Muitas organizações, pequenas e grandes, estão trabalhando para migrar e modernizar suas cargas de trabalho analíticas na Amazon Web Services (AWS). Há muitos motivos para os clientes migrarem para a AWS, mas um dos principais é a capacidade de usar serviços totalmente gerenciados em vez de gastar tempo mantendo a infraestrutura, aplicação de patches, monitoramento, backups e muito mais. As equipes de liderança e desenvolvimento podem gastar mais tempo otimizando as soluções atuais e até mesmo experimentando novos casos de uso, em vez de manter a infraestrutura atual.
Com a capacidade de avançar rapidamente na AWS, você também precisa ser responsável pelos dados que recebe e processa à medida que continua a escalar. Essas responsabilidades incluem estar em conformidade com as leis e regulamentos de privacidade de dados e não armazenar ou expor dados confidenciais, como informações de identificação pessoal (PII) ou informações de saúde protegidas (PHI) de fontes upstream.
Nesta postagem, abordamos uma arquitetura de alto nível e um caso de uso específico que demonstra como você pode continuar a dimensionar a plataforma de dados da sua organização sem precisar gastar muito tempo de desenvolvimento para resolver questões de privacidade de dados. Nós usamos Cola AWS para detectar, mascarar e redigir dados PII antes de carregá-los no Serviço Amazon OpenSearch.
Visão geral da solução
O diagrama a seguir ilustra a arquitetura da solução de alto nível. Definimos todas as camadas e componentes do nosso design de acordo com o Lente de análise de dados do AWS Well-Architected Framework.
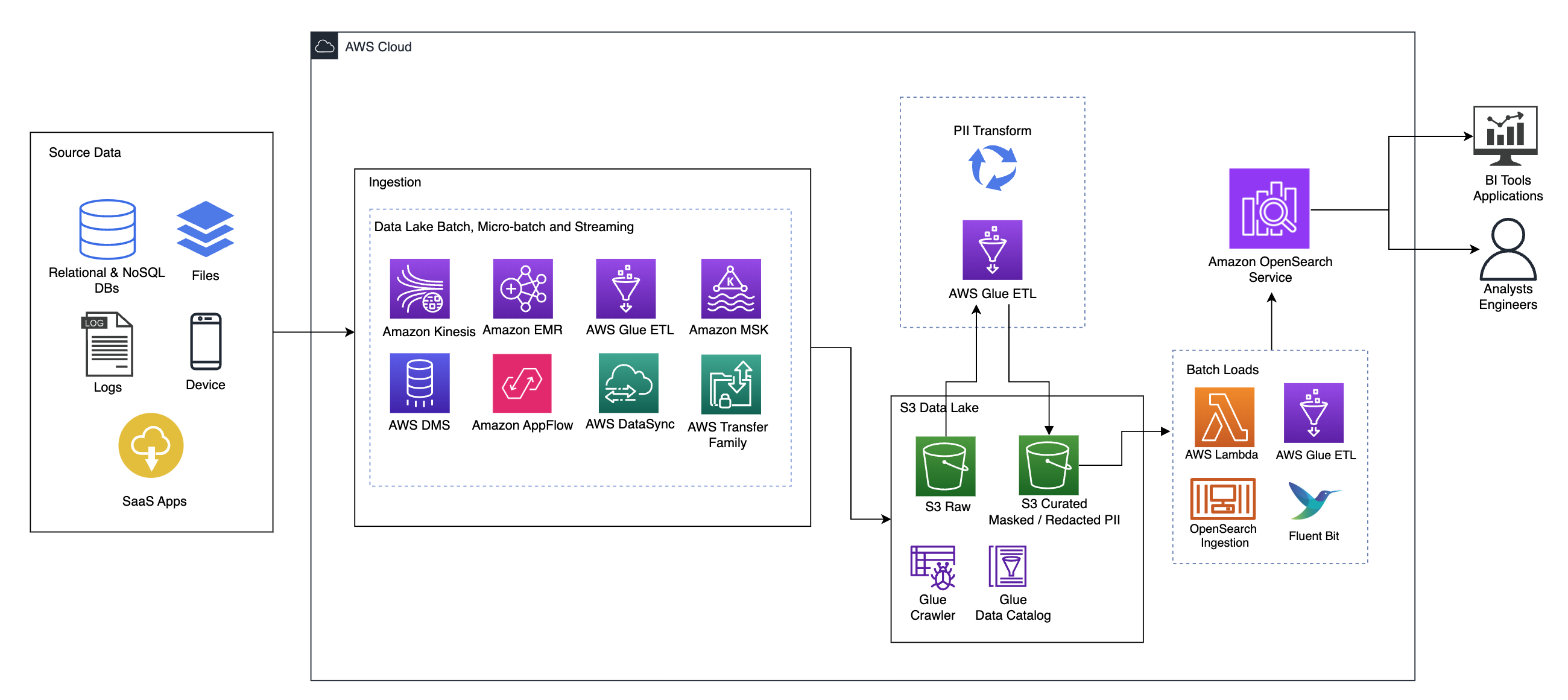
A arquitetura é composta por vários componentes:
Fonte de dados
Os dados podem vir de dezenas a centenas de fontes, incluindo bancos de dados, transferências de arquivos, logs, aplicativos de software como serviço (SaaS) e muito mais. As organizações nem sempre podem ter controle sobre quais dados passam por esses canais e chegam ao armazenamento e aos aplicativos downstream.
Ingestão: lote de data lake, microlote e streaming
Muitas organizações direcionam seus dados de origem para seu data lake de várias maneiras, incluindo trabalhos em lote, microlote e streaming. Por exemplo, Amazon EMR, Cola AWS e Serviço de migração de banco de dados AWS (AWS DMS) podem ser usados para executar operações em lote e/ou streaming que vão para um data lake em Serviço de armazenamento simples da Amazon (Amazônia S3). Fluxo de aplicativos da Amazon pode ser usado para transferir dados de diferentes aplicativos SaaS para um data lake. AWSDataSync e Família AWS Transfer pode ajudar na movimentação de arquivos de e para um data lake por meio de vários protocolos diferentes. Amazon Kinesis e o Amazon MSK também têm recursos para transmitir dados diretamente para um data lake no Amazon S3.
lago de dados S3
Usar o Amazon S3 para seu data lake está alinhado com a estratégia de dados moderna. Ele fornece armazenamento de baixo custo sem sacrificar o desempenho, a confiabilidade ou a disponibilidade. Com essa abordagem, você pode trazer computação para seus dados conforme necessário e pagar apenas pela capacidade necessária para sua execução.
