À medida que a Roblox cresceu nos últimos mais de 16 anos, também cresceu a escala e a complexidade da infraestrutura técnica que suporta milhões de co-experiências imersivas em 3D. O número de máquinas que oferecemos suporte mais do que triplicou nos últimos dois anos, de aproximadamente 36,000 em 30 de junho de 2021 para quase 145,000 hoje. Apoiar estas experiências contínuas para pessoas em todo o mundo requer mais de 1,000 serviços internos. Para nos ajudar a controlar os custos e a latência da rede, implantamos e gerenciamos essas máquinas como parte de uma infraestrutura de nuvem privada híbrida e personalizada que funciona principalmente no local.
Nossa infraestrutura atualmente suporta mais de 70 milhões de usuários ativos diariamente em todo o mundo, incluindo os criadores que contam com o Roblox's economia para seus negócios. Todos esses milhões de pessoas esperam um nível muito alto de confiabilidade. Dada a natureza imersiva das nossas experiências, existe uma tolerância extremamente baixa a atrasos ou latências, muito menos a interrupções. Roblox é uma plataforma de comunicação e conexão, onde as pessoas se reúnem em experiências 3D imersivas. Quando as pessoas estão se comunicando como seus avatares em um espaço imersivo, mesmo pequenos atrasos ou falhas são mais perceptíveis do que em uma conversa de texto ou em uma teleconferência.
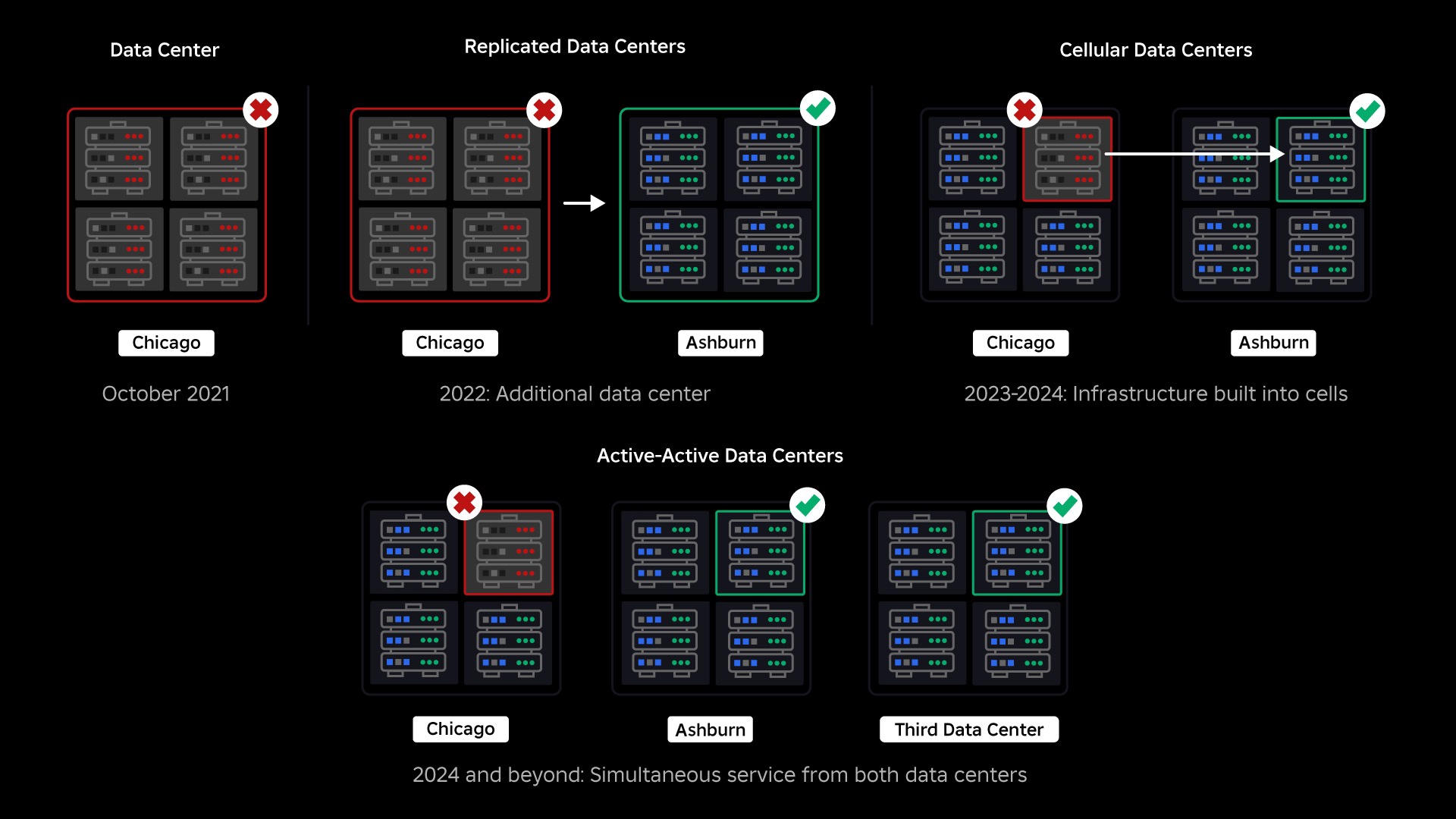
Em outubro de 2021, passamos por uma interrupção em todo o sistema. Tudo começou pequeno, com um problema em um componente de um data center. Mas ele se espalhou rapidamente enquanto estávamos investigando e resultou em uma interrupção de 73 horas. Na época, compartilhamos os dois detalhes sobre o que aconteceu e alguns de nossos primeiros aprendizados sobre o assunto. Desde então, temos estudado esses aprendizados e trabalhado para aumentar a resiliência da nossa infraestrutura aos tipos de falhas que