Resiliens spiller en sentral rolle i utviklingen av enhver arbeidsbelastning, og generativ AI arbeidsbelastningen er ikke annerledes. Det er unike hensyn når man konstruerer generative AI-arbeidsbelastninger gjennom en motstandsdyktig linse. Forståelse og prioritering av robusthet er avgjørende for generative AI-arbeidsbelastninger for å møte organisatorisk tilgjengelighet og krav til forretningskontinuitet. I dette innlegget diskuterer vi de forskjellige stablene i en generativ AI-arbeidsmengde og hva disse hensynene bør være.
Full stack generativ AI
Selv om mye av spenningen rundt generativ AI fokuserer på modellene, involverer en komplett løsning mennesker, ferdigheter og verktøy fra flere domener. Tenk på følgende bilde, som er en AWS-visning av a16z nye applikasjonsstabel for store språkmodeller (LLM).
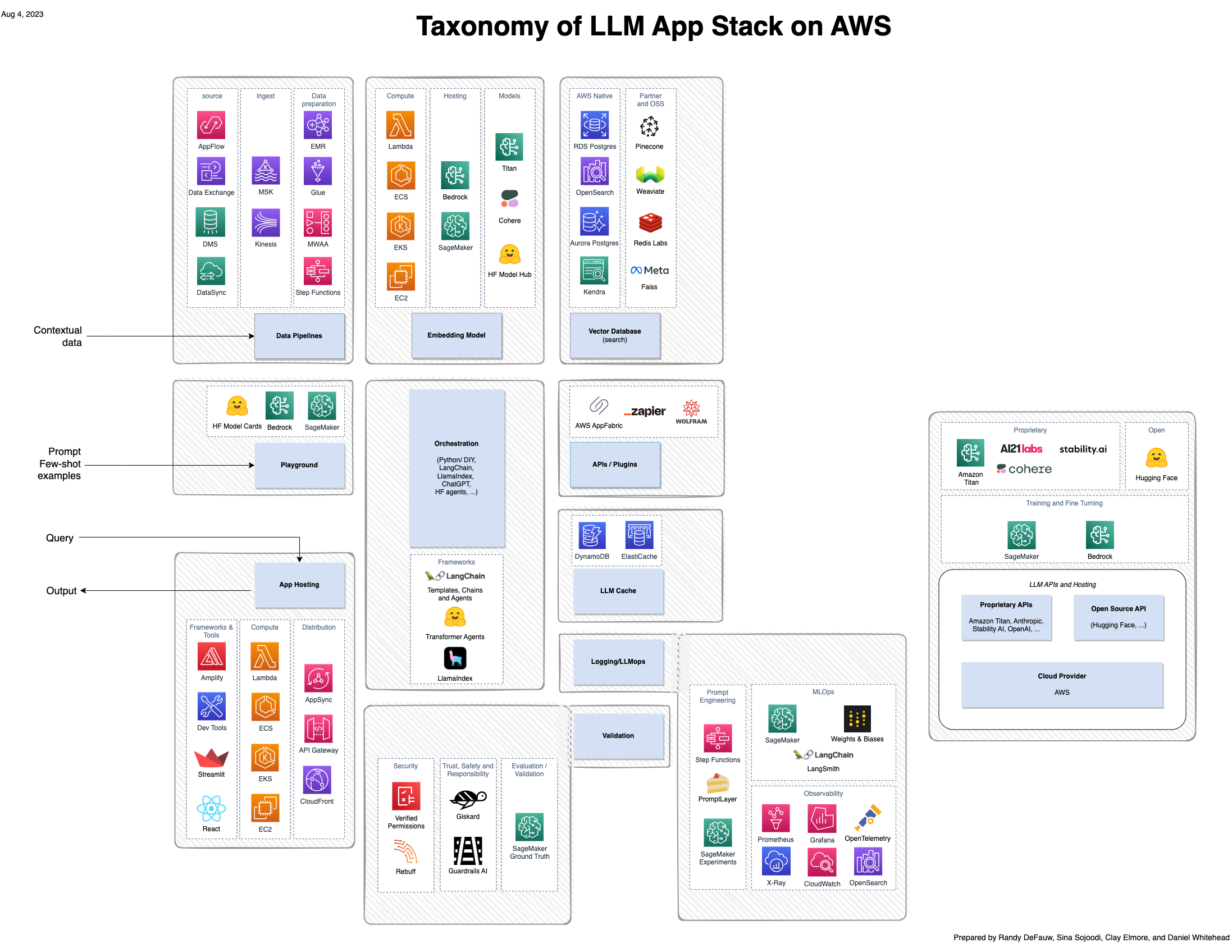
Sammenlignet med en mer tradisjonell løsning bygget rundt AI og maskinlæring (ML), innebærer en generativ AI-løsning nå følgende:
- Nye roller – Du må vurdere modelltunere så vel som modellbyggere og modellintegratorer
- Nye verktøy – Den tradisjonelle MLOps-stakken strekker seg ikke til å dekke den typen eksperimentsporing eller observerbarhet som er nødvendig for prompt engineering eller agenter som påkaller verktøy for å samhandle med andre systemer
Agent resonnement
I motsetning til tradisjonelle AI-modeller tillater Retrieval Augmented Generation (RAG) mer nøyaktige og kontekstuelt relevante svar ved å integrere eksterne kunnskapskilder. Følgende er noen hensyn når du bruker RAG:
- Å angi passende tidsavbrudd er viktig for kundeopplevelsen. Ingenting sier dårlig brukeropplevelse mer enn å være midt i en chat og koble fra.
- Sørg for å validere promptinndata og promptinndatastørrelse for tildelte tegngrenser som er definert av modellen din.
- Hvis du utfører prompt engineering, bør du fortsette forespørslene dine til et pålitelig datalager. Det vil ivareta forespørslene dine i tilfelle utilsiktet tap eller som en del av din overordnede katastrofegjenopprettingsstrategi.
