Imagini de Freepik
AI conversațional se referă la agenți virtuali și chatbot care imită interacțiunile umane și pot implica ființe umane în conversație. Folosirea AI conversațională devine rapid un mod de viață – de la a cere Alexa la „găsiți cel mai apropiat restaurant” să-i rog pe Siri să „creați un memento,” Asistenții virtuali și chatboții sunt adesea folosiți pentru a răspunde la întrebările consumatorilor, a rezolva reclamații, a face rezervări și multe altele.
Dezvoltarea acestor asistenți virtuali necesită un efort substanțial. Cu toate acestea, înțelegerea și abordarea provocărilor cheie poate simplifica procesul de dezvoltare. Am folosit experiența mea de primă mână în crearea unui chatbot matur pentru o platformă de recrutare ca punct de referință pentru a explica provocările cheie și soluțiile corespunzătoare.
Pentru a construi un chatbot AI conversațional, dezvoltatorii pot folosi cadre precum RASA, Amazon's Lex sau Google's Dialogflow pentru a construi chatbot-uri. Cei mai mulți preferă RASA atunci când planifică modificări personalizate sau bot-ul este în stadiul de maturitate, deoarece este un cadru open-source. Alte cadre sunt, de asemenea, potrivite ca punct de plecare.
Provocările pot fi clasificate ca trei componente majore ale unui chatbot.
Înțelegerea limbajului natural (NLU) este capacitatea unui bot de a înțelege dialogul uman. Efectuează clasificarea intențiilor, extragerea entităților și preluarea răspunsurilor.
Manager de dialog este responsabil pentru un set de acțiuni care trebuie efectuate pe baza setului curent și anterior de intrări ale utilizatorului. Ia intenția și entitățile ca intrare (ca parte a conversației anterioare) și identifică următorul răspuns.
Generarea limbajului natural (NLG) este procesul de generare a propozițiilor scrise sau rostite din date date. Acesta încadrează răspunsul, care este apoi prezentat utilizatorului.
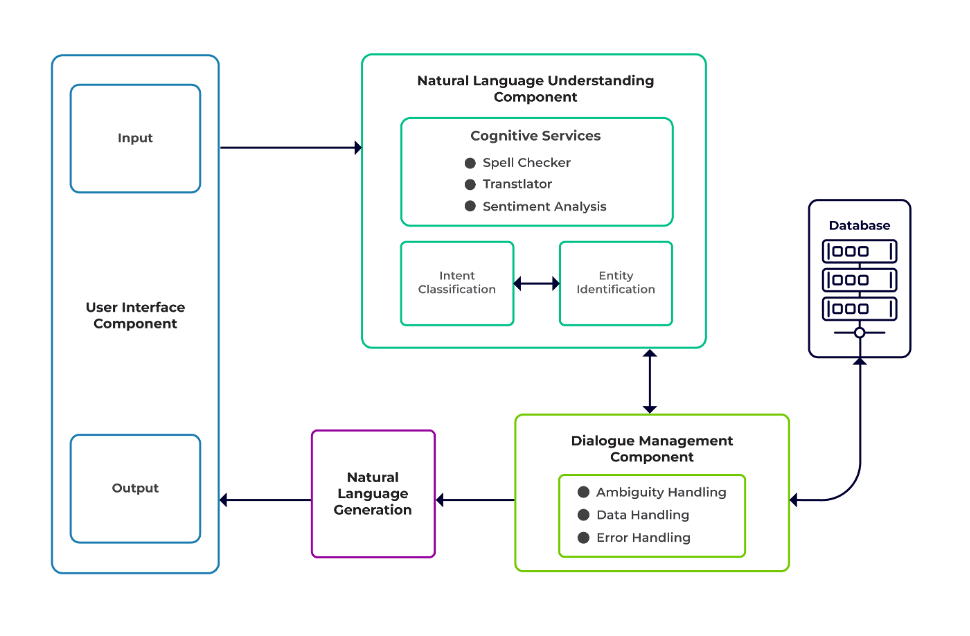
Imagine de la Talentica Software
Date insuficiente
Când dezvoltatorii înlocuiesc întrebările frecvente sau alte sisteme de asistență cu un chatbot, ei obțin o cantitate decentă de date de antrenament. Dar nu același lucru se întâmplă atunci când creează botul de la zero. În astfel de cazuri, dezvoltatorii generează datele de antrenament în mod sintetic.
