Ponieważ inżynieria danych staje się coraz bardziej złożona, organizacje szukają nowych sposobów usprawnienia procesów przetwarzania danych. Wielu inżynierów danych używa dziś Apache Airflow do tworzenia, planowania i monitorowania potoków danych.
Jednak w miarę wzrostu ilości danych zarządzanie tymi potokami i skalowanie ich może stać się trudnym zadaniem. Przepływy pracy zarządzane przez Amazon dla Apache Airflow (Amazon MWAA) może pomóc uprościć proces budowania, uruchamiania i zarządzania potokami danych. Dostarczając Apache Airflow jako w pełni zarządzaną platformę, Amazon MWAA pozwala inżynierom danych skoncentrować się na budowaniu przepływów pracy z danymi, zamiast martwić się o infrastrukturę.
Obecnie firmy i organizacje wymagają ekonomicznych i wydajnych sposobów przetwarzania dużych ilości danych. Bezserwerowe Amazon EMR to ekonomiczne i skalowalne rozwiązanie do przetwarzania dużych zbiorów danych, które może obsłużyć duże ilości danych. Dostawca Amazon w Apache Airflow jest wyposażony w operatorów EMR Serverless i jest już uwzględniony w Amazon MWAA, co ułatwia inżynierom danych budowanie skalowalnych i niezawodnych potoków przetwarzania danych. Możesz używać EMR Serverless do uruchamiania zadań Spark na danych i używać Amazon MWAA do zarządzania przepływami pracy i zależnościami między tymi zadaniami. Integracja ta może również pomóc w obniżeniu kosztów poprzez automatyczne skalowanie zasobów potrzebnych do przetwarzania danych.
Amazon Athena to bezserwerowa, interaktywna usługa analityczna zbudowana w oparciu o platformy typu open source, obsługująca formaty otwartych tabel i plików. Do interakcji z danymi można używać standardowego języka SQL. Athena, bezserwerowa i interaktywna usługa analityczna, umożliwia to bez konieczności zarządzania złożoną infrastrukturą.
W tym poście używamy Amazon MWAA, EMR Serverless i Athena do zbudowania kompletnego, kompleksowego potoku przetwarzania danych.
Omówienie rozwiązania
Poniższy schemat ilustruje architekturę rozwiązania.
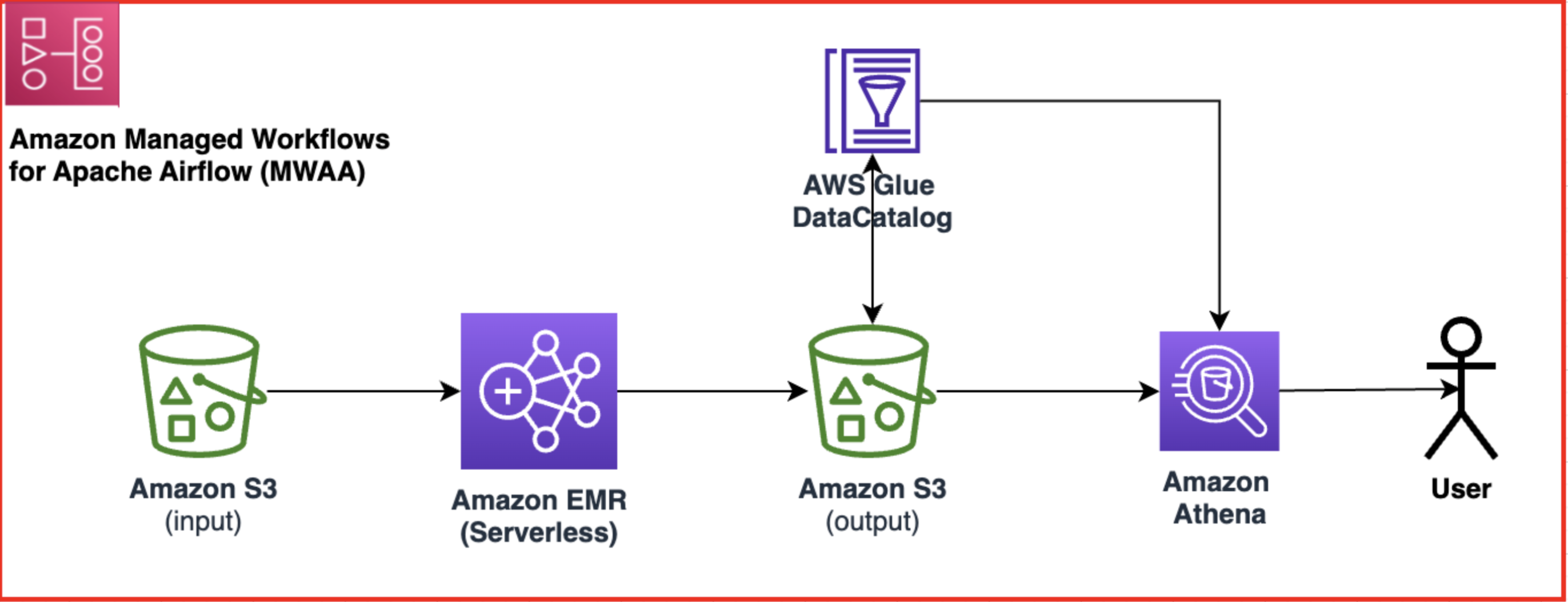
Przepływ pracy obejmuje następujące kroki:
- Utwórz przepływ pracy Amazon MWAA, który pobiera dane z wprowadzonych danych Usługa Amazon Simple Storage Łyżka (Amazon S3).
- Użyj EMR Serverless do przetwarzania danych przechowywanych w Amazon S3. EMR Serverless automatycznie skaluje się w górę lub w dół w zależności od obciążenia, więc nie musisz się martwić o udostępnianie ani zarządzanie jakąkolwiek infrastrukturą.
- Użyj EMR Serverless, aby przekształcić dane za pomocą kodu PySpark, a następnie zapisz przekształcone dane z powrotem w swoim zasobniku S3.
- Użyj Atheny, aby utworzyć zewnętrzną tabelę na podstawie zbioru danych S3 i uruchamiaj zapytania w celu analizy przekształconych danych. Atena używa Klej AWS Katalog danych do przechowywania metadanych tabeli.
Wymagania wstępne
Powinieneś mieć następujące wymagania wstępne:
Przygotowywanie danych
Aby zilustrować korzystanie z zadań EMR Serverless z Apache Spark za pośrednictwem Amazon MWAA i sprawdzanie poprawności danych za pomocą Athena, korzystamy z publicznie dostępnego zbioru danych taksówek w Nowym Jorku. Pobierz następujące zestawy danych na komputer lokalny:
- Rekordy podróży zieloną taksówką i żółtą taksówką – Rejestry podróży dla taksówek żółtych i zielonych, które zawierają takie informacje, jak daty i godziny odbioru i zwrotu, lokalizacje, odległości podróży i rodzaje płatności. W naszym przykładzie korzystamy z najnowszych plików Parquet na rok 2022.
- Zbiór danych do wyszukiwania stref taksówek – Zbiór danych zawierający identyfikatory lokalizacji i szczegóły odpowiednich stref dla taksówek.
