Amazona Kendra é um serviço de pesquisa inteligente fácil de usar que permite integrar recursos de pesquisa com seus aplicativos para que os usuários possam encontrar informações armazenadas em fontes de dados como Serviço de armazenamento simples da Amazon , OneDrive e Google Drive; aplicativos como SalesForce, SharePoint e Service Now; e bancos de dados relacionais como Serviço de banco de dados relacional da Amazon (RDS da Amazônia). O uso de conectores Amazon Kendra permite sincronizar dados de vários repositórios de conteúdo com seu índice Amazon Kendra. Quando os usuários finais fazem perguntas em linguagem natural, o Amazon Kendra usa algoritmos de aprendizado de máquina (ML) para entender o contexto e retornar as respostas mais relevantes.
O conector S3 do Amazon Kendra oferece suporte à indexação de documentos e seus metadados associados armazenados em um bucket S3. Muitas vezes, você deseja garantir que os aplicativos executados em uma VPC tenham acesso apenas a buckets S3 específicos e, em muitos casos, a conexão não deve atravessar a Internet para alcançar endpoints públicos. Muitos clientes, no entanto, possuem vários buckets S3, alguns dos quais podem ser acessados por VPC endpoints para Amazon S3. Nesta postagem, descrevemos como usar o conector Amazon Kendra S3 atualizado com suporte a VPC para usar VPC endpoints.
Esta postagem fornece as etapas para ajudá-lo a criar um mecanismo de pesquisa empresarial na AWS usando o Amazon Kendra, conectando documentos armazenados em um bucket S3 acessível apenas de dentro de uma VPC. Para mais informações, veja aprimorando a pesquisa corporativa com o Amazon Kendra. A postagem também demonstra como configurar seu conector para Amazon S3 e configurar como seu índice é sincronizado com sua fonte de dados quando o conteúdo da fonte de dados muda.
Visão geral da solução
Existem três melhorias principais no Conector Amazon Kendra S3 :
- Suporte a VPC – O conector agora suporta o uso do seu Nuvem virtual privada da Amazon (Amazon VPC). Agora você pode se conectar com segurança ao Amazon S3 usando VPC endpoints para Amazon S3 especificando a conexão VPC, a sub-rede e os grupos de segurança.
- Dois modos de sincronização - Ao agendar a sincronização de uma fonte de dados no Amazon S3 para um índice do Amazon Kendra, agora você pode optar por executar no modo de sincronização completa ou no modo de sincronização de documentos novos, modificados e excluídos. No modo de sincronização completa, toda vez que a sincronização é executada, ela verifica os objetos em todas as pastas no caminho raiz para o qual foi configurado para rastrear e ingere novamente todos os documentos. A atualização completa permite redefinir o índice sem a necessidade de excluir e criar uma nova fonte de dados. No modo de sincronização de documentos novos, modificados e excluídos, toda vez que o trabalho de sincronização é executado, ele processa apenas os objetos que foram adicionados, modificados ou excluídos desde o último rastreamento. Os rastreamentos incrementais podem reduzir o tempo de execução e o custo quando usados com conjuntos de dados que acrescentam novos objetos a fontes de dados existentes regularmente.
- Padrões de inclusão e exclusão adicionais para documentos: além dos prefixos, estamos introduzindo padrões para inclusão ou exclusão de documentos do seu índice. Dois tipos de padrão suportados são os tipos de arquivo ou glob estilo Unix. Agora você pode adicionar um padrão de expressão regular para incluir pastas específicas ou excluir pastas, tipos de arquivo ou arquivos específicos de sua fonte de dados. Isso pode ser útil para repositórios de dados compartilhados que contêm conteúdo pertencente a diferentes categorias, classificações e tipos de arquivo.
Pré-requisitos
Para este passo a passo, você deve ter os seguintes pré-requisitos:
Crie e configure seu repositório de documentos
Antes de poder criar um índice no Amazon Kendra, você precisa carregar documentos em um bucket do S3. Esta seção contém instruções para criar um depósito S3, obter os arquivos e carregá-los no depósito. Depois de concluir todas as etapas desta seção, você terá uma fonte de dados que o Amazon Kendra pode usar.
- No Console de gerenciamento da AWS, na lista Region, escolha US East (N. Virginia) ou qualquer região de sua escolha que Amazon Kendra está disponível em.
- Escolha Serviços.
- Debaixo Armazenamento, escolha S3.
- No console do Amazon S3, escolha Criar balde.
