Pracownia Kleju AWS jest teraz zintegrowany z DataBrew kleju AWS. AWS Glue Studio to interfejs graficzny, który ułatwia tworzenie, uruchamianie i monitorowanie zadań wyodrębniania, przekształcania i ładowania (ETL) w Klej AWS. DataBrew to wizualne narzędzie do przygotowywania danych, które umożliwia czyszczenie i normalizację danych bez pisania kodu. Ponad 200 przekształceń, które zapewnia, jest teraz dostępnych do użycia w wizualnym zadaniu AWS Glue Studio.
W DataBrew a Przepis to zestaw kroków transformacji danych, które można tworzyć interaktywnie w intuicyjnym interfejsie wizualnym. W tym poście zobaczysz, jak użyć kompilacji receptury w DataBrew, a następnie zastosować ją jako część wizualnego zadania ETL AWS Glue Studio.
Obecni użytkownicy DataBrew również skorzystają z tej integracji – możesz teraz uruchamiać swoje przepisy jako część większego wizualnego przepływu pracy ze wszystkimi innymi komponentami zapewnianymi przez AWS Glue Studio, oprócz możliwości korzystania z zaawansowanej konfiguracji zadań i najnowszej wersji silnika AWS Glue .
Ta integracja przynosi wyraźne korzyści obecnym użytkownikom obu narzędzi:
- Masz scentralizowany widok w AWS Glue Studio całego diagramu ETL, od końca do końca
- Możesz interaktywnie zdefiniować przepis, przeglądając wartości, statystyki i dystrybucję w konsoli DataBrew, a następnie ponownie wykorzystać tę przetestowaną i wersjonowaną logikę przetwarzania w zadaniach wizualnych AWS Glue Studio
- Możesz zorganizować wiele receptur DataBrew w zadaniu AWS Glue ETL lub nawet wiele zadań za pomocą przepływów pracy AWS Glue
- Przepisy DataBrew mogą teraz korzystać z funkcji zadań AWS Glue, takich jak zakładki do przyrostowego przetwarzania danych, automatyczne ponawianie prób, automatyczne skalowanie lub grupowanie małych plików w celu zwiększenia wydajności
Omówienie rozwiązania
W naszym fikcyjnym przypadku użycia wymagane jest wyczyszczenie syntetycznego zestawu danych o roszczeniach medycznych utworzonego dla tego stanowiska, który ma pewne problemy z jakością danych wprowadzone celowo w celu zademonstrowania możliwości DataBrew w zakresie przygotowania danych. Następnie dane o roszczeniach są pobierane do katalogu (aby były widoczne dla analityków), po wzbogaceniu ich o kilka istotnych szczegółów na temat odpowiednich dostawców usług medycznych pochodzących z osobnego źródła.
Rozwiązanie składa się z zadania wizualnego AWS Glue Studio, które odczytuje dwa pliki CSV odpowiednio z oświadczeniami i dostawcami. Zadanie stosuje recepturę pierwszego w celu rozwiązania problemów z jakością, wybiera kolumny z drugiego, łączy oba zestawy danych i ostatecznie przechowuje wynik w Usługa Amazon Simple Storage (Amazon S3), tworząc tabelę w katalogu, aby dane wyjściowe mogły być używane przez inne narzędzia, takie jak Amazonka Atena.
Utwórz przepis DataBrew
Zacznij od zarejestrowania magazynu danych dla pliku roszczenia. Umożliwi to zbudowanie receptury w jej interaktywnym edytorze przy użyciu rzeczywistych danych, dzięki czemu będziesz mógł ocenić wynik transformacji podczas ich definiowania.
- Pobierz plik CSV roszczenia, korzystając z następującego linku: alabama_claims_data_Jun2023.csv.
- W konsoli DataBrew wybierz Zbiory danych w okienku nawigacji, a następnie wybierz Połącz nowy zbiór danych.
- Wybierz opcję Udostępnianie pliku.
- W razie zamówieenia projektu Nazwa zestawu danych, wchodzić
Alabama claims. - W razie zamówieenia projektu Wybierz plik do przesłania, wybierz plik, który właśnie pobrałeś na swój komputer.
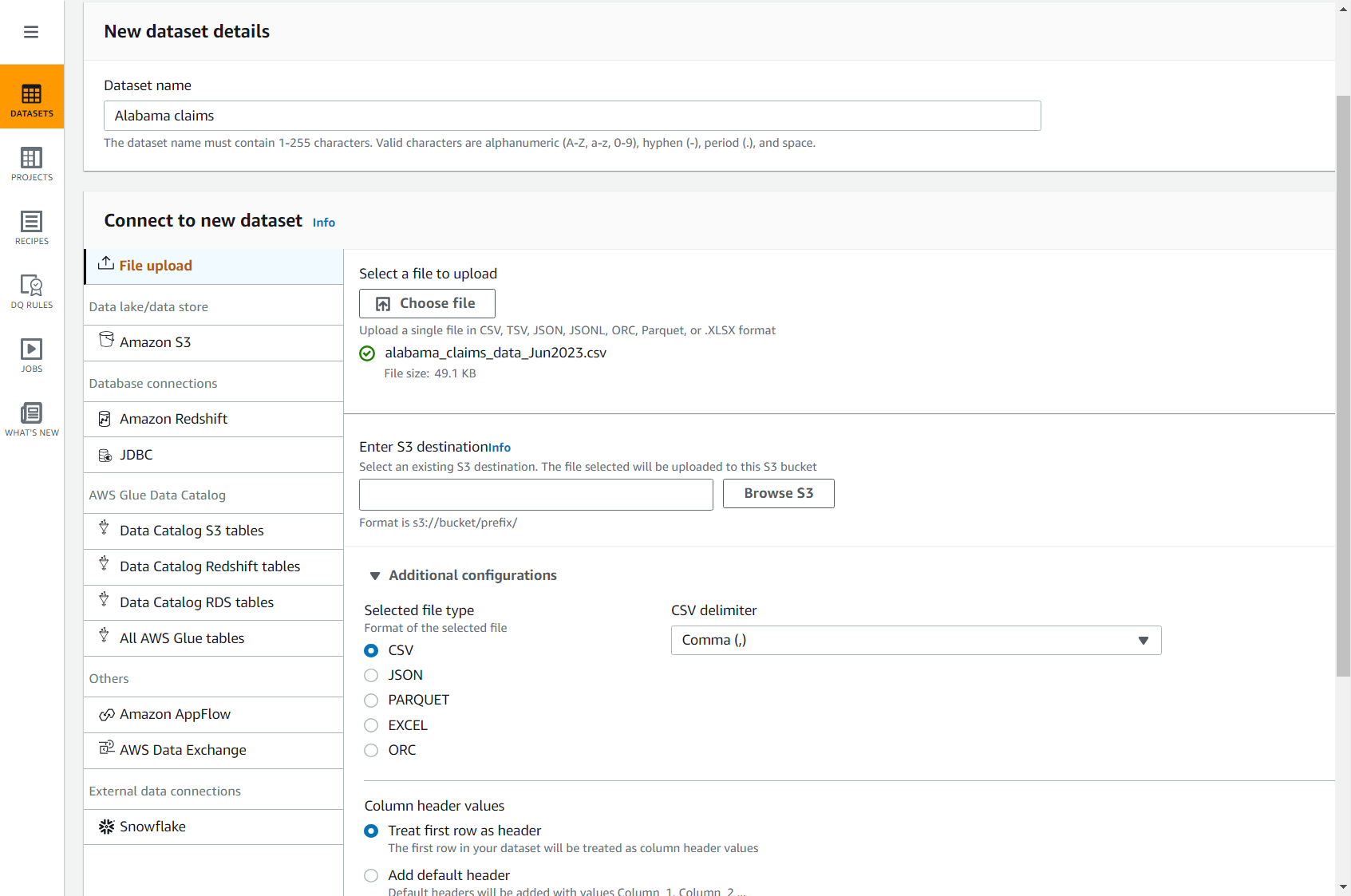
- W razie zamówieenia projektu Wpisz cel S3, wprowadź lub przejdź do zasobnika na swoim koncie i regionie.
- Resztę opcji pozostaw domyślnie (CSV oddzielone przecinkiem i nagłówkiem) i dokończ tworzenie zestawu danych.
- Dodaj Projekty w okienku nawigacji, a następnie wybierz Utwórz projekt.
- W razie zamówieenia projektu Nazwa Projektu, Nazwij to
ClaimsCleanup. - Pod Szczegóły przepisu, Dla Załączony przepiswybierz Utwórz nowy przepis, Nazwij to
ClaimsCleanup-recipei wybierzAlabama claimszestaw danych, który właśnie utworzyłeś.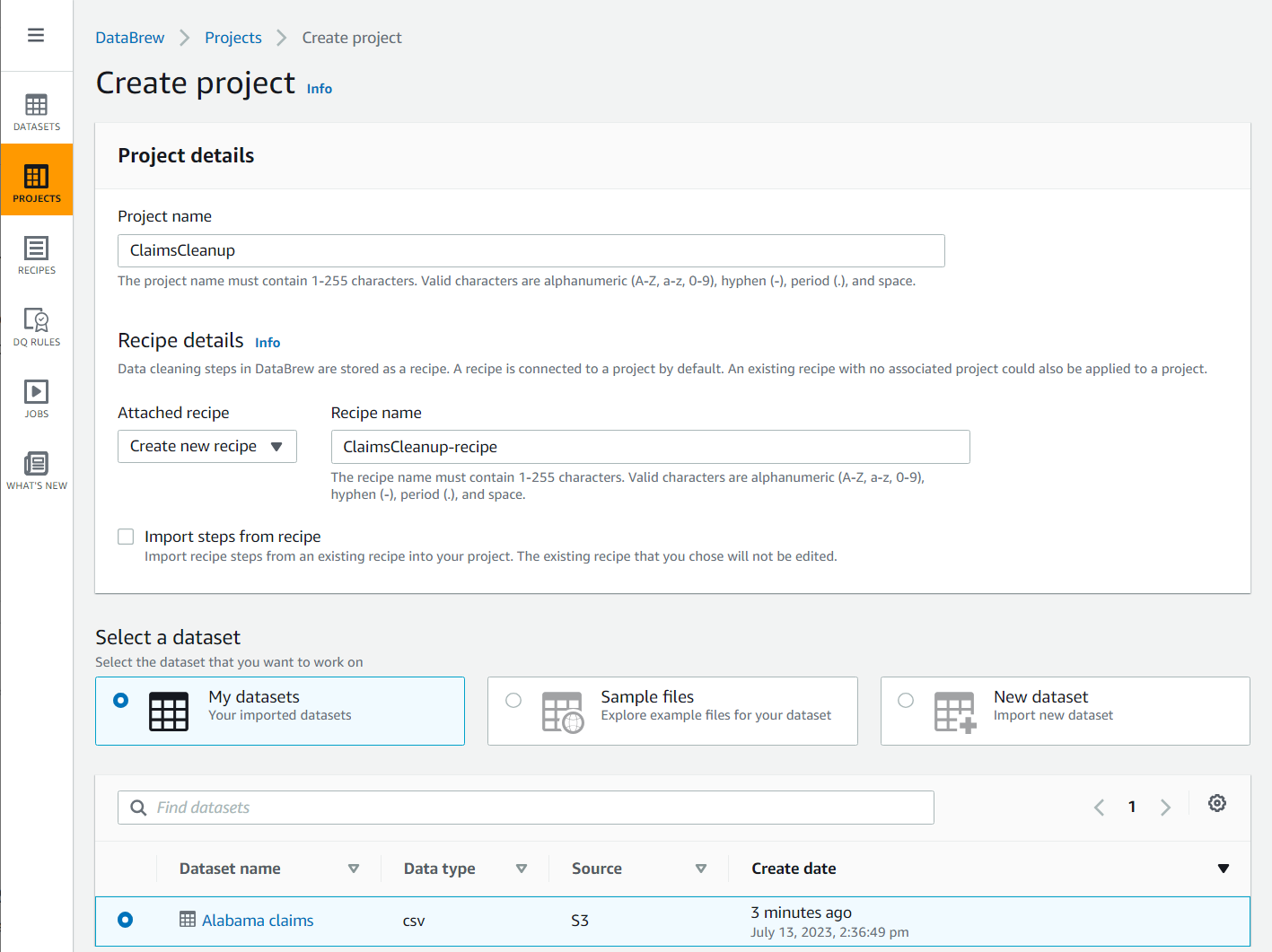
- Wybierz rola odpowiednia dla DataBrew lub utwórz nowy i zakończ tworzenie projektu.
