Amazon RedShift este un serviciu de stocare a datelor în cloud care oferă procesare analitică de înaltă performanță bazată pe o arhitectură de procesare masiv paralelă (MPP). Construirea și întreținerea conductelor de date este o provocare comună pentru toate întreprinderile. Gestionarea fișierelor SQL, integrarea muncii în echipe încrucișate, încorporarea tuturor principiilor de inginerie software și importul de utilități externe pot fi o sarcină consumatoare de timp care necesită un design complex și multă pregătire.
DBT (DataBuildTool) oferă acest mecanism prin introducerea unui cadru bine structurat pentru analiza, transformarea și orchestrarea datelor. De asemenea, aplică principii generale de inginerie software, cum ar fi integrarea cu depozitele git, configurarea Uscător cod, adăugând cazuri de testare funcționale și incluzând biblioteci externe. Acest mecanism permite dezvoltatorilor să se concentreze pe pregătirea fișierelor SQL conform logicii de afaceri, iar de restul se ocupă dbt.
În această postare, analizăm o modalitate optimă și rentabilă de a încorpora dbt în Amazon Redshift. Folosim Amazon Elastic Registrul containerelor (Amazon ECR) pentru a stoca imaginile noastre dbt Docker și AWS Fargate ca o Serviciul Amazon de containere elastice (Amazon ECS) pentru a rula sarcina.
Cum funcționează cadrul dbt cu Amazon Redshift?
dbt are un modul adaptor Amazon Redshift numit dbt-redshift care îi permite să se conecteze și să lucreze cu Amazon Redshift. Toate profilurile de conexiune sunt configurate în cadrul dbt profiles.yml fişier. Într-un mediu optim, stocăm acreditările în Manager de secrete AWS și recuperați-le.
Următorul cod arată conținutul profile.yml:
Următoarea diagramă ilustrează componentele cheie ale cadrului dbt:
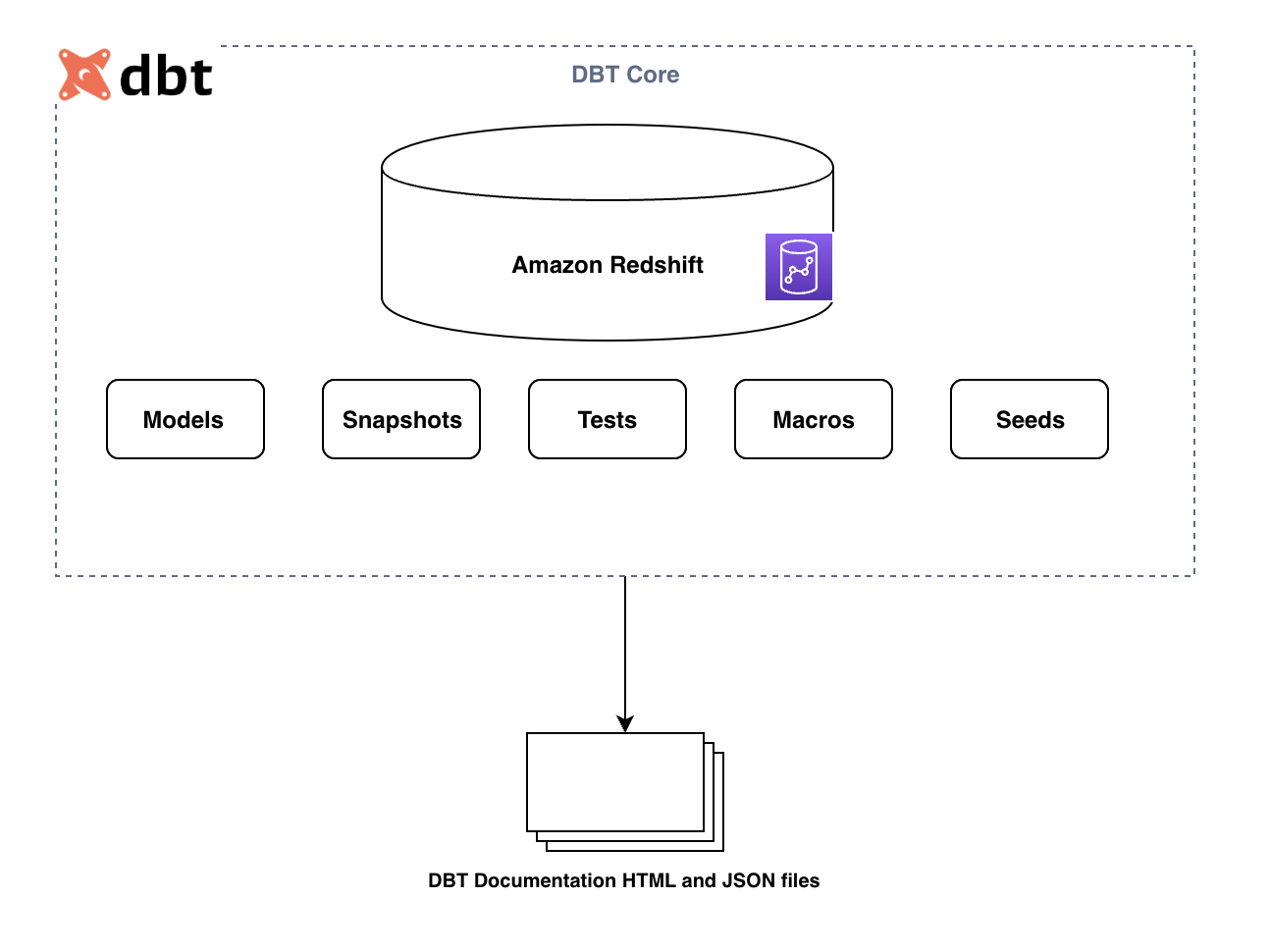
