Wraz z uruchomieniem funkcji wyszukiwania neuronowego dla Usługa Amazon OpenSearch w OpenSearch 2.9 integracja z modelami AI/ML w celu wspomagania wyszukiwania semantycznego i innych zastosowań jest teraz łatwa. Usługa OpenSearch obsługuje zarówno wyszukiwanie leksykalne, jak i wektorowe od czasu wprowadzenia funkcji k-najbliższego sąsiada (k-NN) w 2020 r.; jednak skonfigurowanie wyszukiwania semantycznego wymagało zbudowania platformy umożliwiającej integrację modeli uczenia maszynowego (ML) na potrzeby pozyskiwania i wyszukiwania. Funkcja wyszukiwania neuronowego ułatwia transformację tekstu na wektor podczas przetwarzania i wyszukiwania. Kiedy podczas wyszukiwania używasz zapytania neuronowego, zapytanie jest tłumaczone na osadzenie wektora, a k-NN jest używane do zwrócenia najbliższego osadzania wektora z korpusu.
Aby korzystać z wyszukiwania neuronowego, należy skonfigurować model ML. Zalecamy skonfigurowanie łączników AI/ML z usługami AWS AI i ML (takimi jak Amazon Sage Maker or Amazońska skała macierzysta) lub alternatywy innych firm. Począwszy od wersji 2.9 usługi OpenSearch, złącza AI/ML integrują się z wyszukiwaniem neuronowym, aby uprościć i operacjonalizować tłumaczenie korpusu danych i zapytań na osadzanie wektorów, eliminując w ten sposób znaczną część złożoności związanej z nawadnianiem i wyszukiwaniem wektorów.