Spowoduje to utworzenie sesji przy użyciu konfigurowalnego podzbioru danych. Po zainicjowaniu sesji można zauważyć, że niektóre komórki zawierają nieprawidłowe lub brakujące wartości.
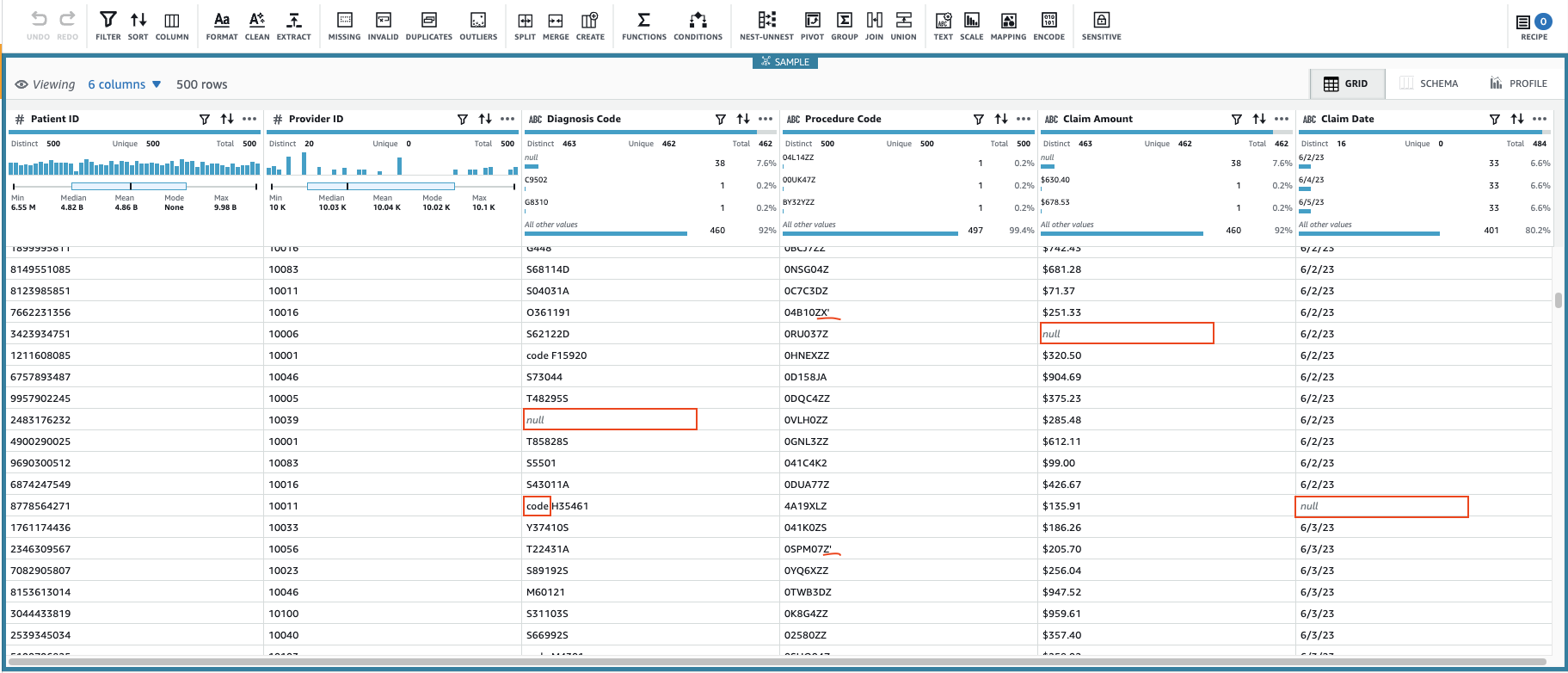
Oprócz brakujących wartości w kolumnach Kod diagnostyczny, Kwota roszczenia, Data roszczenia, niektóre wartości w danych mają dodatkowe znaki: Kod diagnostyczny wartości są czasami poprzedzone przedrostkiem „kod” (wraz ze spacją) i Kodeks postępowania po wartościach czasami występują pojedyncze cudzysłowy.
Kwota roszczenia wartości będą prawdopodobnie używane do niektórych obliczeń, więc przelicz na liczbę i Dane roszczenia należy przekonwertować na typ daty.
Teraz, gdy zidentyfikowaliśmy problemy z jakością danych, którymi należy się zająć, musimy zdecydować, jak postępować w każdym przypadku.
Istnieje wiele sposobów dodawania kroków receptury, w tym za pomocą menu kontekstowego kolumny, paska narzędzi u góry lub z podsumowania receptury. Korzystając z ostatniej metody, możesz wyszukać wskazany typ kroku, aby odtworzyć przepis utworzony w tym poście.
Kwota roszczenia jest niezbędna w tym przypadku użycia, a decyzja polega na usunięciu takich wierszy.
- Dodaj krok Usuń brakujące wartości.
- W razie zamówieenia projektu Kolumna źródłowawybierz Kwota roszczenia.
- Pozostaw domyślną akcję Usuń wiersze z brakującymi wartościami i wybierz Aplikuj aby go zapisać.
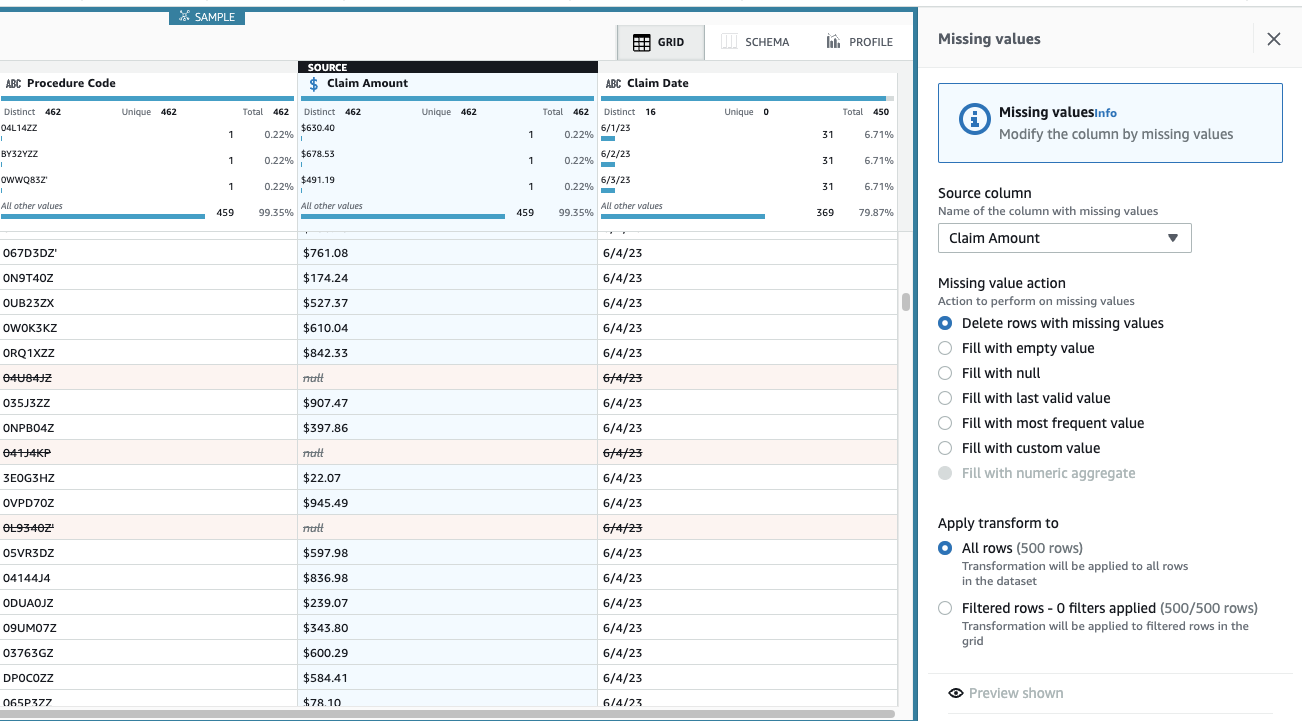
Widok jest teraz aktualizowany, aby odzwierciedlić aplikację krokową, a wiersze z brakującymi kwotami już się nie pojawiają.
Kod diagnostyczny może być pusty, więc jest to akceptowane, ale w przypadku Data roszczenia, chcemy mieć rozsądne oszacowanie. Wiersze w danych są posortowane chronologicznie, dzięki czemu można implikować brakujące daty, korzystając z prawidłowych wartości podglądu z poprzednich wierszy. Zakładając, że każdy dzień ma roszczenia, największym błędem byłoby przypisanie go do dnia podglądu, gdyby było to pierwsze roszczenie tego dnia bez daty; dla celów ilustracyjnych przyjmijmy, że potencjalny błąd jest akceptowalny.
