Importanța depozitelor de date și a analizelor efectuate pe platformele de depozit de date a crescut constant de-a lungul anilor, multe companii ajungând să se bazeze pe aceste sisteme ca fiind esențiale atât pentru luarea deciziilor operaționale pe termen scurt, cât și pentru planificarea strategică pe termen lung. În mod tradițional, depozitele de date sunt reîmprospătate în cicluri batch, de exemplu, lunar, săptămânal sau zilnic, astfel încât companiile să poată obține diverse informații din acestea.
Multe organizații își dau seama că absorbția de date aproape în timp real, împreună cu analiza avansată, deschide noi oportunități. De exemplu, un institut financiar poate prezice dacă o tranzacție cu cardul de credit este frauduloasă prin rularea unui program de detectare a anomaliilor în modul aproape în timp real și nu în modul lot.
În această postare, arătăm cum Amazon RedShift poate oferi asimilare în flux și predicții de învățare automată (ML), toate într-o singură platformă.
Amazon Redshift este un depozit de date cloud rapid, scalabil, securizat și complet gestionat, care face simplă și rentabilă analiza tuturor datelor folosind SQL standard.
Amazon Redshift ML facilitează pentru analiștii de date și dezvoltatorii de baze de date să creeze, să antreneze și să aplice modele ML folosind comenzi SQL familiare în depozitele de date Amazon Redshift.
Suntem încântați să lansăm Amazon Redshift Streaming Ingestion pentru Fluxuri de date Amazon Kinesis și Streaming gestionat de Amazon pentru Apache Kafka (Amazon MSK), care vă permite să ingerați date direct dintr-un flux de date Kinesis sau dintr-un subiect Kafka, fără a fi nevoie să puneți datele în Serviciul Amazon de stocare simplă (Amazon S3). Ingerarea de streaming Amazon Redshift vă permite să obțineți o latență scăzută, de ordinul secundelor, în timp ce ingerați sute de megaocteți de date în depozitul dvs. de date.
Această postare demonstrează modul în care Amazon Redshift, depozitul de date în cloud vă permite să construiți predicții ML aproape în timp real, utilizând absorbția de streaming Amazon Redshift și funcțiile Redshift ML cu limbajul SQL familiar.
Prezentare generală a soluțiilor
Urmând pașii menționați în această postare, veți putea configura o aplicație streamer de producător pe un Cloud Elastic de calcul Amazon (Amazon EC2) instanță care simulează tranzacțiile cu cardul de credit și transmite date către Kinesis Data Streams în timp real. Ați configurat o vizualizare materializată Amazon Redshift Streaming Ingestion pe Amazon Redshift, unde sunt primite date în flux. Antrenați și construiți un model Redshift ML pentru a genera inferențe în timp real împotriva datelor în flux.
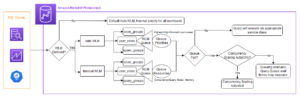
Următoarea diagramă ilustrează arhitectura și fluxul de proces.
Procesul pas cu pas este următorul:
- Instanța EC2 simulează o aplicație de tranzacție cu card de credit, care inserează tranzacții cu cardul de credit în fluxul de date Kinesis.
- Fluxul de date stochează datele tranzacțiilor primite cu cardul de credit.
- O vedere materializată Amazon Redshift Streaming Ingestion este creată deasupra fluxului de date, care ingerează automat date de streaming în Amazon Redshift.
- Creați, antrenați și implementați un model ML folosind Redshift ML. Modelul Redshift ML este antrenat folosind date tranzacționale istorice.
- Transformați datele în flux și generați predicții ML.
- Puteți alerta clienții sau puteți actualiza aplicația pentru a reduce riscul.
Această explicație folosește datele de streaming ale tranzacțiilor cu cardul de credit. Datele tranzacției cu cardul de credit sunt fictive și se bazează pe a Simulator. Setul de date despre clienți este, de asemenea, fictiv și este generat cu unele funcții de date aleatorii.
