Como praticamente todos os clientes, você deseja gastar o mínimo possível e ao mesmo tempo obter o melhor desempenho possível. Isso significa que você precisa prestar atenção ao preço-desempenho. Com Amazon RedShift, Você pode ter seu bolo e comê-lo também! O Amazon Redshift oferece custo por usuário até 4.9 vezes menor e relação preço-desempenho até 7.9 vezes melhor do que outros data warehouses em nuvem em cargas de trabalho do mundo real usando técnicas avançadas como escalabilidade de simultaneidade para oferecer suporte a centenas de usuários simultâneos, codificação de string aprimorada para desempenho de consulta mais rápido , e Sem servidor Amazon Redshift melhorias de desempenho. Continue lendo para entender por que o preço-desempenho é importante e como o preço-desempenho do Amazon Redshift é uma medida de quanto custa obter um nível específico de desempenho de carga de trabalho, ou seja, o ROI (retorno sobre o investimento) de desempenho.
Como tanto o preço como o desempenho entram no cálculo do preço-desempenho, há duas maneiras de pensar sobre o preço-desempenho. A primeira maneira é manter o preço constante: se você tem US$ 1 para gastar, quanto desempenho você obtém do seu data warehouse? Um banco de dados com melhor relação preço-desempenho proporcionará melhor desempenho para cada US$ 1 gasto. Portanto, ao manter o preço constante ao comparar dois data warehouses que custam o mesmo, o banco de dados com melhor relação preço-desempenho executará suas consultas com mais rapidez. A segunda maneira de analisar a relação preço-desempenho é manter o desempenho constante: se você precisa que sua carga de trabalho termine em 10 minutos, quanto custará? Um banco de dados com melhor relação custo-benefício executará sua carga de trabalho em 10 minutos a um custo menor. Portanto, ao manter o desempenho constante ao comparar dois data warehouses dimensionados para oferecer o mesmo desempenho, o banco de dados com melhor relação preço-desempenho custará menos e economizará dinheiro.
Finalmente, outro aspecto importante da relação preço-desempenho é a previsibilidade. Saber quanto custará o seu data warehouse à medida que o número de usuários do data warehouse cresce é crucial para o planejamento. Ele não deve apenas oferecer o melhor custo-benefício atual, mas também escalar de forma previsível e oferecer o melhor custo-benefício à medida que mais usuários e cargas de trabalho são adicionados. Um data warehouse ideal deve ter escala linear— dimensionar seu data warehouse para fornecer o dobro da taxa de transferência de consultas deveria, idealmente, custar o dobro (ou menos).
Nesta postagem, compartilhamos resultados de desempenho para ilustrar como o Amazon Redshift oferece desempenho de preço significativamente melhor em comparação com os principais data warehouses alternativos em nuvem. Isso significa que se você gastar no Amazon Redshift o mesmo valor que gastaria em um desses outros data warehouses, obterá melhor desempenho com o Amazon Redshift. Como alternativa, se você dimensionar seu cluster Redshift para oferecer o mesmo desempenho, verá custos mais baixos em comparação com essas alternativas.
Preço-desempenho para cargas de trabalho do mundo real
Você pode usar o Amazon Redshift para potencializar uma ampla diversidade de cargas de trabalho, desde o processamento em lote de relatórios complexos baseados em extração, transformação e carregamento (ETL) e análise de streaming em tempo real até painéis de business intelligence (BI) de baixa latência que precisa atender centenas ou até milhares de usuários ao mesmo tempo com tempos de resposta de menos de um segundo e tudo mais. Uma das maneiras pelas quais melhoramos continuamente o desempenho de preço para nossos clientes é revisar constantemente a telemetria de desempenho de software e hardware da frota Redshift, procurando oportunidades e casos de uso de clientes onde possamos melhorar ainda mais o desempenho do Amazon Redshift.
Alguns exemplos recentes de otimizações de desempenho impulsionadas pela telemetria da frota incluem:
- Otimizações de consulta de string – Ao analisar como o Amazon Redshift processou diferentes tipos de dados na frota Redshift, descobrimos que a otimização de consultas com muitas strings traria benefícios significativos para as cargas de trabalho de nossos clientes. (Discutiremos isso com mais detalhes posteriormente nesta postagem.)
- Visualizações materializadas automatizadas – Descobrimos que os clientes do Amazon Redshift geralmente executam muitas consultas que possuem padrões de subconsulta comuns. Por exemplo, diversas consultas diferentes podem unir as mesmas três tabelas usando a mesma condição de junção. O Amazon Redshift agora é capaz de criar e manter visualizações materializadas automaticamente e, em seguida, reescrever consultas de forma transparente para usar as visualizações materializadas usando o aprendizado de máquina visão materializada automatizada recurso de autonomia no Amazon Redshift. Quando ativadas, as visualizações materializadas automatizadas podem aumentar de forma transparente o desempenho de consultas repetitivas sem qualquer intervenção do usuário. (Observe que as visualizações materializadas automatizadas não foram usadas em nenhum dos resultados de benchmark discutidos nesta postagem).
