Este é um post convidado de Jose Benitez, fundador e diretor de IA e Mattias Ponchon, chefe de infraestrutura da Intuitivo.
A Intuitivo, pioneira em inovação no varejo, está revolucionando as compras com seu sistema de processamento transacional baseado em IA e aprendizado de máquina (AI/ML). Esta tecnologia inovadora permite-nos operar milhões de pontos de compra autónomos (A-POPs) simultaneamente, transformando a forma como os clientes compram. Nossa solução supera as máquinas de venda automática tradicionais e alternativas, oferecendo uma vantagem econômica com custo dez vezes mais barato, fácil configuração e operação livre de manutenção. Nossos novos e inovadores A-POPs (ou máquinas de venda automática) proporcionam experiências aprimoradas ao cliente a um custo dez vezes menor devido às vantagens de desempenho e custo Inferência da AWS entrega. A Inferentia nos permitiu executar nossos modelos de visão computacional You Only Look Once (YOLO) cinco vezes mais rápido do que nossa solução anterior e oferece suporte a experiências de compra contínuas e em tempo real para nossos clientes. Além disso, o Inferentia também nos ajudou a reduzir custos em 95% em comparação com a nossa solução anterior. Neste post, abordamos nosso caso de uso, desafios e uma breve visão geral de nossa solução usando Inferentia.
O cenário de varejo em mudança e a necessidade do A-POP
O cenário do varejo está evoluindo rapidamente e os consumidores esperam as mesmas experiências fáceis de usar e sem atritos a que estão acostumados quando fazem compras digitalmente. Para colmatar eficazmente a lacuna entre o mundo digital e físico e para responder às novas necessidades e expectativas dos clientes, é necessária uma abordagem transformadora. Na Intuitivo, acreditamos que o futuro do varejo reside na criação de pontos de compra autônomos (A-POP) altamente personalizados, alimentados por IA e orientados por visão computacional. Esta inovação tecnológica coloca os produtos ao alcance dos clientes. Ele não apenas coloca os itens favoritos dos clientes ao seu alcance, mas também oferece a eles uma experiência de compra perfeita, sem longas filas ou sistemas complexos de processamento de transações. Estamos entusiasmados em liderar esta nova era emocionante no varejo.
Com nossa tecnologia de ponta, os varejistas podem implantar milhares de A-POPs de forma rápida e eficiente. O dimensionamento sempre foi um desafio assustador para os varejistas, principalmente devido às complexidades logísticas e de manutenção associadas à expansão das máquinas de venda automática tradicionais ou outras soluções. Contudo, nossa solução baseada em câmera, que elimina a necessidade de sensores de peso, RFID ou outros sensores de alto custo, não requer manutenção e é significativamente mais barata. Isso permite que os varejistas estabeleçam com eficiência milhares de A-POPs, proporcionando aos clientes uma experiência de compra incomparável e, ao mesmo tempo, oferecendo aos varejistas uma solução econômica e escalável.

Usando inferência na nuvem para identificação de produtos em tempo real
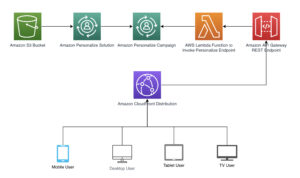
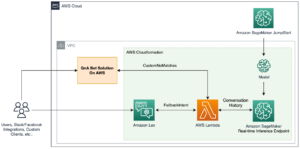
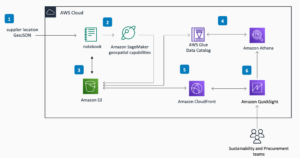
Ao projetar um sistema de reconhecimento e pagamento de produtos baseado em câmeras, decidimos se isso deveria ser feito na borda ou na nuvem. Depois de considerar diversas arquiteturas, projetamos um sistema que envia vídeos das transações para a nuvem para processamento.
