Introducere în învățarea automată a mașinilor
AutoML le permite dezvoltatorilor cu expertiză ML limitată (și experiență de codare) să antreneze modele de înaltă calitate specifice nevoilor lor de afaceri. Pentru acest articol, ne vom concentra pe sistemele AutoML care se adresează aplicațiilor de afaceri și tehnologice de zi cu zi.

Ce sunt sistemele AutoML?
Învățarea automată (ML) – ca un subdomeniu al domeniului mai larg al inteligenței artificiale (AI) – preia toate tipurile de industrii și domenii de afaceri. Aceasta include comerțul cu amănuntul, asistența medicală, auto, finanțe, divertisment și multe altele. Cu această adoptare mai largă în toate tipurile de operațiuni și de către o forță de muncă cu un set divers de abilități, învățarea cum să lucrați cu învățarea automată devine din ce în ce mai importantă.
Datorită acestei extinderi a utilizării ML de către secţiune transversală în continuă creştere a angajaţilor dintr-o organizaţie, a devenit esențial să se dezvolte sisteme care să poată fi utilizate de profesioniștii din mediul de afaceri de toate tipurile. Și asta înseamnă aceste sisteme nu poate fi orientat exclusiv spre codificare sau programare precum cele folosite de inginerii software sau de cercetătorii de date.
Aici intră în imagine sistemele AutoML.
Pe scurt, AutoML permite dezvoltatori cu expertiză limitată în ML (și experiență de codificare) pentru a instrui modele de înaltă calitate specifice acestora nevoi de afaceri. Există și alte aspecte ale AutoML din punct de vedere a cercetării academice (adică căutarea celor mai buni algoritmi ML pentru anumite tipuri de date și demonstrarea proprietăților teoretice despre astfel de sisteme); dar pentru acest articol, ne vom concentra pe sistemele AutoML care se adresează aplicațiilor de afaceri și tehnologice de zi cu zi.
De ce sistemele AutoML câștigă popularitate?
După cum am menționat mai sus, profesioniști din tot felul de medii și seturi de abilități intră în domeniul științei datelor și al învățării automate pentru afacerile lor respective sau activitățile de cercetare și dezvoltare. Nu toți au un fundal riguros sau o pregătire formală în științe statistice sau teoria învățării automate.
Trebuie doar să fie capabili să obțină sau să ingereze un set de date, să urmeze un flux de lucru complet de explorare a datelor și de formare a modelului și să producă un model antrenat pentru o aplicație ML în aval.
Ar fi mai mult consumă timp din partea lor, dacă trebuie să facă toate acestea singuri:
- caută prin toți algoritmii ML posibili,
- evaluează-le pe setul de date de antrenament,
- verificați performanța setului de validare într-o manieră riguroasă,
- aplicați o judecată suplimentară (memorie și amprenta CPU) pentru a selecta cel mai bun model pentru aplicația finală.
Sistemele AutoML, în mare măsură, fac toate acestea sarcini grele pentru oamenii de știință de date sau analiști și automatizează sau eficientizează generarea de modele ML instruite înalt optimizate pentru utilizare gata de producție.
În consecință, aceste sisteme câștigă popularitate în rândul organizațiilor care folosesc intens știința datelor deoarece:
- economisiți costul personalului organizației și numărul de angajați, deoarece o forță de muncă relativ slabă poate utiliza astfel de sisteme pentru a instrui și optimiza un număr mare de modele ML
- reduceți șansa de eroare prin automatizarea nu numai a pregătirii și optimizarii modelului, ci și a așa-numitelor aspecte plictisitoare ale științei datelor (adică asimilarea datelor, analizarea, disputele și explorarea caracteristicilor în mare măsură)
- reduceți timpul de lansare pe piață pentru un procent mare de aplicații bazate pe ML cu un standard de performanță relativ ridicat
În ceea ce privește timpul de lansare pe piață, se poate argumenta că rezultatul final produs de un sistem AutoML poate să nu fie la fel de performant sau optimizat în comparație cu cel proiectat de un inginer expert ML (folosind ingineria de caracteristici realizată manual sau reglarea deep learning). ).
Cu toate acestea, acest tip de reglare manuală este adesea un proces care consumă mult timp și, în majoritatea situațiilor, ajungerea la un statut de pregătire pentru producție cu un model ML decent într-un timp relativ mai scurt este mult mai critic pentru o organizație decât pierderea timpului. pentru producerea celui mai performant model absolut. Sistemele AutoML ajută organizațiile să atingă acest obiectiv critic de afaceri, de unde popularitatea crescândă și adoptarea pe scară largă.
Acum organizațiile pot obține pur și simplu stații de lucru personalizate de învățare automată pentru forța lor de muncă, instalează instrumente precum AutoML pentru a dezvolta rapid un sistem funcțional bazat pe învățarea automată și a merge mai departe cu următorii pași în producția pregătită pentru AI pentru a ieși pe piață cu rezultatele lor mai rapid ca niciodată.
Tipuri de sisteme AutoML și câteva exemple proeminente
Există destul de multe tipuri diferite de sisteme AutoML, deoarece acestea se adresează diferitelor categorii de sarcini într-o știință a datelor sau flux de lucru ML.
Unele tipuri de sisteme AutoML includ:
- AutoML pentru reglarea automată a parametrilor (un tip relativ de bază)
- AutoML pentru învățare non-profundă, de exemplu, Auto-Sklearn. Acest tip este aplicat în principal în preprocesarea datelor, analiza automată a caracteristicilor, detectarea automată a caracteristicilor, selecția automată a caracteristicilor și selecția automată a modelului.
- AutoML pentru deep learning/rețele neuronale, inclusiv sisteme concepute special pentru căutarea arhitecturii neuronale (NAS), precum și pachete de utilitate precum AutoKeras construit pe baza cadrului de învățare profundă foarte popular.
Auto-Sklearn
După cum sugerează și numele, Auto-Sklearn este un pachet software automatizat de învățare automată construit pe scikit-learn. Auto-Sklearn eliberează un cercetător de date de sarcina de selectare a algoritmului și de reglare a hiper-parametrilor. În esență, caută automat algoritmul de învățare potrivit pentru un nou set de date de învățare automată și își optimizează hiperparametrii.
Acesta extinde ideea de a configura un cadru general de învățare automată cu optimizare globală eficientă, care a fost introdus cu Auto-WEKA. Pentru a îmbunătăți generalizarea, Auto-Sklearn construiește un ansamblu de toate modelele testat în timpul procesului de optimizare globală. Pentru a accelera procesul de optimizare, Auto-Sklearn folosește meta-învățare pentru a identifica seturi de date similare și pentru a utiliza cunoștințe adunate în trecut.
Include metode de inginerie a caracteristicilor, cum ar fi codificare one-hot, standardizarea caracteristicilor digitale și analiza componentelor principale (PCA). În esență, biblioteca folosește estimatori scikit-learn pentru a procesa probleme de clasificare și regresie.

