OpenAI Whisper er en avansert automatisk talegjenkjenningsmodell (ASR) med en MIT-lisens. ASR-teknologi finner nytte i transkripsjonstjenester, stemmeassistenter og forbedret tilgjengelighet for personer med hørselshemninger. Denne toppmoderne modellen er trent på et stort og mangfoldig datasett med flerspråklige og multitask-overvåkede data samlet inn fra nettet. Dens høye nøyaktighet og tilpasningsevne gjør den til en verdifull ressurs for et bredt spekter av stemmerelaterte oppgaver.
I det stadig utviklende landskapet med maskinlæring og kunstig intelligens, Amazon SageMaker gir et omfattende økosystem. SageMaker gir dataforskere, utviklere og organisasjoner mulighet til å utvikle, trene, distribuere og administrere maskinlæringsmodeller i stor skala. Den tilbyr et bredt spekter av verktøy og funksjoner, og forenkler hele arbeidsflyten for maskinlæring, fra dataforbehandling og modellutvikling til uanstrengt distribusjon og overvåking. SageMakers brukervennlige grensesnitt gjør det til en sentral plattform for å frigjøre det fulle potensialet til AI, og etablere det som en spillendrende løsning innen kunstig intelligens.
I dette innlegget tar vi fatt på en utforskning av SageMakers muligheter, spesielt med fokus på hosting av Whisper-modeller. Vi vil dykke dypt inn i to metoder for å gjøre dette: den ene bruker Whisper PyTorch-modellen og den andre bruker Hugging Face-implementeringen av Whisper-modellen. I tillegg vil vi gjennomføre en grundig undersøkelse av SageMakers slutningsalternativer, og sammenligne dem på tvers av parametere som hastighet, kostnad, nyttelaststørrelse og skalerbarhet. Denne analysen gir brukerne mulighet til å ta informerte beslutninger når de integrerer Whisper-modeller i deres spesifikke brukstilfeller og systemer.
Løsningsoversikt
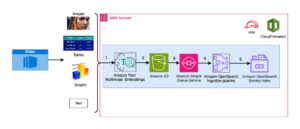
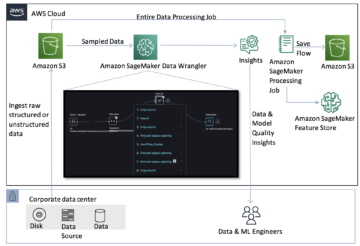
Følgende diagram viser hovedkomponentene i denne løsningen.
- For å være vert for modellen på Amazon SageMaker, er det første trinnet å lagre modellartefaktene. Disse artefaktene refererer til de essensielle komponentene i en maskinlæringsmodell som er nødvendig for ulike applikasjoner, inkludert distribusjon og omskolering. De kan inkludere modellparametere, konfigurasjonsfiler, forhåndsbehandlingskomponenter, samt metadata, for eksempel versjonsdetaljer, forfatterskap og eventuelle merknader relatert til ytelsen. Det er viktig å merke seg at Whisper-modeller for PyTorch og Hugging Face-implementeringer består av forskjellige modellartefakter.
- Deretter lager vi tilpassede slutningsskript. Innenfor disse skriptene definerer vi hvordan modellen skal lastes og spesifiserer inferensprosessen. Det er også her vi kan inkludere tilpassede parametere etter behov. I tillegg kan du liste de nødvendige Python-pakkene i en
requirements.txtfil. Under utrullingen av modellen blir disse Python-pakkene automatisk installert i initialiseringsfasen. - Deretter velger vi enten PyTorch eller Hugging Face deep learning containere (DLC) levert og vedlikeholdt av AWS. Disse beholderne er forhåndsbygde Docker-bilder med dype læringsrammer og andre nødvendige Python-pakker. For mer informasjon kan du sjekke dette link.
- Med modellartefakter, tilpassede slutningsskripter og utvalgte DLC-er, vil vi lage Amazon SageMaker-modeller for henholdsvis PyTorch og Hugging Face.