Cerințe preliminare
- Creați un cluster Amazon Redshift.
- Configurați clusterul pentru a utiliza Redshift ML.
- Crea an Gestionarea identității și accesului AWS utilizator (IAM).
- Actualizați rolul IAM atașat clusterului Redshift pentru a include permisiunile de acces la fluxul de date Kinesis. Pentru mai multe informații despre politica necesară, consultați Începeți cu absorbția în flux.
- Creați o instanță EC5.4 m2xlarge. Am testat aplicația Producer cu instanța m5.4xlarge, dar sunteți liber să utilizați alt tip de instanță. Când creați instanța, utilizați amzn2-ami-kernel-5.10-hvm-2.0.20220426.0-x86_64-gp2 AMI.
- Pentru a vă asigura că Python3 este instalat în instanța EC2, rulați următoarea comandă pentru a verifica versiunea dvs. Python (rețineți că scriptul de extragere a datelor funcționează numai pe Python 3):
- Instalați următoarele pachete dependente pentru a rula programul simulator:
- Configurați Amazon EC2 utilizând variabile precum acreditările AWS generate pentru utilizatorul IAM create la pasul 3 de mai sus. Următoarea captură de ecran arată un exemplu de utilizare configura aws.

Configurați Kinesis Data Streams
Amazon Kinesis Data Streams este un serviciu de streaming de date în timp real, extrem de scalabil și durabil. Poate capta în mod continuu gigaocteți de date pe secundă din sute de mii de surse, cum ar fi fluxurile de clic pe site-uri, fluxurile de evenimente ale bazei de date, tranzacțiile financiare, fluxurile de rețele sociale, jurnalele IT și evenimentele de urmărire a locației. Datele colectate sunt disponibile în milisecunde pentru a permite cazuri de utilizare a analizelor în timp real, cum ar fi tablouri de bord în timp real, detectarea anomaliilor în timp real, prețuri dinamice și multe altele. Folosim Kinesis Data Streams pentru că este o soluție fără server care se poate scala în funcție de utilizare.
Creați un flux de date Kinesis
Mai întâi, trebuie să creați un flux de date Kinesis pentru a primi datele în flux:
- Pe consola Amazon Kinesis, alegeți Fluxuri de date în panoul de navigare.
- Alege Creați flux de date.
- Pentru Numele fluxului de date, introduce
cust-payment-txn-stream. - Pentru Modul de capacitate, Selectați La cerere.

- Pentru restul opțiunilor, alegeți opțiunile implicite și urmați instrucțiunile pentru a finaliza configurarea.
- Capturați ARN-ul pentru fluxul de date creat pentru a-l utiliza în secțiunea următoare când definiți politica IAM.

Configurați permisiunile
Pentru ca o aplicație de streaming să scrie în Kinesis Data Streams, aplicația trebuie să aibă acces la Kinesis. Puteți utiliza următoarea declarație de politică pentru a acorda procesului de simulare pe care l-ați configurat în secțiunea următoare acces la fluxul de date. Utilizați ARN-ul fluxului de date pe care l-ați salvat în pasul anterior.
Configurați producătorul fluxului
Înainte de a putea consuma date de streaming în Amazon Redshift, avem nevoie de o sursă de date de streaming care scrie date în fluxul de date Kinesis. Această postare folosește un generator de date personalizat și SDK AWS pentru Python (Boto3) pentru a publica datele în fluxul de date. Pentru instrucțiuni de configurare, consultați Simulator de producător. Acest proces de simulare publică date în flux în fluxul de date creat în pasul anterior (cust-payment-txn-stream).
Configurați consumatorul de flux
Această secțiune vorbește despre configurarea consumatorului de flux (vizualizarea de asimilare a fluxului Amazon Redshift).