Ce să fac?
Un generator de date bazat pe șabloane poate genera o cantitate decentă de interogări ale utilizatorilor pentru instruire. Odată ce chatbot-ul este gata, proprietarii de proiecte îl pot expune unui număr limitat de utilizatori pentru a îmbunătăți datele de instruire și a le actualiza pe o perioadă.
Alegerea modelului nepotrivit
Selecția adecvată a modelului și datele de instruire sunt cruciale pentru a obține cele mai bune rezultate ale extragerii de intenții și entități. De obicei, dezvoltatorii antrenează chatbot-uri într-o anumită limbă și domeniu, iar majoritatea modelelor disponibile pre-instruite sunt adesea specifice domeniului și instruite într-o singură limbă.
Pot exista și cazuri de limbi mixte în care oamenii sunt poligloți. Ei pot introduce interogări într-o limbă mixtă. De exemplu, într-o regiune dominată de franceză, oamenii pot folosi un tip de engleză care este un amestec de franceză și engleză.
Ce să fac?
Utilizarea modelelor instruite în mai multe limbi ar putea reduce problema. Un model pre-antrenat, cum ar fi LaBSE (încorporarea propoziției Bert agnostice de limbă) poate fi util în astfel de cazuri. LaBSE este instruit în mai mult de 109 de limbi pentru o sarcină de similaritate de propoziții. Modelul cunoaște deja cuvinte similare într-o altă limbă. În proiectul nostru, a funcționat foarte bine.
Extragerea necorespunzătoare a entității
Chatboții solicită entităților să identifice ce fel de date caută utilizatorul. Aceste entități includ ora, locul, persoana, elementul, data etc. Cu toate acestea, roboții nu pot identifica o entitate din limbajul natural:
Același context, dar entități diferite. De exemplu, roboții pot confunda un loc ca entitate atunci când un utilizator tasta „Numele studenților din IIT Delhi” și apoi „Numele studenților din Bengaluru”.
Scenarii în care entitățile sunt estimate greșit cu încredere scăzută. De exemplu, un bot poate identifica IIT Delhi ca un oraș cu încredere scăzută.
Extragerea parțială a entităților prin model de învățare automată. Dacă un utilizator scrie „studenți de la IIT Delhi”, modelul poate identifica doar „IIT” doar ca entitate în loc de „IIT Delhi”.
Intrările cu un singur cuvânt fără context pot încurca modelele de învățare automată. De exemplu, un cuvânt precum „Rishikesh” poate însemna atât numele unei persoane, cât și un oraș.
Ce să fac?
Adăugarea mai multor exemple de antrenament ar putea fi o soluție. Dar există o limită după care adăugarea mai multor nu ar ajuta. În plus, este un proces fără sfârșit. O altă soluție ar putea fi definirea modelelor regex folosind cuvinte predefinite pentru a ajuta la extragerea entităților cu un set cunoscut de valori posibile, cum ar fi orașul, țara etc.
Modelele au o încredere mai scăzută ori de câte ori nu sunt siguri de predicția entităților. Dezvoltatorii pot folosi acest lucru ca declanșator pentru a apela o componentă personalizată care poate rectifica entitatea cu încredere scăzută. Să luăm în considerare exemplul de mai sus. Dacă IIT Delhi este prezis ca un oraș cu încredere scăzută, atunci utilizatorul îl poate căuta oricând în baza de date. După ce nu a reușit să găsească entitatea prezisă în Oraș tabel, modelul ar trece la alte tabele și, în cele din urmă, îl va găsi în Institut tabel, rezultând corectarea entității.
Clasificare greșită a intenției
Fiecare mesaj de utilizator are o intenție asociată cu el. Deoarece intențiile derivă următorul curs de acțiuni al unui bot, clasificarea corectă a interogărilor utilizatorilor cu intenție este crucială. Cu toate acestea, dezvoltatorii trebuie să identifice intențiile cu o confuzie minimă între intenții. În caz contrar, pot exista cazuri deranjate de confuzie. De exemplu, "Arată-mi pozițiile deschise” vs.”Arată-mi candidați la posturi deschise”.