W tym poście pokazujemy, jak skonfigurować łączniki AI/ML do modeli zewnętrznych za pomocą konsoli usługi OpenSearch.
Omówienie rozwiązania
W szczególności ten post przeprowadzi Cię przez proces łączenia się z modelem w SageMaker. Następnie przeprowadzimy Cię przez proces używania łącznika do konfiguracji wyszukiwania semantycznego w usłudze OpenSearch jako przykład przypadku użycia obsługiwanego poprzez połączenie z modelem ML. Integracje Amazon Bedrock i SageMaker są obecnie obsługiwane w interfejsie konsoli OpenSearch Service, a lista integracji własnych i innych firm obsługiwanych przez interfejs użytkownika będzie stale rosnąć.
W przypadku modeli nieobsługiwanych przez interfejs użytkownika można je zamiast tego skonfigurować przy użyciu dostępnych interfejsów API i Plany ML. Aby uzyskać więcej informacji, zobacz Wprowadzenie do modeli OpenSearch. Schematy każdego złącza można znaleźć w pliku Repozytorium ML Commons na GitHubie.
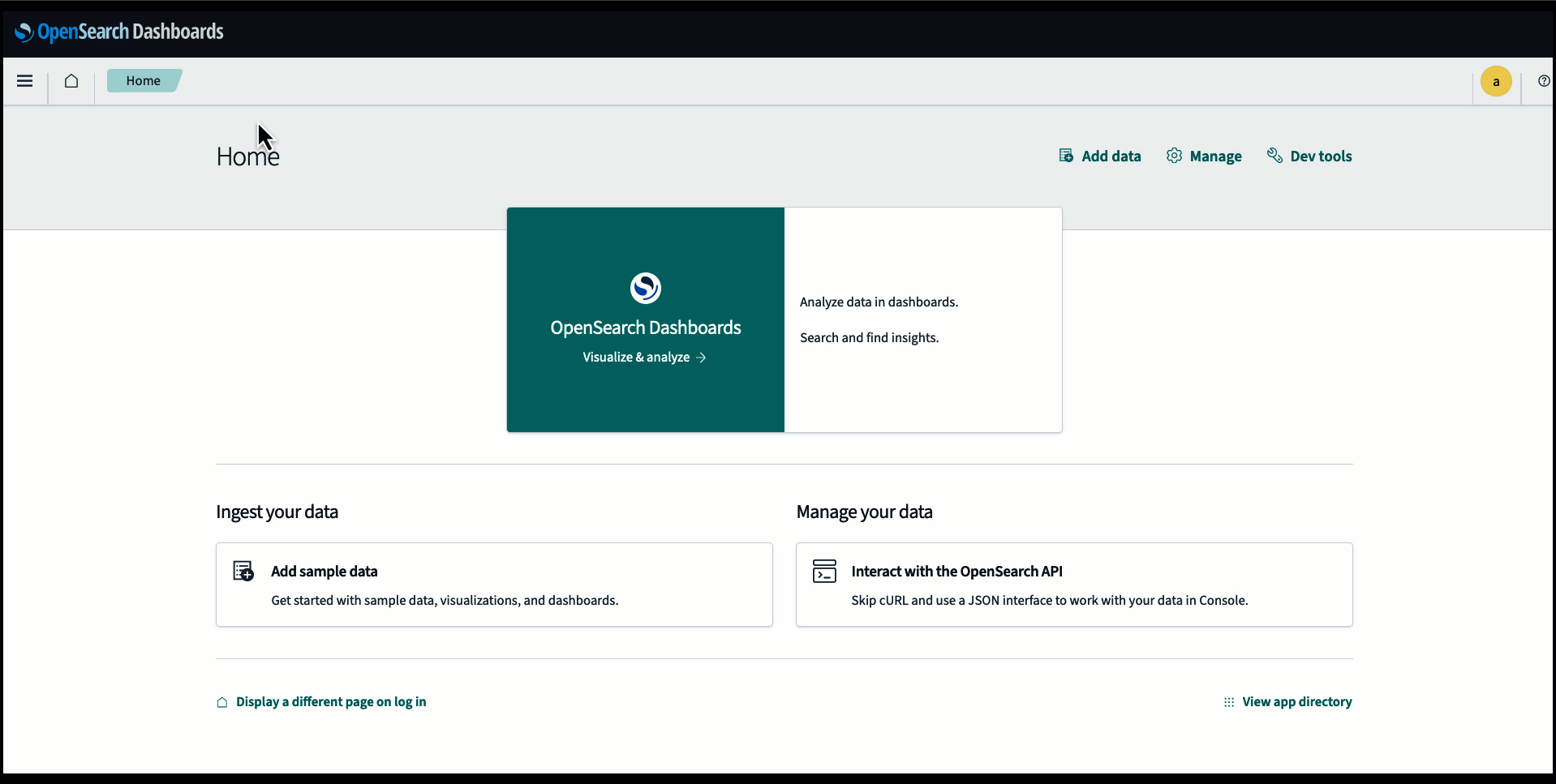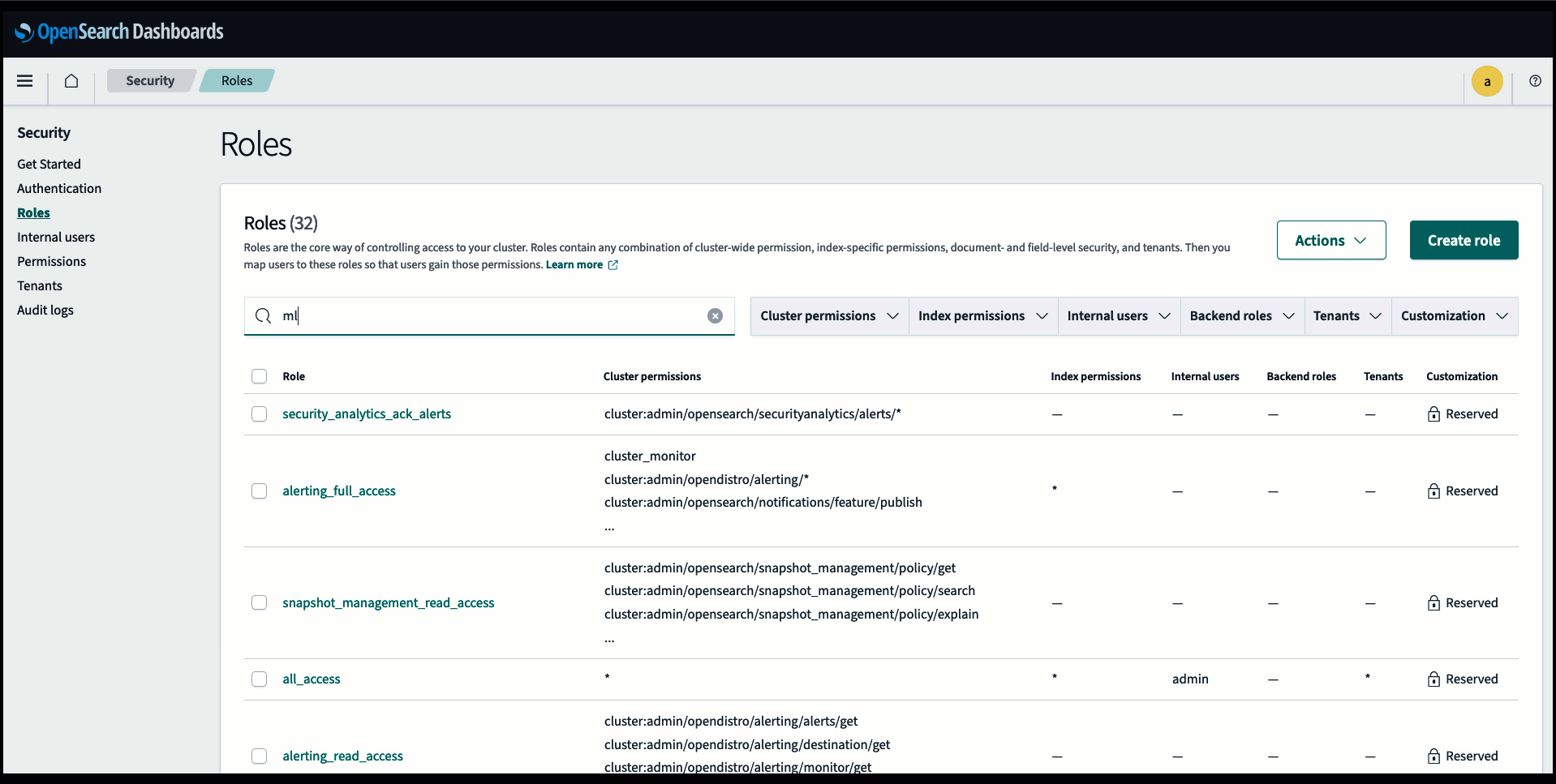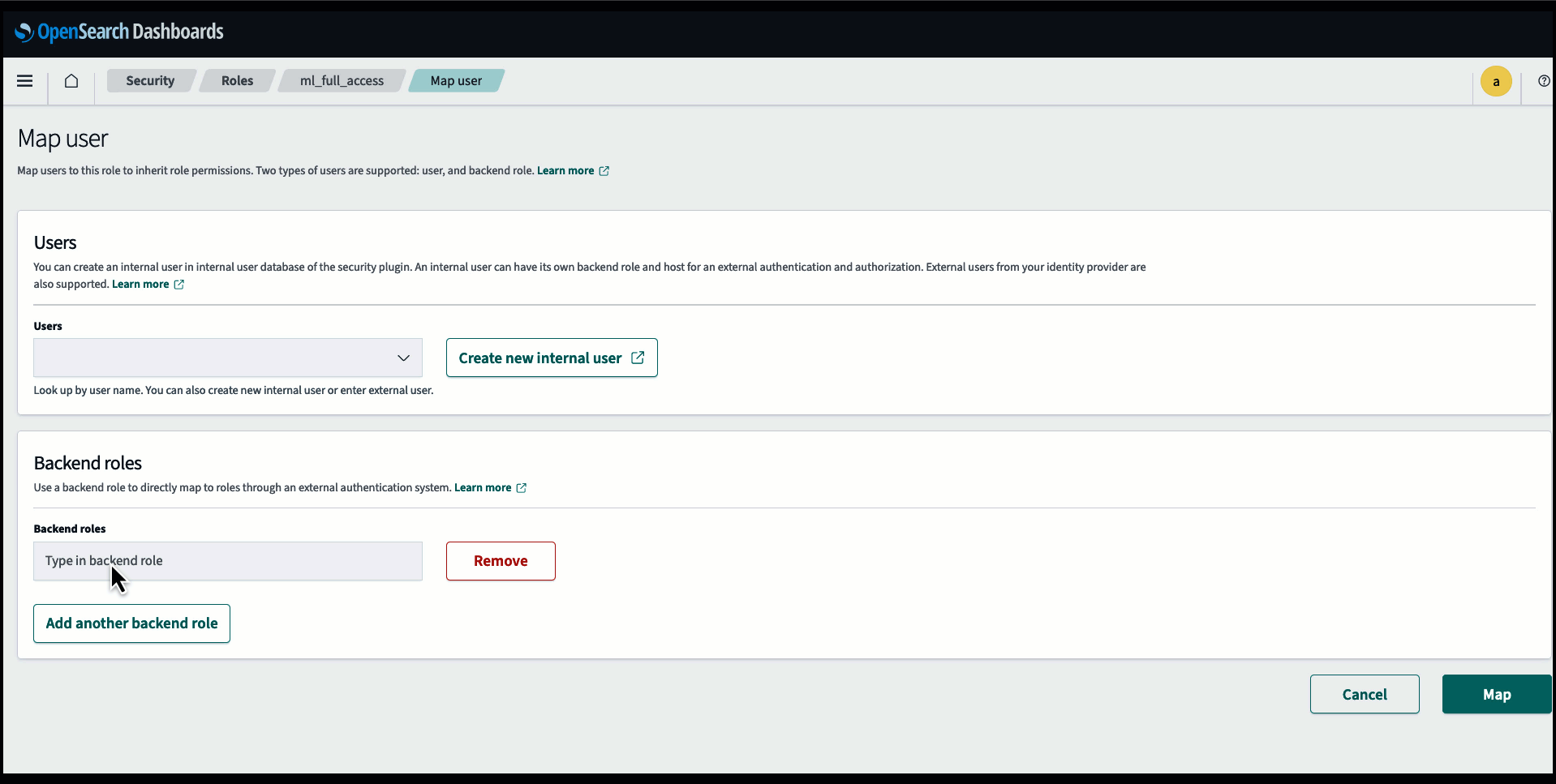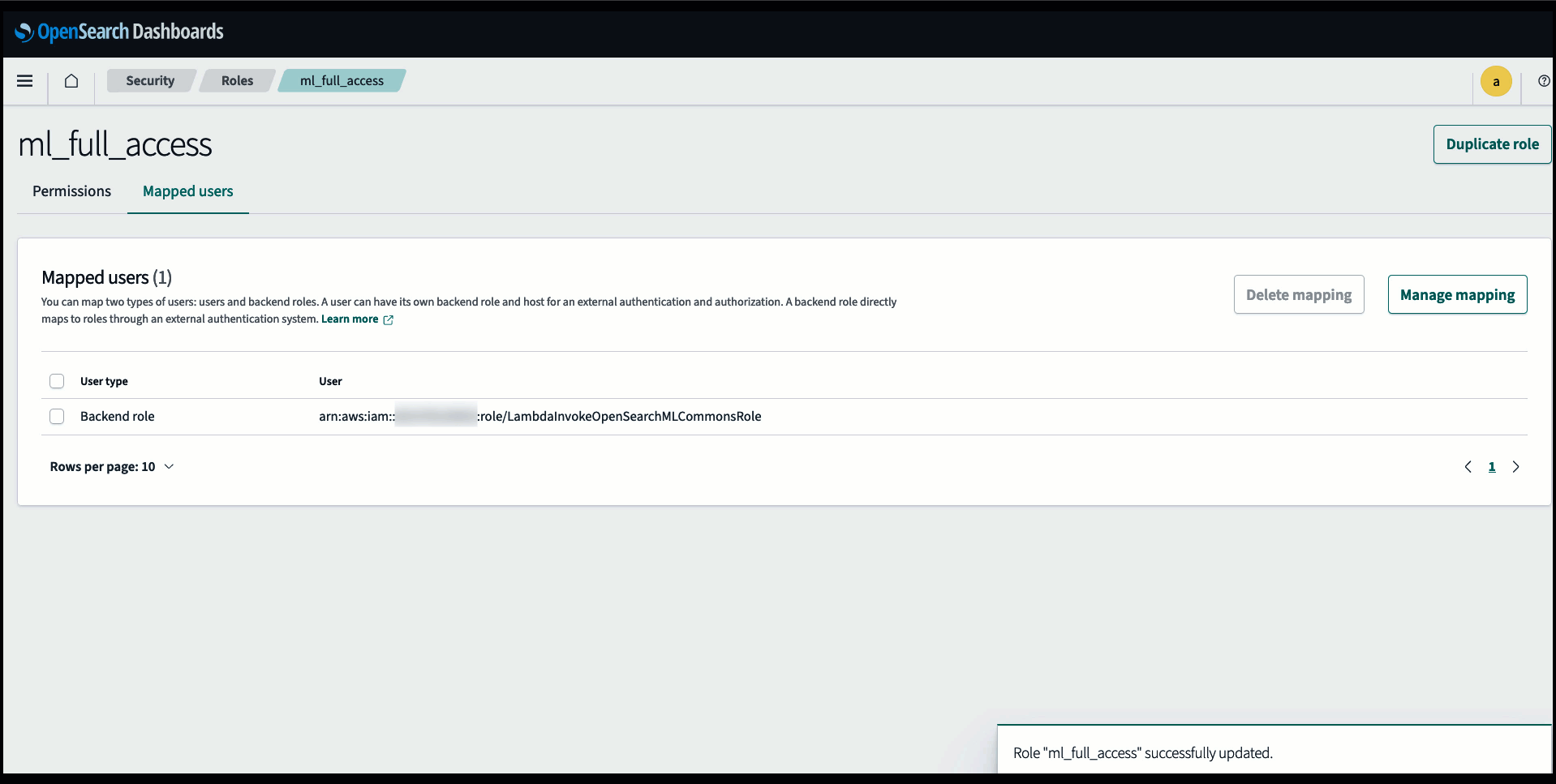
Wymagania wstępne