- Debaixo Configuração geral, Providencie a seguinte informação:
- Para o nome do intervalo, entrar
kendrapost-{your account id}. - Para Region, escolha a mesma Region que você usa para implantar seu índice Amazon Kendra (esta postagem usa
us-east-1). - Debaixo configurações de balde, para Bloquear acesso público, deixe tudo com os valores padrão.
- Para o nome do intervalo, entrar
- Debaixo Configurações avançadas, deixe tudo com os valores padrão.
- Escolha Criar balde.
- Baixar AWS_Whitepapers.zip e descompacte os arquivos.
- No console do Amazon S3, selecione o bucket que você acabou de criar e escolha Escolher arquivo.
- Carregue as pastas
Best Practices,Databases,GeneraleMachine Learningdo arquivo descompactado.
Dentro do seu balde, agora você deve ver quatro pastas.
Adicionar uma fonte de dados
A fonte de dados é um local que armazena os documentos para indexação. Você pode sincronizar fontes de dados automaticamente com um índice do Amazon Kendra para garantir que as pesquisas reflitam corretamente documentos novos, atualizados ou excluídos nos repositórios de origem.
Depois de concluir todas as etapas desta seção, você terá uma fonte de dados vinculada ao Amazon Kendra. Para mais informações, veja Adicionando documentos de uma fonte de dados.
Antes de continuar, verifique se a criação do índice foi concluída e se o índice é exibido como Ativo. Para mais informações, veja Criando um índice.
- No console do Amazon Kendra, navegue até seu índice (para esta postagem,
kendra-blog-index). - No
kendra-blog-indexpágina, escolha Adicionar fontes de dados.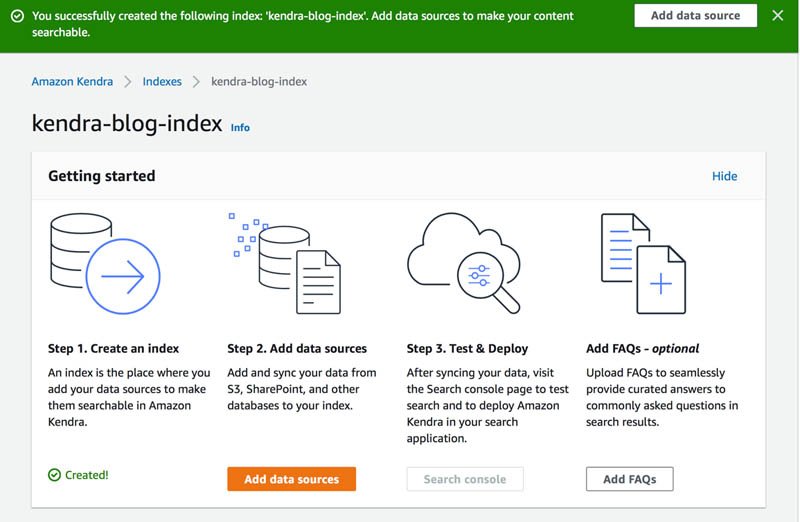
- Em Amazon S3, escolha Adicionar conector.
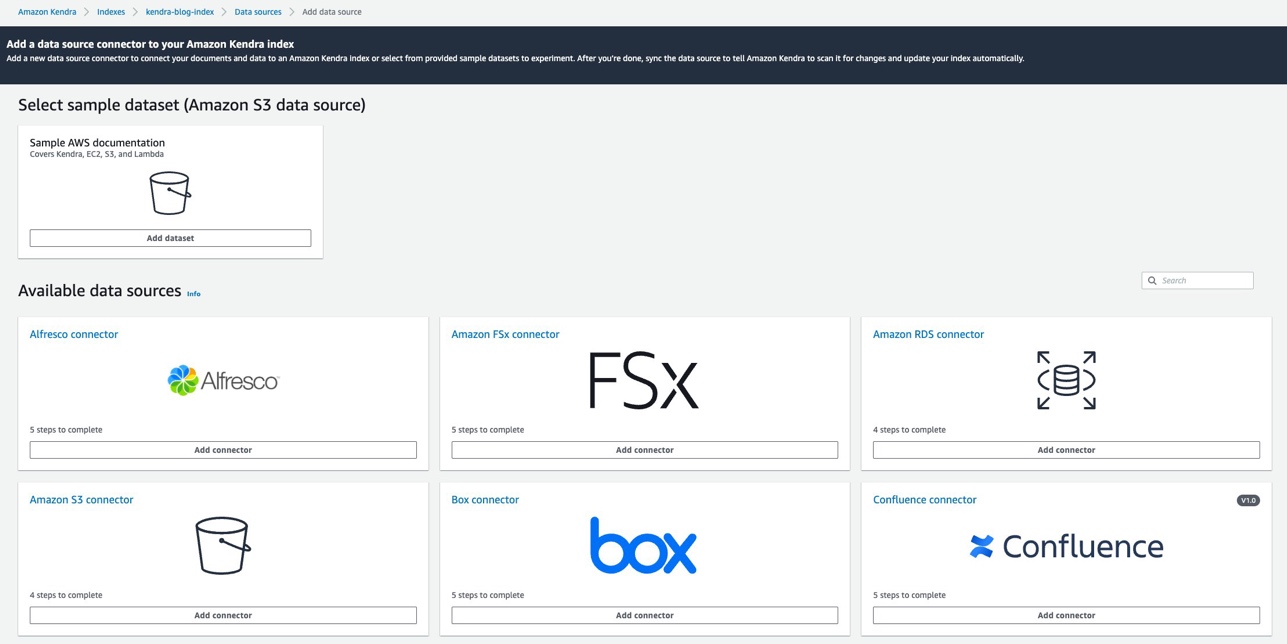
Para obter mais informações sobre as diferentes fontes de dados compatíveis com o Amazon Kendra, consulte Adicionando documentos de uma fonte de dados.
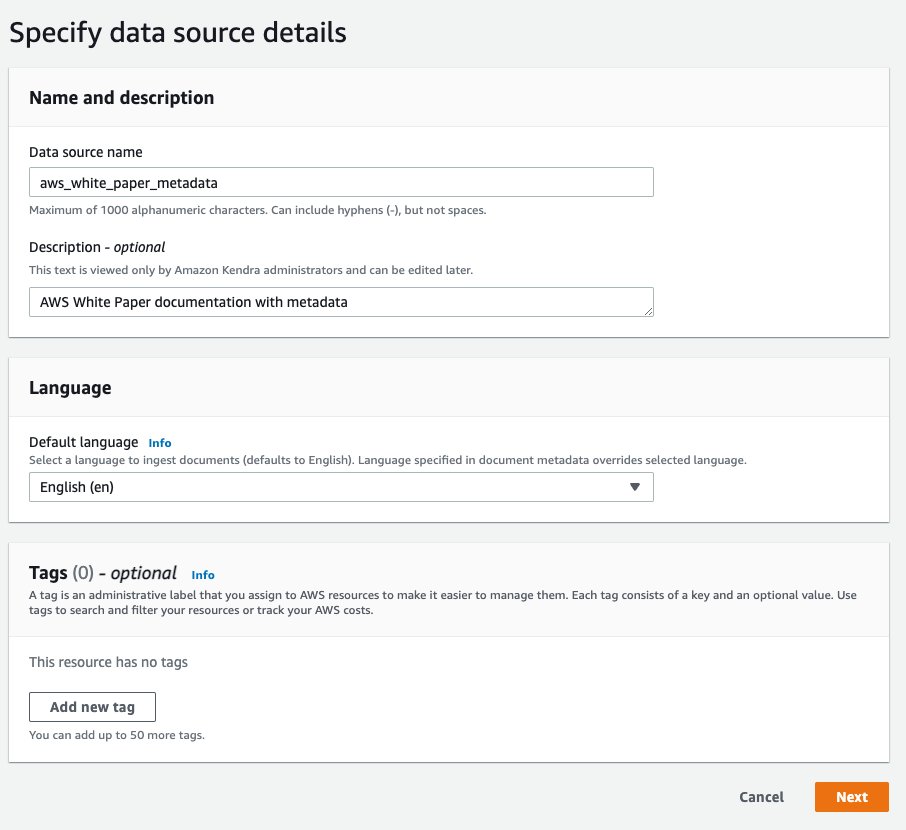
- No Especificar detalhes da fonte de dados seção, para Nome da fonte de dados, entrar
aws_white_paper. - Escolha Descrição, entrar
AWS White Paper documentation. - Escolha Próximo.
Agora você cria um Gerenciamento de acesso e identidade da AWS (IAM) para Amazon Kendra.