- Cargas de trabalho de alta simultaneidade – Um caso de uso crescente que vemos é o uso do Amazon Redshift para atender cargas de trabalho semelhantes a painéis. Essas cargas de trabalho são caracterizadas por tempos de resposta de consulta desejados de segundos ou menos, com dezenas ou centenas de usuários simultâneos executando consultas simultaneamente com um padrão de uso pontiagudo e muitas vezes imprevisível. O exemplo prototípico disso é um painel de BI apoiado pelo Amazon Redshift que apresenta um pico no tráfego nas manhãs de segunda-feira, quando um grande número de usuários inicia a semana.
Cargas de trabalho de alta simultaneidade, em particular, têm aplicabilidade muito ampla: a maioria das cargas de trabalho de data warehouse opera em simultaneidade, e não é incomum que centenas ou até milhares de usuários executem consultas no Amazon Redshift ao mesmo tempo. O Amazon Redshift foi projetado para manter os tempos de resposta das consultas previsíveis e rápidos. O Redshift Serverless faz isso automaticamente para você, adicionando e removendo computação conforme necessário para manter os tempos de resposta das consultas rápidos e previsíveis. Isso significa que um painel com suporte do Redshift Serverless que carrega rapidamente quando está sendo acessado por um ou dois usuários continuará a carregar rapidamente mesmo quando muitos usuários o estiverem carregando ao mesmo tempo.
Para simular esse tipo de carga de trabalho, utilizamos um benchmark derivado do TPC-DS com um conjunto de dados de 100 GB. TPC-DS é um benchmark padrão do setor que inclui uma variedade de consultas típicas de data warehouse. Nessa escala relativamente pequena de 100 GB, as consultas neste benchmark são executadas no Redshift Serverless em uma média de alguns segundos, o que é representativo do que os usuários que carregam um painel de BI interativo esperariam. Executamos entre 1 e 200 testes simultâneos deste benchmark, simulando entre 1 e 200 usuários tentando carregar um painel ao mesmo tempo. Também repetimos o teste em vários data warehouses em nuvem alternativos populares que também suportam expansão automática (se você estiver familiarizado com a postagem Amazon Redshift continua sua liderança em preço-desempenho, não incluímos o Concorrente A porque ele não suporta expansão automática). Medimos o tempo médio de resposta da consulta, ou seja, quanto tempo um usuário esperaria até que suas consultas terminassem (ou que seu painel carregasse). Os resultados são mostrados no gráfico a seguir.
