
Zdjęcie autora
Analiza danych to interdyscyplinarna dziedzina, która w dużym stopniu opiera się na wydobywaniu spostrzeżeń i podejmowaniu świadomych decyzji na podstawie ogromnych ilości danych. Jednym z podstawowych narzędzi w zestawie narzędzi analityka danych jest SQL (Structured Query Language), język programowania przeznaczony do zarządzania relacyjnymi bazami danych i manipulowania nimi.
W tym artykule skupię się na jednej z najpotężniejszych funkcji SQL: złączeniach.
Złączenia SQL umożliwiają łączenie danych z wielu tabel bazy danych w oparciu o wspólne kolumny. W ten sposób można łączyć informacje i tworzyć znaczące połączenia między powiązanymi zbiorami danych.
Istnieje kilka typy złączeń SQL:
- Wewnętrzne dołączenie
- Lewe sprzężenie zewnętrzne
- Prawe połączenie zewnętrzne
- Pełne połączenie zewnętrzne
- Połącz krzyżowo
Wyjaśnijmy każdy typ.
Sprzężenie wewnętrzne zwraca tylko te wiersze, w których występuje dopasowanie w obu łączonych tabelach. Łączy wiersze z dwóch tabel w oparciu o wspólny klucz lub kolumnę, odrzucając niepasujące wiersze.
Wizualizujemy to w następujący sposób.
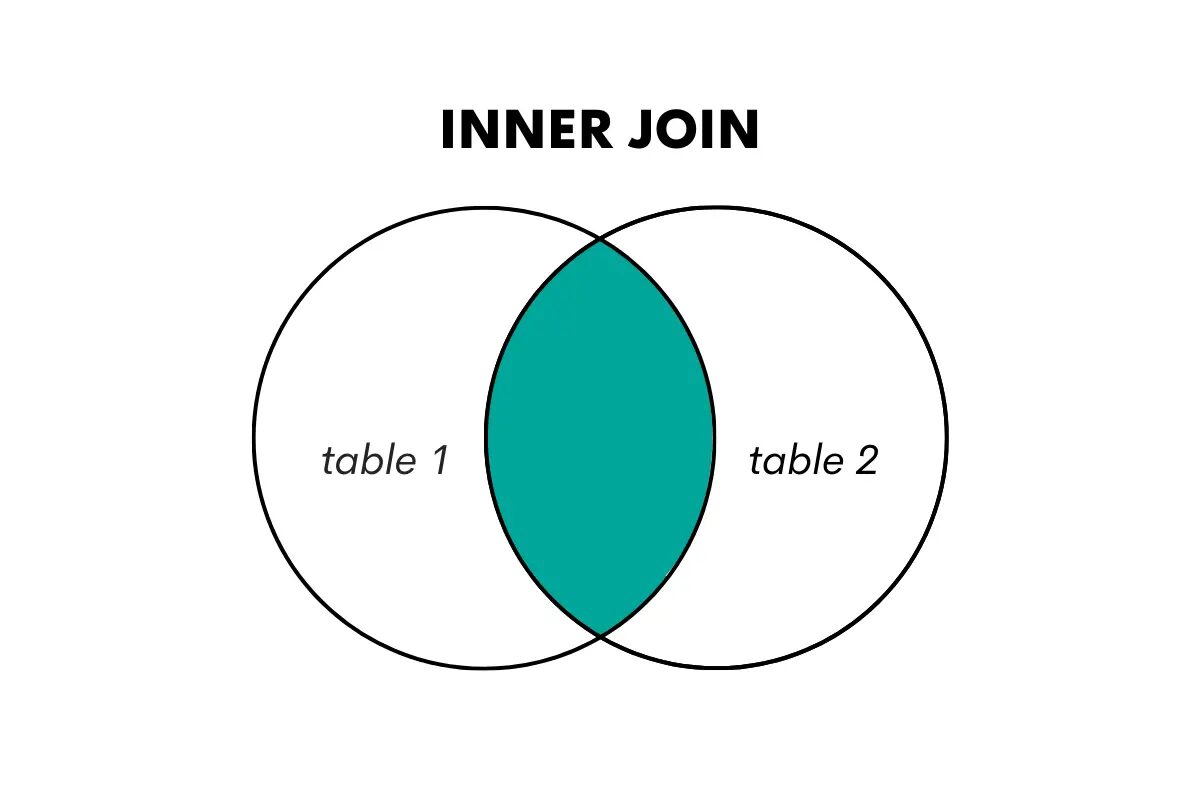
Zdjęcie autora
W języku SQL ten typ łączenia jest wykonywany za pomocą słów kluczowych JOIN lub INNER JOIN.
Lewe sprzężenie zewnętrzne zwraca wszystkie wiersze z lewej (lub pierwszej) tabeli i dopasowane wiersze z prawej (lub drugiej) tabeli. Jeśli nie ma dopasowania, zwraca wartości NULL dla kolumn z prawej tabeli.
Możemy to sobie tak wyobrazić.
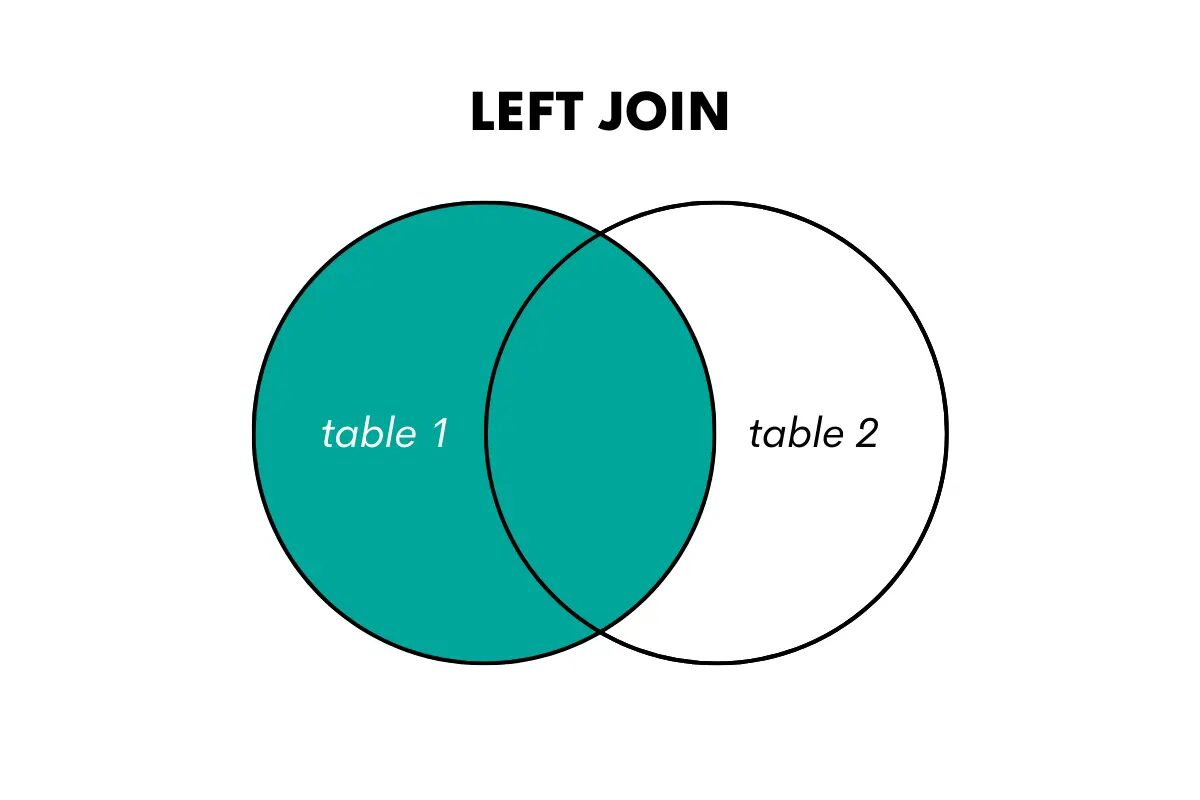
Zdjęcie autora
Jeśli chcesz użyć tego łączenia w SQL, możesz to zrobić, używając słów kluczowych LEFT OUTER JOIN lub LEFT JOIN. Oto artykuł, w którym jest mowa o lewe połączenie vs lewe połączenie zewnętrzne.