Ce să fac?
Există două moduri de a diferenția interogările confuze. În primul rând, un dezvoltator poate introduce sub-intentie. În al doilea rând, modelele pot gestiona interogări bazate pe entitățile identificate.
Un chatbot specific unui domeniu ar trebui să fie un sistem închis în care ar trebui să identifice clar de ce este capabil și ce nu este. Dezvoltatorii trebuie să facă dezvoltarea în faze în timp ce planifică chatbot-uri specifice domeniului. În fiecare fază, aceștia pot identifica caracteristicile neacceptate ale chatbot-ului (prin intenție neacceptată).
De asemenea, pot identifica ceea ce chatbot-ul nu poate gestiona în intenția „în afara domeniului de aplicare”. Dar ar putea exista cazuri în care botul este confuz cu intenția neacceptată și în afara domeniului de aplicare. Pentru astfel de scenarii, ar trebui să existe un mecanism de rezervă în care, dacă încrederea în intenție este sub un prag, modelul poate funcționa cu grație cu o intenție de rezervă pentru a gestiona cazurile de confuzie.
Odată ce botul identifică intenția mesajului unui utilizator, trebuie să trimită un răspuns înapoi. Botul decide răspunsul pe baza unui anumit set de reguli și povești definite. De exemplu, o regulă poate fi la fel de simplă ca absolută "Buna dimineata" când utilizatorul salută "Bună". Cu toate acestea, cel mai adesea, conversațiile cu chatbot cuprind interacțiune ulterioară, iar răspunsurile lor depind de contextul general al conversației.
Ce să fac?
Pentru a gestiona acest lucru, chatboții sunt hrăniți cu exemple de conversații reale numite Povești. Cu toate acestea, utilizatorii nu interacționează întotdeauna așa cum a fost prevăzut. Un chatbot matur ar trebui să gestioneze toate aceste abateri cu grație. Designerii și dezvoltatorii pot garanta acest lucru dacă nu se concentrează doar pe o cale fericită în timp ce scriu povești, ci lucrează și pe căi nefericite.
Interacțiunea utilizatorilor cu chatboții se bazează în mare măsură pe răspunsurile chatbot. Utilizatorii își pot pierde interesul dacă răspunsurile sunt prea robotizate sau prea familiare. De exemplu, unui utilizator poate să nu-i placă un răspuns precum „Ați introdus o interogare greșită” pentru o intrare greșită, chiar dacă răspunsul este corect. Răspunsul de aici nu se potrivește cu personajul unui asistent.
Ce să fac?
Chatbot-ul servește ca asistent și ar trebui să aibă o anumită persoană și un ton al vocii. Ar trebui să fie primitori și umili, iar dezvoltatorii ar trebui să conceapă conversații și enunțuri în consecință. Răspunsurile nu trebuie să sune robotizate sau mecanice. De exemplu, botul ar putea spune „Îmi pare rău, se pare că nu am detalii. Ați putea, vă rog, să reintroduceți interogarea dvs.?” pentru a aborda o intrare greșită.
Chatbot-urile bazate pe LLM (Large Language Model) precum ChatGPT și Bard sunt inovații care schimbă jocul și au îmbunătățit capacitățile IA conversaționale. Ei nu numai că sunt buni în a face conversații deschise asemănătoare oamenilor, dar pot îndeplini diferite sarcini, cum ar fi rezumarea textului, scrierea de paragrafe etc., care ar putea fi realizate mai devreme doar prin anumite modele.
Una dintre provocările sistemelor tradiționale de chatbot este clasificarea fiecărei propoziții în intenții și deciderea răspunsului în consecință. Această abordare nu este practică. Răspunsurile precum „Îmi pare rău, nu am putut să te înțeleg” sunt adesea iritante. Sistemele de chatbot fără intenție sunt calea de urmat, iar LLM-urile pot transforma acest lucru în realitate.
LLM-urile pot obține cu ușurință rezultate de ultimă generație în recunoașterea generală a entităților numite, cu excepția recunoașterii anumitor entități specifice domeniului. O abordare mixtă a utilizării LLM-urilor cu orice cadru de chatbot poate inspira un sistem de chatbot mai matur și mai robust.