Amazon Redshift Streaming Ingestion oferă o latență scăzută, asimilare de mare viteză a datelor în flux din Kinesis Data Streams într-o vizualizare materializată Amazon Redshift. Puteți configura clusterul dvs. Amazon Redshift pentru a permite asimilarea în flux și pentru a crea o vizualizare materializată cu reîmprospătare automată, folosind instrucțiuni SQL, așa cum este descris în Crearea de vizualizări materializate în Amazon Redshift. Procesul automat de reîmprospătare a vizualizării materializate va ingera date în flux la sute de megaocteți de date pe secundă din Kinesis Data Streams în Amazon Redshift. Acest lucru are ca rezultat accesul rapid la datele externe, care este rapid reîmprospătat.
După crearea vizualizării materializate, vă puteți accesa datele din fluxul de date folosind SQL și vă puteți simplifica conductele de date prin crearea de vizualizări materializate direct deasupra fluxului.
Parcurgeți următorii pași pentru a configura o vizualizare materializată în flux Amazon Redshift:
- Pe consola IAM, alegeți politicile din panoul de navigare.
- Alege Creare politică.
- Creați o nouă politică IAM numită
KinesisStreamPolicy. Pentru definirea politicii de streaming, consultați Începeți cu absorbția în flux. - În panoul de navigare, alegeți Roluri.
- Alegeți Creați rol.
- Selectați Serviciu AWS Și alegeți Redshift și Redshift personalizabile.
- Creați un nou rol numit
redshift-streaming-roleși atașați polițaKinesisStreamPolicy. - Creați o schemă externă pentru a mapa la Kinesis Data Streams:
Acum puteți crea o vedere materializată pentru a consuma datele fluxului. Puteți folosi tipul de date SUPER pentru a stoca încărcătura utilă așa cum este, în format JSON sau puteți utiliza funcțiile Amazon Redshift JSON pentru a analiza datele JSON în coloane individuale. Pentru această postare, folosim a doua metodă deoarece schema este bine definită.
- Creați vizualizarea materializată de asimilare în flux
cust_payment_tx_stream. Specificând AUTO REFRESH YES în următorul cod, puteți activa reîmprospătarea automată a vizualizării de asimilare în flux, ceea ce economisește timp prin evitarea construirii conductelor de date:
Rețineți că json_extract_path_text are o limită de lungime de 64 KB. De asemenea, from_varbye filtrează înregistrările mai mari de 65KB.
- Reîmprospătați datele.
Vizualizarea materializată în flux Amazon Redshift este reîmprospătată automat de Amazon Redshift pentru dvs. În acest fel, nu trebuie să vă faceți griji cu privire la învechirea datelor. Cu reîmprospătarea automată a vizualizării materializate, datele sunt încărcate automat în Amazon Redshift pe măsură ce devin disponibile în flux. Dacă alegeți să efectuați manual această operație, utilizați următoarea comandă:
- Acum, să interogăm vizualizarea materializată în flux pentru a vedea date eșantion:

- Să verificăm acum câte înregistrări sunt în vizualizarea în flux:

Acum ați terminat de configurat vizualizarea de asimilare a fluxului Amazon Redshift, care este actualizată continuu cu datele privind tranzacțiile primite cu cardul de credit. În configurația mea, văd că aproximativ 67,000 de înregistrări au fost extrase în vizualizarea de streaming în momentul în care am executat interogarea de numărare selectată. Acest număr ar putea fi diferit pentru tine.
Redshift ML
Cu Redshift ML, puteți aduce un model ML pre-antrenat sau puteți construi unul nativ. Pentru mai multe informații, consultați Utilizarea învățării automate în Amazon Redshift.
În această postare, antrenăm și construim un model ML folosind un set de date istoric. Datele conțin a tx_fraud câmp care semnalează o tranzacție istorică ca fiind frauduloasă sau nu. Construim un model ML supravegheat folosind Redshift Auto ML, care învață din acest set de date și prezice tranzacțiile primite atunci când acestea sunt rulate prin funcțiile de predicție.
În secțiunile următoare, arătăm cum să configurați setul de date istorice și datele clienților.