- Til slutt kan modellene distribueres på SageMaker og brukes med følgende alternativer: sanntidsslutningsendepunkter, batchtransformasjonsjobber og asynkrone inferensendepunkter. Vi vil dykke inn i disse alternativene mer detaljert senere i dette innlegget.
Eksempelnotisboken og koden for denne løsningen er tilgjengelig på denne GitHub repository.
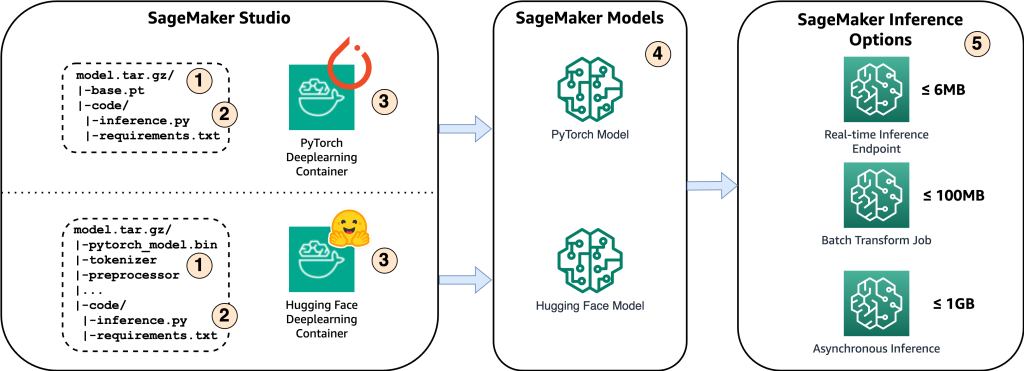
Figur 1. Oversikt over nøkkelkomponenter i løsningen
walkthrough
Hosting Whisper Model på Amazon SageMaker
I denne delen vil vi forklare trinnene for å være vert for Whisper-modellen på Amazon SageMaker, ved å bruke henholdsvis PyTorch og Hugging Face Frameworks. For å eksperimentere med denne løsningen trenger du en AWS-konto og tilgang til Amazon SageMaker-tjenesten.
PyTorch-rammeverket
- Lagre modellartefakter
Det første alternativet for å være vert for modellen er å bruke Whisper offisielle Python-pakke, som kan installeres ved hjelp av pip install openai-whisper. Denne pakken inneholder en PyTorch-modell. Når du lagrer modellartefakter i det lokale depotet, er det første trinnet å lagre modellens parametere som kan læres, for eksempel modellvekter og skjevheter for hvert lag i det nevrale nettverket, som en "pt"-fil. Du kan velge mellom ulike modellstørrelser, inkludert «liten», «base», «liten», «middels» og «stor». Større modellstørrelser gir høyere nøyaktighet, men kommer på bekostning av lengre slutningsforsinkelse. I tillegg må du lagre modelltilstandsordboken og dimensjonsordboken, som inneholder en Python-ordbok som kartlegger hvert lag eller parameter i PyTorch-modellen til de tilsvarende innlærbare parameterne, sammen med andre metadata og egendefinerte konfigurasjoner. Koden nedenfor viser hvordan du lagrer Whisper PyTorch-artefakter.
- Velg DLC
Det neste trinnet er å velge den forhåndsbygde DLC-en fra denne link. Vær forsiktig når du velger riktig bilde ved å vurdere følgende innstillinger: rammeverk (PyTorch), rammeversjon, oppgave (slutning), Python-versjon og maskinvare (dvs. GPU). Det anbefales å bruke de nyeste versjonene for rammeverket og Python når det er mulig, da dette resulterer i bedre ytelse og adresserer kjente problemer og feil fra tidligere utgivelser.
- Lag Amazon SageMaker-modeller
Deretter bruker vi SageMaker Python SDK å lage PyTorch-modeller. Det er viktig å huske å legge til miljøvariabler når du lager en PyTorch-modell. Som standard kan TorchServe bare behandle filstørrelser på opptil 6 MB, uavhengig av inferenstypen som brukes.