ocorrem em todos os sistemas de grande escala devido a fatores como picos extremos de tráfego, clima, falha de hardware, bugs de software ou apenas humanos cometendo erros. Quando essas falhas ocorrem, como podemos garantir que um problema em um único componente, ou grupo de componentes, não se espalhe para todo o sistema? Esta questão tem sido o nosso foco nos últimos dois anos e, embora o trabalho esteja em andamento, o que fizemos até agora já está dando resultado. Por exemplo, no primeiro semestre de 2023, poupámos 125 milhões de horas de envolvimento por mês em comparação com o primeiro semestre de 2022. Hoje, estamos a partilhar o trabalho que já fizemos, bem como a nossa visão a longo prazo para construir um sistema de infraestrutura mais resiliente.
Construindo uma barreira
Em sistemas de infraestrutura de grande escala, falhas de pequena escala acontecem muitas vezes ao dia. Se uma máquina tiver um problema e precisar ser retirada de serviço, isso será administrável porque a maioria das empresas mantém várias instâncias de seus serviços de back-end. Assim, quando uma única instância falha, outras assumem a carga de trabalho. Para resolver essas falhas frequentes, as solicitações geralmente são configuradas para tentar novamente automaticamente caso recebam um erro.
Isto torna-se um desafio quando um sistema ou pessoa tenta novamente de forma demasiado agressiva, o que pode tornar-se uma forma de essas falhas de pequena escala se propagarem através da infraestrutura para outros serviços e sistemas. Se a rede ou um usuário tentar com persistência suficiente, eventualmente sobrecarregará todas as instâncias desse serviço e, potencialmente, outros sistemas, globalmente. Nossa interrupção de 2021 foi o resultado de algo bastante comum em sistemas de grande escala: uma falha começa pequena e depois se propaga pelo sistema, tornando-se tão grande que é difícil resolvê-la antes que tudo caia.
