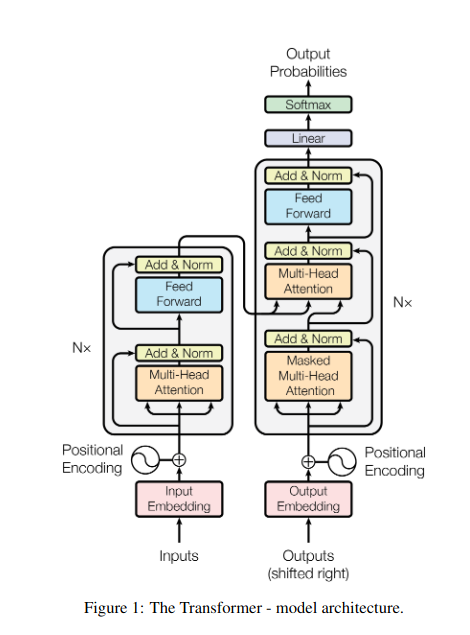
Introduction
Imagine standing in a dimly lit library, struggling to decipher a complex document while juggling dozens of other texts. This was the world of Transformers before the “Attention is All You Need” paper unveiled its revolutionary spotlight – the attention mechanism.
Table of contents
Limitations of RNNs
Traditional sequential models, like Recurrent Neural Networks (RNNs), processed language word by word, leading to several limitations:
- Short-range dependence: RNNs struggled to grasp connections between distant words, often misinterpreting the meaning of sentences like “the man who visited the zoo yesterday,” where the subject and verb are far apart.
- Limited parallelism: Processing information sequentially is inherently slow, preventing efficient training and utilization of computational resources, especially for long sequences.
- Focus on local context: RNNs primarily consider immediate neighbors, potentially missing crucial information from other parts of the sentence.
These limitations hampered the ability of Transformers to perform complex tasks like machine translation and natural language understanding. Then came the attention mechanism, a revolutionary spotlight that illuminates the hidden connections between words, transforming our understanding of language processing. But what exactly did attention solve, and how did it change the game for Transformers?
Let’s focus on three key areas:
Long-range Dependency
- Problem: Traditional models often stumbled on sentences like “the woman who lived on the hill saw a shooting star last night.” They struggled to connect “woman” and “shooting star” due to their distance, leading to misinterpretations.
- Attention Mechanism: Imagine the model shining a bright beam across the sentence, connecting “woman” directly to “shooting star” and understanding the sentence as a whole. This ability to capture relationships regardless of distance is crucial for tasks like machine translation and summarization.
Also Read: An Overview on Long Short Term Memory (LSTM)
Parallel Processing Power
- Problem: Traditional models processed information sequentially, like reading a book page by page. This was slow and inefficient, especially for long texts.
- Attention Mechanism: Imagine multiple spotlights scanning the library simultaneously, analyzing different parts of the text in parallel. This dramatically speeds up the model’s work, allowing it to handle vast amounts of data efficiently. This parallel processing power is essential for training complex models and making real-time predictions.
Global Context Awareness
- Problem: Traditional models often focused on individual words, missing the broader context of the sentence. This led to misunderstandings in cases like sarcasm or double meanings.
- Attention Mechanism: Imagine the spotlight sweeping across the entire library, taking in every book and understanding how they relate to each other. This global context awareness allows the model to consider the entirety of the text when interpreting each word, leading to a richer and more nuanced understanding.
Disambiguating Polysemous Words
- Problem: Words like “bank” or “apple” can be nouns, verbs, or even companies, creating ambiguity that traditional models struggled to resolve.
- Attention Mechanism: Imagine the model shining spotlights on all occurrences of the word “bank” in a sentence, then analyzing the surrounding context and relationships with other words. By considering grammatical structure, nearby nouns, and even past sentences, the attention mechanism can deduce the intended meaning. This ability to disambiguate polysemous words is crucial for tasks like machine translation, text summarization, and dialogue systems.
These four aspects – long-range dependency, parallel processing power, global context awareness, and disambiguation – showcase the transformative power of attention mechanisms. They have propelled Transformers to the forefront of natural language processing, enabling them to tackle complex tasks with remarkable accuracy and efficiency.