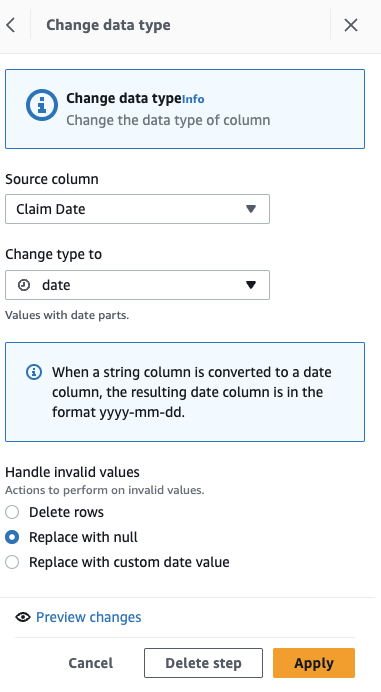
Najpierw przekonwertuj kolumnę z ciągu na typ daty.
- Dodaj krok Zmień typ.
- Dodaj Data roszczenia jako kolumna i dane jako typ, a następnie wybierz Aplikuj.
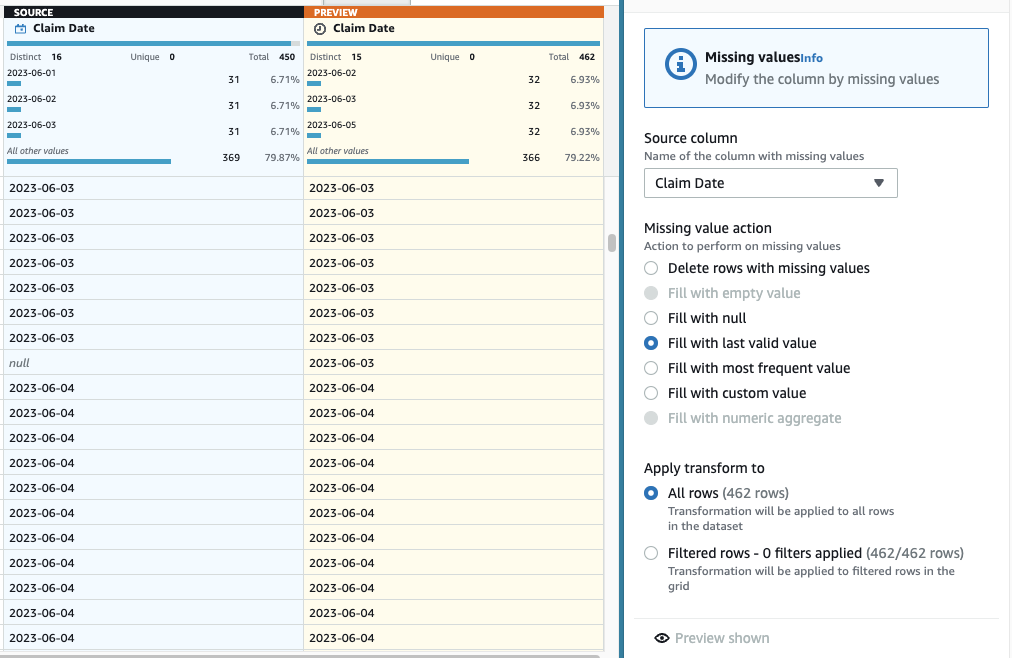
- Teraz, aby wykonać imputację brakujących dat, dodaj krok Wypełnij lub przypisz brakujące wartości.
- Wybierz opcję Wypełnij ostatnią prawidłową wartością jako akcję i wybierz Data roszczenia jako źródło.
- Dodaj Podgląd zmian aby to potwierdzić, a następnie wybierz Aplikuj aby zapisać krok.
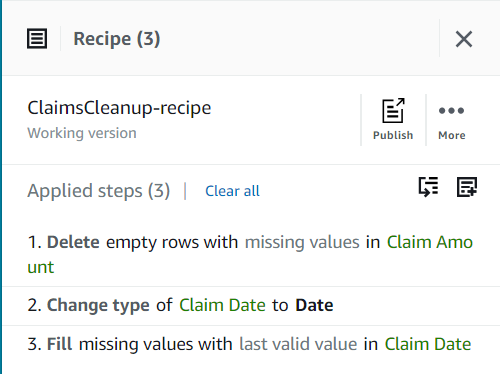
Do tej pory Twój przepis powinien składać się z trzech kroków, jak pokazano na poniższym zrzucie ekranu.
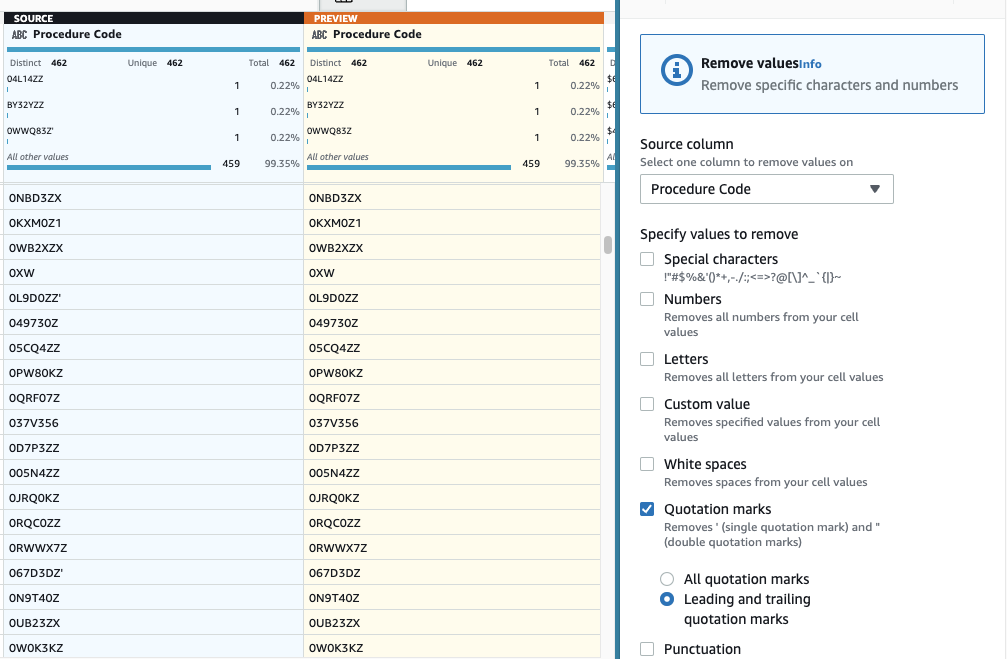
- Następnie dodaj krok Usuń cudzysłowy.
- Wybierz Kodeks postępowania kolumna i wybierz Początkowe i końcowe cudzysłowy.
- Wyświetl podgląd, aby sprawdzić, czy przyniosło to pożądany efekt, i zastosuj nowy krok.
- Dodaj krok Usuń znaki specjalne.
- Wybierz Kwota roszczenia kolumna i aby być bardziej szczegółowym, wybierz Niestandardowe znaki specjalne I wejdź
$dla Wprowadź niestandardowe znaki specjalne.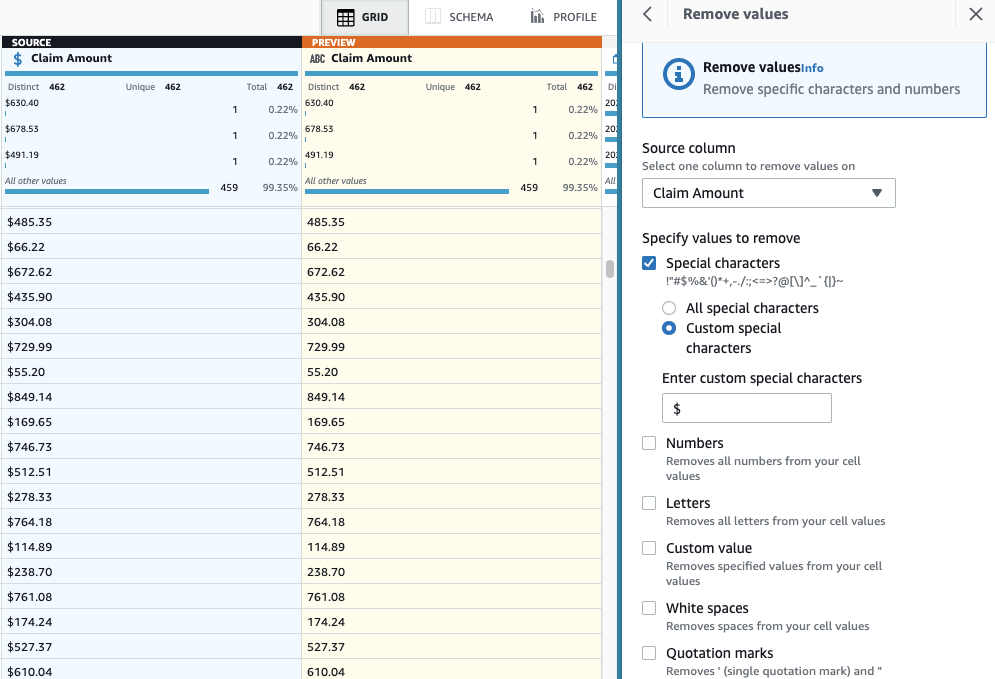
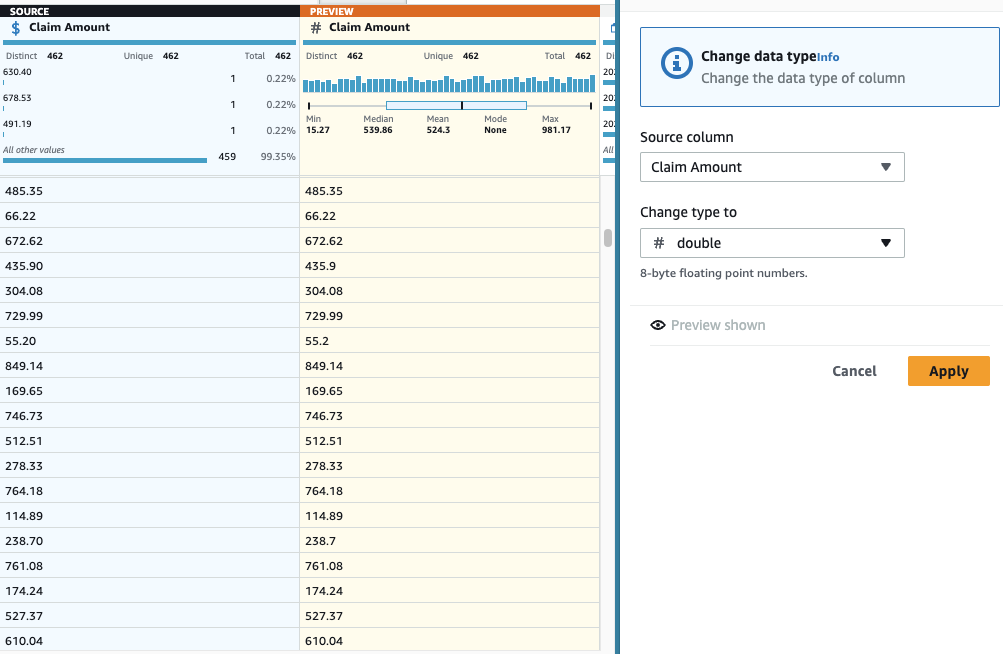
- dodaj Zmień typ wejdź na kolumnę Kwota roszczenia i wybierz Podwójna jako typ.