No momento da interrupção, tínhamos um data center ativo (com componentes dentro dele atuando como backup). Precisávamos da capacidade de fazer failover manualmente para um novo data center quando um problema derrubasse o existente. Nossa primeira prioridade era garantir uma implantação de backup do Roblox, por isso construímos esse backup em um novo data center, localizado em uma região geográfica diferente. Isso adicionou proteção para o pior cenário: uma interrupção que se espalha para componentes suficientes dentro de um data center e o torna totalmente inoperante. Agora temos um data center gerenciando cargas de trabalho (ativo) e outro em standby, servindo como backup (passivo). Nosso objetivo de longo prazo é passar dessa configuração ativa-passiva para uma configuração ativa-ativa, na qual ambos os data centers lidam com cargas de trabalho, com um balanceador de carga distribuindo solicitações entre eles com base na latência, capacidade e integridade. Assim que isso estiver implementado, esperamos ter uma confiabilidade ainda maior para todo o Roblox e ser capazes de fazer failover quase instantaneamente, em vez de várias horas. 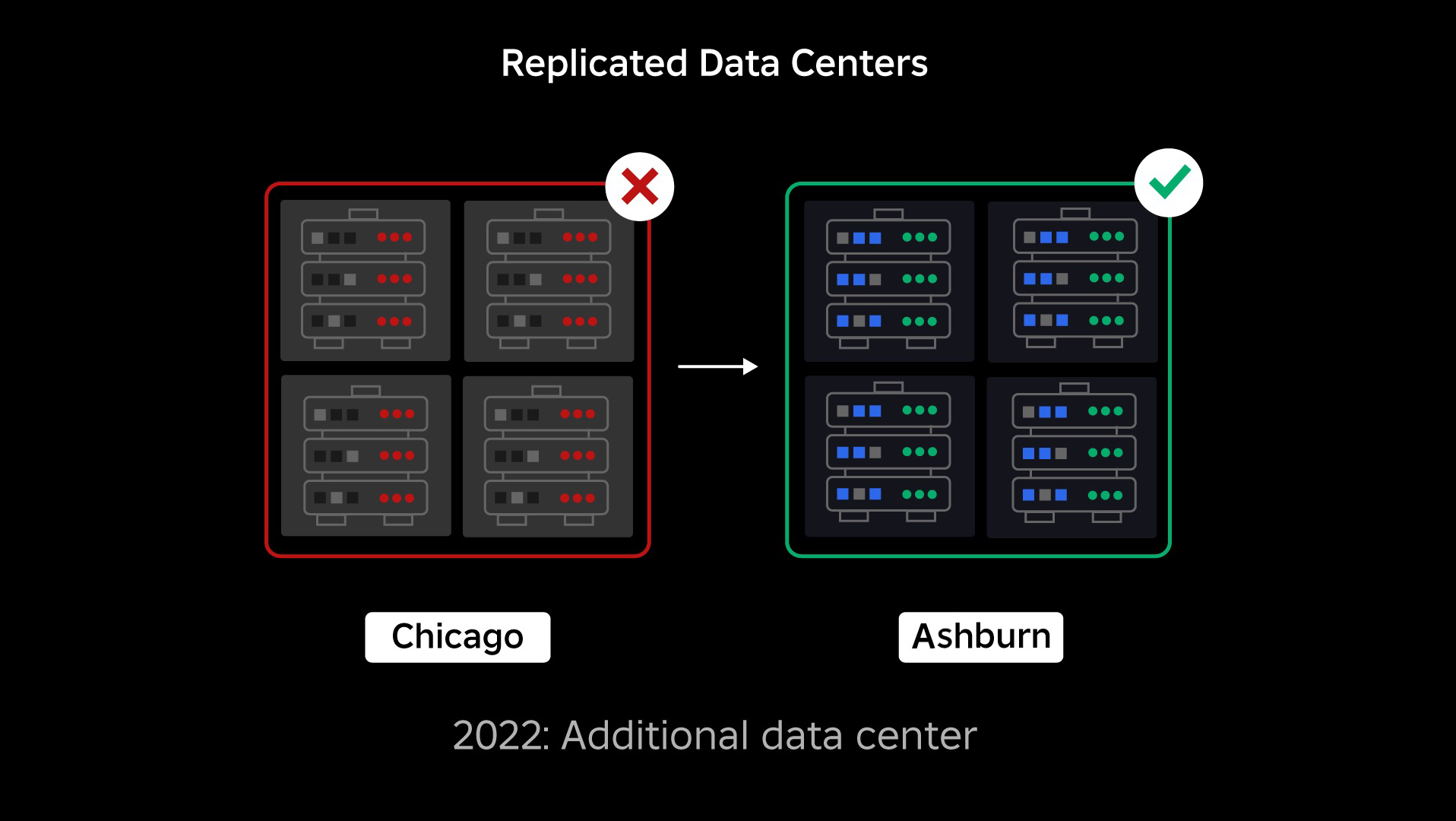
Mudando para uma infraestrutura celular
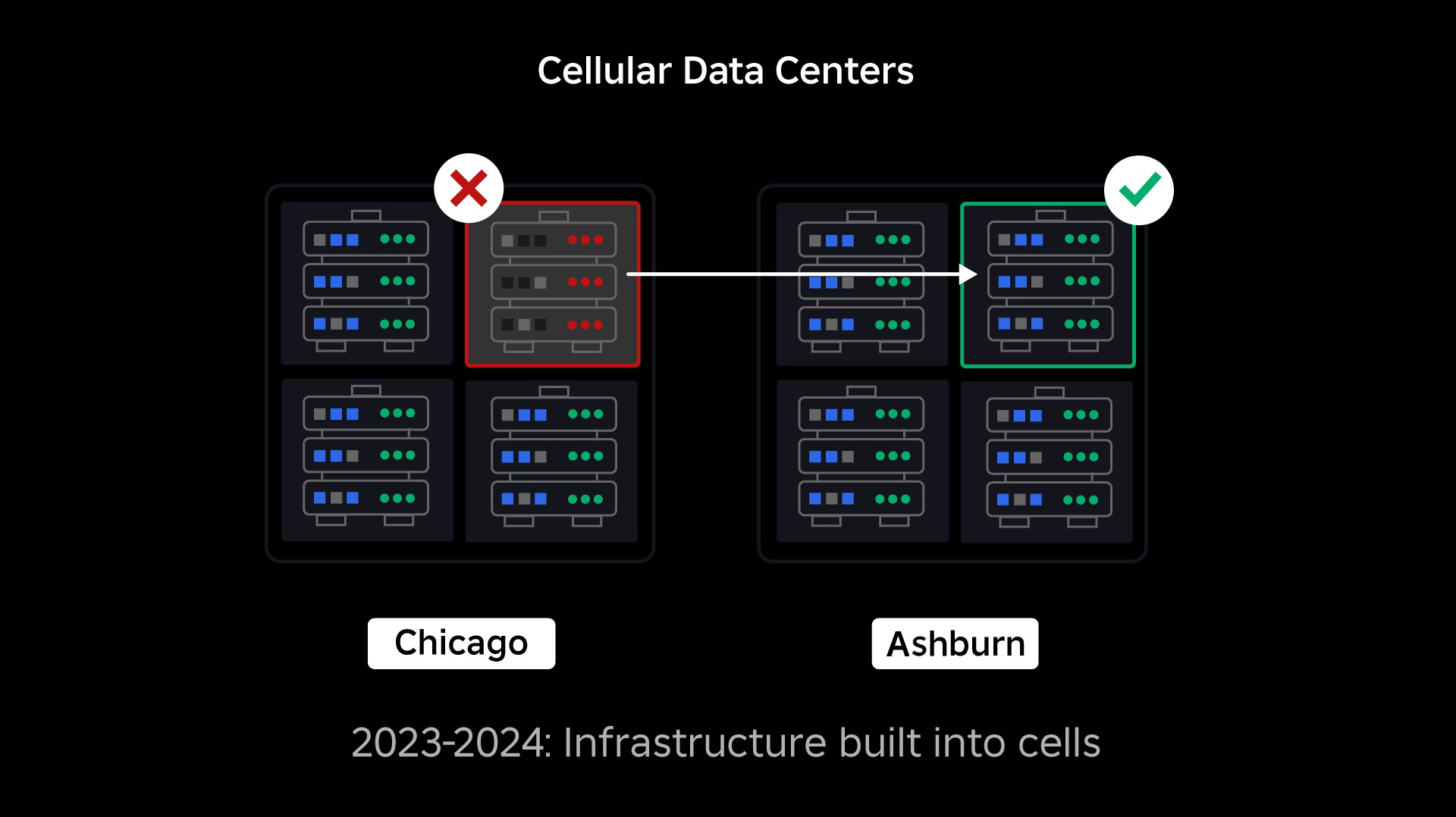
