Ce este procesarea documentelor?

Procesarea documentelor este procesul de automatizare a extragerii datelor structurate din documente. Acest lucru ar putea fi pentru orice document, să spunem o factură, un CV, cărți de identitate etc. Partea provocatoare aici nu este doar OCR. Există multe opțiuni disponibile la costuri mici care pot extrage text și vă pot oferi locația. Adevărata provocare este etichetarea acestor bucăți de text în mod precis și automat.
Impactul de afaceri al procesării documentelor
Mai multe industrii se bazează în mare măsură pe procesarea documentelor pentru operațiunile lor zilnice. Organizațiile financiare au nevoie de acces la dosarele SEC, dosarele de asigurare, o companie de comerț electronic sau de lanț de aprovizionare ar putea avea nevoie de acces la facturile care sunt utilizate, lista poate continua. Acuratețea acestor informații este la fel de importantă ca și timpul economisit, motiv pentru care recomandăm întotdeauna folosirea unor metode avansate de deep learning care generalizează mai mult și sunt mai precise.
Potrivit acestui raport al PwC, [legătură] chiar și cea mai rudimentară cantitate de extragere a datelor structurate poate ajuta la economisirea a 30-50% din timpul petrecut de angajat cu copierea și inserarea manuală a datelor din PDF-uri în foi de calcul Excel. Modele precum LayoutLM nu sunt cu siguranță rudimentare, ele au fost construite ca agenți extrem de inteligenți capabili să extragă date precise la scară, în diferite cazuri de utilizare. Chiar și cu mulți dintre clienții noștri, am redus timpul necesar pentru extragerea manuală a datelor de la 20 de minute per document la mai puțin de 10 secunde. Aceasta este o schimbare masivă, care le permite lucrătorilor să fie mai productivi și pentru un randament general mai mare.
Deci, unde poate fi aplicat AI similar cu LayoutLM? La Nanonets, am folosit o astfel de tehnologie pentru
- Automatizarea procesării facturilor
- Extragerea datelor din tabel
- Extragerea datelor din formular
- Reluați analiza
și multe alte cazuri de utilizare.
De ce LayoutLM?
Cum înțelege un model de învățare profundă dacă o anumită bucată de text este o descriere a articolului dintr-o factură sau numărul facturii? Mai simplu, cum învață un model să atribuie corect etichetele?
O metodă este să utilizați încorporarea textului dintr-un model de limbaj masiv precum BERT sau GPT-3 și să îl rulați printr-un clasificator - deși acest lucru nu este foarte eficient. Există o mulțime de informații pe care nu le putem evalua doar folosind text. Sau, s-ar putea folosi informații bazate pe imagini. Acest lucru a fost realizat prin utilizarea modelelor R-CNN și Faster R-CNN. Cu toate acestea, aceasta încă nu utilizează pe deplin informațiile disponibile în documente. O altă abordare folosită a fost cea a rețelelor neuronale convoluționale Graph, care a combinat atât informațiile locaționale, cât și textuale, dar nu țineau cont de informațiile despre imagine.
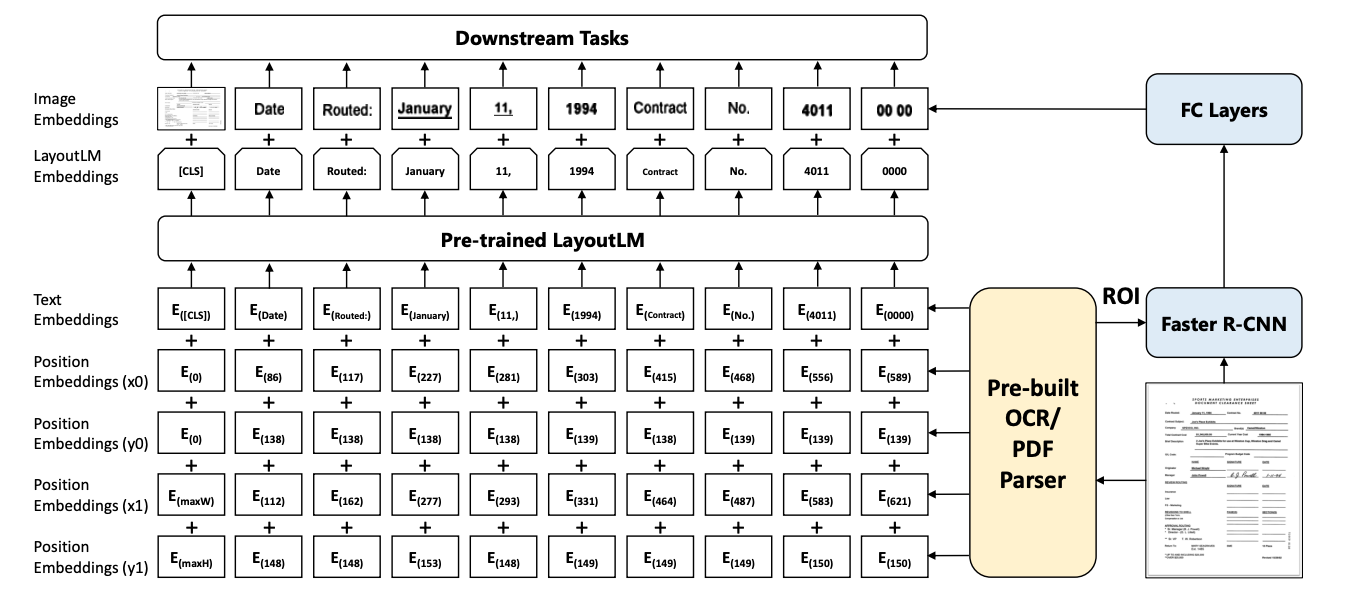
Deci, cum folosim toate cele trei dimensiuni ale informațiilor, adică textul, imaginea și locația textului dat? Aici intervin modele precum LayoutLM. În ciuda faptului că a fost un domeniu activ de cercetare cu mulți ani înainte, LayoutLM a fost unul dintre primele modele care a obținut succes combinând piesele pentru a crea un model singular care efectuează etichetare folosind informații de poziție, informații bazate pe text, și, de asemenea, informații despre imagine.
