W tym poście pokazujemy, jak używać przycinania strukturalnego w oparciu o wyszukiwanie architektury neuronowej (NAS) w celu skompresowania precyzyjnie dostrojonego modelu BERT w celu poprawy wydajności modelu i skrócenia czasu wnioskowania. Wstępnie wytrenowane modele językowe (PLM) przechodzą szybkie wdrażanie w handlu i przedsiębiorstwach w obszarach narzędzi zwiększających produktywność, obsługi klienta, wyszukiwania i rekomendacji, automatyzacji procesów biznesowych i tworzenia treści. Wdrażanie punktów końcowych wnioskowania PLM wiąże się zazwyczaj z większymi opóźnieniami i wyższymi kosztami infrastruktury ze względu na wymagania obliczeniowe i zmniejszoną wydajnością obliczeniową ze względu na dużą liczbę parametrów. Przycinanie PLM zmniejsza rozmiar i złożoność modelu, zachowując jednocześnie jego możliwości predykcyjne. Oczyszczone PLM zapewniają mniejsze zużycie pamięci i mniejsze opóźnienia. Wykazujemy to, przycinając PLM i pomijając liczbę parametrów oraz błąd sprawdzania poprawności dla konkretnego zadania docelowego, i jesteśmy w stanie osiągnąć krótszy czas reakcji w porównaniu z podstawowym modelem PLM.
Optymalizacja wielocelowa to obszar podejmowania decyzji, który optymalizuje jednocześnie więcej niż jedną funkcję celu, taką jak zużycie pamięci, czas szkolenia i zasoby obliczeniowe. Przycinanie strukturalne to technika mająca na celu zmniejszenie rozmiaru i wymagań obliczeniowych PLM poprzez przycinanie warstw lub neuronów/węzłów przy jednoczesnej próbie zachowania dokładności modelu. Usuwając warstwy, przycinanie strukturalne umożliwia osiągnięcie wyższych współczynników kompresji, co prowadzi do przyjaznej dla sprzętu uporządkowanej rzadkości, która skraca czas działania i czas reakcji. Zastosowanie techniki czyszczenia strukturalnego w modelu PLM skutkuje lżejszym modelem o mniejszym zużyciu pamięci, który hostowany jako punkt końcowy wnioskowania w SageMaker oferuje lepszą efektywność wykorzystania zasobów i obniżone koszty w porównaniu z oryginalnym, precyzyjnie dostrojonym PLM.
Koncepcje zilustrowane w tym poście można zastosować w aplikacjach korzystających z funkcji PLM, takich jak systemy rekomendacji, analiza nastrojów i wyszukiwarki. W szczególności możesz zastosować to podejście, jeśli masz dedykowane zespoły zajmujące się uczeniem maszynowym (ML) i analizą danych, które dostrajają własne modele PLM przy użyciu zestawów danych specyficznych dla domeny i wdrażają dużą liczbę punktów końcowych wnioskowania przy użyciu Amazon Sage Maker. Jednym z przykładów jest sprzedawca internetowy, który wdraża dużą liczbę punktów końcowych wnioskowania na potrzeby podsumowań tekstowych, klasyfikacji katalogu produktów i klasyfikacji opinii o produktach. Innym przykładem może być podmiot świadczący opiekę zdrowotną, który wykorzystuje punkty końcowe wnioskowania PLM do klasyfikacji dokumentów klinicznych, rozpoznawania nazwanych podmiotów na podstawie raportów medycznych, chatbotów medycznych i stratyfikacji ryzyka pacjenta.
Omówienie rozwiązania
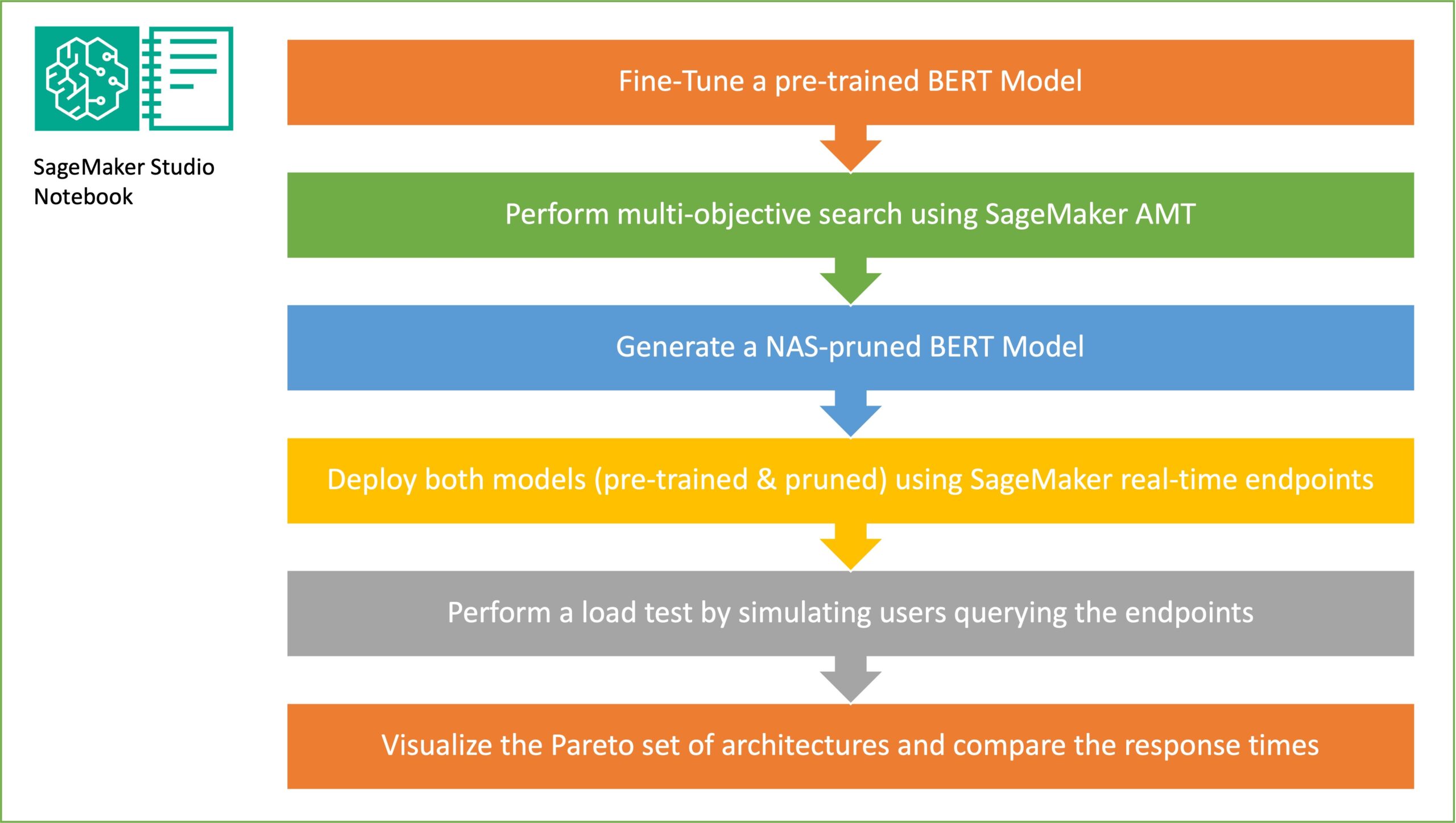