Złączenie prawe jest przeciwieństwem złączenia lewego. Zwraca wszystkie wiersze z prawej tabeli i dopasowane wiersze z lewej tabeli. Jeśli nie ma dopasowania, zwraca wartości NULL dla kolumn z lewej tabeli.
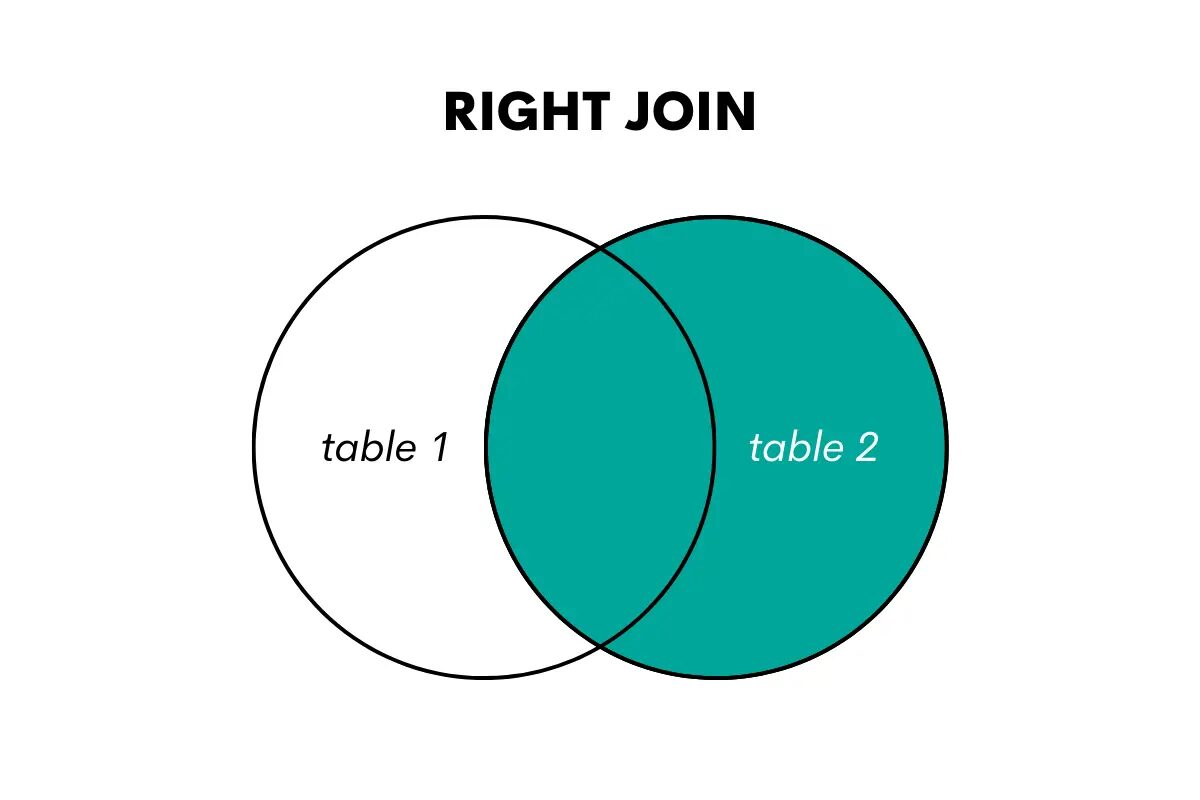
Zdjęcie autora
W języku SQL ten typ łączenia jest wykonywany za pomocą słów kluczowych RIGHT OUTER JOIN lub RIGHT JOIN.
Pełne złączenie zewnętrzne zwraca wszystkie wiersze z obu tabel, dopasowując je, jeśli to możliwe, i wypełniając wartości NULL w przypadku niepasujących wierszy.
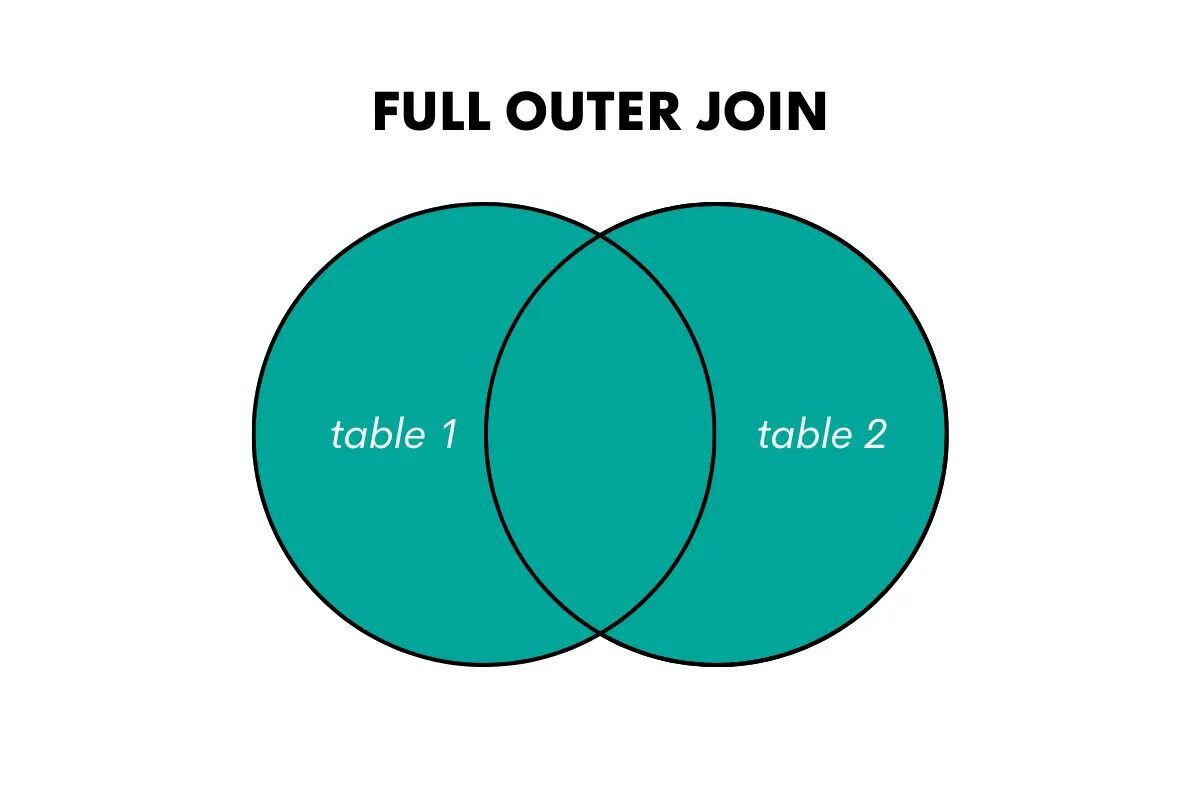
Zdjęcie autora
Słowa kluczowe w języku SQL dla tego łączenia to FULL OUTER JOIN lub FULL JOIN.