Încărcați setul de date istoric
Tabelul istoric are mai multe câmpuri decât are sursa de date în flux. Aceste câmpuri conțin cele mai recente cheltuieli ale clientului și scorul de risc terminal, cum ar fi numărul de tranzacții frauduloase calculate prin transformarea datelor în flux. Există, de asemenea, variabile categorice, cum ar fi tranzacțiile de weekend sau tranzacțiile de noapte.
Pentru a încărca datele istorice, executați comenzile folosind Editor de interogări Amazon Redshift.
Creați tabelul istoric al tranzacțiilor cu următorul cod. DDL-ul poate fi găsit și pe GitHub.
Să verificăm câte tranzacții sunt încărcate:
Verificați tendința lunară a tranzacțiilor frauduloase și non-fraudă:
Creați și încărcați datele clienților
Acum creăm tabelul de clienți și încărcăm datele, care conține e-mailul și numărul de telefon al clientului. Următorul cod creează tabelul, încarcă datele și eșantionează tabelul. Tabelul DDL este disponibil pe GitHub.
Datele noastre de testare au aproximativ 5,000 de clienți. Următoarea captură de ecran arată exemple de date despre clienți.

Construiți un model ML
Tabelul nostru istoric de tranzacții cu carduri are date de 6 luni, pe care acum le folosim pentru a instrui și a testa modelul ML.
Modelul ia ca intrare următoarele câmpuri:
Primim tx_fraud ca ieșire.
Împărțim aceste date în seturi de date de instruire și de testare. Tranzacțiile din 2022-04-01 până în 2022-07-31 sunt pentru setul de instruire. Tranzacțiile din 2022-08-01 până în 2022-09-30 sunt utilizate pentru setul de testare.
Să creăm modelul ML folosind SQL-ul familiar Instrucțiunea CREATE MODEL. Folosim o formă de bază a comenzii Redshift ML. Următoarea metodă folosește Pilot automat cu Amazon SageMaker, care efectuează automat pregătirea datelor, ingineria caracteristicilor, selectarea modelului și antrenamentul. Furnizați numele compartimentului dvs. S3 care conține codul.
Eu numesc modelul ML ca Cust_cc_txn_fd, iar funcția de predicție ca fn_customer_cc_fd. Clauza FROM arată coloanele de intrare din tabelul istoric public.cust_payment_tx_history. Parametrul țintă este setat la tx_fraud, care este variabila țintă pe care încercăm să o anticipăm. IAM_Role este setat ca implicit deoarece clusterul este configurat cu acest rol; dacă nu, trebuie să furnizați ARN-ul rolului IAM al clusterului Amazon Redshift. Am setat max_runtime la 3,600 de secunde, care este timpul pe care îl acordăm lui SageMaker pentru a finaliza procesul. Redshift ML implementează cel mai bun model care este identificat în acest interval de timp.
În funcție de complexitatea modelului și de cantitatea de date, poate dura ceva timp pentru ca modelul să fie disponibil. Dacă descoperiți că selecția dvs. de model nu se finalizează, creșteți valoarea pentru max_runtime. Puteți seta o valoare maximă de 9999.
Comanda CREATE MODEL este rulată asincron, ceea ce înseamnă că rulează în fundal. Puteți folosi ARAȚI MODEL comanda pentru a vedea starea modelului. Când starea arată ca Gata, înseamnă că modelul este antrenat și implementat.
Următoarele capturi de ecran arată rezultatul nostru.



Din rezultat, văd că modelul a fost corect recunoscut ca BinaryClassification, iar F1 a fost selectat ca obiectiv. The Scor F1 este o metrică care ia în considerare ambele precizie și reamintire. Returnează o valoare între 1 (precizie și reamintire perfectă) și 0 (cel mai mic scor posibil). În cazul meu, este 0.91. Cu cât valoarea este mai mare, cu atât performanța modelului este mai bună.