Tutorial LayoutLM
Acest articol presupune că înțelegeți ce este un model de limbă. Dacă nu, nu-ți face griji, am scris un articol si despre asta! Dacă doriți să aflați mai multe despre modelele de transformatoare și despre ce atenție este, aici este un articol uimitor al lui Jay Alammar.
Presupunând că am îndepărtat aceste lucruri din drum, să începem cu tutorialul. Vom folosi documentul original LayoutLM ca referință principală.
Extragerea textului OCR
Primul lucru pe care îl facem cu un document este să extragem informațiile bazate pe text din document și să găsim locațiile respective. Prin locație, ne referim la ceva numit „cutie delimitare”. O casetă de delimitare este un dreptunghi care încapsulează fragmentul de text de pe pagină.

În cele mai multe cazuri, se presupune că caseta de delimitare are originea în colțul din stânga sus și că axa x pozitivă este îndreptată de la origine spre dreapta paginii, iar axa y pozitivă este îndreptată de la origine la partea de jos a paginii, un pixel fiind considerat unitatea de măsură.
Limbă și locație încorporate
În continuare, folosim cinci straturi de încorporare diferite. Unul, este codificarea informațiilor legate de limbă – adică încorporarea textului.
Celelalte patru sunt rezervate pentru încorporarea locațiilor. Presupunând că cunoaștem valorile lui xmin, ymin, xmax și ymax, putem determina întreaga casetă de delimitare (dacă nu îl puteți vizualiza, aici este un link pentru tine). Aceste coordonate sunt trecute prin straturile lor de încorporare respective pentru a codifica informații pentru locație.
Cele cinci înglobări – una pentru text și patru pentru coordonate – sunt apoi adăugate pentru a crea valoarea finală a încorporarii care este trecută prin LayoutLM. Ieșirea este denumită încorporare LayoutLM.
Încorporarea imaginilor
Bine, așa că am reușit să găsim textul și informațiile legate de locație combinând înglobările lor și trecându-le printr-un model de limbă. Acum, cum ocolim procesul de combinare a informațiilor legate de imagine în el?
În timp ce informațiile de text și de aspect sunt codificate, în paralel, folosim Faster R-CNN pentru a extrage regiunile de text legate de document. Faster R-CNN este un model de imagine utilizat pentru detectarea obiectelor. În cazul nostru, îl folosim pentru a detecta diferite bucăți de text (presupunând că fiecare frază este un obiect) și apoi trecem imaginile segmentate printr-un strat complet conectat pentru a ajuta la generarea înglobărilor și pentru imagini.
Înglobările LayoutLM, precum și încorporarea imaginilor sunt combinate pentru a crea o încorporare finală, care poate fi apoi utilizată pentru a efectua procesarea în aval.
LayoutLM pre-antrenament
Toate cele de mai sus au sens numai dacă înțelegem metoda în care a fost antrenat LayoutLM. La urma urmei, indiferent de ce fel de conexiuni stabilim într-o rețea neuronală, până când și cu excepția cazului în care este antrenată cu obiectivul de învățare potrivit, nu este chiar inteligent. Autorii LayoutLM au dorit să urmărească o metodă similară cu cea folosită pentru pre-antrenarea BERT.