Ten typ złączenia łączy wszystkie wiersze z jednej tabeli ze wszystkimi wierszami z drugiej tabeli. Inaczej mówiąc, zwraca iloczyn kartezjański, czyli wszystkie możliwe kombinacje wierszy obu tabel.
Oto wizualizacja, która ułatwi zrozumienie.
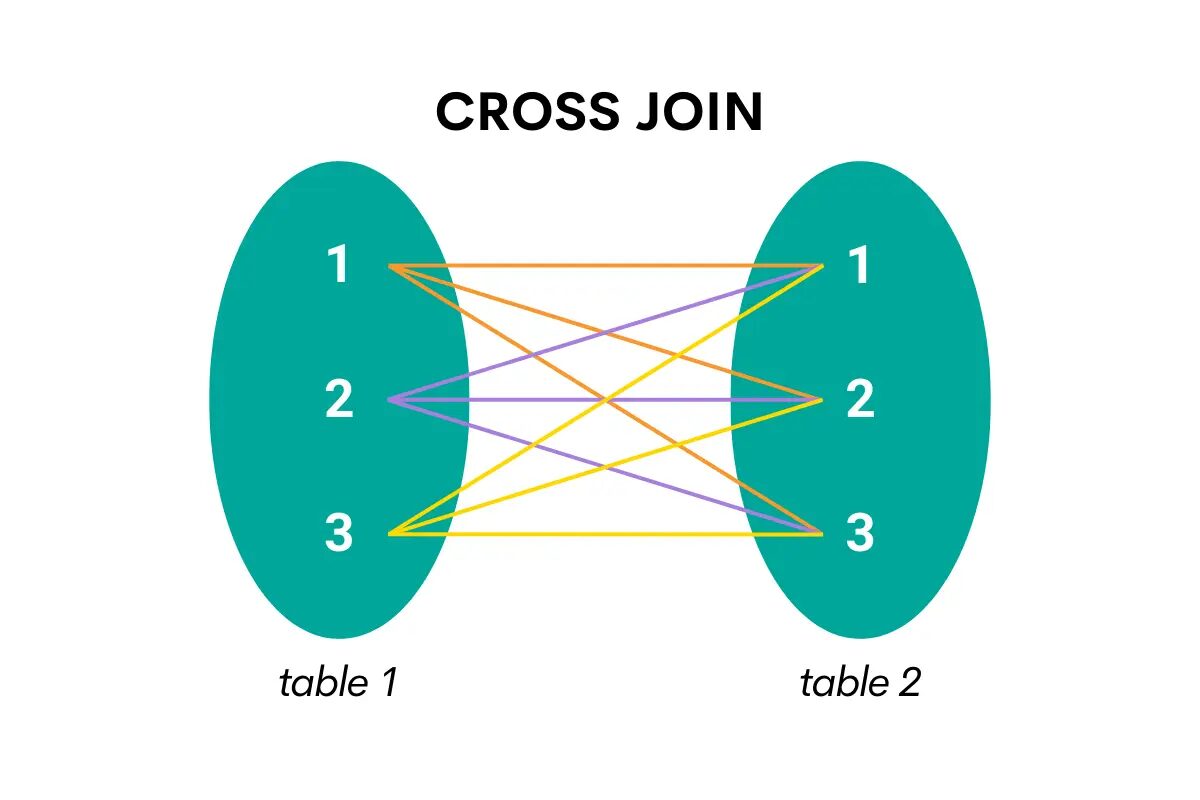
Zdjęcie autora
Podczas łączenia krzyżowego w SQL słowem kluczowym jest CROSS JOIN.
Aby wykonać złączenie w SQL, należy określić tabele, które chcemy złączyć, kolumny użyte do dopasowania oraz typ złączenia, które chcemy wykonać. Podstawowa składnia łączenia tabel w SQL jest następująca:
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;
Ten przykład pokazuje, jak używać JOIN.
Odwołujesz się do pierwszej (lub lewej) tabeli w klauzuli FROM. Następnie wykonaj polecenie JOIN i odwołuj się do drugiej (lub prawej) tabeli.
Następnie pojawia się warunek łączenia w klauzuli ON. W tym miejscu określasz, których kolumn użyjesz do połączenia dwóch tabel. Zwykle jest to kolumna współdzielona, która jest kluczem podstawowym w jednej tabeli i kluczem obcym w drugiej tabeli.
Uwaga: Klucz podstawowy to unikalny identyfikator każdego rekordu w tabeli. Klucz obcy ustanawia połączenie pomiędzy dwiema tabelami, tzn. jest kolumną w drugiej tabeli, która odwołuje się do pierwszej tabeli. Na przykładach pokażemy, co to oznacza.
Jeśli chcesz użyć LEFT JOIN, RIGHT JOIN lub FULL JOIN, po prostu użyj tych słów kluczowych zamiast JOIN – wszystko inne w kodzie jest dokładnie takie samo!
Sprawy mają się nieco inaczej w przypadku CROSS JOIN. Jej istotą jest łączenie wszystkich kombinacji wierszy obu tabel. Dlatego klauzula ON nie jest potrzebna, a składnia wygląda tak.
SELECT columns
FROM table1
CROSS JOIN table2;
Innymi słowy, po prostu odwołujesz się do jednej tabeli w FROM i drugiej w CROSS JOIN.
Alternatywnie możesz odwołać się do obu tabel w FROM i oddzielić je przecinkiem – jest to skrót od CROSS JOIN.
SELECT columns
FROM table1, table2;Istnieje również jeden specyficzny sposób łączenia stołów – łączenie stołu ze sobą. Nazywa się to również samodzielnym dołączeniem do stołu.
