Podobnie jak praktycznie wszyscy klienci, chcesz wydać jak najmniej, jednocześnie uzyskując najlepszą możliwą wydajność. Oznacza to, że należy zwrócić uwagę na stosunek ceny do wydajności. Z Amazonka Przesunięcie ku czerwieni, możesz mieć ciastko i zjeść ciastko! Amazon Redshift zapewnia do 4.9 razy niższy koszt na użytkownika i do 7.9 razy lepszą wydajność cenową niż inne hurtownie danych w chmurze przy rzeczywistych obciążeniach przy użyciu zaawansowanych technik, takich jak skalowanie współbieżności w celu obsługi setek jednoczesnych użytkowników, ulepszone kodowanie ciągów w celu szybszej wydajności zapytań , I Bezserwerowe Amazon Redshift ulepszenia wydajności. Czytaj dalej, aby zrozumieć, dlaczego cena/wydajność ma znaczenie i w jaki sposób cena/wydajność Amazon Redshift jest miarą tego, ile kosztuje uzyskanie określonego poziomu wydajności obciążenia, czyli ROI wydajności (zwrot z inwestycji).
Ponieważ w kalkulacji ceny do wydajności uwzględniana jest zarówno cena, jak i wydajność, istnieją dwa sposoby myślenia o cenie i wydajności. Pierwszy sposób polega na utrzymaniu stałej ceny: jeśli masz 1 USD do wydania, jaką wydajność uzyskasz z hurtowni danych? Baza danych o lepszym stosunku ceny do wydajności zapewni lepszą wydajność za każdy wydany 1 USD. Dlatego też, utrzymując stałą cenę podczas porównywania dwóch hurtowni danych, które kosztują tyle samo, baza danych o lepszym stosunku ceny do wydajności będzie szybciej wykonywać zapytania. Drugim sposobem spojrzenia na stosunek ceny do wydajności jest utrzymanie wydajności na stałym poziomie: jeśli chcesz, aby zadanie zakończyło się w ciągu 10 minut, ile to będzie kosztować? Baza danych o lepszym stosunku ceny do wydajności obsłuży Twoje obciążenie w 10 minut przy niższym koszcie. Dlatego też, utrzymując stałą wydajność podczas porównywania dwóch hurtowni danych o rozmiarze zapewniającym tę samą wydajność, baza danych o lepszym stosunku ceny do wydajności będzie kosztować mniej i pozwala zaoszczędzić pieniądze.
Wreszcie kolejnym ważnym aspektem stosunku ceny do wydajności jest przewidywalność. Wiedza o tym, ile będzie kosztować hurtownia danych w miarę wzrostu liczby użytkowników hurtowni danych, ma kluczowe znaczenie dla planowania. Powinien nie tylko zapewniać obecnie najlepszy stosunek ceny do wydajności, ale także przewidywać skalowanie i zapewniać najlepszy stosunek ceny do wydajności w miarę dodawania większej liczby użytkowników i obciążeń. Idealna hurtownia danych powinna ją posiadać skala liniowa— w idealnym przypadku skalowanie hurtowni danych w celu zapewnienia dwukrotnie większej przepustowości zapytań powinno kosztować dwa razy więcej (lub mniej).
W tym poście udostępniamy wyniki wydajności, aby zilustrować, jak Amazon Redshift zapewnia znacznie lepszy stosunek ceny do wydajności w porównaniu z wiodącymi alternatywnymi hurtowniami danych w chmurze. Oznacza to, że jeśli wydasz tę samą kwotę na Amazon Redshift, co na jedną z tych innych hurtowni danych, uzyskasz lepszą wydajność dzięki Amazon Redshift. Alternatywnie, jeśli dobierzesz rozmiar klastra Redshift tak, aby zapewniał tę samą wydajność, koszty będą niższe w porównaniu z tymi alternatywami.
Cena/wydajność przy rzeczywistych obciążeniach
Możesz używać usługi Amazon Redshift do obsługi bardzo szerokiej gamy obciążeń, od przetwarzania wsadowego złożonych raportów opartych na wyodrębnianiu, przekształcaniu i ładowaniu (ETL), poprzez analizy przesyłania strumieniowego w czasie rzeczywistym, po pulpity nawigacyjne Business Intelligence (BI) o niskim opóźnieniu, które muszą obsługiwać setki, a nawet tysiące użytkowników jednocześnie, zapewniając czas reakcji poniżej sekundy i wszystko pomiędzy. Jednym ze sposobów, w jaki stale poprawiamy stosunek ceny do jakości dla naszych klientów, jest ciągłe przeglądanie danych telemetrycznych dotyczących wydajności oprogramowania i sprzętu floty Redshift w poszukiwaniu możliwości i przypadków użycia przez klientów, w których możemy jeszcze bardziej poprawić wydajność Amazon Redshift.
Oto kilka najnowszych przykładów optymalizacji wydajności opartych na telemetrii floty:
- Optymalizacje zapytań ciągów – Analizując sposób, w jaki Amazon Redshift przetwarzał różne typy danych we flocie Redshift, odkryliśmy, że optymalizacja zapytań zawierających duże ciągi znaków przyniosłaby znaczne korzyści w zakresie obciążenia pracą naszych klientów. (Omawiamy to bardziej szczegółowo w dalszej części tego postu.)