W późniejszych etapach przesyłamy te zbiory danych do Amazon S3.
Utwórz zasoby rozwiązania
W tej sekcji opisano kroki konfigurowania przetwarzania i transformacji danych.
Utwórz aplikację bezserwerową EMR
Możesz utworzyć jedną lub więcej aplikacji EMR Serverless, które korzystają ze struktur analitycznych typu open source, takich jak Apache Spark lub Apache Hive. W przeciwieństwie do EMR na EC2, nie musisz usuwać ani zamykać aplikacji EMR Serverless. Aplikacja EMR Serverless to tylko definicja i raz utworzona może być ponownie używana tak długo, jak to konieczne. Dzięki temu potok MWAA jest prostszy, ponieważ teraz wystarczy przesłać zadania do wcześniej utworzonej aplikacji EMR Serverless.
Domyślnie, aplikacja EMR Serverless będzie domyślnie uruchamiana automatycznie po przesłaniu zadania i automatycznie zatrzymywana po 15 minutach bezczynności, aby zapewnić efektywność kosztową. Możesz zmodyfikować czas bezczynności lub wyłączyć tę funkcję.
Aby utworzyć aplikację za pomocą konsoli EMR Serverless, postępuj zgodnie z instrukcjami w „Utwórz aplikację bezserwerową EMR". Zanotuj identyfikator aplikacji, ponieważ będziemy go używać w kolejnych krokach.
![]()
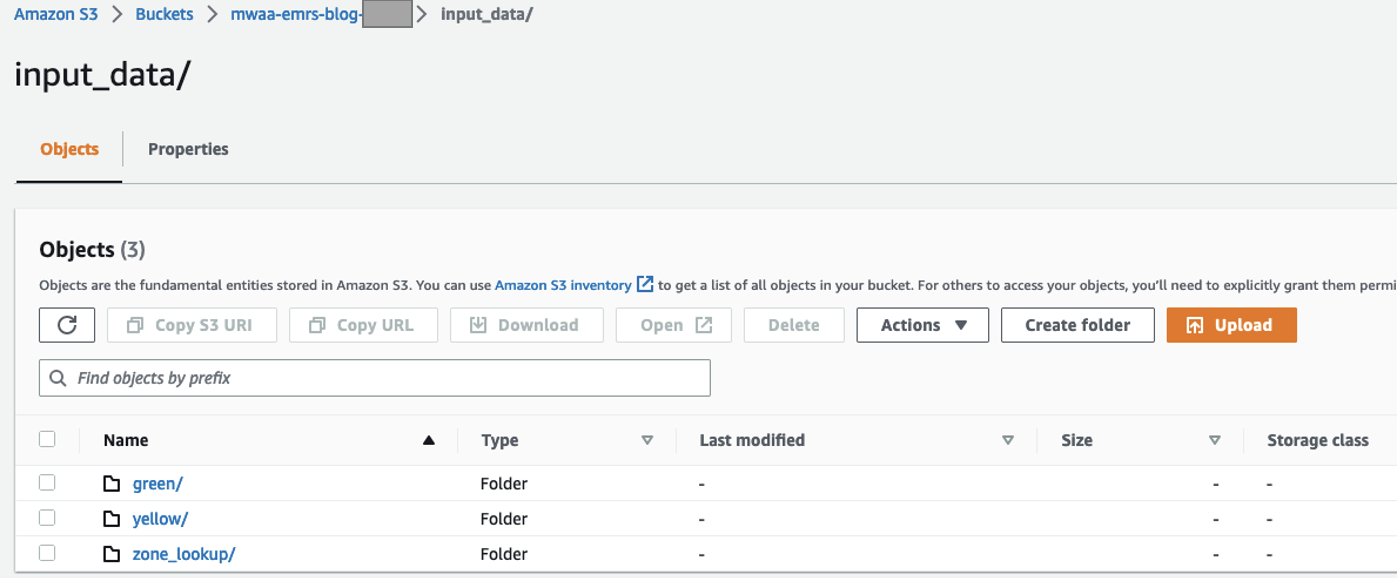
Utwórz zasobnik i foldery S3
Wykonaj następujące kroki, aby skonfigurować zasobnik i foldery S3:
- Na konsoli Amazon S3, utwórz wiadro S3 do przechowywania zbioru danych.
- Zanotuj nazwę segmentu S3, której użyjesz w późniejszych krokach.
- Tworzenie
input_datafolder do przechowywania danych wejściowych. - W tym folderze utwórz trzy osobne foldery, po jednym dla każdego zestawu danych:
green,yellow,zone_lookup.
Możesz pobrać i pracować z najnowszymi dostępnymi zbiorami danych. Do naszych testów używamy następujących plików:
- Połączenia
green/folder zawiera plikgreen_tripdata_2022-06.parquet - Połączenia
yellow/folder zawiera plikyellow_tripdata_2022-06.parquet - Połączenia
zone_lookup/folder zawiera pliktaxi_zone_lookup.csv
Skonfiguruj skrypty Amazon MWAA DAG
Wykonaj następujące kroki, aby skonfigurować skrypty DAG:
- Pobierz następujące skrypty na swój komputer lokalny:
- wymagania.txt – Zależność Pythona to dowolny pakiet lub dystrybucja, która nie jest uwzględniona w podstawowej instalacji Apache Airflow dla Twojej wersji Apache Airflow w środowisku Amazon MWAA. W tym poście używamy Boto3
version >=1.23.9. - blog_dag_mwaa_emrs_ny_taxi.py – Ten skrypt jest częścią Amazon MWAA DAG i składa się z następujących zadań:
yellow_taxi_zone_lookup,green_taxi_zone_lookup,ny_taxi_summary,. Zadania te obejmują uruchamianie zadań platformy Spark w celu wyszukiwania stref taksówek i generowanie podsumowania danych. - green_zone.py – Ten skrypt PySpark odczytuje pliki danych dotyczące przejazdów ekologiczną taksówką i wyszukiwania stref, wykonuje operację łączenia w celu ich połączenia i generuje plik wyjściowy zawierający przejazdy ekologiczną taksówką z informacjami o strefie. Wykorzystuje widoki tymczasowe dla
df_greenidf_zoneramki danych, wykonuje łączenia oparte na kolumnach i agreguje dane, takie jak liczba pasażerów, odległość podróży i wysokość opłaty. Na koniec tworzyoutput_datafolder w określonym segmencie S3, aby zapisać wynikową ramkę danych,df_green_zone, jak pliki Parquet. - żółta_zone.py – Ten skrypt PySpark przetwarza pliki danych dotyczące przejazdów żółtą taksówką i wyszukiwania stref, łącząc je w celu wygenerowania pliku wyjściowego zawierającego przejazdy żółtą taksówką z informacjami o strefie. Skrypt akceptuje podaną przez użytkownika nazwę segmentu S3 i inicjuje sesję Spark z nazwą aplikacji
yellow_zone. Odczytuje pliki żółtych taksówek i plik wyszukiwania stref z określonego segmentu S3, tworzy widoki tymczasowe, wykonuje połączenie na podstawie identyfikatora lokalizacji i oblicza statystyki, takie jak liczba pasażerów, odległość podróży i wysokość opłaty. Na koniec tworzyoutput_datafolder w określonym segmencie S3, aby zapisać wynikową ramkę danych,df_yellow_zone, jak pliki Parquet. - ny_taxi_summary.py – Ten skrypt PySpark przetwarza plik
green_zoneiyellow_zonepliki do agregowania statystyk przejazdów taksówkami, grupowania danych według stref serwisowych i identyfikatorów lokalizacji. Wymaga nazwy wiadra S3 jako argumentu wiersza poleceń, tworzy sesję SparkSession o nazwieny_taxi_summary, odczytuje pliki z S3, wykonuje łączenie i generuje nową ramkę danych o nazwieny_taxi_summary. Tworzy folder Output_data w określonym segmencie S3, aby zapisać wynikową ramkę danych w nowych plikach Parquet.