Nie jest to całkiem odrębny typ łączenia, ponieważ każdy z wcześniej wymienionych typów łączenia może być również używany do samodzielnego łączenia.
Składnia samodzielnego łączenia jest podobna do tej, którą pokazałem wcześniej. Główną różnicą jest to, że do tej samej tabeli odwołują się polecenia FROM i JOIN.
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;
Musisz także nadać tabeli dwa aliasy, aby je rozróżnić. Łączysz stół ze sobą i traktujesz go jak dwa stoły.
Chciałem tylko o tym wspomnieć, ale nie będę wchodził w szczegóły. Jeśli jesteś zainteresowany samodzielnym dołączeniem, zapoznaj się z tym ilustrowanym przewodnikiem na temat samodzielne połączenie w SQL.
Czas pokazać jak wszystko o czym wspomniałem sprawdza się w praktyce. skorzystam Pytania do rozmowy kwalifikacyjnej SQL JOIN ze StrataScratch, aby zaprezentować każdy odrębny typ łączenia w SQL.
1. DOŁĄCZ Przykład
To pytanie zadane przez Microsoft chce, abyś spisał każdy projekt i obliczył budżet projektu przez pracownika.
Drogie projekty
„Mając listę projektów i pracowników przypisanych do każdego projektu, oblicz kwotę budżetu projektu przydzieloną każdemu pracownikowi. Wynik powinien zawierać tytuł projektu i budżet projektu zaokrąglony do najbliższej liczby całkowitej. Najpierw uporządkuj listę według projektów o najwyższym budżecie na pracownika.”
Dane
Pytanie daje dwie tabele.
ms_projekty
| id: | int |
| tytuł: | Varchar |
| budżet: | int |
ms_emp_projects
| em_id: | int |
| identyfikator_projektu: | int |
Teraz identyfikator kolumny w tabeli ms_projekty jest kluczem podstawowym tabeli. Tę samą kolumnę znajdziesz w tabeli ms_emp_projects, aczkolwiek pod inną nazwą: id_projektu. To jest klucz obcy tabeli, odwołujący się do pierwszej tabeli.
Użyję tych dwóch kolumn, aby połączyć tabele w moim rozwiązaniu.
Code
SELECT title AS project, ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
Połączyłem dwie tabele za pomocą JOIN. Stół ms_projekty jest mowa w FROM, podczas gdy ms_emp_projects pojawia się po JOIN. Obu tabelom nadałem aliasy, co pozwala mi nie używać później długich nazw tabel.
Teraz muszę określić kolumny, na których chcę połączyć tabele. Wspomniałem już, które kolumny są kluczem podstawowym w jednej tabeli, a kluczem obcym w innej tabeli, więc użyję ich tutaj.
Wyrównuję te dwie kolumny, ponieważ chcę uzyskać wszystkie dane, w których identyfikator projektu jest taki sam. Użyłem także aliasów tabel przed każdą kolumną.
Teraz, gdy mam dostęp do danych w obu tabelach, mogę wyświetlić kolumny w SELECT. Pierwsza kolumna to nazwa projektu, druga kolumna jest obliczana.
W tym obliczeniu używana jest funkcja COUNT(), aby policzyć liczbę pracowników w każdym projekcie. Następnie dzielę budżet każdego projektu przez liczbę pracowników. Konwertuję również wynik na wartości dziesiętne i zaokrąglam go do zera miejsc po przecinku.
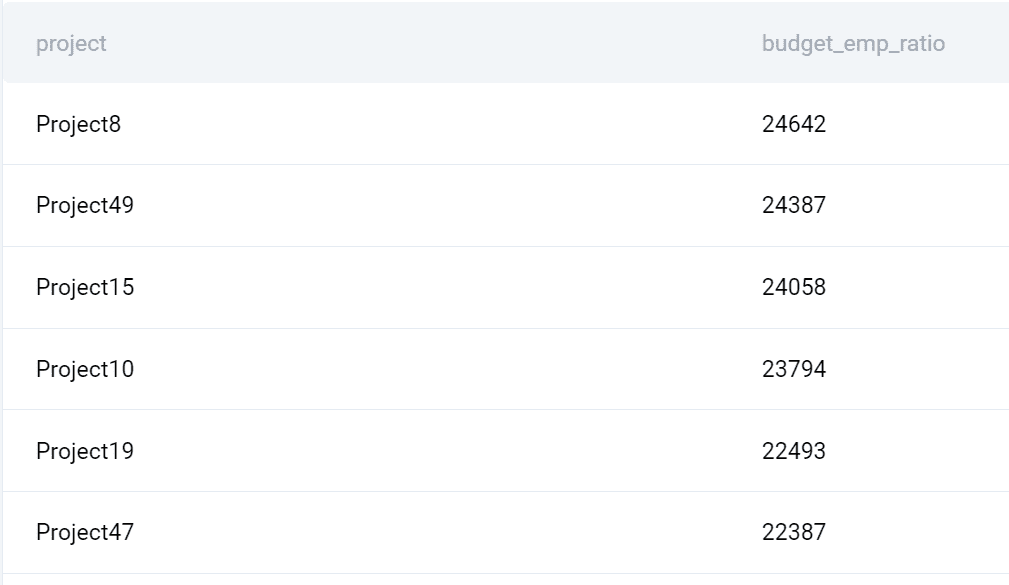
Wydajność
Oto co zwraca zapytanie.
2. Przykład LEWEGO DOŁĄCZENIA
Poćwiczmy to łączenie na Pytanie do rozmowy kwalifikacyjnej Airbnb. Chce, abyś znalazł liczbę zamówień, liczbę klientów i całkowity koszt zamówień dla każdego miasta.
Zamówienia i szczegóły klientów
„Znajdź liczbę zamówień, liczbę klientów i całkowity koszt zamówień dla każdego miasta. Uwzględnij tylko miasta, które złożyły co najmniej 5 zamówień i policz wszystkich klientów w każdym mieście, nawet jeśli nie złożyli oni zamówienia.
Wyprowadź każde obliczenie wraz z odpowiednią nazwą miasta.
Dane
Dostajesz stoły klienci, i Zlecenia.
klienci
| id: | int |
| imię: | Varchar |
| nazwisko: | Varchar |
| miasto: | Varchar |
| adres: | Varchar |
| numer telefonu: | Varchar |
Zlecenia
| id: | int |
| identyfikator_custa: | int |
| Data zamówienia: | data i godzina |
| Szczegóły zamówienia: | Varchar |
| całkowity_koszt_zamówienia: | int |
Wspólne kolumny mają identyfikator z tabeli klienci i cust_id z tabeli Zlecenia. Użyję tych kolumn do połączenia tabel.
Code
Oto jak rozwiązać to pytanie za pomocą LEFT JOIN.
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
Odsyłam do tabeli klienci w FROM (to jest nasz lewy stół) i LEWY DOŁĄCZ do niego Zlecenia w kolumnach identyfikatora klienta.