- Jako ostatni krok, aby usunąć zbędny przedrostek „code ”, dodaj a Zastąp wartość lub wzorzec krok.
- Wybierz kolumnę Kod diagnostyczny, A na Wpisz wartość niestandardową, wchodzić
code(ze spacją na końcu).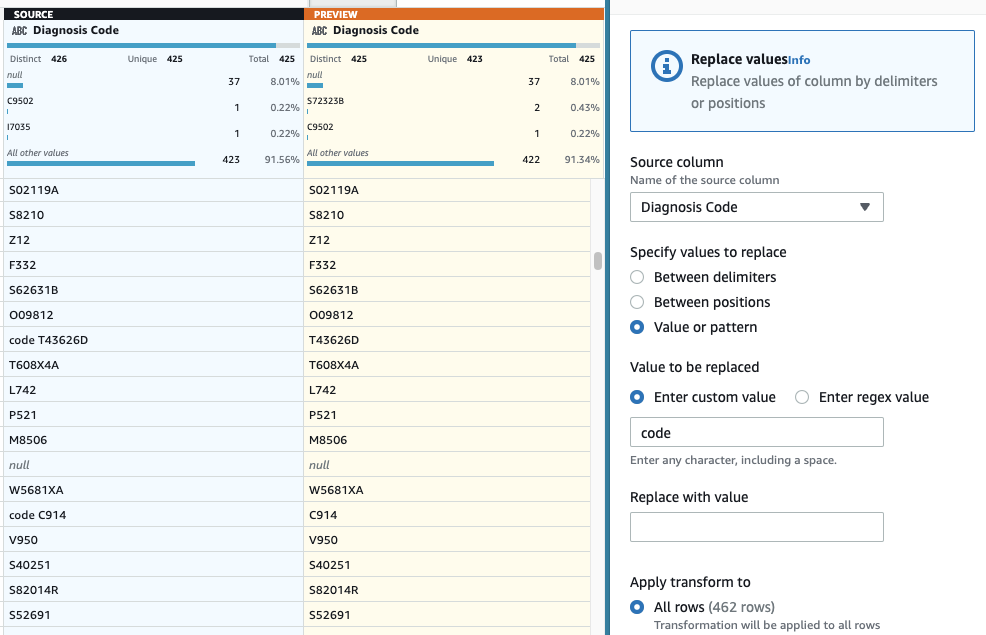
Po rozwiązaniu wszystkich problemów z jakością danych zidentyfikowanych w próbce opublikuj projekt jako przepis.
- Dodaj Publikować Przepis okienko, wprowadź opcjonalny opis i uzupełnij publikację.
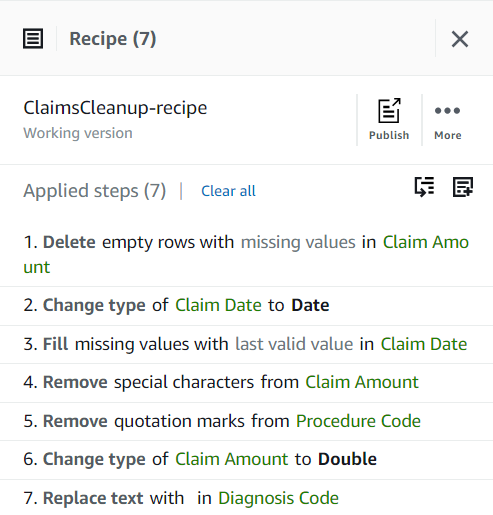
Za każdym razem, gdy opublikujesz, utworzy inną wersję przepisu. Później będziesz mógł wybrać, której wersji przepisu chcesz użyć.
Utwórz wizualne zadanie ETL w AWS Glue Studio
Następnie utwórz zadanie korzystające z przepisu. Wykonaj następujące kroki:
- W konsoli AWS Glue Studio wybierz Wizualny ETL w okienku nawigacji.
- Dodaj Wizualne z pustym płótnem i utwórz pracę wizualną.
- U góry zadania zastąp „Oferta bez tytułu” wybraną nazwą.
- Na szczegóły pracy określ rolę, której będzie używać zadanie.
To musi być AWS Zarządzanie tożsamością i dostępem (JESTEM) rola odpowiednia dla kleju AWS z uprawnieniami do Amazon S3 i AWS Glue Data Catalog. Należy pamiętać, że rola używana wcześniej dla DataBrew nie nadaje się do uruchamiania zadań, więc nie będzie wyświetlana na liście Rola uprawnień menu rozwijane tutaj.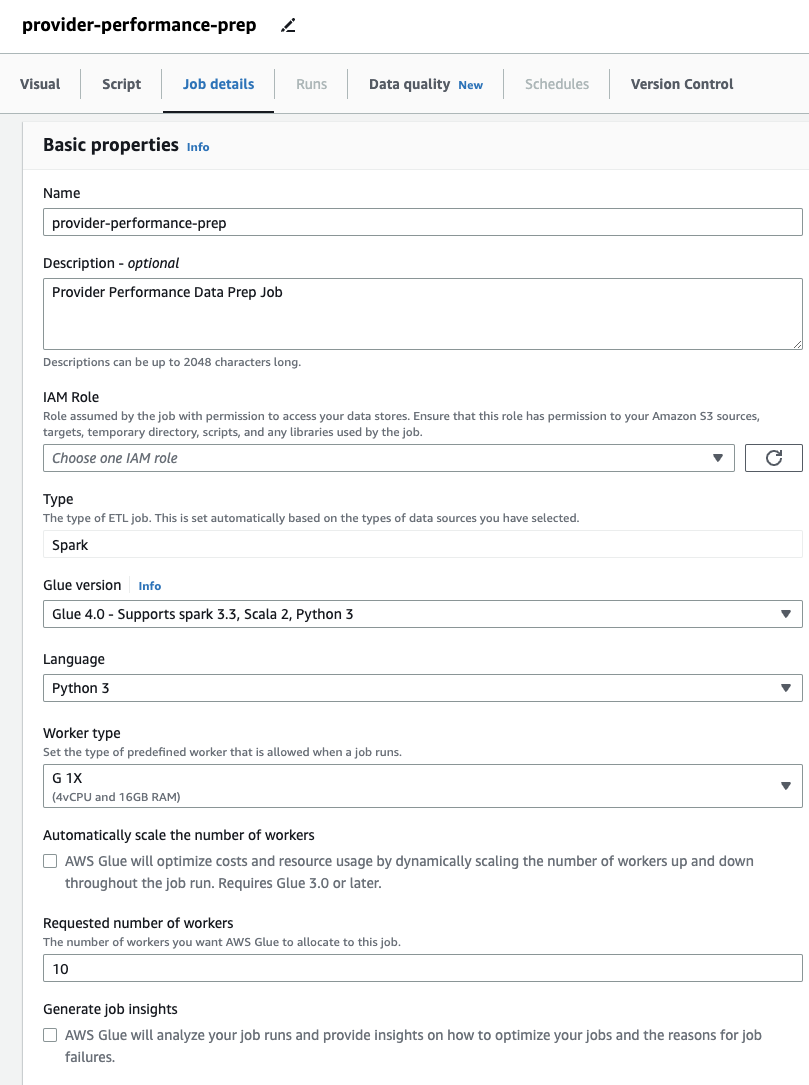
Jeśli wcześniej korzystałeś tylko z zadań DataBrew, zauważ, że w AWS Glue Studio możesz wybrać ustawienia wydajności i kosztów, w tym rozmiar procesu roboczego, automatyczne skalowanie i Elastyczne wykonanie, a także korzystaj z najnowszego środowiska wykonawczego AWS Glue 4.0 i korzystaj ze znacznych ulepszeń wydajności, jakie zapewnia. W przypadku tego zadania możesz użyć ustawień domyślnych, ale zmniejsz żądaną liczbę pracowników w interesie oszczędności. W tym przykładzie wystarczy dwóch pracowników. - Na Wizualny dodaj źródło S3 i nadaj mu nazwę
Providers. - W razie zamówieenia projektu URL S3, wchodzić
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.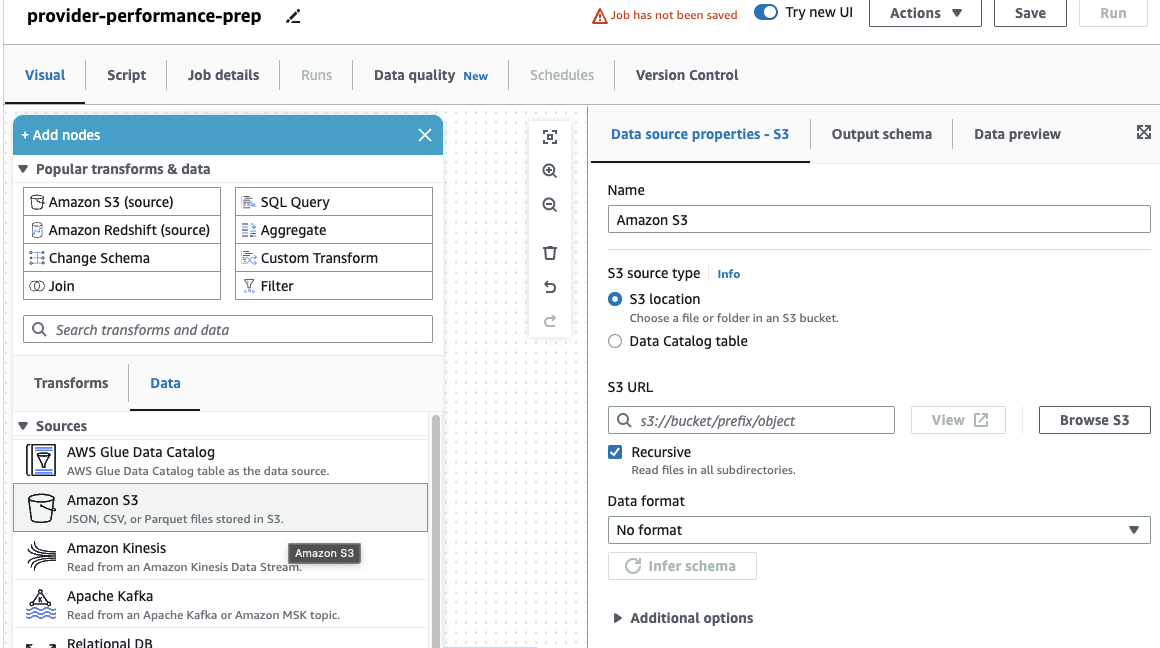
- Wybierz format jako CSV i wybierz Wywnioskować schemat.