Cu cele mai recente progrese și cercetarea continuă în IA conversațională, chatboții se îmbunătățesc în fiecare zi. Domenii precum gestionarea sarcinilor complexe cu intenții multiple, cum ar fi „Rezervați un zbor către Mumbai și aranjați un taxi până la Dadar”, primesc multă atenție.
În curând vor avea loc conversații personalizate pe baza caracteristicilor utilizatorului pentru a menține utilizatorul implicat. De exemplu, dacă un bot descoperă că utilizatorul este nemulțumit, redirecționează conversația către un agent real. În plus, cu datele de chatbot din ce în ce mai mari, tehnicile de învățare profundă precum ChatGPT pot genera automat răspunsuri pentru interogări folosind o bază de cunoștințe.
Suman Saurav este Data Scientist la Talentica Software, o companie de dezvoltare de produse software. El este un absolvent al NIT Agartala cu peste 8 ani de experiență în proiectarea și implementarea de soluții revoluționare AI folosind NLP, IA conversațională și AI generativă.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :are
- :este
- :nu
- :Unde
- 8
- a
- capacitate
- Despre Noi
- mai sus
- în consecință
- Obține
- realizat
- peste
- acțiuni
- adăugare
- În plus,
- adresa
- adresare
- progresele
- După
- Agent
- agenţi
- AI
- Chatbot AI
- Alexa
- TOATE
- deja
- de asemenea
- absolvent al unei școli
- mereu
- sumă
- an
- și
- O alta
- răspunde
- Orice
- abordare
- SUNT
- domenii
- AS
- solicitând
- Asistent
- asistenți
- asociate
- At
- atenţie
- în mod automat
- disponibil
- evita
- înapoi
- de bază
- bazat
- BE
- devenire
- ființe
- de mai jos
- CEL MAI BUN
- Mai bine
- Bot
- atât
- roboţii
- construi
- dar
- by
- apel
- denumit
- CAN
- nu poti
- capacități
- capabil
- cazuri
- categorizând
- sigur
- provocări
- Modificări
- Caracteristici
- chatbot
- chatbots
- Chat GPT
- Oraș
- clasificare
- clasificate
- clar
- închis
- companie
- plângeri
- complex
- component
- componente
- înţelege
- încredere
- confuz
- confuz
- confuzie
- Lua în considerare
- context
- continuu
- Conversație
- de conversaţie
- AI de conversație
- conversații
- corecta
- corect
- Corespunzător
- ar putea
- ţară
- înscrie-te la cursul
- crea
- Crearea
- crucial
- Curent
- personalizat
- de date
- om de știință de date
- Baza de date
- Data
- zi
- decent
- Decidând
- adânc
- învățare profundă
- defini
- definit
- Delhi
- depinde
- deriva
- Amenajări
- Designerii
- proiect
- detalii
- Dezvoltator
- Dezvoltatorii
- Dezvoltare
- flux de dialog
- Dialog
- diferit
- distinge
- do
- Nu
- domeniu
- Dont
- fiecare
- Mai devreme
- cu ușurință
- efort
- Încorporarea
- Fără sfârşit
- angaja
- angajat
- angajament
- Engleză
- spori
- Intrați
- entități
- entitate
- etc
- Chiar
- în cele din urmă
- tot mai mare
- Fiecare
- in fiecare zi
- exemplu
- exemple
- experienţă
- Explica
- extrage
- extracţie
- FAIL
- în lipsa
- familiar
- FAST
- DESCRIERE
- fed-
- Găsi
- descoperiri
- zbor
- Concentra
- Pentru
- Înainte
- Cadru
- cadre
- Franceză
- din
- General
- genera
- generator
- generaţie
- generativ
- AI generativă
- generator
- obține
- obtinerea
- dat
- bine
- garanta
- manipula
- Manipularea
- întâmpla
- fericit
- Avea
- având în
- he
- puternic
- ajutor
- util
- aici
- Cum
- Cum Pentru a
- Totuși
- HTTPS
- uman
- umil
- i
- identificat
- identifică
- identifica
- if
- Punere în aplicare a
- îmbunătățit
- in
- include
- inovații
- intrare
- intrări
- inspira
- instanță
- in schimb
- destinate
- scop
- interacţiona
- interacţiune
- interacţiuni
- interes
- în
- introduce
- IT
- jpg
- doar
- KDnuggets
- A pastra
- Cheie
- Copil
- cunoştinţe
- cunoscut
- știe
- limbă
- Limbă
- mare
- Ultimele
- învăţare
- Viaţă
- ca
- LIMITĂ
- Limitat
- pierde
- Jos
- LOWER
- maşină
- masina de învățare
- major
- face
- Efectuarea
- Meci
- matur
- Mai..