W tej sekcji przedstawiamy ogólny przepływ pracy i wyjaśniamy podejście. Najpierw używamy Studio Amazon SageMaker notatnik dostrojenie wstępnie wyszkolonego modelu BERT do docelowego zadania przy użyciu zbioru danych specyficznego dla domeny. BERTI (Dwukierunkowe reprezentacje koderów z Transformers) to wstępnie wytrenowany model językowy oparty na architektura transformatora używany do zadań związanych z przetwarzaniem języka naturalnego (NLP). Przeszukiwanie architektury neuronowej (NAS) to podejście do automatyzacji projektowania sztucznych sieci neuronowych i jest ściśle powiązane z optymalizacją hiperparametrów, szeroko stosowanym podejściem w dziedzinie uczenia maszynowego. Celem NAS jest znalezienie optymalnej architektury dla danego problemu poprzez przeszukanie dużego zestawu potencjalnych architektur przy użyciu technik takich jak optymalizacja bez gradientów lub optymalizacja pożądanych wskaźników. Wydajność architektury jest zwykle mierzona za pomocą wskaźników, takich jak utrata walidacji. Automatyczne strojenie modeli SageMaker (AMT) automatyzuje żmudny i złożony proces znajdowania optymalnych kombinacji hiperparametrów modelu ML, które zapewniają najlepszą wydajność modelu. AMT wykorzystuje inteligentne algorytmy wyszukiwania i oceny iteracyjne przy użyciu zakresu określonych hiperparametrów. Wybiera wartości hiperparametrów, aby utworzyć model, który działa najlepiej, mierząc metryki wydajności, takie jak dokładność i wynik F-1.
Podejście dostrajające opisane w tym poście ma charakter ogólny i można je zastosować do dowolnego zbioru danych tekstowych. Zadanie przydzielone BERT PLM może być zadaniem tekstowym, takim jak analiza nastrojów, klasyfikacja tekstu lub pytania i odpowiedzi. W tym pokazie docelowym zadaniem jest problem klasyfikacji binarnej, w którym BERT służy do określenia, na podstawie zbioru danych składającego się ze zbioru par fragmentów tekstu, czy znaczenie jednego fragmentu tekstu można wywnioskować z drugiego fragmentu. Używamy Rozpoznawanie zbioru danych związanych z tekstem z pakietu porównawczego GLUE. Przeprowadzamy wyszukiwanie wielocelowe za pomocą SageMaker AMT w celu zidentyfikowania podsieci, które oferują optymalne kompromisy między liczbą parametrów a dokładnością przewidywania dla docelowego zadania. Przeprowadzając wyszukiwanie wielocelowe, zaczynamy od zdefiniowania dokładności i liczby parametrów jako celów, które chcemy zoptymalizować.
W sieci BERT PLM mogą istnieć modułowe, samodzielne podsieci, które umożliwiają modelowi posiadanie wyspecjalizowanych funkcji, takich jak rozumienie języka i reprezentacja wiedzy. BERT PLM wykorzystuje wielogłowicową podsieć samouważności i podsieć ze sprzężeniem zwrotnym. Wielogłowa warstwa samouważności umożliwia BERT powiązanie różnych pozycji pojedynczej sekwencji w celu obliczenia reprezentacji sekwencji, umożliwiając wielu głowicom obsługę wielu sygnałów kontekstu. Dane wejściowe są dzielone na wiele podprzestrzeni, a samouważność jest stosowana oddzielnie do każdej z podprzestrzeni. Wiele głowic w transformatorze PLM umożliwia modelowi wspólne przetwarzanie informacji z różnych podprzestrzeni reprezentacji. Podsieć ze sprzężeniem zwrotnym to prosta sieć neuronowa, która pobiera dane wyjściowe z wielogłowicowej podsieci samouważności, przetwarza dane i zwraca ostateczną reprezentację kodera.