Nesta arquitetura, os dados brutos podem vir de diversas fontes (internas e externas), que podem conter dados confidenciais.
Usando rastreadores do AWS Glue, podemos descobrir e catalogar os dados, que construirão os esquemas de tabela para nós e, em última análise, simplificarão o uso do ETL do AWS Glue com a transformação PII para detectar e mascarar ou redigir quaisquer dados confidenciais que possam ter chegado no lago de dados.
Contexto de negócios e conjuntos de dados
Para demonstrar o valor da nossa abordagem, vamos imaginar que você faz parte de uma equipe de engenharia de dados de uma organização de serviços financeiros. Seus requisitos são detectar e mascarar dados confidenciais à medida que são ingeridos no ambiente de nuvem da sua organização. Os dados serão consumidos por processos analíticos downstream. No futuro, seus usuários poderão pesquisar com segurança o histórico de transações de pagamento com base em fluxos de dados coletados de sistemas bancários internos. Os resultados da pesquisa de equipes de operação, clientes e aplicativos de interface devem ser mascarados em campos confidenciais.
A tabela a seguir mostra a estrutura de dados usada para a solução. Para maior clareza, mapeamos nomes de colunas brutos para selecionados. Você notará que vários campos neste esquema são considerados dados confidenciais, como nome, sobrenome, número do Seguro Social (SSN), endereço, número do cartão de crédito, número de telefone, e-mail e endereço IPv4.
| Nome da coluna bruta | Nome da coluna selecionada | Formato |
| c0 | primeiro nome | corda |
| c1 | último nome | corda |
| c2 | ssn | corda |
| c3 | endereço | corda |
| c4 | código postal | corda |
| c5 | país | corda |
| c6 | site_de_compra | corda |
| c7 | Número do cartão de crédito | corda |
| c8 | provedor_de_cartão_de_crédito | corda |
| c9 | moeda | corda |
| c10 | valor de compra | número inteiro |
| c11 | data_da_transação | dados |
| c12 | número de telefone | corda |
| c13 | corda | |
| c14 | ipv4 | corda |
Caso de uso: detecção de lote de PII antes de carregar no OpenSearch Service
Os clientes que implementam a arquitetura a seguir criaram seu data lake no Amazon S3 para executar diferentes tipos de análises em escala. Esta solução é adequada para clientes que não precisam de ingestão em tempo real no OpenSearch Service e planejam usar ferramentas de integração de dados que são executadas de acordo com uma programação ou acionadas por meio de eventos.
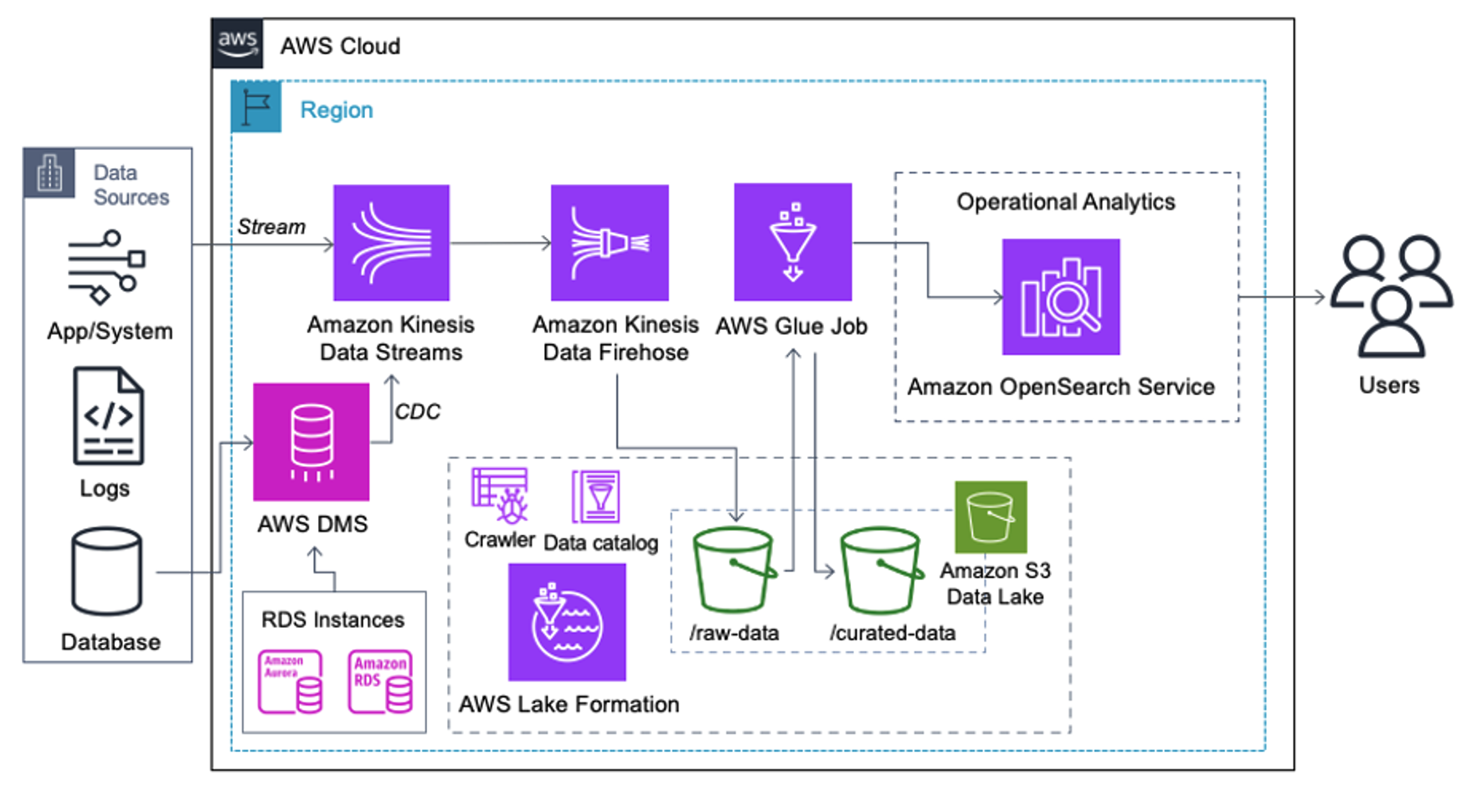
Antes que os registros de dados cheguem ao Amazon S3, implementamos uma camada de ingestão para levar todos os fluxos de dados de maneira confiável e segura ao data lake. O Kinesis Data Streams é implantado como uma camada de ingestão para ingestão acelerada de fluxos de dados estruturados e semiestruturados. Exemplos disso são alterações em bancos de dados relacionais, aplicativos, logs do sistema ou fluxos de cliques. Para casos de uso de change data capture (CDC), você pode usar o Kinesis Data Streams como destino para o AWS DMS. Aplicativos ou sistemas que geram streams contendo dados confidenciais são enviados ao stream de dados do Kinesis por meio de um dos três métodos compatíveis: o Amazon Kinesis Agent, o AWS SDK for Java ou a Kinesis Producer Library. Como último passo, Mangueira de incêndio de dados do Amazon Kinesis nos ajuda a carregar lotes de dados quase em tempo real de maneira confiável em nosso destino de data lake S3.