Przed podłączeniem modelu poprzez konsolę usługi OpenSearch utwórz domenę usługi OpenSearch. Mapa AWS Zarządzanie tożsamością i dostępem (IAM) rola z nazwy LambdaInvokeOpenSearchMLCommonsRole jako rola backendu w ml_full_access rolę za pomocą wtyczki Security w panelach OpenSearch, jak pokazano na poniższym filmie. Przepływ pracy związany z integracją usługi OpenSearch jest wstępnie wypełniony, aby móc korzystać z LambdaInvokeOpenSearchMLCommonsRole Domyślna rola IAM służąca do tworzenia łącznika między domeną usługi OpenSearch a modelem wdrożonym w SageMaker. Jeśli używasz niestandardowej roli uprawnień w integracji konsoli OpenSearch Service, upewnij się, że niestandardowa rola jest mapowana jako rola zaplecza za pomocą ml_full_access uprawnienia przed wdrożeniem szablonu.
Wdróż model za pomocą AWS CloudFormation
Poniższy film pokazuje, jak używać konsoli OpenSearch Service do wdrożenia modelu w ciągu kilku minut w serwisie Amazon SageMaker i wygenerowania identyfikatora modelu za pośrednictwem złączy AI. Pierwszym krokiem jest wybór Integracje w panelu nawigacyjnym konsoli AWS OpenSearch Service, który prowadzi do listy dostępnych integracji. Integrację konfiguruje się poprzez interfejs użytkownika, który poprosi Cię o wprowadzenie niezbędnych danych.