Følgende tabell viser innstillingene for forskjellige PyTorch-versjoner:
| Rammeverk | Miljøvariabler |
| PyTorch 1.8 (basert på TorchServe) | 'TS_MAX_REQUEST_SIZE': '100000000'' TS_MAX_RESPONSE_SIZE': '100000000'' TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (basert på MMS) | 'MMS_MAX_REQUEST_SIZE': '1000000000'' MMS_MAX_RESPONSE_SIZE': '1000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definer modelllastingsmetoden i inference.py
I skikken inference.py skript, sjekker vi først tilgjengeligheten til en CUDA-kompatibel GPU. Hvis en slik GPU er tilgjengelig, tildeler vi 'cuda' enheten til DEVICE variabel; ellers tildeler vi 'cpu' enhet. Dette trinnet sikrer at modellen plasseres på tilgjengelig maskinvare for effektiv beregning. Vi laster PyTorch-modellen ved å bruke Whisper Python-pakken.
Hugging Face rammeverk
- Lagre modellartefakter
Det andre alternativet er å bruke Hugging Face's Whisper gjennomføring. Modellen kan lastes ved hjelp av AutoModelForSpeechSeq2Seq transformator klasse. De lærbare parameterne lagres i en binær (bin) fil ved hjelp av save_pretrained metode. Tokenizeren og forprosessoren må også lagres separat for å sikre at Hugging Face-modellen fungerer som den skal. Alternativt kan du distribuere en modell på Amazon SageMaker direkte fra Hugging Face Hub ved å angi to miljøvariabler: HF_MODEL_ID og HF_TASK. For mer informasjon, se denne webside.
- Velg DLC
I likhet med PyTorch-rammeverket kan du velge en forhåndsbygd Hugging Face DLC fra det samme link. Sørg for å velge en DLC som støtter de nyeste Hugging Face-transformatorene og inkluderer GPU-støtte.
- Lag Amazon SageMaker-modeller
På samme måte bruker vi SageMaker Python SDK å lage Hugging Face-modeller. Hugging Face Whisper-modellen har en standardbegrensning der den kun kan behandle lydsegmenter i opptil 30 sekunder. For å løse denne begrensningen kan du inkludere chunk_length_s parameter i miljøvariabelen når du oppretter Hugging Face-modellen, og senere overføre denne parameteren til det tilpassede slutningsskriptet når du laster modellen. Til slutt setter du miljøvariablene for å øke nyttelaststørrelsen og tidsavbrudd for respons for Hugging Face-beholderen.
| Rammeverk | Miljøvariabler |
|
HuggingFace Inference Container (basert på MMS) |
'MMS_MAX_REQUEST_SIZE': '2000000000'' MMS_MAX_RESPONSE_SIZE': '2000000000'' MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definer modelllastingsmetoden i inference.py
Når vi lager tilpasset slutningsskript for Hugging Face-modellen, bruker vi en pipeline som lar oss passere chunk_length_s som en parameter. Denne parameteren gjør det mulig for modellen å effektivt behandle lange lydfiler under inferens.
Utforske forskjellige slutningsalternativer på Amazon SageMaker
Trinnene for å velge slutningsalternativer er de samme for både PyTorch og Hugging Face-modeller, så vi vil ikke skille mellom dem nedenfor. Det er imidlertid verdt å merke seg at på tidspunktet for skriving av dette innlegget serverløs slutning alternativet fra SageMaker støtter ikke GPUer, og som et resultat ekskluderer vi dette alternativet for denne brukssaken.
Vi kan distribuere modellen som et endepunkt i sanntid, og gir svar på millisekunder. Det er imidlertid viktig å merke seg at dette alternativet er begrenset til å behandle innganger under 6 MB. Vi definerer serializeren som en audio serializer, som er ansvarlig for å konvertere inndataene til et passende format for den utplasserte modellen. Vi bruker en GPU-forekomst for slutninger, som tillater akselerert behandling av lydfiler. Inferensinngangen er en lydfil som er fra det lokale depotet.