- Zautomatyzowane widoki zmaterializowane – Odkryliśmy, że klienci Amazon Redshift często uruchamiają wiele zapytań, które mają wspólne wzorce podzapytań. Na przykład kilka różnych zapytań może połączyć te same trzy tabele, korzystając z tego samego warunku złączenia. Amazon Redshift może teraz automatycznie tworzyć i utrzymywać zmaterializowane widoki, a następnie w przejrzysty sposób przepisywać zapytania, aby korzystać ze zmaterializowanych widoków, korzystając z uczenia maszynowego zautomatyzowany widok zmaterializowany funkcja autonomiczna w Amazon Redshift. Po włączeniu zautomatyzowane widoki zmaterializowane mogą w przejrzysty sposób zwiększyć wydajność zapytań powtarzających się bez jakiejkolwiek interwencji użytkownika. (Należy pamiętać, że w żadnym z wyników testów porównawczych omawianych w tym poście nie wykorzystano automatycznych widoków zmaterializowanych).
- Obciążenia o dużej współbieżności – Coraz częstszym przypadkiem użycia, jaki obserwujemy, jest wykorzystanie Amazon Redshift do obsługi obciążeń przypominających pulpit nawigacyjny. Obciążenia te charakteryzują się pożądanym czasem odpowiedzi na zapytania wynoszącym jednocyfrowe sekundy lub mniej, przy czym dziesiątki lub setki równoczesnych użytkowników wykonują zapytania jednocześnie z gwałtownym i często nieprzewidywalnym wzorcem użycia. Prototypowym przykładem jest pulpit BI wspierany przez Amazon Redshift, który odnotowuje gwałtowny wzrost ruchu w poniedziałkowe poranki, kiedy duża liczba użytkowników rozpoczyna tydzień.
Szczególnie obciążenia wymagające dużej współbieżności mają bardzo szerokie zastosowanie: większość obciążeń hurtowni danych działa współbieżnie i nierzadko zdarza się, że setki, a nawet tysiące użytkowników uruchamiają zapytania w serwisie Amazon Redshift w tym samym czasie. Amazon Redshift został zaprojektowany, aby zapewnić przewidywalny i szybki czas odpowiedzi na zapytania. Redshift Serverless robi to automatycznie za Ciebie, dodając i usuwając obliczenia zgodnie z potrzebami, aby zapewnić szybki i przewidywalny czas odpowiedzi na zapytania. Oznacza to, że pulpit nawigacyjny oparty na Redshift Serverless, który ładuje się szybko, gdy uzyskuje do niego dostęp jeden lub dwóch użytkowników, będzie nadal szybko się ładować, nawet jeśli wielu użytkowników ładuje go w tym samym czasie.