Nossos usuários finais iniciam uma transação digitalizando o código QR do A-POP, que aciona o desbloqueio do A-POP e então os clientes pegam o que desejam e vão embora. Vídeos pré-processados dessas transações são carregados na nuvem. Nosso pipeline de transações baseado em IA processa automaticamente esses vídeos e cobra a conta do cliente de acordo.
O diagrama a seguir mostra a arquitetura de nossa solução.

Desbloqueando inferência de alto desempenho e econômica usando AWS Inferentia
À medida que os retalhistas procuram escalar as operações, o custo dos A-POPs torna-se uma consideração. Ao mesmo tempo, é fundamental fornecer uma experiência de compra perfeita em tempo real para os usuários finais. Nossa equipe de pesquisa de IA/ML se concentra em identificar os melhores modelos de visão computacional (CV) para nosso sistema. Agora nos deparamos com o desafio de como otimizar simultaneamente as operações de IA/ML em termos de desempenho e custo.
Implantamos nossos modelos em Instâncias do Amazon EC2 Inf1 desenvolvido com Inferentia, o primeiro silício de ML da Amazon projetado para acelerar cargas de trabalho de inferência de aprendizado profundo. Foi demonstrado que o Inferentia reduz significativamente os custos de inferência. Nós usamos o Neurônio AWS SDK — um conjunto de ferramentas de software usado com Inferentia — para compilar e otimizar nossos modelos para implantação em instâncias EC2 Inf1.
O trecho de código a seguir mostra como compilar um modelo YOLO com Neuron. O código funciona perfeitamente com PyTorch e funções como torch.jit.trace() e neuron.trace() registram as operações do modelo em uma entrada de exemplo durante a passagem direta para construir um gráfico IR estático.
Migramos nossos modelos de computação pesada para Inf1. Ao usar o AWS Inferentia, alcançamos a produtividade e o desempenho que atendem às nossas necessidades de negócios. A adoção de instâncias Inf1 baseadas em Inferentia no ciclo de vida do MLOps foi a chave para alcançar resultados notáveis:
- Melhoria de desempenho: Nossos grandes modelos de visão computacional agora rodam cinco vezes mais rápido, atingindo mais de 120 quadros por segundo (FPS), permitindo experiências de compra perfeitas e em tempo real para nossos clientes. Além disso, a capacidade de processar nesta taxa de quadros não apenas aumenta a velocidade das transações, mas também nos permite inserir mais informações em nossos modelos. Este aumento na entrada de dados melhora significativamente a precisão da detecção de produtos nos nossos modelos, aumentando ainda mais a eficácia geral dos nossos sistemas de compras.
- Poupança de custos: Reduzimos os custos de inferência. Isto melhorou significativamente o design da arquitetura que suporta nossos A-POPs.
A inferência paralela de dados foi fácil com o AWS Neuron SDK
Para melhorar o desempenho de nossas cargas de trabalho de inferência e extrair o máximo desempenho do Inferentia, queríamos usar todos os NeuronCores disponíveis no acelerador Inferentia. Alcançar esse desempenho foi fácil com as ferramentas e APIs integradas do Neuron SDK. Nós usamos o torch.neuron.DataParallel() API. Atualmente estamos usando inf1.2xlarge que possui um acelerador Inferentia com quatro aceleradores Neuron. Então estamos usando torch.neuron.DataParallel() para usar totalmente o hardware Inferentia e usar todos os NeuronCores disponíveis. Esta função Python implementa paralelismo de dados no nível do módulo em modelos criados pela API PyTorch Neuron. O paralelismo de dados é uma forma de paralelização entre vários dispositivos ou núcleos (NeuronCores for Inferentia), chamados de nós. Cada nó contém o mesmo modelo e parâmetros, mas os dados são distribuídos entre os diferentes nós. Ao distribuir os dados entre vários nós, o paralelismo de dados reduz o tempo total de processamento de entradas de lote grande em comparação com o processamento sequencial. O paralelismo de dados funciona melhor para modelos em aplicativos sensíveis à latência que possuem grandes requisitos de tamanho de lote.