Nossa próxima prioridade foi criar fortes barreiras contra proteção dentro de cada data center para reduzir a possibilidade de falha de todo o data center. As células (algumas empresas as chamam de clusters) são essencialmente um conjunto de máquinas e são como criamos essas paredes. Replicamos serviços dentro e entre células para maior redundância. Em última análise, queremos que todos os serviços da Roblox funcionem em células para que possam se beneficiar tanto de fortes barreiras anti-explosão quanto de redundância. Se uma célula não estiver mais funcional, ela poderá ser desativada com segurança. A replicação entre células permite que o serviço continue em execução enquanto a célula é reparada. Em alguns casos, a reparação celular pode significar um reprovisionamento completo da célula. Em todo o setor, limpar e reprovisionar uma máquina individual ou um pequeno conjunto de máquinas é bastante comum, mas fazer isso para uma célula inteira, que contém cerca de 1,400 máquinas, não é.
Para que isso funcione, essas células precisam ser bastante uniformes, para que possamos mover as cargas de trabalho de uma célula para outra de maneira rápida e eficiente. Definimos certos requisitos que os serviços precisam atender antes de serem executados em uma célula. Por exemplo, os serviços devem ser conteinerizados, o que os torna muito mais portáveis e impede que alguém faça alterações na configuração no nível do sistema operacional. Adotamos uma filosofia de infraestrutura como código para células: em nosso repositório de código-fonte, incluímos a definição de tudo o que está em uma célula para que possamos reconstruí-la rapidamente do zero usando ferramentas automatizadas.