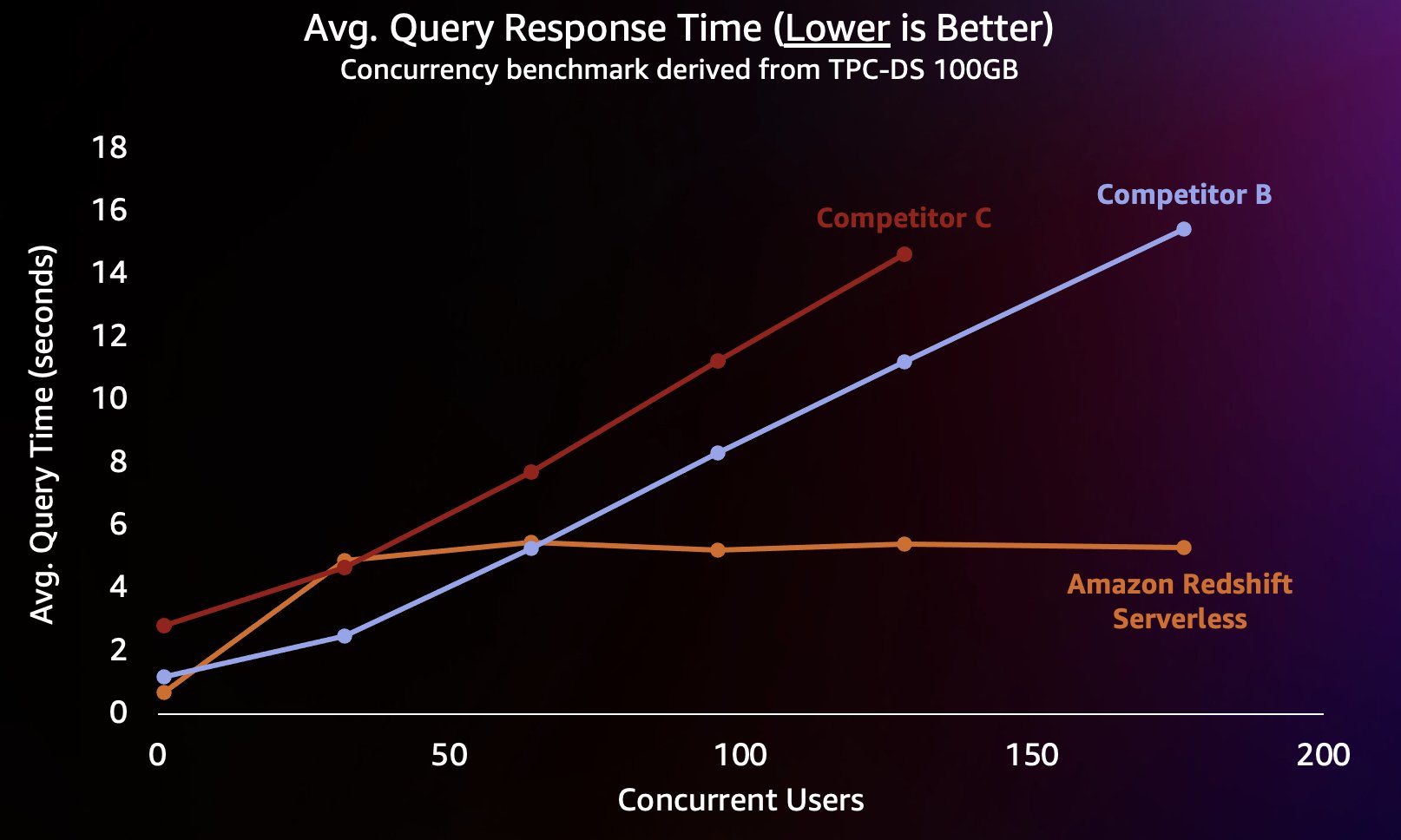
O concorrente B escala bem até cerca de 64 consultas simultâneas, momento em que ele não consegue fornecer computação adicional e as consultas começam a entrar na fila, levando a maiores tempos de resposta de consulta. Embora o concorrente C possa ser dimensionado automaticamente, ele é dimensionado para uma taxa de transferência de consulta mais baixa do que o Amazon Redshift e o concorrente B e não é capaz de manter baixos os tempos de execução da consulta. Além disso, ele não suporta consultas em fila quando fica sem computação, o que o impede de escalar além de cerca de 128 usuários simultâneos. O envio de consultas adicionais além disso é rejeitado pelo sistema.
Aqui, o Redshift Serverless é capaz de manter o tempo de resposta da consulta relativamente consistente em cerca de 5 segundos, mesmo quando centenas de usuários estão executando consultas ao mesmo tempo. Os tempos médios de resposta de consulta para os Concorrentes B e C aumentam constantemente à medida que a carga nos armazéns aumenta, o que faz com que os utilizadores tenham de esperar mais tempo (até 16 segundos) para que as suas consultas retornem quando o armazém de dados está ocupado. Isso significa que se um usuário estiver tentando atualizar um painel (que pode até enviar diversas consultas simultâneas quando recarregado), o Amazon Redshift poderá manter os tempos de carregamento do painel muito mais consistentes, mesmo que o painel esteja sendo carregado por dezenas ou centenas de outros usuários ao mesmo tempo.
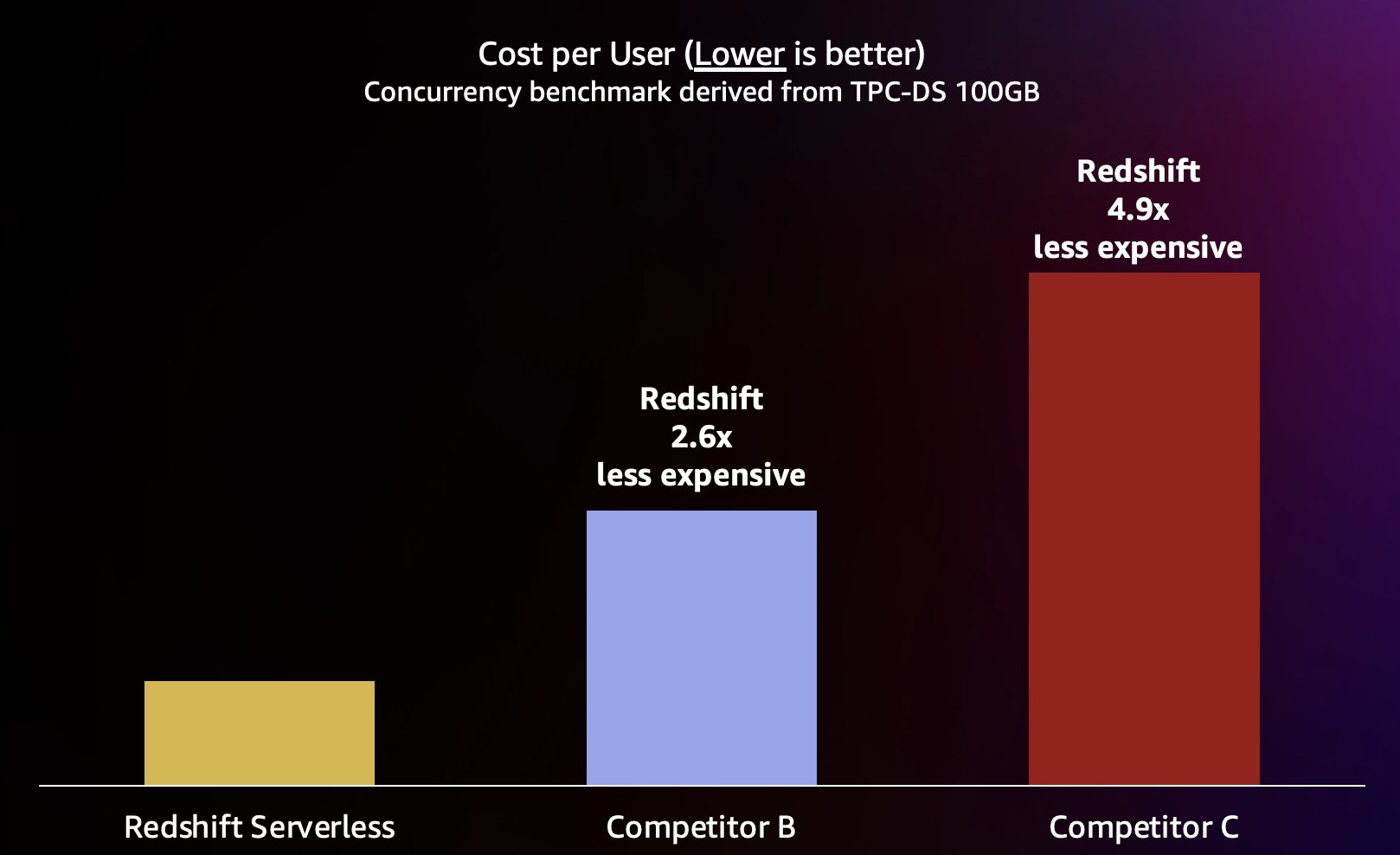
Como o Amazon Redshift é capaz de fornecer uma taxa de transferência de consulta muito alta para consultas curtas (como escrevemos em Amazon Redshift continua sua liderança em preço-desempenho), ele também é capaz de lidar com essas simultaneidades mais altas ao expandir com mais eficiência e, portanto, a um custo significativamente menor. Para quantificar isso, analisamos o preço-desempenho usando dados publicados preços sob demanda para cada um dos armazéns do teste anterior, mostrado no gráfico a seguir. Vale a pena notar que usando Instâncias Reservadas (RIs), especialmente RIs de 3 anos adquiridas com a opção de pagamento antecipado, têm o menor custo para executar o Amazon Redshift em clusters provisionados, resultando no melhor preço-desempenho relativo em comparação com opções de RI sob demanda ou outras opções de RI.