Să testăm acest model cu setul de date de testare. Rulați următoarea comandă, care preia predicții eșantion:

Vedem că unele valori se potrivesc, iar altele nu. Să comparăm predicțiile cu adevărul de bază:

Am validat că modelul funcționează și scorul F1 este bun. Să trecem la generarea de predicții privind datele în flux.
Prevede tranzacțiile frauduloase
Deoarece modelul Redshift ML este gata de utilizat, îl putem folosi pentru a rula predicțiile împotriva ingerării datelor în flux. Setul de date istoric are mai multe câmpuri decât cele pe care le avem în sursa de date în flux, dar sunt doar valori recente și frecvență în jurul clientului și a riscului terminalului pentru o tranzacție frauduloasă.
Putem aplica transformările peste datele de streaming foarte ușor prin încorporarea SQL în interiorul vizualizărilor. Creați prima vedere, care cumulează datele de streaming la nivel de client. Apoi creați a doua vedere, care adună date în flux la nivel de terminal și a treia vedere, care combină datele tranzacționale primite cu datele agregate ale clienților și terminalului și apelează funcția de predicție într-un singur loc. Codul pentru a treia vedere este următorul:
Rulați o instrucțiune SELECT pe vizualizare:
Pe măsură ce rulați declarația SELECT în mod repetat, cele mai recente tranzacții cu cardul de credit trec prin transformări și predicții ML în timp aproape real.
Acest lucru demonstrează puterea Amazon Redshift - cu comenzi SQL ușor de utilizat, puteți transforma datele în flux aplicând funcții complexe de fereastră și aplicați un model ML pentru a prezice tranzacțiile frauduloase într-un singur pas, fără a construi conducte complexe de date sau a crea și gestiona infrastructură suplimentară.
Extinde soluția
Deoarece fluxurile de date și predicțiile ML sunt făcute aproape în timp real, puteți construi procese de afaceri pentru a vă alerta clientul folosind Serviciul de notificare simplă Amazon (Amazon SNS), sau puteți bloca contul cardului de credit al clientului într-un sistem operațional.
Această postare nu intră în detaliile acestor operațiuni, dar dacă sunteți interesat să aflați mai multe despre construirea de soluții bazate pe evenimente folosind Amazon Redshift, consultați următoarele GitHub depozit.
A curăța
Pentru a evita costurile viitoare, ștergeți resursele care au fost create ca parte a acestei postări.
Concluzie
În această postare, am demonstrat cum să configurați un flux de date Kinesis, să configurați un producător și să publicați date în fluxuri, apoi să creați o vizualizare Amazon Redshift Streaming Ingestion și să interogați datele în Amazon Redshift. După ce datele au fost în clusterul Amazon Redshift, am demonstrat cum să antrenăm un model ML și să construim o funcție de predicție și să o aplicăm pe datele de streaming pentru a genera predicții în timp aproape real.
Dacă aveți feedback sau întrebări, vă rugăm să le lăsați în comentarii.
Despre Autori
 Bhanu Pittampally este un arhitect specializat în soluții de analiză, cu sediul în Dallas. Este specializat în construirea de soluții analitice. Studiul său este în depozitele de date – arhitectură, dezvoltare și administrare. El este în domeniul datelor și a analizei de peste 15 ani.
Bhanu Pittampally este un arhitect specializat în soluții de analiză, cu sediul în Dallas. Este specializat în construirea de soluții analitice. Studiul său este în depozitele de date – arhitectură, dezvoltare și administrare. El este în domeniul datelor și a analizei de peste 15 ani.
 Praveen Kadipikonda este arhitect senior în soluții de specialitate în analiză la AWS, cu sediul în Dallas. El îi ajută pe clienți să construiască soluții analitice eficiente, performante și scalabile. El a lucrat cu construirea de baze de date și soluții de depozit de date de peste 15 ani.
Praveen Kadipikonda este arhitect senior în soluții de specialitate în analiză la AWS, cu sediul în Dallas. El îi ajută pe clienți să construiască soluții analitice eficiente, performante și scalabile. El a lucrat cu construirea de baze de date și soluții de depozit de date de peste 15 ani.
