Data lakes alimentados pela AWS, apoiados pela disponibilidade incomparável de Serviço de armazenamento simples da Amazon (Amazon S3), pode lidar com a escala, a agilidade e a flexibilidade necessárias para combinar diferentes abordagens de dados e análises. À medida que os data lakes cresceram em tamanho e amadureceram em uso, uma quantidade significativa de esforço pode ser despendida para manter os dados consistentes com os eventos de negócios. Para garantir que os arquivos sejam atualizados de maneira transacionalmente consistente, um número crescente de clientes está usando formatos de tabelas transacionais de código aberto, como Iceberg Apache, Apache Hudi e Fundação Linux Delta Lake que ajudam você a armazenar dados com altas taxas de compactação, fazer interface nativa com seus aplicativos e estruturas e simplificar o processamento incremental de dados em data lakes criados no Amazon S3. Esses formatos permitem transações, upserts e exclusões ACID (atomicidade, consistência, isolamento, durabilidade), além de recursos avançados, como viagem no tempo e instantâneos que antes estavam disponíveis apenas em data warehouses. Cada formato de armazenamento implementa esta funcionalidade de maneiras ligeiramente diferentes; para uma comparação, consulte Escolhendo um formato de tabela aberto para seu data lake transacional na AWS.
Em 2023, AWS anunciou disponibilidade geral para Apache Iceberg, Apache Hudi e Linux Foundation Delta Lake em Amazon Athena para Apache Spark, o que elimina a necessidade de instalar um conector separado ou dependências associadas e gerenciar versões, além de simplificar as etapas de configuração necessárias para usar essas estruturas.
Neste post, mostramos como usar o Spark SQL em Amazona atena notebooks e trabalhar com formatos de tabela Iceberg, Hudi e Delta Lake. Demonstramos operações comuns, como criação de bancos de dados e tabelas, inserção de dados nas tabelas, consulta de dados e visualização de snapshots de tabelas no Amazon S3 usando Spark SQL no Athena.
Pré-requisitos
Preencha os seguintes pré-requisitos:
Baixe e importe notebooks de exemplo do Amazon S3
Para acompanhar, baixe os notebooks discutidos nesta postagem nos seguintes locais:
Depois de fazer download dos notebooks, importe-os para o ambiente do Athena Spark seguindo o procedimento Para importar um bloco de notas seção em Gerenciando arquivos de notebook.
Navegue até a seção específica do formato de tabela aberta
Se você estiver interessado no formato da tabela Iceberg, navegue até Trabalhando com tabelas Apache Iceberg seção.
Se você estiver interessado no formato da tabela Hudi, navegue até Trabalhando com tabelas Apache Hudi seção.
Se você estiver interessado no formato da tabela Delta Lake, navegue até Trabalhando com tabelas Delta Lake básicas do Linux seção.
Trabalhando com tabelas Apache Iceberg
Ao usar notebooks Spark no Athena, você pode executar consultas SQL diretamente sem precisar usar o PySpark. Fazemos isso usando magias de células, que são cabeçalhos especiais em uma célula de notebook que alteram o comportamento da célula. Para SQL, podemos adicionar o %%sql magic, que interpretará todo o conteúdo da célula como uma instrução SQL a ser executada no Athena.
Nesta seção, mostramos como você pode usar o SQL no Apache Spark for Athena para criar, analisar e gerenciar tabelas do Apache Iceberg.
Configurar uma sessão de notebook
Para usar o Apache Iceberg no Athena, ao criar ou editar uma sessão, selecione o ícone Iceberg Apache opção expandindo o Propriedades do Apache Spark seção. Ele irá preencher previamente as propriedades conforme mostrado na imagem a seguir.