Atualmente, nem todos os serviços atendem a esses requisitos, por isso trabalhamos para ajudar os proprietários de serviços a atendê-los sempre que possível e criamos novas ferramentas para facilitar a migração de serviços para células quando estiverem prontos. Por exemplo, nossa nova ferramenta de implantação “distribui” automaticamente uma implantação de serviço entre células, para que os proprietários de serviços não precisem pensar na estratégia de replicação. Este nível de rigor torna o processo de migração muito mais desafiante e demorado, mas a recompensa a longo prazo será um sistema onde:
- É muito mais fácil conter uma falha e evitar que ela se espalhe para outras células;
- Nossos engenheiros de infraestrutura podem ser mais eficientes e agir mais rapidamente; e
- Os engenheiros que constroem os serviços em nível de produto que são finalmente implantados nas células não precisam saber ou se preocupar com quais células seus serviços estão sendo executados.
Resolvendo desafios maiores
Semelhante à forma como as portas corta-fogo são usadas para conter chamas, as células atuam como fortes paredes anti-explosão dentro de nossa infraestrutura para ajudar a conter qualquer problema que esteja provocando uma falha em uma única célula. Eventualmente, todos os serviços que compõem o Roblox serão implantados de forma redundante dentro e entre células. Depois que esse trabalho for concluído, os problemas ainda poderão se propagar o suficiente para tornar uma célula inteira inoperante, mas seria extremamente difícil que um problema se propagasse além dessa célula. E se conseguirmos tornar as células intercambiáveis, a recuperação será significativamente mais rápida porque poderemos fazer failover para uma célula diferente e evitar que o problema afete os usuários finais.
O que fica complicado é separar essas células o suficiente para reduzir a oportunidade de propagação de erros, ao mesmo tempo que mantém o desempenho e a funcionalidade. Num sistema de infraestrutura complexo, os serviços precisam de comunicar entre si para partilhar consultas, informações, cargas de trabalho, etc. À medida que replicamos estes serviços em células, precisamos de estar atentos à forma como gerimos a comunicação cruzada. Em um mundo ideal, redirecionamos o tráfego de uma célula não saudável para outras células saudáveis. Mas como administramos uma “questão de morte” – uma que é causando uma célula não é saudável? Se redirecionarmos essa consulta para outra célula, isso poderá fazer com que essa célula se torne insalubre da maneira que estamos tentando evitar. Precisamos encontrar mecanismos para desviar o tráfego “bom” de células não saudáveis e, ao mesmo tempo, detectar e silenciar o tráfego que está causando a deterioração das células.
No curto prazo, implantamos cópias de serviços de computação em cada célula de computação para que a maioria das solicitações ao data center possa ser atendida por uma única célula. Também estamos balanceando a carga do tráfego entre as células. Olhando mais além, começamos a construir um processo de descoberta de serviços de próxima geração que será aproveitado por uma malha de serviços, que esperamos concluir em 2024. Isso nos permitirá implementar políticas sofisticadas que permitirão a comunicação entre células somente quando não afetará negativamente as células de failover. Também será lançado em 2024 um método para direcionar solicitações dependentes para uma versão de serviço na mesma célula, o que minimizará o tráfego entre células e, assim, reduzirá o risco de propagação de falhas entre células.
No pico, mais de 70% do nosso tráfego de serviços de back-end é servido fora das células e aprendemos muito sobre como criar células, mas prevemos mais pesquisas e testes à medida que continuamos a migrar nossos serviços até 2024 e além. À medida que avançamos, estas paredes anti-explosão tornar-se-ão cada vez mais fortes.
Migrando uma infraestrutura sempre ativa
Roblox é uma plataforma global que oferece suporte a usuários em todo o mundo, por isso não podemos mover serviços fora do horário de pico ou “tempo de inatividade”, o que complica ainda mais o processo de migração de todas as nossas máquinas para células e nossos serviços para serem executados nessas células . Temos milhões de experiências sempre ativas que precisam continuar a receber suporte, mesmo enquanto movemos as máquinas em que são executadas e os serviços que as suportam. Quando iniciamos esse processo, não tínhamos dezenas de milhares de máquinas paradas, sem uso e disponíveis para migrar essas cargas de trabalho.