Portanto, o Amazon Redshift não apenas é capaz de oferecer melhor desempenho em simultaneidades mais altas, mas também a um custo significativamente menor. Cada ponto de dados no gráfico de preço-desempenho é equivalente ao custo para executar o benchmark na simultaneidade especificada. Como o preço-desempenho é linear, podemos dividir o custo para executar o benchmark em qualquer simultaneidade pela simultaneidade (número de usuários simultâneos neste gráfico) para nos dizer quanto custa adicionar cada novo usuário para este benchmark específico.
Os resultados anteriores são fáceis de replicar. Todas as consultas usadas no benchmark estão disponíveis em nosso Repositório GitHub e o desempenho é medido iniciando um data warehouse, habilitando o escalonamento de simultaneidade no Amazon Redshift (ou o recurso de escalonamento automático correspondente em outros armazéns), carregando os dados prontos para uso (sem ajuste manual ou configuração específica do banco de dados) e, em seguida, executando um fluxo simultâneo de consultas em simultaneidades de 1 a 200 em etapas de 32 em cada data warehouse. O mesmo repositório GitHub faz referência a dados TPC-DS pré-gerados (e não modificados) em Serviço de armazenamento simples da Amazon (Amazon S3) em diversas escalas usando o kit oficial de geração de dados TPC-DS.
Otimizando cargas de trabalho com muitas strings
Conforme mencionado anteriormente, a equipe do Amazon Redshift está continuamente em busca de novas oportunidades para oferecer uma relação preço-desempenho ainda melhor aos nossos clientes. Uma melhoria que lançamos recentemente e que melhora significativamente o desempenho é uma otimização que acelera o desempenho de consultas em dados de string. Por exemplo, você pode querer encontrar a receita total gerada em lojas de varejo localizadas na cidade de Nova York com uma consulta como SELECT sum(price) FROM sales WHERE city = ‘New York’. Esta consulta está aplicando um predicado sobre dados de string (city = ‘New York’). Como você pode imaginar, o processamento de dados de strings é onipresente em aplicativos de data warehouse.
