Os pesquisadores continuam desenvolvendo novas arquiteturas de modelo para tarefas comuns de aprendizado de máquina (ML). Uma dessas tarefas é a classificação de imagens, onde as imagens são aceitas como entrada e o modelo tenta classificar a imagem como um todo com saídas de rótulos de objetos. Com muitos modelos disponíveis hoje que executam essa tarefa de classificação de imagem, um profissional de ML pode fazer perguntas como: “Qual modelo devo ajustar e implantar para obter o melhor desempenho em meu conjunto de dados?” E um pesquisador de ML pode fazer perguntas como: “Como posso gerar minha própria comparação justa de várias arquiteturas de modelo em um conjunto de dados especificado enquanto controlo hiperparâmetros de treinamento e especificações de computador, como GPUs, CPUs e RAM?” A primeira pergunta aborda a seleção de modelo em arquiteturas de modelo, enquanto a última pergunta diz respeito ao benchmarking de modelos treinados em relação a um conjunto de dados de teste.
Neste post, você verá como o Classificação de imagens do TensorFlow algoritmo de JumpStart do Amazon SageMaker pode simplificar as implementações necessárias para resolver essas questões. Juntamente com os detalhes de implementação em um exemplo de notebook Jupyter, você terá ferramentas disponíveis para realizar a seleção de modelos explorando as fronteiras de pareto, onde melhorar uma métrica de desempenho, como precisão, não é possível sem piorar outra métrica, como taxa de transferência.
Visão geral da solução
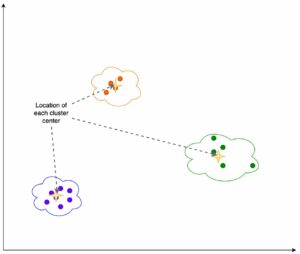
A figura a seguir ilustra a compensação de seleção de modelo para um grande número de modelos de classificação de imagem ajustados no Caltech-256 conjunto de dados, que é um conjunto desafiador de 30,607 imagens do mundo real abrangendo 256 categorias de objetos. Cada ponto representa um único modelo, os tamanhos dos pontos são dimensionados em relação ao número de parâmetros que compõem o modelo e os pontos são codificados por cores com base na arquitetura do modelo. Por exemplo, os pontos verdes claros representam a arquitetura EfficientNet; cada ponto verde claro é uma configuração diferente dessa arquitetura com medições de desempenho de modelo ajustadas com precisão. A figura mostra a existência de uma fronteira pareto para seleção de modelo, onde maior precisão é trocada por menor throughput. Em última análise, a seleção de um modelo ao longo da fronteira pareto, ou o conjunto de soluções pareto eficientes, depende dos requisitos de desempenho de implantação do seu modelo.