Teraz mogę wybrać miasto, użyć funkcji COUNT(), aby uzyskać liczbę zamówień i klientów według miast, oraz użyć funkcji SUM(), aby obliczyć całkowity koszt zamówień według miast.
Aby uzyskać wszystkie te obliczenia według miast, grupuję wyniki według miast.
W pytaniu jest jedno dodatkowe żądanie: „Uwzględnij tylko miasta, które złożyły co najmniej 5 zamówień…” Używam HAVING, aby pokazać tylko miasta, które mają co najmniej pięć zamówień, aby to osiągnąć.
Pytanie brzmi, dlaczego użyłem LEFT JOIN i uwaga DOŁĄCZ? Wskazówka tkwi w pytaniu: „…i policz wszystkich klientów w każdym mieście, nawet jeśli nie złożyli zamówienia”. Możliwe, że nie wszyscy klienci złożyli zamówienia. Oznacza to, że chcę pokazać wszystkich klientów z tabeli klienci, co idealnie pasuje do definicji LEFT JOIN.
Gdybym użył JOIN, wynik byłby błędny, ponieważ przegapiłbym klientów, którzy nie złożyli żadnych zamówień.
Uwaga: Złożoność złączeń w SQL nie odzwierciedla ich składnia, ale semantyka! Jak widziałeś, każde łączenie jest napisane w ten sam sposób, zmienia się tylko słowo kluczowe. Jednak każde połączenie działa inaczej i dlatego może dawać różne wyniki w zależności od danych. Z tego powodu ważne jest, abyś w pełni rozumiał, co robi każde połączenie i wybrał to, które zwróci dokładnie to, czego chcesz!
Wydajność
Przyjrzyjmy się teraz wynikom.

3. Przykład PRAWEGO DOŁĄCZENIA
PRAWE ŁĄCZENIE jest lustrzanym odbiciem LEWEGO ŁĄCZENIA. Dlatego mogłem łatwo rozwiązać poprzedni problem, używając RIGHT JOIN. Pokażę ci, jak to zrobić.
Dane
Tabele pozostają takie same; Po prostu użyję innego typu łączenia.
Code
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id GROUP BY c.city
HAVING COUNT(o.id) >=5;
Oto, co się zmieniło. Ponieważ używam RIGHT JOIN, zmieniłem kolejność tabel. Teraz stół Zlecenia staje się lewym i stołem klienci Ten dobry, ten wlasciwy. Warunki połączenia pozostają takie same. Właśnie zmieniłem kolejność kolumn, aby odzwierciedlić kolejność tabel, ale nie jest to konieczne.
Zmieniając kolejność tabel i używając PRAWEGO JOIN, ponownie wypiszę wszystkich klientów, nawet jeśli nie złożyli żadnych zamówień.
Pozostała część zapytania jest taka sama jak w poprzednim przykładzie. To samo dotyczy wyjścia.
Uwaga: w praktyce WŁAŚCIWE DOŁĄCZENIE jest stosunkowo rzadko stosowany. LEFT JOIN wydaje się bardziej naturalny użytkownikom SQL, dlatego używają go znacznie częściej. Wszystko, co można zrobić za pomocą RIGHT JOIN, można również zrobić za pomocą LEFT JOIN. Z tego powodu nie ma konkretnej sytuacji, w której preferowane byłoby PRAWE DOŁĄCZENIE.
Wydajność
4. Przykład PEŁNEGO DOŁĄCZENIA
Pytanie Salesforce i Tesli chce, abyś policzył różnicę netto pomiędzy liczbą produktów wprowadzonych przez firmy w 2020 r. a liczbą produktów wprowadzonych przez firmy w roku poprzednim.
Produkt
„Otrzymujesz tabelę wprowadzanych na rynek produktów według firm i lat. Napisz zapytanie obliczające różnicę netto pomiędzy liczbą produktów wprowadzonych przez firmy w 2020 r. a liczbą produktów wprowadzonych przez firmy w roku poprzednim. Podaj nazwy firm i różnicę netto produktów netto wydanych na rok 2020 w porównaniu z rokiem poprzednim.
Dane
Pytanie zawiera jedną tabelę z następującymi kolumnami.
uruchomienie_samochodu
| rok: | int |
| Nazwa firmy: | Varchar |
| Nazwa produktu: | Varchar |
Jak do cholery mam dołączyć do stołów, skoro jest tylko jeden stół? Hmm, to też zobaczmy!
Code
To zapytanie jest nieco bardziej skomplikowane, więc będę je ujawniał stopniowo.
SELECT company_name, product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
Pierwsza instrukcja SELECT wyszukuje firmę i nazwę produktu w 2020. To zapytanie zostanie później zamienione na podzapytanie.
Pytanie ma na celu znalezienie różnicy między rokiem 2020 a 2019. Napiszmy więc to samo zapytanie, ale dla roku 2019.
SELECT company_name, product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
Teraz zamienię te zapytania w podzapytania i dołączę do nich za pomocą FULL OUTER JOIN.
SELECT *
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name;
Podzapytania można traktować jak tabele i dlatego można je łączyć. Nadałem pierwszemu podzapytaniu alias i umieściłem go w klauzuli FROM. Następnie używam FULL OUTER JOIN, aby połączyć je z drugim podzapytaniem w kolumnie z nazwą firmy.
Używając tego typu sprzężenia SQL, wszystkie firmy i produkty w 2020 roku zostaną połączone ze wszystkimi firmami i produktami w 2019 roku.