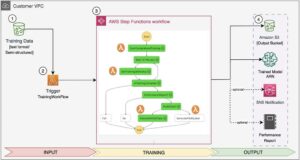
Celem losowego próbkowania podsieci jest uczenie mniejszych modeli BERT, które mogą wystarczająco dobrze wykonywać docelowe zadania. Próbujemy 100 losowych podsieci ze dopracowanego podstawowego modelu BERT i oceniamy 10 sieci jednocześnie. Wyszkolone podsieci są oceniane pod kątem obiektywnych metryk, a ostateczny model jest wybierany na podstawie kompromisów znalezionych pomiędzy obiektywnymi metrykami. Wizualizujemy Przód Pareta dla próbkowanych podsieci, które zawierają oczyszczony model oferujący optymalny kompromis pomiędzy dokładnością modelu a rozmiarem modelu. Wybieramy kandydującą podsieć (model BERT oczyszczony przez NAS) w oparciu o rozmiar modelu i dokładność modelu, na które jesteśmy gotowi zaradzić. Następnie hostujemy punkty końcowe, wstępnie wytrenowany model podstawowy BERT i model BERT oczyszczony z NAS przy użyciu SageMaker. Do przeprowadzenia testów obciążeniowych używamy Szarańcza, narzędzie do testowania obciążenia typu open source, które można wdrożyć za pomocą języka Python. Przeprowadzamy testy obciążenia na obu punktach końcowych za pomocą Locust i wizualizujemy wyniki za pomocą frontu Pareto, aby zilustrować kompromis między czasem reakcji a dokładnością w przypadku obu modeli. Poniższy diagram przedstawia przegląd przepływu pracy wyjaśnionego w tym poście.
Wymagania wstępne
Na to stanowisko wymagane są następujące wymagania wstępne:
Należy także zwiększyć limit usług aby uzyskać dostęp do co najmniej trzech instancji ml.g4dn.xlarge w SageMaker. Typ instancji ml.g4dn.xlarge to ekonomiczna instancja GPU, która umożliwia natywne uruchamianie PyTorch. Aby zwiększyć limit usług, wykonaj następujące kroki:
- W konsoli przejdź do Przydziałów usług.
- W razie zamówieenia projektu Zarządzaj limitamiwybierz Amazon Sage Maker, A następnie wybierz Zobacz limity.

- Wyszukaj „ml-g4dn.xlarge do wykorzystania zadań szkoleniowych” i wybierz element przydziału.
- Dodaj Poproś o zwiększenie na poziomie konta.
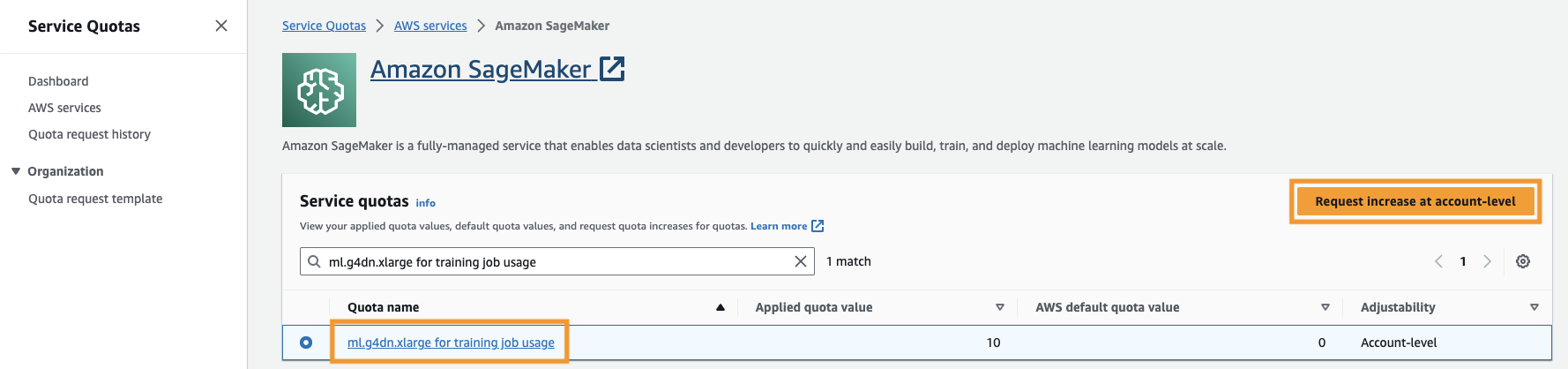
- W razie zamówieenia projektu Zwiększ wartość limituwprowadź wartość 5 lub wyższą.
- Dodaj PROŚBA.
Zatwierdzenie żądanego limitu może zająć trochę czasu, w zależności od uprawnień konta.

- Otwórz SageMaker Studio z konsoli SageMaker.

- Dodaj Terminal systemowy dla Narzędzia i pliki.

- Uruchom następujące polecenie, aby sklonować plik GitHub repo do instancji SageMaker Studio:
- Nawigować do
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Otwórz plik
nas_for_llm_with_amt.ipynb. - Skonfiguruj środowisko za pomocą pliku
ml.g4dn.xlargeinstancja i wybierz Wybierz.

Skonfiguruj wstępnie wytrenowany model BERT
W tej sekcji importujemy zestaw danych Recognizing Textual Entailment z biblioteki zestawów danych i dzielimy go na zestawy szkoleniowe i walidacyjne. Ten zbiór danych składa się z par zdań. Zadaniem BERT PLM jest rozpoznanie, na podstawie dwóch fragmentów tekstu, czy znaczenie jednego fragmentu tekstu można wywnioskować z drugiego fragmentu. W poniższym przykładzie możemy wywnioskować znaczenie pierwszego wyrażenia z drugiego wyrażenia:
Ładujemy zestaw danych dotyczących rozpoznawania tekstu z pliku KLEJ pakiet testów porównawczych za pośrednictwem biblioteka zbiorów danych z Hugging Face w naszym skrypcie szkoleniowym (./training.py). Podzieliliśmy oryginalny zbiór danych szkoleniowych z GLUE na zbiór uczący i walidacyjny. W naszym podejściu dostrajamy podstawowy model BERT za pomocą zbioru danych szkoleniowych, a następnie przeprowadzamy wielocelowe wyszukiwanie w celu zidentyfikowania zestawu podsieci, które optymalnie równoważą obiektywne metryki. Używamy zbioru danych szkoleniowych wyłącznie do dostrojenia modelu BERT. Jednakże używamy danych walidacyjnych do wyszukiwania wielocelowego, mierząc dokładność w zbiorze danych walidacyjnych wstrzymanych.