Aby skonfigurować integrację, wystarczy podać punkt końcowy domeny usługi OpenSearch i podać nazwę modelu, aby jednoznacznie zidentyfikować połączenie modelu. Domyślnie szablon wdraża model transformatorów zdań Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
Kiedy wybierzesz Utwórz stos, nastąpi przekierowanie do Tworzenie chmury AWS konsola. Szablon CloudFormation wdraża architekturę szczegółowo przedstawioną na poniższym diagramie.

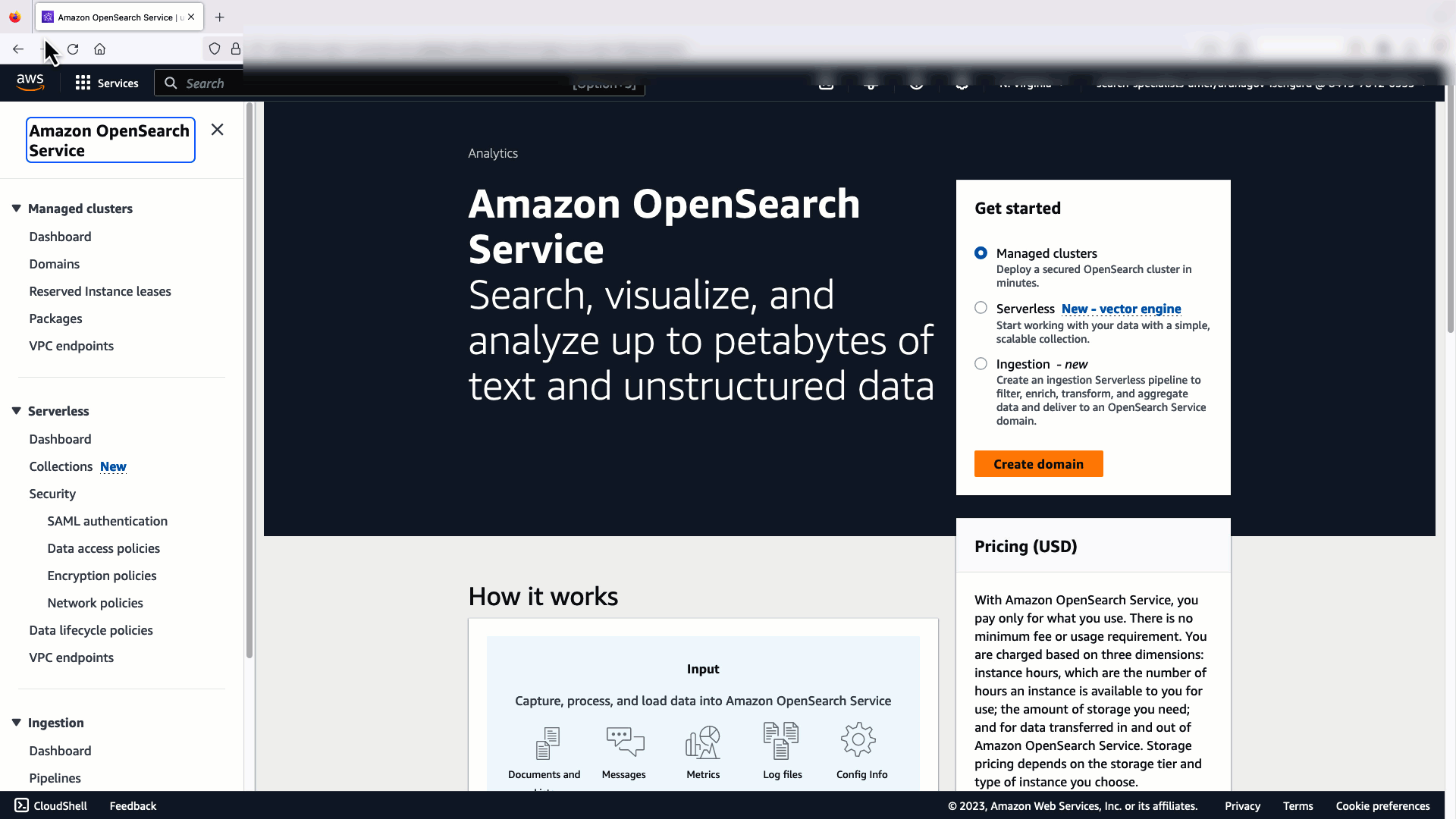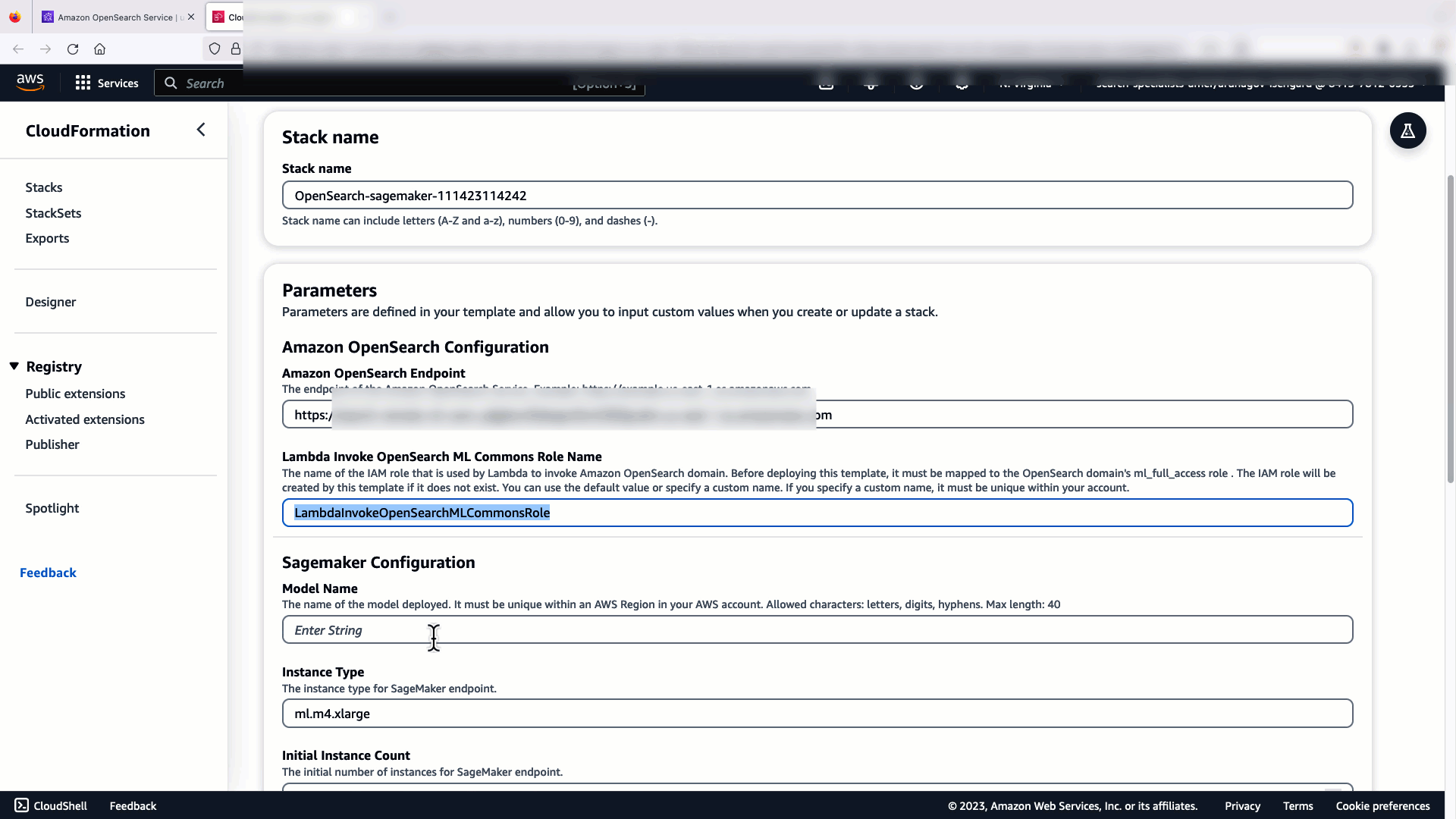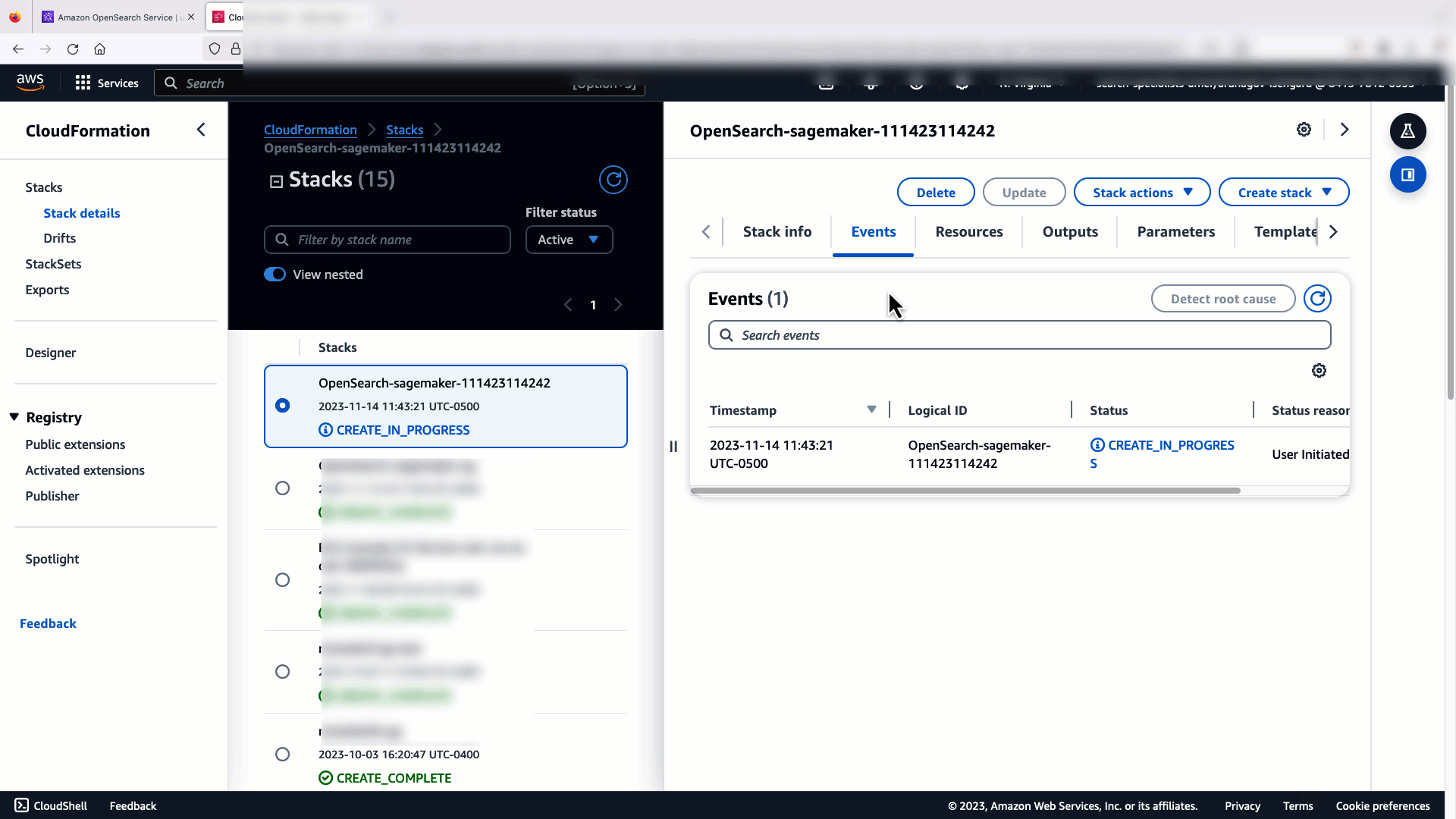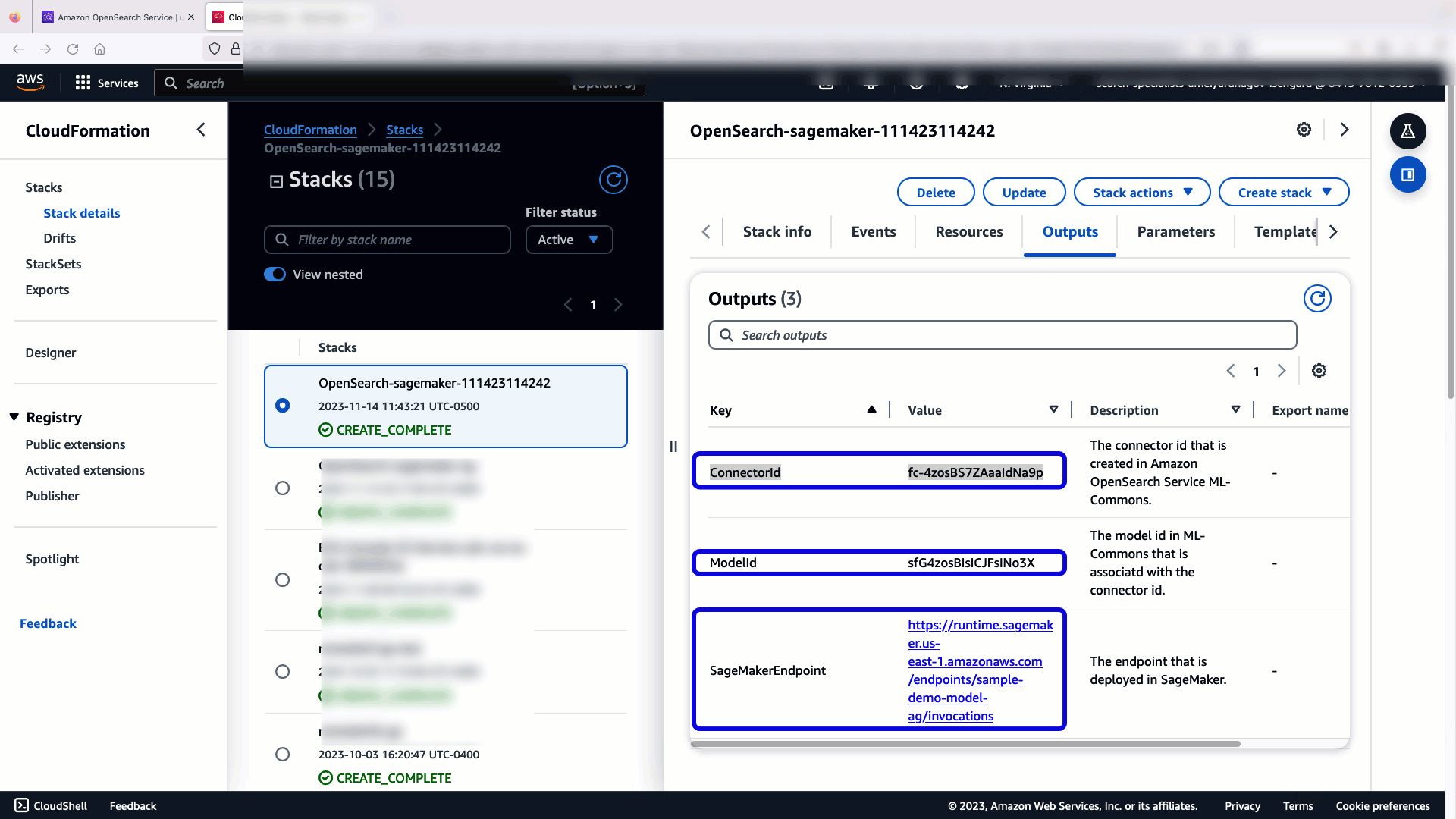
Stos CloudFormation tworzy plik AWS Lambda aplikacja, która wdraża model z Usługa Amazon Simple Storage (Amazon S3), tworzy złącze i generuje identyfikator modelu na wyjściu. Następnie możesz użyć tego identyfikatora modelu do utworzenia indeksu semantycznego.
Jeśli domyślny model składający się wyłącznie z MiniLM-L6-v2 nie spełnia Twoich oczekiwań, możesz wdrożyć dowolny wybrany model osadzania tekstu na wybranym hoście modelu (SageMaker lub Amazon Bedrock), udostępniając artefakty modelu jako dostępny obiekt S3. Alternatywnie możesz wybrać jedną z poniższych opcji wstępnie wytrenowane modele językowe i wdróż go w SageMaker. Aby uzyskać instrukcje dotyczące konfigurowania punktu końcowego i modeli, zobacz Dostępne obrazy Amazon SageMaker.