Aby zasymulować tego typu obciążenie, użyliśmy testu porównawczego pochodzącego z TPC-DS z zestawem danych o wielkości 100 GB. TPC-DS to standardowy test porównawczy, który obejmuje różnorodne typowe zapytania dotyczące hurtowni danych. Przy tej stosunkowo małej skali wynoszącej 100 GB zapytania w tym teście porównawczym działają na Redshift Serverless średnio w ciągu kilku sekund, co jest reprezentatywne dla oczekiwań użytkowników ładujących interaktywny pulpit BI. Przeprowadziliśmy od 1 do 200 równoczesnych testów tego testu porównawczego, symulując od 1 do 200 użytkowników próbujących jednocześnie załadować pulpit nawigacyjny. Powtórzyliśmy także test z kilkoma popularnymi alternatywnymi hurtowniami danych w chmurze, które również obsługują automatyczne skalowanie w poziomie (jeśli znasz post Amazon Redshift kontynuuje swoją pozycję lidera w stosunku ceny do wydajności, nie uwzględniliśmy Konkurenta A, ponieważ nie obsługuje on automatycznego skalowania w górę). Zmierzyliśmy średni czas odpowiedzi na zapytanie, czyli czas oczekiwania użytkownika na zakończenie zapytania (lub załadowanie panelu). Wyniki przedstawiono na poniższym wykresie.
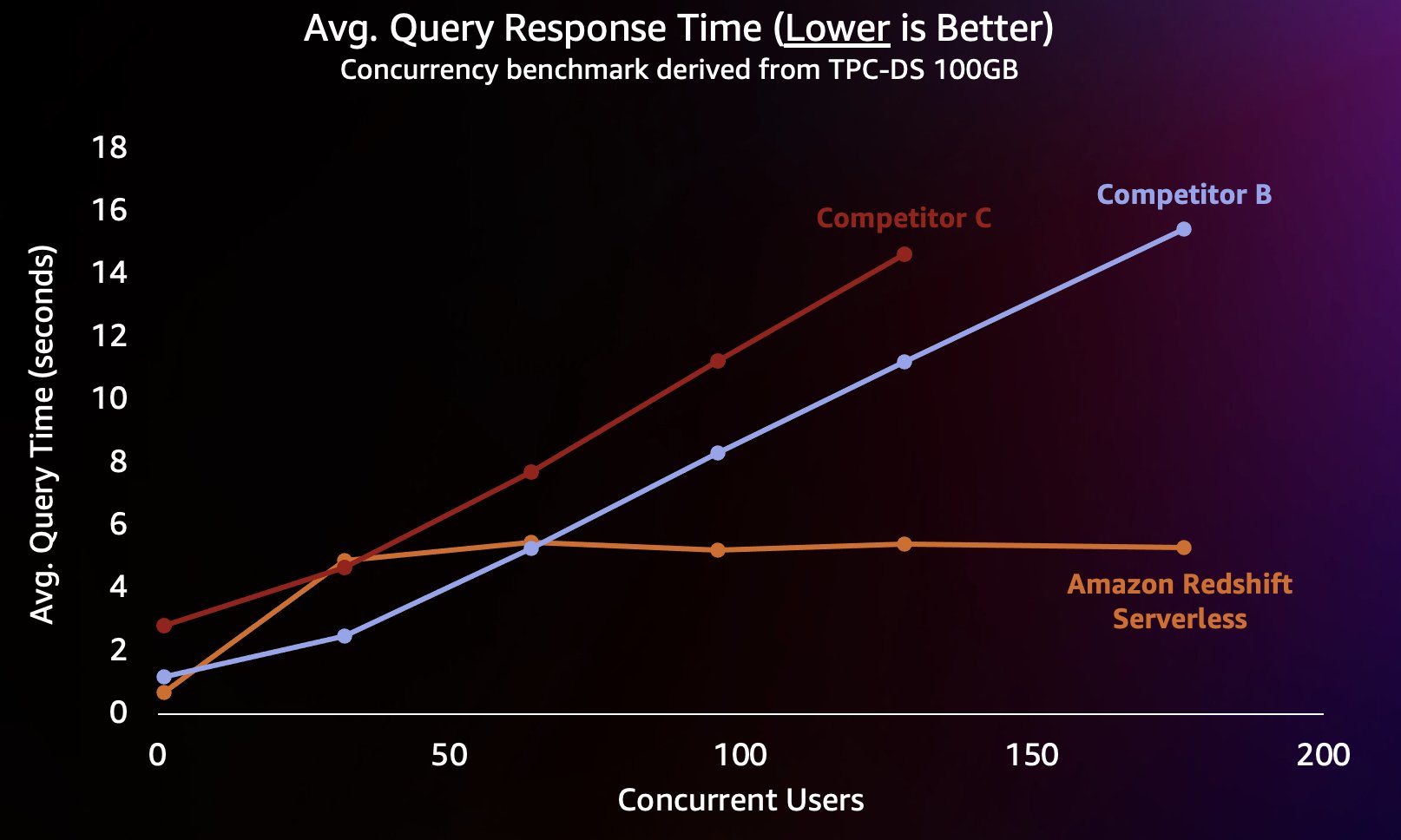
Konkurent B dobrze się skaluje do około 64 jednoczesnych zapytań, kiedy to nie jest w stanie zapewnić dodatkowej mocy obliczeniowej i zapytania zaczynają ustawiać się w kolejce, co prowadzi do wydłużenia czasu odpowiedzi na zapytania. Chociaż Konkurent C może skalować się automatycznie, skaluje się w celu niższej przepustowości zapytań niż zarówno Amazon Redshift, jak i Konkurent B i nie jest w stanie utrzymać niskiego czasu wykonywania zapytań. Ponadto nie obsługuje kolejkowania zapytań w przypadku wyczerpania się mocy obliczeniowej, co uniemożliwia skalowanie poza około 128 jednoczesnych użytkowników. Złożenie dodatkowych zapytań wykraczających poza ten zakres jest odrzucane przez system.
W tym przypadku Redshift Serverless jest w stanie utrzymać stosunkowo spójny czas odpowiedzi na zapytanie na poziomie około 5 sekund, nawet jeśli setki użytkowników uruchamia zapytania w tym samym czasie. Średni czas odpowiedzi na zapytania dla Konkurentów B i C stale rośnie wraz ze wzrostem obciążenia hurtowni, co powoduje, że użytkownicy muszą czekać dłużej (do 16 sekund) na zwrot zapytań, gdy hurtownia danych jest zajęta. Oznacza to, że jeśli użytkownik próbuje odświeżyć pulpit nawigacyjny (który może nawet przesłać kilka jednoczesnych zapytań po ponownym załadowaniu), Amazon Redshift będzie w stanie utrzymać znacznie spójny czas ładowania pulpitu nawigacyjnego, nawet jeśli pulpit nawigacyjny jest ładowany przez dziesiątki lub setki innych użytkowników w tym samym czasie.
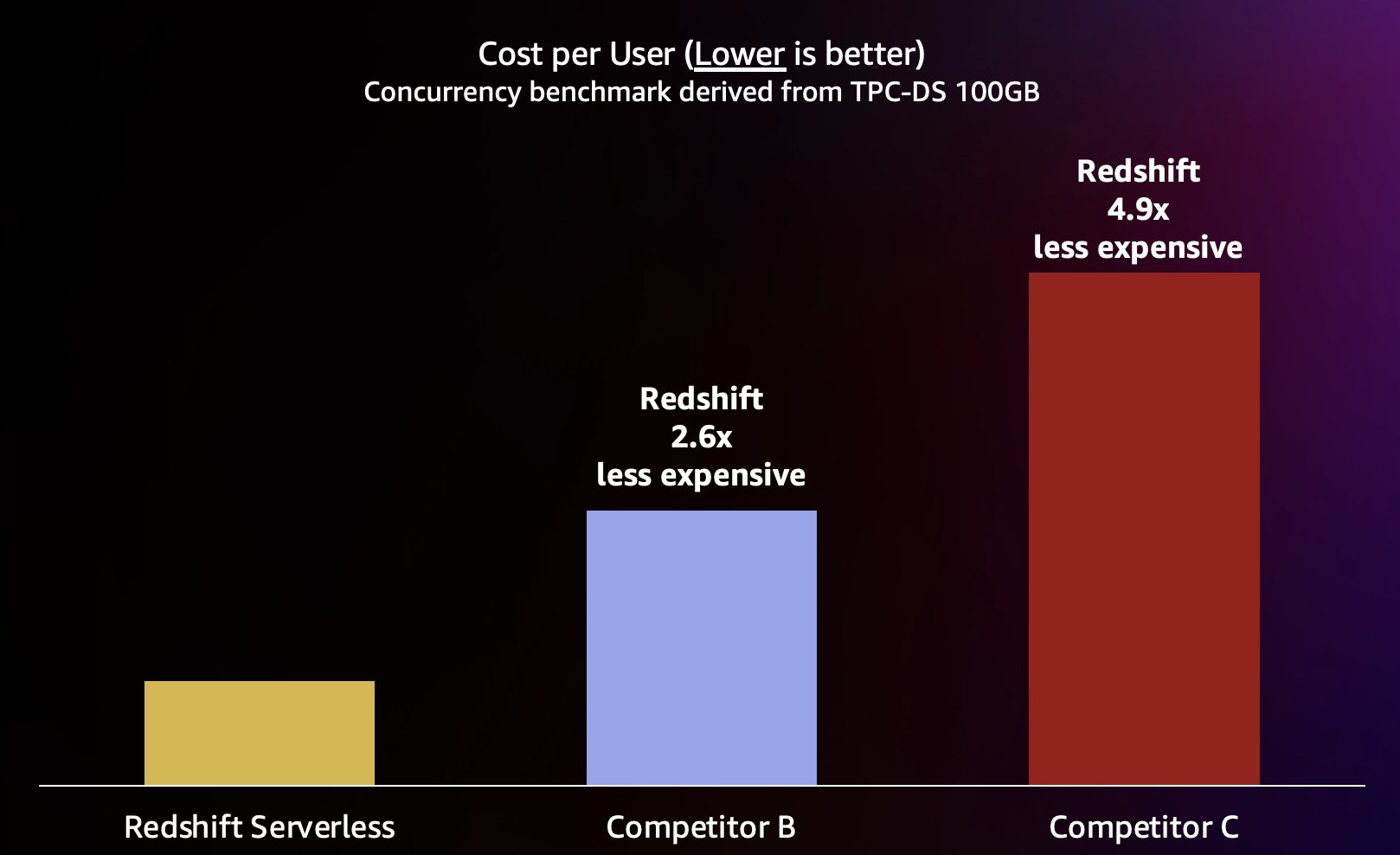