Det andre slutningsalternativet er batch-transformeringsjobben, som er i stand til å behandle input-nyttelaster på opptil 100 MB. Imidlertid kan denne metoden ta noen minutter med latenstid. Hver forekomst kan håndtere bare én batchforespørsel om gangen, og forekomstinitieringen og avslutningen krever også noen minutter. Inferensresultatene lagres i en Amazon Simple Storage Service (Amazon S3) bøtte ved fullføring av batchtransformeringsjobben.
Når du konfigurerer batchtransformatoren, sørg for å inkludere max_payload = 100 å håndtere større nyttelast effektivt. Inferensinngangen skal være Amazon S3-banen til en lydfil eller en Amazon S3 Bucket-mappe som inneholder en liste over lydfiler, hver med en størrelse mindre enn 100 MB.
Batch Transform partisjonerer Amazon S3-objektene i input med nøkkel og tilordner Amazon S3-objekter til instanser. For eksempel, når du har flere lydfiler, kan én forekomst behandle input1.wav, og en annen forekomst kan behandle filen med navnet input2.wav for å forbedre skalerbarheten. Batch Transform lar deg konfigurere max_concurrent_transforms for å øke antallet HTTP-forespørsler til hver enkelt transformatorbeholder. Det er imidlertid viktig å merke seg at verdien av (max_concurrent_transforms* max_payload) må ikke overstige 100 MB.
Til slutt, Amazon SageMaker Asynchronous Inference er ideell for å behandle flere forespørsler samtidig, og tilbyr moderat latens og støtter input-nyttelast på opptil 1 GB. Dette alternativet gir utmerket skalerbarhet, og muliggjør konfigurasjon av en autoskaleringsgruppe for endepunktet. Når en bølge av forespørsler oppstår, skaleres den automatisk opp for å håndtere trafikken, og når alle forespørsler er behandlet, skaleres endepunktet ned til 0 for å spare kostnader.
Ved å bruke asynkron inferens lagres resultatene automatisk i en Amazon S3-bøtte. I AsyncInferenceConfig, kan du konfigurere varsler for vellykkede eller mislykkede fullføringer. Inndatabanen peker til en Amazon S3-plassering for lydfilen. For ytterligere detaljer, se koden på GitHub.
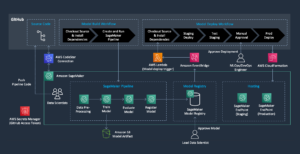
Valgfritt: Som nevnt tidligere har vi muligheten til å konfigurere en autoskaleringsgruppe for det asynkrone inferensendepunktet, som lar det håndtere en plutselig økning i inferensforespørsler. Et kodeeksempel er gitt i denne GitHub repository. I det følgende diagrammet kan du observere et linjediagram som viser to beregninger fra Amazon CloudWatch: ApproximateBacklogSize og ApproximateBacklogSizePerInstance. I utgangspunktet, da 1000 forespørsler ble utløst, var bare én instans tilgjengelig for å håndtere slutningen. I tre minutter overskred backlog-størrelsen konsekvent tre (vær oppmerksom på at disse tallene kan konfigureres), og autoskaleringsgruppen svarte med å spinne opp flere forekomster for å effektivt fjerne etterslepet. Dette resulterte i en betydelig nedgang i ApproximateBacklogSizePerInstance, slik at forespørsler om etterslep kan behandles mye raskere enn i den innledende fasen.