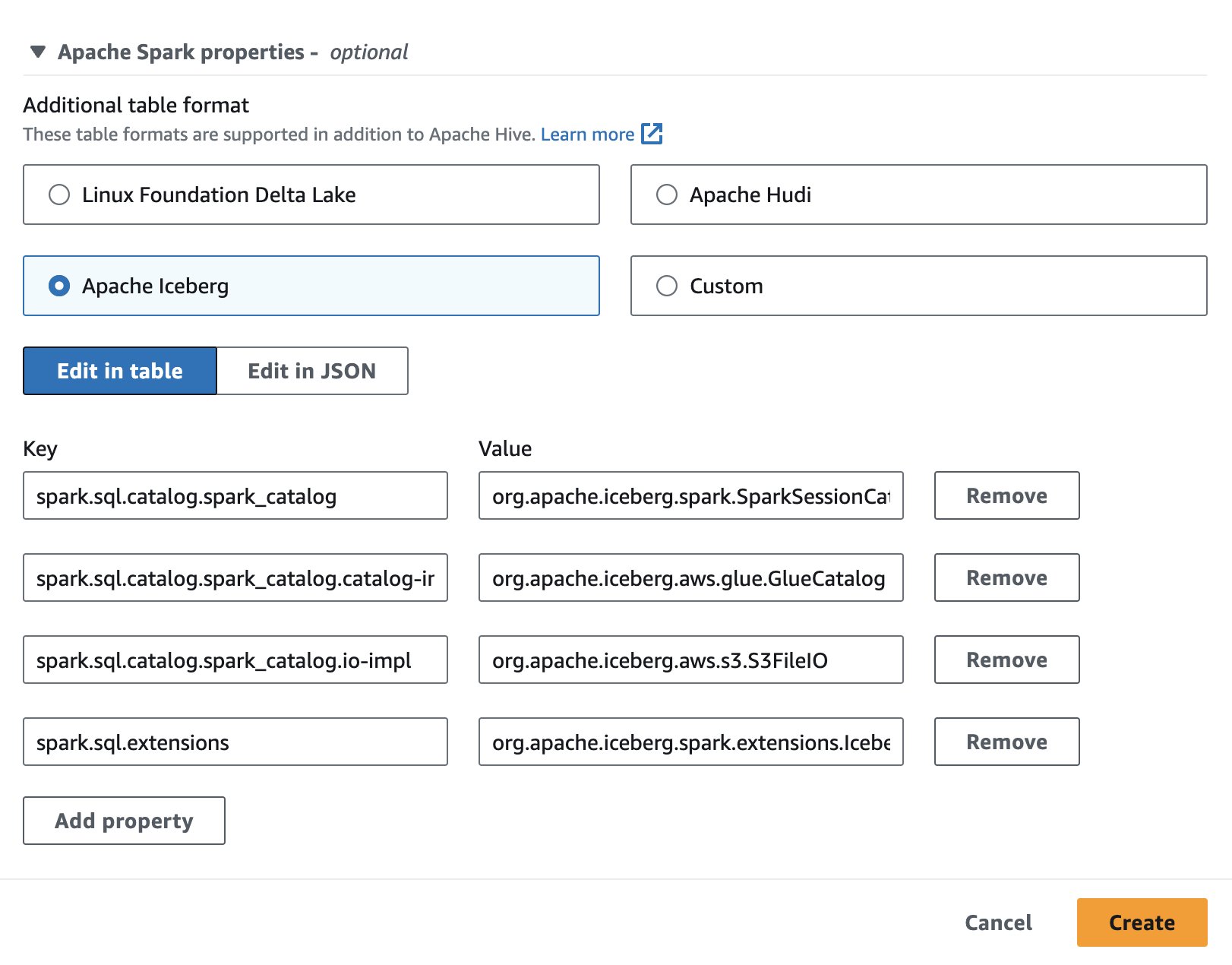
Para ver as etapas, consulte Editando detalhes da sessão or Criando seu próprio caderno.
O código usado nesta seção está disponível no SparkSQL_iceberg.ipynb arquivo para acompanhar.
Crie um banco de dados e uma tabela Iceberg
Primeiro, criamos um banco de dados no AWS Glue Data Catalog. Com o seguinte SQL, podemos criar um banco de dados chamado icebergdb:
A seguir, no banco de dados icebergdb, criamos uma tabela Iceberg chamada noaa_iceberg apontando para um local no Amazon S3 onde carregaremos os dados. Execute a seguinte instrução e substitua o local s3://<your-S3-bucket>/<prefix>/ com seu bucket S3 e prefixo:
Inserir dados na tabela
Para povoar o noaa_iceberg Tabela Iceberg, inserimos dados da tabela Parquet sparkblogdb.noaa_pq que foi criado como parte dos pré-requisitos. Você pode fazer isso usando um INSERT INTO declaração no Spark:
Alternativamente, você pode usar CRIAR TABELA COMO SELECT com a cláusula USING iceberg para criar uma tabela Iceberg e inserir dados de uma tabela de origem em uma única etapa:
Consultar a tabela Iceberg
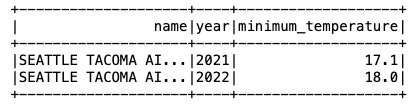
Agora que os dados estão inseridos na tabela Iceberg, podemos começar a analisá-los. Vamos executar um Spark SQL para encontrar a temperatura mínima registrada por ano para o 'SEATTLE TACOMA AIRPORT, WA US' localização:
Obtemos o seguinte resultado.