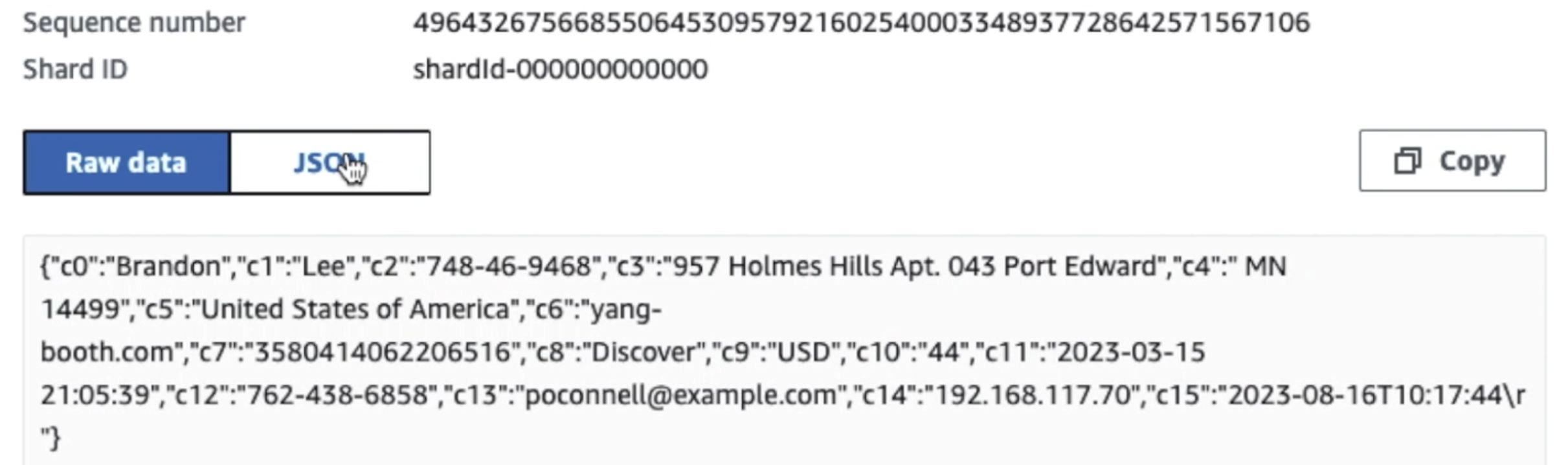
A captura de tela a seguir mostra como os dados fluem pelo Kinesis Data Streams por meio do Visualizador de dados e recupera dados de amostra que chegam ao prefixo S3 bruto. Para esta arquitetura, seguimos o ciclo de vida dos dados para prefixos S3 conforme recomendado em Fundação de data lake.
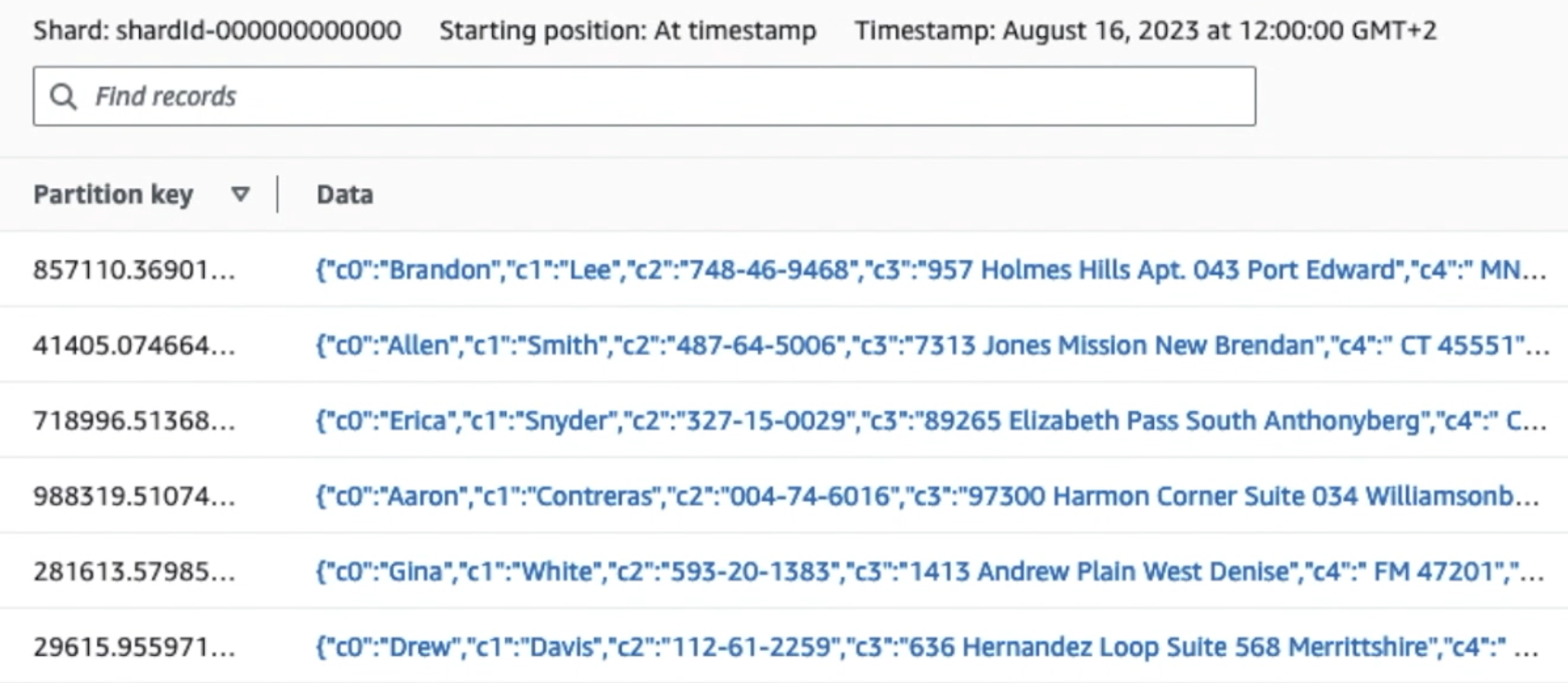
Como você pode ver nos detalhes do primeiro registro na captura de tela a seguir, a carga JSON segue o mesmo esquema da seção anterior. Você pode ver os dados não editados fluindo para o fluxo de dados do Kinesis, que será ofuscado posteriormente em estágios subsequentes.