Para quantificar a frequência com que as cargas de trabalho dos clientes acessam strings, conduzimos uma análise detalhada do uso do tipo de dados de string usando telemetria de frota de dezenas de milhares de clusters de clientes gerenciados pelo Amazon Redshift. Nossa análise indica que em 90% dos clusters, as colunas de string constituem pelo menos 30% de todas as colunas, e em 50% dos clusters, as colunas de string constituem pelo menos 50% de todas as colunas. Além disso, a maioria de todas as consultas executadas na plataforma de data warehouse em nuvem Amazon Redshift acessam pelo menos uma coluna de string. Outro fator importante é que os dados da string costumam ter baixa cardinalidade, o que significa que as colunas contêm um conjunto relativamente pequeno de valores exclusivos. Por exemplo, embora um orders tabela que representa dados de vendas pode conter bilhões de linhas, um order_status coluna dentro dessa tabela pode conter apenas alguns valores exclusivos nesses bilhões de linhas, como pending, in process e completed.
No momento em que este livro foi escrito, a maioria das colunas de string no Amazon Redshift eram compactadas com LZO or ZSTD algoritmos. Esses são bons algoritmos de compactação de uso geral, mas não foram projetados para aproveitar dados de string de baixa cardinalidade. Em particular, eles exigem que os dados sejam descompactados antes de serem operados e são menos eficientes no uso da largura de banda da memória do hardware. Para dados de baixa cardinalidade, existe outro tipo de codificação que pode ser mais ideal: BYTEDICTO. Essa codificação usa um esquema de codificação de dicionário que permite que o mecanismo de banco de dados opere diretamente sobre dados compactados sem a necessidade de descompactá-los primeiro.
Para melhorar ainda mais a relação preço-desempenho para cargas de trabalho com muitas strings, o Amazon Redshift agora está introduzindo melhorias de desempenho adicionais que aceleram verificações e avaliações de predicados, em colunas de string de baixa cardinalidade codificadas como BYTEDICT, entre 5 e 63 vezes mais rápido (veja os resultados em na próxima seção) em comparação com codificações de compactação alternativas, como LZO ou ZSTD. O Amazon Redshift alcança essa melhoria de desempenho vetorizando verificações em colunas de string leves, com uso eficiente de CPU, codificadas em BYTEDICT e de baixa cardinalidade. Essas otimizações de processamento de strings fazem uso eficaz da largura de banda da memória oferecida pelo hardware moderno, permitindo análises em tempo real sobre dados de strings. Esses recursos de desempenho recém-introduzidos são ideais para colunas de cadeia de caracteres de baixa cardinalidade (até algumas centenas de valores de cadeia de caracteres exclusivos).
Você pode se beneficiar automaticamente desse novo aprimoramento de string de alto desempenho ativando otimização automática de mesa no data warehouse do Amazon Redshift. Se você não tiver a otimização automática de tabelas ativada em suas tabelas, poderá receber recomendações do Consultor Amazon Redshift no console do Amazon Redshift sobre a adequação de uma coluna de string para codificação BYTEDICT. Você também pode definir novas tabelas que possuem colunas de cadeia de caracteres de baixa cardinalidade com codificação BYTEDICT. Os aprimoramentos de strings no Amazon Redshift agora estão disponíveis em todas as regiões da AWS onde Amazon Redshift está disponível.
Resultados de desempenho
Para medir o impacto no desempenho de nossas melhorias de string, geramos um conjunto de dados de 10 TB (Tera Byte) que consistia em dados de string de baixa cardinalidade. Geramos três versões dos dados usando strings curtas, médias e longas, correspondendo aos percentis 25, 50 e 75 dos comprimentos de strings da telemetria de frota do Amazon Redshift. Carregamos esses dados no Amazon Redshift duas vezes, codificando-os em um caso usando compactação LZO e em outro usando compactação BYTEDICT. Por fim, medimos o desempenho de consultas com muita varredura que retornam muitas linhas (90% da tabela), um número médio de linhas (50% da tabela) e algumas linhas (1% da tabela) nesses valores baixos. -conjuntos de dados de strings de cardinalidade. Os resultados de desempenho estão resumidos no gráfico a seguir.

Consultas com predicados que correspondem a uma alta porcentagem de linhas tiveram melhorias de 5 a 30 vezes com a nova codificação BYTEDICT vetorizada em comparação com LZO, enquanto consultas com predicados que correspondem a uma baixa porcentagem de linhas tiveram melhorias de 10 a 63 vezes neste benchmark interno.
Preço-desempenho Redshift Serverless
Além dos resultados de desempenho de alta simultaneidade apresentados nesta postagem, também usamos o benchmark Cloud Data Warehouse derivado do TPC-DS para comparar o desempenho de preço do Redshift Serverless com outros data warehouses que usam um conjunto de dados maior de 3 TB. Escolhemos data warehouses com preços semelhantes, neste caso dentro de 10% de US$ 32 por hora, usando preços sob demanda disponíveis publicamente. Esses resultados mostram que, assim como as instâncias RA3 do Amazon Redshift, o Redshift Serverless oferece melhor relação custo-benefício em comparação com outros data warehouses em nuvem líderes. Como sempre, esses resultados podem ser replicados usando nossos scripts SQL em nosso Repositório GitHub.