- wymagania.txt – Zależność Pythona to dowolny pakiet lub dystrybucja, która nie jest uwzględniona w podstawowej instalacji Apache Airflow dla Twojej wersji Apache Airflow w środowisku Amazon MWAA. W tym poście używamy Boto3
- Na komputerze lokalnym zaktualizuj plik
blog_dag_mwaa_emrs_ny_taxi.pyskrypt z następującymi informacjami:- Zaktualizuj nazwę segmentu S3 w następujących dwóch wierszach:
- Zaktualizuj swoją nazwę roli ARN:
- Zaktualizuj identyfikator aplikacji bezserwerowej EMR. Użyj utworzonego wcześniej identyfikatora aplikacji.
- Prześlij plik
requirements.txtplik do utworzonego wcześniej segmentu S3
- W wiadrze S3 utwórz folder o nazwie
dagsi prześlij zaktualizowanyblog_dag_mwaa_emrs_ny_taxi.pyplik z komputera lokalnego.
- Na konsoli Amazon S3 utwórz nowy folder o nazwie
scriptswewnątrz segmentu S3 i prześlij skrypty do tego folderu z komputera lokalnego.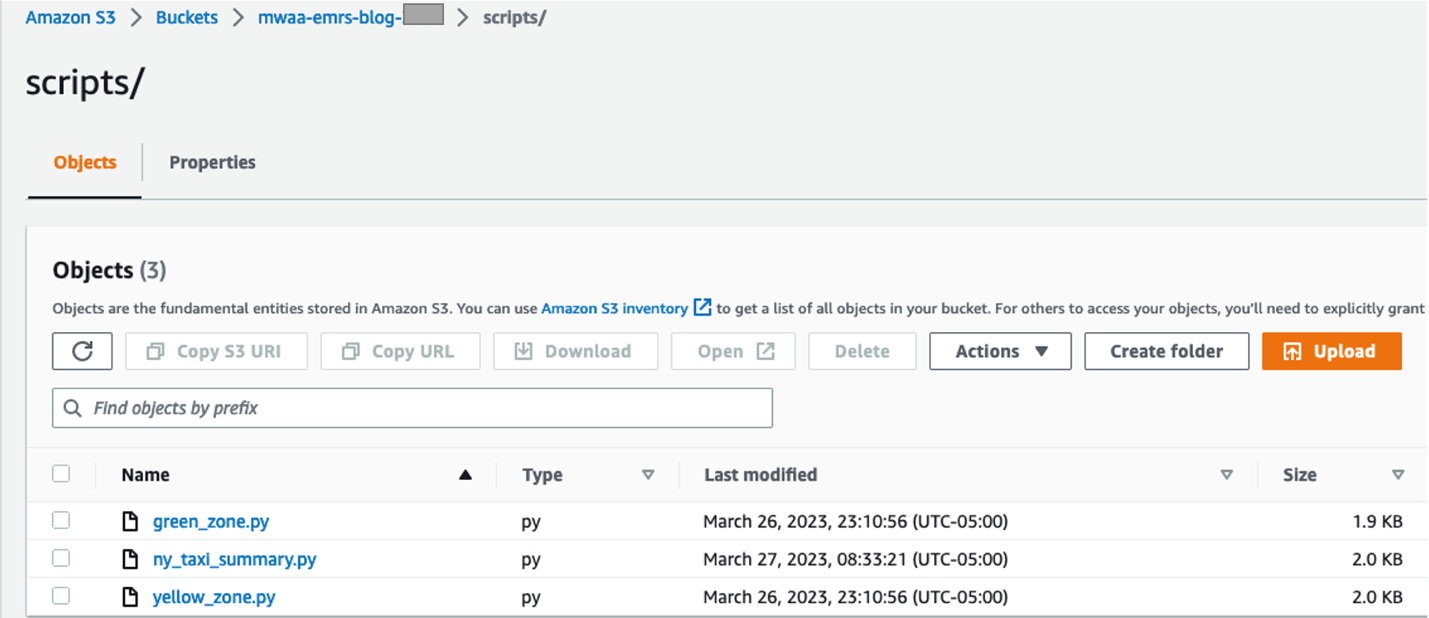
Stwórz środowisko Amazon MWAA
Aby utworzyć środowisko Airflow, wykonaj następujące kroki:
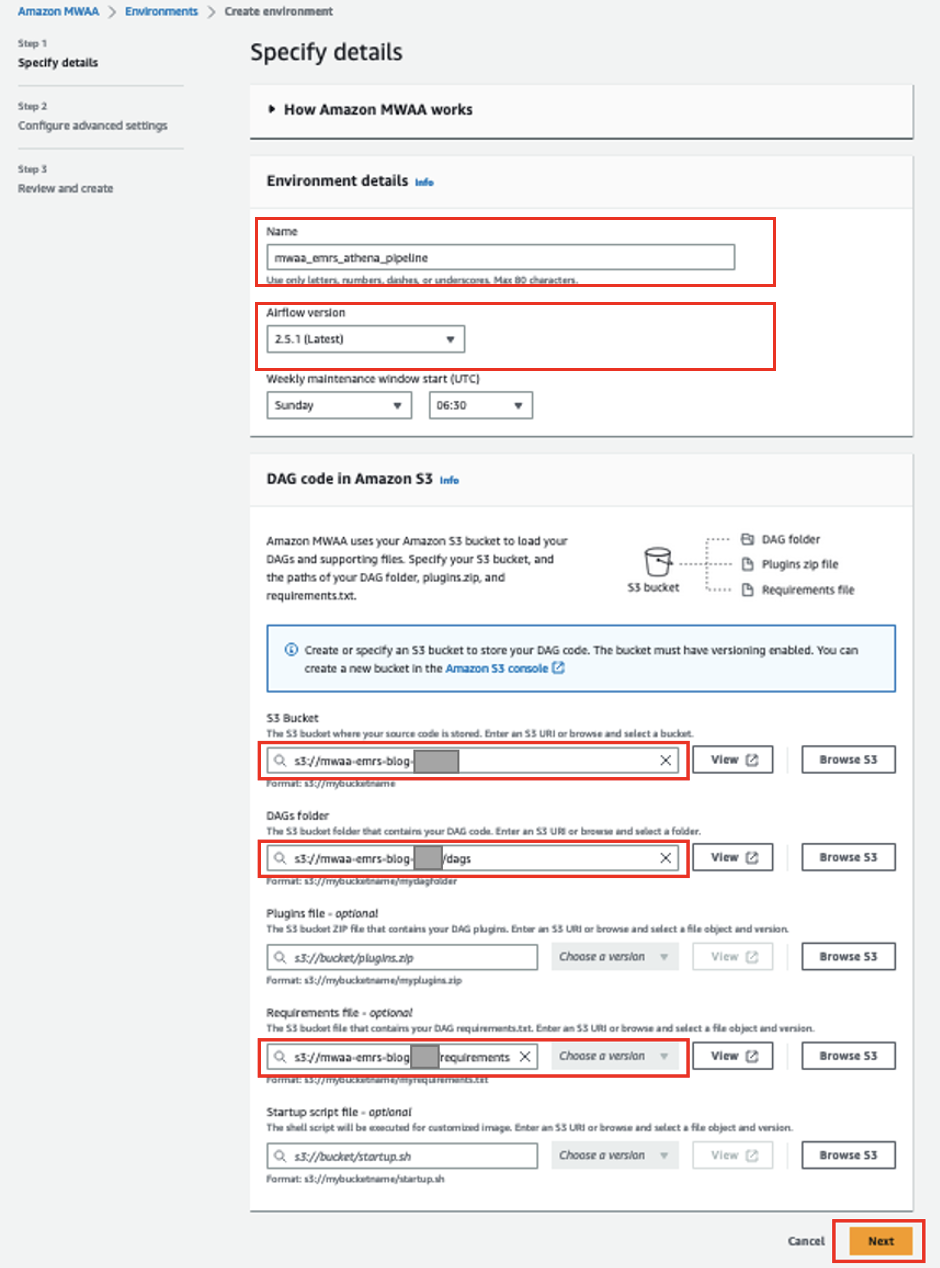
- Na konsoli Amazon MWAA wybierz Stwórz środowisko.