Teraz schemat jest wymieniony na Schemat wyjściowy za pomocą nagłówka pliku.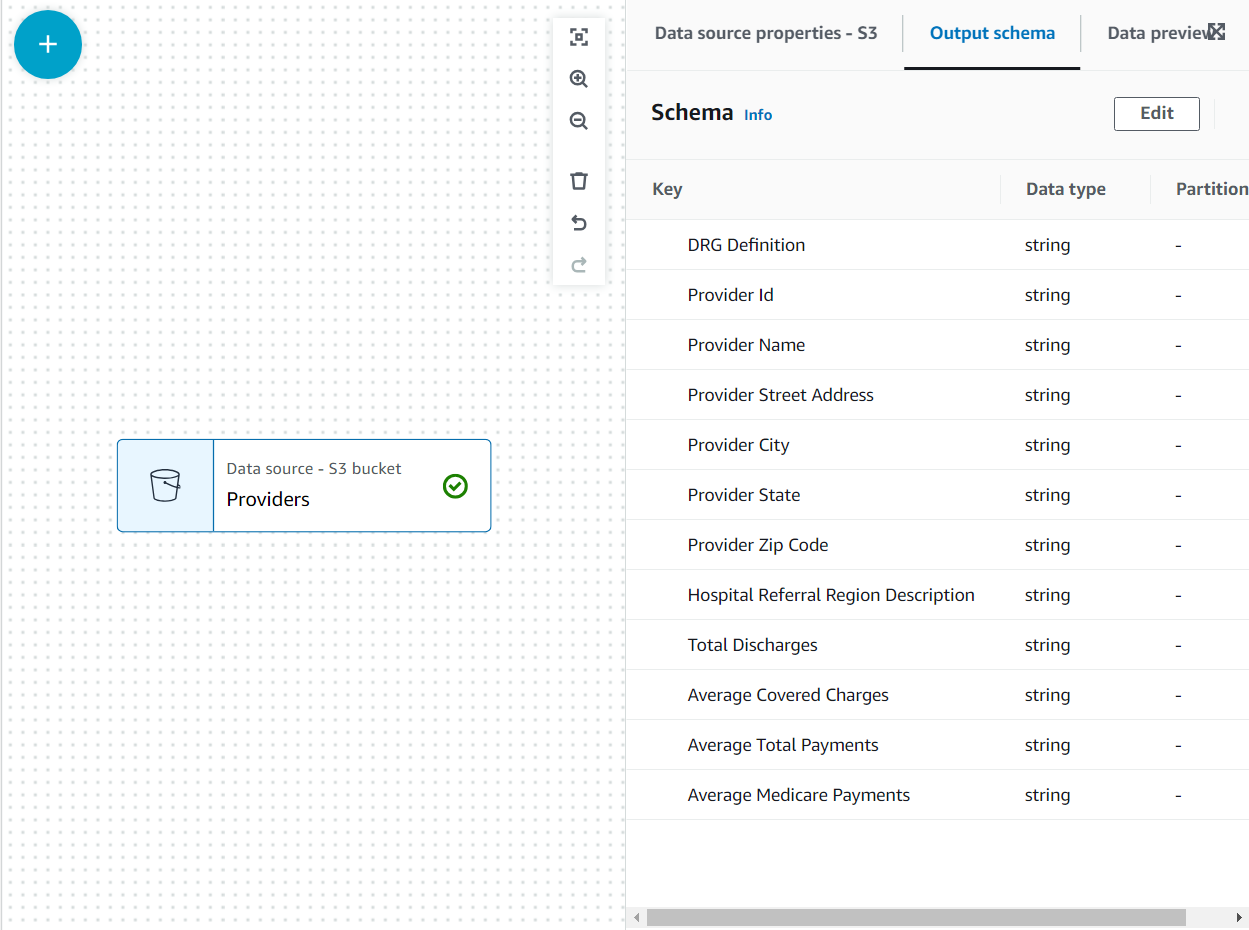
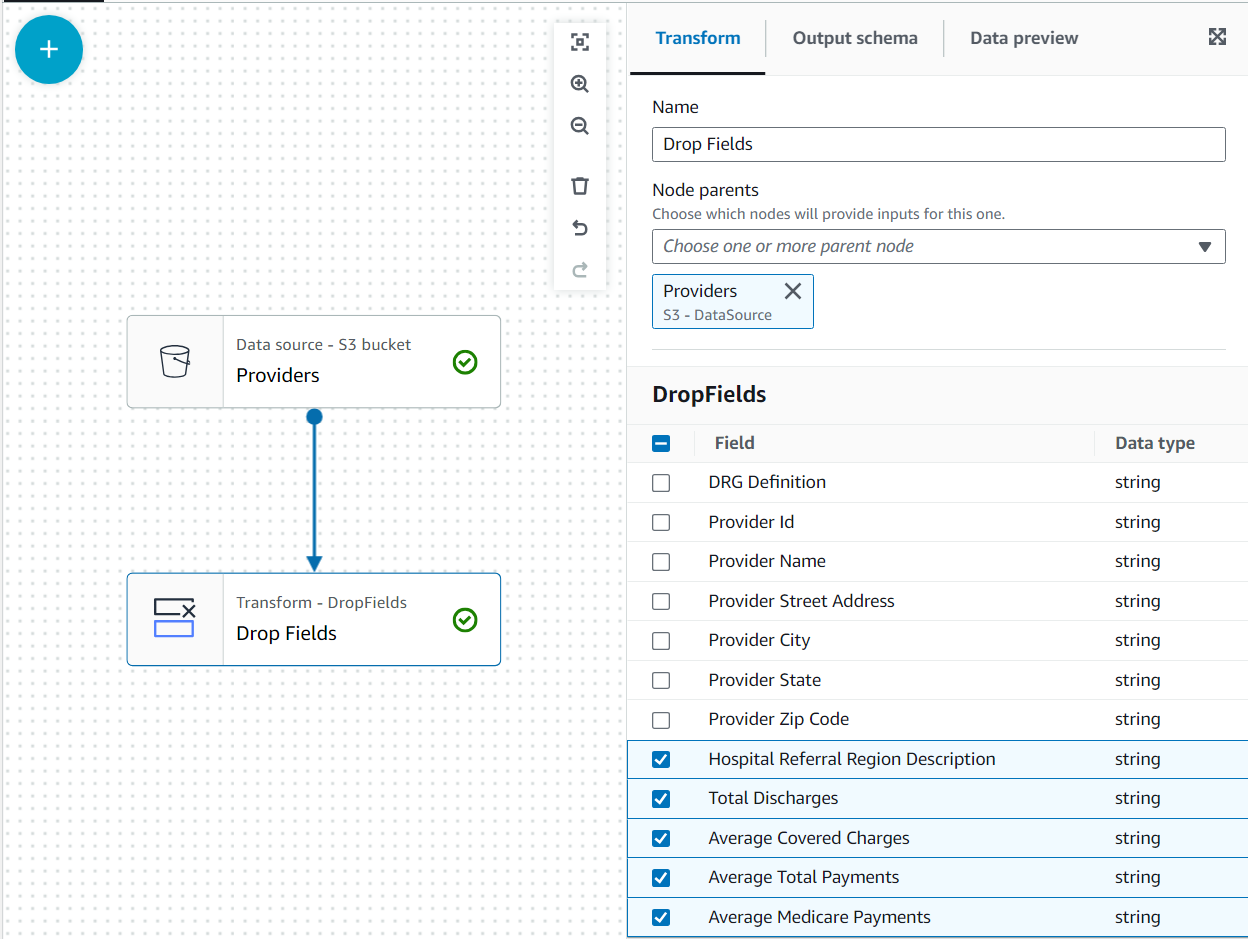
W tym przypadku użycia decyzja jest taka, że nie wszystkie kolumny w zbiorze danych dostawcy są potrzebne, więc możemy odrzucić resztę.
- Z Dostawcy wybrany węzeł, dodaj a Upuść pola transform (jeśli nie wybrałeś węzła nadrzędnego, nie będzie go miał; w takim przypadku ręcznie przypisz węzeł nadrzędny).
- Wybierz wszystkie pola po Kod pocztowy dostawcy.
Później do tych danych dołączą roszczenia dla stanu Alabama korzystające z usługodawcy; jednak ten drugi zestaw danych nie ma określonego stanu. Możemy wykorzystać wiedzę o danych do optymalizacji łączenia poprzez filtrowanie danych, których naprawdę potrzebujemy.
- dodaj FILTRY przemienić się w dziecko Upuść pola.