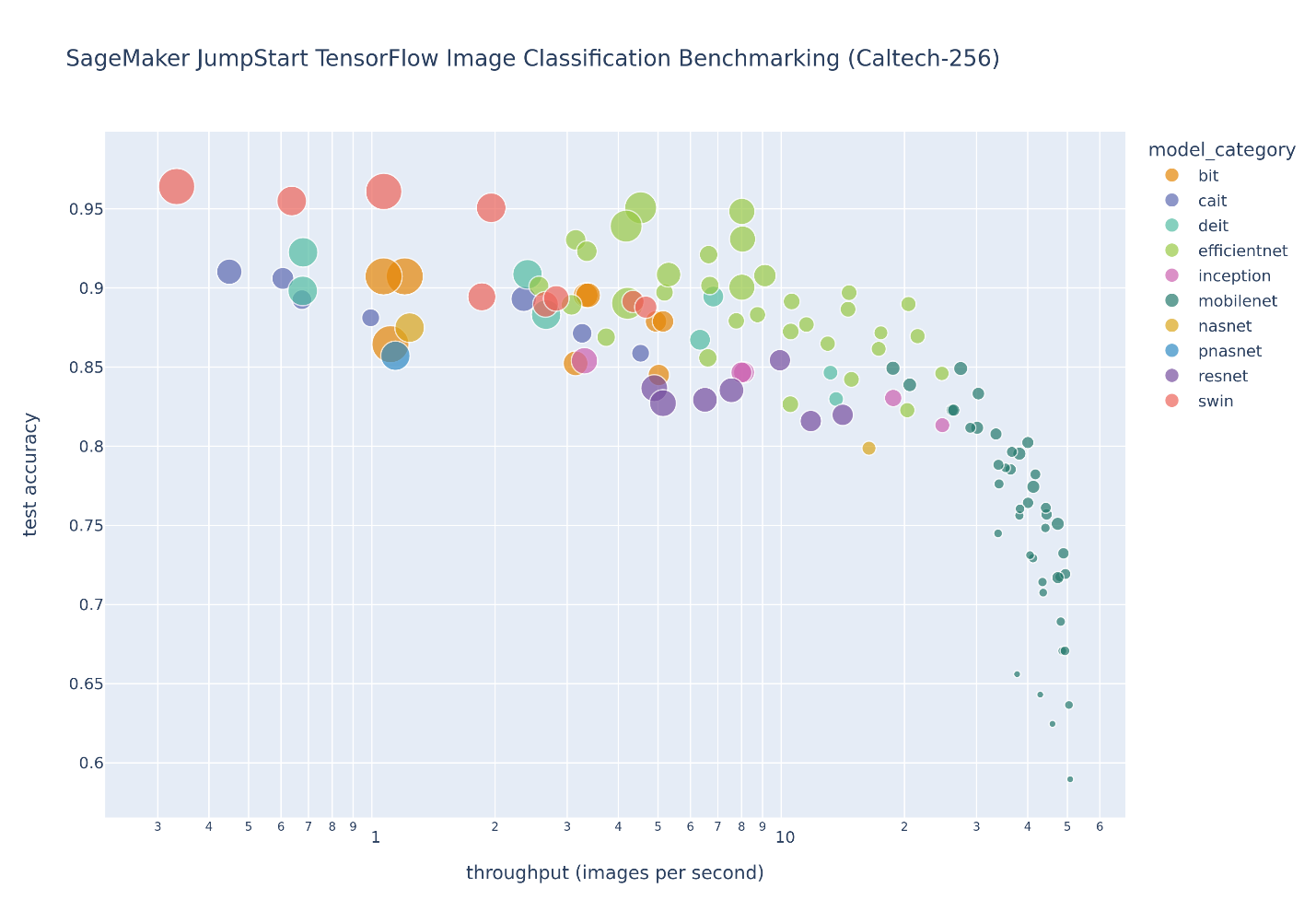
Se você observar a precisão do teste e as fronteiras de taxa de transferência de teste de interesse, o conjunto de soluções pareto eficientes na figura anterior será extraído na tabela a seguir. As linhas são classificadas de forma que a produtividade do teste aumente e a precisão do teste diminua.
| Nome do modelo | Número de parâmetros | Precisão do teste | Testar 5 principais precisão | Rendimento (imagens/s) | Duração por Época(s) |
| swin-large-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| eficientenet-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| eficientenet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| eficientenet-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| eficientenet-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| eficientenet-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| eficientenet-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| eficientenet-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobilenet-v3-grande-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobilenet-v3-grande-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
Este post fornece detalhes sobre como implementar em larga escala Amazon Sage Maker tarefas de benchmarking e seleção de modelos. Primeiro, apresentamos o JumpStart e os algoritmos de classificação de imagens TensorFlow integrados. Em seguida, discutimos considerações de implementação de alto nível, como configurações de hiperparâmetros JumpStart, extração de métricas de Logs do Amazon CloudWatche iniciar trabalhos de ajuste de hiperparâmetros assíncronos. Por fim, abordamos o ambiente de implementação e a parametrização que leva às soluções pareto eficientes na tabela e na figura anteriores.
Introdução à classificação de imagens JumpStart TensorFlow
O JumpStart fornece ajuste fino com um clique e implantação de uma ampla variedade de modelos pré-treinados em tarefas populares de ML, bem como uma seleção de soluções completas que resolvem problemas comerciais comuns. Esses recursos removem o trabalho pesado de cada etapa do processo de ML, facilitando o desenvolvimento de modelos de alta qualidade e reduzindo o tempo de implantação. O APIs JumpStart permitem que você implante e ajuste programaticamente uma vasta seleção de modelos pré-treinados em seus próprios conjuntos de dados.