- W razie zamówieenia projektu Imię, wchodzić
mwaa_emrs_athena_pipeline. - W razie zamówieenia projektu Wersja z przepływem powietrza, wybierz najnowszą wersję (w tym poście 2.5.1).
- W razie zamówieenia projektu Wiadro S3, wprowadź ścieżkę do zasobnika S3.
- W razie zamówieenia projektu folderze DAG, wprowadź ścieżkę do swojego
dagsteczka. - W razie zamówieenia projektu Plik wymagań, wprowadź ścieżkę do
requirements.txtplik. - Dodaj Następna.
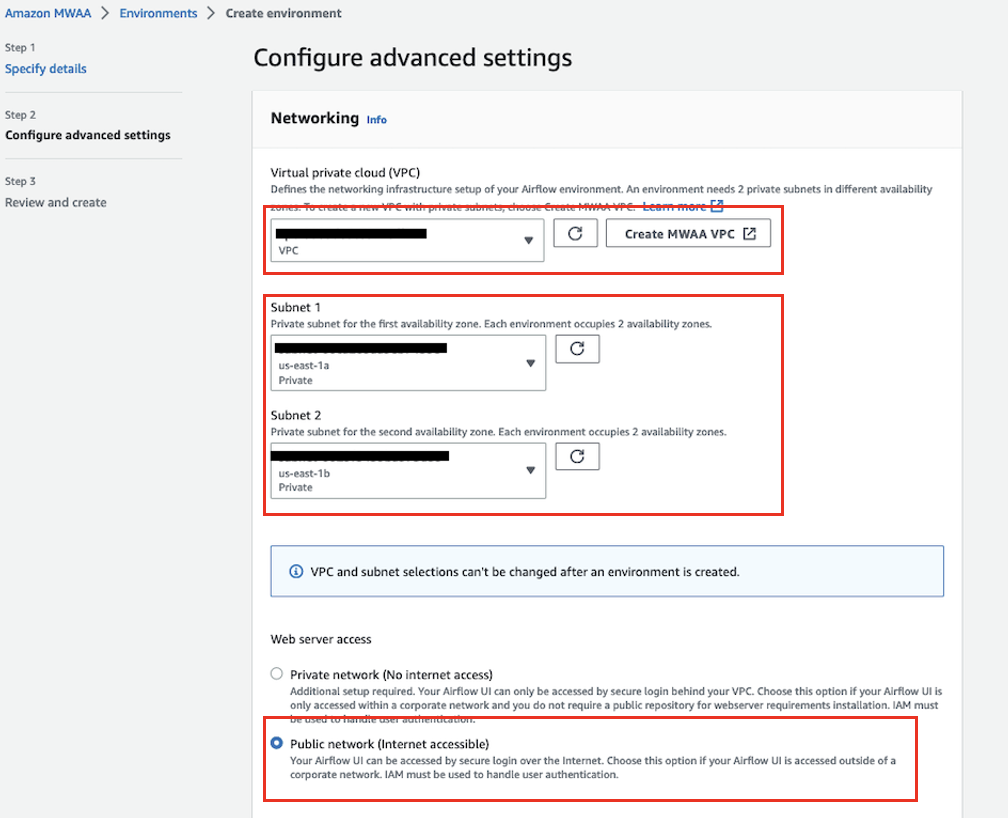
- W razie zamówieenia projektu Wirtualna chmura prywatna (VPC), wybierz VPC, która ma co najmniej dwie prywatne podsieci.
Spowoduje to zapełnienie dwóch prywatnych podsieci w Twojej sieci VPC.
- Pod Dostęp do serwera WWW, Wybierz Sieć publiczna.
Umożliwia to dostęp do interfejsu użytkownika Apache Airflow przez Internet użytkownikom, którzy mają dostęp do Polityka uprawnień dla Twojego środowiska.
- W razie zamówieenia projektu Grupa (y) bezpieczeństwa, Wybierz Utwórz nową grupę zabezpieczeń.
- W razie zamówieenia projektu Klasa środowiska, Wybierz mw1.mały.