- Nazwij to
Alabama providersi dodaj warunek, który musi spełniać stanAL.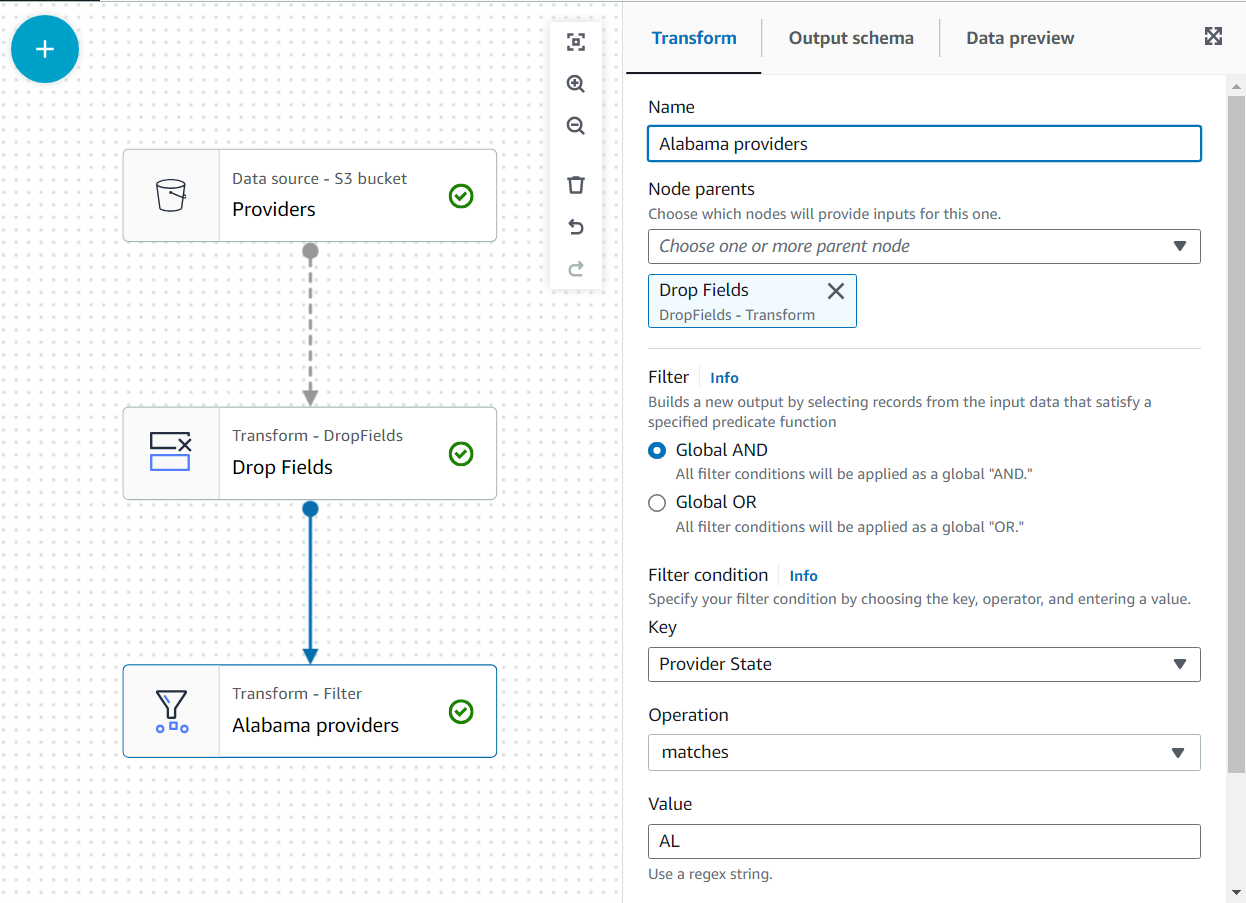
- Dodaj drugie źródło (nowe źródło S3) i nadaj mu nazwę
Alabama claims. - Wejść do URL S3, otwórz DataBrew na osobnej karcie przeglądarki, wybierz Datasets w panelu nawigacyjnym i skopiuj do tabeli lokalizację pokazaną w tabeli dla twierdzi Alabama (skopiuj tekst zaczynający się od s3://, a nie powiązany link http). Następnie wróć do pracy wizualnej, wklej ją jako URL S3; jeśli jest poprawny, zobaczysz w Schemat wyjściowy zakładkę z wymienionymi polami danych.
- Wybierz format CSV i wywnioskuj schemat, tak jak zrobiłeś to z innym źródłem.
- Jako dziecko tego źródła, szukaj w Dodaj węzły menu dla
recipei wybierz Przepis przygotowania danych.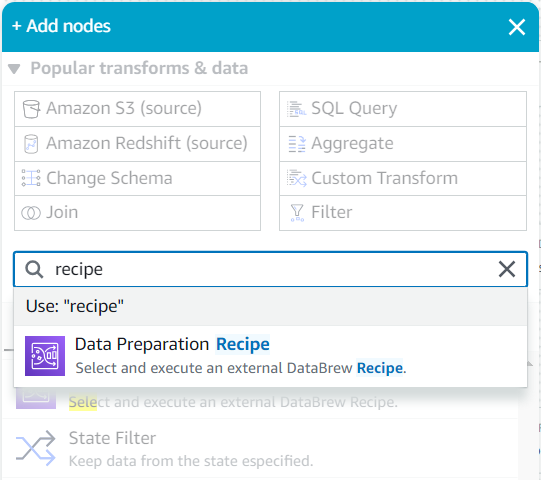
- We właściwościach tego nowego węzła nadaj mu nazwę
Claim cleanup recipei wybierz przepis i wersję, którą wcześniej opublikowałeś. - Możesz przejrzeć kroki przepisu tutaj i użyć łącza do DataBrew, aby wprowadzić zmiany w razie potrzeby.
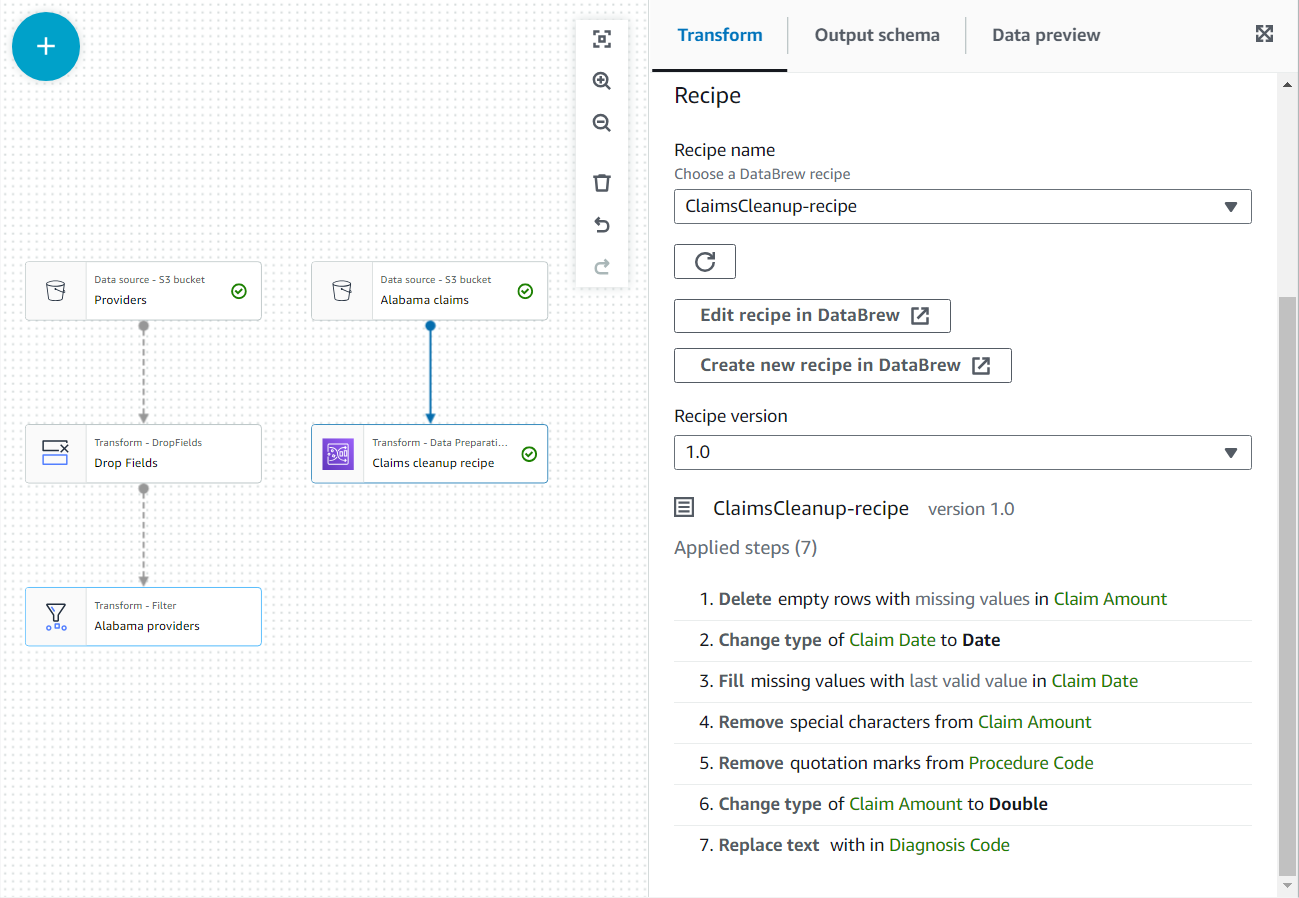
- dodaj Dołącz do rejestru węzeł i wybierz oba Dostawcy z Alabamy i Odbierz przepisy na sprzątanie jako rodzic.
- Dodaj warunek łączenia równy identyfikatorowi dostawcy z obu źródeł.
- Jako ostatni krok dodaj węzeł S3 jako cel (zwróć uwagę, że pierwszy wymieniony podczas wyszukiwania jest źródłem; upewnij się, że wybrałeś wersję, która jest wymieniona jako cel).
- W konfiguracji węzła pozostaw domyślny format JSON i wprowadź adres URL S3, pod którym rola zadania ma uprawnienia do zapisu.
Ponadto udostępnij dane wyjściowe jako tabelę w katalogu.
- W Opcje aktualizacji katalogu danych sekcji, wybierz drugą opcję Utwórz tabelę w Data Catalog i przy kolejnych uruchomieniach, aktualizuj schemat i dodawaj nowe partycje, a następnie wybierz bazę danych, w której masz uprawnienia do tworzenia tabel.