Atualizar dados na tabela Iceberg
Vejamos como atualizar os dados em nossa tabela. Queremos atualizar o nome da estação 'SEATTLE TACOMA AIRPORT, WA US' para 'Sea-Tac'. Usando Spark SQL, podemos executar um ATUALIZAÇÃO declaração contra a mesa Iceberg:
Podemos então executar a consulta SELECT anterior para encontrar a temperatura mínima registrada para o 'Sea-Tac' localização:
Obtemos a seguinte saída.

Arquivos de dados compactos
Formatos de tabela abertos como Iceberg funcionam criando alterações delta no armazenamento de arquivos e rastreando as versões de linhas por meio de arquivos de manifesto. Mais arquivos de dados levam a mais metadados armazenados em arquivos de manifesto, e arquivos de dados pequenos geralmente geram uma quantidade desnecessária de metadados, resultando em consultas menos eficientes e custos de acesso mais elevados ao Amazon S3. Executando Icebergs rewrite_data_files O procedimento no Spark for Athena compactará arquivos de dados, combinando muitos pequenos arquivos de alteração delta em um conjunto menor de arquivos Parquet otimizados para leitura. A compactação de arquivos acelera a operação de leitura quando consultados. Para executar a compactação em nossa tabela, execute o seguinte Spark SQL:
rewrite_data_files oferece opções para especificar sua estratégia de classificação, que pode ajudar a reorganizar e compactar os dados.
Listar instantâneos de tabela
Cada operação de gravação, atualização, exclusão, upsert e compactação em uma tabela Iceberg cria um novo instantâneo de uma tabela, mantendo os dados e metadados antigos para isolamento de instantâneo e viagem no tempo. Para listar os instantâneos de uma tabela Iceberg, execute a seguinte instrução Spark SQL:
Expirar instantâneos antigos
Recomenda-se a expiração regular de snapshots para excluir arquivos de dados que não são mais necessários e para manter pequeno o tamanho dos metadados da tabela. Ele nunca removerá arquivos que ainda são exigidos por um snapshot não expirado. No Spark for Athena, execute o SQL a seguir para expirar os snapshots da tabela icebergdb.noaa_iceberg que são mais antigos que um carimbo de data/hora específico:
Observe que o valor do carimbo de data/hora é especificado como uma string no formato yyyy-MM-dd HH:mm:ss.fff. A saída fornecerá uma contagem do número de arquivos de dados e metadados excluídos.
Elimine a tabela e o banco de dados
Você pode executar o seguinte Spark SQL para limpar as tabelas Iceberg e os dados associados no Amazon S3 deste exercício:
Execute o seguinte Spark SQL para remover o banco de dados icebergdb:
Para saber mais sobre todas as operações que você pode realizar em tabelas Iceberg usando Spark for Athena, consulte Consultas Spark e Procedimentos de faísca na documentação do Iceberg.
Trabalhando com tabelas Apache Hudi
A seguir, mostramos como você pode usar SQL no Spark for Athena para criar, analisar e gerenciar tabelas Apache Hudi.
Configurar uma sessão de notebook
Para usar o Apache Hudi no Athena, ao criar ou editar uma sessão, selecione o ícone Apache Hudi opção expandindo o Propriedades do Apache Spark seção.