Model de limbaj vizual mascat (MVLM)
Pentru a ajuta modelul să învețe ce text ar fi putut fi într-o anumită locație, autorii au mascat aleatoriu câteva semne de text, păstrând în același timp informații și înglobări legate de locație. Acest lucru a permis LayoutLM să depășească simpla modelare a limbajului mascat și a ajutat să asocieze încorporarea textului cu modalități legate de locație.
Clasificarea documentelor cu mai multe etichete (MDC)
Utilizarea tuturor informațiilor din document pentru a le clasifica în categorii ajută modelul să înțeleagă ce informații sunt relevante pentru o anumită clasă de documente. Cu toate acestea, autorii notează că pentru seturi de date mai mari, este posibil ca datele despre clasele de documente să nu fie ușor disponibile. Prin urmare, au oferit o bază de rezultate atât formarea MVLM, cât și formarea MVLM + MDC.
Reglare fină LayoutLM pentru sarcinile din aval
Există mai multe sarcini în aval care pot fi executate cu LayoutLM. Vom discuta despre cele pe care le-au întreprins autorii.
Înțelegerea formei
Această sarcină presupune legarea unui tip de etichetă la o anumită bucată de text. Folosind aceasta, putem extrage date structurate din orice tip de document. Având în vedere rezultatul final, adică încorporarea LayouLM + încorporarea imaginilor, acestea sunt trecute printr-un strat complet conectat și apoi trecute printr-un softmax pentru a prezice probabilitățile de clasă pentru eticheta unei anumite porțiuni de text.
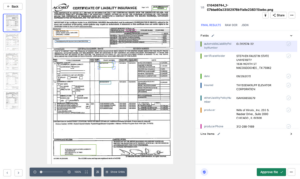
Înțelegerea chitanței
În această sarcină, mai multe sloturi de informații au fost lăsate goale pe chitanțe, iar modelul a trebuit să poziționeze corect bucăți de text pe sloturile respective.
Clasificarea imaginilor documentelor
Informațiile din textul și imaginea documentului sunt combinate pentru a ajuta la înțelegerea clasei documentului prin simpla trecere printr-un strat softmax.
Huggingface LayoutLM
Unul dintre principalele motive pentru care LayoutLM este discutat atât de mult este că modelul a fost open source cu ceva timp în urmă. Este disponibil pe Hugging Face, așa că utilizarea LayoutLM este semnificativ mai ușoară acum.
Înainte de a ne aprofunda în detaliile modului în care puteți ajusta LayoutLM pentru propriile nevoi, există câteva lucruri de luat în considerare.
Instalarea Bibliotecilor
Pentru a rula LayoutLM, veți avea nevoie de biblioteca de transformatoare de la Hugging Face, care, la rândul ei, depinde de biblioteca PyTorch. Pentru a le instala (dacă nu sunt deja instalate), rulați următoarele comenzi
Pe cutii de delimitare
Pentru a crea o schemă de încorporare uniformă, indiferent de dimensiunea imaginii, coordonatele casetei de delimitare sunt normalizate pe o scară de 1000
Configuraţie
Folosind clasa transformers.LayoutLMConfig, puteți seta dimensiunea modelului pentru a se potrivi cel mai bine cerințelor dvs., deoarece aceste modele sunt de obicei grele și necesită destul de multă putere de calcul. Setarea acestuia la un model mai mic vă poate ajuta să îl rulați local. Puteți afla mai multe despre clasa aici.
LayoutLM pentru clasificarea documentelor (Link)
Dacă doriți să efectuați clasificarea documentelor, veți avea nevoie de clasa transformatoare.LayoutLMForSequenceClassification. Secvența de aici este secvența de text din documentul pe care l-ați extras. Iată un mic eșantion de cod de la Hugging Face.co care vă va explica cum să îl utilizați
LayoutLM pentru etichetarea textului (Link)
Pentru a efectua etichetarea semantică, adică atribuirea de etichete diferitelor părți de text din document, veți avea nevoie de clasa transformers.LayoutLMForTokenClassification. Puteți găsi mai multe detalii despre La fel şi eu.Iată un mic exemplu de cod pentru a vedea cum poate funcționa pentru dvs
Câteva puncte de reținut despre Hugging Face LayoutLM
- În prezent, modelul Hugging Face LayoutLM folosește biblioteca open source Tesseract pentru extragerea textului, care nu este foarte precisă. Poate doriți să luați în considerare utilizarea unui alt instrument OCR plătit, cum ar fi AWS Text sau Google Cloud Vision
- Modelul existent oferă doar modelul de limbaj, adică înglobările LayoutLM, și nu straturile finale care combină caracteristicile vizuale. LayoutLMv2 (discutat în secțiunea următoare) folosește biblioteca Detectron pentru a activa și încorporarea caracteristicilor vizuale.