Ponieważ Amazon Redshift jest w stanie zapewnić bardzo wysoką przepustowość zapytań dla krótkich zapytań (o czym pisaliśmy w Amazon Redshift kontynuuje swoją pozycję lidera w stosunku ceny do wydajności), jest również w stanie obsłużyć większą liczbę współbieżności podczas bardziej wydajnego skalowania, a zatem przy znacznie niższych kosztach. Aby to określić ilościowo, patrzymy na stosunek ceny do wydajności, korzystając z opublikowanych danych ceny na żądanie dla każdego z magazynów w poprzednim teście, co przedstawiono na poniższym wykresie. Warto zauważyć, że za pomocą Instancje zarezerwowane (RI), zwłaszcza 3-letnie RI zakupione z opcją płatności z góry, mają najniższy koszt uruchomienia usługi Amazon Redshift w udostępnianych klastrach, co zapewnia najlepszy względny stosunek ceny do wydajności w porównaniu z opcjami RI na żądanie lub innymi opcjami RI.

Zatem Amazon Redshift nie tylko jest w stanie zapewnić lepszą wydajność przy większej współbieżności, ale jest w stanie to zrobić przy znacznie niższych kosztach. Każdy punkt danych na wykresie ceny do wydajności odpowiada kosztowi uruchomienia testu porównawczego przy określonej współbieżności. Ponieważ stosunek ceny do wydajności jest liniowy, możemy podzielić koszt uruchomienia testu porównawczego przy dowolnej współbieżności przez współbieżność (liczbę jednoczesnych użytkowników na tym wykresie), aby dowiedzieć się, ile kosztuje dodanie każdego nowego użytkownika dla tego konkretnego testu porównawczego.
Powyższe wyniki są łatwe do powtórzenia. Wszystkie zapytania użyte w benchmarku są dostępne w naszym Repozytorium GitHub a wydajność mierzy się poprzez uruchomienie hurtowni danych, włączenie skalowania współbieżności w Amazon Redshift (lub odpowiednią funkcję automatycznego skalowania w innych hurtowniach), załadowanie danych od razu po wyjęciu z pudełka (bez ręcznego dostrajania lub konfiguracji specyficznej dla bazy danych), a następnie uruchomienie równoczesny strumień zapytań przy współbieżnościach od 1 do 200 w krokach co 32 w każdej hurtowni danych. To samo repozytorium GitHub odwołuje się do wstępnie wygenerowanych (i niezmodyfikowanych) danych TPC-DS w formacie Usługa Amazon Simple Storage (Amazon S3) w różnych skalach przy użyciu oficjalnego zestawu do generowania danych TPC-DS.
Optymalizacja obciążeń wymagających dużej liczby ciągów
Jak wspomniano wcześniej, zespół Amazon Redshift nieustannie szuka nowych możliwości, aby zapewnić naszym klientom jeszcze lepszy stosunek ceny do jakości. Jednym z ulepszeń, które niedawno wprowadziliśmy i które znacznie poprawiło wydajność, jest optymalizacja, która przyspiesza wydajność zapytań za pomocą danych ciągów. Możesz na przykład znaleźć łączny przychód wygenerowany w sklepach detalicznych zlokalizowanych w Nowym Jorku za pomocą zapytania typu SELECT sum(price) FROM sales WHERE city = ‘New York’. To zapytanie stosuje predykat do danych w postaci ciągu znaków (city = ‘New York’). Jak możesz sobie wyobrazić, przetwarzanie danych ciągów jest wszechobecne w aplikacjach hurtowni danych.