Figur 2. Linjediagram som illustrerer de tidsmessige endringene i Amazon CloudWatch-beregninger
Komparativ analyse for slutningsalternativene
Sammenligningene for forskjellige slutningsalternativer er basert på vanlige brukstilfeller for lydbehandling. Sanntidsslutning gir den raskeste inferenshastigheten, men begrenser nyttelaststørrelsen til 6 MB. Denne inferenstypen er egnet for lydkommandosystemer, der brukere kontrollerer eller samhandler med enheter eller programvare ved hjelp av talekommandoer eller talte instruksjoner. Talekommandoer er vanligvis små i størrelse, og lav inferensforsinkelse er avgjørende for å sikre at transkriberte kommandoer umiddelbart kan utløse påfølgende handlinger. Batch Transform er ideell for planlagte offline-oppgaver, når hver lydfils størrelse er under 100 MB, og det ikke er noe spesifikt krav til raske responstider. Asynkron slutning gir mulighet for opplastinger på opptil 1 GB og tilbyr moderat slutningsforsinkelse. Denne inferenstypen er godt egnet for transkribering av filmer, TV-serier og innspilte konferanser der større lydfiler må behandles.
Alternativer for både sanntid og asynkron inferens gir autoskaleringsmuligheter, slik at endepunktforekomstene automatisk kan skaleres opp eller ned basert på volumet av forespørsler. I tilfeller uten forespørsler, fjerner autoskalering unødvendige forekomster, og hjelper deg med å unngå kostnader forbundet med klargjorte forekomster som ikke er aktivt i bruk. For sanntidsslutninger må imidlertid minst én vedvarende forekomst beholdes, noe som kan føre til høyere kostnader hvis endepunktet opererer kontinuerlig. I kontrast tillater asynkron inferens at instansvolumet reduseres til 0 når det ikke er i bruk. Når du konfigurerer en batch-transformeringsjobb, er det mulig å bruke flere forekomster for å behandle jobben og justere max_concurrent_transforms for å aktivere én forekomst til å håndtere flere forespørsler. Derfor tilbyr alle tre slutningsalternativene stor skalerbarhet.
Rydder opp
Når du har fullført bruken av løsningen, sørg for å fjerne SageMaker-endepunktene for å forhindre ekstra kostnader. Du kan bruke den medfølgende koden til å slette henholdsvis sanntids- og asynkrone inferensendepunkter.
konklusjonen
I dette innlegget viste vi deg hvordan distribusjon av maskinlæringsmodeller for lydbehandling har blitt stadig viktigere i ulike bransjer. Ved å ta Whisper-modellen som et eksempel, demonstrerte vi hvordan du kan være vert for åpen kildekode ASR-modeller på Amazon SageMaker ved å bruke PyTorch eller Hugging Face-tilnærminger. Utforskningen omfattet ulike slutningsalternativer på Amazon SageMaker, og ga innsikt i effektiv håndtering av lyddata, lage spådommer og administrere kostnadene effektivt. Dette innlegget tar sikte på å gi kunnskap til forskere, utviklere og dataforskere som er interessert i å utnytte Whisper-modellen for lydrelaterte oppgaver og ta informerte beslutninger om slutningsstrategier.
For mer detaljert informasjon om distribusjon av modeller på SageMaker, vennligst se denne Utviklerveiledning. I tillegg kan Whisper-modellen distribueres ved hjelp av SageMaker JumpStart. For ytterligere detaljer, vennligst sjekk Whisper-modeller for automatisk talegjenkjenning er nå tilgjengelig i Amazon SageMaker JumpStart post.
Sjekk gjerne ut notatboken og koden for dette prosjektet på GitHub og del kommentaren din med oss.
om forfatteren
 Ying Hou, PhD, er Machine Learning Prototyping Architect ved AWS. Hennes primære interesseområder omfatter Deep Learning, med fokus på GenAI, Computer Vision, NLP og tidsseriedataprediksjon. På fritiden liker hun å tilbringe gode øyeblikk med familien, fordype seg i romaner og gå på fotturer i nasjonalparkene i Storbritannia.