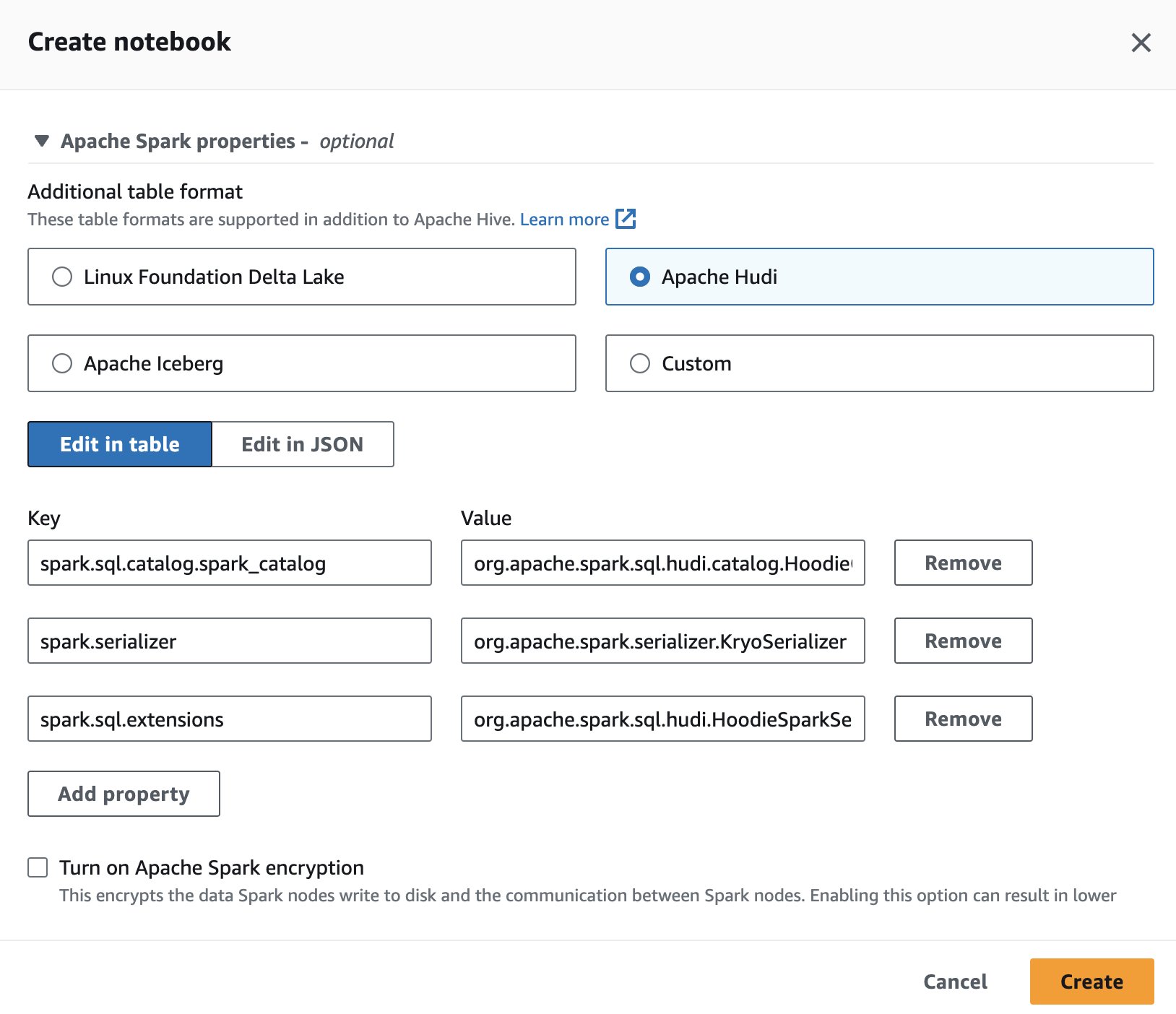
Para ver as etapas, consulte Editando detalhes da sessão or Criando seu próprio caderno.
O código usado nesta seção deve estar disponível no SparkSQL_hudi.ipynb arquivo para acompanhar.