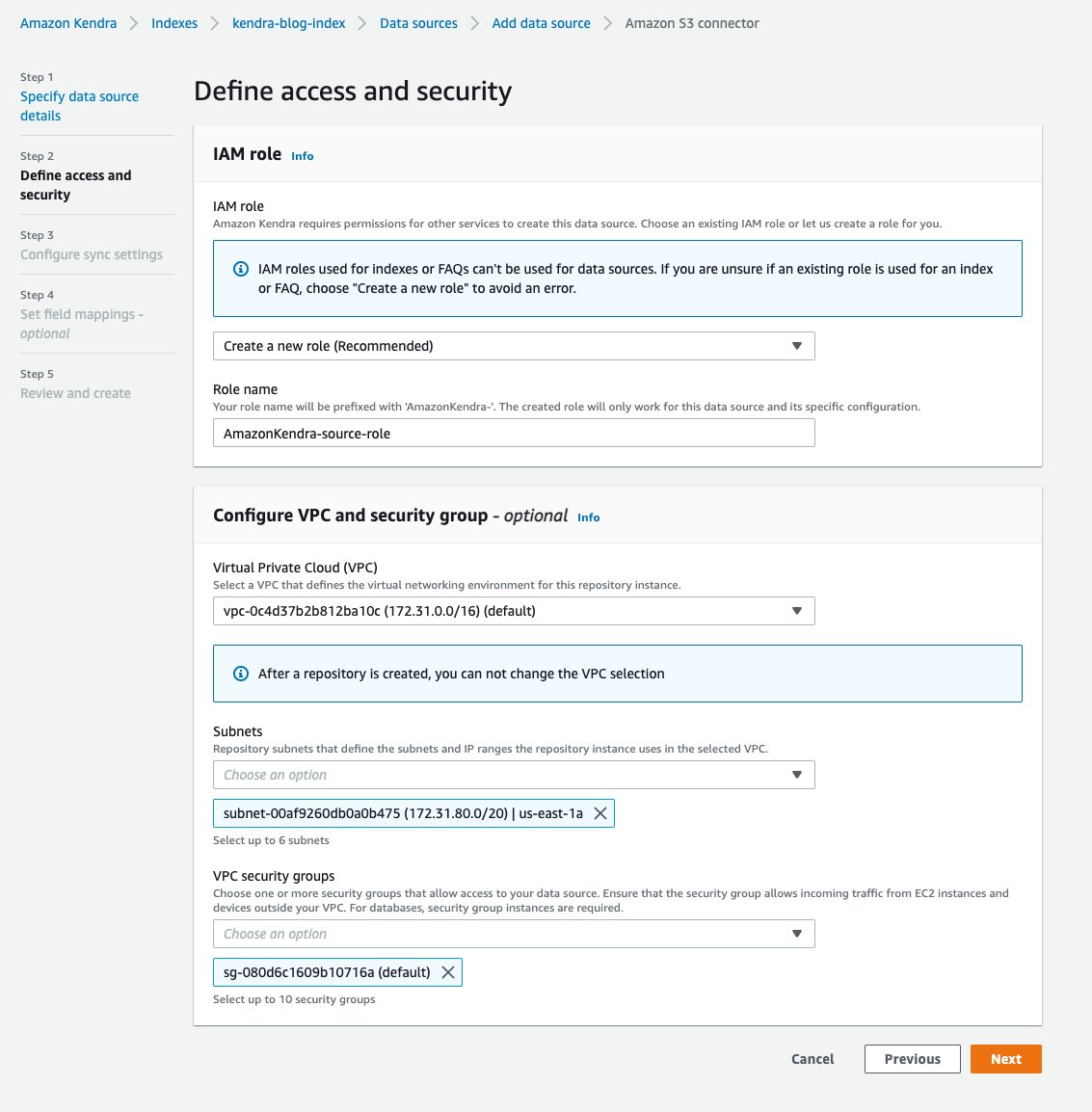
- No Definir acesso e segurança página, para Papel do IAM seção, escolha Crie uma nova função.
- Em Nome da função, insira
source-role(seu nome de função é prefixado comAmazonKendra-). - No Configurar VPC e segurança seção, escolha o seu VPC, e digite seu Sub-redes e grupos de segurança VPC.
Para obter mais informações sobre como conectar seu Amazon Kendra à sua Amazon Virtual Private Cloud, consulte Configurar o Amazon Kendra para usar uma VPC.
- Escolha Próximo.