As NLP and specifically LLMs continue to evolve, attention mechanisms will undoubtedly play an even more critical role. They are the bridge between the linear sequence of words and the rich tapestry of human language, and ultimately, the key to unlocking the true potential of these linguistic marvels. This article delves into the various types of attention mechanisms and their functionalities.
1. Self-Attention: The Transformer’s Guiding Star
Imagine juggling multiple books and needing to reference specific passages in each while writing a summary. Self-attention or Scaled Dot-Product attention acts like an intelligent assistant, helping models do the same with sequential data like sentences or time series. It allows each element in the sequence to attend to every other element, effectively capturing long-range dependencies and complex relationships.
Here’s a closer look at its core technical aspects:
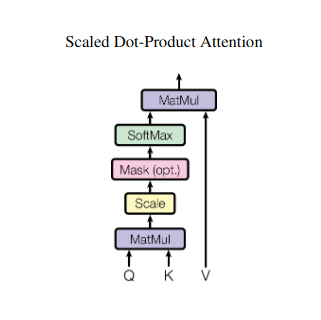
Vector Representation
Each element (word, data point) is transformed into a high-dimensional vector, encoding its information content. This vector space serves as the foundation for the interaction between elements.
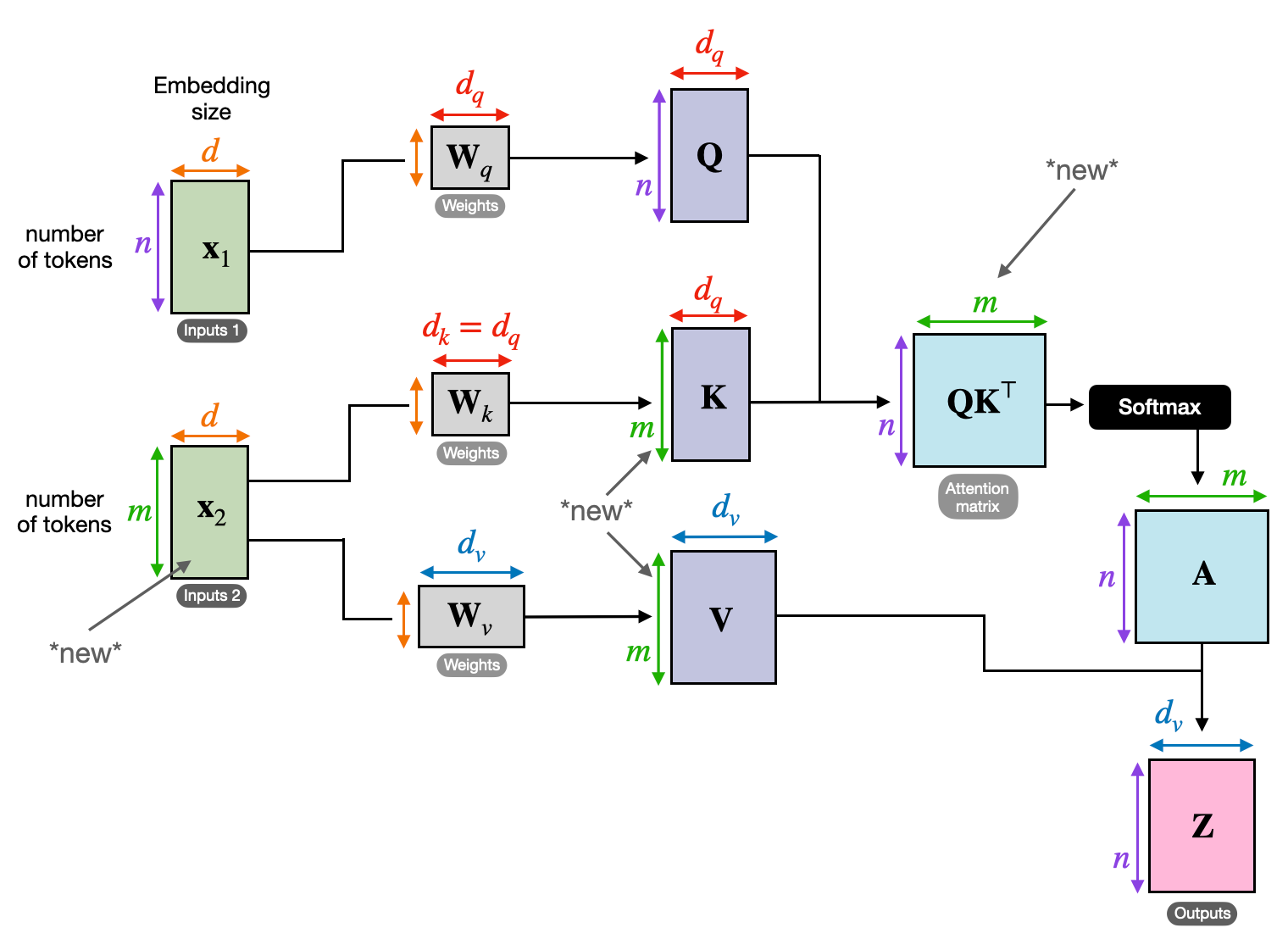
QKV Transformation
Three key matrices are defined:
- Query (Q): Represents the “question” each element poses to the others. Q captures the current element’s information needs and guides its search for relevant information within the sequence.