Componentele primare sunt după cum urmează:
- modele – Acestea sunt scrise ca instrucțiune SELECT și salvate ca fișier .sql. Toate interogările de transformare pot fi scrise aici, care pot fi materializate ca tabel sau vizualizare. Actualizarea tabelului poate fi completă sau incrementală, în funcție de configurație. Pentru mai multe informații, consultați modele SQL.
- Instantanee – Aceste instrumente dimensiunile de tip 2 care se schimbă lent (SCD) peste tabele sursă mutabile. Aceste SCD-uri identifică modul în care un rând dintr-un tabel se modifică în timp.
- Seminte - Acestea sunt fișiere CSV din proiectul dvs. dbt (de obicei, în directorul dvs. de semințe), pe care dbt le poate încărca în dvs. depozit de date folosind
dbt seedcomanda. - Teste – Acestea sunt afirmații pe care le faceți despre modelele și alte resurse din proiectul dvs. dbt (cum ar fi sursele, semințele și instantaneele). Când alergi
dbt test, dbt vă va spune dacă fiecare test din proiectul dvs. trece sau nu. - Macrocomenzi – Acestea sunt bucăți de cod care pot fi reutilizate de mai multe ori. Ele sunt analoge cu „funcțiile” din alte limbaje de programare și sunt extrem de utile dacă repeți codul pe mai multe modele.
Aceste componente sunt stocate ca fișiere .sql și sunt rulate de comenzile dbt CLI. În timpul rulării, dbt creează un Graficul aciclic direcționat (DAG) bazată pe referința internă între componentele dbt. Utilizează DAG pentru a orchestra secvența de rulare în consecință.
Pot fi create mai multe profiluri în fișierul profiles.yml, pe care dbt îl poate folosi pentru a viza diferite medii Redshift în timpul rulării. Pentru mai multe informații, consultați Configurarea Redshift.
Prezentare generală a soluțiilor
Următoarea diagramă ilustrează arhitectura soluției noastre.