- Przydzielać
alabama_claimsjak nazwa i wybierz Data roszczenia jako klucz partycji (to dla celów ilustracyjnych; taka mała tabela tak naprawdę nie potrzebuje partycji, jeśli dalsze dane nie zostaną dodane później).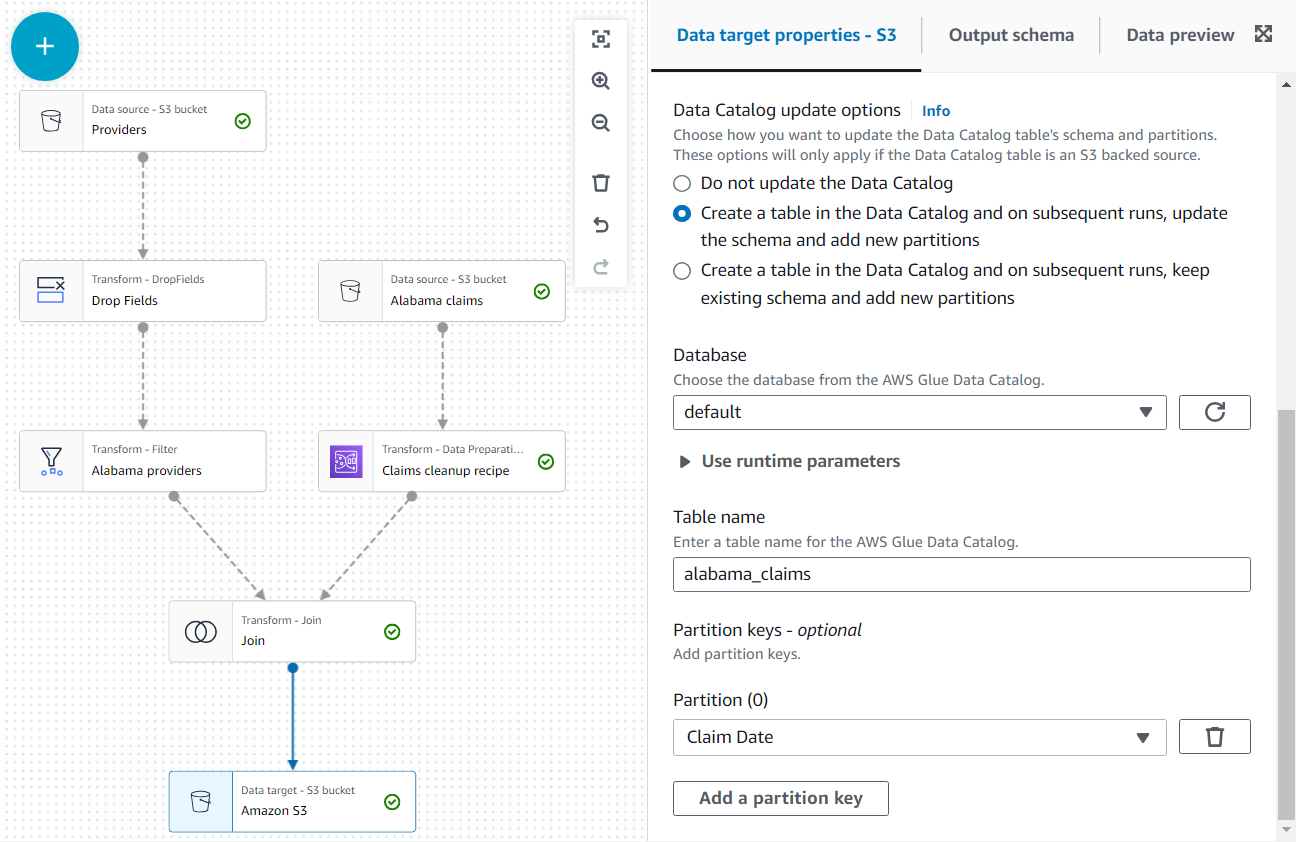
- Teraz możesz zapisać i uruchomić zadanie.
- Na Działa możesz śledzić proces i wyświetlać szczegółowe dane dotyczące zadania, korzystając z łącza do identyfikatora zadania.
Zadanie powinno zająć kilka minut.
- Po zakończeniu zadania przejdź do konsoli Athena.
- Wyszukaj tabelę
alabama_claimsw wybranej bazie danych i korzystając z menu kontekstowego wybierz Podgląd tabeli, który uruchomi prostą instrukcję SELECT * SQL na tabeli.
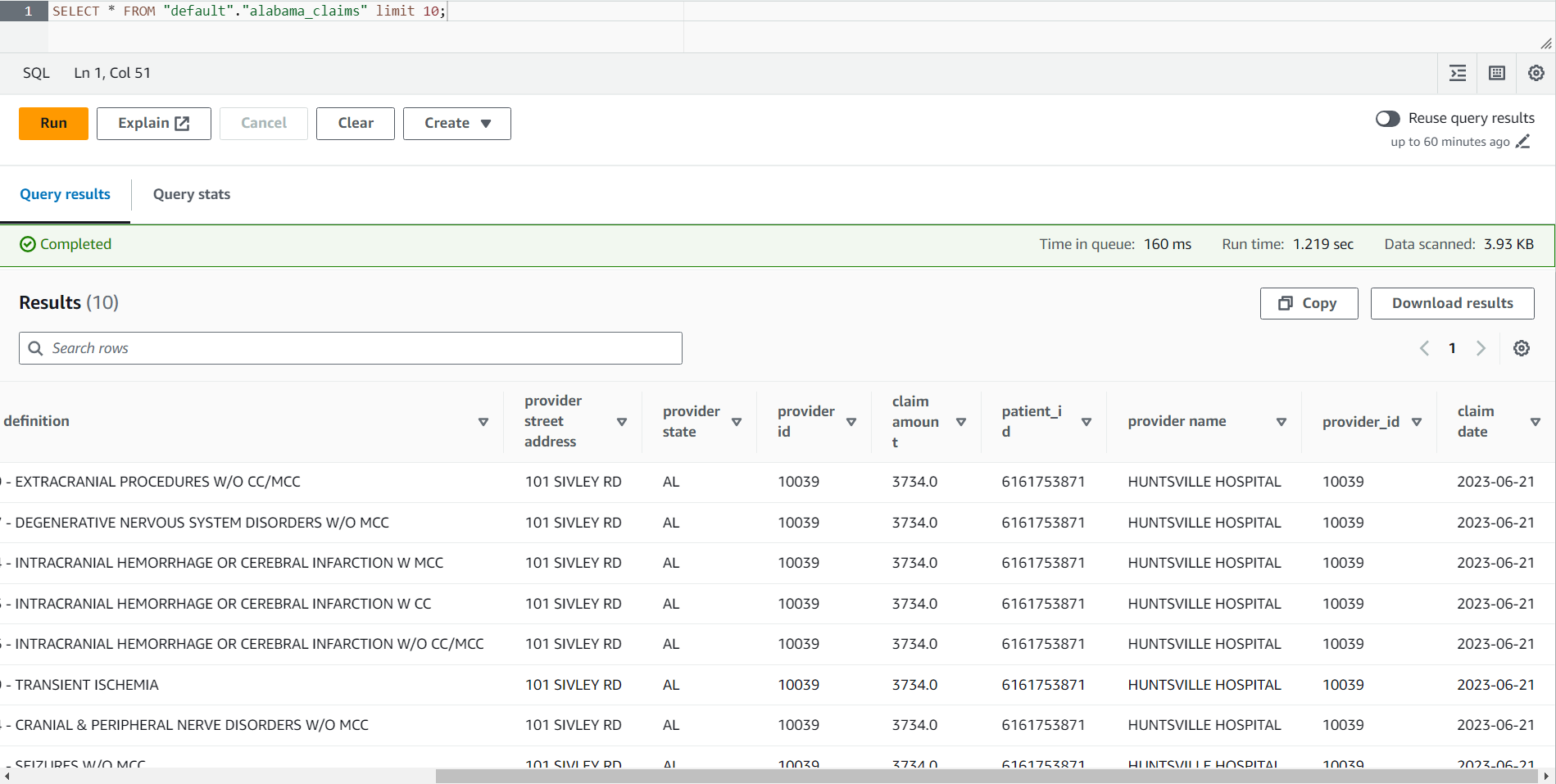
W wyniku zadania widać, że dane zostały wyczyszczone przez recepturę DataBrew i wzbogacone o złącze AWS Glue Studio.
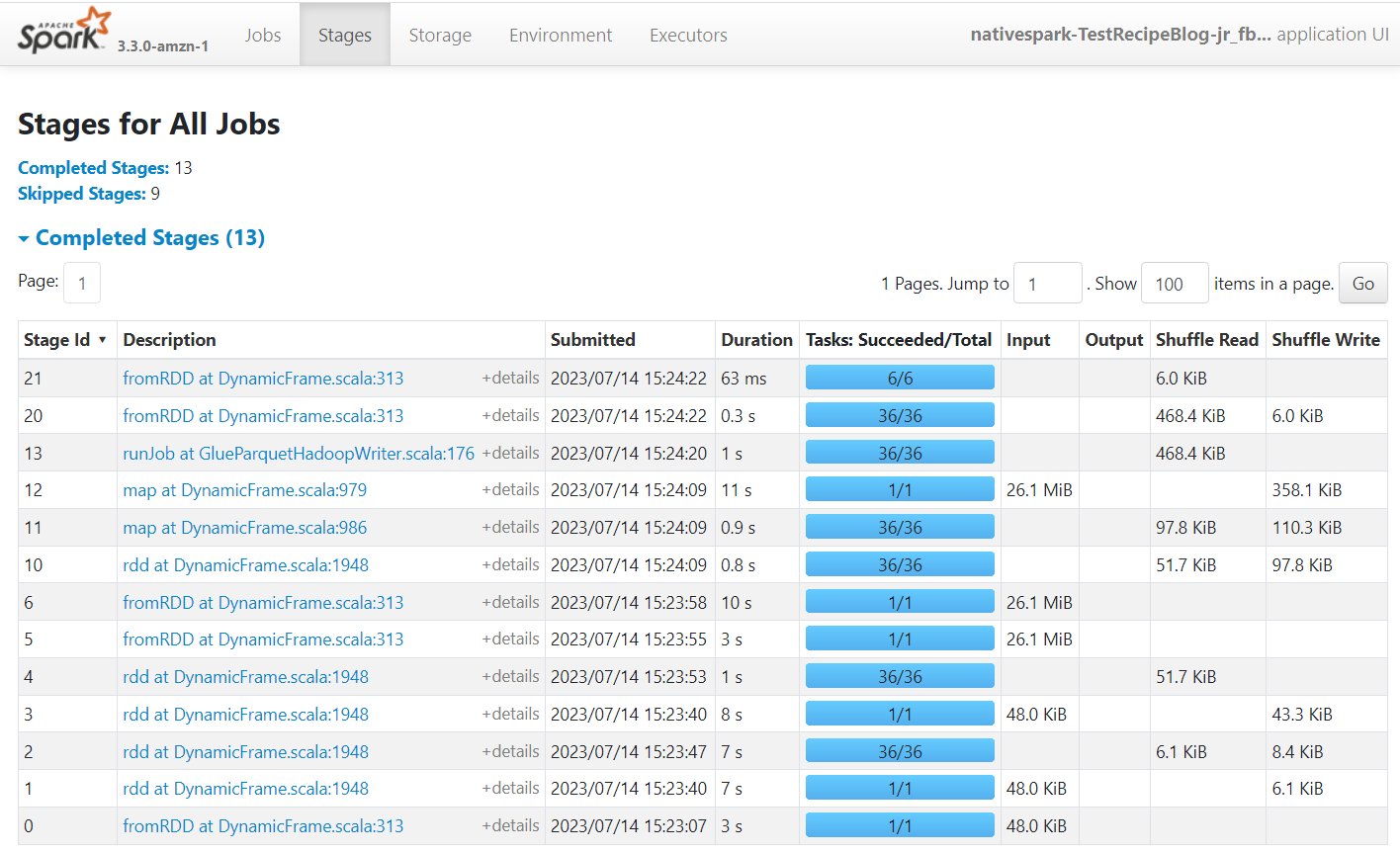
Apache Spark to silnik, który uruchamia zadania utworzone w AWS Glue Studio. Korzystając z interfejsu użytkownika platformy Spark w tworzonych przez nią dziennikach zdarzeń, można wyświetlać szczegółowe informacje na temat planu pracy i przebiegu, co może pomóc w zrozumieniu wydajności zadania i potencjalnych wąskich gardeł wydajności. Na przykład w przypadku tego zadania na dużym zbiorze danych można go użyć do porównania wpływu jawnego filtrowania stanu dostawcy przed wykonaniem sprzężenia lub określenia, czy można skorzystać z dodania transformacji automatycznego równoważenia w celu poprawy równoległości.