Aby określić, jak często obciążenia klientów uzyskują dostęp do ciągów znaków, przeprowadziliśmy szczegółową analizę wykorzystania typów danych ciągów, korzystając z telemetrii floty dziesiątek tysięcy klastrów klientów zarządzanych przez Amazon Redshift. Z naszej analizy wynika, że w 90% skupień kolumny łańcuchowe stanowią co najmniej 30% wszystkich kolumn, a w 50% skupień kolumny łańcuchowe stanowią co najmniej 50% wszystkich kolumn. Co więcej, większość wszystkich zapytań uruchamianych na platformie hurtowni danych w chmurze Amazon Redshift uzyskuje dostęp do co najmniej jednej kolumny ciągu. Innym ważnym czynnikiem jest to, że dane łańcuchowe mają bardzo często niską liczność, co oznacza, że kolumny zawierają stosunkowo niewielki zestaw unikalnych wartości. Na przykład, chociaż orders tabela reprezentująca dane sprzedażowe może zawierać miliardy wierszy, an order_status kolumna w tej tabeli może zawierać tylko kilka unikalnych wartości w miliardach wierszy, np pending, in process, completed.
W chwili pisania tego tekstu większość kolumn ciągów w Amazon Redshift jest skompresowana LZO or ZSTD algorytmy. Są to dobre algorytmy kompresji ogólnego przeznaczenia, ale nie są zaprojektowane tak, aby wykorzystywać dane łańcuchowe o niskiej kardynalności. W szczególności wymagają dekompresji danych przed operacją i są mniej wydajne w wykorzystaniu przepustowości pamięci sprzętowej. W przypadku danych o niskiej kardynalności istnieje inny typ kodowania, który może być bardziej optymalny: BYTEDYKT. To kodowanie wykorzystuje schemat kodowania słownikowego, który umożliwia silnikowi bazy danych działanie bezpośrednio na skompresowanych danych bez konieczności ich wcześniejszej dekompresji.
Aby jeszcze bardziej poprawić stosunek ceny do wydajności w przypadku obciążeń wymagających dużej liczby ciągów, Amazon Redshift wprowadza teraz dodatkowe ulepszenia wydajności, które przyspieszają skanowanie i ocenę predykcji w porównaniu z kolumnami ciągów o niskiej liczności, które są zakodowane jako BYTEDICT, od 5 do 63 razy szybciej (zobacz wyniki w następna sekcja) w porównaniu z alternatywnymi kodowaniami kompresyjnymi, takimi jak LZO lub ZSTD. Amazon Redshift osiąga tę poprawę wydajności poprzez wektoryzację skanów w lekkich, wydajnych procesorowo, zakodowanych w technologii BYTEDICT kolumnach ciągów o niskiej kardynalności. Te optymalizacje przetwarzania ciągów efektywnie wykorzystują przepustowość pamięci zapewnianą przez nowoczesny sprzęt, umożliwiając analizę danych ciągów w czasie rzeczywistym. Te nowo wprowadzone możliwości wydajności są optymalne w przypadku kolumn ciągów o niskiej liczności (do kilkuset unikalnych wartości ciągów).
Możesz automatycznie skorzystać z tego nowego ulepszenia ciągów o wysokiej wydajności, włączając automatyczna optymalizacja stołu w hurtowni danych Amazon Redshift. Jeśli nie masz włączonej automatycznej optymalizacji stołów, możesz otrzymywać rekomendacje od Doradca Amazon Redshift w konsoli Amazon Redshift na temat przydatności kolumny ciągu do kodowania BYTEDICT. Można także definiować nowe tabele zawierające kolumny łańcuchowe o niskiej liczności z kodowaniem BYTEDICT. Ulepszenia ciągów w Amazon Redshift są teraz dostępne we wszystkich regionach AWS, gdzie Dostępna jest funkcja Amazon Redshift.
Wyniki osiągów
Aby zmierzyć wpływ naszych ulepszeń ciągów na wydajność, wygenerowaliśmy zestaw danych o rozmiarze 10 TB (terabajtów), który składał się z danych ciągów o niskiej kardynalności. Wygenerowaliśmy trzy wersje danych przy użyciu krótkich, średnich i długich ciągów, odpowiadających 25., 50. i 75. percentylowi długości ciągów z telemetrii floty Amazon Redshift. Dwukrotnie załadowaliśmy te dane do Amazon Redshift, kodując je w jednym przypadku przy użyciu kompresji LZO, a w drugim przy użyciu kompresji BYTEDICT. Na koniec zmierzyliśmy wydajność zapytań wymagających dużego skanowania, które zwracają wiele wierszy (90% tabeli), średnią liczbę wierszy (50% tabeli) i kilka wierszy (1% tabeli) w ciągu tych niskich -zestawy danych ciągów liczności. Wyniki wydajności podsumowano na poniższym wykresie.

Zapytania z predykatami pasującymi do wysokiego odsetka wierszy odnotowały poprawę 5–30 razy dzięki nowemu wektorowemu kodowaniu BYTEDICT w porównaniu z LZO, natomiast zapytania z predykatami pasującymi do niskiego odsetka wierszy odnotowały poprawę 10–63 razy w tym wewnętrznym teście.
Redshift Bezserwerowy stosunek ceny do wydajności
Oprócz wyników wydajności przy dużej współbieżności przedstawionych w tym poście, wykorzystaliśmy także test porównawczy Cloud Data Warehouse oparty na TPC-DS, aby porównać stosunek ceny do wydajności Redshift Serverless z innymi hurtowniami danych korzystającymi z większego zestawu danych o pojemności 3 TB. Wybraliśmy hurtownie danych o podobnej cenie, w tym przypadku w granicach 10% z 32 USD za godzinę, przy zastosowaniu publicznie dostępnych cen na żądanie. Wyniki te pokazują, że podobnie jak instancje Amazon Redshift RA3, Redshift Serverless zapewnia lepszy stosunek ceny do wydajności w porównaniu z innymi wiodącymi hurtowniami danych w chmurze. Jak zawsze wyniki te można odtworzyć za pomocą naszych skryptów SQL w naszym pliku Repozytorium GitHub.