Olhando para o futuro: Acelerando a transformação do varejo com modelos básicos e implantação escalável
À medida que nos aventuramos no futuro, o impacto dos modelos básicos no setor retalhista não pode ser exagerado. Os modelos de base podem fazer uma diferença significativa na rotulagem de produtos. A capacidade de identificar e categorizar diferentes produtos com rapidez e precisão é crucial em um ambiente de varejo em ritmo acelerado. Com modelos modernos baseados em transformadores, podemos implantar uma maior diversidade de modelos para atender mais às nossas necessidades de IA/ML com maior precisão, melhorando a experiência dos usuários e sem ter que perder tempo e dinheiro treinando modelos do zero. Ao aproveitar o poder dos modelos básicos, podemos acelerar o processo de etiquetagem, permitindo que os retalhistas dimensionem as suas soluções A-POP de forma mais rápida e eficiente.
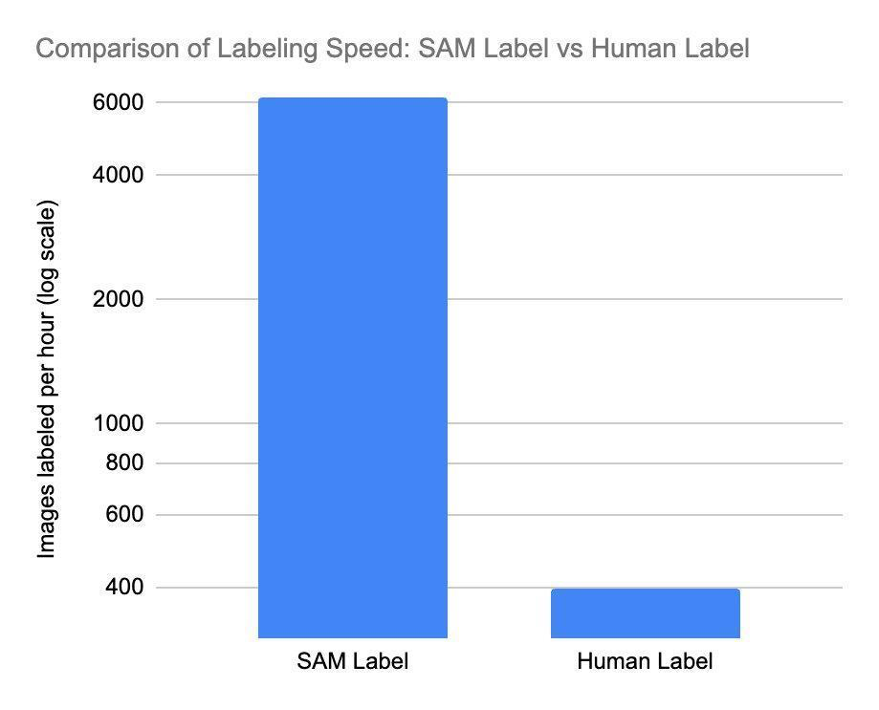
Começamos a implementar Segmentar qualquer modelo (SAM), um modelo básico de transformador de visão que pode segmentar qualquer objeto em qualquer imagem (discutiremos isso mais detalhadamente em outra postagem do blog). O SAM nos permite acelerar nosso processo de etiquetagem com velocidade incomparável. O SAM é muito eficiente, capaz de processar aproximadamente 62 vezes mais imagens do que um ser humano pode criar manualmente caixas delimitadoras no mesmo período de tempo. A saída do SAM é usada para treinar um modelo que detecta máscaras de segmentação em transações, abrindo uma janela de oportunidade para processar milhões de imagens de forma exponencialmente mais rápida. Isso reduz significativamente o tempo e o custo de treinamento para modelos de planogramas de produtos.
