Os clientes de serviços financeiros estão usando dados de diferentes fontes originados em frequências diferentes, o que inclui conjuntos de dados em tempo real, em lote e arquivados. Além disso, necessitam de arquiteturas de streaming para lidar com os crescentes volumes de comércio, a volatilidade do mercado e as exigências regulamentares. A seguir estão alguns dos principais casos de uso de negócios que destacam essa necessidade:
- Relatórios comerciais – Desde a crise financeira global de 2007-2008, os reguladores aumentaram as suas exigências e o escrutínio dos relatórios regulamentares. Os reguladores colocaram um foco maior na proteção do consumidor através de relatórios de transações (normalmente T+1, ou seja, 1 dia útil após a data da negociação) e no aumento da transparência nos mercados através de requisitos de relatórios comerciais quase em tempo real.
- Gestão de riscos – À medida que os mercados de capitais se tornam mais complexos e os reguladores lançam novos quadros de risco, tais como Revisão Fundamental da Carteira de Negociação (FRTB) e Basileia III, as instituições financeiras procuram aumentar a frequência dos cálculos do risco global de mercado, do risco de liquidez, do risco de contraparte e de outras medições de risco, e pretendem aproximar-se tanto quanto possível dos cálculos em tempo real.
- Qualidade e otimização comercial – Para monitorar e otimizar a qualidade da negociação, você precisa avaliar continuamente as características do mercado, como volume, direção, profundidade do mercado, taxa de preenchimento e outros parâmetros de referência relacionados à conclusão das negociações. A qualidade do comércio não está apenas relacionada ao desempenho do corretor, mas também é uma exigência dos reguladores, começando com MIFID II.
O desafio é encontrar uma solução que possa lidar com essas fontes distintas, frequências variadas e requisitos de consumo de baixa latência. A solução deve ser escalonável, econômica e simples de adotar e operar. Amazon RedShift recursos como ingestão de streaming, Aurora Amazônica integração zero-ETLe compartilhamento de dados com Troca de dados da AWS permitem o processamento quase em tempo real para relatórios comerciais, gerenciamento de risco e otimização comercial.
Nesta postagem, fornecemos uma arquitetura de solução que descreve como você pode processar dados de três tipos diferentes de fontes (dados de streaming, transacionais e de referência de terceiros) e agregá-los no Amazon Redshift para relatórios de business intelligence (BI).
Visão geral da solução
Esta arquitetura de solução é criada priorizando uma abordagem low-code/no-code com os seguintes princípios orientadores:
- FÁCIL DE USAR – Deve ser menos complexo de implementar e operar com interfaces de usuário intuitivas
- Escalável – Você deve ser capaz de aumentar e diminuir continuamente a capacidade sob demanda
- Integração nativa – Os componentes devem ser integrados sem conectores ou software adicionais
- Custo benefício – Deve oferecer preço/desempenho equilibrado
- Baixa manutenção – Deve exigir menos sobrecarga de gerenciamento e operacional
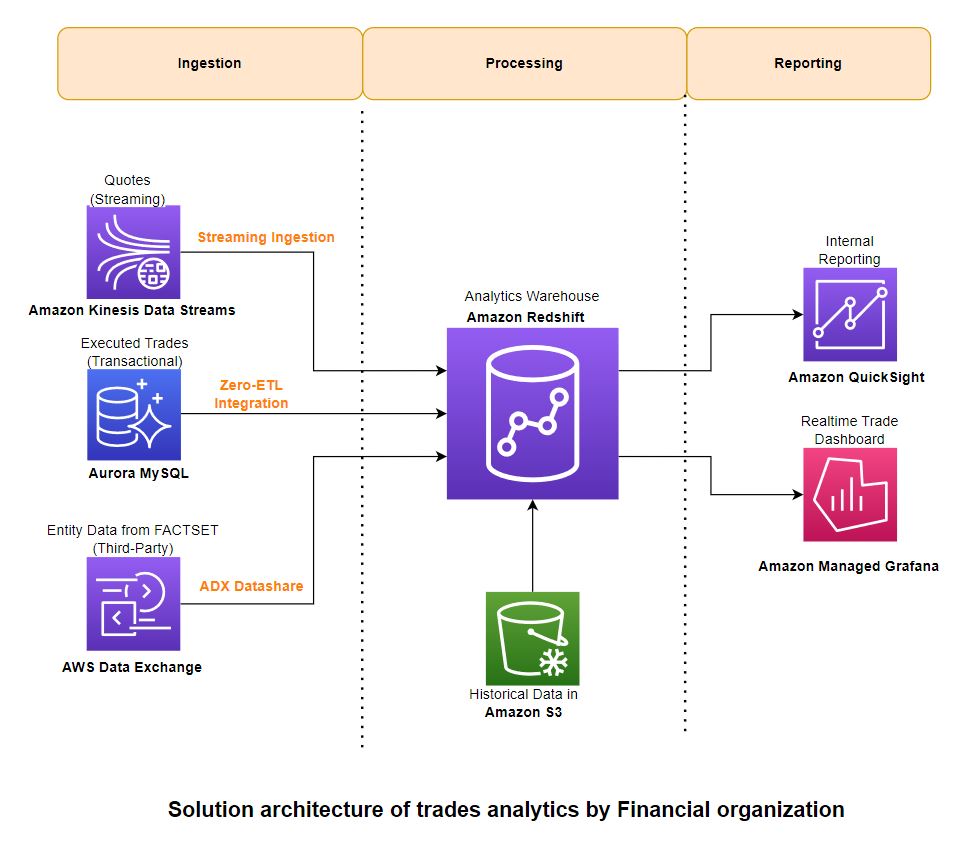
O diagrama a seguir ilustra a arquitetura da solução e como esses princípios orientadores foram aplicados aos componentes de ingestão, agregação e relatório.
![]()
Implante a solução