Zachęcamy do wypróbowania Amazon Redshift przy użyciu własnego dowód koncepcji obciążeń roboczych, co jest najlepszym sposobem sprawdzenia, jak Amazon Redshift może zaspokoić Twoje potrzeby w zakresie analizy danych.
Znajdź najlepszy stosunek ceny do wydajności dla swoich obciążeń
Testy porównawcze użyte w tym poście pochodzą ze standardowego testu porównawczego TPC-DS i mają następujące cechy:
- Schemat i dane są używane w niezmienionej postaci z TPC-DS.
- Zapytania są generowane przy użyciu oficjalnego zestawu TPC-DS z parametrami zapytań generowanymi przy użyciu domyślnego losowego materiału siewnego zestawu TPC-DS. Warianty zapytań zatwierdzone przez TPC są używane w hurtowni, jeśli hurtownia nie obsługuje dialektu SQL domyślnego zapytania TPC-DS.
- Test obejmuje 99 zapytań TPC-DS SELECT. Nie obejmuje etapów konserwacji i przepustowości.
- W przypadku pojedynczego testu współbieżności 3 TB przeprowadzono trzy cykle zasilania i dla każdej hurtowni danych wybrano najlepszy przebieg.
- Stosunek ceny do wydajności zapytań TPC-DS oblicza się jako koszt za godzinę (USD) pomnożony przez czas działania testu porównawczego w godzinach, co odpowiada kosztowi uruchomienia testu porównawczego. W przypadku wszystkich hurtowni danych stosowane są najnowsze opublikowane ceny usług na żądanie, a nie, jak wspomniano wcześniej, ceny instancji zarezerwowanych.
Nazywamy to testem porównawczym Cloud Data Warehouse i możesz łatwo odtworzyć wyniki poprzedniego testu porównawczego, korzystając ze skryptów, zapytań i danych dostępnych w naszym Repozytorium GitHub. Wywodzi się on z testów porównawczych TPC-DS opisanych w tym poście i jako taki nie jest porównywalny z opublikowanymi wynikami TPC-DS, ponieważ wyniki naszych testów nie są zgodne z oficjalną specyfikacją.
Wnioski
Firma Amazon Redshift dąży do zapewnienia najlepszego w branży stosunku ceny do wydajności dla najszerszej gamy obciążeń. Redshift Serverless skaluje się liniowo, zapewniając najlepszy (najniższy) stosunek ceny do wydajności, obsługując setki jednoczesnych użytkowników przy jednoczesnym zachowaniu stałych czasów odpowiedzi na zapytania. W oparciu o wyniki testów omówione w tym poście, Amazon Redshift ma do 2.6 razy lepszy stosunek ceny do jakości przy tym samym poziomie współbieżności w porównaniu do najbliższego konkurenta (Konkurent B). Jak wspomniano wcześniej, korzystanie z Instancji Zarezerwowanych z 3-letnią opcją z góry zapewnia najniższy koszt uruchomienia usługi Amazon Redshift, co skutkuje jeszcze lepszą względną wydajnością cenową w porównaniu z cenami instancji na żądanie, które zastosowaliśmy w tym poście. Nasze podejście do ciągłego doskonalenia wydajności obejmuje unikalne połączenie obsesji klientów na punkcie zrozumienia przypadków ich użycia i powiązanych z nimi wąskich gardeł skalowalności w połączeniu z ciągłą analizą danych floty w celu zidentyfikowania możliwości wprowadzenia znaczących optymalizacji wydajności.
Każde obciążenie ma unikalne cechy, więc jeśli dopiero zaczynasz, a dowód koncepcji to najlepszy sposób, aby zrozumieć, w jaki sposób Amazon Redshift może obniżyć koszty, zapewniając jednocześnie lepszą wydajność. Prowadząc własną weryfikację koncepcji, ważne jest, aby skupić się na właściwych metrykach — przepustowości zapytań (liczbie zapytań na godzinę), czasie odpowiedzi i stosunku ceny do wydajności. Możesz podjąć decyzję w oparciu o dane, samodzielnie przeprowadzając weryfikację koncepcji lub z pomocą z AWS lub a partner w zakresie integracji systemów i doradztwa.
Aby być na bieżąco z najnowszymi osiągnięciami w Amazon Redshift, śledź Co nowego w Amazon Redshift karmić.
O autorach
 Stefana Gromola jest starszym inżynierem ds. wydajności w zespole Amazon Redshift, gdzie jest odpowiedzialny za pomiar i poprawę wydajności Redshift. W wolnym czasie lubi gotować, bawić się z trzema synami i rąbać drewno na opał.
Stefana Gromola jest starszym inżynierem ds. wydajności w zespole Amazon Redshift, gdzie jest odpowiedzialny za pomiar i poprawę wydajności Redshift. W wolnym czasie lubi gotować, bawić się z trzema synami i rąbać drewno na opał.
 Ravi Animi jest starszym liderem zarządzania produktami w zespole Amazon Redshift i zarządza kilkoma obszarami funkcjonalnymi usługi hurtowni danych w chmurze Amazon Redshift, w tym wydajnością, analityką przestrzenną, pozyskiwaniem strumieniowym i strategiami migracji. Ma doświadczenie z relacyjnymi bazami danych, wielowymiarowymi bazami danych, technologiami IoT, usługami w zakresie infrastruktury pamięci masowej i obliczeniowej, a ostatnio jako założyciel startupu wykorzystującego sztuczną inteligencję/głębokie uczenie się, wizję komputerową i robotykę.