Incentivamos você a experimentar o Amazon Redshift usando seu próprio prova de conceito cargas de trabalho como a melhor maneira de ver como o Amazon Redshift pode atender às suas necessidades de análise de dados.
Encontre a melhor relação custo-benefício para suas cargas de trabalho
Os benchmarks usados nesta postagem são derivados do benchmark TPC-DS padrão da indústria e possuem as seguintes características:
- O esquema e os dados são usados sem modificações do TPC-DS.
- As consultas são geradas usando o kit TPC-DS oficial com parâmetros de consulta gerados usando a semente aleatória padrão do kit TPC-DS. Variantes de consulta aprovadas por TPC serão usadas para um warehouse se o warehouse não suportar o dialeto SQL da consulta TPC-DS padrão.
- O teste inclui as 99 consultas SELECT do TPC-DS. Não inclui etapas de manutenção e rendimento.
- Para o teste de simultaneidade único de 3 TB, três execuções de energia foram executadas e a melhor execução foi realizada para cada data warehouse.
- O preço-desempenho para as consultas TPC-DS é calculado como o custo por hora (USD) vezes o tempo de execução do benchmark em horas, o que equivale ao custo para executar o benchmark. Os preços sob demanda publicados mais recentemente são usados para todos os data warehouses e não para os preços de instâncias reservadas, conforme observado anteriormente.
Chamamos isso de benchmark Cloud Data Warehouse, e você pode reproduzir facilmente os resultados de benchmark anteriores usando os scripts, consultas e dados disponíveis em nosso Repositório GitHub. É derivado dos benchmarks TPC-DS descritos neste post e, como tal, não é comparável aos resultados publicados do TPC-DS, porque os resultados dos nossos testes não estão em conformidade com as especificações oficiais.
Conclusão
O Amazon Redshift tem o compromisso de oferecer o melhor custo-benefício do setor para a mais ampla variedade de cargas de trabalho. O Redshift Serverless é dimensionado linearmente com o melhor (mais baixo) custo-desempenho, oferecendo suporte a centenas de usuários simultâneos e mantendo tempos de resposta de consulta consistentes. Com base nos resultados dos testes discutidos nesta postagem, o Amazon Redshift tem desempenho de preço até 2.6 vezes melhor no mesmo nível de simultaneidade em comparação com o concorrente mais próximo (concorrente B). Conforme mencionado anteriormente, o uso de instâncias reservadas com a opção totalmente antecipada de 3 anos oferece o menor custo para executar o Amazon Redshift, resultando em um preço-desempenho relativo ainda melhor em comparação com a definição de preço de instância sob demanda que usamos nesta postagem. Nossa abordagem para a melhoria contínua do desempenho envolve uma combinação única de obsessão do cliente para entender os casos de uso do cliente e seus gargalos de escalabilidade associados, juntamente com a análise contínua de dados da frota para identificar oportunidades para fazer otimizações significativas de desempenho.
Cada carga de trabalho tem características únicas, portanto, se você está apenas começando, um prova de conceito é a melhor maneira de entender como o Amazon Redshift pode reduzir seus custos e, ao mesmo tempo, oferecer melhor desempenho. Ao executar sua própria prova de conceito, é importante focar nas métricas corretas: taxa de transferência de consultas (número de consultas por hora), tempo de resposta e preço-desempenho. Você pode tomar uma decisão baseada em dados executando uma prova de conceito por conta própria ou com assistência da AWS ou de um parceiro de integração e consultoria de sistemas.
Para se manter atualizado com os desenvolvimentos mais recentes no Amazon Redshift, siga o O que há de novo no Amazon Redshift alimentar.
Sobre os autores
 Stefan Gromoll é engenheiro de desempenho sênior da equipe Amazon Redshift, onde é responsável por medir e melhorar o desempenho do Redshift. Nas horas vagas, gosta de cozinhar, brincar com os três filhos e cortar lenha.
Stefan Gromoll é engenheiro de desempenho sênior da equipe Amazon Redshift, onde é responsável por medir e melhorar o desempenho do Redshift. Nas horas vagas, gosta de cozinhar, brincar com os três filhos e cortar lenha.
 Ravi Anima é líder sênior de gerenciamento de produtos na equipe Amazon Redshift e gerencia diversas áreas funcionais do serviço de data warehouse em nuvem Amazon Redshift, incluindo desempenho, análise espacial, ingestão de streaming e estratégias de migração. Ele tem experiência com bancos de dados relacionais, bancos de dados multidimensionais, tecnologias IoT, serviços de infraestrutura de armazenamento e computação e, mais recentemente, como fundador de startups usando IA/aprendizado profundo, visão computacional e robótica.