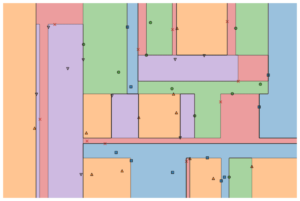
Flux de lucru și diagramă Auto-Sklearn
Documentație: Puteți găsi documentație detaliată aici.
Exemplu de cod: Aici arătăm un exemplu de cod de sarcină de clasificare de bază cu Auto-Sklearn. Construim un model ML pentru clasificarea cifrelor numerice folosind un set de date încorporat în pachetul scikit-learn.
import autosklearn.classification
import sklearn.model_selection
import sklearn.datasets
import sklearn.metrics if __name__ == "__main__": X, y = sklearn.datasets.load_digits(return_X_y=True) X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, random_state=1) automl = autosklearn.classification.AutoSklearnClassifier() automl.fit(X_train, y_train) y_hat = automl.predict(X_test) print("Accuracy score", sklearn.metrics.accuracy_score(y_test, y_hat))Notă despre sistemul de operare: Auto-Sklearn se bazează în mare măsură pe resursa modulului Python. Acest modul face parte din serviciile specifice Unix ale Python și nu este disponibil pe o mașină Windows. Prin urmare, de astăzi, nu este posibil să rulați auto-sklearn pe o mașină Windows.
Solutii posibile:
- Windows 10 bash shell (consultați 431 și 860 pentru sugestii)
- Mașină virtuală
- Imagine Docker
MLBox

MLBox este o bibliotecă Python puternică de învățare automată automată. Conform documentației oficiale, acesta oferă următoarele caracteristici:
- Citire rapidă și preprocesare/curățare/formatare a datelor distribuite
- Selectare foarte robustă a caracteristicilor și detectarea scurgerilor, precum și optimizare precisă a hiper-parametrilor
- Modele predictive de ultimă generație pentru clasificare și regresie (Deep Learning, Stacking, LightGBM)
- Predicția cu interpretarea modelului
- MLBox a fost testat pe Kaggle și arată performanțe bune
- Clădirea conductei
TPOT

TPOT este un instrument Python Automated Machine Learning care optimizează conductele de învățare automată folosind programarea genetică. De asemenea, este construit pe baza scikit-learn.