Crie um banco de dados e uma tabela Hudi
Primeiro, criamos um banco de dados chamado hudidb que será armazenado no AWS Glue Data Catalog seguido pela criação da tabela Hudi:
Criamos uma tabela Hudi apontando para um local no Amazon S3 onde carregaremos os dados. Observe que a tabela é de cópia na escrita tipo. É definido por type= 'cow' na tabela DDL. Definimos estação e data como múltiplas chaves primárias e preCombinedField como ano. Além disso, a tabela é particionada por ano. Execute a seguinte instrução e substitua o local s3://<your-S3-bucket>/<prefix>/ com seu bucket S3 e prefixo:
Inserir dados na tabela
Tal como acontece com o Iceberg, usamos o INSERT INTO instrução para preencher a tabela lendo dados do sparkblogdb.noaa_pq tabela criada no post anterior:
Consultar a tabela Hudi
Agora que a tabela foi criada, vamos executar uma consulta para encontrar a temperatura máxima registrada para o 'SEATTLE TACOMA AIRPORT, WA US' localização:
Atualizar dados na tabela Hudi
Vamos mudar o nome da estação 'SEATTLE TACOMA AIRPORT, WA US' para 'Sea–Tac'. Podemos executar uma instrução UPDATE no Spark para Athena para atualizar os registros do noaa_hudi tabela:
Executamos a consulta SELECT anterior para encontrar a temperatura máxima registrada para o 'Sea-Tac' localização:
Execute consultas de viagem no tempo
Podemos usar consultas de viagem no tempo em SQL no Athena para analisar instantâneos de dados anteriores. Por exemplo:
Esta consulta verifica os dados de temperatura do aeroporto de Seattle em um horário específico no passado. A cláusula timestamp nos permite viajar de volta sem alterar os dados atuais. Observe que o valor do carimbo de data/hora é especificado como uma string no formato yyyy-MM-dd HH:mm:ss.fff.
Otimize a velocidade da consulta com clustering
Para melhorar o desempenho da consulta, você pode executar agrupamento em tabelas Hudi usando SQL no Spark for Athena:
Mesas compactas
Compactação é um serviço de tabela empregado pelo Hudi especificamente em tabelas Merge On Read (MOR) para mesclar atualizações de arquivos de log baseados em linhas para o arquivo base baseado em colunas correspondente periodicamente para produzir uma nova versão do arquivo base. A compactação não é aplicável a tabelas Copy On Write (COW) e aplica-se apenas a tabelas MOR. Você pode executar a seguinte consulta no Spark for Athena para realizar compactação em tabelas MOR:
Elimine a tabela e o banco de dados
Execute o seguinte Spark SQL para remover a tabela Hudi que você criou e os dados associados do local do Amazon S3:
Execute o seguinte Spark SQL para remover o banco de dados hudidb:
Para saber mais sobre todas as operações que você pode realizar em tabelas Hudi usando Spark for Athena, consulte DDL SQL e Procedimentos na documentação do Hudi.
Trabalhando com tabelas Delta Lake básicas do Linux
A seguir, mostramos como você pode usar SQL no Spark for Athena para criar, analisar e gerenciar tabelas Delta Lake.
Configurar uma sessão de notebook
Para usar Delta Lake no Spark for Athena, ao criar ou editar uma sessão, selecione Fundação Linux Delta Lake expandindo o Propriedades do Apache Spark seção.
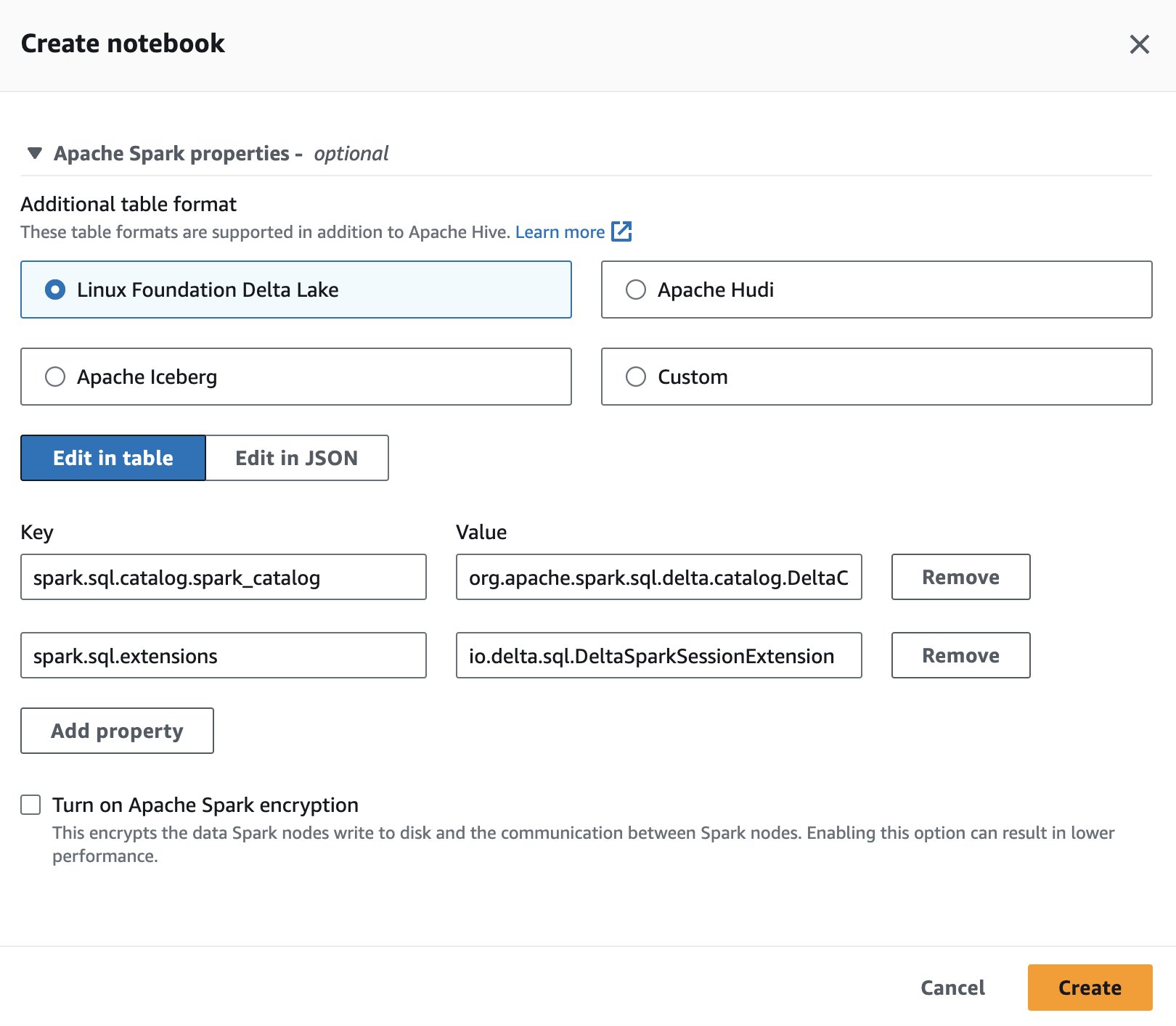
Para ver as etapas, consulte Editando detalhes da sessão or Criando seu próprio caderno.
O código usado nesta seção deve estar disponível no SparkSQL_delta.ipynb arquivo para acompanhar.
Crie um banco de dados e uma tabela Delta Lake
Nesta seção, criamos um banco de dados no AWS Glue Data Catalog. Usando o seguinte SQL, podemos criar um banco de dados chamado deltalakedb:
A seguir, no banco de dados deltalakedb, criamos uma tabela Delta Lake chamada noaa_delta apontando para um local no Amazon S3 onde carregaremos os dados. Execute a seguinte instrução e substitua o local s3://<your-S3-bucket>/<prefix>/ com seu bucket S3 e prefixo:
Inserir dados na tabela
Nós usamos um INSERT INTO instrução para preencher a tabela lendo dados do sparkblogdb.noaa_pq tabela criada no post anterior:
Você também pode usar CREATE TABLE AS SELECT para criar uma tabela Delta Lake e inserir dados de uma tabela de origem em uma consulta.
Consultar a tabela Delta Lake
Agora que os dados estão inseridos na tabela Delta Lake, podemos começar a analisá-los. Vamos executar um Spark SQL para encontrar a temperatura mínima registrada para o 'SEATTLE TACOMA AIRPORT, WA US' localização:
Atualizar dados na tabela Delta lake
Vamos mudar o nome da estação 'SEATTLE TACOMA AIRPORT, WA US' para 'Sea–Tac'. Podemos executar um ATUALIZAÇÃO declaração no Spark para Athena atualizar os registros do noaa_delta tabela:
Podemos executar a consulta SELECT anterior para encontrar a temperatura mínima registrada para o 'Sea-Tac' localização, e o resultado deve ser o mesmo de antes:
Arquivos de dados compactos
No Spark for Athena, você pode executar OPTIMIZE na tabela Delta Lake, que compactará os arquivos pequenos em arquivos maiores, para que as consultas não sejam sobrecarregadas pela sobrecarga de arquivos pequenos. Para realizar a operação de compactação, execute a seguinte consulta:
Consulte otimizações na documentação do Delta Lake para diferentes opções disponíveis durante a execução do OPTIMIZE.