Ravi Animi jest starszym liderem zarządzania produktami w zespole Amazon Redshift i zarządza kilkoma obszarami funkcjonalnymi usługi hurtowni danych w chmurze Amazon Redshift, w tym wydajnością, analityką przestrzenną, pozyskiwaniem strumieniowym i strategiami migracji. Ma doświadczenie z relacyjnymi bazami danych, wielowymiarowymi bazami danych, technologiami IoT, usługami w zakresie infrastruktury pamięci masowej i obliczeniowej, a ostatnio jako założyciel startupu wykorzystującego sztuczną inteligencję/głębokie uczenie się, wizję komputerową i robotykę.
 Aamera Shaha jest starszym inżynierem w zespole Amazon Redshift Service.
Aamera Shaha jest starszym inżynierem w zespole Amazon Redshift Service.
 Sanketa Hase’a jest menedżerem ds. rozwoju oprogramowania w zespole Amazon Redshift Service.
Sanketa Hase’a jest menedżerem ds. rozwoju oprogramowania w zespole Amazon Redshift Service.
 Orestis Polichroniou jest głównym inżynierem w zespole Amazon Redshift Service.
Orestis Polichroniou jest głównym inżynierem w zespole Amazon Redshift Service.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :ma
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 10
- 100
- 16
- 32
- 7
- 9
- a
- Zdolny
- O nas
- przyspiesza
- dostęp
- dostęp
- Osiąga
- w poprzek
- w dodatku
- dodanie
- dodatek
- Dodatkowy
- zaawansowany
- Korzyść
- przyznane
- przed
- Algorytmy
- Wszystkie kategorie
- pozwala
- również
- alternatywny
- alternatywy
- Chociaż
- zawsze
- Amazonka
- Amazon Web Services
- ilość
- an
- analiza
- analityka
- Analizując
- i
- Inne
- każdy
- aplikacje
- Stosowanie
- podejście
- SĄ
- obszary
- na około
- AS
- aspekt
- powiązany
- At
- Uwaga
- samochód
- zautomatyzowane
- automatycznie
- automatycznie
- dostępny
- średni
- AWS
- b
- przepustowość
- na podstawie
- BE
- bo
- zanim
- rozpocząć
- jest
- Benchmark
- Benchmarki
- korzyści
- BEST
- Ulepsz Swój
- pomiędzy
- Poza
- miliardy
- obie
- wąskie gardła
- Pudełko
- przynieść
- szeroki
- biznes
- business intelligence
- zajęty
- ale
- by
- CAKE
- obliczony
- obliczenie
- wezwanie
- CAN
- możliwości
- walizka
- Etui
- Charakterystyka
- charakteryzuje
- Wykres
- okazały
- wybrał
- Miasto
- Chmura
- Grupa
- Kolumna
- kolumny
- połączenie
- zobowiązany
- wspólny
- porównywalny
- porównać
- w porównaniu
- porównanie
- konkurent
- konkurenci
- kompleks
- wykonania
- obliczać
- komputer
- Wizja komputerowa
- pojęcie
- równoległy
- warunek
- przeprowadzone
- zgodny
- Konsola
- stały
- stale
- stanowić
- consulting
- zawierać
- nieustannie
- kontynuować
- ciągły
- ciągły
- bez przerwy
- gotowanie
- Odpowiedni
- Koszty:
- Koszty:
- sprzężony
- Stwórz
- istotny
- klient
- Klientów
- tablica rozdzielcza
- Deski rozdzielcze
- dane
- analiza danych
- Analityka danych
- analiza danych
- zbiór danych
- hurtownia danych
- magazyn danych
- sterowane danymi
- Baza danych
- Bazy danych
- zbiory danych
- Data
- decyzja
- Domyślnie
- określić
- dostarczyć
- dostarczanie
- dostarcza
- Pochodny
- opisane
- zaprojektowany
- życzenia
- detal
- szczegółowe
- oprogramowania
- wydarzenia
- różne
- bezpośrednio
- dyskutować
- omówione
- Różnorodność
- podzielić
- do
- robi
- Nie
- nie
- napędzany
- każdy
- Wcześniej
- z łatwością
- jeść
- Efektywne
- wydajny
- skutecznie
- włączony
- umożliwiając
- zachęcać
- silnik
- inżynier
- wzmocnione
- wzmocnienie
- ulepszenia
- Wchodzę
- Równoważny
- szczególnie
- Eter (ETH)
- oceny
- Parzyste
- wszystko
- przykład
- przykłady
- oczekiwać
- doświadczenie
- wyciąg
- czynnik
- znajomy
- daleko
- FAST
- szybciej
- Cecha
- kilka
- W końcu
- Znajdź
- koniec
- i terminów, a
- FLOTA
- Skupiać
- obserwuj
- następujący
- W razie zamówieenia projektu
- znaleziono
- założyciel
- od
- funkcjonalny
- dalej
- ogólny cel
- wygenerowane
- generacja
- otrzymać
- miejsce
- GitHub
- daje
- będzie
- dobry
- Rozwój
- Rośnie
- uchwyt
- sprzęt komputerowy
- Have
- mający
- he
- Wysoki
- wyższy
- jego
- przytrzymaj
- przytrzymanie
- godzina
- GODZINY
- W jaki sposób
- HTML
- http
- HTTPS
- cetnar
- Setki
- idealny
- idealnie
- zidentyfikować
- if
- zilustrować
- obraz
- Rezultat
- ważny
- ważny aspekt
- podnieść
- ulepszony
- poprawa
- ulepszenia
- poprawy
- in
- zawierać
- obejmuje
- Włącznie z
- Zwiększać
- wzrosła
- Zwiększenia
- wskazuje
- przemysłu
- Infrastruktura
- przykład
- instancje
- integracja
- Inteligencja
- interaktywne
- wewnętrzny
- interwencja
- najnowszych
- wprowadzono
- wprowadzenie
- inwestycja
- dotyczy
- Internet przedmiotów
- IT
- JEGO
- przystąpić
- jpg
- właśnie
- Trzymać
- zestaw
- Wiedząc
- duży
- większe
- później
- firmy
- najnowsze osiągnięcia
- uruchomiona
- wodowanie
- lider
- prowadzący
- nauka
- najmniej
- mniej
- poziom
- lekki
- lubić
- mało
- załadować
- załadunek
- masa
- usytuowany
- długo
- dłużej
- Popatrz
- poszukuje
- niski
- niższy
- najniższy
- utrzymać
- utrzymanie
- konserwacja
- Większość
- robić
- zarządzane
- i konserwacjami
- kierownik
- zarządza
- podręcznik
- wiele
- Mecz
- Matters
- Może..