Ying Hou, PhD, er Machine Learning Prototyping Architect ved AWS. Hennes primære interesseområder omfatter Deep Learning, med fokus på GenAI, Computer Vision, NLP og tidsseriedataprediksjon. På fritiden liker hun å tilbringe gode øyeblikk med familien, fordype seg i romaner og gå på fotturer i nasjonalparkene i Storbritannia.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- akselerert
- adgang
- tilgjengelighet
- Logg inn
- nøyaktighet
- tvers
- handlinger
- aktivt
- legge til
- Ytterligere
- I tillegg
- adresse
- justere
- avansert
- AI
- mål
- Alle
- tillate
- tillater
- langs
- også
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- analyse
- og
- En annen
- noen
- søknader
- tilnærminger
- ER
- områder
- Array
- kunstig
- kunstig intelligens
- AS
- eiendel
- assistenter
- assosiert
- At
- lyd
- Forfatterskap
- Automatisk
- automatisk
- tilgjengelighet
- tilgjengelig
- unngå
- AWS
- basen
- basert
- BE
- bli
- under
- Bedre
- mellom
- skjevheter
- BIN
- både
- bugs
- men
- by
- CAN
- evner
- stand
- forsiktig
- saker
- Endringer
- Figur
- sjekk
- Velg
- velge
- klasse
- fjerne
- kode
- Kom
- kommentere
- Felles
- sammenligne
- sammenligninger
- Terminado
- ferdigstillelse
- komponenter
- omfattende
- beregningen
- datamaskin
- Datamaskin syn
- Gjennomføre
- konferanser
- Konfigurasjon
- konfigurert
- konfigurering
- vurderer
- konsekvent
- inneholde
- Container
- Containere
- kontinuerlig
- kontrast
- kontroll
- konvertering
- korrigere
- Tilsvarende
- Kostnad
- Kostnader
- kunne
- prosessor
- skape
- Opprette
- avgjørende
- skikk
- dato
- avgjørelser
- redusere
- dyp
- dyp læring
- Misligholde
- definere
- demonstrert
- utplassere
- utplassert
- utplasserings
- distribusjon
- detalj
- detaljert
- detaljer
- utvikle
- utviklere
- Utvikling
- enhet
- Enheter
- forskjellig
- differensiere
- Dimensjon
- direkte
- visning
- dykk
- diverse
- Docker
- ikke
- gjør
- ned
- under
- e
- hver enkelt
- Tidligere
- økosystem
- effektivt
- effektiv
- effektivt
- uanstrengt
- enten
- ellers
- legge ut på
- bemyndiger
- muliggjøre
- muliggjør
- muliggjør
- omfatte
- Endpoint
- endepunkter
- forbedre
- styrke
- sikre
- sikrer
- Hele
- Miljø
- avgjørende
- etablere
- Eter (ETH)
- undersøkelse
- eksempel
- stige
- skredet
- utmerket
- eksperiment
- Forklar
- leting
- Utforske
- Face
- Mislyktes
- falsk
- familie
- FAST
- raskere
- raskeste
- Noen få
- filet
- Filer
- funn
- Først
- Fokus
- fokusering
- etter
- Til
- format
- Rammeverk
- rammer
- Gratis
- fra
- fullt
- GPU
- GPU
- flott
- Gruppe
- håndtere
- Håndtering
- maskinvare
- Ha
- hørsel
- hjelpe
- her
- Høy
- høyere
- vandreturer
- vert
- Hosting
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- Hub
- Klem ansikt
- i
- ideell
- if
- illustrerer
- bilde
- bilder
- gjennomføring
- implementeringer
- importere
- viktig
- in
- dyptgående
- inkludere
- inkluderer
- Inkludert
- innlemme
- Øke
- stadig
- individuelt
- individer
- bransjer
- informasjon
- informert
- innledende
- i utgangspunktet
- initiering
- inngang
- innganger
- innsikt
- installere
- f.eks
- forekomster
- instruksjoner
- Integrering
- Intelligens
- samhandle
- interesse
- interessert
- Interface
- inn
- saker
- IT
- DET ER
- Jobb
- Jobb
- jpg
- nøkkel
- kunnskap
- kjent
- landskap
- større
- til slutt
- Ventetid
- seinere
- siste
- lag
- føre
- læring
- minst
- utnytte
- Tillatelse
- begrensning
- Begrenset
- linje
- Liste
- laste
- lasting
- lokal
- plassering
- Lang
- lenger
- Lav
- maskin
- maskinlæring
- laget
- Hoved
- gjøre
- GJØR AT
- Making
- administrer
- administrerende
- Kart
- Kan..