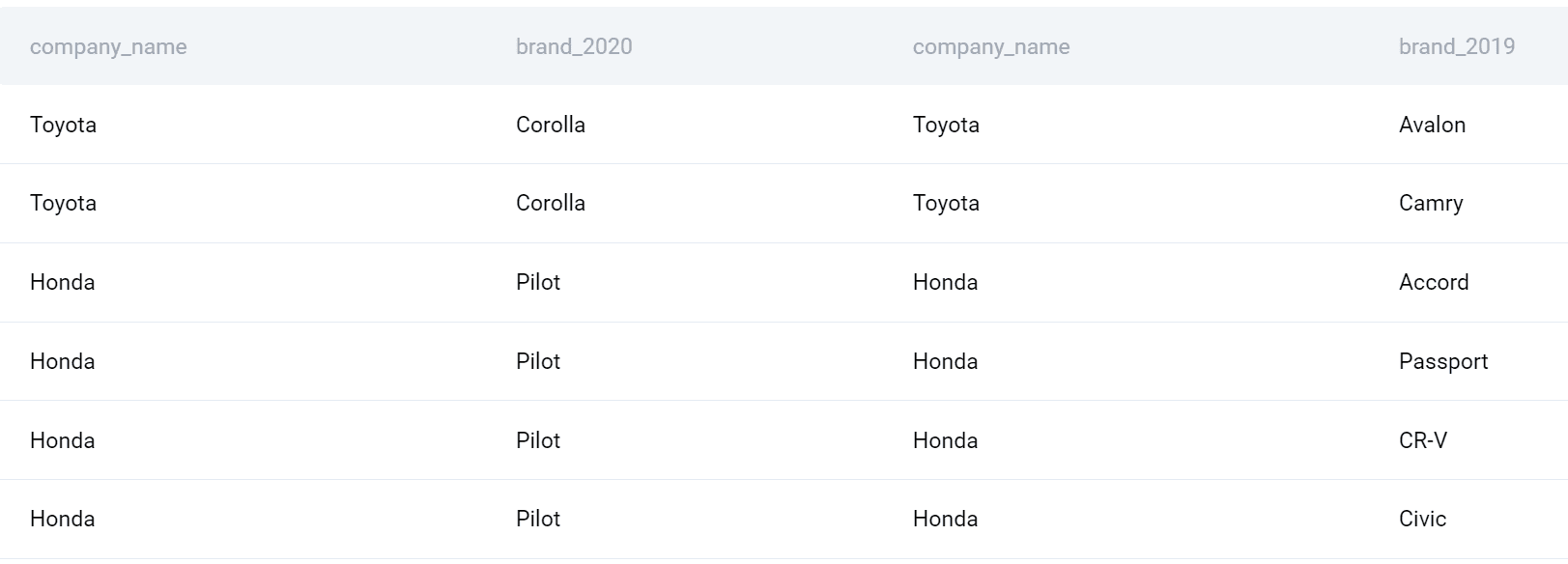
Teraz mogę sfinalizować zapytanie. Wybierzmy nazwę firmy. Użyję także funkcji COUNT(), aby znaleźć liczbę produktów wprowadzonych na rynek w każdym roku, a następnie odejmij ją, aby uzyskać różnicę. Na koniec pogrupuję dane wyjściowe według firmy i posortuję je również alfabetycznie według firmy.
Oto całe zapytanie.
SELECT a.company_name, (COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name
GROUP BY a.company_name
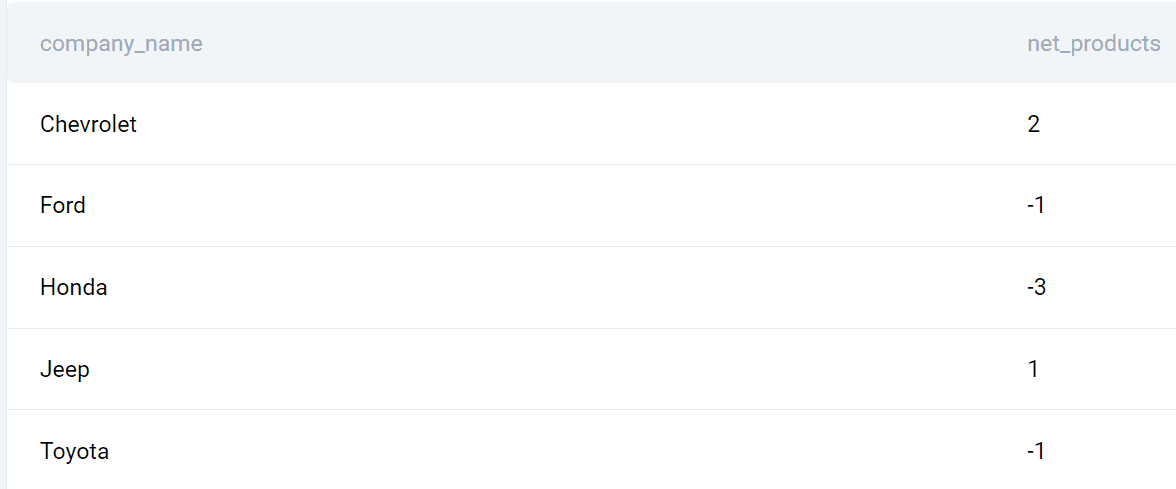
ORDER BY company_name;Wydajność
Oto lista firm i różnica wprowadzonych produktów pomiędzy 2020 a 2019 rokiem.
5. Przykład łączenia krzyżowego
To pytanie zadane przez Deloitte świetnie nadaje się do pokazania, jak działa CROSS JOIN.
Maksymalnie dwie liczby
„Mając pojedynczą kolumnę liczb, rozważ wszystkie możliwe permutacje dwóch liczb, zakładając, że pary liczb (x, y) i (y, x) są dwiema różnymi permutacjami. Następnie dla każdej permutacji znajdź maksimum z dwóch liczb.
Wyprowadź trzy kolumny: pierwszą liczbę, drugą liczbę i maksimum z tych dwóch.
Pytanie wymaga znalezienia wszystkich możliwych permutacji dwóch liczb, zakładając, że pary liczb (x,y) i (y,x) są dwiema różnymi permutacjami. Następnie musimy znaleźć maksimum liczb dla każdej permutacji.
Dane
Pytanie daje nam jedną tabelę z jedną kolumną.
deloitte_numbers
| numer: | int |
Code
Ten kod jest przykładem CROSS JOIN, ale także samodzielnego łączenia.
SELECT dn1.number AS number1, dn2.number AS number2, CASE WHEN dn1.number > dn2.number THEN dn1.number ELSE dn2.number END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
Odwołuję się do tabeli w FROM i nadaję jej jeden alias. Następnie KRZYŻAM JOIN ze sobą, odwołując się do niego po CROSS JOIN i nadając tabeli inny alias.
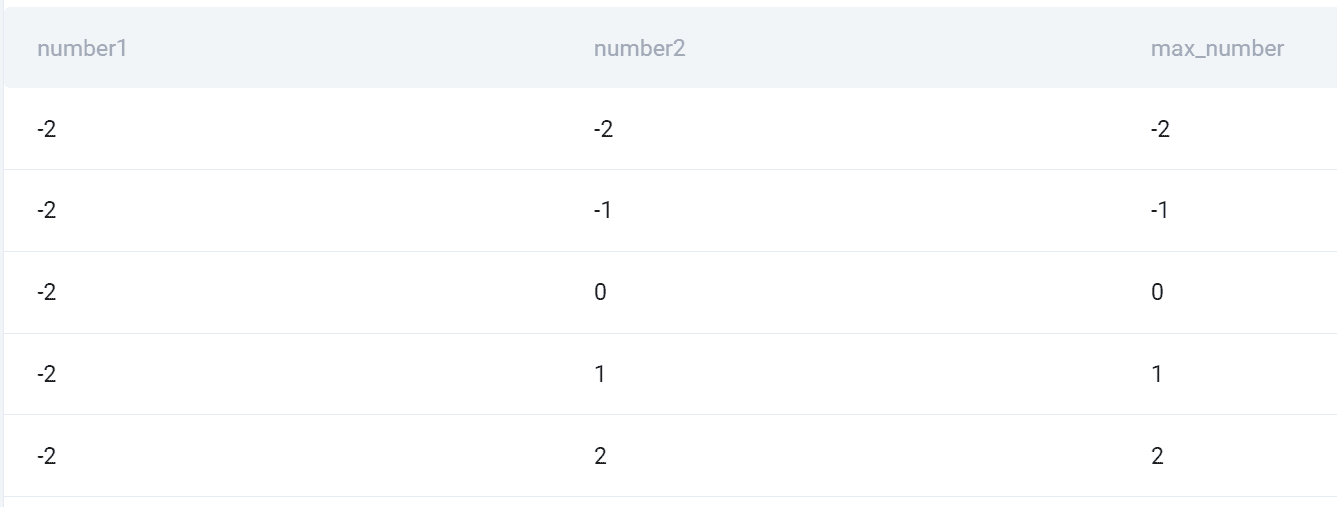
Teraz można używać jednego stołu, ponieważ są dwa. Wybieram numer kolumny z każdej tabeli. Następnie używam instrukcji CASE, aby ustawić warunek, który pokaże maksymalną liczbę dwóch liczb.