Remover arquivos que não são mais referenciados por uma tabela Delta Lake
Você pode remover arquivos armazenados no Amazon S3 que não são mais referenciados por uma tabela Delta Lake e são mais antigos que o limite de retenção executando o comando VACCUM na tabela usando Spark for Athena:
Consulte Remover arquivos que não são mais referenciados por uma tabela Delta na documentação do Delta Lake para opções disponíveis com VACUUM.
Elimine a tabela e o banco de dados
Execute o seguinte Spark SQL para remover a tabela Delta Lake que você criou:
Execute o seguinte Spark SQL para remover o banco de dados deltalakedb:
A execução de DROP TABLE DDL na tabela e no banco de dados Delta Lake exclui os metadados desses objetos, mas não exclui automaticamente os arquivos de dados no Amazon S3. Você pode executar o seguinte código Python na célula do notebook para excluir os dados do local S3:
Para saber mais sobre as instruções SQL que podem ser executadas em uma tabela Delta Lake usando Spark for Athena, consulte o começo rápido na documentação do Delta Lake.
Conclusão
Esta postagem demonstrou como usar Spark SQL em notebooks Athena para criar bancos de dados e tabelas, inserir e consultar dados e realizar operações comuns como atualizações, compactações e viagens no tempo em tabelas Hudi, Delta Lake e Iceberg. Os formatos de tabela abertos adicionam transações ACID, upserts e exclusões a data lakes, superando as limitações do armazenamento de objetos brutos. Ao eliminar a necessidade de instalar conectores separados, a integração integrada do Spark no Athena reduz as etapas de configuração e a sobrecarga de gerenciamento ao usar essas estruturas populares para criar data lakes confiáveis no Amazon S3. Para saber mais sobre como selecionar um formato de tabela aberto para suas cargas de trabalho de data lake, consulte Escolhendo um formato de tabela aberto para seu data lake transacional na AWS.
Sobre os autores
![]() Pathik Xá é arquiteto sênior de análise no Amazon Athena. Ele ingressou na AWS em 2015 e tem se concentrado no espaço de análise de big data desde então, ajudando os clientes a criar soluções escaláveis e robustas usando os serviços de análise da AWS.
Pathik Xá é arquiteto sênior de análise no Amazon Athena. Ele ingressou na AWS em 2015 e tem se concentrado no espaço de análise de big data desde então, ajudando os clientes a criar soluções escaláveis e robustas usando os serviços de análise da AWS.
![]() Raj Devnath é gerente de produtos da AWS no Amazon Athena. Ele é apaixonado por criar produtos que os clientes amam e ajudá-los a extrair valor de seus dados. Sua experiência é no fornecimento de soluções para vários mercados finais, como finanças, varejo, edifícios inteligentes, automação residencial e sistemas de comunicação de dados.
Raj Devnath é gerente de produtos da AWS no Amazon Athena. Ele é apaixonado por criar produtos que os clientes amam e ajudá-los a extrair valor de seus dados. Sua experiência é no fornecimento de soluções para vários mercados finais, como finanças, varejo, edifícios inteligentes, automação residencial e sistemas de comunicação de dados.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :tem
- :é
- :não
- :onde
- $UP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- Sobre
- Acesso
- adicionar
- avançado
- contra
- aeroporto
- Todos os Produtos
- juntamente
- tb
- Amazon
- Amazona atena
- Amazon Web Services
- quantidade
- an
- analítica
- analisar
- análise
- e
- anunciou
- apache
- Apache Spark
- relevante
- aplicações
- aplica
- se aproxima
- SOMOS
- por aí
- AS
- associado
- At
- automaticamente
- Automação
- disponibilidade
- disponível
- AWS
- Cola AWS
- em caminho duplo
- fundo
- base
- BE
- sido
- comportamento
- Grande
- Big Data
- construir
- Prédio
- construído
- construídas em
- negócio
- mas a
- by
- chamada