Exemplu de conductă TPOT (de la https://epistasislab.github.io/tpot/)
Documentație: Aici este link de documentare.
Exemplu de cod:
from tpot import TPOTClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data.astype(np.float64), iris.target.astype(np.float64), train_size=0.75, test_size=0.25, random_state=42) tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_iris_pipeline.py')
AutoKeras
AutoKeras este o bibliotecă de software open-source pentru învățarea automată automatizată dezvoltată de DATA Lab de la Universitatea Texas A&M. Construit pe baza cadrului de învățare profundă Keras, AutoKeras oferă funcții pentru a căuta automat arhitectura și hiper-parametrii modelelor de deep learning.
AutoKeras urmează designul clasic scikit-learn API și, prin urmare, este ușor de utilizat. Scopul acestui cadru este de a simplifica practica și cercetarea ML prin utilizarea automată Căutare arhitectură neuronală (NAS) algoritmi.
Documentație: Aici este detaliat link de documentare.
Exemplu de cod: Iată un exemplu de cod exemplu pentru sarcina de clasificare a imaginilor MNIST.
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import mnist
import autokeras as ak # Data loading
(x_train, y_train), (x_test, y_test) = mnist.load_data() # Initialize the image classifier.
clf = ak.ImageClassifier(overwrite=True, max_trials=1)
# Feed the image classifier with training data.
clf.fit(x_train, y_train, epochs=10) # Predict with the best model.
predicted_y = clf.predict(x_test)
print(predicted_y) # Evaluate the best model with testing data.
print(clf.evaluate(x_test, y_test))Rezumatul sistemelor AutoML și importanța lor
În acest articol, am început prin a explica ideea de bază din spatele cadrelor ML automatizate sau așa-numitele sisteme AutoML. Am descris utilitatea lor și de ce câștigă tracțiune în diverse organizații de afaceri și tehnologie. De asemenea, am prezentat câteva biblioteci și cadre AutoML proeminente cu exemple de cod relevante și ilustrații de arhitectură, după caz.
Aflarea despre aceste cadre puternice va fi benefică pentru orice viitor cercetător de date, deoarece acestea vor continua să crească în capabilități și utilizare pe scară largă.
Anunțați-ne despre orice subiecte care vă interesează lăsând un comentariu mai jos sau nu ezitați Contacteaza-ne oricând cu întrebările pe care le aveți.
Bio: Kevin Vu gestionează blogul Exxact Corp și lucrează cu mulți dintre autorii săi talentați care scriu despre diferite aspecte ale Deep Learning.
Original. Repostat cu permisiunea.
Related:
| Povestiri de top trecute 30 de zile | |||
|---|---|---|---|
|
|||
Sursa: https://www.kdnuggets.com/2021/09/introduction-automated-machine-learning.html
- "
- &
- 9
- Absolut
- activităţi de
- Suplimentar
- Adoptare
- AI
- Algoritmul
- algoritmi
- TOATE
- printre
- analiză
- api
- aplicație
- aplicatii
- Apps
- arhitectură
- Artă
- articol
- inteligență artificială
- Inteligența artificială (AI)
- Autorii
- Auto
- Automata
- învățare automată automată
- auto
- CEL MAI BUN
- Blog
- construi
- Clădire
- afaceri
- clasificare
- cod
- Codificare
- venire
- Comun
- component
- continua
- Corp
- de date
- știința datelor
- om de știință de date
- învățare profundă
- Amenajări
- Detectare
- dezvolta
- Dezvoltatorii
- digital
- cifre
- domenii
- de angajați
- inginer
- Inginerie
- inginerii
- Divertisment
- Excel
- expansiune
- experienţă
- explorare
- Caracteristică
- DESCRIERE
- Figura
- finanţa
- First
- Concentra
- urma
- Înainte
- Cadru
- Gratuit
- General
- GitHub
- Caritate
- bine
- Crește
- de asistență medicală
- aici
- Cum
- Cum Pentru a
- HTTPS
- idee
- identifica
- imagine
- Inclusiv
- industrii
- Inteligență
- IT
- keras
- mare
- scăpa
- învăţare
- Bibliotecă
- Limitat
- masina de învățare
- Piață
- Metrici
- Microsoft
- ML
- Algoritmi ML
- model
- muta
- rețele
- neural
- rețele neuronale
- oficial
- Operațiuni
- comandă
- Altele
- performanță
- imagine
- Punct de vedere
- Popular
- postări
- Principal
- Produs
- producere
- profesioniști
- Programare
- proiect
- Piton
- C&D
- RE
- Citind
- regres
- cercetare
- resursă
- REZULTATE
- cu amănuntul
- Alerga
- Ştiinţă
- ȘTIINȚE
- oamenii de stiinta
- Caută
- Servicii
- set
- Coajă
- Pantaloni scurți
- aptitudini
- Software
- soluţii
- viteză
- Rotire
- început
- Stare
- Istorii
- sistem
- sisteme
- Ţintă
- Tehnologia
- tensorflow
- Testarea
- Texas
- timp
- top
- subiecte
- Pregătire
- us
- utilitate
- Vizualizare
- web
- OMS
- ferestre
- Apartamente
- flux de lucru
- Forta de munca
- fabrică
- X