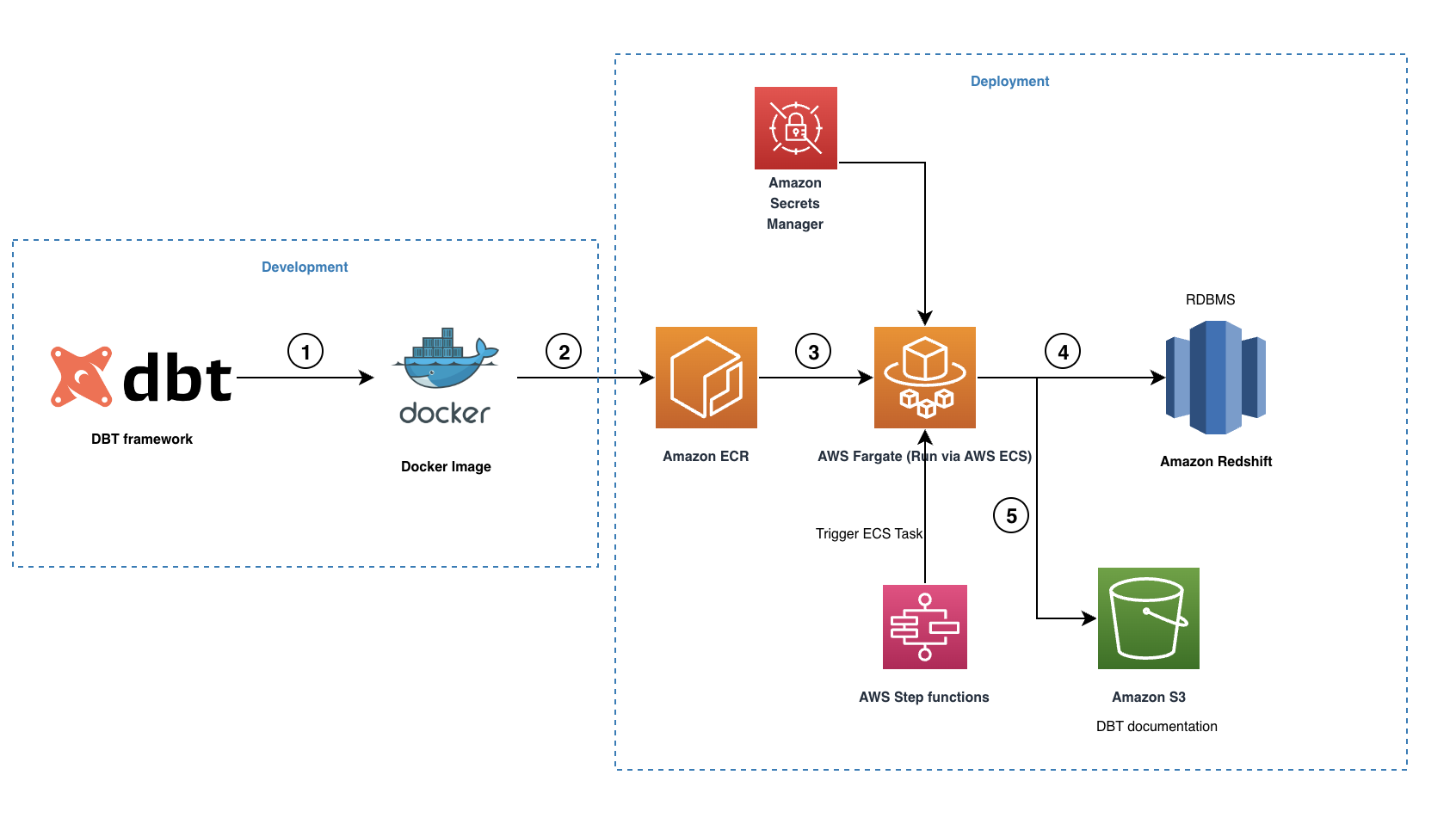
Fluxul de lucru conține următorii pași:
- Conectorul open source dbt-redshift este folosit pentru a crea proiectul nostru dbt, inclusiv toate modelele necesare, instantanee, teste, macrocomenzi și profiluri.
- O imagine Docker este creată și trimisă în depozitul ECR.
- Imaginea Docker este rulată de Fargate ca o sarcină ECS declanșată prin Funcții pas AWS. Toate acreditările Amazon Redshift sunt stocate în Secrets Manager, care este apoi folosit de sarcina ECS pentru a se conecta la Amazon Redshift.
- În timpul rulării, dbt convertește toate modelele, instantaneele, testele și macrocomenzile în instrucțiuni SQL compatibile cu Amazon Redshift și orchestrează rularea pe baza datelor interne. graficul liniei de date menținut. Aceste comenzi SQL sunt executate direct pe clusterul Redshift și, prin urmare, volumul de lucru este transmis direct către Amazon Redshift.
- Când rularea este completă, dbt va crea un set de fișiere HTML și JSON pentru a găzdui documentație dbt, care descrie catalogul de date, instrucțiunile SQL compilate, graficul descendenței datelor și multe altele.
Cerințe preliminare
Ar trebui să aveți următoarele condiții preliminare:
- O bună înțelegere a principiilor dbt și a etapelor de implementare.
- Un cont AWS cu permisiune de rol de utilizator pentru a accesa serviciile AWS utilizate în această soluție.