 Ritesh Kumar Sinha este un arhitect specializat în soluții de analiză cu sediul în San Francisco. El a ajutat clienții să construiască soluții scalabile de depozitare de date și date mari de peste 16 ani. Îi place să proiecteze și să construiască soluții eficiente end-to-end pe AWS. În timpul liber, îi place să citească, să meargă și să facă yoga.
Ritesh Kumar Sinha este un arhitect specializat în soluții de analiză cu sediul în San Francisco. El a ajutat clienții să construiască soluții scalabile de depozitare de date și date mari de peste 16 ani. Îi place să proiecteze și să construiască soluții eficiente end-to-end pe AWS. În timpul liber, îi place să citească, să meargă și să facă yoga.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- Platoblockchain. Web3 Metaverse Intelligence. Cunoștințe amplificate. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/near-real-time-fraud-detection-using-amazon-redshift-streaming-ingestion-with-amazon-kinesis-data-streams-and-amazon-redshift-ml/
- 000
- 000 de clienți
- 1
- 10
- 100
- 11
- ani 15
- 67
- 7
- 9
- a
- Capabil
- Despre Noi
- mai sus
- acces
- Cont
- Obține
- Acțiune
- Suplimentar
- administrare
- avansat
- După
- împotriva
- Alerta
- TOATE
- permite
- Amazon
- Amazon EC2
- Amazon Kinesis
- sumă
- analiști
- analitic
- Google Analytics
- analiza
- și
- detectarea anomaliilor
- Apache
- aplicație
- Aplică
- Aplicarea
- arhitectură
- în jurul
- atașa
- Auto
- Automat
- în mod automat
- disponibil
- evitarea
- AWS
- fundal
- bazat
- de bază
- deoarece
- devine
- CEL MAI BUN
- Mai bine
- între
- Mare
- Datele mari
- aduce
- construi
- Clădire
- afaceri
- procesele de afaceri
- întreprinderi
- apel
- denumit
- apeluri
- captura
- card
- caz
- cazuri
- caracter
- taxe
- verifica
- Alege
- Oraș
- Cloud
- Grup
- cod
- Coloane
- combină
- venire
- comentarii
- comparaţie
- Completă
- completarea
- complex
- complexitate
- Calcula
- consideră
- Consoleze
- consuma
- consumator
- conține
- cost-eficiente
- ar putea
- crea
- a creat
- creează
- Crearea
- scrisori de acreditare
- credit
- card de credit
- client
- datele despre consumator
- clienţii care
- cicluri
- zilnic
- Dallas
- de date
- Pregătirea datelor
- depozit de date
- depozite de date
- Baza de date
- baze de date
- seturi de date
- Data
- Luarea deciziilor
- Mod implicit
- definire
- livra
- demonstrat
- Dependent/ă
- implementa
- dislocate
- implementează
- descris
- Amenajări
- detalii
- Detectare
- Dezvoltatorii
- Dezvoltare
- diferit
- direct
- Nu
- face
- Dont
- dow
- dinamic
- cu ușurință
- ușor de folosit
- efect
- eficient
- permite
- permite
- un capăt la altul
- Inginerie
- Intrați
- Eter (ETH)
- eveniment
- evenimente
- exemplu
- excitat
- extern
- extracţie
- f1
- familiar
- FAST
- Caracteristică
- DESCRIERE
- feedback-ul
- camp
- Domenii
- Filtre
- financiar
- Găsi
- steaguri
- debit
- urma
- următor
- urmează
- formă
- format
- găsit
- FRAME
- Francisco
- fraudă
- detectarea fraudei
- Gratuit
- Frecvență
- din
- complet
- funcţie
- funcții
- viitor
- genera
- generată
- generator
- generator
- obține