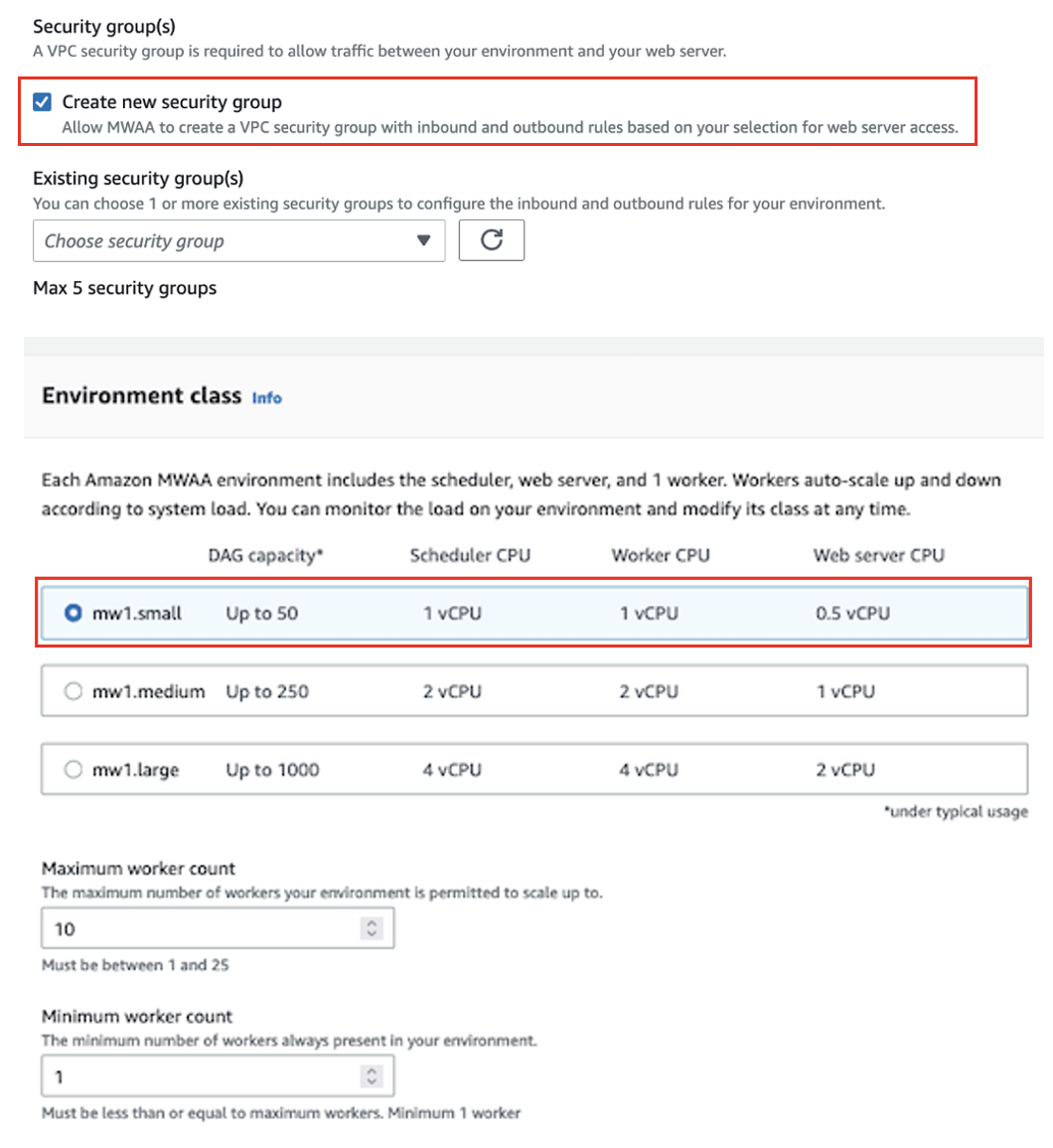
- W razie zamówieenia projektu Rola wykonawczawybierz Utwórz nową rolę.
- W razie zamówieenia projektu Nazwa roli, Wpisz imię.
- Pozostaw pozostałe konfiguracje jako domyślne i wybierz Następna.

- Na następnej stronie wybierz Stwórz środowisko.
Utworzenie środowiska Amazon MWAA może zająć około 20–30 minut.
- Kiedy stan środowiska Amazon MWAA zmieni się na Dostępny, przejdź do konsoli IAM i zaktualizuj rolę wykonywania klastra, którą chcesz dodać przekazać uprawnienia roli do
emr_serverless_execution_role.
Uruchom Amazon MWAA DAG
Aby uruchomić DAG, wykonaj następujące kroki:
- Na konsoli Amazon MWAA wybierz Środowiska w okienku nawigacji.
- Otwórz swoje środowisko i wybierz Otwórz interfejs przepływu powietrza.
- Wybierz
blog_dag_mwaa_emr_ny_taxi, wybierz ikonę odtwarzania i wybierz Wyzwalaj DAG.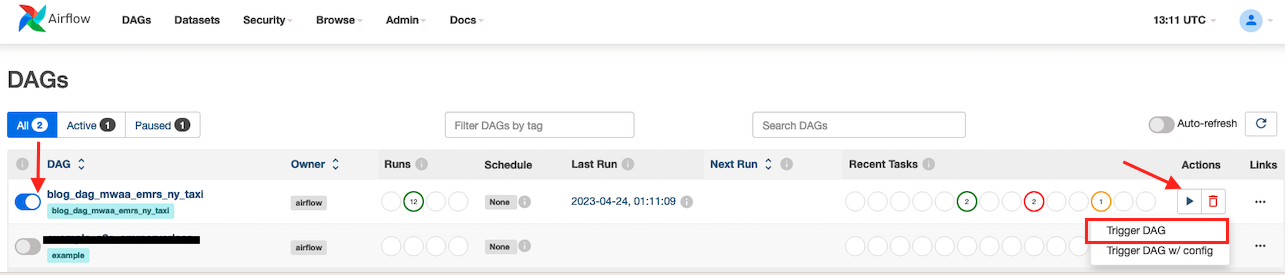
- Gdy DAG jest uruchomiony, wybierz DAG
blog_dag_mwaa_emrs_ny_taxii wybierz Wykres aby zlokalizować przepływ pracy związany z uruchomieniem DAG.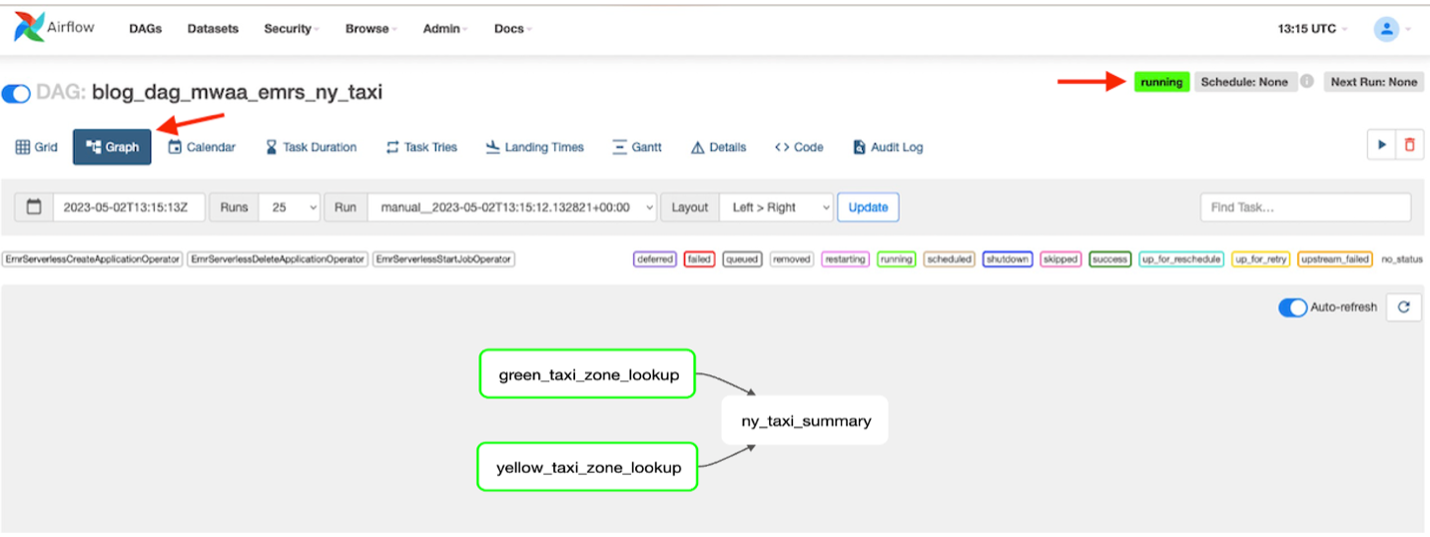
Uruchomienie wszystkich skryptów zajmie DAGowi około 4–6 minut. Zobaczysz wszystkie ukończone zadania, a ogólny status DAG będzie pokazany jako sukces.