No entanto, tínhamos um pequeno número de máquinas adicionais que foram adquiridas em antecipação ao crescimento futuro. Para começar, construímos novas células usando essas máquinas e depois migramos as cargas de trabalho para elas. Valorizamos a eficiência e também a confiabilidade, portanto, em vez de sair e comprar mais máquinas quando ficamos sem máquinas “sobressalentes”, construímos mais células limpando e reprovisionando as máquinas das quais migramos. Em seguida, migramos as cargas de trabalho para essas máquinas reprovisionadas e iniciamos o processo novamente. Este processo é complexo – à medida que as máquinas são substituídas e libertadas para serem incorporadas nas células, elas não são libertadas de uma forma ideal e ordenada. Eles estão fisicamente fragmentados em data halls, o que nos obriga a provisioná-los de forma fragmentada, o que requer um processo de desfragmentação em nível de hardware para manter os locais de hardware alinhados com domínios de falha física em grande escala.
Uma parte de nossa equipe de engenharia de infraestrutura está focada na migração de cargas de trabalho existentes de nosso ambiente legado, ou “pré-célula”, para células. Esse trabalho continuará até migrarmos milhares de diferentes serviços de infraestrutura e milhares de serviços de back-end para células recém-construídas. Esperamos que isso leve todo o próximo ano e possivelmente até 2025, devido a alguns fatores complicadores. Primeiro, este trabalho requer a construção de ferramentas robustas. Por exemplo, precisamos de ferramentas para reequilibrar automaticamente um grande número de serviços quando implantamos uma nova célula — sem impactar nossos usuários. Também vimos serviços que foram construídos com base em suposições sobre a nossa infraestrutura. Precisamos rever estes serviços para que não dependam de coisas que possam mudar no futuro, à medida que avançamos para as células. Também implementamos uma forma de pesquisar padrões de design conhecidos que não funcionarão bem com a arquitetura celular, bem como um processo de teste metódico para cada serviço que for migrado. Esses processos nos ajudam a evitar quaisquer problemas enfrentados pelo usuário causados pela incompatibilidade de um serviço com células.
Hoje, cerca de 30,000 mil máquinas são gerenciadas por células. É apenas uma fração da nossa frota total, mas tem sido uma transição muito tranquila até agora, sem nenhum impacto negativo para os jogadores. Nosso objetivo final é que nossos sistemas atinjam 99.99% de tempo de atividade do usuário todos os meses, o que significa que não interromperíamos mais do que 0.01% das horas de engajamento. O tempo de inatividade em todo o setor não pode ser completamente eliminado, mas nosso objetivo é reduzir qualquer tempo de inatividade do Roblox a um nível que seja quase imperceptível.
Preparado para o futuro à medida que crescemos
Embora os nossos esforços iniciais estejam a revelar-se bem-sucedidos, o nosso trabalho com células está longe de estar concluído. À medida que a Roblox continua a crescer, continuaremos a trabalhar para melhorar a eficiência e a resiliência dos nossos sistemas através desta e de outras tecnologias. À medida que avançamos, a plataforma tornar-se-á cada vez mais resiliente aos problemas, e quaisquer problemas que ocorram deverão tornar-se progressivamente menos visíveis e perturbadores para as pessoas na nossa plataforma.
Em resumo, até o momento, temos:
- Construiu um segundo data center e alcançou com sucesso o status ativo/passivo.
- Criamos células em nossos data centers ativos e passivos e migramos com sucesso mais de 70% do nosso tráfego de serviço de back-end para essas células.
- Estabeleça os requisitos e as práticas recomendadas que precisaremos seguir para manter todas as células uniformes à medida que continuamos a migrar o restante da nossa infraestrutura.
- Iniciou um processo contínuo de construção de “paredes anti-explosão” mais fortes entre as células.
À medida que essas células se tornam mais intercambiáveis, haverá menos interferência entre as células. Isso abre algumas oportunidades muito interessantes para nós em termos de aumento da automação em torno do monitoramento, solução de problemas e até mesmo transferência automática de cargas de trabalho.
Em setembro, também começamos a realizar experimentos ativos/ativos em nossos data centers. Este é outro mecanismo que estamos testando para melhorar a confiabilidade e minimizar os tempos de failover. Estas experiências ajudaram a identificar uma série de padrões de design de sistemas, principalmente em torno do acesso a dados, que precisamos de retrabalhar à medida que avançamos para nos tornarmos totalmente ativos-ativos. No geral, o experimento foi bem-sucedido o suficiente para deixá-lo funcionando para o tráfego de um número limitado de nossos usuários.