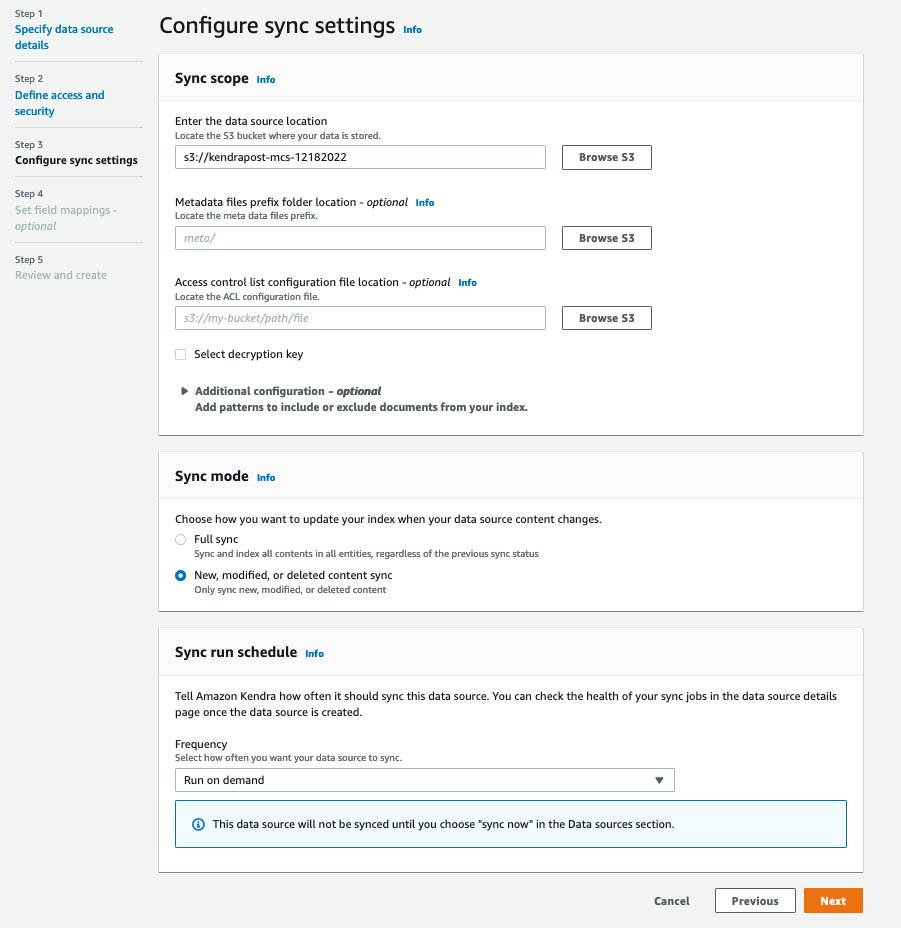
- No Definir as configurações de sincronização página, para Insira o local da fonte de dados, insira o bucket S3 que você criou:
kendrapost-{your account id}. - Deixar Localização da pasta do prefixo dos arquivos de metadados em branco.
Por padrão, os arquivos de metadados são armazenados no mesmo diretório dos documentos. Se você deseja colocar esses arquivos em uma pasta diferente, pode adicionar um prefixo. Para mais informações, veja Metadados do documento Amazon S3.
- Escolha Selecione a chave de descriptografia, deixe-o desmarcado.
- Escolha Configuração adicional, você pode adicionar um padrão para incluir ou excluir determinadas pastas ou arquivos. Para esta postagem, mantenha os valores padrão.
- Escolha Modo de sincronização escolher Sincronização de documentos novos, modificados ou excluídos.
- Escolha Frequência, escolha Executar sob demanda.
Esta etapa define a frequência com que a fonte de dados é sincronizada com o índice Amazon Kendra.
- Escolha Próximo.
- No Definir mapeamentos de campo página, mantenha os valores padrão.
- Escolha Próximo.

- No Revise e crie página, escolha Adicionar fonte de dados.
- Navegue de volta ao seu índice Kendra.
- Escolha o seu Fonte de dados, Em seguida, escolha Sincronize agora para sincronizar os documentos com o índice Amazon Kendra.