- chamado
- CAN
- catálogo
- Causar
- célula
- alterar
- Alterações
- Cheques
- limpar
- código
- combinar
- combinando
- comum
- Comunicação
- sistemas de comunicação
- compacto
- comparação
- Configuração
- consistente
- conteúdo
- Correspondente
- custos
- contar
- crio
- criado
- cria
- Criar
- criação
- Atual
- Clientes
- dados,
- Análise de Dados
- lago data
- informática
- armazéns de dados
- banco de dados
- bases de dados
- Data
- definido
- entregando
- Delta
- demonstrar
- demonstraram
- dependências
- diferente
- diretamente
- discutido
- do
- documentação
- Não faz
- download
- Cair
- durabilidade
- cada
- Mais cedo
- edição
- eficiente
- esforço
- empregada
- permitir
- final
- garantir
- Todo
- Meio Ambiente
- Éter (ETH)
- eventos
- exemplo
- Exercício
- expansão
- extrato
- Funcionalidades
- Envie o
- Arquivos
- financiar
- Encontre
- Primeiro nome
- Flexibilidade
- focando
- seguir
- seguido
- seguinte
- Escolha
- formato
- Foundation
- enquadramentos
- da
- funcionalidade
- Geral
- ter
- OFERTE
- Grupo
- Crescente
- crescido
- manipular
- Ter
- ter
- he
- cabeçalhos
- ajudar
- ajuda
- hh
- Alta
- superior
- sua
- Início
- Domótica
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- imagem
- implementa
- importar
- melhorar
- in
- incrementais
- instalar
- integração
- interessado
- Interface
- para dentro
- isolamento
- IT
- ingressou
- jpg
- Guarda
- manutenção
- chaves
- lago
- lagos
- Maior
- latitude
- Leads
- APRENDER
- menos
- Permite
- como
- limitações
- linux
- fundação linux
- Lista
- carregar
- localização
- locais
- log
- mais
- olhar
- procurando
- gosta,
- mágica
- gerencia
- de grupos
- Gerente
- maneira
- muitos
- Mercados
- max
- máximo
- ir
- metadados
- minutos
- mínimo
- mais
- múltiplo
- nome
- nativamente
- Navegar
- você merece...
- necessário
- nunca
- Novo
- não
- nota
- caderno
- laptops
- número
- objeto
- Armazenamento de objetos
- objetos
- of
- Oferece
- frequentemente
- Velho
- mais velho
- on
- ONE
- só
- OP
- aberto
- open source
- operação
- Operações
- Otimize
- Opção
- Opções
- or
- ordem
- A Nossa
- saída
- superação
- próprio
- parte
- apaixonado
- passado
- realizar
- atuação
- platão
- Inteligência de Dados Platão
- PlatãoData
- Popular
- Publique
- pré-requisitos
- anterior
- anteriormente
- primário
- procedimentos
- em processamento
- produzir
- Produto
- gerente de produto
- Produtos
- Propriedades
- Python
- consultas
- Preços
- Cru
- Leia
- Leitura
- Recomenda
- gravado
- registros
- reduz
- referir
- referenciada
- confiável
- remover
- remove
- removendo
- substituir
- requeridos
- resultar
- resultando
- varejo
- retenção
- uma conta de despesas robusta
- Execute
- corrida
- mesmo
- escalável
- Escala
- Seattle
- Segundo
- Seção
- Vejo
- selecionar
- selecionando
- separado
- serviço
- Serviços
- Sessão
- conjunto
- rede de apoio social
- mostrar
- mostrando
- Shows
- periodo
- simples
- simplifica
- simplificar
- desde
- Tamanho
- ligeiramente diferente
- SLP
- pequeno
- menor
- smart
- Instantâneo
- So
- Soluções
- fonte
- Espaço
- Faísca
- especial
- específico
- especificamente
- especificada
- velocidade
- velocidades
- gasto
- SQL
- começo
- Declaração
- declarações
- estação
- Passo
- Passos
- Ainda
- armazenamento
- loja
- armazenadas
- Estratégia
- Tanga
- tal
- Suportado
- .
- sistemas
- mesa
- Tacoma
- do que
- que
- A
- deles
- Eles
- então
- Este
- isto
- limiar
- Através da
- tempo
- viagem no tempo
- timestamp
- para
- Rastreamento
- transacional
- Transações
- viagens
- tipo
- incomparável
- Atualizar
- Atualizada
- Atualizações
- us
- Uso
- usar
- usava
- utilização
- Vácuo
- valor
- versão
- versões
- queremos
- foi
- maneiras
- we
- web
- serviços web
- foram
- quando
- qual
- enquanto
- precisarão
- de
- sem
- Atividades:
- escrever
- ano
- Você
- investimentos
- zefirnet