Nossas equipes de pesquisa de produtos e IA/ML estão entusiasmadas por estar na vanguarda dessa transformação. A parceria contínua com a AWS e o uso do Inferentia em nossa infraestrutura garantirão que possamos implantar esses modelos básicos de maneira econômica. Como pioneiros, estamos trabalhando com as novas instâncias baseadas no AWS Inferentia 2. As instâncias Inf2 são criadas para a IA generativa atual e a aceleração de inferência de modelo de linguagem grande (LLM), proporcionando maior desempenho e custos mais baixos. O Inf2 nos permitirá capacitar os varejistas para aproveitar os benefícios das tecnologias baseadas em IA sem gastar muito, tornando o cenário do varejo mais inovador, eficiente e centrado no cliente.
À medida que continuamos a migrar mais modelos para Inferentia e Inferentia2, incluindo modelos fundamentais baseados em transformadores, estamos confiantes de que nossa aliança com a AWS nos permitirá crescer e inovar junto com nosso confiável provedor de nuvem. Juntos, remodelaremos o futuro do retalho, tornando-o mais inteligente, mais rápido e mais sintonizado com as necessidades em constante evolução dos consumidores.
Conclusão
Neste percurso técnico, destacamos nossa jornada transformacional usando AWS Inferentia para seu inovador sistema de processamento transacional de IA/ML. Esta parceria levou a um aumento de cinco vezes na velocidade de processamento e a uma impressionante redução de 95% nos custos de inferência em comparação com a nossa solução anterior. Ele mudou a abordagem atual do setor de varejo, facilitando uma experiência de compra contínua e em tempo real.
Se você estiver interessado em saber mais sobre como o Inferentia pode ajudá-lo a economizar custos e ao mesmo tempo otimizar o desempenho de suas aplicações de inferência, visite o Instâncias do Amazon EC2 Inf1 e Instâncias do Amazon EC2 Inf2 páginas de produtos. A AWS fornece vários códigos de amostra e recursos de introdução ao Neuron SDK que você pode encontrar no site. Repositório de amostras de neurônios.
Sobre os autores
Matias Ponchon é o chefe de infraestrutura da Intuitivo. Ele é especialista em arquitetar aplicativos seguros e robustos. Com vasta experiência em empresas FinTech e Blockchain, aliada à sua mentalidade estratégica, o ajuda a projetar soluções inovadoras. Ele tem um profundo compromisso com a excelência, por isso fornece consistentemente soluções resilientes que ultrapassam os limites do que é possível.
Jose Benitez é o fundador e diretor de IA da Intuitivo, especializado no desenvolvimento e implementação de aplicações de visão computacional. Ele lidera uma talentosa equipe de aprendizado de máquina, nutrindo um ambiente de inovação, criatividade e tecnologia de ponta. Em 2022, Jose foi reconhecido como 'Inovador com menos de 35 anos' pela MIT Technology Review, uma prova de suas contribuições inovadoras na área. Esta dedicação vai além dos elogios e abrange todos os projetos que ele realiza, demonstrando um compromisso incansável com a excelência e a inovação.
Diwakar Bansal é um especialista sênior da AWS com foco no desenvolvimento de negócios e entrada no mercado de serviços de computação acelerada Gen AI e Machine Learning. Anteriormente, Diwakar liderou a definição de produtos, o desenvolvimento de negócios globais e o marketing de produtos de tecnologia para IoT, Edge Computing e direção autônoma, com foco em trazer IA e aprendizado de máquina para esses domínios.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/intuitivo-achieves-higher-throughput-while-saving-on-ai-ml-costs-using-aws-inferentia-and-pytorch/
- :tem
- :é
- :não
- $UP
- 1
- 2022
- 23
- 710
- a
- habilidade
- Capaz
- Sobre
- acelerar
- acelerado
- acelerando
- aceleração
- acelerador
- aceleradores
- conformemente
- Conta
- precisão
- exatamente
- alcançado
- Alcança
- alcançar
- em