Datarørledninger
I tilfeller der du trenger å gi kontekstuelle data til fundamentmodellen ved hjelp av RAG-mønsteret, trenger du en datapipeline som kan ta inn kildedataene, konvertere dem til innebyggingsvektorer og lagre innebyggingsvektorene i en vektordatabase. Denne pipelinen kan være en batch-pipeline hvis du forbereder kontekstuelle data på forhånd, eller en pipeline med lav latens hvis du inkorporerer nye kontekstuelle data på farten. I batch-tilfellet er det et par utfordringer sammenlignet med typiske datarørledninger.
Datakildene kan være PDF-dokumenter på et filsystem, data fra et software as a service-system (SaaS) som et CRM-verktøy, eller data fra en eksisterende wiki eller kunnskapsbase. Inntak fra disse kildene er forskjellig fra de typiske datakildene som loggdata i en Amazon enkel lagringstjeneste (Amazon S3) bøtte eller strukturerte data fra en relasjonsdatabase. Nivået av parallellitet du kan oppnå kan være begrenset av kildesystemet, så du må ta hensyn til struping og bruke backoff-teknikker. Noen av kildesystemene kan være sprø, så du må bygge inn feilhåndtering og prøve logikk på nytt.
Embedding-modellen kan være en ytelsesflaskehals, uavhengig av om du kjører den lokalt i pipeline eller kaller en ekstern modell. Innebyggingsmodeller er grunnleggende modeller som kjører på GPUer og ikke har ubegrenset kapasitet. Hvis modellen kjører lokalt, må du tildele arbeid basert på GPU-kapasitet. Hvis modellen kjører eksternt, må du sørge for at du ikke metter den eksterne modellen. I begge tilfeller vil nivået av parallellitet du kan oppnå dikteres av innbyggingsmodellen i stedet for hvor mye CPU og RAM du har tilgjengelig i batchbehandlingssystemet.
I tilfellet med lav latens må du ta hensyn til tiden det tar å generere innebyggingsvektorene. Den anropende applikasjonen skal påkalle rørledningen asynkront.