Aby ponownie uruchomić DAG, usuń s3://<<your_s3_bucket here >>/output_data/.
Opcjonalnie, aby zrozumieć, w jaki sposób Amazon MWAA realizuje te zadania, wybierz zadanie, które chcesz sprawdzić.

Dodaj run , aby wyświetlić szczegóły uruchomienia zadania.
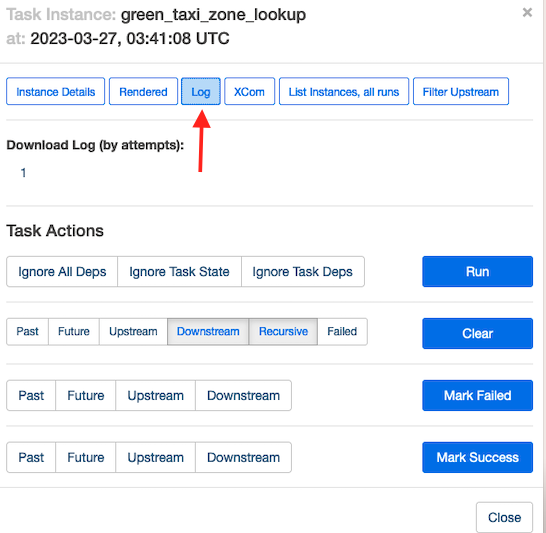
Poniższy zrzut ekranu przedstawia przykład dzienników zadań.
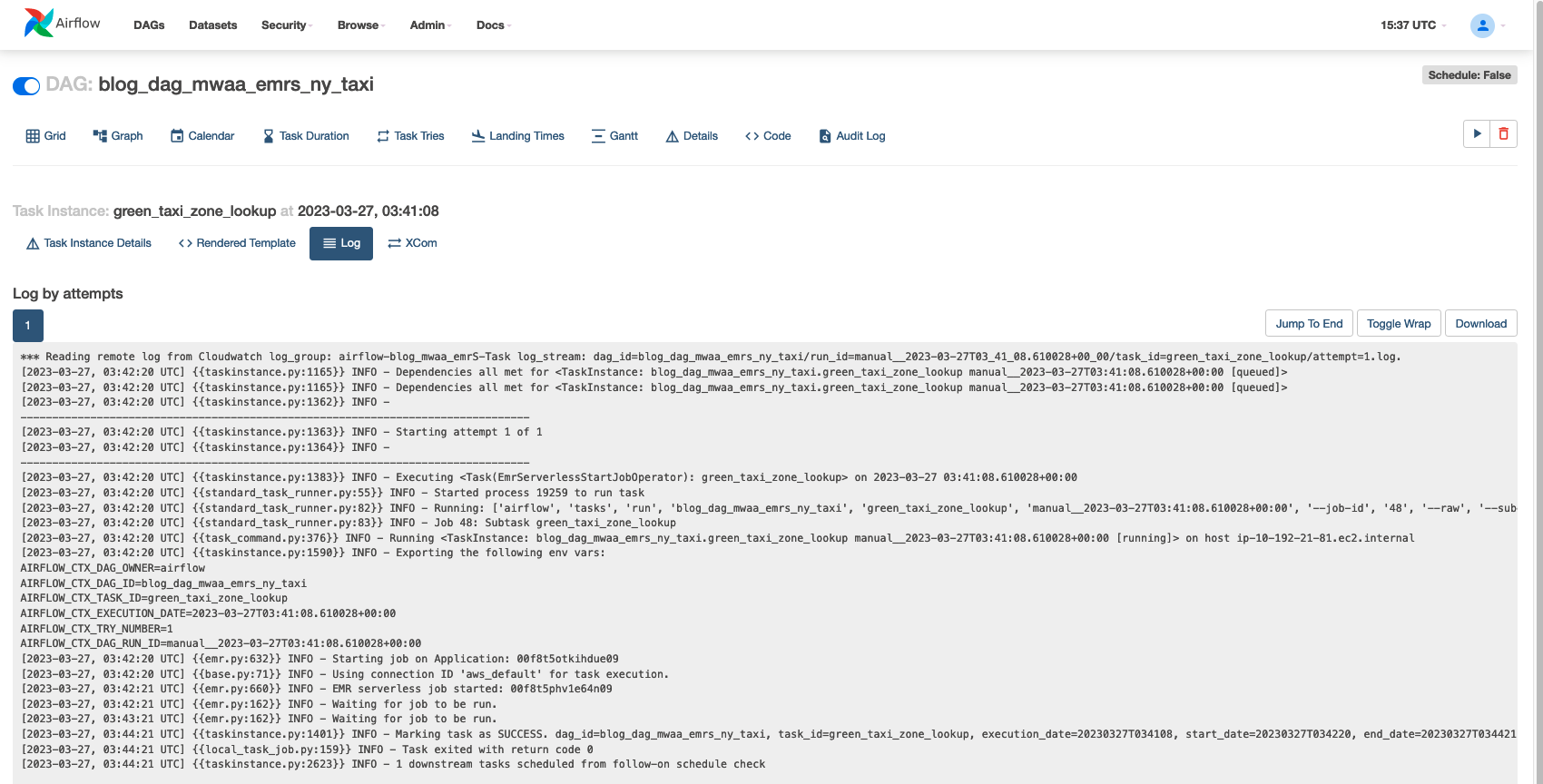
Jeśli chcesz zagłębić się w dzienniki wykonania, w konsoli EMR Serverless przejdź do „Aplikacje”. Dzienniki sterownika Apache Spark będą wskazywać inicjację zadania wraz ze szczegółami wykonawców, etapów i zadań utworzonych przez EMR Serverless. Dzienniki te mogą być pomocne w monitorowaniu postępu zadań i rozwiązywaniu problemów.
Domyślnie EMR Serverless bezpiecznie przechowuje dzienniki aplikacji w pamięci zarządzanej przez Amazon EMR przez okres 30 dni. Można jednak również określić Amazon S3 lub Amazon CloudWatch jako opcje dostarczania dziennika podczas przesyłania zadania.

Zweryfikuj ostateczny zestaw wyników za pomocą narzędzia Athena
Zweryfikujmy dane załadowane przez proces za pomocą zapytań SQL Athena.
- Na konsoli Athena wybierz Edytor zapytań w okienku nawigacji.