Dostosuj BERT PLM, korzystając ze zbioru danych specyficznego dla domeny
Typowe przypadki użycia surowego modelu BERT obejmują przewidywanie następnego zdania lub modelowanie języka maskowanego. Aby wykorzystać podstawowy model BERT do dalszych zadań, takich jak rozpoznawanie tekstu, musimy jeszcze bardziej dostroić model, korzystając ze zbioru danych specyficznego dla domeny. Dopracowanego modelu BERT można używać do zadań takich jak klasyfikacja sekwencji, odpowiadanie na pytania i klasyfikacja tokenów. Jednakże na potrzeby tego pokazu używamy dopracowanego modelu klasyfikacji binarnej. Dostrajamy wstępnie wytrenowany model BERT za pomocą zbioru danych szkoleniowych, który przygotowaliśmy wcześniej, korzystając z następujących hiperparametrów:
Zapisujemy punkt kontrolny uczenia modelu do pliku Usługa Amazon Simple Storage (Amazon S3), dzięki czemu model można załadować podczas wyszukiwania wieloobiektowego w oparciu o NAS. Zanim wytrenujemy model, definiujemy metryki, takie jak epoka, strata uczenia, liczba parametrów i błąd walidacji:
Po rozpoczęciu procesu dostrajania ukończenie zadania szkoleniowego zajmuje około 15 minut.
Przeprowadź wyszukiwanie wielocelowe, aby wybrać podsieci i zwizualizować wyniki
W następnym kroku przeprowadzamy wieloobiektowe wyszukiwanie w dopracowanym podstawowym modelu BERT, próbkując losowe podsieci za pomocą SageMaker AMT. Aby uzyskać dostęp do podsieci w ramach supersieci (dopracowany model BERT), maskujemy wszystkie komponenty PLM, które nie są częścią podsieci. Maskowanie supersieci w celu znalezienia podsieci w PLM to technika stosowana do izolowania i identyfikowania wzorców zachowania modelu. Należy pamiętać, że transformatory Hugging Face wymagają ukrytego rozmiaru będącego wielokrotnością liczby głów. Rozmiar ukryty w transformatorze PLM steruje rozmiarem przestrzeni wektorów stanu ukrytego, co wpływa na zdolność modelu do uczenia się złożonych reprezentacji i wzorców w danych. W BERT PLM wektor stanu ukrytego ma stały rozmiar (768). Nie możemy zmienić ukrytego rozmiaru, dlatego liczba głów musi wynosić [1, 3, 6, 12].
W przeciwieństwie do optymalizacji jednocelowej, w ustawieniu wielocelowym zazwyczaj nie mamy jednego rozwiązania, które jednocześnie optymalizuje wszystkie cele. Zamiast tego staramy się zebrać zbiór rozwiązań, które dominują nad wszystkimi innymi rozwiązaniami w co najmniej jednym celu (takim jak błąd walidacji). Teraz możemy rozpocząć wieloobiektowe przeszukiwanie za pomocą AMT, ustawiając metryki, które chcemy zredukować (błąd walidacji i liczba parametrów). Losowe podsieci są definiowane przez parametr max_jobs a liczba jednoczesnych zadań jest określona przez parametr max_parallel_jobs. Kod ładujący punkt kontrolny modelu i oceniający podsieć jest dostępny w pliku evaluate_subnetwork.py skrypt.
Wykonanie zadania strojenia AMT zajmuje około 2 godzin i 20 minut. Po pomyślnym uruchomieniu zadania dostrajania AMT analizujemy historię zadania i zbieramy konfiguracje podsieci, takie jak liczba głowic, liczba warstw, liczba jednostek i odpowiednie metryki, takie jak błąd sprawdzania poprawności i liczba parametrów. Poniższy zrzut ekranu pokazuje podsumowanie udanego zadania tunera AMT.
Następnie wizualizujemy wyniki za pomocą zbioru Pareto (znanego również jako granica Pareto lub zbiór optymalny Pareto), który pomaga nam zidentyfikować optymalne zbiory podsieci, które dominują nad wszystkimi innymi podsieciami w obiektywnej metryce (błąd walidacji):
Najpierw zbieramy dane z zadania strojenia AMT. Następnie wykreślamy zbiór Pareto za pomocą matplotlob.pyplot z liczbą parametrów na osi x i błędem walidacji na osi y. Oznacza to, że kiedy przechodzimy z jednej podsieci zestawu Pareto do innej, musimy albo poświęcić wydajność, albo rozmiar modelu, ale ulepszyć drugą. Ostatecznie zestaw Pareto zapewnia nam elastyczność wyboru podsieci, która najlepiej odpowiada naszym preferencjom. Możemy zdecydować, jak bardzo chcemy zmniejszyć rozmiar naszej sieci i ile wydajności jesteśmy skłonni poświęcić.

Wdróż precyzyjnie dostrojony model BERT i model podsieci zoptymalizowany pod kątem NAS za pomocą SageMaker
Następnie wdrażamy największy model w naszym zbiorze Pareto, który prowadzi do najmniejszego pogorszenia wydajności do a Punkt końcowy SageMaker. Najlepszy model to taki, który zapewnia optymalny kompromis między błędem walidacji a liczbą parametrów dla naszego przypadku użycia.
Porównanie modeli
Wzięliśmy wstępnie wytrenowany podstawowy model BERT, dostroiliśmy go przy użyciu zestawu danych specyficznego dla domeny, przeprowadziliśmy wyszukiwanie NAS w celu zidentyfikowania dominujących podsieci w oparciu o obiektywne metryki i wdrożyliśmy oczyszczony model w punkcie końcowym SageMaker. Ponadto wykorzystaliśmy wstępnie wytrenowany podstawowy model BERT i wdrożyliśmy model podstawowy w drugim punkcie końcowym SageMaker. Następnie pobiegliśmy testowanie obciążenia używając Locust na obu punktach końcowych wnioskowania i oceniając wydajność pod względem czasu odpowiedzi.