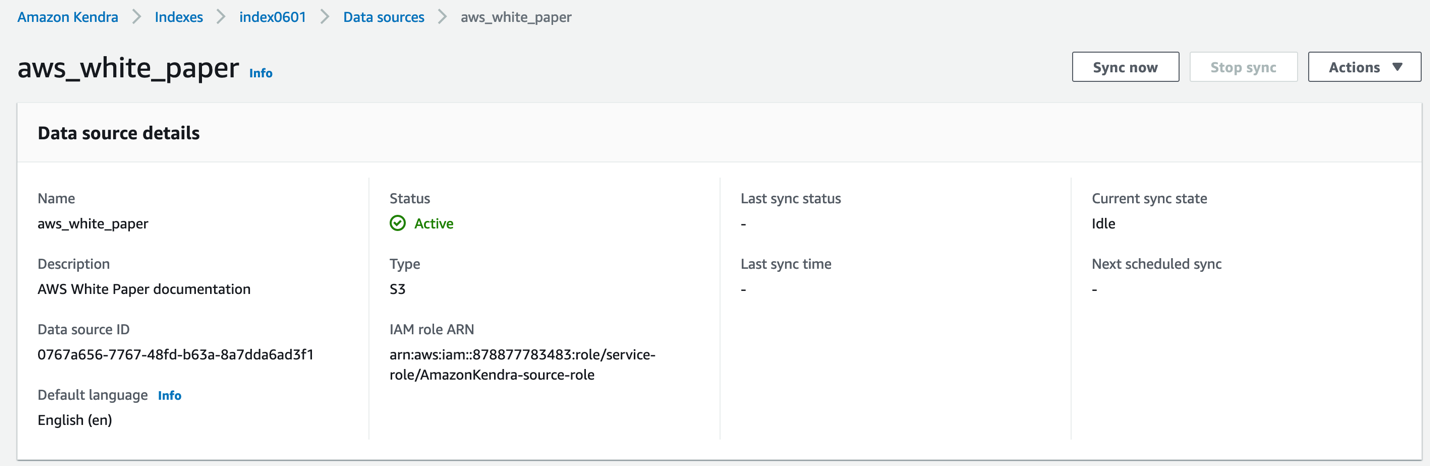
A duração desse processo depende do número de documentos indexados. Para este caso de uso, pode levar 15 minutos, após os quais você verá uma mensagem informando que a sincronização foi bem-sucedida. Na seção Histórico de execução de sincronização, você pode ver que 40 documentos foram sincronizados.

Seu índice do Amazon Kendra agora está pronto para consultas em linguagem natural. Quando você pesquisa seu índice, o Amazon Kendra usa todos os dados e metadados fornecidos para retornar as respostas mais precisas à sua consulta de pesquisa. No console Amazon Kendra, escolha Pesquisar conteúdo indexado. No campo de consulta, comece com uma consulta como “Qual serviço da AWS tem 11 noves de durabilidade?”
Para obter mais informações sobre como consultar o índice, consulte Consultando um índice
Sincronize as alterações da fonte de dados para pesquisar o índice
Sua fonte de dados está configurada para sincronizar quaisquer dados novos, modificados ou excluídos. Antes de sincronizar sua fonte de dados de forma incremental com um índice no Amazon Kendra, você precisa carregar novos documentos em um bucket do S3.
- No console do Amazon S3, selecione o bucket que você acabou de criar e escolha Escolher arquivo.
- Carregue as pastas
SecurityeWell_Architecteddo arquivo descompactado.
Agora você pode sincronizar os novos documentos adicionados ao bucket S3:
- No console Amazon Kendra, escolha As fontes de dados e, em seguida, selecione sua fonte de dados S3.
- Escolha Sincronize agora.
A duração desse processo depende do número de documentos indexados. Para este caso de uso, pode levar 15 minutos, após os quais você verá uma mensagem informando que a sincronização foi bem-sucedida.
No Sincronizar histórico de execução seção, você pode ver que 20 documentos foram sincronizados.

Reindexar a fonte de dados
Em um cenário em que a fonte de dados tem informações desatualizadas, agora você pode reindexar a fonte de dados sem precisar excluir e criar uma nova fonte de dados. Para modificar o modo de sincronização e reindexar a fonte de dados, conclua as seguintes etapas:
- No console Amazon Kendra, escolha As fontes de dados e, em seguida, selecione sua fonte de dados S3.
- No Opções menu, escolha Editar.
- Escolha Próximo para mover para Passo 3 – Configure a página de configurações de sincronização.
- Para o modo de sincronização, selecione Sincronização total.