Depois que os dados são coletados e ingeridos no Kinesis Data Streams e entregues ao bucket S3 usando o Kinesis Data Firehose, a camada de processamento da arquitetura assume o controle. Usamos a transformação AWS Glue PII para automatizar a detecção e o mascaramento de dados confidenciais em nosso pipeline. Conforme mostrado no diagrama de fluxo de trabalho a seguir, adotamos uma abordagem de ETL visual sem código para implementar nosso trabalho de transformação no AWS Glue Studio.
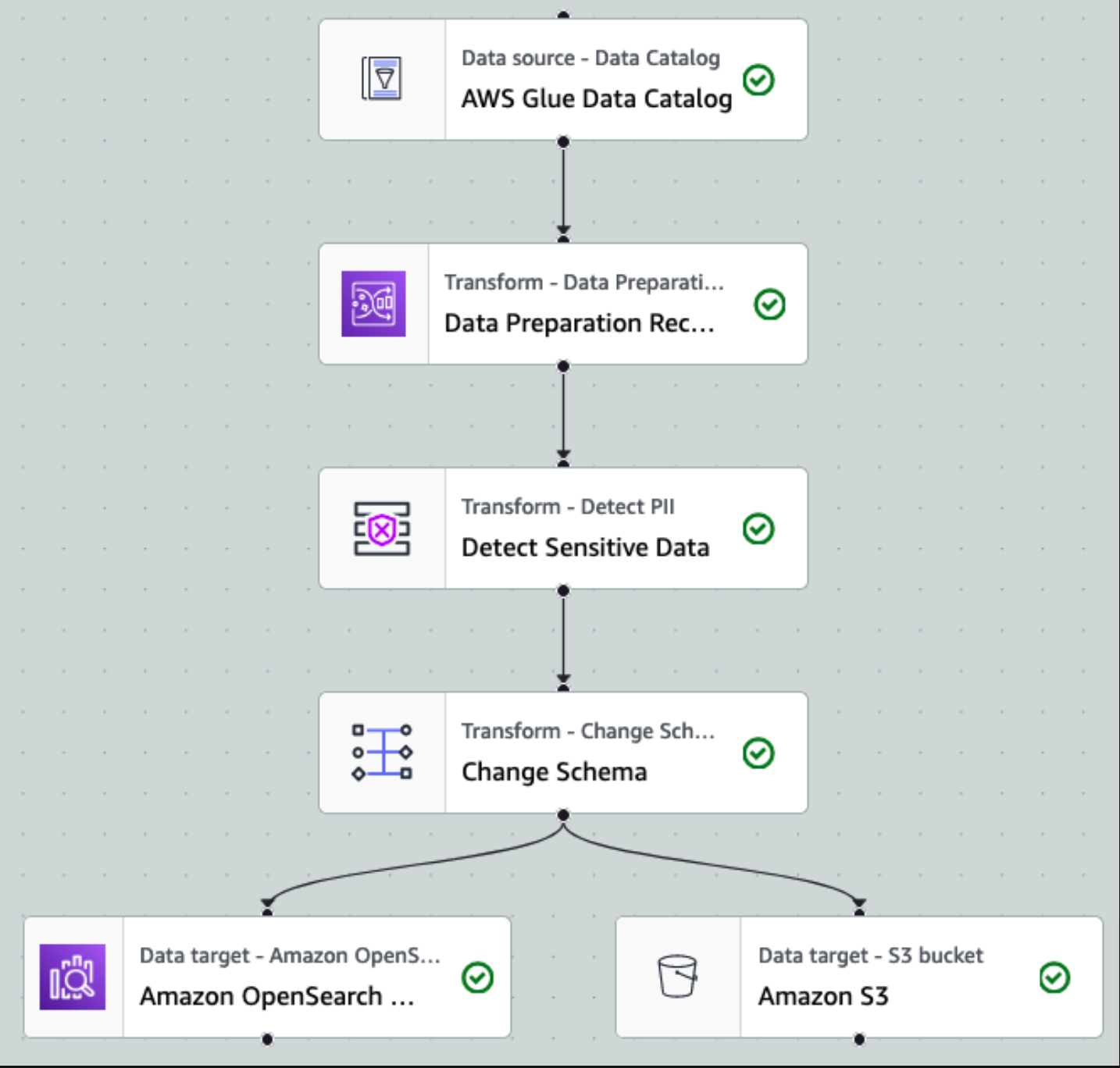
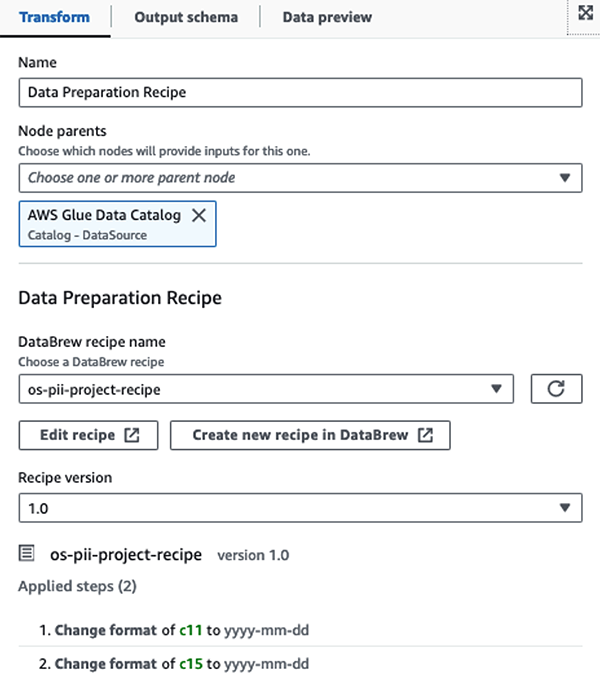
Primeiro, acessamos a tabela de origem do Catálogo de Dados bruta a partir do pii_data_db base de dados. A tabela possui a estrutura do esquema apresentada na seção anterior. Para acompanhar os dados brutos processados, usamos marcadores de trabalho.

