Imagine de autor
Multe modele avansate de învățare automată, cum ar fi păduri aleatorii sau algoritmi de creștere a gradientului, cum ar fi XGBoost, CatBoost sau LightGBM (și chiar autoencoderi!) se bazează pe un ingredient comun crucial: cel arborele de decizie!
Fără înțelegerea arborilor de decizie, este imposibil să înțelegi și oricare dintre algoritmii avansați de ambalare sau de creștere a gradientului menționați anterior, ceea ce este o rușine pentru orice om de știință de date! Deci, să demitificăm funcționarea interioară a unui arbore de decizie prin implementarea unuia în Python.
În acest articol, vei învăța
- de ce și cum un arbore de decizie împarte datele,
- câștigul de informații și
- cum să implementați arbori de decizie în Python folosind NumPy.
Puteți găsi codul pe Github-ul meu.
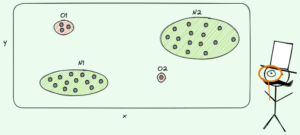
Pentru a face predicții, arborii de decizie se bazează despicare setul de date în părți mai mici într-un mod recursiv.

Imagine de autor
În imaginea de mai sus, puteți vedea un exemplu de împărțire - setul de date original este separat în două părți. În pasul următor, ambele părți se despart din nou și așa mai departe. Aceasta continuă până când este îndeplinit un fel de criteriu de oprire, de exemplu,
- dacă despărțirea are ca rezultat o parte goală
- dacă s-a atins o anumită adâncime de recursivitate
- dacă (după împărțirile anterioare) setul de date constă doar din câteva elemente, făcând inutile divizări ulterioare.
Cum găsim aceste despărțiri? Și de ce ne pasă? Să aflăm.
motivaţia
Să presupunem că vrem să rezolvăm a binar problema de clasificare că noi înșine ne creăm acum:
import numpy as np
np.random.seed(0) X = np.random.randn(100, 2) # features
y = ((X[:, 0] > 0) * (X[:, 1] < 0)) # labels (0 and 1)Datele bidimensionale arată astfel:

Imagine de autor
Putem vedea că există două clase diferite - violet în aproximativ 75% și galben în aproximativ 25% din cazuri. Dacă introduceți aceste date într-un arbore de decizie clasifica, acest arbore are inițial următoarele gânduri:
„Există două etichete diferite, ceea ce este prea dezordonat pentru mine. Vreau să curăț această mizerie împărțind datele în două părți - aceste părți ar trebui să fie mai curate decât datele complete de până acum.” — copac care a căpătat conștiință
Și așa face copacul.

Imagine de autor
Copacul decide să facă o despicare aproximativ de-a lungul x-axă. Acest lucru are ca efect faptul că partea superioară a datelor este acum perfectă curat, adica doar gasesti o singură clasă (violet în acest caz) acolo.
Cu toate acestea, partea de jos este încă dezordonat, chiar mai dezordonat decât înainte într-un sens. Raportul de clasă obișnuia să fie în jur de 75:25 în setul de date complet, dar în această parte mai mică este de aproximativ 50:50, ceea ce este cât se poate de amestecat.
Notă: Aici, nu contează că violetul și galbenul sunt bine separate în imagine. Doar cantitate brută de diferite etichete in cele doua parti conteaza.

Imagine de autor
Totuși, acest lucru este suficient de bun ca prim pas pentru copac și astfel continuă. Deși nu ar crea o altă divizare în partea de sus, curat mai mult, poate crea o altă divizare în partea de jos pentru a o curăța.

Imagine de autor
Și voilà, fiecare dintre cele trei părți separate este complet curată, deoarece găsim doar o singură culoare (etichetă) per parte.
Este foarte ușor să faci predicții acum: dacă apare un nou punct de date, trebuie doar să verifici care dintre ele trei părți minte și da-i culoarea corespunzătoare. Acest lucru funcționează atât de bine acum, deoarece fiecare parte este curat. Ușor, nu?