- Jeśli używasz Ateny po raz pierwszy, poniżej Ustawieniawybierz zarządzanie i wprowadź utworzoną wcześniej lokalizację zasobnika S3 (
<S3_BUCKET_NAME>/athena), następnie wybierz Zapisz.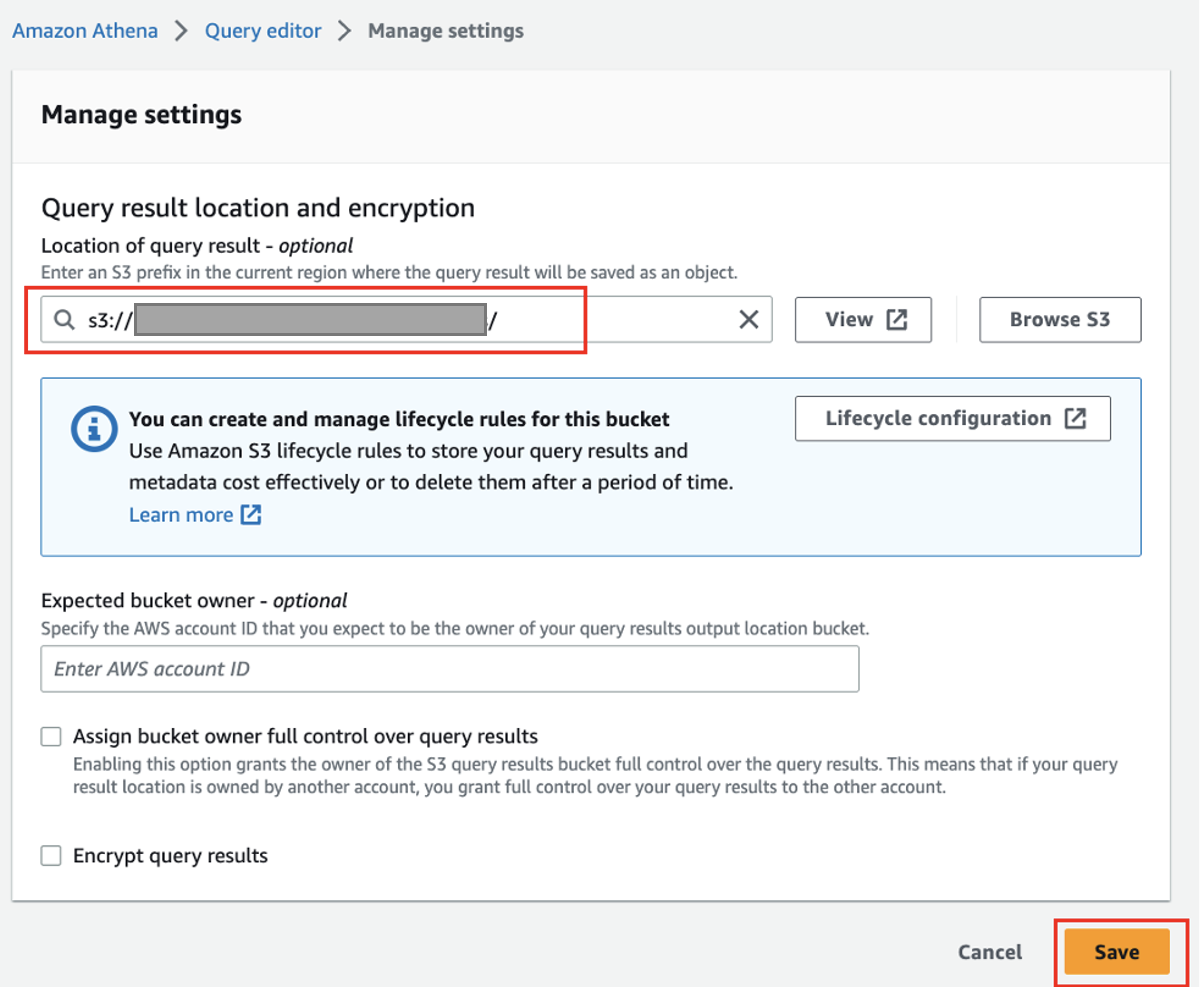
- W edytorze zapytań wprowadź następujące zapytanie, aby utworzyć tabelę zewnętrzną:

Uruchom następujące zapytanie na ostatnio utworzonym pliku ny_taxi_summary table, aby pobrać pierwsze 10 wierszy w celu sprawdzenia poprawności danych:

Sprzątać
Aby zapobiec przyszłym opłatom, wykonaj następujące kroki:
- Na konsoli Amazon S3 usuń segment S3 utworzony do przechowywania plików Amazon MWAA DAG, skryptów i dzienników.
- Na konsoli Athena upuść utworzoną tabelę:
- Na konsoli Amazon MWAA przejdź do utworzonego środowiska i wybierz je Usuń.

- W konsoli EMR Studio usuń aplikację.
Aby usunąć aplikację, przejdź do Lista aplikacji strona. Wybierz utworzoną aplikację i wybierz Akcje → Zatrzymaj aby zatrzymać aplikację. Gdy aplikacja znajdzie się w stanie ZATRZYMANA, wybierz tę samą aplikację i wybierz Akcje → Usuń.

Wnioski
Inżynieria danych jest kluczowym elementem wielu organizacji, a wraz ze wzrostem ilości danych konieczne jest znalezienie sposobów usprawnienia przepływów pracy związanych z przetwarzaniem danych. Połączenie Amazon MWAA, EMR Serverless i Athena zapewnia potężne rozwiązanie do wydajnego tworzenia, uruchamiania i zarządzania potokami danych. Dzięki temu kompleksowemu procesowi przetwarzania danych inżynierowie danych mogą z łatwością przetwarzać i analizować duże ilości danych, szybko i oszczędnie, bez konieczności zarządzania złożoną infrastrukturą. Integracja tych usług AWS zapewnia solidne i skalowalne rozwiązanie do przetwarzania danych, pomagając organizacjom w podejmowaniu świadomych decyzji w oparciu o wiedzę o danych.
Teraz, gdy wiesz, jak przesyłać zadania Spark w systemie EMR Serverless za pośrednictwem usługi Amazon MWAA, zachęcamy Cię do korzystania z usługi Amazon MWAA w celu utworzenia przepływu pracy, który będzie uruchamiał zadania PySpark za pośrednictwem usługi EMR Serverless.
Czekamy na Twoje opinie i zapytania. Jeśli masz jakiekolwiek pytania lub uwagi, skontaktuj się z nami.
O autorach
 Rahula Sonawane jest głównym architektem rozwiązań analitycznych w AWS ze specjalizacją AI/ML i Analytics.
Rahula Sonawane jest głównym architektem rozwiązań analitycznych w AWS ze specjalizacją AI/ML i Analytics.
 Gaurava Parekha jest architektem rozwiązań pomagającym klientom AWS budować nowoczesną architekturę na dużą skalę. Specjalizuje się w analizie danych i networkingu. Poza pracą Gaurav lubi grać w krykieta, piłkę nożną i siatkówkę.
Gaurava Parekha jest architektem rozwiązań pomagającym klientom AWS budować nowoczesną architekturę na dużą skalę. Specjalizuje się w analizie danych i networkingu. Poza pracą Gaurav lubi grać w krykieta, piłkę nożną i siatkówkę.