Najpierw importujemy niezbędne biblioteki Locust i Boto3. Następnie konstruujemy metadane żądania i rejestrujemy czas rozpoczęcia, który ma zostać wykorzystany do testowania obciążenia. Następnie ładunek jest przekazywany do interfejsu API wywoływania punktu końcowego SageMaker za pośrednictwem BotoClient w celu symulowania żądań rzeczywistych użytkowników. Używamy Locust do tworzenia wielu wirtualnych użytkowników w celu równoległego wysyłania żądań i pomiaru wydajności punktu końcowego pod obciążeniem. Testy przeprowadzane są poprzez zwiększenie liczby użytkowników odpowiednio dla każdego z dwóch punktów końcowych. Po zakończeniu testów Locust generuje plik CSV ze statystykami żądań dla każdego z wdrożonych modeli.
Następnie generujemy wykresy czasu odpowiedzi z plików CSV pobranych po uruchomieniu testów z Locustem. Celem wykreślenia czasu odpowiedzi w funkcji liczby użytkowników jest analiza wyników testów obciążenia poprzez wizualizację wpływu czasu odpowiedzi punktów końcowych modelu. Na poniższym wykresie widać, że punkt końcowy modelu oczyszczonego przez NAS osiąga krótszy czas odpowiedzi w porównaniu z punktem końcowym podstawowego modelu BERT.
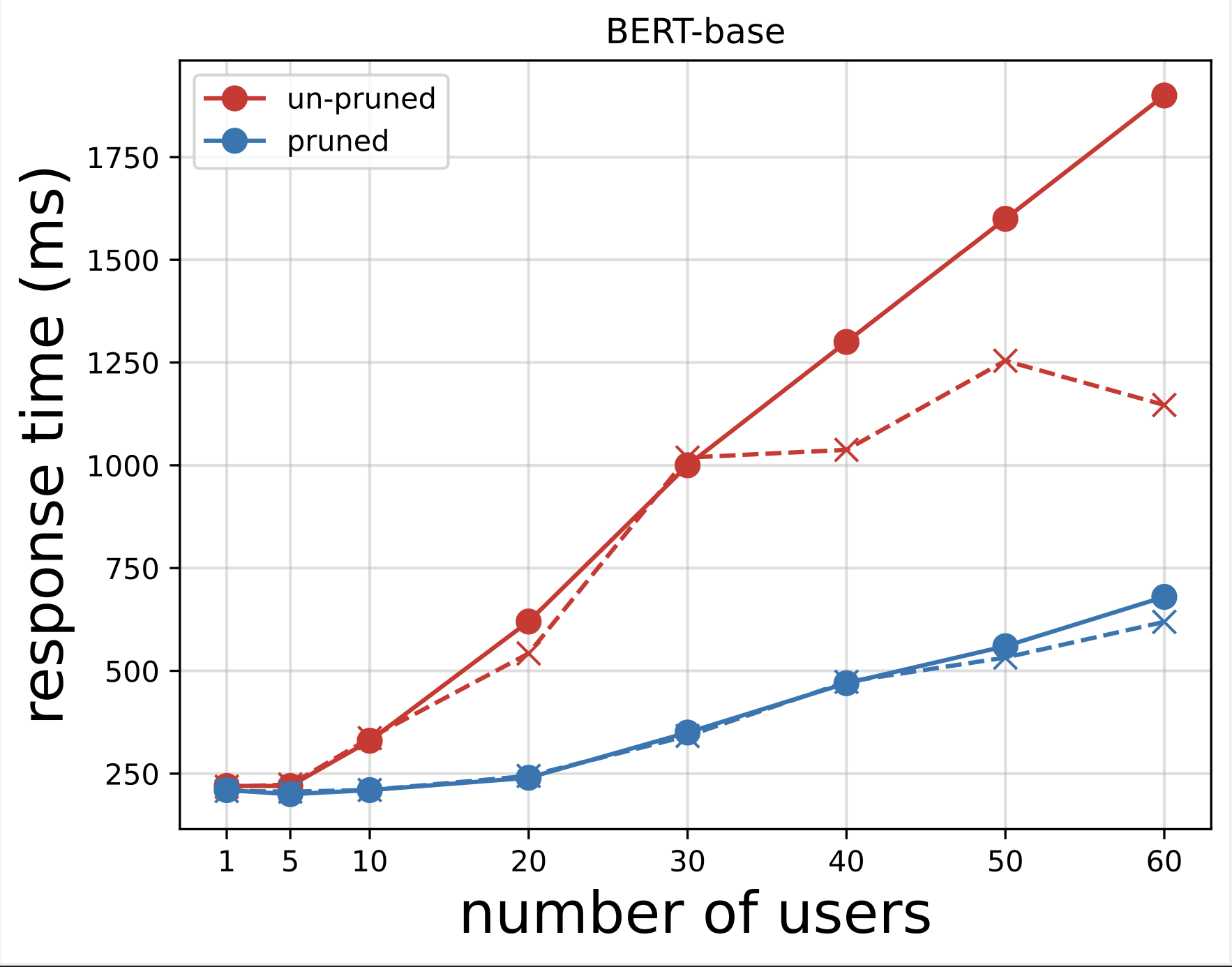
Na drugim wykresie, będącym rozwinięciem pierwszego wykresu, obserwujemy, że po około 70 użytkownikach SageMaker zaczyna ograniczać punkt końcowy podstawowego modelu BERT i zgłasza wyjątek. Jednak w przypadku punktu końcowego modelu oczyszczonego z serwera NAS ograniczanie następuje między 90–100 użytkownikami i przy krótszym czasie reakcji.

Z dwóch wykresów obserwujemy, że model przycięty ma szybszy czas reakcji i lepiej się skaluje w porównaniu z modelem nieprzyciętym. W miarę skalowania liczby punktów końcowych wnioskowania, jak ma to miejsce w przypadku użytkowników, którzy wdrażają dużą liczbę punktów końcowych wnioskowania w swoich aplikacjach PLM, korzyści kosztowe i poprawa wydajności zaczynają być dość znaczne.