Usamos o Receitas do AWS Glue DataBrew no trabalho de ETL visual do AWS Glue Studio para transformar dois atributos de data para serem compatíveis com o OpenSearch esperado formatos. Isso nos permite ter uma experiência completa sem código.
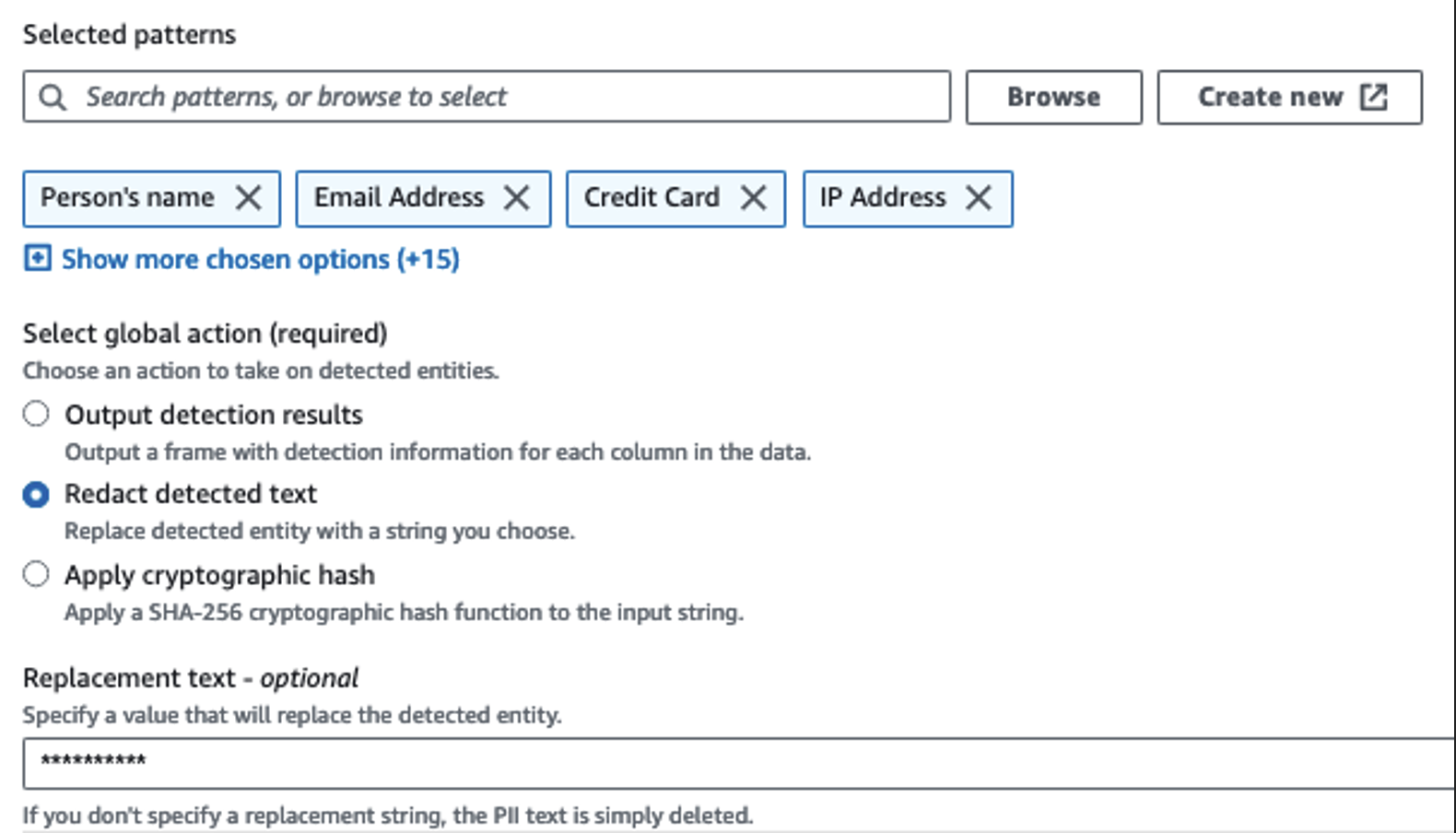
Usamos a ação Detectar PII para identificar colunas confidenciais. Permitimos que o AWS Glue determine isso com base nos padrões selecionados, no limite de detecção e na porção de amostra das linhas do conjunto de dados. Em nosso exemplo, usamos padrões que se aplicam especificamente aos Estados Unidos (como SSNs) e podem não detectar dados confidenciais de outros países. Você pode procurar categorias e locais disponíveis aplicáveis ao seu caso de uso ou usar expressões regulares (regex) no AWS Glue para criar entidades de detecção para dados confidenciais de outros países.
É importante selecionar o método de amostragem correto oferecido pelo AWS Glue. Neste exemplo, sabe-se que os dados provenientes do fluxo possuem dados confidenciais em todas as linhas, portanto, não é necessário amostrar 100% das linhas no conjunto de dados. Se você tiver um requisito em que nenhum dado confidencial seja permitido para fontes downstream, considere amostrar 100% dos dados para os padrões escolhidos ou verifique todo o conjunto de dados e atue em cada célula individual para garantir que todos os dados confidenciais sejam detectados. O benefício que você obtém com a amostragem é a redução de custos porque você não precisa digitalizar tantos dados.