Estamos entusiasmados em continuar impulsionando esse trabalho para trazer maior eficiência e resiliência à plataforma. Este trabalho em células e infraestruturas ativo-ativas, juntamente com os nossos outros esforços, permitir-nos-á crescer e tornar-nos numa empresa de serviços públicos fiável e de elevado desempenho para milhões de pessoas e continuar a crescer à medida que trabalhamos para ligar mil milhões de pessoas em condições reais. tempo.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- habilidade
- Capaz
- Sobre
- Acesso
- Alcançar
- alcançado
- em
- Aja
- atuação
- ativo
- adicionado
- Adicional
- endereço
- adotado
- novamente
- agressivamente
- alinhado
- Todos os Produtos
- permitir
- sozinho
- juntamente
- já
- tb
- an
- e
- Outro
- antecipar
- antecipação
- qualquer
- qualquer um
- aproximadamente
- arquitetura
- SOMOS
- por aí
- AS
- suposições
- At
- Automatizado
- automaticamente
- Automação
- disponível
- Avatares
- evitar
- Back-end
- backup
- balanceador
- equilíbrio
- baseado
- BE
- Porque
- tornam-se
- torna-se
- tornando-se
- sido
- antes
- começou
- ser
- beneficiar
- MELHOR
- melhores práticas
- entre
- Pós
- Grande
- maior
- bilhão
- Blog
- ambos
- trazer
- Trazido
- erros
- construir
- Prédio
- construído
- negócios
- mas a
- Comprar
- by
- chamada
- CAN
- não podes
- Capacidade
- casos
- Causar
- causado
- causando
- célula
- Células
- celular
- Centralização de
- Centros
- certo
- desafiante
- alterar
- Alterações
- Fechar
- Na nuvem
- infraestrutura de nuvem
- código
- como
- vinda
- comum
- comunicar
- comunicação
- Comunicação
- Empresas
- comparado
- completar
- completamente
- integrações
- complexidade
- componente
- componentes
- Computar
- computação
- Conferência
- Configuração
- Contato
- da conexão
- não contenho
- contém
- continuar
- continua
- contínuo
- ao controle
- cópias
- custos
- poderia
- crio
- Criar
- criadores
- Atualmente
- Feito sob encomenda
- diariamente
- dados,
- acesso a dados
- Data Center
- centros de dados
- Data
- dia
- definição
- Grau
- atrasos
- depender
- dependente
- implantar
- implantado
- desenvolvimento
- Design
- Padrões de design
- DID
- diferente
- difícil
- dirigindo
- descoberta
- perturbe
- disruptivo
- distribuindo
- do
- parece
- fazer
- domínios
- feito
- não
- portas
- down
- tempo de inatividade
- condução
- dois
- durante
- cada
- Cedo
- mais fácil
- fácil
- eficiência
- eficiente
- eficientemente
- esforços
- eliminado
- permite
- final
- COMPROMETIMENTO
- Engenharia
- Engenheiros
- suficiente
- garantir
- Todo
- inteiramente
- Meio Ambiente
- erro
- erros
- essencialmente
- etc.
- Mesmo
- eventualmente
- Cada
- tudo
- exemplo
- animado
- existente
- esperar
- experiente
- Experiências
- experimentar
- experimentos
- extremo
- extremamente
- fatores
- FALHA
- falta
- falha
- Falha
- falhas
- bastante
- longe
- Moda
- mais rápido
- Encontre
- Fogo
- Primeiro nome
- ANIMARIS
- Foco
- focado
- seguir
- Escolha
- para a frente
- fração
- fragmentado
- Gratuito
- freqüente
- da
- cheio
- totalmente
- funcional
- mais distante
- futuro
- crescimento futuro
- geralmente
- geográfico
- ter
- obtendo
- dado
- Global
- Globalmente
- Go
- meta
- vai
- vai
- maior
- Grupo
- Cresça:
- crescido
- Growth
- tinha
- Metade
- manipular
- Manipulação
- acontecer
- Queijos duros
- Hardware
- Ter
- cabeça
- Saúde
- saudável
- ajudar
- ajudou
- Alta
- superior
- esperança
- HORÁRIO
- Como funciona o dobrador de carta de canal
- Como Negociar
- Contudo
- HTTPS
- Humanos
- HÍBRIDO
- ideal
- identificar
- if
- imersiva
- Impacto
- impactando
- executar
- implementado
- melhorar
- in
- incluir
- Incluindo
- incompatível
- Crescimento
- aumentando
- cada vez mais
- Individual
- indústria
- INFORMAÇÕES
- Infraestrutura
- dentro
- instância
- instâncias
- instantaneamente
- interessante
- interno
- para dentro
- emitem
- questões
- IT
- Junho
- apenas por
- Guarda
- manutenção
- Saber
- conhecido
- grande
- em grande escala
- largamente
- Latência
- aprendido
- Deixar
- partida
- Legado
- menos
- deixar
- Nível
- alavancado
- como
- Limitado
- carregar
- localizado
- locais
- longo prazo
- mais
- procurando
- lote
- Baixo
- máquina
- máquinas
- a manter
- fazer
- FAZ
- Fazendo
- gerencia
- gerenciados
- manualmente
- muitos
- max-width
- significar
- significado
- mecanismo
- mecanismos
- Conheça
- malha
- método
- metódico
- poder
- migrado
- migrou
- migrando
- migração
- milhão
- milhões
- minimizar
- menor
- erros
- monitoração
- Mês
- mais
- mais eficiente
- a maioria
- mover
- muito
- múltiplo
- devo
- Natureza
- quase
- você merece...