Ravi Anima é líder sênior de gerenciamento de produtos na equipe Amazon Redshift e gerencia diversas áreas funcionais do serviço de data warehouse em nuvem Amazon Redshift, incluindo desempenho, análise espacial, ingestão de streaming e estratégias de migração. Ele tem experiência com bancos de dados relacionais, bancos de dados multidimensionais, tecnologias IoT, serviços de infraestrutura de armazenamento e computação e, mais recentemente, como fundador de startups usando IA/aprendizado profundo, visão computacional e robótica.
 Aamer Xá é engenheiro sênior na equipe do Amazon Redshift Service.
Aamer Xá é engenheiro sênior na equipe do Amazon Redshift Service.
 Sanket Hase é gerente de desenvolvimento de software na equipe do Amazon Redshift Service.
Sanket Hase é gerente de desenvolvimento de software na equipe do Amazon Redshift Service.
 Orestis Polychroniou é engenheiro principal da equipe do Amazon Redshift Service.
Orestis Polychroniou é engenheiro principal da equipe do Amazon Redshift Service.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :tem
- :é
- :não
- :onde
- $UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- Capaz
- Sobre
- acelera
- Acesso
- acessadas
- Alcança
- em
- adicionado
- acrescentando
- Adição
- Adicional
- avançado
- Vantagem
- permitido
- contra
- algoritmos
- Todos os Produtos
- permite
- tb
- alternativa
- alternativas
- Apesar
- sempre
- Amazon
- Amazon Web Services
- quantidade
- an
- análise
- analítica
- análise
- e
- Outro
- qualquer
- aplicações
- Aplicando
- abordagem
- SOMOS
- áreas
- por aí
- AS
- aspecto
- associado
- At
- por WhatsApp.
- auto
- Automatizado
- Automático
- automaticamente
- disponível
- média
- AWS
- b
- Largura de Banda
- baseado
- BE
- Porque
- antes
- começar
- ser
- referência
- benchmarks
- beneficiar
- MELHOR
- Melhor
- entre
- Pós
- bilhões
- ambos
- gargalos
- Caixa
- trazer
- amplo
- negócio
- inteligência de negócios
- ocupado
- mas a
- by
- BOLO
- calculado
- Cálculo
- chamada
- CAN
- capacidades
- casas
- casos
- características
- caracterizado
- de cores
- cortar
- escolheu
- Cidades
- Na nuvem
- Agrupar
- Coluna
- colunas
- combinação
- comprometido
- comum
- comparável
- comparar
- comparado
- comparando
- concorrente
- concorrentes
- integrações
- obedecer
- Computar
- computador
- Visão de Computador
- conceito
- concorrente
- condição
- conduzido
- consistente
- cônsul
- constante
- constantemente
- constituir
- consultor
- não contenho
- continuamente
- continuar
- continua
- contínuo
- continuamente
- cozinha
- Correspondente
- Custo
- custos
- acoplado
- crio
- crucial
- cliente
- Clientes
- painel de instrumentos
- painéis
- dados,
- análise de dados
- Análise de Dados
- informática
- conjunto de dados
- data warehouse
- armazéns de dados
- orientado por dados
- banco de dados
- bases de dados
- conjuntos de dados
- Data
- decisão
- Padrão
- definir
- entregar
- entregando
- entrega
- Derivado
- descrito
- projetado
- desejado
- detalhe
- detalhado
- Desenvolvimento
- desenvolvimentos
- diferente
- diretamente
- discutir
- discutido
- Diversidade
- dividir
- do
- parece
- Não faz
- não
- dirigido
- cada
- Mais cedo
- facilmente
- comer
- Eficaz
- eficiente
- eficientemente
- habilitado
- permitindo
- encorajar
- Motor
- engenheiro
- aprimorada
- aprimoramento
- Melhorias
- Entrar
- Equivalente
- especialmente
- Éter (ETH)
- avaliações
- Mesmo
- tudo
- exemplo
- exemplos
- esperar
- vasta experiência
- extrato
- fator
- familiar
- longe
- RÁPIDO
- mais rápido
- Característica
- poucos
- Finalmente
- Encontre
- acabamento
- Primeiro nome
- ANIMARIS
- Foco
- seguir
- seguinte
- Escolha
- encontrado
- fundador
- da
- funcional
- mais distante
- propósito geral
- gerado
- geração
- ter
- obtendo
- GitHub
- dá
- vai
- Bom estado, com sinais de uso
- Crescente
- Cresce
- manipular
- Hardware
- Ter
- ter
- he
- Alta
- superior
- sua
- segurar
- segurando
- hora
- HORÁRIO
- Como funciona o dobrador de carta de canal
- HTML
- http
- HTTPS
- cem
- Centenas
- ideal
- idealmente
- identificar
- if
- ilustrar
- fotografia
- Impacto
- importante
- aspecto importante
- melhorar
- melhorado
- melhoria
- melhorias
- melhorar
- in
- incluir
- inclui
- Incluindo
- Crescimento
- aumentou
- Aumenta
- indicam
- da indústria
- Infraestrutura
- instância
- instâncias
- integração
- Inteligência
- interativo
- interno
- da intervenção
- para dentro
- introduzido
- introduzindo
- investimento
- envolve
- iot
- IT
- ESTÁ
- juntar
- jpg
- apenas por
- Guarda
- de emergência
- Conhecimento
- grande
- Maior
- mais tarde
- mais recente
- ultimos desenvolvimentos
- lançado
- de lançamento
- líder
- principal
- aprendizagem
- mínimo
- menos
- Nível
- leve
- como
- pequeno
- carregar
- carregamento
- cargas
- localizado
- longo
- mais
- olhar
- procurando
- Baixo
- diminuir
- menor
- a manter
- manutenção
- manutenção
- Maioria
- fazer
- gerenciados
- de grupos
- Gerente
- gestão
- manual
- muitos
- Match
- Matéria
- Posso..