Domyślnie zadanie będzie przechowywać dzienniki zdarzeń Apache Spark w ścieżce s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Aby przeglądać zadania, musisz zainstalować serwer historii za pomocą jedną z dostępnych metod.
Sprzątać
Jeśli nie potrzebujesz już tego rozwiązania, możesz usunąć pliki wygenerowane na Amazon S3, tabelę utworzoną przez zadanie, recepturę DataBrew i zadanie AWS Glue.
Wnioski
W tym poście pokazaliśmy, jak możesz użyć AWS DataBrew do zbudowania przepisu za pomocą dostarczonego interaktywnego edytora, a następnie użyć opublikowanego przepisu jako części wizualnego zadania ETL AWS Glue Studio. Zawarliśmy kilka przykładów typowych zadań, które są wymagane podczas przygotowywania danych i przyjmowania danych do tabel AWS Glue Catalog.
W tym przykładzie użyto jednej receptury w zadaniu wizualnym, ale możliwe jest użycie wielu receptur w różnych częściach procesu ETL, a także ponowne użycie tej samej receptury w wielu zadaniach.
Te rozwiązania AWS Glue umożliwiają efektywne tworzenie zaawansowanych potoków ETL, które są proste w budowie i utrzymaniu, a wszystko to bez pisania kodu. Już dziś możesz zacząć tworzyć rozwiązania łączące oba narzędzia.
O autorach
 Michaił Smirnow jest starszym inżynierem oprogramowania w zespole AWS Glue i członkiem zespołu programistów AWS Glue DataBrew. Poza pracą interesuje się nauką gry na gitarze i podróżami z rodziną.
Michaił Smirnow jest starszym inżynierem oprogramowania w zespole AWS Glue i członkiem zespołu programistów AWS Glue DataBrew. Poza pracą interesuje się nauką gry na gitarze i podróżami z rodziną.
 Gonzalo herreros jest Starszym Architektem Big Data w zespole AWS Glue. Z siedzibą w Dublinie w Irlandii pomaga klientom odnieść sukces dzięki rozwiązaniom big data opartym na AWS Glue. W wolnym czasie lubi grać w gry planszowe i jeździć na rowerze.
Gonzalo herreros jest Starszym Architektem Big Data w zespole AWS Glue. Z siedzibą w Dublinie w Irlandii pomaga klientom odnieść sukces dzięki rozwiązaniom big data opartym na AWS Glue. W wolnym czasie lubi grać w gry planszowe i jeździć na rowerze.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- :ma
- :Jest
- :nie
- $W GÓRĘ
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- Zdolny
- O nas
- do przyjęcia
- zaakceptowany
- dostęp
- Konto
- Działania
- rzeczywisty
- Dodaj
- w dodatku
- dodanie
- dodatek
- adres
- zaawansowany
- Po
- Alabama
- Wszystkie kategorie
- dopuszczać
- również
- Amazonka
- Amazon Web Services
- kwoty
- an
- analitycy
- i
- każdy
- Apache
- Apache Spark
- Zastosowanie
- Aplikuj
- SĄ
- AS
- powiązany
- At
- autor
- samochód
- automatycznie
- dostępny
- AWS
- Klej AWS
- z powrotem
- na podstawie
- BE
- zanim
- jest
- korzyści
- Korzyści
- Duży
- Big Data
- pusty
- deska
- Gry planszowe
- bookmarks
- obie
- Przynosi
- przeglądarka
- budować
- ale
- by
- CAN
- możliwości
- walizka
- katalog
- Komórki
- scentralizowane
- zmiana
- Zmiany
- znaków
- dziecko
- wybór
- Dodaj
- roszczenie
- roszczenia
- kod
- Kolumna
- kolumny
- połączyć
- przyjście
- wspólny
- porównać
- kompletny
- składniki
- komputer
- warunek
- systemu
- Rozważać
- składa się
- Konsola
- kontekst
- konwertować
- przeliczone
- skorygowania
- Odpowiedni
- Koszty:
- mógłby
- Stwórz
- stworzony
- Tworzenie
- tworzenie
- zwyczaj
- Klientów
- dane
- Przygotowywanie danych
- analiza danych
- jakość danych
- Baza danych
- zbiory danych
- Data
- Daty
- dzień
- sprawa
- zdecydować
- decyzja
- Domyślnie
- wykazać
- opis
- życzenia
- szczegółowe
- detale
- dev
- oprogramowania
- zespół programistów
- ZROBIŁ
- różne
- odrębny
- 分配
- do
- Nie
- robi
- Dolar
- Podwójna
- Spadek
- Dublin
- każdy
- łatwo
- redaktor
- efekt
- faktycznie
- Umożliwia
- zakończenia
- silnik
- inżynier
- Wzbogacony
- wzbogacanie
- Wchodzę
- błąd
- niezbędny
- Eter (ETH)
- oceniać
- Parzyste
- wydarzenie
- Każdy
- codziennie
- przykład
- przykłady
- Przede wszystkim system został opracowany
- dodatkowy
- wyciąg
- członków Twojej rodziny
- daleko
- Korzyści
- kilka
- Łąka
- filet
- Akta
- wypełniać
- filtrować
- filtracja
- W końcu
- i terminów, a
- następnie
- następujący
- W razie zamówieenia projektu
- format
- od
- dalej
- Games
- wygenerowane
- Dać
- większy
- Have
- he
- pomoc
- pomaga
- tutaj
- jego
- historia
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- IAM
- ID
- zidentyfikowane
- zidentyfikować
- tożsamość
- if
- Rezultat
- podnieść
- ulepszenia
- in
- zawierać
- włączony
- Włącznie z
- wskazany
- wkład
- spostrzeżenia
- zainstalować
- przykład
- zintegrowany
- integracja
- interaktywne
- odsetki
- zainteresowania
- Interfejs
- najnowszych
- wprowadzono
- intuicyjny
- Irlandia
- problemy
- IT
- JEGO
- Praca
- Oferty pracy
- przystąpić
- Dołączył
- jpg
- json
- właśnie
- Trzymać
- Klawisz
- wiedza
- duży
- większe
- największym
- Nazwisko
- później
- firmy
- nauka
- Pozostawiać
- lubić
- Prawdopodobnie
- LINK
- Katalogowany
- załadować
- lokalizacja
- logika
- dłużej
- utrzymać
- robić
- WYKONUJE
- ręcznie
- Mecz
- medyczny
- Menu
- metoda
- metody
- Metryka
- minuty
- brakujący
- monitor
- jeszcze
- wielokrotność
- musi
- Nazwa
- Nawigacja
- Nawigacja
- Potrzebować
- potrzebne
- wymagania
- Nowości
- Nie
- węzeł
- Zauważyć..
- już dziś
- numer
- of
- on
- ONE
- tylko
- koncepcja
- Optymalizacja
- Option
- Opcje
- or
- zamówienie
- Inne
- ludzkiej,
- wydajność
- zewnętrzne
- koniec
- ogólny
- chleb
- część
- strony
- ścieżka
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywania
- pozwolenie
- uprawnienia
- krok po kroku
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- możliwy
- Post
- potencjał
- przygotowanie
- Podgląd
- Zapowiedzi
- wygląda tak
- przetwarzanie
- produkuje
- projekt
- niska zabudowa
- pod warunkiem,
- dostawca
- dostawców
- zapewnia
- Publikacja
- publikować
- opublikowany
- cel
- cele
- jakość
- cytaty
- naprawdę
- rozsądny
- Przepis
- przepisy
- zmniejszyć
- odzwierciedlić
- region
- rejestracji
- usunąć
- obsługi produkcji rolnej, która zastąpiła
- wniosek
- wymagany
- wymaganie
- odpowiednio
- REST
- dalsze
- Efekt
- ponownie
- przeglądu
- Rola
- run
- działa
- taki sam
- Zapisz
- Skala
- skalowaniem
- Szukaj
- druga
- Sekcja
- widzieć
- widzenie
- wybrany
- oddzielny
- Usługi
- Sesja
- zestaw
- w panelu ustawień
- powinien
- pokazał
- pokazane
- znak
- znaczący
- Prosty
- pojedynczy
- Rozmiar
- mały
- So
- dotychczas
- Tworzenie
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Źródła
- Typ przestrzeni
- Iskra
- specjalny
- specyficzny
- określony
- SQL
- początek
- Startowy
- Stan
- Zestawienie sprzedaży
- statystyka
- Ewolucja krok po kroku
- Cel
- przechowywanie
- sklep
- bezpośredni
- sznur
- studio
- kolejny
- osiągnąć sukces
- taki
- odpowiedni
- PODSUMOWANIE
- pewnie
- syntetyczny
- stół
- Brać
- cel
- zadania
- zespół
- przetestowany
- że
- Połączenia
- Źródło
- Państwo
- Im
- następnie
- Tam.
- to
- trzy
- czas
- do
- już dziś
- narzędzie
- narzędzia
- Top
- śledzić
- Przekształcać
- Transformacja
- przemiany
- Podróżowanie
- drugiej
- rodzaj
- ui
- dla
- zrozumieć
- Aktualizacja
- zaktualizowane
- URL
- nadający się do użytku
- posługiwać się
- przypadek użycia
- używany
- Użytkownicy
- zastosowania
- za pomocą
- UPRAWOMOCNIĆ
- wartość
- Wartości
- zweryfikować
- wersja
- Zobacz i wysłuchaj
- widoczny
- chcieć
- była
- sposoby
- we
- sieć
- usługi internetowe
- DOBRZE
- były
- jeśli chodzi o komunikację i motywację
- który
- będzie
- w
- bez
- Praca
- pracownik
- pracowników
- workflow
- by
- napisać
- pisanie
- ty
- Twój
- zefirnet
- Zamek błyskawiczny