SageMaker to w pełni zarządzana usługa, która łączy szeroki zestaw narzędzi umożliwiających wydajne i niedrogie ML w każdym przypadku użycia, zapewniając kluczowe korzyści, takie jak monitorowanie modeli, hosting bezserwerowy i automatyzacja przepływu pracy na potrzeby ciągłego szkolenia i wdrażania. SageMaker umożliwia hostowanie i zarządzanie cyklem życia modeli osadzania tekstu oraz wykorzystywanie ich do obsługi zapytań wyszukiwania semantycznego w usłudze OpenSearch Service. Po połączeniu SageMaker hostuje Twoje modele, a usługa OpenSearch służy do wysyłania zapytań na podstawie wyników wnioskowania z SageMaker.
Wyświetl wdrożony model za pomocą pulpitów nawigacyjnych OpenSearch
Aby sprawdzić, czy szablon CloudFormation pomyślnie wdrożył model w domenie usługi OpenSearch i uzyskał identyfikator modelu, możesz użyć interfejsu API REST GET ML Commons za pośrednictwem narzędzi deweloperskich OpenSearch Dashboards.
Interfejs API REST GET _plugins udostępnia teraz dodatkowe interfejsy API umożliwiające również przeglądanie stanu modelu. Poniższe polecenie pozwala zobaczyć status zdalnego modelu:
Jak pokazano na poniższym zrzucie ekranu, a DEPLOYED Stan w odpowiedzi wskazuje, że model został pomyślnie wdrożony w klastrze usługi OpenSearch.