- Da
- Go
- bine
- acordarea
- Teren
- grup
- având în
- a ajutat
- ajută
- superior
- Evidențiați
- istoric
- istorie
- Cum
- Cum Pentru a
- HTML
- HTTPS
- sute
- IAM
- identificat
- Identitate
- importanță
- in
- include
- Intrare
- Crește
- crescând
- individ
- informații
- Infrastructură
- intrare
- inserții
- perspective
- instala
- instanță
- Institut
- instrucțiuni
- interesat
- IT
- alătura
- JSON
- Kafka
- Fluxuri de date Kinesis
- limbă
- mai mare
- Latență
- Ultimele
- lansa
- învăţare
- Părăsi
- Lungime
- Nivel
- LIMITĂ
- limitare
- încărca
- loturile
- pe termen lung
- Jos
- maşină
- masina de învățare
- făcut
- face
- FACE
- gestionate
- de conducere
- manual
- multe
- Hartă
- masiv
- potrivire
- matplotlib
- max
- mijloace
- Mass-media
- metodă
- metric
- Metrici
- diminua
- ML
- mod
- model
- Modele
- lunar
- luni
- mai mult
- cele mai multe
- muta
- nume
- Navigare
- Nevoie
- nevoilor
- Nou
- următor
- notificare
- număr
- NumPy
- obiectiv
- ONE
- deschide
- operaţie
- operațional
- Operațiuni
- Oportunităţi
- Opţiuni
- comandă
- organizații
- Altele
- a subliniat
- ofertele
- panda
- pâine
- parametru
- parte
- Perfect
- efectua
- performanță
- efectuează
- permisiuni
- telefon
- Loc
- planificare
- platformă
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- Politicile
- Politica
- posibil
- Post
- putere
- Precizie
- prezice
- prezicere
- Predictii
- prezice
- precedent
- de stabilire a prețurilor
- proces
- procese
- producător
- Program
- furniza
- furnizează
- public
- publica
- Piton
- Întrebări
- repede
- aleator
- Citind
- gata
- real
- în timp real
- date în timp real
- realizarea
- a primi
- primit
- recent
- recunoscut
- înregistrări
- REPETAT
- înlocui
- necesar
- resursă
- Resurse
- REST
- REZULTATE
- Returnează
- Risc
- Rol
- Alerga
- funcţionare
- sagemaker
- San
- San Francisco
- scalabil
- Scară
- capturi de ecran
- sdk
- născut în mare
- Al doilea
- secunde
- Secțiune
- secțiuni
- sigur
- selectate
- selecţie
- serverless
- serviciu
- set
- instalare
- setări
- configurarea
- Pe termen scurt
- Arăta
- Emisiuni
- simplu
- simplifica
- Simulator
- So
- Social
- social media
- soluţie
- soluţii
- unele
- Sursă
- Surse
- specialist
- specializată
- petrece
- împărţi
- SQL
- Etapă
- standard
- început
- Stat
- Declarație
- Declarații
- Stare
- Pas
- paşi
- depozitare
- stoca
- magazine
- Strategic
- curent
- de streaming
- serviciul de streaming
- fluxuri
- astfel de
- Super
- sistem
- sisteme
- tabel
- Lua
- ia
- Tratative
- Ţintă
- Terminal
- test
- Al treilea
- mii
- Prin
- timp
- timestamp-ul
- la
- top
- subiect
- tradiţional
- Tren
- dresat
- Pregătire
- tranzacție
- tranzacțional
- Tranzacții
- Transforma
- transformări
- transformare
- tendință
- Actualizează
- actualizat
- Folosire
- utilizare
- Utilizator
- validate
- valoare
- Valori
- diverse
- Verity
- versiune
- Vizualizare
- vizualizari
- mers
- walkthrough
- Depozit
- depozitare
- website
- weekend
- săptămânal
- Ce
- care
- în timp ce
- Wikipedia
- voi
- fără
- a lucrat
- de lucru
- fabrică
- scrie
- ani
- yoga
- Ta
- zephyrnet