Sprzątać
Aby usunąć punkty końcowe SageMaker dla dostrojonego podstawowego modelu BERT i modelu oczyszczonego przez NAS, wykonaj następujące kroki:
- W konsoli SageMaker wybierz Wnioskowanie i Punkty końcowe w okienku nawigacji.
- Wybierz punkt końcowy i usuń go.
Alternatywnie, w notatniku SageMaker Studio uruchom następujące polecenia, podając nazwy punktów końcowych:
Wnioski
W tym poście omówiliśmy, jak używać NAS do przycinania dopracowanego modelu BERT. Najpierw przeszkoliliśmy podstawowy model BERT przy użyciu danych specyficznych dla domeny i wdrożyliśmy go w punkcie końcowym SageMaker. Przeprowadziliśmy wieloobiektowe wyszukiwanie w precyzyjnie dostrojonym podstawowym modelu BERT przy użyciu narzędzia SageMaker AMT do zadania docelowego. Zwizualizowaliśmy przód Pareto i wybraliśmy optymalny dla Pareto model BERT oczyszczony z NAS, a następnie wdrożyliśmy model w drugim punkcie końcowym SageMaker. Przeprowadziliśmy testy obciążenia przy użyciu Locust, aby symulować użytkowników wysyłających zapytania do obu punktów końcowych, a także zmierzyliśmy i zarejestrowaliśmy czasy odpowiedzi w pliku CSV. Dla obu modeli wykreśliliśmy czas odpowiedzi w funkcji liczby użytkowników.
Zaobserwowaliśmy, że oczyszczony model BERT działał znacznie lepiej zarówno pod względem czasu odpowiedzi, jak i progu ograniczania instancji. Doszliśmy do wniosku, że model oczyszczony z NAS był bardziej odporny na zwiększone obciążenie punktu końcowego, utrzymując krótszy czas reakcji, nawet gdy więcej użytkowników obciążało system w porównaniu z podstawowym modelem BERT. Możesz zastosować technikę NAS opisaną w tym poście do dowolnego dużego modelu językowego, aby znaleźć uproszczony model, który może wykonać docelowe zadanie ze znacznie krótszym czasem odpowiedzi. Można dodatkowo zoptymalizować podejście, używając opóźnienia jako parametru oprócz utraty walidacji.
Chociaż w tym poście używamy serwera NAS, kwantyzacja jest kolejnym powszechnym podejściem stosowanym do optymalizacji i kompresji modeli PLM. Kwantyzacja zmniejsza precyzję wag i aktywacji w wytrenowanej sieci z 32-bitowej liczby zmiennoprzecinkowej do mniejszych szerokości bitowych, takich jak 8-bitowe lub 16-bitowe liczby całkowite, co skutkuje skompresowanym modelem, który generuje szybsze wnioskowanie. Kwantyzacja nie zmniejsza liczby parametrów; zamiast tego zmniejsza precyzję istniejących parametrów, aby uzyskać skompresowany model. Oczyszczanie NAS usuwa nadmiarowe sieci z PLM, co tworzy rzadki model z mniejszą liczbą parametrów. Zwykle oczyszczanie i kwantyzacja NAS są używane razem w celu kompresji dużych PLM w celu utrzymania dokładności modelu, zmniejszenia strat podczas sprawdzania poprawności przy jednoczesnej poprawie wydajności i zmniejszeniu rozmiaru modelu. Inne powszechnie stosowane techniki zmniejszania rozmiaru PLM obejmują destylacja wiedzy, faktoryzacja macierzy, kaskady destylacyjne.
Podejście zaproponowane w poście na blogu jest odpowiednie dla zespołów korzystających z SageMaker do trenowania i dostrajania modeli przy użyciu danych specyficznych dla domeny oraz wdrażania punktów końcowych w celu generowania wnioskowań. Jeśli szukasz w pełni zarządzanej usługi oferującej wybór wydajnych modeli podstawowych potrzebnych do tworzenia generatywnych aplikacji AI, rozważ skorzystanie z Amazońska skała macierzysta. Jeśli szukasz wstępnie wytrenowanych modeli typu open source do szerokiego zakresu zastosowań biznesowych i chcesz uzyskać dostęp do szablonów rozwiązań i przykładowych notatników, rozważ użycie Amazon SageMaker JumpStart. Wstępnie wytrenowana wersja podstawowego modelu obudowy Hugging Face BERT, którego użyliśmy w tym poście, jest również dostępna w SageMaker JumpStart.
O autorach
 Aparajithan Vaidyanathan jest głównym architektem rozwiązań dla przedsiębiorstw w AWS. Jest architektem chmury z ponad 24-letnim doświadczeniem w projektowaniu i tworzeniu systemów oprogramowania dla przedsiębiorstw, wielkoskalowych i rozproszonych. Specjalizuje się w generatywnej sztucznej inteligencji i inżynierii danych w uczeniu maszynowym. Jest początkującym maratończykiem, a jego hobby to piesze wędrówki, jazda na rowerze i spędzanie czasu z żoną i dwoma chłopcami.
Aparajithan Vaidyanathan jest głównym architektem rozwiązań dla przedsiębiorstw w AWS. Jest architektem chmury z ponad 24-letnim doświadczeniem w projektowaniu i tworzeniu systemów oprogramowania dla przedsiębiorstw, wielkoskalowych i rozproszonych. Specjalizuje się w generatywnej sztucznej inteligencji i inżynierii danych w uczeniu maszynowym. Jest początkującym maratończykiem, a jego hobby to piesze wędrówki, jazda na rowerze i spędzanie czasu z żoną i dwoma chłopcami.
 Aaron Klein jest starszym naukowcem stosowanym w AWS, pracującym nad zautomatyzowanymi metodami uczenia maszynowego dla głębokich sieci neuronowych.