O hub de modelo JumpStart fornece acesso a um grande número de Modelos de classificação de imagens do TensorFlow que permitem o aprendizado de transferência e o ajuste fino em conjuntos de dados personalizados. Até o momento, o hub de modelos JumpStart contém 135 modelos de classificação de imagens do TensorFlow em uma variedade de arquiteturas de modelos populares de Hub do TensorFlow, para incluir redes residuais (ResNet), MobileNet, EficienteNet, Começo, Redes de pesquisa de arquitetura neural (NASNet), Grande Transferência (Mordeu), janela deslocada (Nadar) transformadores, atenção de classe em transformadores de imagem (CaiT) e transformadores de imagem com eficiência de dados (DeiT).
Estruturas internas muito diferentes compreendem cada arquitetura de modelo. Por exemplo, os modelos ResNet utilizam conexões de salto para permitir redes substancialmente mais profundas, enquanto os modelos baseados em transformadores usam mecanismos de auto-atenção que eliminam a localidade intrínseca das operações de convolução em favor de campos receptivos mais globais. Além dos diversos conjuntos de recursos que essas diferentes estruturas fornecem, cada arquitetura de modelo possui várias configurações que ajustam o tamanho, a forma e a complexidade do modelo dentro dessa arquitetura. Isso resulta em centenas de modelos exclusivos de classificação de imagens disponíveis no hub de modelos JumpStart. Combinada com aprendizado de transferência integrado e scripts de inferência que abrangem muitos recursos do SageMaker, a API JumpStart é um excelente ponto de partida para os profissionais de ML começarem a treinar e implantar modelos rapidamente.
Consulte Transferir aprendizado para modelos de classificação de imagem do TensorFlow no Amazon SageMaker e o seguinte caderno de exemplo para saber mais sobre a classificação de imagens do SageMaker TensorFlow, incluindo como executar a inferência em um modelo pré-treinado, bem como ajustar o modelo pré-treinado em um conjunto de dados personalizado.
Considerações de seleção de modelo em grande escala
A seleção de modelo é o processo de selecionar o melhor modelo de um conjunto de modelos candidatos. Este processo pode ser aplicado em modelos do mesmo tipo com diferentes pesos de parâmetros e em modelos de diferentes tipos. Exemplos de seleção de modelos entre modelos do mesmo tipo incluem o ajuste do mesmo modelo com diferentes hiperparâmetros (por exemplo, taxa de aprendizado) e parada antecipada para evitar o superajuste dos pesos do modelo ao conjunto de dados do trem. A seleção de modelos entre modelos de diferentes tipos inclui a seleção da melhor arquitetura de modelo (por exemplo, Swin vs. MobileNet) e a seleção das melhores configurações de modelo em uma única arquitetura de modelo (por exemplo, mobilenet-v1-025-128 vs mobilenet-v3-large-100-224).
As considerações descritas nesta seção permitem todos esses processos de seleção de modelo em um conjunto de dados de validação.
Selecione configurações de hiperparâmetros
A classificação de imagens do TensorFlow no JumpStart tem um grande número de hiperparâmetros que pode ajustar os comportamentos do script de aprendizado de transferência uniformemente para todas as arquiteturas de modelo. Esses hiperparâmetros estão relacionados ao aumento e pré-processamento de dados, especificação do otimizador, controles de sobreajuste e indicadores de camada treináveis. Você é encorajado a ajustar os valores padrão desses hiperparâmetros conforme necessário para seu aplicativo:
Para esta análise e o notebook associado, todos os hiperparâmetros são definidos com valores padrão, exceto para taxa de aprendizado, número de épocas e especificação de parada antecipada. A taxa de aprendizagem é ajustada como um parâmetro categórico pelo SageMaker ajuste automático do modelo trabalho. Como cada modelo tem valores de hiperparâmetro padrão exclusivos, a lista discreta de possíveis taxas de aprendizado inclui a taxa de aprendizado padrão, bem como um quinto da taxa de aprendizado padrão. Isso inicia dois trabalhos de treinamento para um único trabalho de ajuste de hiperparâmetros e o trabalho de treinamento com o melhor desempenho relatado no conjunto de dados de validação é selecionado. Como o número de épocas é definido como 10, que é maior do que a configuração de hiperparâmetro padrão, o melhor trabalho de treinamento selecionado nem sempre corresponde à taxa de aprendizado padrão. Por fim, utiliza-se um critério de parada precoce com uma paciência, ou o número de épocas para continuar treinando sem melhora, de três épocas.