Vektordatabaser
En vektordatabase har to funksjoner: lagre innebygde vektorer, og kjør et likhetssøk for å finne den nærmeste k samsvarer med en ny vektor. Det er tre generelle typer vektordatabaser:
- Dedikerte SaaS-alternativer som Pinecone.
- Vektordatabasefunksjoner innebygd i andre tjenester. Dette inkluderer native AWS-tjenester som Amazon OpenSearch-tjeneste og Amazonas Aurora.
- Alternativer i minnet som kan brukes for forbigående data i scenarier med lav latens.
Vi dekker ikke funksjonene for likhetssøk i detalj i dette innlegget. Selv om de er viktige, er de et funksjonelt aspekt av systemet og påvirker ikke motstandskraften direkte. I stedet fokuserer vi på motstandsdyktigheten til en vektordatabase som et lagringssystem:
- Ventetid – Kan vektordatabasen prestere godt mot høy eller uforutsigbar belastning? Hvis ikke, må den anropende applikasjonen håndtere satsbegrensning og backoff og prøve på nytt.
- skalerbarhet – Hvor mange vektorer kan systemet holde? Hvis du overskrider kapasiteten til vektordatabasen, må du se nærmere på sharding eller andre løsninger.
- Høy tilgjengelighet og katastrofegjenoppretting – Innbygging av vektorer er verdifulle data, og det kan være dyrt å gjenskape dem. Er vektordatabasen din svært tilgjengelig i en enkelt AWS-region? Har den muligheten til å replikere data til en annen region for gjenopprettingsformål?
Søknadsnivå
Det er tre unike hensyn til applikasjonsnivået ved integrering av generative AI-løsninger:
- Potensielt høy latens – Grunnmodeller kjører ofte på store GPU-forekomster og kan ha begrenset kapasitet. Sørg for å bruke beste fremgangsmåter for hastighetsbegrensning, backoff og prøv på nytt, og belastningsreduksjon. Bruk asynkrone design slik at høy latenstid ikke forstyrrer programmets hovedgrensesnitt.
- Sikkerhetsstilling – Hvis du bruker agenter, verktøy, plugins eller andre metoder for å koble en modell til andre systemer, vær ekstra oppmerksom på sikkerhetsstillingen din. Modeller kan prøve å samhandle med disse systemene på uventede måter. Følg den vanlige praksisen med minst privilegert tilgang, for eksempel å begrense innkommende meldinger fra andre systemer.
- Rammer i rask utvikling – Rammeverk med åpen kildekode som LangChain utvikler seg raskt. Bruk en mikrotjenester-tilnærming for å isolere andre komponenter fra disse mindre modne rammeverkene.
Kapasitet
Vi kan tenke på kapasitet i to sammenhenger: slutnings- og treningsmodelldatarørledninger. Kapasitet er en vurdering når organisasjoner bygger sine egne rørledninger. CPU- og minnekrav er to av de største kravene når du velger forekomster for å kjøre arbeidsbelastningene dine.
Forekomster som kan støtte generative AI-arbeidsbelastninger kan være vanskeligere å få tak i enn den gjennomsnittlige forekomsttypen for generell bruk. Forekomstfleksibilitet kan hjelpe med kapasitets- og kapasitetsplanlegging. Avhengig av hvilken AWS-region du kjører arbeidsmengden din i, er forskjellige forekomsttyper tilgjengelige.
For brukerreisene som er kritiske, vil organisasjoner vurdere enten å reservere eller forhåndsklarere forekomsttyper for å sikre tilgjengelighet når det er nødvendig. Dette mønsteret oppnår en statisk stabil arkitektur, som er en beste praksis for robusthet. For å lære mer om statisk stabilitet i AWS Well-Architected Framework pålitelighetspilar, se Bruk statisk stabilitet for å forhindre bimodal atferd.
observerbarhet
I tillegg til ressursberegningene du vanligvis samler inn, som CPU- og RAM-utnyttelse, må du overvåke GPU-bruken nøye hvis du er vert for en modell på Amazon SageMaker or Amazon Elastic Compute Cloud (Amazon EC2). GPU-bruken kan endres uventet hvis basismodellen eller inngangsdataene endres, og hvis det går tom for GPU-minne, kan systemet settes i en ustabil tilstand.