Aaron Klein jest starszym naukowcem stosowanym w AWS, pracującym nad zautomatyzowanymi metodami uczenia maszynowego dla głębokich sieci neuronowych.
 Jacka Gołębiowskiego jest starszym naukowcem w AWS.
Jacka Gołębiowskiego jest starszym naukowcem w AWS.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :ma
- :Jest
- :nie
- :Gdzie
- ][P
- $W GÓRĘ
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- zdolność
- Zdolny
- dostęp
- Konto
- precyzja
- Osiągać
- Osiąga
- aktywacje
- dodatek
- Przyjęcie
- Po
- AI
- zmierzać
- Cel
- Algorytmy
- Wszystkie kategorie
- dopuszczać
- Pozwalać
- pozwala
- również
- Amazonka
- Amazon Web Services
- ilość
- an
- analiza
- analityka
- w czasie rzeczywistym sprawiają,
- i
- Inne
- sekretarka
- każdy
- api
- aplikacje
- stosowany
- Aplikuj
- Stosowanie
- podejście
- zatwierdzenie
- w przybliżeniu
- architektura
- SĄ
- POWIERZCHNIA
- obszary
- argumenty
- na około
- sztuczny
- sztuczne sieci neuronowe
- AS
- ambitny
- przydzielony
- powiązany
- At
- próbując
- uczęszczać
- zautomatyzowane
- zautomatyzowane uczenie maszynowe
- automaty
- automatycznie
- automatyzacja
- Automatyzacja
- dostępny
- AWS
- Oś
- Bilans
- baza
- na podstawie
- BE
- stają się
- zanim
- zachowanie
- Benchmarkingu
- Korzyści
- BEST
- Ulepsz Swój
- pomiędzy
- Bit
- ciało
- obie
- budować
- biznes
- Proces biznesowy
- Automatyzacja procesów biznesowych
- ale
- by
- CAN
- kandydat
- możliwości
- walizka
- Etui
- katalog
- zmiana
- Wykres
- Wykresy
- nasze chatboty
- wybór
- Dodaj
- wybrany
- klasa
- klasyfikacja
- Kliniczne
- dokładnie
- Chmura
- kod
- zbierać
- kolekcja
- kombinacje
- handlowy
- wspólny
- powszechnie
- w porównaniu
- kompletny
- Zakończony
- kompleks
- kompleksowość
- składniki
- obliczeniowy
- obliczać
- Koncepcje
- zawarta
- Rozważać
- składa się
- Konsola
- Ograniczenia
- skonstruować
- konsumpcja
- zawiera
- zawartość
- Tworzenie treści
- kontekst
- kontynuować
- kontrast
- kontroli
- Odpowiedni
- Koszty:
- Koszty:
- liczyć
- Stwórz
- tworzy
- tworzenie
- klient
- Obsługa klienta
- dane
- nauka danych
- zbiory danych
- data i godzina
- zdecydować
- Podejmowanie decyzji
- dedykowane
- głęboko
- głębokie sieci neuronowe
- określić
- zdefiniowane
- definiowanie
- Demo
- wykazać
- W zależności
- rozwijać
- wdrażane
- wdrażanie
- wdraża się
- opisane
- Wnętrze
- projektowanie
- życzenia
- rozwijanie
- różne
- omówione
- dystrybuowane
- dokument
- Nie
- dominujący
- dominować
- nie
- z powodu
- podczas
- e
- każdy
- efektywność
- wydajny
- bądź
- Punkt końcowy
- Punkty końcowe
- Inżynieria
- silniki
- dość
- Wchodzę
- Enterprise
- adopcja przedsiębiorstwa
- Enterprise Solutions
- jednostka
- wejście
- Środowisko
- epoka
- błąd
- Eter (ETH)
- oceniać
- oceniane
- oceny
- Parzyste
- wydarzenia
- przykład
- Z wyjątkiem
- wyjątek
- wyłącznie
- Przede wszystkim system został opracowany
- doświadczenie
- Wyjaśniać
- wyjaśnione
- rozbudowa
- Twarz
- fałszywy
- szybciej
- Korzyści
- informacja zwrotna
- mniej
- pole
- filet
- Akta
- finał
- Znajdź
- znalezieniu
- i terminów, a
- ustalony
- Elastyczność
- unoszący się
- następujący
- Ślad stopy
- W razie zamówieenia projektu
- znaleziono
- Fundacja
- od
- z przodu
- Granica
- w pełni
- funkcjonować
- dalej
- Generować
- generuje
- generatywny
- generatywna sztuczna inteligencja
- otrzymać
- dany
- cel
- GPU
- szary
- dzieje
- Have
- he
- głowa
- głowice
- opieki zdrowotnej
- pomaga
- Ukryty
- wydajny
- wyższy
- turystyka
- jego
- historia
- Hobby
- gospodarz
- hostowane
- GODZINY
- W jaki sposób
- How To
- Jednak
- HTML
- http
- HTTPS
- Przytulanie twarzy
- Optymalizacja hiperparametrów
- Dostrajanie hiperparametrów
- i
- zidentyfikować
- IDX
- if
- zilustrować
- Rezultat
- Oddziaływania
- wdrożenia
- importować
- podnieść
- ulepszony
- poprawa
- poprawy
- in
- zawierać
- Zwiększać
- wzrosła
- wzrastający
- Informacja
- Infrastruktura
- wkład
- przykład
- instancje
- zamiast
- Inteligentny
- najnowszych
- IT
- JEGO
- Praca
- Oferty pracy
- jpg
- json
- wiedza
- znany
- język
- duży
- na dużą skalę
- największym
- Utajenie
- warstwa
- nioski
- Wyprowadzenia
- UCZYĆ SIĘ
- nauka
- najmniej
- niech
- biblioteki
- Biblioteka
- Linia
- załadować
- log
- zalogowaniu
- poszukuje
- od
- straty
- niższy
- maszyna
- uczenie maszynowe
- utrzymać
- utrzymanie
- mężczyzna
- zarządzane
- Maraton
- maska
- matplotlib
- maksymalny
- Może..