Historia audytu
Grudzień 2023: Santosh Gantaram, starszy menedżer ds. klientów technicznych sprawdził ten post pod kątem poprawności technicznej.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-spark-jobs-with-amazon-mwaa-and-data-validation-using-amazon-athena/
- :ma
- :Jest
- :nie
- $W GÓRĘ
- 1
- 10
- 100
- 118
- 15%
- 16
- 2022
- 2023
- 23
- 25
- 30
- 300
- 7
- 700
- 8
- 9
- 990
- a
- O nas
- Akceptuje
- dostęp
- dostęp
- Konto
- precyzja
- Dodaj
- Po
- agregat
- AI / ML
- Wszystkie kategorie
- pozwala
- wzdłuż
- już
- również
- Amazonka
- Amazonka Atena
- Amazon EMR
- Amazon Web Services
- ilość
- kwoty
- an
- analityka
- w czasie rzeczywistym sprawiają,
- i
- każdy
- Apache
- Apache Spark
- Zastosowanie
- aplikacje
- w przybliżeniu
- architektura
- SĄ
- POWIERZCHNIA
- argument
- AS
- At
- automatycznie
- dostępny
- AWS
- z powrotem
- baza
- na podstawie
- BE
- stają się
- staje się
- pomiędzy
- Duży
- Big Data
- budować
- Budowanie
- wybudowany
- biznes
- by
- oblicza
- CAN
- katalog
- zmiana
- Zmiany
- Opłaty
- Dodaj
- klasyfikacja
- Chmura
- Grupa
- kod
- połączenie
- połączyć
- byliśmy spójni, od początku
- komentarze
- kompletny
- kompleks
- składnik
- składa się
- Konsola
- kontynuować
- Odpowiedni
- Koszty:
- opłacalne
- Koszty:
- Stwórz
- stworzony
- tworzy
- krykiet
- krytyczny
- Klientów
- DZIEŃ
- dane
- Analityka danych
- analiza danych
- zbiory danych
- Daty
- Dni
- Decyzje
- głęboko
- Domyślnie
- definicja
- dostawa
- Zależności
- Zależność
- detale
- dystans
- 分配
- nurkować
- do
- nie
- Podwójna
- na dół
- pobieranie
- kierowca
- Spadek
- podczas
- e
- każdy
- Wcześniej
- z łatwością
- łatwo
- redaktor
- efektywność
- wydajny
- skutecznie
- zachęcać
- koniec końców
- Inżynieria
- Inżynierowie
- zapewnić
- Wchodzę
- Środowisko
- niezbędny
- Eter (ETH)
- przykład
- egzekucja
- zewnętrzny
- dodatkowy
- Awarie
- Cecha
- informacja zwrotna
- czuć
- filet
- Akta
- finał
- Znajdź
- i terminów, a
- pierwszy raz
- Skupiać
- obserwuj
- następujący
- W razie zamówieenia projektu
- format
- FRAME
- Ramy
- Darmowy
- od
- w pełni
- przyszłość
- Generować
- generuje
- generujący
- udzielony
- Zielony
- Rosnąć
- Rośnie
- Hadoop
- uchwyt
- Have
- he
- pomoc
- pomocny
- pomoc
- tutaj
- jego
- Ul
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- Idle
- ids
- if
- zilustrować
- ilustruje
- in
- zawierać
- włączony
- obejmuje
- coraz bardziej
- wskazać
- Informacja
- poinformowany
- Infrastruktura
- Inicjuje
- inicjacja
- wkład
- Zapytania
- wewnątrz
- spostrzeżenia
- zainstalować
- zamiast
- instrukcje
- integracja
- interakcji
- interaktywne
- Internet
- angażować
- IT
- Praca
- Oferty pracy
- przystąpić
- łączący
- Łączy
- jpg
- właśnie
- duży
- w końcu
- później
- firmy
- lubić
- LIMIT
- Linia
- linie
- miejscowy
- lokalizacja
- lokalizacji
- log
- długo
- poszukuje
- wyszukiwania
- maszyna
- robić
- WYKONUJE
- Dokonywanie
- zarządzanie
- zarządzane
- kierownik
- zarządzający
- wiele
- Może..
- Metadane
- minimum
- minuty
- Nowoczesne technologie
- modyfikować
- monitor
- jeszcze
- Nazwa
- O imieniu
- Nawigacja
- Nawigacja
- Potrzebować
- potrzebne
- sieci
- Nowości
- Następny
- żaden
- już dziś
- NYC
- of
- poza
- on
- pewnego razu
- ONE
- tylko
- koncepcja
- open source
- działanie
- operatorzy
- Opcje
- or
- organizacji
- Inne
- ludzkiej,
- na zewnątrz
- wytyczne
- wydajność
- zewnętrzne
- koniec
- ogólny
- pakiet
- strona
- chleb
- część
- ścieżka
- płatność
- wykonuje
- okres
- rurociąg
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- gra
- Proszę
- polityka
- możliwy
- Post
- mocny
- warunki wstępne
- zapobiec
- Główny
- prywatny
- wygląda tak
- procesów
- przetwarzanie
- Postęp
- dostawca
- zapewnia
- że
- publicznie
- Python
- zapytania
- pytania
- szybko
- dosięgnąć
- niedawno
- dokumentacja
- zmniejszyć
- rzetelny
- usunąć
- wymagać
- Wymaga
- Zasoby
- dalsze
- wynikły
- recenzja
- zmarszczka
- przejażdżki
- krzepki
- Rola
- RZĄD
- run
- bieganie
- działa
- s
- taki sam
- skalowalny
- Skala
- waga
- skalowaniem
- rozkład
- scenariusz
- skrypty
- Sekcja
- bezpiecznie
- bezpieczeństwo
- widzieć
- widziany
- wybierać
- oddzielny
- serwer
- Bezserwerowe
- usługa
- Usługi
- Sesja
- zestaw
- ustawienie
- powinien
- pokazać
- Targi
- Prosty
- upraszczać
- So
- Piłka nożna
- rozwiązanie
- Rozwiązania
- Źródło
- Iskra
- specjalizuje się
- Specjalność
- określony
- SQL
- etapy
- standard
- Stan
- statystyka
- Rynek
- Cel
- Stop
- zatrzymany
- przechowywanie
- sklep
- przechowywany
- opływowy
- sznur
- studio
- uległość
- Zatwierdź
- podsieci
- taki
- PODSUMOWANIE
- Wspierający
- stół
- Brać
- Zadanie
- zadania
- Techniczny
- tymczasowy
- Testowanie
- że
- Połączenia
- ich
- Im
- następnie
- Te
- to
- trzy
- czas
- czasy
- do
- już dziś
- Przekształcać
- Transformacja
- przekształcony
- wyzwalać
- wycieczka
- SKRĘCAĆ
- drugiej
- typy
- ui
- dla
- zrozumieć
- w odróżnieniu
- Aktualizacja
- zaktualizowane
- us
- posługiwać się
- Użytkownicy
- zastosowania
- za pomocą
- wykorzystuje
- UPRAWOMOCNIĆ
- uprawomocnienie
- wersja
- przez
- Zobacz i wysłuchaj
- widoki
- Tom
- kłęby
- chcieć
- była
- sposoby
- we
- sieć
- usługi internetowe
- powitanie
- były
- jeśli chodzi o komunikację i motywację
- który
- będzie
- w
- bez
- Praca
- workflow
- przepływów pracy
- martwić się
- martwiąc
- napisać
- z żółtymi
- ty
- Twój
- zefirnet
- Strefy