Dlaczego zastosowano tutaj CROSS JOIN? Pamiętaj, że jest to typ złączenia SQL, który pokaże wszystkie kombinacje wszystkich wierszy ze wszystkich tabel. Właśnie o to chodzi w pytaniu!
Wydajność
Oto migawka wszystkich kombinacji i wyższej liczby z nich.
Teraz, gdy wiesz, jak używać złączeń SQL, pytanie brzmi, jak wykorzystać tę wiedzę w nauce danych.
Złączenia SQL odgrywają kluczową rolę w zadaniach związanych z nauką o danych, takich jak eksploracja danych, czyszczenie danych i inżynieria funkcji.
Oto kilka przykładów wykorzystania złączeń SQL:
- Łączenie danych: Łączenie tabel umożliwia łączenie różnych źródeł danych, co pozwala analizować relacje i korelacje między wieloma zbiorami danych. Na przykład połączenie tabeli klientów z tabelą transakcji może zapewnić wgląd w zachowania klientów i wzorce zakupów.
- Walidacji danych: Złączy można używać do sprawdzania jakości i integralności danych. Porównując dane z różnych tabel, można zidentyfikować niespójności, brakujące wartości lub wartości odstające. Pomaga to w czyszczeniu danych i gwarantuje, że dane użyte do analizy są dokładne i wiarygodne.
- Inżynieria funkcji: Złączenia mogą odegrać kluczową rolę w tworzeniu nowych funkcji modeli uczenia maszynowego. Łącząc odpowiednie tabele, można wyodrębnić istotne informacje i wygenerować funkcje, które uchwycą ważne relacje w danych. Może to zwiększyć siłę predykcyjną modeli.
- Agregacja i analiza: Złączenia umożliwiają wykonywanie złożonych agregacji i analiz w wielu tabelach. Łącząc dane z różnych źródeł, można uzyskać kompleksowy wgląd w dane i wyciągnąć cenne spostrzeżenia. Na przykład połączenie tabeli sprzedaży z tabelą produktów może pomóc w analizie wyników sprzedaży według kategorii produktu lub regionu.
Jak już wspomniałem, złożoność złączeń nie jest widoczna w ich składni. Widziałeś, że składnia jest stosunkowo prosta.
Najlepsze praktyki dotyczące złączeń również to odzwierciedlają, ponieważ nie dotyczą one samego kodowania, ale tego, co robi i jak działa.
Aby jak najlepiej wykorzystać sprzężenia w SQL, rozważ następujące najlepsze praktyki.
- Zrozum swoje dane: Zapoznaj się ze strukturą i relacjami zachodzącymi w Twoich danych. Pomoże Ci to wybrać odpowiedni typ złączenia i wybrać odpowiednie kolumny do dopasowania.
- Użyj indeksów: Jeśli Twoje tabele są duże lub często łączone, rozważ dodanie indeksów do kolumn używanych do łączenia. Indeksy mogą znacznie poprawić wydajność zapytań.
- Pamiętaj o wydajności: Łączenie dużych tabel lub wielu tabel może być kosztowne obliczeniowo. Optymalizuj swoje zapytania, filtrując dane, stosując odpowiednie typy złączeń i biorąc pod uwagę użycie tabel tymczasowych lub podzapytań.
- Przetestuj i zweryfikuj: Zawsze sprawdzaj wyniki łączenia, aby zapewnić poprawność. Przeprowadź kontrolę poprawności i zweryfikuj, czy połączone dane są zgodne z Twoimi oczekiwaniami i logiką biznesową.
Złączenia SQL to podstawowa koncepcja, która umożliwia badaczowi danych łączenie i analizowanie danych z wielu źródeł. Rozumiejąc różne typy złączeń SQL, opanowując ich składnię i skutecznie je wykorzystując, badacze danych mogą uzyskać cenne spostrzeżenia, zweryfikować jakość danych i podejmować decyzje oparte na danych.
Pokazałem Ci jak to zrobić na pięciu przykładach. Teraz Twoim zadaniem jest wykorzystanie mocy SQL i złączeń w swoich projektach związanych z analizą danych i osiągnięcie lepszych wyników.