- Adicionalmente
- adotantes
- Adotando
- vantagens
- Depois de
- à frente
- AI
- Alimentado por AI
- AI / ML
- Todos os Produtos
- aliança
- Permitindo
- permite
- ao lado de
- tb
- alternativas
- sempre
- Amazon
- Amazon Web Services
- an
- e
- Outro
- qualquer
- nada
- api
- APIs
- aplicações
- abordagem
- aproximadamente
- arquitetura
- SOMOS
- AS
- associado
- At
- automaticamente
- Autônomo
- disponível
- AWS
- Inferência da AWS
- Bank
- BE
- Porque
- torna-se
- sido
- começou
- Acreditar
- Benefícios
- MELHOR
- entre
- Pós
- blockchain
- empresas de blockchain
- Blog
- impulsionar
- limites
- caixas
- Quebra
- PONTE
- Trazendo
- Traz
- construir
- construído
- construídas em
- negócio
- desenvolvimento de negócios
- mas a
- by
- CAN
- não podes
- casas
- desafiar
- desafios
- mudado
- mudança
- acusações
- mais barato
- Na nuvem
- código
- códigos
- COM
- compromisso
- Empresas
- comparado
- integrações
- complexidades
- computador
- Visão de Computador
- Aplicativos de visão computacional
- computação
- confiante
- consideração
- considerando
- consistentemente
- Consumidores
- contém
- continuar
- contribuições
- Custo
- relação custo-benefício
- custos
- acoplado
- cobrir
- CPU
- crio
- criado
- Criar
- criatividade
- crucial
- Atual
- Atualmente
- cliente
- Clientes
- ponta
- dados,
- decisão
- dedicação
- profundo
- deep learning
- definição
- entregar
- entregando
- entrega
- implantar
- desenvolvimento
- Design
- projetado
- concepção
- Detecção
- Desenvolvimento
- Dispositivos/Instrumentos
- diferença
- diferente
- digital
- digitalmente
- Diretor
- discutir
- distribuído
- distribuindo
- Diversidade
- parece
- domínios
- feito
- condução
- dois
- durante
- dinâmico
- cada
- Cedo
- early adopters
- fácil
- fácil de usar
- borda
- computação de borda
- efetivamente
- eficácia
- eficiente
- eficientemente
- elimina
- autorizar
- permitir
- habilitado
- permite
- permitindo
- final
- aprimorada
- Melhora
- garantir
- Meio Ambiente
- Era
- estabelecer
- Éter (ETH)
- Cada
- evolução
- exemplo
- Excelência
- animado
- emocionante
- expansão
- esperar
- expectativas
- vasta experiência
- Experiências
- exponencialmente
- se estende
- extenso
- Experiência Extensiva
- extrato
- facilitando
- falso
- ritmo acelerado
- mais rápido
- Favorito
- campo
- Encontre
- ponta dos dedos
- FinTech
- Primeiro nome
- cinco
- focado
- concentra-se
- focando
- seguinte
- segue
- Escolha
- Frente
- formulário
- para a frente
- Foundation
- fundador
- quatro
- fps
- QUADRO
- sem atrito
- da
- totalmente
- função
- funções
- mais distante
- Além disso
- futuro
- lacuna
- Gen
- generativo
- IA generativa
- obtendo
- Global
- negócio global
- Go
- Ir ao mercado
- agarrar
- gráfico
- maior
- inovador
- Cresça:
- Locatário
- Visitante Mensagem
- Metade
- Hardware
- arreios
- Aproveitamento
- Ter
- ter
- he
- cabeça
- ajudar
- ajudou
- ajuda
- alta performance
- superior
- Destaque
- altamente
- ele
- sua
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- humano
- identificar
- identificar
- if
- imagem
- imagens
- Impacto
- implementação
- implementação
- implementa
- importar
- melhorar
- melhoria
- melhora
- melhorar
- in
- Incluindo
- Crescimento
- indústria
- INFORMAÇÕES
- Infraestrutura
- inovar
- Inovação
- inovadores
- entrada
- inputs
- instâncias
- interessado
- para dentro
- iot
- IT
- Unid
- ESTÁ
- JIT
- viagem
- Chave
- marcação
- paisagem
- língua
- grande
- conduzir
- Leads
- aprendizagem
- levou
- Nível
- encontra-se
- wifecycwe
- linhas
- longo
- olhar
- diminuir
- máquina
- aprendizado de máquina
- máquinas
- principalmente
- manutenção
- fazer
- Fazendo
- manualmente
- Marketing
- Máscaras
- Match
- máximo
- Conheça
- migrado
- migrou
- milhões
- Mindset
- MIT
- ML
- MLOps
- modelo
- modelos
- EQUIPAMENTOS
- módulo
- dinheiro
- mais
- múltiplo
- nome
- você merece...