Você pode usar o seguinte Formação da Nuvem AWS modelo para implantar a solução.
![]()
Esta pilha cria os seguintes recursos e permissões necessárias para integrar os serviços:
Ingestão
Para ingerir dados, você usa Ingestão de streaming do Amazon Redshift para carregar dados de streaming do fluxo de dados do Kinesis. Para dados transacionais, você usa o Integração Redshift zero-ETL com Amazon Aurora MySQL. Para dados de referência de terceiros, você aproveita Compartilhamentos de dados do AWS Data Exchange. Esses recursos permitem que você crie pipelines de dados escalonáveis rapidamente, pois é possível aumentar a capacidade dos fragmentos do Kinesis Data Streams, calcular fontes e destinos com ETL zero e calcular o Redshift para compartilhamentos de dados quando seus dados crescem. A ingestão de streaming do Redshift e a integração zero-ETL são soluções de baixo código/sem código que você pode construir com SQLs simples sem investir tempo e dinheiro significativos no desenvolvimento de código personalizado complexo.
Para os dados usados para criar esta solução, fizemos parceria com FactSet, um fornecedor líder de dados financeiros, análises e tecnologia aberta. FactSet tem vários conjuntos de dados disponível no mercado AWS Data Exchange, que usamos para dados de referência. Também usamos o FactSet soluções de dados de mercado para cotações e negociações históricas e de streaming de mercado.
Tratamento
Os dados são processados no Amazon Redshift seguindo uma metodologia de extração, carregamento e transformação (ELT). Com escala virtualmente ilimitada e isolamento de carga de trabalho, o ELT é mais adequado para soluções de data warehouse em nuvem.
Você usa a ingestão de streaming do Redshift para ingestão em tempo real de cotações de streaming (bid/ask) do fluxo de dados do Kinesis diretamente em uma visualização materializada de streaming e processa os dados na próxima etapa usando PartiQL para analisar as entradas do fluxo de dados. Observe que o streaming de visualizações materializadas difere das visualizações materializadas regulares em termos de como a atualização automática funciona e dos comandos SQL de gerenciamento de dados usados. Referir-se Considerações sobre ingestão de streaming para obter detalhes.
Você usa a integração Aurora sem ETL para ingerir dados transacionais (negociações) de fontes OLTP. Referir-se Trabalhando com integrações zero-ETL para fontes atualmente suportadas. Você pode combinar dados de todas essas fontes usando visualizações e procedimentos armazenados para implementar regras de transformação de negócios, como calcular médias ponderadas entre setores e bolsas.
Os volumes históricos de transações e cotações são enormes e muitas vezes não são consultados com frequência. Você pode usar Espectro Amazon Redshift para acessar esses dados sem carregá-los no Amazon Redshift. Você cria tabelas externas apontando para dados em Serviço de armazenamento simples da Amazon (Amazon S3) e consulte de forma semelhante à consulta de qualquer outra tabela local no Amazon Redshift. Vários data warehouses do Redshift podem consultar simultaneamente os mesmos conjuntos de dados no Amazon S3 sem a necessidade de fazer cópias dos dados para cada data warehouse. Esse recurso simplifica o acesso a dados externos sem escrever processos ETL complexos e aumenta a facilidade de uso da solução geral.