- nevnt
- metadata
- metode
- metoder
- Metrics
- kunne
- millisekunder
- minutter
- MIT
- ML
- modell
- modeller
- moderat
- Moments
- overvåking
- mer
- Filmer
- mye
- flere
- må
- oppkalt
- nasjonal
- nasjonalparker
- nødvendig
- Trenger
- nødvendig
- nettverk
- neural
- nevrale nettverket
- neste
- nlp
- Nei.
- note
- bærbare
- Merknader
- varsling
- varslinger
- merke seg
- nå
- Antall
- tall
- objekt
- gjenstander
- observere
- of
- tilby
- tilby
- Tilbud
- offisiell
- offline
- on
- gang
- ONE
- bare
- åpen kildekode
- opererer
- Alternativ
- alternativer
- or
- rekkefølge
- organisasjoner
- OS
- Annen
- ellers
- ut
- oversikt
- pakke
- pakker
- parameter
- parametere
- parker
- passere
- banen
- utføre
- ytelse
- fase
- rørledning
- sentral
- plasseres
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- vær så snill
- poeng
- mulig
- Post
- potensiell
- prediksjon
- Spådommer
- forebygge
- forrige
- primære
- prosess
- behandlet
- prosessering
- prosessor
- prosjekt
- riktig
- prototyping
- gi
- forutsatt
- gir
- gi
- Python
- pytorch
- kvalitet
- område
- sanntids
- riket
- anerkjennelse
- anbefales
- registrert
- Redusert
- referere
- Uansett
- i slekt
- Utgivelser
- husker
- fjerne
- Fjerner
- Repository
- anmode
- forespørsler
- krever
- påkrevd
- behov
- forskere
- henholdsvis
- svar
- svar
- ansvarlig
- resultere
- resulterte
- Resultater
- beholdes
- omskolering
- retur
- sagemaker
- samme
- Spar
- lagret
- besparende
- skalerbarhet
- Skala
- vekter
- planlagt
- forskere
- script
- skript
- Sekund
- sekunder
- Seksjon
- segmenter
- velg
- valgt
- velge
- Serien
- tjeneste
- Tjenester
- sett
- innstilling
- innstillinger
- Del
- hun
- bør
- viste
- Viser
- nedleggelse
- signifikant
- Enkelt
- forenkler
- Størrelse
- størrelser
- liten
- mindre
- So
- Software
- løsning
- spesifikk
- spesielt
- spesifisert
- tale
- Talegjenkjenning
- fart
- utgifter
- talt
- Begynn
- Tilstand
- state-of-the-art
- Trinn
- Steps
- lagring
- strategier
- senere
- vellykket
- slik
- plutselig
- egnet
- støtte
- Støtte
- Støtter
- sikker
- bølge
- Systemer
- bord
- Ta
- ta
- Oppgave
- oppgaver
- Teknologi
- enn
- Det
- De
- Storbritannia
- deres
- Dem
- deretter
- Der.
- derfor
- Disse
- de
- denne
- tre
- tid
- Tidsserier
- ganger
- til
- verktøy
- lommelykt
- trafikk
- Tog
- trent
- Transform
- transformator
- transformers
- utløse
- utløst
- tv
- TV-serie
- to
- typen
- typisk
- Uk
- etter
- opplåsing
- upon
- us
- bruke
- brukt
- brukervennlig
- Brukere
- ved hjelp av
- verktøyet
- bruke
- utnytte
- Verdifull
- verdi
- variabel
- ulike
- enorme
- versjon
- syn
- Voice
- talekommandoer
- volum
- vente
- ønsker
- var
- we
- web
- webtjenester
- VI VIL
- var
- når
- når som helst
- hvilken
- Hviske
- bred
- Bred rekkevidde
- med
- innenfor
- arbeidsflyt
- virker
- verdt
- skriving
- du
- Din
- zephyrnet