Uma configuração de hiperparâmetro padrão de particular importância é train_only_on_top_layer, onde, se definido como True, as camadas de extração de recursos do modelo não são ajustadas no conjunto de dados de treinamento fornecido. O otimizador treinará apenas parâmetros na camada de classificação totalmente conectada superior com dimensionalidade de saída igual ao número de rótulos de classe no conjunto de dados. Por padrão, esse hiperparâmetro é definido como True, que é uma configuração direcionada para aprendizado de transferência em pequenos conjuntos de dados. Você pode ter um conjunto de dados personalizado em que a extração de recursos do pré-treinamento no conjunto de dados ImageNet não é suficiente. Nestes casos, você deve definir train_only_on_top_layer para False. Embora essa configuração aumente o tempo de treinamento, você extrairá recursos mais significativos para o seu problema de interesse, aumentando assim a precisão.
Extraia métricas do CloudWatch Logs
O algoritmo de classificação de imagem JumpStart TensorFlow registra de forma confiável uma variedade de métricas durante o treinamento que são acessíveis ao SageMaker Estimator e objetos HyperparameterTuner. O construtor de um SageMaker Estimator tem um metric_definitions argumento de palavra-chave, que pode ser usado para avaliar o trabalho de treinamento fornecendo uma lista de dicionários com duas chaves: Nome para o nome da métrica e Regex para a expressão regular usada para extrair a métrica dos logs. O acompanhamento caderno mostra os detalhes da implementação. A tabela a seguir lista as métricas disponíveis e as expressões regulares associadas para todos os modelos de classificação de imagem JumpStart TensorFlow.
| Nome da métrica | Expressão Regular |
| número de parâmetros | “- Número de parâmetros: ([0-9\.]+)” |
| número de parâmetros treináveis | “- Número de parâmetros treináveis: ([0-9\.]+)” |
| número de parâmetros não treináveis | “- Número de parâmetros não treináveis: ([0-9\.]+)” |
| métrica de conjunto de dados de treinamento | f”- {métrica}: ([0-9\.]+)” |
| métrica de conjunto de dados de validação | f”- val_{métrica}: ([0-9\.]+)” |
| métrica de conjunto de dados de teste | f”- Teste {métrica}: ([0-9\.]+)” |
| duração do trem | “- Duração total do treino: ([0-9\.]+)” |
| duração do trem por época | “- Duração média do treino por época: ([0-9\.]+)” |
| latência de avaliação de teste | “- Latência de avaliação do teste: ([0-9\.]+)” |
| latência de teste por amostra | “- Latência média do teste por amostra: ([0-9\.]+)” |
| taxa de transferência de teste | “- Rendimento médio do teste: ([0-9\.]+)” |
O script de aprendizado de transferência integrado fornece uma variedade de métricas de conjunto de dados de treinamento, validação e teste dentro dessas definições, conforme representado pelos valores de substituição de f-string. As métricas exatas disponíveis variam de acordo com o tipo de classificação que está sendo executada. Todos os modelos compilados têm um loss métrica, que é representada por uma perda de entropia cruzada para um problema de classificação binária ou categórica. O primeiro é usado quando há um rótulo de classe; o último é usado se houver dois ou mais rótulos de classe. Se houver apenas um único rótulo de classe, as seguintes métricas serão calculadas, registradas e extraídas por meio das expressões regulares de string f na tabela anterior: número de verdadeiros positivos (true_pos), número de falsos positivos (false_pos), número de verdadeiros negativos (true_neg), número de falsos negativos (false_neg), precision, recall, área sob a curva característica de operação do receptor (ROC) (auc) e área sob a curva de recuperação de precisão (PR) (prc). Da mesma forma, se houver seis ou mais rótulos de classe, uma das 5 principais métricas de precisão (top_5_accuracy) também pode ser calculado, registrado e extraído por meio das expressões regulares anteriores.