- Key (K): Holds the “key” to each element’s information. K encodes the essence of each element’s content, enabling other elements to identify potential relevance based on their own needs.
- Value (V): Stores the actual content each element wants to share. V contains the detailed information other elements can access and leverage based on their attention scores.
Attention Score Calculation
The compatibility between each element pair is measured through a dot product between their respective Q and K vectors. Higher scores indicate a stronger potential relevance between the elements.
Scaled Attention Weights
To ensure relative importance, these compatibility scores are normalized using a softmax function. This results in attention weights, ranging from 0 to 1, representing the weighted importance of each element for the current element’s context.
Weighted Context Aggregation
Attention weights are applied to the V matrix, essentially highlighting the important information from each element based on its relevance to the current element. This weighted sum creates a contextualized representation for the current element, incorporating insights gleaned from all other elements in the sequence.
Enhanced Element Representation
With its enriched representation, the element now possesses a deeper understanding of its own content as well as its relationships with other elements in the sequence. This transformed representation forms the basis for subsequent processing within the model.
This multi-step process enables self-attention to:
- Capture long-range dependencies: Relationships between distant elements become readily apparent, even if separated by multiple intervening elements.
- Model complex interactions: Subtle dependencies and correlations within the sequence are brought to light, leading to a richer understanding of the data structure and dynamics.
- Contextualize each element: The model analyzes each element not in isolation but within the broader framework of the sequence, leading to more accurate and nuanced predictions or representations.
Self-attention has revolutionized how models process sequential data, unlocking new possibilities across diverse fields like machine translation, natural language generation, time series forecasting, and beyond. Its ability to unveil the hidden relationships within sequences provides a powerful tool for uncovering insights and achieving superior performance in a wide range of tasks.
2. Multi-Head Attention: Seeing Through Different Lenses
Self-attention provides a holistic view, but sometimes focusing on specific aspects of the data is crucial. That’s where multi-head attention comes in. Imagine having multiple assistants, each equipped with a different lens:
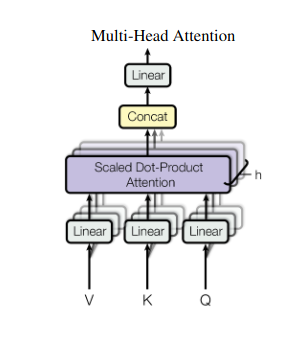
- Multiple “heads” are created, each attending to the input sequence through its own Q, K, and V matrices.
- Each head learns to focus on different aspects of the data, like long-range dependencies, syntactic relationships, or local word interactions.
- The outputs from each head are then concatenated and projected to a final representation, capturing the multifaceted nature of the input.
This allows the model to simultaneously consider various perspectives, leading to a richer and more nuanced understanding of the data.
3. Cross-Attention: Building Bridges Between Sequences
The ability to understand connections between different pieces of information is crucial for many NLP tasks. Imagine writing a book review – you wouldn’t just summarize the text word for word, but rather draw insights and connections across chapters. Enter cross-attention, a potent mechanism that builds bridges between sequences, empowering models to leverage information from two distinct sources.
- In encoder-decoder architectures like Transformers, the encoder processes the input sequence (the book) and generates a hidden representation.
- The decoder uses cross-attention to attend to the encoder’s hidden representation at each step while generating the output sequence (the review).