- Grupuri de securitate pentru Fargate pentru a accesa clusterul Redshift și Secrets Manager de la Amazon ECS.
- Un cluster Redshift. Pentru instrucțiuni de creare, consultați Creați un cluster.
- Un depozit ECR: Pentru instrucțiuni, consultați Crearea unui depozit privat
- Un manager de secrete secret care conține toate acreditările pentru conectarea la Amazon Redshift. Aceasta include gazda, portul, numele bazei de date, numele de utilizator și parola. Pentru mai multe informații, consultați Creați un secret al bazei de date AWS Secrets Manager.
- An Stocare simplă Amazon (Amazon S3) pentru a găzdui fișiere de documentație.
Creați un proiect dbt
Folosim dbt CLI, astfel încât toate comenzile sunt executate în linia de comandă. Prin urmare, instalați pip dacă nu este deja instalat. A se referi la instalare pentru mai multe informatii.
Pentru a crea un proiect dbt, parcurgeți următorii pași:
- Instalați pachete dbt dependente:
pip install dbt-redshift - Inițializați un proiect dbt folosind
dbt init <project_name>comanda, care creează automat toate folderele șabloane. - Adăugați toate artefactele DBT necesare.
Consultați dbt-redshift-etlpattern repo care include un proiect dbt de referință. Pentru mai multe informații despre proiectele de construcție, consultați Despre proiectele dbt.
În proiectul de referință, am implementat următoarele caracteristici:
- SCD tip 1 folosind modele incrementale
- SCD tip 2 folosind instantanee
- Fișiere de căutare a semințelor
- Macro-uri pentru adăugarea de cod reutilizabil în proiect
- Teste pentru analiza datelor de intrare
Scriptul Python este pregătit pentru a prelua acreditările necesare de la Secrets Manager pentru a accesa Amazon Redshift. Consultați export_redshift_connection.py fișier.
- Pregătiți
run_dbt.shscript pentru a rula conducta dbt secvenţial. Acest script este plasat în folderul rădăcină al proiectului dbt, așa cum se arată în exemplul de depozit.
- Creați un fișier Docker în directorul părinte al folderului de proiect dbt. Acest pas construiește imaginea proiectului dbt pentru a fi împins în depozitul ECR.
Încărcați imaginea în Amazon ECR și rulați-o ca sarcină ECS
Pentru a trimite imaginea în depozitul ECR, parcurgeți următorii pași:
- Preluați un token de autentificare și autentificați-vă clientul Docker în registru:
- Creați-vă imaginea Docker folosind următoarea comandă:
- După ce construirea este completă, etichetați imaginea pentru a o putea împinge în depozit:
- Rulați următoarea comandă pentru a împinge imaginea în depozitul AWS nou creat:
- Pe consola Amazon ECS, creați un cluster cu Fargate ca opțiune de infrastructură.
- Furnizați VPC-ul și subrețelele, după cum este necesar.
- După ce creați clusterul, creați o sarcină ECS și atribuiți imaginea dbt creată ca familie de definire a activității.
- În secțiunea de rețea, alegeți VPC-ul, subrețelele și grupul de securitate pentru a vă conecta cu Amazon Redshift, Amazon S3 și Secrets Manager.
Această sarcină va declanșa run_dbt.sh pipeline și rulați toate comenzile dbt secvenţial. Când scriptul este complet, putem vedea rezultatele în Amazon Redshift și fișierele de documentație trimise către Amazon S3.
- Puteți găzdui documentația prin găzduirea site-ului static Amazon S3. Pentru mai multe informații, consultați Găzduirea unui site web static folosind Amazon S3.
- În cele din urmă, puteți rula această sarcină în Step Functions ca o sarcină ECS pentru a programa joburile după cum este necesar. Pentru mai multe informații, consultați Gestionați activitățile Amazon ECS sau Fargate cu funcții Step.
dbt-redshift-etlpattern repo are acum toate mostrele de cod necesare.
Costul executării joburilor dbt în AWS Fargate ca sarcină Amazon ECS cu cerințe operaționale minime ar dura aproximativ 1.5 USD (cost_link) pe luna.
A curăța
Parcurgeți următorii pași pentru a vă curăța resursele:
- Ștergeți clusterul ECS ai creat.
- Ștergeți depozitul ECR ați creat pentru stocarea fișierelor imagine.
- Ștergeți clusterul Redshift ai creat.