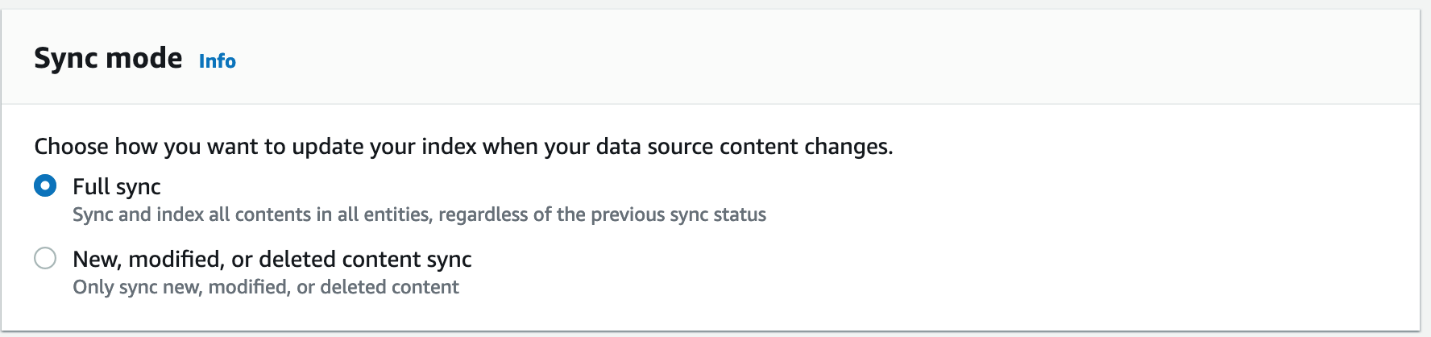
- Escolha Frequência, escolha Executar sob demanda.
- Escolha Próximo.
- No Definir mapeamentos de campo página, mantenha os valores padrão.
- Escolha Próximo.
- No Revise e crie página, escolha Atualizar.
Agora você pode sincronizar os novos documentos adicionados ao bucket S3.
- No console Amazon Kendra, escolha As fontes de dados e, em seguida, selecione sua fonte de dados S3.
- Escolha Sincronize agora.
No Sincronizar histórico de execução seção, você pode ver que todos os documentos foram sincronizados independentemente do status de sincronização anterior na coluna modificada.

limpar
Para evitar cobranças futuras e limpar funções e políticas não utilizadas, exclua os recursos que você criou:
- No índice Amazon Kendra, escolha Índices no painel de navegação.
- Selecione o índice que você criou e no Opções menu, escolha Apagar.
- Para confirmar a exclusão, digite Excluir quando solicitado e escolha Apagar.
Aguarde até receber a mensagem de confirmação; o processo pode levar até 15 minutos.
- No console do Amazon S3, excluir o balde S3.
- No console IAM, exclua as funções IAM correspondentes.
Conclusão
Nesta postagem, você aprendeu a usar o Amazon Kendra para implantar um serviço de pesquisa empresarial usando uma conexão segura com o Amazon S3 que não requer um gateway de Internet ou um dispositivo Network Address Translation (NAT). Você pode habilitar sincronizações mais rápidas para seus documentos usando o modo de sincronização.
Há muitos recursos adicionais que não cobrimos. Por exemplo:
- Você pode habilitar o controle de acesso baseado em usuário para seu índice Amazon Kendra e restringir o acesso a documentos com base nos controles de acesso que você já configurou.
- Você pode mapear atributos de objeto para atributos de índice do Amazon Kendra e ativá-los para facetamento, pesquisa e exibição nos resultados da pesquisa.
- Você pode encontrar rapidamente informações de páginas da web (tabelas HTML) usando a pesquisa tabular do Amazon Kendra
Para saber mais sobre o Amazon Kendra, consulte Guia do desenvolvedor do Amazon Kendra.
Sobre os autores
 Maran Chandrasekaran é Arquiteto de Soluções Sênior na Amazon Web Services, trabalhando com nossos clientes corporativos. Fora do trabalho, ele adora viajar.
Maran Chandrasekaran é Arquiteto de Soluções Sênior na Amazon Web Services, trabalhando com nossos clientes corporativos. Fora do trabalho, ele adora viajar.
 Arjun Agrawal é engenheiro de software da AWS, atualmente trabalhando com uma equipe Amazon Kendra em um mecanismo de pesquisa empresarial. Ele é apaixonado por novas tecnologias e por resolver problemas do mundo real. Fora do trabalho, ele adora caminhar e viajar.