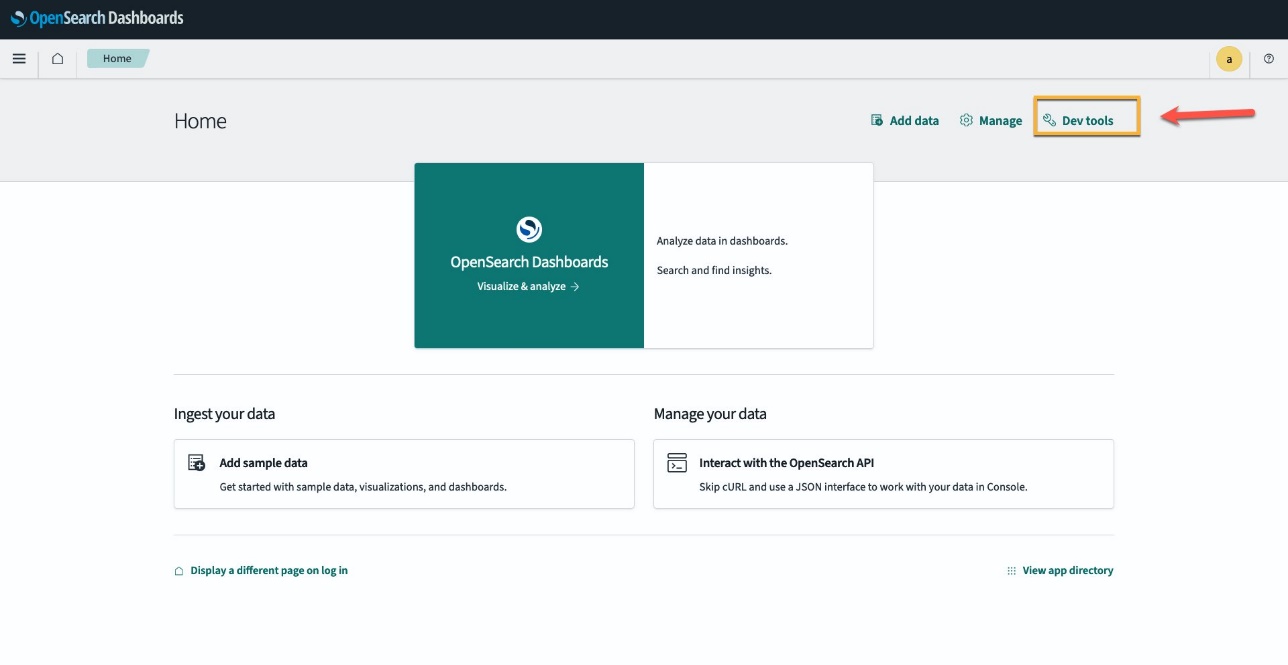
Alternatywnie możesz wyświetlić model wdrożony w domenie usługi OpenSearch za pomocą Nauczanie maszynowe strona paneli kontrolnych OpenSearch.

Na tej stronie znajdują się informacje o modelu i stany wszystkich wdrożonych modeli.
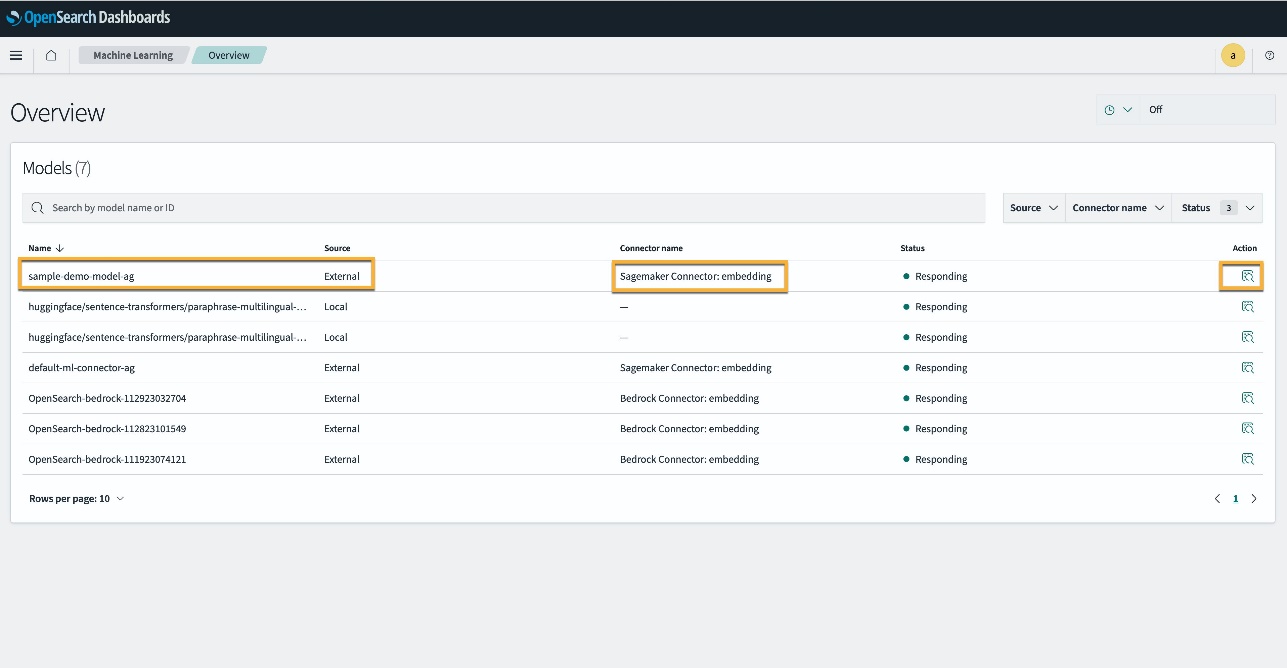

Utwórz potok neuronowy przy użyciu identyfikatora modelu
Gdy status modelu jest wyświetlany jako albo DEPLOYED w Dev Tools lub zielonym i Odpowiadając w panelach kontrolnych OpenSearch możesz użyć identyfikatora modelu do zbudowania potoku pozyskiwania danych neuronowych. Poniższy potok pozyskiwania jest uruchamiany w narzędziach deweloperskich OpenSearch Dashboards w Twojej domenie. Pamiętaj, aby zastąpić identyfikator modelu unikalnym identyfikatorem wygenerowanym dla modelu wdrożonego w Twojej domenie.

Utwórz indeks wyszukiwania semantycznego, używając potoku neuronowego jako potoku domyślnego
Możesz teraz zdefiniować mapowanie indeksu przy użyciu domyślnego potoku skonfigurowanego do korzystania z nowego potoku neuronowego utworzonego w poprzednim kroku. Upewnij się, że pola wektorowe są zadeklarowane jako knn_vector a wymiary są odpowiednie dla modelu wdrożonego w SageMaker. Jeśli zachowałeś domyślną konfigurację do wdrożenia modelu składającego się wyłącznie z MiniLM-L6-v2 w SageMaker, zachowaj następujące ustawienia bez zmian i uruchom polecenie w Narzędziach deweloperskich.

Pozyskuj przykładowe dokumenty, aby wygenerować wektory
W przypadku tej wersji demonstracyjnej możesz pozyskać plik przykładowy katalog produktów w sklepie detalicznym do nowego semantic_demostore indeks. Zastąp nazwę użytkownika, hasło i punkt końcowy domeny informacjami o swojej domenie i pozyskuj surowe dane do usługi OpenSearch:

Sprawdź nowy indeks semantic_demostore
Teraz, gdy już pozyskałeś zbiór danych do domeny usługi OpenSearch, sprawdź, czy wymagane wektory zostały wygenerowane za pomocą prostego wyszukiwania w celu pobrania wszystkich pól. Sprawdź, czy pola zdefiniowane jako knn_vectors mają wymagane wektory.

Porównaj wyszukiwanie leksykalne i wyszukiwanie semantyczne oparte na wyszukiwaniu neuronowym za pomocą narzędzia Porównaj wyniki wyszukiwania
Połączenia Narzędzie Porównaj wyniki wyszukiwania w OpenSearch Dashboards jest dostępna dla obciążeń produkcyjnych. Możesz przejść do Porównaj wyniki wyszukiwania i porównaj wyniki zapytań między wyszukiwaniem leksykalnym a wyszukiwaniem neuronowym skonfigurowanym do korzystania z wygenerowanego wcześniej identyfikatora modelu.