Durante o treinamento, as métricas especificadas para um SageMaker Estimator são emitidos para o CloudWatch Logs. Quando o treinamento estiver completo, você pode invocar o API DescriptionTrainingJob do SageMaker e inspecionar o FinalMetricDataList chave na resposta JSON:
Essa API requer apenas o nome do trabalho a ser fornecido para a consulta, portanto, uma vez concluída, as métricas podem ser obtidas em análises futuras, desde que o nome do trabalho de treinamento seja devidamente registrado e recuperável. Para esta tarefa de seleção de modelo, os nomes dos trabalhos de ajuste de hiperparâmetros são armazenados e as análises subsequentes reanexam um HyperparameterTuner objeto dado o nome do trabalho de ajuste, extraia o melhor nome de trabalho de treinamento do sintonizador de hiperparâmetro anexado e chame o DescribeTrainingJob API conforme descrito anteriormente para obter métricas associadas ao melhor trabalho de treinamento.
Iniciar trabalhos de ajuste de hiperparâmetros assíncronos
Consulte o correspondente caderno para obter detalhes de implementação sobre tarefas de ajuste de hiperparâmetros de inicialização assíncrona, que usa a biblioteca padrão do Python futuros simultâneos module, uma interface de alto nível para chamadas de execução assíncrona. Várias considerações relacionadas ao SageMaker são implementadas nesta solução:
- Cada conta da AWS é afiliada com Cotas de serviço do SageMaker. Você deve visualizar seus limites atuais para utilizar totalmente seus recursos e, potencialmente, solicitar aumentos de limite de recursos conforme necessário.
- Chamadas de API frequentes para criar muitos trabalhos de ajuste de hiperparâmetros simultâneos podem exceder a taxa do Python SDK e lançar exceções de limitação. Uma solução para isso é criar um cliente SageMaker Boto3 com uma configuração de repetição personalizada.
- O que acontece se o seu script encontrar um erro ou se o script for interrompido antes da conclusão? Para uma seleção de modelo tão grande ou estudo de benchmarking, você pode registrar nomes de tarefas de ajuste e fornecer funções de conveniência para reanexar trabalhos de ajuste de hiperparâmetros que já existem:
Detalhes da análise e discussão
A análise neste post realiza aprendizado de transferência para IDs de modelo no algoritmo de classificação de imagem JumpStart TensorFlow no conjunto de dados Caltech-256. Todos os trabalhos de treinamento foram executados na instância de treinamento SageMaker ml.g4dn.xlarge, que contém uma única GPU NVIDIA T4.
O conjunto de dados de teste é avaliado na instância de treinamento no final do treinamento. A seleção do modelo é realizada antes da avaliação do conjunto de dados de teste para definir os pesos do modelo para a época com o melhor desempenho do conjunto de validação. A taxa de transferência do teste não é otimizada: o tamanho do lote do conjunto de dados é definido como o tamanho do lote do hiperparâmetro de treinamento padrão, que não é ajustado para maximizar o uso da memória da GPU; a taxa de transferência de teste relatada inclui tempo de carregamento de dados porque o conjunto de dados não é pré-armazenado em cache; e a inferência distribuída em várias GPUs não é utilizada. Por esses motivos, essa taxa de transferência é uma boa medida relativa, mas a taxa de transferência real dependeria muito das configurações de implantação do ponto de extremidade de inferência para o modelo treinado.
Embora o hub do modelo JumpStart contenha muitos tipos de arquitetura de classificação de imagens, essa fronteira pareto é dominada por modelos Swin, EfficientNet e MobileNet selecionados. Os modelos Swin são maiores e relativamente mais precisos, enquanto os modelos MobileNet são menores, relativamente menos precisos e adequados para restrições de recursos de dispositivos móveis. É importante observar que essa fronteira está condicionada a uma variedade de fatores, incluindo o conjunto de dados exato usado e os hiperparâmetros de ajuste fino selecionados. Você pode descobrir que seu conjunto de dados personalizado produz um conjunto diferente de soluções pareto eficientes e pode desejar tempos de treinamento mais longos com hiperparâmetros diferentes, como mais aumento de dados ou ajuste fino além da camada de classificação superior do modelo.