Vamos revisar alguns exemplos de consultas usadas para analisar cotações e negociações. Usamos as seguintes tabelas nas consultas de exemplo:
- dt_hist_quote – Dados históricos de cotações contendo preço e volume de oferta, preço e volume de venda e bolsas e setores. Você deve usar conjuntos de dados relevantes em sua organização que contenham esses atributos de dados.
- dt_hist_trades – Dados históricos de negociações contendo preço negociado, volume, setor e detalhes de câmbio. Você deve usar conjuntos de dados relevantes em sua organização que contenham esses atributos de dados.
- factset_sector_map – Mapeamento entre setores e bolsas. Você pode obter isso no Conjunto de dados ADX do FactSet Fundamentals.
Exemplo de consulta para análise de cotações históricas
Você pode usar a seguinte consulta para encontrar spreads médios ponderados nas cotações:
Exemplo de consulta para análise de negociações históricas
Você pode usar a seguinte consulta para encontrar $-volume em negociações por bolsa detalhada, por setor e por bolsa principal (NYSE e Nasdaq):
Relatórios
Você pode usar AmazonQuickSight e Grafana gerenciada pela Amazon para BI e relatórios em tempo real, respectivamente. Esses serviços integram-se nativamente ao Amazon Redshift sem a necessidade de usar conectores ou software adicionais entre eles.
Você pode executar uma consulta direta do QuickSight para relatórios e painéis de BI. Com o QuickSight, você também pode armazenar dados localmente no cache SPICE com atualização automática para baixa latência. Referir-se Autorização de conexões do Amazon QuickSight para clusters do Amazon Redshift para obter detalhes abrangentes sobre como integrar o QuickSight ao Amazon Redshift.
Você pode usar o Amazon Managed Grafana para obter painéis comerciais quase em tempo real que são atualizados a cada poucos segundos. Os painéis em tempo real para monitorar as latências de ingestão comercial são criados usando Grafana e os dados são provenientes de visualizações do sistema no Amazon Redshift. Referir-se Usar a fonte de dados do Amazon Redshift para saber como configurar o Amazon Redshift como fonte de dados para Grafana.
Os usuários que interagem com os sistemas de relatórios regulatórios incluem analistas, gerentes de risco, operadores e outras pessoas que dão suporte às operações comerciais e tecnológicas. Além de gerar relatórios regulatórios, essas equipes exigem visibilidade da saúde dos sistemas de relatórios.
Análise de cotações históricas
Nesta seção, exploramos alguns exemplos de análise de cotações históricas do AmazonQuickSight painel de controle.
Spread médio ponderado por setores
O gráfico a seguir mostra a agregação diária por setor da média ponderada dos spreads de compra e venda de todas as negociações individuais na NASDAQ e NYSE durante 3 meses. Para calcular o spread médio diário, cada spread é ponderado pela soma do volume de compra e venda em dólares. A consulta para gerar este gráfico processa 103 bilhões de pontos de dados no total, une cada negociação à tabela de referência do setor e é executada em menos de 10 segundos.
![]()
Spread médio ponderado por bolsas
O gráfico a seguir mostra a agregação diária dos spreads médios ponderados de compra e venda de todas as negociações individuais na NASDAQ e NYSE durante 3 meses. A metodologia de cálculo e as métricas de desempenho da consulta são semelhantes às do gráfico anterior.
![]()
Análise histórica de negociações
Nesta seção, exploramos alguns exemplos de análise histórica de negociações do AmazonQuickSight painel de controle.
Volumes comerciais por setor
O gráfico a seguir mostra a agregação diária por setor de todas as negociações individuais na NASDAQ e NYSE durante 3 meses. A consulta para gerar este gráfico processa 3.6 bilhões de negociações no total, junta cada negociação à tabela de referência do setor e é executada em menos de 5 segundos.
![]()
Volumes de comércio para as principais bolsas
O gráfico a seguir mostra a agregação diária por grupo de bolsas de todas as negociações individuais durante 3 meses. A consulta para gerar este gráfico tem métricas de desempenho semelhantes às do gráfico anterior.