Sprzątać
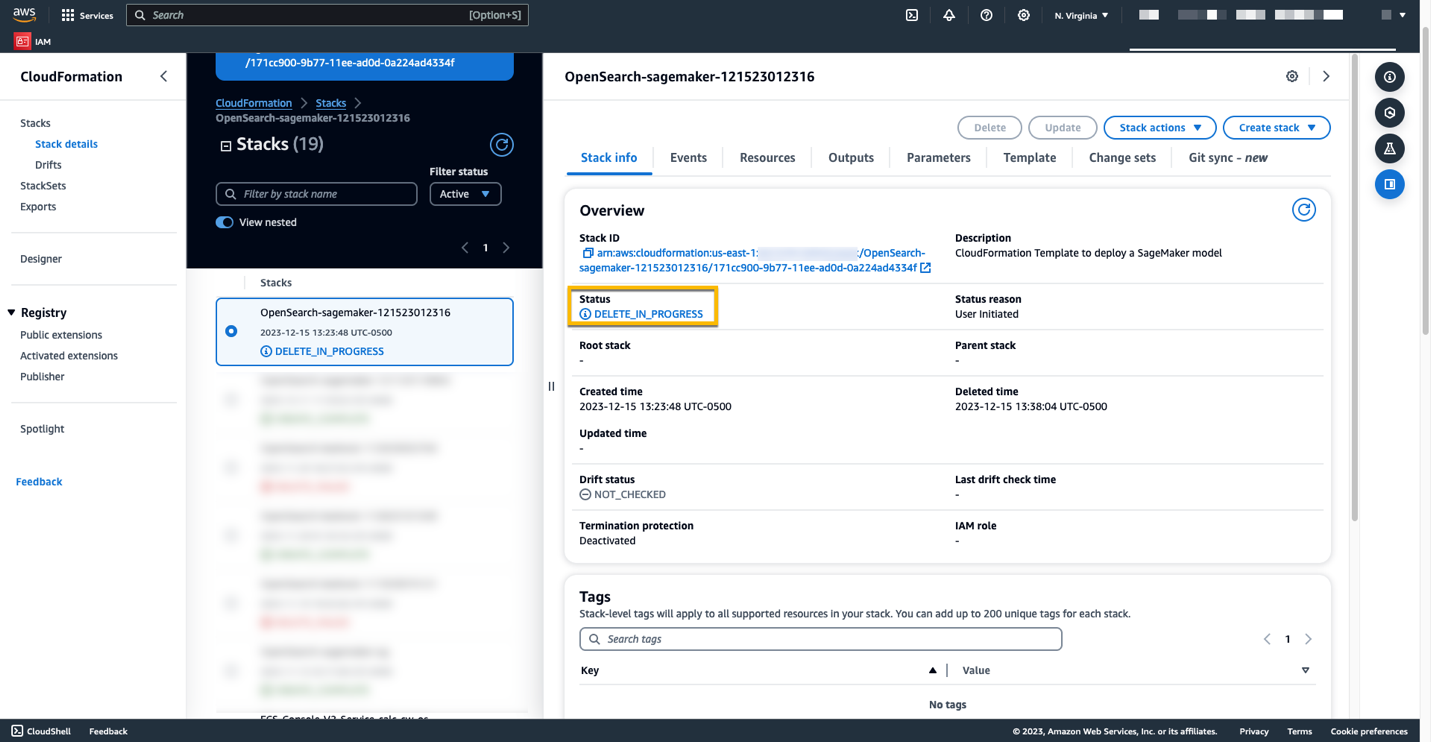
Możesz usunąć utworzone zasoby, postępując zgodnie z instrukcjami zawartymi w tym poście, usuwając stos CloudFormation. Spowoduje to usunięcie zasobów Lambda i zasobnika S3 zawierającego model wdrożony w SageMaker. Wykonaj następujące kroki:
- W konsoli AWS CloudFormation przejdź do strony szczegółów stosu.
- Dodaj Usuń.

- Dodaj Usuń potwierdzać.

Możesz monitorować postęp usuwania stosu w konsoli AWS CloudFormation.
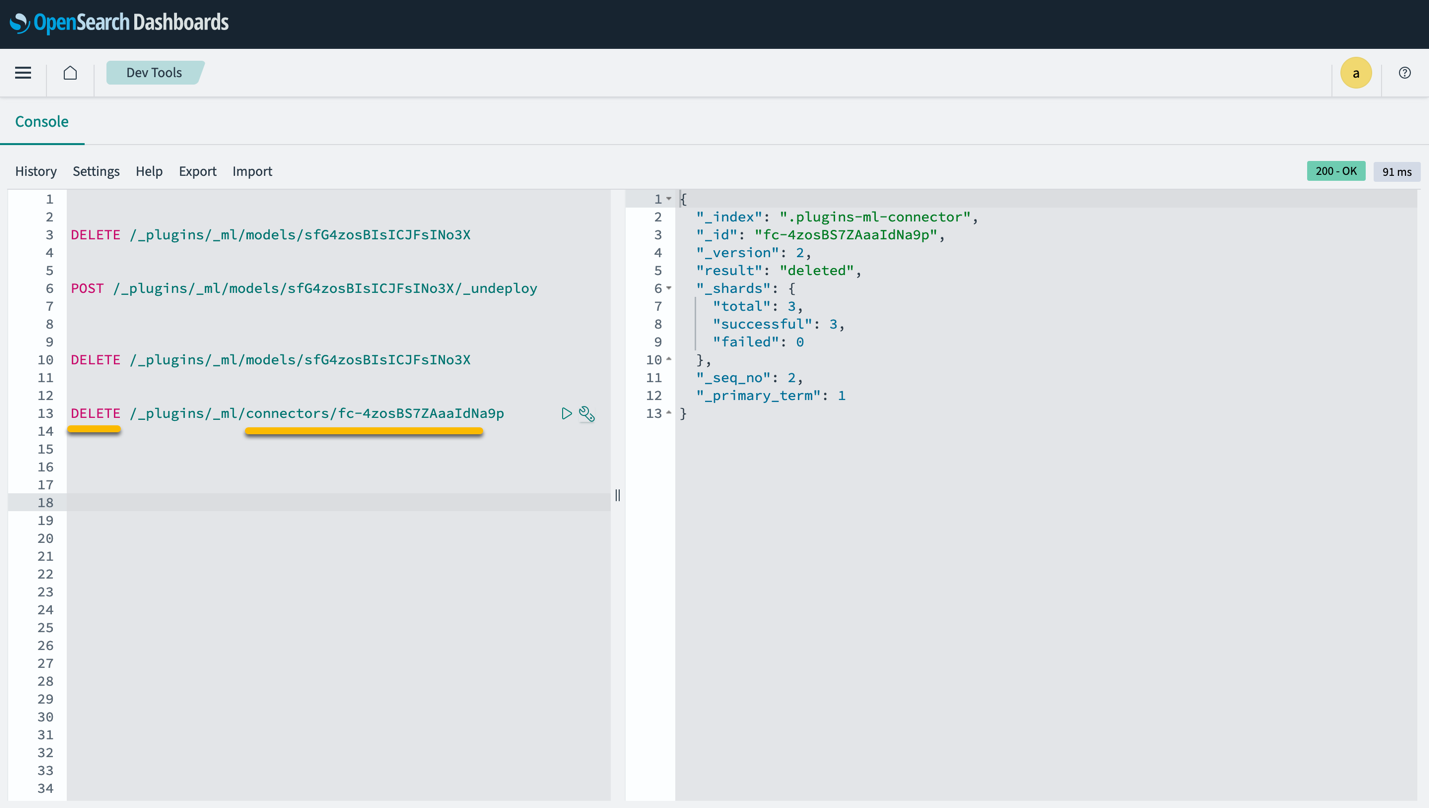
Należy pamiętać, że usunięcie stosu CloudFormation nie powoduje usunięcia modelu wdrożonego w domenie SageMaker i utworzonego łącznika AI/ML. Dzieje się tak, ponieważ te modele i łącznik mogą być powiązane z wieloma indeksami w domenie. Aby konkretnie usunąć model i powiązany z nim łącznik, użyj interfejsów API modelu, jak pokazano na poniższych zrzutach ekranu.