Conclusão
Nesta postagem, mostramos como executar tarefas de seleção de modelos ou benchmarking em grande escala usando o hub de modelo JumpStart. Esta solução pode ajudá-lo a escolher o melhor modelo para as suas necessidades. Nós encorajamos você a experimentar e explorar este solução em seu próprio conjunto de dados.
Referências
Mais informações estão disponíveis nos seguintes recursos:
Sobre os autores
 Dr. é um Cientista Aplicado com o Algoritmos integrados do Amazon SageMaker equipe. Seus interesses de pesquisa incluem algoritmos de aprendizado de máquina escaláveis, visão computacional, séries temporais, processos não paramétricos bayesianos e processos gaussianos. Seu PhD é pela Duke University e ele publicou artigos em NeurIPS, Cell e Neuron.
Dr. é um Cientista Aplicado com o Algoritmos integrados do Amazon SageMaker equipe. Seus interesses de pesquisa incluem algoritmos de aprendizado de máquina escaláveis, visão computacional, séries temporais, processos não paramétricos bayesianos e processos gaussianos. Seu PhD é pela Duke University e ele publicou artigos em NeurIPS, Cell e Neuron.
 Dr. é um Cientista Aplicado Sênior com Algoritmos integrados do Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD da Universidade de Illinois Urbana Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos nas conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
Dr. é um Cientista Aplicado Sênior com Algoritmos integrados do Amazon SageMaker e ajuda a desenvolver algoritmos de aprendizado de máquina. Ele obteve seu PhD da Universidade de Illinois Urbana Champaign. Ele é um pesquisador ativo em aprendizado de máquina e inferência estatística e publicou muitos artigos nas conferências NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/image-classification-model-selection-using-amazon-sagemaker-jumpstart/
- 10
- 100
- 9
- a
- Sobre
- Acesso
- acessível
- Conta
- precisão
- preciso
- Alcançar
- em
- ativo
- Adição
- endereço
- endereços
- Ajustado
- Afiliado
- contra
- algoritmo
- algoritmos
- Todos os Produtos
- já
- Apesar
- sempre
- Amazon
- Amazon Sage Maker
- JumpStart do Amazon SageMaker
- análise
- e
- Outro
- api
- Aplicação
- aplicado
- adequadamente
- arquitetura
- ÁREA
- argumento
- associado
- anexar
- Tentativas
- Automático
- disponível
- média
- AWS
- baseado
- Bayesiano
- Porque
- antes
- ser
- MELHOR
- Grande
- construídas em
- negócio
- chamadas
- candidato
- casos
- Categorias
- desafiante
- característica
- Escolha
- classe
- classificação
- classificar
- cliente
- combinado
- comum
- comparação
- completar
- Efetuado
- realização
- complexidade
- computador
- Visão de Computador
- Preocupações
- conferências
- Configuração
- conectado
- Coneções
- Considerações
- restrições
- contém
- continuar
- controle
- controles
- facilidade
- Correspondente
- cobrir
- crio
- Atual
- curva
- personalizadas
- dados,
- conjuntos de dados
- mais profunda
- Padrão
- depende
- implantar
- Implantação
- desenvolvimento
- profundidade
- descrito
- descrição
- detalhes
- desenvolver
- Dispositivos/Instrumentos
- diferente
- discutir
- distribuído
- diferente
- Não faz
- Duque
- Universidade Duke
- durante
- cada
- Mais cedo
- Cedo
- mais fácil
- eficiente
- ou
- eliminado
- permitir
- encorajar
- encorajados
- end-to-end
- Ponto final
- Meio Ambiente
- época
- épocas
- erro
- Éter (ETH)
- avaliar
- avaliadas
- avaliação
- exemplo
- exemplos
- Exceto
- explorar
- Explorando