- Ștergeți secretele Redshift stocate în Secrets Manager.
Concluzie
Această postare a acoperit implementarea de bază a utilizării dbt cu Amazon Redshift într-un mod eficient din punct de vedere al costurilor prin utilizarea Fargate în Amazon ECS. Am descris infrastructura cheie și configurația cu un proiect exemplu. Această arhitectură vă poate ajuta să profitați de avantajele de a avea un cadru dbt pentru a vă gestiona platforma de depozit de date în Amazon Redshift.
Pentru mai multe informații despre macrocomenzile și modelele dbt pentru operarea și întreținerea internă Amazon Redshift, consultați următoarele GitHub repo. În postarea ulterioară, vom explora modelele tradiționale de extragere, transformare și încărcare (ETL) pe care le puteți implementa folosind cadrul dbt din Amazon Redshift. Testează această soluție în contul tău și oferă feedback sau sugestii în comentarii.
Despre Autori
 Seshadri Senthamaraikannan este un arhitect de date cu echipa de servicii profesionale AWS cu sediul în Londra, Marea Britanie. Are o bună experiență și este specializat în Data Analytics și lucrează cu clienții concentrându-se pe construirea de soluții inovatoare și scalabile în AWS Cloud pentru a-și îndeplini obiectivele de afaceri. În timpul liber, îi place să petreacă timpul cu familia și să facă sport.
Seshadri Senthamaraikannan este un arhitect de date cu echipa de servicii profesionale AWS cu sediul în Londra, Marea Britanie. Are o bună experiență și este specializat în Data Analytics și lucrează cu clienții concentrându-se pe construirea de soluții inovatoare și scalabile în AWS Cloud pentru a-și îndeplini obiectivele de afaceri. În timpul liber, îi place să petreacă timpul cu familia și să facă sport.
 Mohamed Hamdy este un arhitect senior Big Data cu AWS Professional Services cu sediul în Londra, Marea Britanie. Are peste 15 ani de experiență în arhitectura, conducerea și construirea de depozite de date și platforme de date mari. El îi ajută pe clienți să dezvolte soluții de date mari și de analiză pentru a-și accelera rezultatele afacerii prin călătoria lor de adoptare a cloud-ului. În afara serviciului, lui Mohamed îi place să călătorească, să alerge, să înoate și să joace squash.
Mohamed Hamdy este un arhitect senior Big Data cu AWS Professional Services cu sediul în Londra, Marea Britanie. Are peste 15 ani de experiență în arhitectura, conducerea și construirea de depozite de date și platforme de date mari. El îi ajută pe clienți să dezvolte soluții de date mari și de analiză pentru a-și accelera rezultatele afacerii prin călătoria lor de adoptare a cloud-ului. În afara serviciului, lui Mohamed îi place să călătorească, să alerge, să înoate și să joace squash.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/big-data/implement-data-warehousing-solution-using-dbt-on-amazon-redshift/
- :are
- :este
- :nu
- $UP
- 1
- 10
- 11
- ani 15
- 15%
- 7
- 8
- 90
- 970
- a
- Despre Noi
- accelera
- acces
- accesarea
- Cont
- peste
- adăuga
- adăugare
- Adoptare
- Avantaj
- TOATE
- permite
- deja
- de asemenea
- Amazon
- Amazon Web Services
- an
- analiză
- Analitic
- Google Analytics
- analiza
- și
- se aplică
- arhitectură
- SUNT
- în jurul
- AS
- autentifica
- Autentificare
- în mod automat
- AWS
- Servicii profesionale AWS
- bazat
- de bază
- BE
- Beneficiile
- între
- Mare
- Datele mari
- construi
- Clădire
- construiește
- afaceri
- by
- CAN
- pasă
- cazuri
- catalog
- contesta
- Modificări
- schimbarea
- Alege
- curat
- client
- Cloud
- adoptarea norului
- Grup
- cod
- comentarii
- Comun
- compilat
- Completă
- complex
- conforme
- componente
- Configuraţie