- znaczenie
- znaczy
- zmierzyć
- mierzona
- zmierzenie
- średni
- Poznaj nasz
- Pamięć
- wzmiankowany
- może
- migracja
- minuty
- Nowoczesne technologie
- Poniedziałek
- pieniądze
- jeszcze
- Ponadto
- większość
- dużo
- mianowicie
- Potrzebować
- potrzebne
- wymagania
- Nowości
- I Love New York
- nowy jork
- nowo
- Następny
- Nie
- noty
- zauważyć
- Zauważając
- już dziś
- numer
- of
- urzędnik
- często
- on
- Na żądanie
- ONE
- tylko
- działać
- eksploatowane
- Szanse
- Optymalny
- optymalizacja
- optymalizacji
- Option
- Opcje
- or
- Inne
- ludzkiej,
- na zewnątrz
- koniec
- własny
- parametry
- szczególny
- Wzór
- wzory
- Zapłacić
- płatność
- dla
- procent
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- planowanie
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- gra
- punkt
- Popularny
- możliwy
- Post
- power
- Możliwy do przewidzenia
- przedstawione
- zapobiega
- Cena
- wycena
- Główny
- obrobiony
- przetwarzanie
- Produkt
- zarządzanie produktem
- dowód
- dowód koncepcji
- zapewniać
- publicznie
- opublikowany
- zakupione
- zapytania
- szybko
- przypadkowy
- Czytaj
- Prawdziwy świat
- w czasie rzeczywistym
- otrzymać
- niedawny
- niedawno
- zalecenia
- referencje
- regiony
- Odrzucony..
- względny
- stosunkowo
- usuwanie
- powtórzony
- powtarzalne
- replikowane
- Raporty
- przedstawiciel
- reprezentowanie
- wymagać
- zarezerwowany
- odpowiedź
- odpowiedzialny
- wynikły
- Efekt
- detaliczny
- powrót
- dochód
- przeglądu
- prawo
- robotyka
- ROI
- run
- bieganie
- działa
- sole
- taki sam
- Zapisz
- zobaczył
- Skalowalność
- Skala
- waga
- skalowaniem
- skany
- schemat
- skrypty
- druga
- sekund
- Sekcja
- widzieć
- nasienie
- senior
- służyć
- Bezserwerowe
- usługa
- Usługi
- zestaw
- ustawienie
- kilka
- Share
- Short
- powinien
- pokazać
- pokazane
- znaczący
- znacznie
- Podobnie
- Prosty
- jednocześnie
- pojedynczy
- Rozmiar
- wielkości
- mały
- So
- Tworzenie
- rozwoju oprogramowania
- Przestrzenne
- specyfikacja
- określony
- prędkość
- wydać
- spędził
- kolec
- SQL
- początek
- rozpoczęty
- startup
- pobyt
- stale
- Cel
- przechowywanie
- sklep
- bezpośredni
- strategie
- strumień
- Streaming
- sznur
- Zatwierdź
- taki
- stosowność
- wsparcie
- Wspierający
- system
- stół
- Brać
- Zadania
- zespół
- Techniki
- Technologies
- powiedzieć
- kilkadziesiąt
- test
- Testy
- niż
- że
- Połączenia
- ich
- następnie
- Tam.
- w związku z tym
- Te
- one
- myśleć
- to
- tych
- tysiące
- trzy
- wydajność
- czas
- czasy
- do
- już dziś
- Kwota produktów:
- ruch drogowy
- Przekształcać
- transparentnie
- próbować
- stara
- Dwa razy
- drugiej
- rodzaj
- typy
- typowy
- wszechobecny
- niezdolny
- Niezwykły
- zrozumieć
- wyjątkowy
- nieobliczalny
- aż do
- us
- Stosowanie
- USD
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- zastosowania
- za pomocą
- Wartości
- różnorodność
- różnorodny
- początku.
- widoki
- prawie
- wizja
- czekać
- chcieć
- Magazyn
- była
- Droga..
- sposoby
- we
- sieć
- usługi internetowe
- tydzień
- DOBRZE
- były
- Co
- jeśli chodzi o komunikację i motywację
- natomiast
- który
- Podczas
- dlaczego
- szeroki
- będzie
- w
- w ciągu
- bez
- wartość
- by
- pisanie
- napisał
- york
- ty
- Twój
- zefirnet