- The decoder’s Q matrix interacts with the encoder’s K and V matrices, allowing it to focus on relevant parts of the book while writing each sentence of the review.
This mechanism is invaluable for tasks like machine translation, summarization, and question answering, where understanding the relationships between input and output sequences is essential.
4. Causal Attention: Preserving the Flow of Time
Imagine predicting the next word in a sentence without peeking ahead. Traditional attention mechanisms struggle with tasks that require preserving the temporal order of information, such as text generation and time-series forecasting. They readily “peek ahead” in the sequence, leading to inaccurate predictions. Causal attention addresses this limitation by ensuring predictions solely depend on previously processed information.
Here’s How it Works
- Masking Mechanism: A specific mask is applied to the attention weights, effectively blocking the model’s access to future elements in the sequence. For instance, when predicting the second word in “the woman who…”, the model can only consider “the” and not “who” or subsequent words.
- Autoregressive Processing: Information flows linearly, with each element’s representation built solely from elements appearing before it. The model processes the sequence word by word, generating predictions based on the context established up to that point.
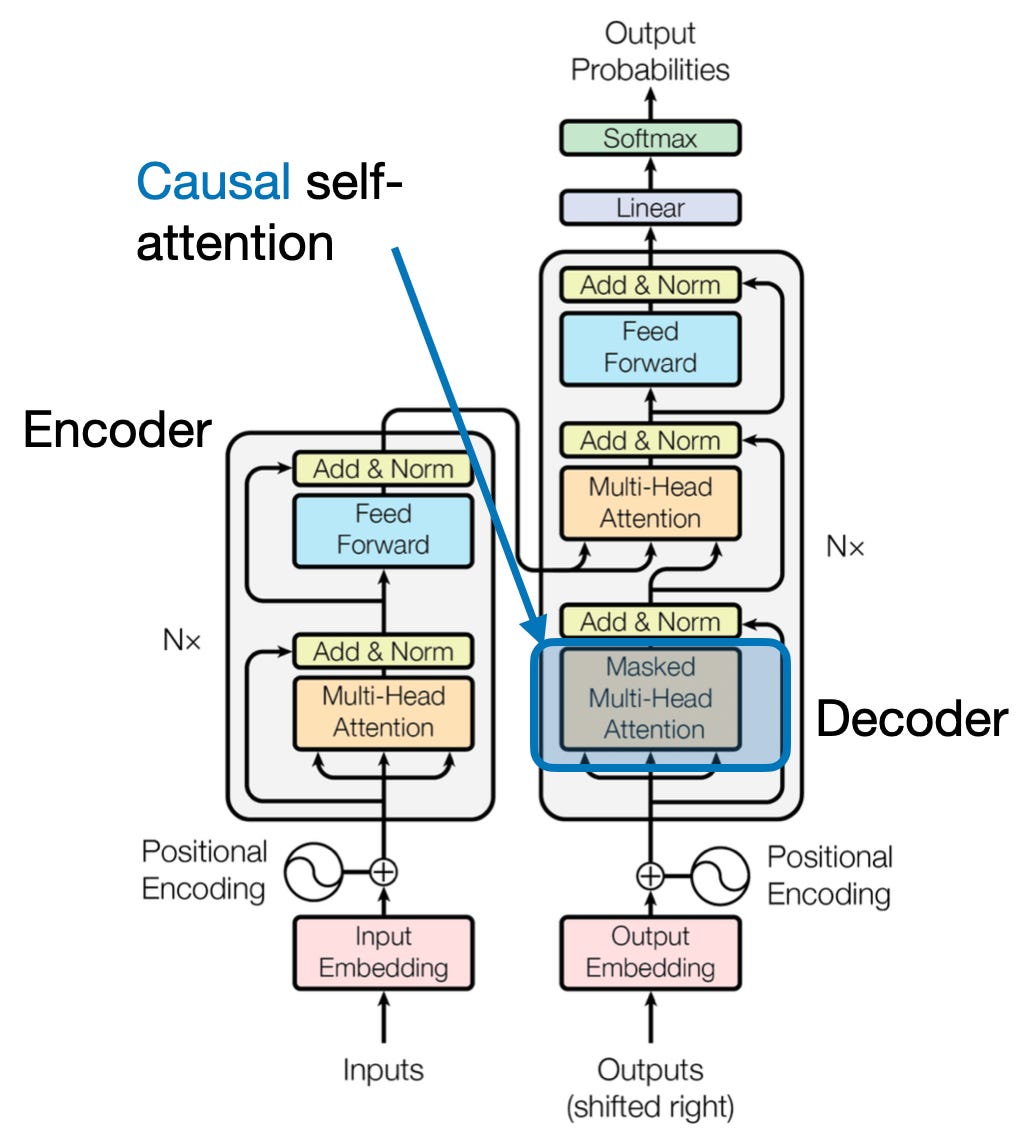
Causal attention is crucial for tasks like text generation and time-series forecasting, where maintaining the temporal order of the data is vital for accurate predictions.