Po pierwsze, undeploy model z pamięci domeny OpenSearch Service:

Następnie możesz usunąć model z indeksu modelu:

Na koniec usuń złącze z indeksu złącza:
Wnioski
W tym poście dowiesz się, jak wdrożyć model w SageMaker, utworzyć łącznik AI/ML za pomocą konsoli OpenSearch Service i zbudować indeks wyszukiwania neuronowego. Możliwość skonfigurowania łączników AI/ML w usłudze OpenSearch Service upraszcza proces hydratacji wektorów, czyniąc integracje z modelami zewnętrznymi natywnymi. Indeks wyszukiwania neuronowego można utworzyć w ciągu kilku minut, korzystając z potoku pozyskiwania danych neuronowych i wyszukiwania neuronowego korzystającego z identyfikatora modelu do generowania osadzania wektorów na bieżąco podczas pozyskiwania i wyszukiwania.
Aby dowiedzieć się więcej na temat tych złączy AI/ML, zobacz Złącza Amazon OpenSearch Service AI dla usług AWS, Integracja szablonów AWS CloudFormation do wyszukiwania semantycznego, Tworzenie łączników dla platform ML innych firm.
O autorach
 Aruna Govindaraju jest architektem rozwiązań Amazon OpenSearch Specialist i współpracował z wieloma wyszukiwarkami komercyjnymi i open source. Pasjonuje się wyszukiwaniem, trafnością i doświadczeniem użytkownika. Jej wiedza na temat korelowania sygnałów użytkowników końcowych z zachowaniami wyszukiwarek pomogła wielu klientom poprawić jakość wyszukiwania.
Aruna Govindaraju jest architektem rozwiązań Amazon OpenSearch Specialist i współpracował z wieloma wyszukiwarkami komercyjnymi i open source. Pasjonuje się wyszukiwaniem, trafnością i doświadczeniem użytkownika. Jej wiedza na temat korelowania sygnałów użytkowników końcowych z zachowaniami wyszukiwarek pomogła wielu klientom poprawić jakość wyszukiwania.
 Dagney Brauna jest głównym menedżerem produktu w AWS zajmującym się OpenSearch.
Dagney Brauna jest głównym menedżerem produktu w AWS zajmującym się OpenSearch.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :ma
- :Jest
- :nie
- $W GÓRĘ
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- zdolność
- O nas
- dostęp
- dostępny
- Dodatkowy
- AI
- AI / ML
- Wszystkie kategorie
- pozwala
- również
- alternatywy
- Amazonka
- Amazon Sage Maker
- Amazon Web Services
- an
- i
- każdy
- api
- Pszczoła
- Zastosowanie
- właściwy
- architektura
- SĄ
- AS
- powiązany
- At
- Automatyzacja
- dostępny
- AWS
- Tworzenie chmury AWS
- Backend
- na podstawie
- BE
- bo
- zachowanie
- Korzyści
- pomiędzy
- obie
- Przynosi
- szeroki
- budować
- Budowanie
- by
- CAN
- walizka
- Etui
- katalog
- wybór
- Dodaj
- wybrany
- Grupa
- handlowy
- Lud
- porównać
- kompletny
- kompleksowość
- systemu
- skonfigurowany
- konfigurowanie
- Potwierdzać
- połączony
- Podłączanie
- połączenie
- Konsola
- zawierać
- kontynuować
- ciągły
- skorelowane
- Stwórz
- stworzony
- tworzy
- Obecnie
- zwyczaj
- Klientów
- Deski rozdzielcze
- dane
- Domyślnie
- określić
- zdefiniowane
- dostarczanie
- Demo
- wykazać
- demonstruje
- rozwijać
- wdrażane
- wdrażanie
- Wdrożenie
- wdraża się
- opis
- szczegółowe
- detale
- dev
- Wymiary
- Wymiary
- dokumenty
- Nie
- domena
- podczas
- każdy
- Wcześniej
- łatwy
- bądź
- osadzanie
- umożliwiać
- Punkt końcowy
- silnik
- silniki
- zapewnić
- Eter (ETH)
- przykład
- doświadczenie
- ekspertyza
- zewnętrzny
- Twarz
- ułatwia
- Cecha
- Łąka
- Znajdź
- i terminów, a
- koncentruje
- następujący
- W razie zamówieenia projektu
- Framework
- od
- w pełni
- Generować
- wygenerowane
- generuje
- otrzymać
- gif
- GitHub
- Zielony
- Rosnąć
- poprowadzi
- Have
- pomógł
- jej
- wysoka wydajność
- gospodarz
- Hosting
- gospodarze
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- Przytulanie twarzy
- uwodnienie
- IAM
- ID
- zidentyfikować
- tożsamość
- if
- podnieść
- in
- wskaźnik
- indeksy
- wskazuje
- Informacja
- Wejścia
- zamiast
- instrukcje
- integrować
- integracja
- integracje
- najnowszych
- Wprowadzenie
- IT
- JEGO
- jpg
- json
- Trzymać
- Klawisz
- język
- uruchomić
- UCZYĆ SIĘ
- dowiedziałem
- nauka
- wifecycwe
- Lista
- wykazy
- low-cost
- maszyna
- uczenie maszynowe
- robić
- Dokonywanie
- zarządzanie
- zarządzane
- kierownik
- wiele
- mapa
- mapowanie
- Pamięć
- metoda
- minuty
- ML
- model
- modele
- monitor
- monitorowanie
- jeszcze
- dużo
- wielokrotność
- musi
- Nazwa
- rodzimy
- Nawigacja
- Nawigacja
- niezbędny
- Potrzebować
- Nerwowy
- Nowości
- już dziś
- przedmiot
- of
- on
- ONE
- tylko
- koncepcja
- open source
- or
- Inne
- wydajność
- strona
- chleb
- namiętny
- Hasło
- uprawnienia
- rurociąg
- plato
- Analiza danych Platona
- PlatoDane
- wtyczka
- Post
- power
- powered
- poprzedni
- Główny
- Wcześniejszy
- wygląda tak
- Procesory
- Produkt
- product manager
- Produkcja
- Postęp
- niska zabudowa
- zapewniać
- zapewnia
- że
- cel
- zapytania
- Surowy
- surowe dane
- polecić
- odnosić się
- zdalny
- usuwanie
- obsługi produkcji rolnej, która zastąpiła
- wymagany
- Zasoby
- odpowiedź
- REST
- Efekt
- detaliczny
- zatrzymany
- powrót
- Rola
- trasy
- run
- sagemaker
- screeny
- Szukaj
- Wyszukiwarka
- Wyszukiwarki
- bezpieczeństwo
- widzieć
- wybierać
- służyć
- Bezserwerowe
- usługa
- Usługi
- zestaw
- w panelu ustawień
- ona
- pokazane
- Targi
- Sygnały
- Prosty
- upraszcza
- upraszczać
- ponieważ
- Rozwiązania
- Źródło
- specjalista
- swoiście
- stos
- Startowy
- Rynek
- Ewolucja krok po kroku
- Cel
- przechowywanie
- Z powodzeniem
- taki
- Utrzymany
- pewnie
- szablon
- XNUMX
- że
- Połączenia
- ich
- Im
- następnie
- a tym samym
- Te
- innych firm
- to
- Przez
- do
- razem
- narzędzia
- Trening
- Transformacja
- Tłumaczenie
- prawdziwy
- rodzaj
- ui
- wyjątkowy
- wyjątkowo
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Doświadczenie użytkownika
- za pomocą
- UPRAWOMOCNIĆ
- zweryfikować
- wersja
- przez
- Wideo
- Zobacz i wysłuchaj
- spacery
- była
- we
- sieć
- usługi internetowe
- jeśli chodzi o komunikację i motywację
- który
- będzie
- w
- w ciągu
- pracował
- workflow
- automatyzacja przepływu pracy
- ty
- Twój
- zefirnet