- configurat
- Conectați
- Conectarea
- conexiune
- Consoleze
- Recipient
- conține
- conținut
- cost-eficiente
- acoperit
- crea
- a creat
- creează
- creaţie
- scrisori de acreditare
- personalizat
- clienţii care
- DAG
- de date
- analiza datelor
- Analiza datelor
- depozit de date
- depozite de date
- Baza de date
- Mod implicit
- definiție
- Dependent/ă
- descris
- Amenajări
- dev
- dezvolta
- Dezvoltatorii
- diferit
- direct
- Docher
- documentaţie
- face
- în timpul
- fiecare
- permite
- Inginerie
- Companii
- Mediu inconjurator
- medii
- Eter (ETH)
- executând
- experienţă
- cu experienţă
- explora
- extern
- extrage
- extrem
- eșuează
- familie
- DESCRIERE
- feedback-ul
- Fișier
- Fişiere
- Găsi
- Concentra
- concentrându-se
- următor
- urmează
- Pentru
- Cadru
- din
- Complet
- funcțional
- funcții
- General
- genera
- merge
- Goluri
- bine
- grafic
- grup
- Grupului
- Avea
- având în
- he
- ajutor
- ajută
- aici
- performanta ridicata
- lui
- gazdă
- găzduire
- Cum
- HTML
- HTTPS
- identifica
- if
- ilustrează
- imagine
- imagini
- punerea în aplicare a
- implementarea
- implementat
- import
- importatoare
- in
- În altele
- include
- Inclusiv
- care încorporează
- incrementală
- informații
- Infrastructură
- inovatoare
- instala
- instrucțiuni
- integrarea
- intern
- în
- introducerea
- IT
- Loc de munca
- Locuri de munca
- călătorie
- JSON
- Cheie
- Limbă
- Ultimele
- conducere
- biblioteci
- ca
- îi place
- Linie
- încărca
- logică
- Logare
- Londra
- Uite
- loturi
- macro-uri
- mentine
- întreținere
- face
- administra
- manager
- de conducere
- masiv
- mecanism
- Întâlni
- minim
- model
- Modele
- modul
- Mohamed
- Lună
- mai mult
- multiplu
- nume
- Numit
- necesar
- rețele
- recent
- acum
- of
- promoții
- on
- deschide
- open-source
- operaţie
- operațional
- optimă
- Opțiune
- or
- orchestrație
- Altele
- al nostru
- rezultate
- iesiri
- exterior
- peste
- Prezentare generală
- ofertele
- Paralel
- trece
- Parolă
- modele
- pentru
- permisiune
- piese
- conducte
- plasat
- platformă
- Platforme
- Plato
- Informații despre date Platon
- PlatoData
- Joaca
- joc
- Post
- pregătire
- pregătit
- pregătirea
- premise
- primar
- Principiile
- privat
- prelucrare
- profesional
- Profil
- Profiluri
- Programare
- limbaje de programare
- proiect
- Proiecte
- furniza
- furnizează
- Împinge
- împins
- Piton
- interogări
- trimite
- referință
- registru
- depozit
- necesita
- necesar
- Cerinţe
- Necesită
- Resurse
- REST
- REZULTATE
- reutilizabile
- Rol
- rădăcină
- RÂND
- Alerga
- funcţionare
- salvate
- scalabil
- programa
- scenariu
- secunde
- secrete
- Secțiune
- securitate
- vedea
- sămânţă
- seminţe
- senior
- Secvenţă
- serviciu
- Servicii
- set
- instalare
- să
- indicat
- Emisiuni
- simplu
- Încet
- Instantaneu
- So
- Software
- Inginerie software
- soluţie
- soluţii
- Sursă
- Surse
- de specialitate
- Cheltuire
- Sportul
- SQL
- Declarație
- Declarații
- Pas
- paşi
- stoca
- stocate
- subrețele
- ulterior
- astfel de
- de înot
- tabel
- TAG
- Lua
- luate
- Ţintă
- Sarcină
- sarcini
- echipă
- spune
- șablon
- test
- teste
- acea
- lor
- Lor
- apoi
- prin urmare
- Acestea
- ei
- acest
- Prin
- timp
- consumă timp
- ori
- la
- semn
- tradiţional
- Transforma
- Transformare
- declanşa
- a declanșat
- tip
- tipic
- Uk
- înţelegere
- utilizare
- utilizat
- Utilizator
- utilizări
- folosind
- utilitati
- de
- Vizualizare
- Depozit
- depozitare
- Cale..
- we
- web
- servicii web
- website
- BINE
- cand
- care
- în timp ce
- Wikipedia
- voi
- cu
- în
- Apartamente
- flux de lucru
- fabrică
- ar
- scris
- ani
- tu
- Ta
- te
- zephyrnet