoi
- Acolo.
- prin urmare
- Acestea
- ei
- acest
- aceste
- trei
- Prin
- debit
- timp
- ori
- la
- Bluze
- Total
- urmări
- Urmărire
- trafic
- transfer
- Transferuri
- Transforma
- călătorie
- adevărat
- Două
- tipic
- în cele din urmă
- incapabil
- înţelege
- unitate
- de unităţi
- Folosire
- USB
- utilizare
- utilizat
- utilizări
- folosind
- obișnuit
- Utilizand
- Valori
- varietate
- diverse
- Video
- Vizualizare
- Virtual
- Realitate virtuala
- viziune
- vital
- vr
- Cale..
- we
- au fost
- Ce
- dacă
- care
- pe larg
- voi
- cu
- fără
- cuvinte
- de lucru
- ar
- X
- Randament
- Yolo
- tu
- Ta
- zephyrnet
- zero