- expressões
- extrato
- Extração
- fatores
- feira
- favorecer
- Característica
- Funcionalidades
- Campos
- Figura
- Finalmente
- Encontre
- Primeiro nome
- apropriado
- seguinte
- Antigo
- da
- Frontier
- Fronteiras
- totalmente
- funções
- futuro
- futuros
- gerar
- ter
- dado
- Global
- Bom estado, com sinais de uso
- GPU
- GPUs
- ótimo
- maior
- Verde
- acontece
- fortemente
- ajudar
- ajuda
- de alto nível
- alta qualidade
- superior
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- HTTPS
- Hub
- Centenas
- Ajuste de hiperparâmetros
- ICLR
- Illinois
- imagem
- Classificação de imagem
- IMAGEnet
- imagens
- executar
- implementação
- implementado
- importância
- importante
- melhoria
- melhorar
- in
- incluir
- inclui
- Incluindo
- Crescimento
- Aumenta
- aumentando
- indicadores
- INFORMAÇÕES
- entrada
- instância
- interesse
- interesses
- Interface
- interno
- intrínseco
- introduzir
- IT
- Trabalho
- Empregos
- json
- Chave
- chaves
- O rótulo
- Rótulos
- grande
- em grande escala
- Maior
- Latência
- lança
- de lançamento
- camada
- camadas
- principal
- APRENDER
- aprendizagem
- facelift
- leve
- LIMITE
- limites
- Lista
- listas
- carregamento
- longo
- mais
- fora
- máquina
- aprendizado de máquina
- Fazendo
- muitos
- Maximizar
- significativo
- medições
- Memória
- métrico
- Métrica
- ML
- Móvel Esteira
- dispositivos móveis
- modelo
- modelos
- módulo
- mais
- múltiplo
- nome
- nomes
- necessário
- necessário
- Cria
- redes
- Neural
- NeuroIPS
- Novo
- caderno
- número
- Nvidia
- objeto
- objetos
- observar
- obter
- obtido
- ONE
- operando
- Operações
- otimizado
- delineado
- próprio
- papéis
- parâmetro
- parâmetros
- particular
- Paciência
- realizar
- atuação
- executa
- platão
- Inteligência de Dados Platão
- PlatãoData
- ponto
- pontos
- Popular
- possível
- Publique
- potencialmente
- pr
- evitar
- Prévio
- Problema
- problemas
- processo
- processos
- fornecer
- fornecido
- fornece
- fornecendo
- publicado
- Python
- questão
- Frequentes
- rapidamente
- RAM
- Taxa
- Preços
- mundo real
- razões
- redução
- regular
- relativamente
- remover
- Informou
- representar
- representado
- representa
- solicitar
- requeridos
- Requisitos
- exige
- pesquisa
- investigador
- Resolução
- recurso
- Recursos
- resposta
- Resultados
- Execute
- corrida
- sábio
- mesmo
- escalável
- Cientista
- Scripts
- Sdk
- Pesquisar
- Seção
- selecionado
- selecionando
- doadores,
- senior
- Série
- serviço
- Sessão
- conjunto
- Conjuntos
- contexto
- vários
- Shape
- rede de apoio social
- Shows
- Similarmente
- simplificar
- Simultâneo
- solteiro
- SIX
- Tamanho
- tamanhos
- pequeno
- menor
- So
- solução
- Soluções
- RESOLVER
- especificação
- especificações
- especificada
- padrão
- começado
- estatístico
- Passo
- parou
- paragem
- armazenadas
- Estudo
- subseqüente
- substancialmente
- tal
- suficiente
- adequado
- mesa
- visadas
- Tarefa
- tarefas
- Profissionais
- fluxo tensor
- teste
- A
- deles
- assim
- três
- Taxa de transferência
- tempo
- Séries temporais
- vezes
- para
- hoje
- juntos
- ferramentas
- topo
- 5 topo
- Total
- Trem
- treinado
- Training
- transferência
- transformadores
- verdadeiro
- tipos
- Em última análise
- para
- único
- universidade
- Uso
- usar
- utilizar
- utilizado
- validação
- Valores
- variedade
- Grande
- via
- Ver
- visão
- qual
- enquanto
- Largo
- precisarão
- dentro
- sem
- seria
- escrita
- investimentos
- zefirnet