![]()
Painéis em tempo real
O monitoramento e a observabilidade são requisitos importantes para qualquer aplicação crítica de negócios, como relatórios comerciais, gerenciamento de riscos e sistemas de gerenciamento comercial. Além das métricas no nível do sistema, também é importante monitorar os principais indicadores de desempenho em tempo real para que os operadores possam ser alertados e responder o mais rápido possível aos eventos que impactam os negócios. Para esta demonstração, construímos painéis no Grafana que monitoram o atraso dos dados de cotação e negociação do fluxo de dados Kinesis e Aurora, respectivamente.
O painel de atraso de ingestão de cotação mostra quanto tempo leva para cada registro de cotação ser ingerido do fluxo de dados e ficar disponível para consulta no Amazon Redshift.
![]()
O painel de atraso de ingestão comercial mostra quanto tempo leva para uma transação no Aurora ficar disponível no Amazon Redshift para consulta.
![]()
limpar
Para limpar seus recursos, exclua a pilha implantada usando o AWS CloudFormation. Para obter instruções, consulte Exclusão de uma pilha no console do AWS CloudFormation.
Conclusão
O aumento dos volumes de actividade comercial, a gestão de risco mais complexa e os requisitos regulamentares reforçados estão a levar as empresas do mercado de capitais a adoptar o processamento de dados em tempo real e quase em tempo real, mesmo em plataformas de mid-office e back-office onde o processamento de fim de dia e durante a noite era o padrão. Nesta postagem, demonstramos como você pode usar os recursos do Amazon Redshift para facilidade de uso, baixa manutenção e economia. Também discutimos integrações entre serviços para ingerir dados de mercado de streaming, processar atualizações de bancos de dados OLTP e usar dados de referência de terceiros sem ter que realizar processamento ETL ou ELT complexo e caro antes de disponibilizar os dados para análise e relatórios.
Entre em contato conosco se precisar de alguma orientação na implementação desta solução. Referir-se Análise em tempo real com ingestão de streaming do Amazon Redshift, Guia de conceitos básicos para análises operacionais quase em tempo real usando a integração zero-ETL do Amazon Aurora com o Amazon Redshift e Trabalhar com compartilhamentos de dados do AWS Data Exchange como produtor para obter mais informações.
Sobre os autores
![]() Satesh Sonti é um arquiteto de soluções especialista em análise sênior com sede em Atlanta, especializado na construção de plataformas de dados corporativos, armazenamento de dados e soluções de análise. Ele tem mais de 18 anos de experiência na construção de ativos de dados e na liderança de programas complexos de plataforma de dados para clientes bancários e de seguros em todo o mundo.
Satesh Sonti é um arquiteto de soluções especialista em análise sênior com sede em Atlanta, especializado na construção de plataformas de dados corporativos, armazenamento de dados e soluções de análise. Ele tem mais de 18 anos de experiência na construção de ativos de dados e na liderança de programas complexos de plataforma de dados para clientes bancários e de seguros em todo o mundo.
![]() Alket Memushaj trabalha como arquiteto principal na equipe de desenvolvimento do mercado de serviços financeiros na AWS. Alket é responsável pela estratégia técnica para mercados de capitais, trabalhando com parceiros e clientes para implantar aplicativos em todo o ciclo de vida comercial na Nuvem AWS, incluindo conectividade de mercado, sistemas de negociação e análises pré e pós-negociação e plataformas de pesquisa.
Alket Memushaj trabalha como arquiteto principal na equipe de desenvolvimento do mercado de serviços financeiros na AWS. Alket é responsável pela estratégia técnica para mercados de capitais, trabalhando com parceiros e clientes para implantar aplicativos em todo o ciclo de vida comercial na Nuvem AWS, incluindo conectividade de mercado, sistemas de negociação e análises pré e pós-negociação e plataformas de pesquisa.
![]() Ruben Falk é especialista em mercado de capitais com foco em IA e dados e análises. Ruben presta consultoria a participantes do mercado de capitais sobre arquitetura moderna de dados e processos sistemáticos de investimento. Ele ingressou na AWS vindo da S&P Global Market Intelligence, onde foi chefe global de soluções de gestão de investimentos.
Ruben Falk é especialista em mercado de capitais com foco em IA e dados e análises. Ruben presta consultoria a participantes do mercado de capitais sobre arquitetura moderna de dados e processos sistemáticos de investimento. Ele ingressou na AWS vindo da S&P Global Market Intelligence, onde foi chefe global de soluções de gestão de investimentos.