5. Global vs. Local Attention: Striking the Balance
Attention mechanisms face a key trade-off: capturing long-range dependencies versus maintaining efficient computation. This manifests in two primary approaches: global attention and local attention. Imagine reading an entire book versus focusing on a specific chapter. Global attention processes the whole sequence at once, while local attention focuses on a smaller window:
- Global attention captures long-range dependencies and overall context but can be computationally expensive for long sequences.
- Local attention is more efficient but might miss out on distant relationships.
The choice between global and local attention depends on several factors:
- Task requirements: Tasks like machine translation require capturing distant relationships, favoring global attention, while sentiment analysis might favor local attention’s focus.
- Sequence length: Longer sequences make global attention computationally expensive, necessitating local or hybrid approaches.
- Model capacity: Resource constraints might necessitate local attention even for tasks requiring global context.
To achieve the optimal balance, models can employ:
- Dynamic switching: use global attention for key elements and local attention for others, adapting based on importance and distance.
- Hybrid approaches: combine both mechanisms within the same layer, leveraging their respective strengths.
Also Read: Analyzing Types of Neural Networks in Deep Learning
Conclusion
Ultimately, the ideal approach lies on a spectrum between global and local attention. Understanding these trade-offs and adopting suitable strategies allows models to efficiently exploit relevant information across different scales, leading to a richer and more accurate understanding of the sequence.
References
- Raschka, S. (2023). “Understanding and Coding Self-Attention, Multi-Head Attention, Cross-Attention, and Causal-Attention in LLMs.”
- Vaswani, A., et al. (2017). “Attention Is All You Need.”
- Radford, A., et al. (2019). “Language Models are Unsupervised Multitask Learners.”
Related
I am a data lover and I love to extract and understand the hidden patterns in the data. I want to learn and grow in the field of Machine Learning and Data Science.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :has
- :is
- :not
- :where
- $UP
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- ability
- access
- accuracy
- accurate
- Achieve
- achieving
- across
- acts
- actual
- addresses
- Adopting
- ahead
- AL
- All
- Allowing
- allows
- am
- Ambiguity
- amounts
- an
- analysis
- analyzes
- analyzing
- and
- answering
- apart
- apparent
- applied
- approach
- approaches
- ARE
- areas
- article
- AS
- aspects
- Assistant
- assistants
- At
- attend
- attending
- attention
- awareness
- Balance
- based
- basis
- BE
- Beam
- become
- before
- between
- Beyond
- blocking
- book
- Books
- both
- BRIDGE
- bridges
- Bright
- broader
- brought
- Building
- builds
- built
- but
- by
- came
- CAN
- capture
- captures
- Capturing
- cases
- change
- Chapter
- chapters
- choice
- closer
- Coding
- combine
- comes
- Companies
- compatibility
- complex
- computation
- computational
- Connect
- Connecting
- Connections
- Consider
- considering
- constraints
- contains
- content
- context
- continue
- Core
- correlations
- created
- creates
- Creating
- critical
- crucial
- Current
- data
- data science
- Decipher
- deep
- deeper
- defined
- delves
- depend
- dependence
- dependencies
- Dependency
- depends
- detailed
- dialogue
- DID
- different
- directly
- distance
- Distant
- distinct
- diverse
- do
- document
- DOT
- double
- dozens
- dramatically
- draw
- due
- dynamics
- E&T
- each
- effectively
- efficiency
- efficient
- efficiently
- element
- elements
- empowering
- enables
- enabling
- encoding
- enriched
- ensure
- ensuring
- Enter
- Entire
- entirety
- equipped
