Computer engineer [Marco Cilloni] realized a lot of developers today still have trouble dealing with Unicode in their programs, especially in the C/C++ world. He wrote an excellent guide that summarizes many of the issues surrounding Unicode and its encoding called “Unicode is harder than you think“. He first presents a brief history of Unicode and how it came about, so you can understand the reasons for the frustrating edge cases you’re bound to encounter.
There have been a variety of Unicode encoding methods over the years, but modern programs dealing with strings will probably be using UTF-8 encoding — and you should too. This multibyte encoding scheme has the convenient property of not changing the original character values when dealing with 7-bit ASCII text. We were surprised to read that there is actually an EBCDIC version of UTF still officially on the books today:
UTF-EBCDIC, a variable-width encoding that uses 1-byte characters designed for IBM’s EBCDIC systems (note: I think it’s safe to argue that using EBCDIC in 2023 edges very close to being a felony)
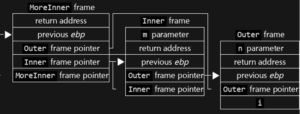
[Marco] goes in detail about different problems found when dealing with Unicode strings. When C was being developed, ASCII itself had just been finalized in the form we know today, so it treats characters as single byte numbers. With multi-byte, variable-width character strings, the usual functions like strlen fall apart.
Unicode’s combining characters also causes problems when it comes to comparison and collation of text. These are characters which can be built from multiple glyphs, but they also have a pre-built Unicode point. There are also ligatures that combine multiple characters into a single code point. Suddenly it isn’t so clear what character equality even means — Unicode defines two kinds of equivalences, canonical and compatibility.
These are but a sampling of the issues [Marco] discusses. The most important takeaway is that “Unicode handling is always best left to a library“. If your language / compiler of choice doesn’t have one, the Unicode organization provides a reference design called the ICU.
If this topic interests you, do check out his essay linked above. And if you want to get your hands dirty with Unicode glyphs, check out [Roman Czyborra]’s tools here, which are simple command line tools that let you easily experiment using ASCII art. [Roman] founded the open-sourced GNU Unicode Font project back in the 1990s, Unifoundry. Our own [Maya Posch] wrote a great article on the history of Unicode in 2021.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://hackaday.com/2023/07/28/understanding-and-using-unicode/
- :has
- :is
- :not
- 2021
- 2023
- a
- About
- above
- actually
- also
- always
- an
- and
- apart
- ARE
- argue
- Art
- AS
- back
- BE
- been
- being
- BEST
- Books
- bound
- built
- but
- called
- came
- CAN
- cases
- causes
- changing
- character
- characters
- check
- choice
- clear
- Close
- code
- combine
- combining
- comes
- comparison
- compatibility
- Convenient
- dealing
- Defines
- Design
- designed
- detail
- developed
- developers
- different
- different problems
- do
- Doesn’t
- easily
- Edge
- encounter
- engineer
- equality
- especially
- ESSAY
- Even
- excellent
- experiment
- Fall
- felony
- finalized
- First
- For
- form
- found
- Founded
- from
- frustrating
- functions
- get
- GitHub
- Goes
- great
- had
- Handling
- Hands
- harder
- Have
- he
- his
- history
- How
- http
- HTTPS
- i
- if
- important
- in
- interests
- into
- issues
- IT
- ITS
- itself
- just
- Know
- language
- left
- like
- Line
- linked
- Lot
- many
- Marco
- Maya
- means
- methods
- Modern
- most
- multiple
- numbers
- of
- Officially
- on
- ONE
- organization
- original
- our
- out
- over
- own
- plato
- Plato Data Intelligence
- PlatoData
- Point
- presents
- probably
- problems
- Programs
- project
- property
- provides
- Read
- realized
- reasons
- reference design
- safe
- scheme
- should
- Simple
- single
- So
- Still
- surprised
- Surrounding
- Systems
- than
- that
- The
- their
- There.
- These
- they
- think
- this
- to
- today
- too
- tools
- topic
- treats
- trouble
- two
- understand
- understanding
- unicode
- uses
- using
- Values
- variety
- version
- very
- want
- was
- we
- were
- What
- when
- which
- will
- with
- world
- years
- you
- Your
- zephyrnet