- Cria
- Novo
- não
- nó
- nós
- nenhum
- agora
- alimentando
- objeto
- of
- oferecendo treinamento para distância
- Oferece
- on
- uma vez
- ONE
- contínuo
- só
- abertura
- operar
- operação
- Operações
- Oportunidade
- Otimize
- otimizando
- Opções
- or
- Outros
- A Nossa
- saída
- Acima de
- global
- exagerado
- Visão geral
- páginas
- Paralelo
- parâmetros
- Supremo
- Google Cloud
- passar
- pagamento
- sistema de pagamento
- para
- por cento
- atuação
- Personalizado
- físico
- pioneiro
- oleoduto
- planograma
- platão
- Inteligência de Dados Platão
- PlatãoData
- pontos
- possível
- Publique
- poder
- alimentado
- apresentado
- anterior
- anteriormente
- processo
- processos
- em processamento
- Produto
- Produtos
- projeto
- provedor
- fornece
- fornecendo
- compra
- Empurrar
- colocar
- Python
- pytorch
- QR code
- rapidamente
- rapidamente
- Taxa
- alcançar
- em tempo real
- reconhecimento
- reconhecido
- reduzir
- reduz
- redução
- a que se refere
- implacável
- notável
- requeridos
- Requisitos
- exige
- pesquisa
- remodelar
- resiliente
- Recursos
- Resultados
- varejo
- indústria de varejo
- varejistas
- rever
- Revolucionando
- uma conta de despesas robusta
- Execute
- Sam
- mesmo
- Salvar
- poupança
- escalável
- Escala
- operações de escala
- dimensionamento
- exploração
- arranhar
- Sdk
- desatado
- sem problemas
- Segundo
- seguro
- segmento
- segmentação
- senior
- sensor
- servir
- Serviços
- conjunto
- instalação
- vários
- Loja
- minha
- rede de apoio social
- apresentando
- mostrando
- Shows
- periodo
- de forma considerável
- Silício
- simultaneamente
- Tamanho
- mais inteligente
- fragmento
- So
- Software
- solução
- Soluções
- especialista
- especializada
- especializando
- velocidade
- começo
- começado
- Estratégico
- Assombroso
- tal
- Apoiar
- suportes
- .
- sistemas
- talentoso
- Profissionais
- equipes
- Dados Técnicos:
- tecnológica
- Tecnologias
- Tecnologia
- dez
- vontade
- do que
- que
- A
- O Futuro
- deles
- Eles
- então
- Este
- deles
- isto
- milhares
- Taxa de transferência
- tempo
- prazo
- vezes
- para
- hoje
- juntos
- ferramentas
- tocha
- Total
- tradicional
- Trem
- Training
- transação
- processamento de transação
- velocidade de transação
- transacional
- Transações
- Transformação
- transformacional
- transformadora
- transformador
- transformando
- atravessar
- verdadeiro
- confiável
- Em última análise
- para
- compromete-se
- destravar
- incomparável
- inigualável
- carregado
- us
- usar
- caso de uso
- usava
- usuários
- utilização
- vário
- máquinas de venda automática
- risco
- muito
- VÍDEOS
- visão
- Visite a
- queremos
- querido
- foi
- Desperdício
- Caminho..
- we
- web
- serviços web
- peso
- foram
- O Quê
- quando
- se
- qual
- enquanto
- porque
- precisarão
- janela
- de
- dentro
- sem
- trabalhar
- trabalho
- mundo
- Yolo
- Você
- investimentos
- zefirnet