- significado
- significa
- a medida
- medido
- medição
- média
- Conheça
- Memória
- mencionado
- poder
- migração
- minutos
- EQUIPAMENTOS
- Segunda-feira
- dinheiro
- mais
- Além disso
- a maioria
- muito
- nomeadamente
- você merece...
- necessário
- Cria
- Novo
- New York
- Cidade de Nova Iorque
- recentemente
- Próximo
- não
- nota
- notado
- notando
- agora
- número
- of
- oficial
- frequentemente
- on
- Sob demanda
- ONE
- só
- operar
- operado
- oportunidades
- ideal
- otimização
- otimizando
- Opção
- Opções
- or
- Outros
- A Nossa
- Fora
- Acima de
- próprio
- parâmetros
- particular
- padrão
- padrões
- Pagar
- pagamento
- para
- percentagem
- atuação
- planejamento
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- ponto
- Popular
- possível
- Publique
- poder
- Previsível
- apresentado
- impede
- preço
- preços
- Diretor
- processado
- em processamento
- Produto
- gestão de produtos
- prova
- prova de conceito
- fornecer
- publicamente
- publicado
- comprado
- consultas
- rapidamente
- acaso
- Leia
- mundo real
- em tempo real
- receber
- recentemente
- recentemente
- recomendações
- referências
- regiões
- Rejeitado..
- relativo
- relativamente
- removendo
- repetido
- repetitivo
- replicado
- Relatórios
- representante
- representando
- requerer
- reservado
- resposta
- responsável
- resultando
- Resultados
- varejo
- retorno
- receita
- rever
- certo
- robótica
- ROI
- Execute
- corrida
- é executado
- vendas
- mesmo
- Salvar
- serra
- AMPLIAR
- Escala
- Escalas
- dimensionamento
- digitaliza
- esquema
- Scripts
- Segundo
- segundo
- Seção
- Vejo
- semente
- senior
- servir
- Serverless
- serviço
- Serviços
- conjunto
- instalação
- vários
- Partilhar
- Baixo
- rede de apoio social
- mostrar
- mostrando
- periodo
- de forma considerável
- Similarmente
- simples
- simultaneamente
- solteiro
- Tamanho
- de tamanho
- pequeno
- So
- Software
- desenvolvimento de software
- Espacial
- especificação
- especificada
- velocidade
- gastar
- gasto
- espigão
- SQL
- começo
- começado
- inicialização
- ficar
- constantemente
- Passos
- armazenamento
- lojas
- franco
- estratégias
- transmitir canais
- de streaming
- Tanga
- enviar
- tal
- aptidão
- ajuda
- Apoiar
- .
- mesa
- Tire
- tomado
- Profissionais
- técnicas
- Tecnologias
- dizer
- dezenas
- teste
- testes
- do que
- que
- A
- deles
- então
- Lá.
- assim sendo
- Este
- deles
- think
- isto
- aqueles
- milhares
- três
- Taxa de transferência
- tempo
- vezes
- para
- hoje
- Total
- tráfego
- Transformar
- transparentemente
- tentar
- tentando
- Twice
- dois
- tipo
- tipos
- típico
- onipresente
- incapaz
- Incomum
- compreender
- único
- imprevisível
- até
- us
- Uso
- USD
- usar
- caso de uso
- usava
- Utilizador
- usuários
- usos
- utilização
- Valores
- variedade
- vário
- muito
- visualizações
- praticamente
- visão
- esperar
- queremos
- Armazém
- foi
- Caminho..
- maneiras
- we
- web
- serviços web
- semana
- BEM
- foram
- O Quê
- quando
- enquanto que
- qual
- enquanto
- porque
- Largo
- precisarão
- de
- dentro
- sem
- Equivalente há
- seria
- escrita
- escreveu
- Iorque
- Você
- investimentos
- zefirnet