- especially
- essence
- essential
- essentially
- established
- Even
- Every
- evolve
- exactly
- expensive
- Exploit
- extract
- Face
- factors
- far
- favor
- field
- Fields
- final
- flow
- Flows
- Focus
- focused
- focuses
- focusing
- For
- forefront
- forms
- Foundation
- four
- Framework
- from
- function
- functionalities
- future
- game
- generates
- generating
- generation
- Global
- global context
- grasp
- Grow
- Guides
- guiding
- handle
- Have
- having
- head
- helping
- Hidden
- High
- higher
- highlighting
- holds
- holistic
- How
- HTTPS
- human
- Hybrid
- i
- ideal
- identify
- if
- imagine
- immediate
- importance
- important
- in
- inaccurate
- incorporating
- indicate
- individual
- inefficient
- information
- inherently
- input
- insights
- instance
- Intelligent
- intended
- interaction
- interactions
- interacts
- intervening
- into
- invaluable
- isolation
- IT
- ITS
- jpg
- just
- Key
- Key Areas
- language
- Last
- layer
- leading
- LEARN
- Learn and Grow
- learners
- learning
- Led
- Lens
- lenses
- Leverage
- leveraging
- Library
- lies
- light
- like
- limitation
- limitations
- local
- Long
- longer
- Look
- love
- machine
- machine learning
- machine translation
- maintaining
- make
- Making
- man
- many
- mask
- Matrix
- max-width
- meaning
- meanings
- measured
- mechanism
- mechanisms
- Memory
- might
- miss
- missing
- model
- models
- more
- more efficient
- multifaceted
- multiple
- Natural
- Natural Language
- Natural Language Generation
- Natural Language Processing
- Natural Language Understanding
- Nature
- Need
- needing
- needs
- neighbors
- networks
- Neural
- neural networks
- New
- next
- night
- nlp
- nouns
- now
- nuanced
- of
- often
- on
- once
- only
- optimal
- or
- order
- Other
- Others
- our
- out
- output
- outputs
- overall
- overview
- own
- page
- pair
- Paper
- Parallel
- parts
- passages
- past
- patterns
- perform
- performance
- perspectives
- pieces
- plato
- Plato Data Intelligence
- PlatoData
- Play
- Point
- poses
- possesses
- possibilities
- potent
- potential
- potentially
- power
- powerful
- predicting
- Predictions
- preserving
- preventing
- previously
- primarily
- primary
- process
- processed
- processes
- processing
- Processing Power
- Product
- projected
- propelled
- provides
- question
- range
- ranging
- rather
- Read
- readily
- Reading
- real-time
- reference
- Regardless
- Relationships
- relative
- relevance
- relevant
- remarkable
- representation
- representing
- represents
- require
- resolve
- resource
- Resources
- respective
- Results
- review
- revolutionary
- revolutionized
- Rich
- Role
- s
- same
- Sarcasm
- saw
- scales
- scanning
- Science
- score
- scores
- Search
- Second
- seeing
- sentence
- sentiment
- Sequence
- Series
- serves
- several
- Share
- shining
- shooting
- Short
- showcase
- simultaneously
- slow
- smaller
- solely
- SOLVE
- sometimes
- Sources
- Space
- specific
- specifically
- Spectrum
- speeds
- Spotlight
- standing
- Star
- Step
- stores
- strategies
- strengths
- stronger
- structure
- Struggle
- Struggling
- subject
- subsequent
- such
- suitable
- sum
- summarize
- SUMMARY
- superior
- Surrounding
- Systems
- tackle
- taking
- tapestry
- tasks
- Technical
- term
- text
- text generation
- that
- The
- the world
- their
- Them
- then
- These
- they
- this
- three
- Through
- time
- Time Series
- to
- tool
- traditional
- Training
- transformative
- transformed
- transformer
- transformers
- transforming
- Translation
- true
- two
- types
- Ultimately
- understand
- understanding
- undoubtedly
- unlocking
- unveil
- unveiled
- use
- uses
- using
- various
- Vast
- Versus
- View
- visited
- vital
- vs
- want
- wants
- was
- WELL
- What
- when
- while
- WHO
- whole
- wide
- Wide range
- will
- window
- with
- within
- without
- woman
- Word
- words
- Work
- world
- writing
- yesterday
- you
- zephyrnet
- ZOO