![]() Jeff Wilson é um especialista mundial em Go-to-market com 15 anos de experiência trabalhando com plataformas analíticas. Seu foco atual é compartilhar os benefícios do uso do Amazon Redshift, o data warehouse nativo em nuvem da Amazon. Jeff mora na Flórida e trabalha na AWS desde 2019.
Jeff Wilson é um especialista mundial em Go-to-market com 15 anos de experiência trabalhando com plataformas analíticas. Seu foco atual é compartilhar os benefícios do uso do Amazon Redshift, o data warehouse nativo em nuvem da Amazon. Jeff mora na Flórida e trabalha na AWS desde 2019.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/combine-transactional-streaming-and-third-party-data-on-amazon-redshift-for-financial-services/
- :tem
- :é
- :não
- :onde
- ][p
- $UP
- 1
- 10
- 100
- 130
- 15 anos
- 15%
- 150
- 16
- 20
- 2019
- 27
- 30
- a
- Capaz
- Sobre
- Acesso
- acessando
- em
- atividade
- Adicional
- Adicionalmente
- aderente
- adotar
- Vantagem
- adx
- Depois de
- agregar
- agregação
- AI
- Todos os Produtos
- permitir
- tb
- Amazon
- Grafana gerenciada pela Amazon
- AmazonQuickSight
- Amazon Web Services
- quantidade
- an
- análise
- Analistas
- Analítico
- analítica
- análise
- e
- qualquer
- à parte
- Aplicação
- aplicações
- aplicado
- abordagem
- arquitetura
- Arquiteturas
- SOMOS
- AS
- perguntar
- Ativos
- At
- Atlanta
- atributos
- aurora
- auto
- disponível
- média
- AWS
- Formação da Nuvem AWS
- b
- Equilibrado
- Bancário
- baseado
- BE
- Porque
- tornam-se
- sido
- antes
- benchmarks
- Benefícios
- entre
- oferta
- bilhão
- para
- ambos
- corretor
- construir
- Prédio
- construído
- negócio
- inteligência de negócios
- Transformação de negócios
- mas a
- by
- esconderijo
- calcular
- cálculo
- Cálculo
- CAN
- capacidades
- Capacidade
- capital
- Mercados capitais
- casas
- casos
- Cboe
- desafiar
- características
- de cores
- limpar
- clientes
- Fechar
- Na nuvem
- código
- combinar
- como
- realização
- integrações
- componentes
- compreensivo
- Computar
- Coneções
- Conectividade
- consumidor
- consumo
- não contenho
- continuamente
- cópias
- crio
- criado
- cria
- crise
- crítico
- Atual
- Atualmente
- personalizadas
- Clientes
- diariamente
- painel de instrumentos
- painéis
- dados,
- Data Exchange
- gestão de dados
- Plataforma de dados
- Os pontos de dados
- informática
- compartilhamento de dados
- data warehouse
- armazéns de dados
- bases de dados
- conjuntos de dados
- Data
- dia
- diminuir
- atraso
- entregar
- demandas
- demonstraram
- implantar
- implantado
- profundidade
- descreve
- detalhado
- detalhes
- em desenvolvimento
- Desenvolvimento
- equipe de desenvolvimento
- diagrama
- diferente
- diretamente
- direção
- diretamente
- discutido
- díspar
- Dólar
- cada
- facilidade
- facilidade de utilização
- abraços
- permitir
- final
- aprimorada
- Melhora
- Empreendimento
- Éter (ETH)
- avaliar
- Mesmo
- eventos
- Cada
- exemplos
- exchange
- Trocas
- caro
- vasta experiência
- explorar
- externo
- extrato
- Característica
- Funcionalidades
- poucos
- preencher
- financeiro
- crise financeira
- dados financeiros
- Instituições financeiras
- serviços financeiros
- Encontre
- empresas
- florida
- Foco
- focado
- seguinte
- Escolha
- enquadramentos
- Frequência
- freqüentemente
- da
- Fundamentos
- gerar
- gerando
- ter
- Global
- financeiro global
- Crise financeira global
- mercado global
- globo
- Ir ao mercado
- Grupo
- Crescente
- Cresce
- orientações
- guia
- guia
- manipular
- Ter
- ter
- he
- cabeça
- Saúde
- Destaques
- sua
- histórico
- Como funciona o dobrador de carta de canal
- Como Negociar
- HTML
- http
- HTTPS
- enorme
- if
- ilustra
- executar
- implementação
- importante
- in
- incluir
- inclui
- Incluindo
- Crescimento
- aumentou
- indicadores
- Individual
- INFORMAÇÕES
- inputs
- instituições
- instruções
- com seguro
- integrar
- integração
- integrações
- Inteligência
- interagir
- para dentro
- intuitivo
- investir
- investimento
- isolamento
- IT
- juntar
- ingressou
- Junta
- jpg
- Chave
- Streams de dados Kinesis
- Latência
- lançamento
- principal
- APRENDER
- menos
- wifecycwe
- como
- Liquidez
- carregar
- carregamento
- local
- localmente
- procurando
- Baixo
- manutenção
- principal
- fazer
- Fazendo
- gerenciados
- de grupos
- Gerentes
- mapeamento
- mercado
- Dados de mercado
- Volatilidade do mercado
- marketplace
- Mercados
- significado
- medições
- Metodologia
- Métrica
- EQUIPAMENTOS
- dinheiro
- Monitore
- monitoração
- mês
- mais
- múltiplo
- MySQL
- Nasdaq
- nativo
- nativamente
- necessário
- você merece...