- Clasificarea etichetelor are loc la nivel de cuvânt, așa că depinde de motorul de extracție a textului OCR să se asigure că toate cuvintele dintr-un câmp sunt într-o secvență continuă, sau un câmp ar putea fi prezis ca două.
LayoutLMv2
LayoutLM a apărut ca o revoluție în modul în care erau extrase datele din documente. Cu toate acestea, în ceea ce privește cercetarea învățării profunde, modelele se îmbunătățesc din ce în ce mai mult în timp. LayoutLM a fost succedat în mod similar de LayoutLMv2, unde autorii au făcut câteva modificări semnificative la modul în care a fost antrenat modelul.
Inclusiv înglobări spațiale 1-D și înglobări de simboluri vizuale
LayoutLMv2 a inclus informații referitoare la locația relativă 1-D, precum și informații generale legate de imagine. Motivul pentru care acest lucru este important este din cauza noilor obiective de formare, pe care le vom discuta acum
Noi obiective de formare
LayoutLMv2 a inclus câteva obiective de antrenament modificate. Acestea sunt după cum urmează:
- Modelarea limbajului vizual mascat: este la fel ca în LayoutLM
- Alinierea imaginii textului: textul a fost acoperit aleatoriu din imagine, în timp ce simbolurile de text au fost furnizate modelului. Pentru fiecare jeton, modelul trebuia să învețe dacă textul dat a fost acoperit sau nu. Prin aceasta, modelul a reușit să combine informații atât din modalitățile vizuale, cât și din cele textuale
- Potrivirea imaginii text: modelului i se cere să verifice dacă imaginea dată corespunde textului dat. Mostrele negative fie sunt alimentate ca imagini false, fie nu sunt furnizate deloc încorporarea imaginilor. Acest lucru se face pentru a se asigura că modelul învață mai multe despre modul în care textul și imaginile sunt legate.
Folosind aceste noi metode și înglobări, modelul a reușit să obțină scoruri F1 mai mari pe aproape toate seturile de date de testare ca LayoutLM.
- Despre Noi
- acces
- Cont
- precis
- realizat
- peste
- activ
- avansat
- agenţi
- AI
- TOATE
- deja
- Cu toate ca
- sumă
- O alta
- abordare
- ZONĂ
- în jurul
- articol
- Autorii
- disponibil
- AWS
- bază
- fiind
- CEL MAI BUN
- Pic
- Cutie
- Carduri
- cazuri
- contesta
- clasificare
- Cloud
- cod
- combinate
- companie
- Calcula
- Configuraţie
- Conexiuni
- considerare
- Cheltuieli
- ar putea
- clienţii care
- de date
- zi
- În ciuda
- Detectare
- FĂCUT
- diferit
- documente
- jos
- e-commerce
- Eficace
- permițând
- stabili
- Excel
- Față
- mai repede
- Caracteristică
- DESCRIERE
- fed-
- financiar
- First
- următor
- genera
- GitHub
- ajutor
- ajută
- aici
- Cum
- Cum Pentru a
- HTTPS
- imagine
- Impactul
- important
- îmbunătăţi
- inclus
- industrii
- informații
- asigurare
- Inteligent
- IT
- etichetarea
- etichete
- limbă
- mai mare
- AFLAȚI
- învăţare
- Nivel
- Bibliotecă
- LINK
- Listă
- la nivel local
- locaţie
- Locații
- manual
- masiv
- potrivire
- materie
- model
- Modele
- cele mai multe
- reţea
- rețele
- deschide
- open-source
- Operațiuni
- Opţiuni
- comandă
- organizații
- Altele
- plătit
- Hârtie
- bucată
- putere
- proces
- furnizează
- PWC
- motive
- recomanda
- raportează
- necesar
- Cerinţe
- cercetare
- REZULTATE
- relua
- Alerga
- Scară
- schemă
- SEC
- sens
- set
- instalare
- schimbare
- semnificativ
- asemănător
- simplu
- Mărimea
- mic
- inteligent
- So
- ceva
- început
- succes
- livra
- lanțului de aprovizionare
- sarcini
- Tehnologia
- test
- Prin
- timp
- semn
- indicativele
- top
- Pregătire
- înţelege
- utilizare
- folosi
- valoare
- Ce
- dacă
- cuvinte
- Apartamente
- muncitorii
- ani