A ação Detectar PII permite selecionar uma string padrão ao mascarar dados confidenciais. Em nosso exemplo, usamos a string **********.
Usamos a operação de mapeamento de aplicação para renomear e remover colunas desnecessárias, como ingestion_year, ingestion_month e ingestion_day. Esta etapa também nos permite alterar o tipo de dados de uma das colunas (purchase_value) de string para inteiro.

Deste ponto em diante, o trabalho se divide em dois destinos de saída: OpenSearch Service e Amazon S3.
Nosso cluster do OpenSearch Service provisionado está conectado por meio do Conector integrado OpenSearch para Glue. Especificamos o índice OpenSearch no qual gostaríamos de gravar e o conector trata das credenciais, domínio e porta. Na captura de tela abaixo, escrevemos no índice especificado index_os_pii.
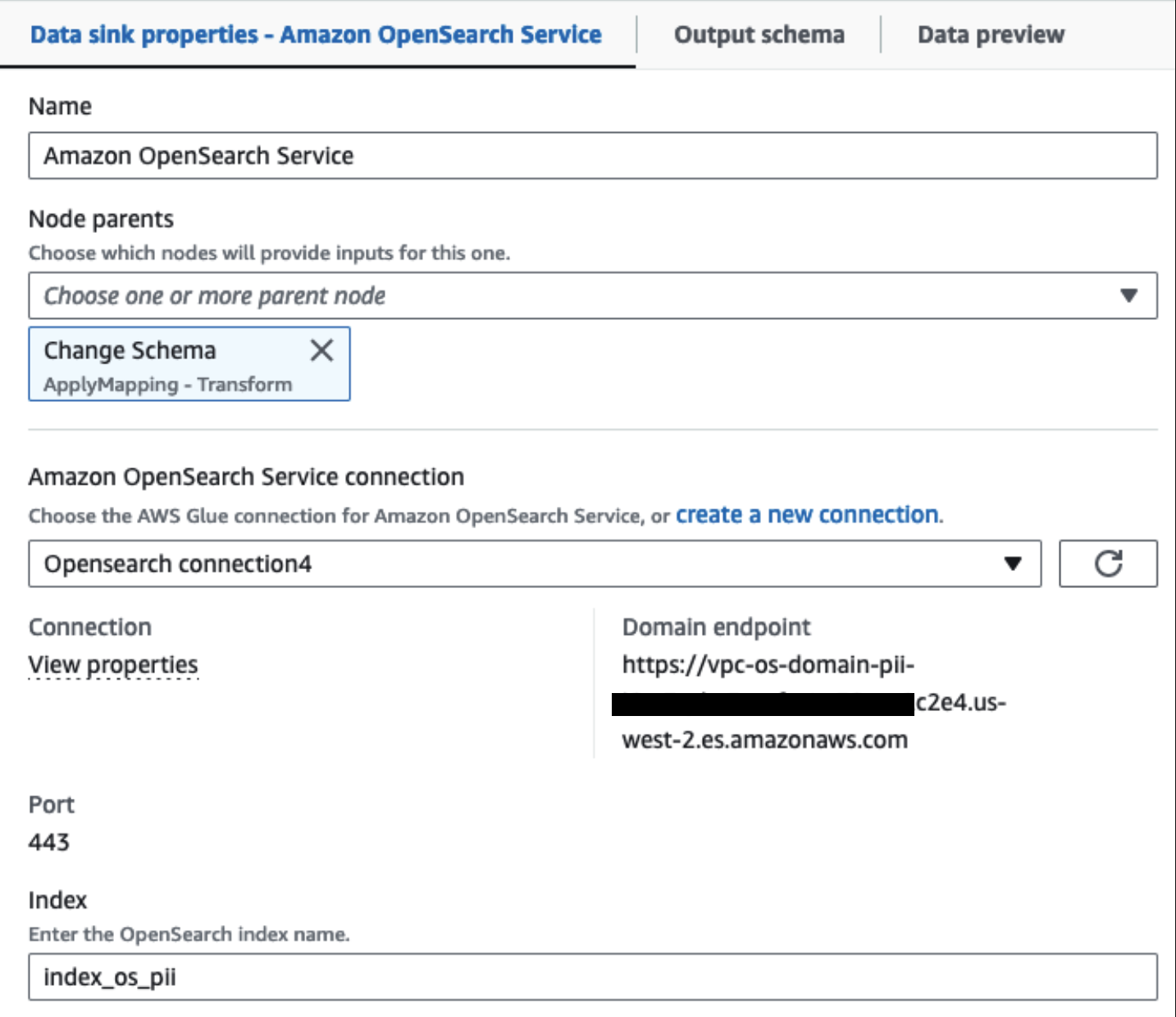
Armazenamos o conjunto de dados mascarado no prefixo S3 selecionado. Lá, temos dados normalizados para um caso de uso específico e consumo seguro por cientistas de dados ou para necessidades de relatórios ad hoc.
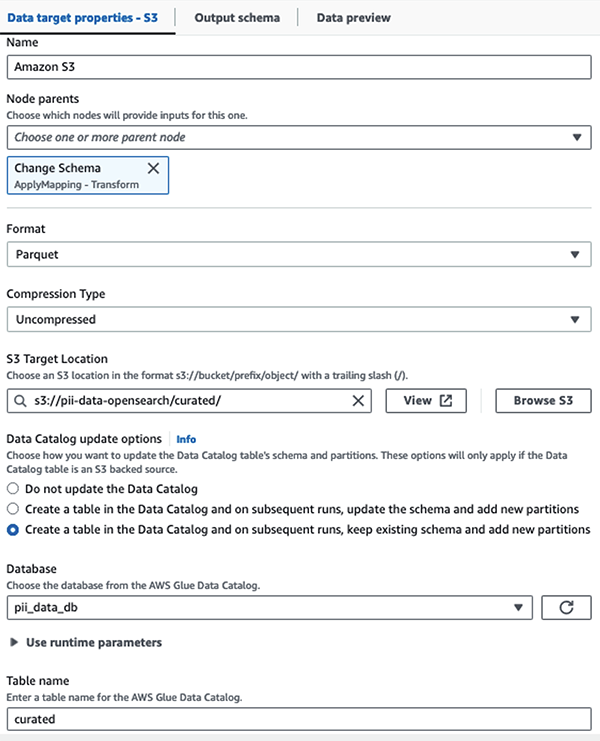
Para governança unificada, controle de acesso e trilhas de auditoria de todos os conjuntos de dados e tabelas do Data Catalog, você pode usar Formação AWS Lake. Isso ajuda a restringir o acesso às tabelas do AWS Glue Data Catalog e aos dados subjacentes apenas aos usuários e funções que receberam as permissões necessárias para fazer isso.