- necessário
- negativo
- negativamente
- rede
- Novo
- recentemente
- Próximo
- próxima geração
- não
- agora
- número
- números
- ocorrer
- Outubro
- of
- WOW!
- on
- uma vez
- ONE
- contínuo
- só
- oportunidades
- Oportunidade
- or
- OS
- Outros
- Outros
- A Nossa
- Fora
- interrupção
- Interrupções
- Acima de
- global
- proprietários
- parte
- passiva
- passado
- padrões
- pagar
- Pico
- Pessoas
- para
- por cento
- realização
- persistentemente
- pessoa
- filosofia
- físico
- Fisicamente
- escolher
- Lugar
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogador
- políticas
- portátil
- parte
- possibilidade
- possível
- possivelmente
- potencialmente
- práticas
- evitar
- impede
- principalmente
- prioridade
- privado
- processo
- processos
- Progresso
- progressivamente
- propagação
- proteção
- provando
- provisão
- comprado
- Empurrar
- consultas
- questão
- rapidamente
- em vez
- pronto
- reais
- em tempo real
- reequilibrar
- recuperação
- redirecionar
- reduzir
- região
- confiabilidade
- confiável
- depender
- reparar
- substituído
- réplica
- repositório
- pedidos
- Requisitos
- exige
- pesquisa
- resiliência
- resiliente
- resolver
- DESCANSO
- resultar
- resultou
- revisão
- Risco
- Roblox
- uma conta de despesas robusta
- Execute
- corrida
- é executado
- seguramente
- mesmo
- salvo
- Escala
- cenário
- arranhar
- Pesquisar
- Segundo
- visto
- separando
- Setembro
- servido
- serviço
- Serviços
- de servir
- conjunto
- vários
- Partilhar
- compartilhado
- compartilhando
- mudança
- MUDANÇA
- Baixo
- rede de apoio social
- de forma considerável
- desde
- solteiro
- Sentado
- pequeno
- Liso
- So
- até aqui
- Software
- alguns
- algo
- sofisticado
- fonte
- código fonte
- Espaço
- picos
- propagação
- Espalhando
- começo
- começado
- começa
- Status
- Ainda
- Estratégia
- mais forte,
- mais forte
- Estudando
- suceder
- bem sucedido
- entraram com sucesso
- RESUMO
- ajuda
- Suportado
- Apoiar
- suportes
- .
- sistemas
- Tire
- tomado
- Profissionais
- Dados Técnicos:
- Tecnologias
- dezenas
- prazo
- condições
- ensaio
- texto
- do que
- que
- A
- O Futuro
- o mundo
- deles
- Eles
- então
- Lá.
- assim
- Este
- deles
- coisas
- think
- isto
- aqueles
- milhares
- Através da
- todo
- tempo
- vezes
- para
- hoje
- juntos
- tolerância
- também
- ferramenta
- ferramentas
- Total
- para
- tráfego
- transição
- desencadeando
- tentando
- dois
- tipos
- final
- Em última análise
- destranca
- até
- não usado
- sobre
- uptime
- us
- usava
- Utilizador
- usuários
- utilização
- utilidade
- valor
- versão
- muito
- visível
- visão
- queremos
- foi
- Caminho..
- we
- Clima
- BEM
- foram
- O Quê
- o que quer
- quando
- qual
- enquanto
- QUEM
- Largo
- precisarão
- limpando
- de
- dentro
- Atividades:
- trabalhou
- trabalhar
- mundo
- preocupar-se
- seria
- ano
- anos
- zefirnet