- Novo
- New York
- New York Stock Exchange
- Próximo
- nota
- NYSE
- obter
- of
- frequentemente
- on
- só
- aberto
- operar
- operacional
- Operações
- operadores
- otimização
- Otimize
- or
- ordem
- organização
- Outros
- Fora
- Acima de
- global
- durante a noite
- participantes
- parceria
- Parceiros
- realizar
- atuação
- permissões
- Lugar
- colocado
- plataforma
- Plataformas
- platão
- Inteligência de Dados Platão
- PlatãoData
- pontos
- possível
- Publique
- pós-negociação
- precedente
- preço
- Diretor
- princípios
- priorização
- procedimentos
- processo
- processado
- processos
- em processamento
- Programas
- proteger
- fornecer
- provedor
- qualidade
- consultas
- pergunta
- rapidamente
- citar
- citações
- Taxa
- alcançar
- reais
- em tempo real
- registro
- referir
- referência
- regular
- Reguladores
- reguladores
- relacionado
- relevante
- Relatórios
- Relatórios
- requerer
- requerimento
- Requisitos
- pesquisa
- Recursos
- respectivamente
- Responder
- responsável
- rever
- Risco
- gestão de risco
- regras
- Execute
- é executado
- S&P
- S&P Global
- mesmo
- escalável
- Escala
- escrutínio
- sem problemas
- segundo
- Seção
- setor
- Setores
- selecionar
- Serviços
- vários
- ações
- compartilhando
- rede de apoio social
- Shows
- periodo
- semelhante
- Similarmente
- simples
- simplifica
- desde
- So
- Software
- solução
- Soluções
- alguns
- Em breve
- fonte
- de origem
- Fontes
- especialista
- especializado
- tempero
- propagação
- Spreads
- SQL
- pilha
- padrão
- começado
- Comece
- Passo
- estoque
- Bolsa de Valores
- armazenamento
- loja
- armazenadas
- franco
- Estratégia
- transmitir canais
- de streaming
- córregos
- tal
- soma
- ajuda
- Suportado
- .
- sistemas
- mesa
- Tire
- toma
- tem como alvo
- Profissionais
- equipes
- Dados Técnicos:
- Tecnologia
- modelo
- condições
- do que
- que
- A
- deles
- Eles
- então
- Este
- deles
- De terceiros
- dados de terceiros
- isto
- aqueles
- três
- Através da
- tempo
- para
- Total
- comércio
- negociadas
- trades
- Trading
- transação
- transacional
- Transformar
- Transformação
- Transparência
- tipos
- tipicamente
- para
- ilimitado
- Atualizações
- us
- usar
- usava
- Utilizador
- usuários
- utilização
- via
- Ver
- visualizações
- praticamente
- visibilidade
- 👍 Volatilidade
- volume
- volumes
- queremos
- Armazém
- Armazenagem
- foi
- we
- web
- serviços web
- peso
- foram
- quando
- qual
- QUEM
- de
- sem
- trabalhar
- trabalho
- escrita
- yaml
- anos
- Iorque
- Você
- investimentos
- zefirnet