- me
- însemna
- mecanic
- mecanism
- mesaj
- ar putea
- minim
- amesteca
- mixt
- model
- Modele
- mai mult
- În plus
- cele mai multe
- mult
- multiplu
- Mumbai
- trebuie sa
- my
- nume
- Numit
- Natural
- Limbajul natural
- următor
- NLG
- nlp
- nlu
- Nu.
- număr
- of
- de multe ori
- on
- dată
- afară
- deschide
- open-source
- or
- Altele
- in caz contrar
- al nostru
- peste
- global
- Proprietarii
- parte
- cale
- căi
- modele
- oameni
- efectua
- efectuată
- efectuează
- perioadă
- persoană
- Personalizat
- fază
- faze
- Loc
- plan
- planificare
- platformă
- Plato
- Informații despre date Platon
- PlatoData
- "vă rog"
- Punct
- poziţie
- poseda
- posibil
- Practic
- a prezis
- prezicere
- a prefera
- prezentat
- precedent
- Problemă
- continua
- proces
- Produs
- dezvoltare de produs
- proiect
- interogări
- Întrebări
- R
- Rasa
- gata
- real
- Realitate
- într-adevăr
- recunoaştere
- recrutare
- reduce
- referință
- se referă
- regiune
- se bazează
- aducere aminte
- înlocui
- necesita
- Necesită
- cercetare
- rezolvă
- răspuns
- răspunsuri
- responsabil
- rezultând
- REZULTATE
- revoluționar
- robust
- Regula
- norme
- acelaşi
- Spune
- scenarii
- Om de stiinta
- zgâria
- Caută
- căutare
- pare
- selecţie
- trimite
- propoziție
- servește
- set
- Distribuie
- să
- asemănător
- simplu
- întrucât
- singur
- crab
- Software
- soluţie
- soluţii
- unele
- Suna
- specific
- vorbit
- Etapă
- Pornire
- de ultimă oră
- Istorii
- simplifica
- Elevi
- substanțial
- astfel de
- potrivit
- a sustine
- Sisteme de suport
- sigur
- sintetic
- sistem
- sisteme
- T
- tabel
- Lua
- ia
- Sarcină
- sarcini
- tehnici de
- a) Sport and Nutrition Awareness Day in Manasia Around XNUMX people from the rural commune Manasia have participated in a sports and healthy nutrition oriented activity in one of the community’s sports ready yards. This activity was meant to gather, mainly, middle-aged people from a Romanian rural community and teach them about the benefits that sports have on both their mental and physical health and on how sporting activities can be used to bring people from a community closer together. Three trainers were made available for this event, so that the participants would get the best possible experience physically and so that they could have the best access possible to correct information and good sports/nutrition practices. b) Sports Awareness Day in Poiana Țapului A group of young participants have taken part in sporting activities meant to teach them about sporting conduct, fairplay, and safe physical activities. The day culminated with a football match.
- decât
- acea
- lor
- Lor
- apoi
- Acolo.
- Acestea
- ei
- acest
- deşi?
- trei
- prag
- timp
- la
- TONE
- Tonul vocii
- de asemenea
- tradiţional
- Tren
- dresat
- Pregătire
- declanşa
- Două
- tip
- Tipuri
- înţelegere
- upgrade-ul
- utilizare
- utilizat
- Utilizator
- utilizatorii
- folosind
- obișnuit
- Valori
- de
- Virtual
- Voce
- vs
- W
- Cale..
- modalități de
- salutând
- BINE
- Ce
- cand
- oricând
- care
- în timp ce
- voi
- cu
- Cuvânt
- cuvinte
- Apartamente
- a lucrat
- ar
- scris
- scris
- Greșit
- ani
- tu
- Ta
- zephyrnet