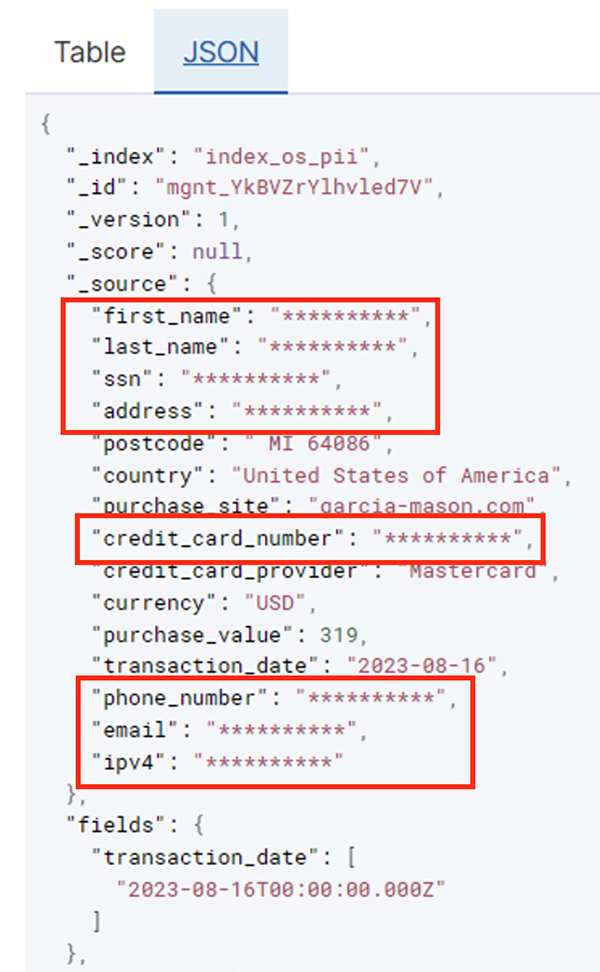
Após a execução bem-sucedida da tarefa em lote, você poderá usar o OpenSearch Service para executar consultas de pesquisa ou relatórios. Conforme mostrado na captura de tela a seguir, o pipeline mascarou campos confidenciais automaticamente, sem esforços de desenvolvimento de código.

Você pode identificar tendências a partir dos dados operacionais, como a quantidade de transações por dia filtradas pela operadora do cartão de crédito, conforme mostrado na captura de tela anterior. Você também pode determinar os locais e domínios onde os usuários fazem compras. O transaction_date atributo nos ajuda a ver essas tendências ao longo do tempo. A captura de tela a seguir mostra um registro com todas as informações da transação redigidas de forma adequada.
Para obter métodos alternativos sobre como carregar dados no Amazon OpenSearch, consulte Carregar dados de streaming no Amazon OpenSearch Service.
Além disso, dados confidenciais também podem ser descobertos e mascarados usando outras soluções da AWS. Por exemplo, você poderia usar Amazon Macie para detectar dados confidenciais dentro de um bucket S3 e, em seguida, usar Amazon Comprehend para redigir os dados confidenciais que foram detectados. Para obter mais informações, consulte Técnicas comuns para detectar dados PHI e PII usando serviços da AWS.
Conclusão
Esta postagem discutiu a importância de lidar com dados confidenciais em seu ambiente e vários métodos e arquiteturas para permanecer em conformidade e, ao mesmo tempo, permitir que sua organização cresça rapidamente. Agora você deve ter um bom entendimento de como detectar, mascarar ou editar e carregar seus dados no Amazon OpenSearch Service.
Sobre os autores
 Michael Hamilton é arquiteto sênior de soluções analíticas com foco em ajudar clientes corporativos a modernizar e simplificar suas cargas de trabalho analíticas na AWS. Ele gosta de praticar mountain bike e de passar o tempo com a esposa e os três filhos quando não está trabalhando.
Michael Hamilton é arquiteto sênior de soluções analíticas com foco em ajudar clientes corporativos a modernizar e simplificar suas cargas de trabalho analíticas na AWS. Ele gosta de praticar mountain bike e de passar o tempo com a esposa e os três filhos quando não está trabalhando.
 Daniel Rozo é arquiteto de soluções sênior da AWS, oferecendo suporte a clientes na Holanda. Sua paixão é projetar soluções simples de dados e análises e ajudar os clientes a migrar para arquiteturas de dados modernas. Fora do trabalho, ele gosta de jogar tênis e andar de bicicleta.