Arjun Agrawal é engenheiro de software da AWS, atualmente trabalhando com uma equipe Amazon Kendra em um mecanismo de pesquisa empresarial. Ele é apaixonado por novas tecnologias e por resolver problemas do mundo real. Fora do trabalho, ele adora caminhar e viajar.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/search-for-answers-accurately-using-amazon-kendra-s3-connector-with-vpc-support/
- 10
- 100
- 11
- 7
- a
- Sobre
- Acesso
- acessível
- Conta
- preciso
- exatamente
- em
- adicionado
- Adição
- Adicional
- endereço
- Depois de
- algoritmos
- Todos os Produtos
- permite
- já
- Amazon
- Amazona Kendra
- Amazon RDS
- Amazon Web Services
- e
- respostas
- aplicações
- associado
- atributos
- automaticamente
- disponível
- AWS
- em caminho duplo
- baseado
- base
- antes
- capacidades
- casas
- casos
- Categorias
- certo
- Alterações
- acusações
- escolha
- Escolha
- classificação
- Na nuvem
- Coluna
- completar
- completando
- Confirmar
- Contato
- Conexão de
- da conexão
- cônsul
- contém
- conteúdo
- contexto
- continuar
- ao controle
- controles
- Correspondente
- Custo
- cobrir
- crio
- criado
- criação
- Atualmente
- Clientes
- dados,
- banco de dados
- bases de dados
- conjuntos de dados
- Padrão
- Define
- demonstra
- depende
- implantar
- descreve
- Developer
- dispositivo
- diferente
- Ecrã
- documento
- INSTITUCIONAIS
- Não faz
- distância
- durabilidade
- Leste
- fácil de usar
- permitir
- permite
- Motor
- engenheiro
- Entrar
- Empreendimento
- clientes corporativos
- Pesquisa Corporativa
- Éter (ETH)
- Cada
- tudo
- exemplo
- existente
- Funcionalidades
- campo
- Envie o
- Arquivos
- Encontre
- seguinte
- Frequência
- da
- cheio
- futuro
- porta de entrada
- ter
- Do grupo
- ter
- ajudar
- Marchar
- história
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTML
- HTTPS
- IAM
- Identidade
- melhorias
- in
- incluir
- inclusão
- índice
- INFORMAÇÕES
- instruções
- integrar
- Inteligente
- Internet
- introduzindo
- independentemente
- IT
- Trabalho
- Guarda
- língua
- Sobrenome
- APRENDER
- aprendido
- aprendizagem
- Deixar
- ligado
- Lista
- carregar
- localização
- máquina
- aprendizado de máquina
- a Principal
- fazer
- de grupos
- muitos
- mapa,
- Menu
- mensagem
- metadados
- minutos
- ML
- Moda
- modos
- modificada
- modificar
- mais
- a maioria
- mover
- múltiplo
- nome
- natural
- Linguagem Natural
- Navegar
- Navegação
- você merece...
- rede
- redes
- Novo
- número
- objeto
- objetos
- onedrive
- lado de fora
- próprio
- pão
- Papel
- apaixonado
- caminho
- padrão
- padrões
- Lugar
- platão
- Inteligência de Dados Platão
- PlatãoData
- políticas
- Publique
- pré-requisitos
- anterior
- privado
- problemas
- processo
- processos
- fornecer
- fornecido
- fornece
- público
- Frequentes
- mais rápido
- rapidamente
- alcançar
- pronto
- mundo real
- reduzir
- refletir
- região
- regular
- relevante
- requerer
- Recursos
- restringir
- Resultados
- retorno
- Tipo
- papéis
- raiz
- Execute
- corrida
- Salesforce
- mesmo
- cenário
- cronograma
- Pesquisar
- motor de busca
- Seção
- seguro
- firmemente
- segurança
- senior
- serviço
- Serviços
- conjunto
- Configurações
- compartilhado
- sharepoint
- rede de apoio social
- Shows
- simples
- desde
- So
- Software
- Engenheiro de Software
- Soluções
- Resolvendo
- alguns
- fonte
- Fontes
- específico
- começo
- Status
- Passo
- Passos
- armazenamento
- armazenadas
- lojas
- estilo
- sub-rede
- sub-redes
- bem sucedido
- tal
- ajuda
- Suportado
- suportes
- Sincronização
- Tire
- Profissionais
- Tecnologia
- A
- A fonte
- deles
- três
- tempo
- para
- Tradução
- viagens
- tipos
- para
- compreender
- unix
- não usado
- Atualizada
- us
- usar
- caso de uso
- usuários
- Valores
- Virgínia
- Virtual
- Passo a passo
- web
- serviços web
- qual
- branco
- artigo:
- dentro
- sem
- Atividades:
- trabalhar
- investimentos
- zefirnet
- Zip