- znaczenie
- zmierzyć
- mierzona
- zmierzenie
- medyczny
- Poznaj nasz
- Pamięć
- Metadane
- metody
- metryczny
- Metryka
- może
- zminimalizować
- minuty
- ML
- model
- modelowanie
- modele
- Modułowa
- jeszcze
- ruch
- dużo
- wielokrotność
- musi
- Nazwa
- O imieniu
- Nazwy
- nas
- Naturalny
- Język naturalny
- Przetwarzanie języka naturalnego
- Nawigacja
- Nawigacja
- niezbędny
- Potrzebować
- potrzebne
- wymagania
- sieć
- sieci
- Nerwowy
- sieci neuronowe
- sieci neuronowe
- Następny
- nlp
- żaden
- noty
- notatnik
- laptopy
- już dziś
- numer
- przedmiot
- cel
- Cele
- obserwować
- zauważony
- of
- poza
- oferta
- Oferty
- on
- ONE
- Online
- sklep internetowy
- tylko
- koncepcja
- open source
- Optymalny
- optymalizacja
- Optymalizacja
- zoptymalizowane
- Optymalizuje
- optymalizacji
- or
- zamówienie
- oryginalny
- Inne
- ludzkiej,
- na zewnątrz
- wydajność
- Wyjścia
- koniec
- ogólny
- przegląd
- własny
- par
- chleb
- Parallel
- parametr
- parametry
- Pareto
- część
- minęło
- ścieżka
- pacjent
- wzory
- wykonać
- jest gwarancją najlepszej jakości, które mogą dostarczyć Ci Twoje monitory,
- wykonywane
- wykonywania
- wykonuje
- uprawnienia
- plato
- Analiza danych Platona
- PlatoDane
- punkt
- zwrotnica
- Pozycje
- Post
- Detaliczność
- przepowiednia
- proroczy
- Urządzenie prognozujące
- preferencje
- przygotowany
- warunki wstępne
- teraźniejszość
- poprzednio
- Główny
- Problem
- wygląda tak
- Automatyzacja procesów
- procesów
- przetwarzanie
- Produkt
- wydajność
- Narzędzia zwiększające wydajność
- zaproponowane
- dostawca
- zapewnia
- że
- ciągnięcie
- Ściąga
- cel
- cele
- Python
- płomień
- Q & A
- pytanie
- całkiem
- przypadkowy
- zasięg
- szybki
- ceny
- Surowy
- real
- uznanie
- rozpoznać
- rozpoznawanie
- Rekomendacja
- zalecenia
- rekord
- nagrany
- Czerwony
- zmniejszyć
- Zredukowany
- zmniejsza
- regresja
- związane z
- usuwa
- usuwanie
- Raporty
- reprezentacja
- zażądać
- wniosek
- wywołań
- wymagany
- wymagania
- sprężysty
- Zasób
- Zasoby
- odpowiednio
- odpowiedź
- Efekt
- detalista
- wspornikowy
- powraca
- jazda konna
- Ryzyko
- RZĄD
- run
- biegacz
- bieganie
- działa
- s
- poświęcać
- sagemaker
- Wnioskowanie SageMakera
- Zapisz
- Skala
- waga
- nauka
- Naukowiec
- wynik
- scenariusz
- Szukaj
- Wyszukiwarki
- poszukiwania
- druga
- Sekcja
- widzieć
- wybierać
- wybrany
- SAMEGO SIEBIE
- wysłać
- wyrok
- sentyment
- Sekwencja
- usługa
- Usługi
- Sesja
- zestaw
- Zestawy
- ustawienie
- Targi
- Sygnały
- znacznie
- Prosty
- jednoczesny
- jednocześnie
- pojedynczy
- Rozmiar
- mniejszy
- So
- Tworzenie
- rozwiązanie
- Rozwiązania
- kilka
- Źródło
- Typ przestrzeni
- Ikra
- wyspecjalizowanym
- specjalizuje się
- specyficzny
- swoiście
- Spędzanie
- dzielić
- początek
- rozpocznie
- Stan
- statystyka
- Ewolucja krok po kroku
- Cel
- przechowywanie
- strukturalny
- zbudowany
- studio
- znaczny
- udany
- Z powodzeniem
- taki
- odpowiedni
- apartament
- PODSUMOWANIE
- system
- systemy
- T
- Brać
- trwa
- cel
- Zadanie
- zadania
- Zespoły
- technika
- Techniki
- Szablony
- REGULAMIN
- Testowanie
- Testy
- XNUMX
- Klasyfikacja tekstu
- tekstowy
- niż
- że
- Połączenia
- ich
- następnie
- Tam.
- w związku z tym
- Te
- to
- trzy
- próg
- Przez
- czas
- czasy
- do
- razem
- żeton
- wziął
- narzędzie
- narzędzia
- handel
- Handel
- Pociąg
- przeszkolony
- Trening
- transformator
- Transformatory
- prawdziwy
- próbować
- drugiej
- rodzaj
- typy
- typowy
- zazwyczaj
- Ostatecznie
- dla
- w trakcie
- zrozumienie
- jednostek
- us
- posługiwać się
- przypadek użycia
- używany
- Użytkownik
- Użytkownicy
- zastosowania
- za pomocą
- uprawomocnienie
- wartość
- Wartości
- wersja
- przez
- Wirtualny
- wyobrażać sobie
- vs
- chcieć
- była
- we
- sieć
- usługi internetowe
- DOBRZE
- jeśli chodzi o komunikację i motywację
- czy
- który
- Podczas
- KIM
- szeroki
- Szeroki zasięg
- szeroko
- żona
- Wikipedia
- będzie
- skłonny
- w
- w ciągu
- Praca
- workflow
- pracujący
- X
- lat
- Wydajność
- ty
- Twój
- zefirnet