Daniel Rozo é arquiteto de soluções sênior da AWS, oferecendo suporte a clientes na Holanda. Sua paixão é projetar soluções simples de dados e análises e ajudar os clientes a migrar para arquiteturas de dados modernas. Fora do trabalho, ele gosta de jogar tênis e andar de bicicleta.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :tem
- :é
- :não
- :onde
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- habilidade
- Capaz
- acelerado
- Acesso
- Aja
- Açao Social
- Ad
- endereço
- Agente
- Todos os Produtos
- permitidas
- Permitindo
- permite
- tb
- sempre
- Amazon
- Amazon Kinesis
- Amazon Web Services
- Amazon Web Services (AWS)
- quantidade
- quantidades
- an
- Análises
- analítica
- e
- qualquer
- relevante
- aplicações
- Aplicar
- abordagem
- adequadamente
- arquitetura
- SOMOS
- AS
- At
- atributos
- auditor
- automatizar
- automaticamente
- disponibilidade
- disponível
- AWS
- Cola AWS
- backups
- Bancário
- Sistemas bancários
- baseado
- BE
- Porque
- sido
- antes
- ser
- abaixo
- beneficiar
- trazer
- construir
- construído
- construídas em
- mas a
- by
- CAN
- capacidades
- Capacidade
- capturar
- cartão
- casas
- casos
- catálogo
- Categorias
- CDC
- célula
- alterar
- Alterações
- canais
- Crianças
- escolheu
- clareza
- Na nuvem
- Agrupar
- código
- Coluna
- colunas
- como
- vem
- vinda
- compatível
- compatível
- componentes
- Composto
- Computar
- Preocupações
- conectado
- Considerar
- considerado
- consumida
- consumo
- não contenho
- contexto
- continuar
- ao controle
- correta
- custos
- poderia
- países
- crio
- Credenciais
- crédito
- cartão de crédito
- comissariada
- Atual
- Clientes
- dados,
- Análise de Dados
- integração de dados
- lago data
- Plataforma de dados
- privacidade de dados
- estratégia de dados
- banco de dados
- bases de dados
- conjuntos de dados
- Data
- dia
- Padrão
- definido
- entregue
- demonstrar
- demonstra
- implantado
- Design
- destino
- destinos
- detalhes
- descobrir
- detectou
- Detecção
- Determinar
- Desenvolvimento
- equipes de desenvolvimento
- diferente
- diretamente
- descobrir
- descoberto
- discutido
- do
- domínio
- domínios
- não
- cada
- esforços
- Engenharia
- garantir
- Empreendimento
- clientes corporativos
- Todo
- entidades
- Meio Ambiente
- Éter (ETH)
- Mesmo
- eventos
- Cada
- exemplo
- exemplos
- esperado
- vasta experiência
- expressões
- externo
- RÁPIDO
- Campos
- Envie o
- Arquivos
- financeiro
- serviços financeiros
- Primeiro nome
- Fluindo
- Fluxos
- focando
- seguido
- seguinte
- segue
- Escolha
- Quadro
- da
- cheio
- totalmente
- futuro
- gerando
- ter
- Bom estado, com sinais de uso
- governo
- concedido
- Alças
- Manipulação
- Ter
- he
- Saúde
- informação de saúde
- ajudar
- ajuda
- ajuda
- de alto nível
- sua
- histórico
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- Centenas
- identificar
- if
- ilustra
- fotografia
- executar
- importância
- importante
- in
- incluir
- Incluindo
- índice
- Individual
- INFORMAÇÕES
- Infraestrutura
- dentro
- integração
- interno
- para dentro
- IT
- Java
- Trabalho
- Empregos
- jpg
- json
- Guarda
- Mangueira de dados Kinesis
- Streams de dados Kinesis
- conhecido
- lago
- Terreno
- Terras
- grande
- Sobrenome
- mais tarde
- Leis
- Leis e regulamentos
- camada
- camadas
- Liderança
- deixar
- Biblioteca
- wifecycwe
- como
- Line
- carregar
- carregamento
- locais
- olhar
- baixo custo
- a Principal
- manutenção
- fazer
- gerenciados
- muitos
- mapeamento
- máscara
- Posso..
- método
- métodos
- migrado
- migração
- EQUIPAMENTOS
- modernizar
- monitoração
- mais
- Montanha
- mover
- em movimento
- muito
- múltiplo
- devo
- nome
- nomes
- necessário
- você merece...
- necessário
- necessitando
- Cria
- Nederland
- Novo
- não
- nós
- Perceber..
- agora
- número
- of
- Oferece
- on
- ONE
- só
- operação
- operacional
- Operações
- otimizando
- Opções
- or
- organização
- organizações
- Outros
- A Nossa
- saída
- lado de fora
- Acima de
- parte
- paixão
- Patching
- padrões
- Pagar
- pagamento
- para
- realizar
- atuação
- permissões
- Pessoalmente
- telefone
- Pii
- oleoduto
- plano
- plataforma
- platão
- Inteligência de Dados Platão
- PlatãoData
- jogar
- ponto
- parte
- Publique
- precedente
- apresentado
- anterior
- política de privacidade
- leis de privacidade
- processado
- processos
- em processamento
- produtor
- protegido
- protocolos
- provedor
- fornece
- compras
- consultas
- rapidamente
- em vez
- Cru
- dados não tratados
- em tempo real
- razões
- receber
- Receitas
- Recomenda
- registro
- registros
- Reduzido
- referir
- regular
- regulamentos
- confiabilidade
- permanecem
- remover
- Relatórios
- Relatórios
- requerer
- requerimento
- Requisitos
- responsabilidades
- responsável
- restringir
- Resultados
- papéis
- LINHA
- Execute
- é executado
- SaaS
- sacrificando
- seguro
- seguramente
- mesmo
- Escala
- digitalização
- cronograma
- cientistas
- Peneira
- Sdk
- Pesquisar
- Seção
- firmemente
- segurança
- Vejo
- selecionar
- selecionado
- senior
- sensível
- enviei
- serviço
- Serviços
- tiro
- rede de apoio social
- mostrando
- Shows
- simples
- simplificar
- pequeno
- So
- Redes Sociais
- Software
- software como serviço
- solução
- Soluções
- fonte
- Fontes
- específico
- especificamente
- especificada
- gastar
- Passar
- splits
- Estágio
- Unidos
- Passo
- armazenamento
- loja
- franco
- Estratégia
- transmitir canais
- de streaming
- córregos
- Tanga
- estrutura
- estruturada
- estudo
- subseqüente
- entraram com sucesso
- tal
- adequado
- Suportado
- Apoiar
- .
- sistemas
- mesa
- toma
- Target
- Profissionais
- equipes
- técnicas
- tênis
- dezenas
- do que
- que
- A
- O Futuro
- Países Baixos
- A fonte
- deles
- então
- Lá.
- Este
- isto
- aqueles
- três
- limiar
- Através da
- tempo
- para
- levou
- ferramentas
- pista
- Transações
- transferência
- fáceis
- Transformar
- Transformação
- Tendências
- desencadeado
- dois
- tipo
- tipos
- Em última análise
- subjacente
- compreensão
- unificado
- Unido
- Estados Unidos
- us
- usar
- caso de uso
- usava
- usuários
- utilização
- valor
- variedade
- vário
- via
- visual
- andar
- foi
- maneiras
- we
- web
- serviços web
- O Quê
- quando
- qual
- enquanto
- QUEM
- mulher
- precisarão
- de
- dentro
- sem
- Atividades:
- de gestão de documentos
- trabalhar
- escrever
- Você
- investimentos
- zefirnet