Imagine de autor
Bine, vorbeam despre curat și dezordonat date, dar până acum aceste cuvinte reprezintă doar o idee vagă. Pentru a implementa orice, trebuie să găsim o modalitate de a defini curăţenie.
Masuri pentru curatenie
Să presupunem că avem niște etichete, de exemplu
y_1 = [0, 0, 0, 0, 0, 0, 0, 0] y_2 = [1, 0, 0, 0, 0, 0, 1, 0]
y_3 = [1, 0, 1, 1, 0, 0, 1, 0]Intuitiv, y₁ este cel mai curat set de etichete, urmat de y₂ și apoi y₃. Până acum, bine, dar cum putem pune cifre pe acest comportament? Poate cel mai ușor lucru care îmi vine în minte este următorul:
Numără doar numărul de zerouri și numărul de unu. Calculați diferența lor absolută. Pentru a-l face mai frumos, normalizați-l prin împărțirea pe lungimea matricelor.
De exemplu, y₂ are 8 intrări în total — 6 zerouri și 2 unități. Prin urmare, ne-am definit personalizat scorul de curățenie ar fi |6 – 2| / 8 = 0.5. Este ușor de calculat acel scor de curățenie y₁ și y₃ sunt 1.0 și, respectiv, 0.0. Aici, putem vedea formula generală:

Imagine de autor
Aici, n₀ și n₁ sunt numerele de zerouri și, respectiv, de unu, n = n₀ + n₁ este lungimea matricei și p₁ = n₁/n este ponderea celor 1 etichete.
Problema cu această formulă este că este special adaptate pentru cazul a două clase, dar de foarte multe ori ne interesează clasificarea multiclasă. O formulă care funcționează destul de bine este Măsurarea impurităților Gini:

Imagine de autor
sau cazul general:

Imagine de autor
Funcționează atât de bine încât scikit-learn a adoptat-o ca măsură implicită pentru ei DecisionTreeClassifier clasă.

Imagine de autor
Notă: Măsoară Gini dezordinea in loc de curatenie. Exemplu: dacă o listă conține doar o singură clasă (=date foarte curate!), atunci toți termenii din sumă sunt zero, deci suma este zero. Cel mai rău caz este dacă toate clasele apar de numărul exact de ori, caz în care Gini este 1–1/C Unde C este numărul de clase.
Acum că avem o măsură pentru curățenie/dezordine, să vedem cum poate fi folosită pentru a găsi despărțiri bune.
Găsirea diviziunilor
Există o mulțime de împărțiri din care alegem, dar care este una bună? Să folosim din nou setul de date inițial, împreună cu măsura de impurități Gini.

Imagine de autor
Nu vom număra punctele acum, dar să presupunem că 75% sunt violet și 25% galben. Folosind definiția lui Gini, impuritatea setului de date complet este

Imagine de autor
Dacă împărțim setul de date de-a lungul x-axa, așa cum sa făcut anterior:

Imagine de autor
partea superioară are o impuritate Gini de 0.0 iar partea de jos