Nate'a Rosidiego jest analitykiem danych i strategii produktu. Jest także adiunktem wykładającym analitykę i jest założycielem StrataScratch, platforma pomagająca analitykom danych przygotować się do rozmów kwalifikacyjnych z prawdziwymi pytaniami do wywiadów z czołowymi firmami. Połącz się z nim dalej Twitter: StrataScratch or LinkedIn.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://www.kdnuggets.com/2023/08/sql-data-science-understanding-leveraging-joins.html?utm_source=rss&utm_medium=rss&utm_campaign=sql-for-data-science-understanding-and-leveraging-joins
- :Jest
- :nie
- :Gdzie
- $W GÓRĘ
- 1
- 11
- 12
- 13
- 2019
- 2020
- 7
- 8
- a
- O nas
- dostęp
- Dostęp do danych
- dokładny
- Osiągać
- w poprzek
- dodanie
- dodatek
- Po
- ponownie
- zbiór
- Wyrównuje
- Wszystkie kategorie
- przydzielony
- dopuszczać
- Pozwalać
- pozwala
- wzdłuż
- już
- również
- zawsze
- ilość
- kwoty
- an
- analiza
- analityka
- w czasie rzeczywistym sprawiają,
- i
- Inne
- każdy
- wszystko
- właściwy
- SĄ
- artykuł
- AS
- At
- b
- na podstawie
- podstawowy
- BE
- bo
- staje się
- być
- jest
- BEST
- Najlepsze praktyki
- Ulepsz Swój
- pomiędzy
- obie
- przynieść
- budżet
- biznes
- ale
- by
- obliczać
- obliczony
- nazywa
- CAN
- zdobyć
- walizka
- Kategoria
- zmieniony
- Zmiany
- Wykrywanie urządzeń szpiegujących
- Dodaj
- Miasta
- Miasto
- Sprzątanie
- kod
- Kodowanie
- Kolumna
- kolumny
- COM
- kombinacje
- połączyć
- kombajny
- łączenie
- byliśmy spójni, od początku
- wspólny
- Firmy
- sukcesy firma
- w porównaniu
- porównanie
- kompleks
- kompleksowość
- skomplikowane
- wszechstronny
- pojęcie
- zaniepokojony
- warunek
- Skontaktuj się
- połączenia
- Rozważać
- wobec
- konwertować
- Odpowiedni
- Koszty:
- Stwórz
- Tworzenie
- Krzyż
- istotny
- klient
- zachowanie klienta
- Klientów
- dane
- jakość danych
- nauka danych
- naukowiec danych
- sterowane danymi
- Baza danych
- Bazy danych
- zbiory danych
- Podejmowanie decyzji
- Decyzje
- definicja
- W zależności
- zaprojektowany
- detal
- ZROBIŁ
- różnica
- różne
- odrębny
- rozróżniać
- do
- robi
- Nie
- robi
- zrobić
- napęd
- e
- każdy
- Wcześniej
- łatwiej
- z łatwością
- faktycznie
- więcej
- Pracownik
- pracowników
- upoważnia
- umożliwiać
- umożliwiając
- zakończenia
- Inżynieria
- wzmacniać
- zapewnić
- zapewnia
- równy
- ustanawia
- Parzyste
- wszystko
- dokładnie
- przykład
- przykłady
- oczekiwania
- drogi
- Wyjaśniać
- eksploracja
- dodatkowy
- wyciąg
- Cecha
- Korzyści
- kilka
- pole
- Nadzienie
- filtracja
- sfinalizować
- W końcu
- Znajdź
- znajduje
- i terminów, a
- pięć
- pływak
- Skupiać
- obserwuj
- następujący
- następujący sposób
- W razie zamówieenia projektu
- obcy
- znaleziono
- założyciel
- często
- od
- z przodu
- pełny
- w pełni
- funkcjonować
- fundamentalny
- dalej
- Wzrost
- Generować
- otrzymać
- Dać
- dany
- daje
- Dający
- Goes
- będzie
- stopniowo
- wspaniały
- Zarządzanie
- poprowadzi
- uprząż
- Have
- mający
- he
- ciężko
- pomoc
- pomoc
- pomaga
- tutaj
- wyższy
- Najwyższa
- go
- W jaki sposób
- How To
- Jednak
- HTTPS
- i
- CHORY
- ID
- identyfikator
- zidentyfikować
- if
- obraz
- ważny
- podnieść
- in
- W innych
- zawierać
- indeksy
- Informacja
- poinformowany
- spostrzeżenia
- zamiast
- instrumentalny
- integralność
- zainteresowany
- Wywiad
- pytania podczas rozmowy kwalifikacyjnej
- Wywiady
- najnowszych
- IT
- JEGO
- samo
- przystąpić
- Dołączył
- łączący
- Łączy
- jpg
- właśnie
- Knuggety
- Klawisz
- słowa kluczowe
- Wiedzieć
- wiedza
- język
- duży
- później
- uruchomiona
- uruchamia
- nauka
- najmniej
- lewo
- lewarowanie
- lubić
- LINK
- Lista
- mało
- logika
- długo
- Popatrz
- WYGLĄD
- maszyna
- uczenie maszynowe
- zrobiony
- Główny
- robić
- Dokonywanie
- zarządzający
- manipulowanie
- Mastering
- Mecz
- dopasowane
- dopasowywanie
- maksymalny
- me
- wymowny
- znaczy
- wzmiankowany
- Łączyć
- połączenie
- może
- lustro
- Odbicie Lustrzane
- nieodebranych
- brakujący
- modele
- jeszcze
- większość
- dużo
- wielokrotność
- my
- Nazwa
- Nazwy
- Naturalny
- Natura
- niezbędny
- Potrzebować
- potrzebne
- netto
- Nowości
- Nowe funkcje
- Nie
- już dziś
- numer
- z naszej
- of
- często
- on
- ONE
- tylko
- naprzeciwko
- Optymalizacja
- or
- zamówienie
- Zlecenia
- Inne
- ludzkiej,
- na zewnątrz
- wydajność
- par
- wzory
- dla
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywane
- wykonuje
- Miejsce
- Miejsca
- Platforma
- plato
- Analiza danych Platona
- PlatoDane
- Grać
- Proszę
- możliwy
- power
- mocny
- praktyka
- praktyki
- Korzystny
- Przygotować
- poprzedni
- pierwotny
- Problem
- Produkt
- Produkty
- Profesor
- Programowanie
- projekt
- projektowanie
- zapewniać
- zapewnia
- nabywczy
- jakość
- zapytania
- pytanie
- pytania
- rzadko
- real
- rekord
- referencje
- odwoływanie się
- odzwierciedlić
- odzwierciedlenie
- region
- związane z
- Relacje
- stosunkowo
- wydany
- rzetelny
- pamiętać
- zażądać
- REST
- dalsze
- Efekt
- powrót
- powraca
- ujawniać
- prawo
- Rola
- okrągły
- s
- sole
- sprzedawca
- taki sam
- zobaczył
- nauka
- Naukowiec
- Naukowcy
- druga
- widzieć
- wydaje
- SAMEGO SIEBIE
- oddzielny
- zestaw
- kilka
- shared
- stenografia
- powinien
- pokazać
- prezentacja
- pokazał
- seans
- Targi
- znacznie
- podobny
- po prostu
- pojedynczy
- sytuacja
- Migawka
- So
- rozwiązanie
- ROZWIĄZANIA
- Źródła
- specyficzny
- SQL
- Zestawienie sprzedaży
- pobyt
- bezpośredni
- Strategia
- Struktura
- zbudowany
- taki
- przełączane
- składnia
- T1
- stół
- Rozmowy
- zadania
- Nauczanie
- tymczasowy
- test
- że
- Połączenia
- ich
- Im
- następnie
- Tam.
- w związku z tym
- Te
- one
- to
- trzy
- czas
- Tytuł
- do
- razem
- Toolbox
- narzędzia
- Top
- Kwota produktów:
- transakcja
- leczony
- leczenia
- Obrócony
- drugiej
- rodzaj
- typy
- zrozumieć
- zrozumienie
- wyjątkowy
- odblokować
- us
- posługiwać się
- używany
- Użytkownicy
- zastosowania
- za pomocą
- zazwyczaj
- wykorzystać
- UPRAWOMOCNIĆ
- uprawomocnienie
- Cenny
- Wartości
- różnorodny
- Naprawiono
- zweryfikować
- Zobacz i wysłuchaj
- wyobrażanie sobie
- vs
- chcieć
- poszukiwany
- brakujący
- chce
- Droga..
- we
- Co
- jeśli chodzi o komunikację i motywację
- który
- Podczas
- cały
- dlaczego
- będzie
- w
- w ciągu
- słowa
- działa
- napisać
- napisany
- Źle
- X
- rok
- ty
- Twój
- siebie
- zefirnet
- zero