Imagine de autor
În medie, cele două părți au o impuritate Gini de (0.0 + 0.5) / 2 = 0.25, ceea ce este mai bun decât 0.375 al întregului set de date anterior. O putem exprima și în termenii așa-zisului câștig de informații:
Câștigul de informații al acestei împărțiri este 0.375 – 0.25 = 0.125.
Ușor ca asta. Cu cât câștigul de informații este mai mare (adică cu cât impuritatea Gini este mai mică), cu atât mai bine.
Notă: O altă împărțire inițială la fel de bună ar fi de-a lungul axei y.
Un lucru important de reținut este că este util se cântăresc impuritățile Gini ale pieselor după dimensiunea pieselor. De exemplu, să presupunem că
- partea 1 constă din 50 de puncte de date și are o impuritate Gini de 0.0 și
- partea 2 constă din 450 de puncte de date și are o impuritate Gini de 0.5,
atunci impuritatea medie Gini nu ar trebui să fie (0.0 + 0.5) / 2 = 0.25 ci mai degrabă 50 / (50 + 450) * 0.0 + 450 / (50 + 450) * 0.5 = 0.45.
Bine, și cum găsim cea mai bună împărțire? Răspunsul simplu, dar serios este:
Încercați doar toate diviziunile și alegeți-o pe cea cu cel mai mare câștig de informații. Practic, este o abordare cu forță brută.
Pentru a fi mai precis, se folosesc arbori de decizie standard se împarte de-a lungul axelor de coordonate, adică xᵢ = c pentru unele caracteristici i si pragul c. Acest lucru înseamnă că
- o parte a datelor împărțite constă din toate punctele de date x cu xᵢ cși
- cealaltă parte a tuturor punctelor x cu xᵢ ≥ c.
Aceste reguli simple de împărțire s-au dovedit suficient de bune în practică, dar, desigur, puteți extinde această logică pentru a crea alte divizări (adică linii diagonale precum xᵢ + 2xⱼ = 3, de exemplu).
Grozav, acestea sunt toate ingredientele de care avem nevoie pentru a începe acum!
Vom implementa acum arborele de decizie. Deoarece este format din noduri, să definim a Node clasa întâi.
from dataclasses import dataclass @dataclass
class Node: feature: int = None # feature for the split value: float = None # split threshold OR final prediction left: np.array = None # store one part of the data right: np.array = None # store the other part of the dataUn nod cunoaște caracteristica pe care o folosește pentru împărțire (feature), precum și valoarea de împărțire (value). value este folosit și ca stocare pentru predicția finală a arborelui de decizie. Deoarece vom construi un arbore binar, fiecare nod trebuie să-și cunoască copiii din stânga și din dreapta, așa cum sunt stocați left și right .
Acum, să facem implementarea propriu-zisă a arborelui de decizie. Îl fac compatibil cu scikit-learn, de aceea folosesc câteva clase de la sklearn.base . Dacă nu sunteți familiarizat cu asta, consultați articolul meu despre cum să construiți modele compatibile cu scikit-learn.
Să punem în aplicare!
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin class DecisionTreeClassifier(BaseEstimator, ClassifierMixin): def __init__(self): self.root = Node() @staticmethod def _gini(y): """Gini impurity.""" counts = np.bincount(y) p = counts / counts.sum() return (p * (1 - p)).sum() def _split(self, X, y): """Bruteforce search over all features and splitting points.""" best_information_gain = float("-inf") best_feature = None best_split = None for feature in range(X.shape[1]): split_candidates = np.unique(X[:, feature]) for split in split_candidates: left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] information_gain = self._gini(y) - ( len(X_left) / len(X) * self._gini(y_left) + len(X_right) / len(X) * self._gini(y_right) ) if information_gain > best_information_gain: best_information_gain = information_gain best_feature = feature best_split = split return best_feature, best_split def _build_tree(self, X, y): """The heavy lifting.""" feature, split = self._split(X, y) left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] if len(X_left) == 0 or len(X_right) == 0: return Node(value=np.argmax(np.bincount(y))) else: return Node( feature, split, self._build_tree(X_left, y_left), self._build_tree(X_right, y_right), ) def _find_path(self, x, node): """Given a data point x, walk from the root to the corresponding leaf node. Output its value.""" if node.feature == None: return node.value else: if x[node.feature] node.value: return self._find_path(x, node.left) else: return self._find_path(x, node.right) def fit(self, X, y): self.root = self._build_tree(X, y) return self def predict(self, X): return np.array([self._find_path(x, self.root) for x in X])Si asta e! Puteți face toate lucrurile care vă plac la scikit-learn acum:
dt = DecisionTreeClassifier().fit(X, y)
print(dt.score(X, y)) # accuracy # Output
# 1.0Deoarece copacul este neregularizat, este supraadaptat mult, de unde scorul perfect pentru tren. Precizia ar fi mai proastă în cazul datelor nevăzute. De asemenea, putem verifica cum arată copacul prin
print(dt.root) # Output (prettified manually):
# Node(
# feature=1,
# value=-0.14963454032767076,
# left=Node(
# feature=0,
# value=0.04575851730144607,
# left=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# ),
# right=Node(
# feature=None,
# value=1,
# left=None,
# right=None
# )
# ),
# right=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# )
# )Ca imagine, ar fi aceasta:

Imagine de autor
În acest articol, am văzut cum funcționează arborii de decizie în detaliu. Am început cu câteva idei vagi, dar intuitive și le-am transformat în formule și algoritmi. În cele din urmă, am reușit să implementăm un arbore de decizie de la zero.
Totuși, un cuvânt de precauție: arborele nostru de decizie nu poate fi încă regularizat. De obicei, am dori să specificăm parametri precum
- adancime maxima
- dimensiunea frunzelor
- și câștig minim de informații
printre multe altele. Din fericire, aceste lucruri nu sunt atât de greu de implementat, ceea ce face ca aceasta să fie o temă perfectă pentru tine. De exemplu, dacă specificați leaf_size=10 ca parametru, atunci nodurile care conțin mai mult de 10 eșantioane nu ar trebui să mai fie împărțite. De asemenea, această implementare este nu eficient. De obicei, nu ați dori să stocați părți din seturile de date în noduri, ci doar indicii. Deci setul dvs. de date (potențial mare) este în memorie o singură dată.
Lucrul bun este că poți înnebuni acum cu acest șablon de arbore de decizie. Puteți:
- implementați despărțiri diagonale, de ex xᵢ + 2xⱼ = 3 în loc de doar xᵢ = 3,
- schimbați logica care se întâmplă în interiorul frunzelor, adică puteți rula o regresie logistică în fiecare frunză în loc să faceți doar un vot majoritar, ceea ce vă oferă un arbore liniar
- schimbați procedura de împărțire, adică în loc să faceți forță brută, încercați câteva combinații aleatorii și alegeți-o pe cea mai bună, care vă oferă o clasificator extra-arboresc
- şi mai mult.
Dr. Robert Kübler este Data Scientist la Publicis Media și autor la Towards Data Science.
Original. Repostat cu permisiunea.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://www.kdnuggets.com/2023/02/understanding-implementing-decision-tree.html?utm_source=rss&utm_medium=rss&utm_campaign=understanding-by-implementing-decision-tree
- 1
- 10
- 100
- 11
- 28
- 7
- 9
- a
- Capabil
- Despre Noi
- mai sus
- Absolut
- precizie
- avansat
- După
- algoritmi
- TOATE
- sumă
- și
- O alta
- răspunde
- apărea
- abordare
- aproximativ
- în jurul
- Mulțime
- articol
- autor
- in medie
- de bază
- Pe scurt
- deoarece
- înainte
- fiind
- CEL MAI BUN
- Mai bine
- stimularea
- De jos
- brute force
- construi
- nu poti
- pasă
- caz
- cazuri
- sigur
- verifica
- Copii
- Alege
- clasă
- clase
- clasificare
- cod
- culoare
- combinaţii
- Comun
- compatibil
- Completă
- complet
- Calcula
- Constiinta
- continuă
- coordona
- Corespunzător
- înscrie-te la cursul
- crea
- crucial
- de date
- știința datelor
- om de știință de date
- seturi de date
- decizie
- arborele de decizie
- Mod implicit
- adâncime
- detaliu
- diferenţă
- diferit
- dificil
- Nu
- face
- fiecare
- Cel mai simplu
- efect
- element
- suficient de
- Întreg
- la fel de
- Eter (ETH)
- Chiar
- exemplu
- expres
- extinde
- familiar
- Modă
- Caracteristică
- DESCRIERE
- puțini
- final
- Găsi
- First
- pluti
- a urmat
- următor
- Forţarea
- formulă
- din
- mai mult
- Câştig
- General
- obține
- Gini
- Da
- dat
- oferă
- Go
- merge
- bine
- se întâmplă
- aici
- superior
- cea mai mare
- teme pentru acasă
- Cum
- HTML
- HTTPS
- idee
- idei
- punerea în aplicare a
- implementarea
- Punere în aplicare a
- import
- important
- imposibil
- in
- Indici
- informații
- inițială
- inițial
- in schimb
- interesat
- intuitiv
- IT
- KDnuggets
- A pastra
- Copil
- Cunoaște
- Etichetă
- etichete
- mare
- învăţare
- Lungime
- ridicare
- linii
- Listă
- Se pare
- Lot
- dragoste
- maşină
- masina de învățare
- Majoritate
- face
- FACE
- Efectuarea
- manual
- multe
- materie
- mijloace
- măsura
- Mass-media
- Memorie
- minte
- minim
- mixt
- Modele
- mai mult
- Nevoie
- nevoilor
- Nou
- următor
- nod
- noduri
- număr
- numere
- NumPy
- ONE
- comandă
- original
- Altele
- Altele
- parametru
- parametrii
- parte
- piese
- Perfect
- permisiune
- alege
- imagine
- Plato
- Informații despre date Platon
- PlatoData
- Punct
- puncte
- potenţial
- practică
- prezicere
- Predictii
- precedent
- Problemă
- dovedit
- pune
- Piton
- aleator
- raport
- atins
- recursive
- regres
- reprezenta
- respectiv
- REZULTATE
- reveni
- ROBERT
- rădăcină
- norme
- Alerga
- Ştiinţă
- Om de stiinta
- scikit-learn
- Caută
- SELF
- sens
- distinct
- set
- Distribuie
- să
- simplu
- întrucât
- singur
- Mărimea
- mai mici
- So
- până acum
- REZOLVAREA
- unele
- împărţi
- șpalturi
- standard
- început
- Pas
- oprire
- depozitare
- stoca
- stocate
- astfel de
- adaptate
- vorbesc
- șablon
- termeni
- informațiile
- lor
- lucru
- lucruri
- trei
- prag
- Prin
- ori
- la
- împreună
- de asemenea
- top
- Total
- față de
- Tren
- Copaci
- transformat
- înţelege
- înţelegere
- us
- utilizare
- obișnuit
- valoare
- Vot
- care
- în timp ce
- voi
- în
- Cuvânt
- cuvinte
- Apartamente
- lucrări
- fabrică
- Mini rulouri de absorbție
- ar
- X
- XGBoost
- Ta
- zephyrnet
- zero