Høyere opp i stabelen vil du også spore flyten av samtaler gjennom systemet, og fange opp interaksjonene mellom agenter og verktøy. Fordi grensesnittet mellom agenter og verktøy er mindre formelt definert enn en API-kontrakt, bør du overvåke disse sporene ikke bare for ytelse, men også for å fange opp nye feilscenarier. For å overvåke modellen eller agenten for eventuelle sikkerhetsrisikoer og trusler, kan du bruke verktøy som Amazon Guard Duty.
Du bør også fange opp grunnlinjer for innebyggingsvektorer, ledetekster, kontekst og utdata, og interaksjonene mellom disse. Hvis disse endres over tid, kan det tyde på at brukerne bruker systemet på nye måter, at referansedataene ikke dekker spørsmålsrommet på samme måte, eller at modellens output plutselig er annerledes.
katastrofe~~POS=TRUNC gjenoppretting~~POS=HEADCOMP
Å ha en forretningskontinuitetsplan med en katastrofegjenopprettingsstrategi er et must for enhver arbeidsbelastning. Generative AI-arbeidsbelastninger er ikke annerledes. Å forstå feilmodusene som gjelder for arbeidsmengden din, vil hjelpe deg med å veilede strategien din. Hvis du bruker AWS-administrerte tjenester for arbeidsmengden din, for eksempel Amazonas grunnfjell og SageMaker, sørg for at tjenesten er tilgjengelig i din gjenopprettings-AWS-region. Når dette skrives, støtter ikke disse AWS-tjenestene replikering av data på tvers av AWS-regioner, så du må tenke på databehandlingsstrategiene dine for katastrofegjenoppretting, og du må kanskje også finjustere flere AWS-regioner.
konklusjonen
Dette innlegget beskrev hvordan du tar hensyn til robusthet når du bygger generative AI-løsninger. Selv om generative AI-applikasjoner har noen interessante nyanser, gjelder de eksisterende motstandsmønstrene og beste praksisene fortsatt. Det er bare et spørsmål om å evaluere hver del av en generativ AI-applikasjon og bruke de relevante beste praksisene.
For mer informasjon om generativ AI og bruk av den med AWS-tjenester, se følgende ressurser:
Om forfatterne
 Jennifer Moran er en AWS Senior Resiliency Specialist Solutions Architect basert i New York City. Hun har en mangfoldig bakgrunn, etter å ha jobbet i mange tekniske disipliner, inkludert programvareutvikling, smidig lederskap og DevOps, og er en talsmann for kvinner i teknologi. Hun liker å hjelpe kunder med å designe spenstige løsninger for å forbedre motstandskraften og snakker offentlig om alle emner relatert til resiliens.
Jennifer Moran er en AWS Senior Resiliency Specialist Solutions Architect basert i New York City. Hun har en mangfoldig bakgrunn, etter å ha jobbet i mange tekniske disipliner, inkludert programvareutvikling, smidig lederskap og DevOps, og er en talsmann for kvinner i teknologi. Hun liker å hjelpe kunder med å designe spenstige løsninger for å forbedre motstandskraften og snakker offentlig om alle emner relatert til resiliens.
 Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han jobbet med datasyn for autonome kjøretøy. Han har også en MBA fra Colorado State University. Randy har hatt en rekke stillinger innen teknologiområdet, alt fra programvareutvikling til produktadministrasjon. Han gikk inn i big data-området i 2013 og fortsetter å utforske det området. Han jobber aktivt med prosjekter i ML-området og har presentert på en rekke konferanser, inkludert Strata og GlueCon.
Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han jobbet med datasyn for autonome kjøretøy. Han har også en MBA fra Colorado State University. Randy har hatt en rekke stillinger innen teknologiområdet, alt fra programvareutvikling til produktadministrasjon. Han gikk inn i big data-området i 2013 og fortsetter å utforske det området. Han jobber aktivt med prosjekter i ML-området og har presentert på en rekke konferanser, inkludert Strata og GlueCon.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 100
- 2013
- 90
- a
- a16z
- evne
- Om oss
- adgang
- utilsiktet
- Logg inn
- nøyaktig
- Oppnå
- oppnår
- tvers
- aktivt
- avansere
- advokat
- påvirke
- mot
- Agent
- agenter
- smidig
- AI
- AI-modeller
- Alle
- allokert
- tillater
- også
- Selv
- Amazon
- Amazon EC2
- Amazon Web Services
- an
- og
- En annen
- noen
- api
- app
- aktuelt
- Søknad
- søknader
- Påfør
- påføring
- tilnærming
- hensiktsmessig
- arkitektur
- ER
- AREA
- rundt
- AS
- aspektet
- aspekter
- At
- oppmerksomhet
- augmented
- autonom
- autonome kjøretøyer
- tilgjengelighet
- tilgjengelig
- gjennomsnittlig
- AWS
- bakgrunn
- dårlig
- basen
- basert
- BE
- fordi
- være
- BEST
- beste praksis
- mellom
- Stor
- Store data
- Biggest
- flaskehals
- bygge
- utbyggere
- Bygning
- bygget
- virksomhet
- Forretnings kontinuitet
- men
- by
- ring
- ringer
- Samtaler
- CAN
- evner
- Kapasitet
- fangst
- fange
- saken
- saker
- utfordringer
- endring
- Endringer
- karakter
- chatte
- velge
- City
- tett
- samle
- Colorado
- sammenlignet
- fullføre
- komponenter
- Beregn
- datamaskin
- Datamaskin syn
- konferanser
- Tilkobling
- Vurder
- hensyn
- betraktninger
- kontekst
- sammenhenger
- kontekstuelle
- fortsetter
- kontinuitet
- kontrakt
- konvertere
- kunne
- Par
- dekke
- dekker
- prosessor
- kritisk
- CRM
- avgjørende
- kunde
- kundeopplevelse
- Kunder
- dato
- Dataledelse
- Database
- databaser
- definert
- avhengig
- beskrevet
- utforming
- utforme
- design
- detalj
- Utvikling
- DevOps
- diktert
- forskjellig
- vanskelig
- direkte
- katastrofe
- disipliner
- frakoblet
- diskutere
- diverse
- do
- dokumenter
- gjør
- ikke
- domener
- ikke
- hver enkelt
- enten
- embedding
- Emery
- Ingeniørarbeid
- sikre
- kom inn
- feil
- Eter (ETH)
- evaluere
- utvikling
- eksempel
- stige
- Kjøreglede
- eksisterende
- dyrt
- erfaring
- eksperiment
- utforske
- utvide
- utvendig
- eksternt
- ekstra
- Failure
- Egenskaper
- filet
- Finn
- fleksibilitet
- flyten
- Fokus
- fokuserer
- følge
- etter
- Til
- Formelt
- Fundament
- Rammeverk
- rammer
- fra
- funksjonelle
- funksjoner
- general
- generell
- generere
- generasjonen
- generative
- Generativ AI
- få
- GPU
- GPU
- veilede
- håndtere
- Håndtering
- Ha
- å ha
- he
- Held
- hjelpe
- hjelpe
- Høy
- svært
- hold
- holder
- vert
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- if
- viktig
- forbedre
- in
- inkluderer
- Inkludert
- Innkommende
- innlemme
- indikerer
- informasjon
- inngang
- f.eks
- forekomster
- i stedet
- Integrering
- samhandle
- interaksjoner
- interessant
- Interface
- forstyrre
- inn
- innebærer
- IT
- Journeys
- bare
- kunnskap
- Språk
- stor
- Ventetid
- Ledelse
- LÆRE
- læring
- Lens
- mindre
- Nivå
- i likhet med
- Begrenset
- begrense
- grenser
- llm
- laste
- lokalt
- logg
- logikk
- Se
- tap
- Lot
- maskin
- maskinlæring
- Hoved
- gjøre
- fikk til
- ledelse
- mange
- fyrstikker
- Saken
- moden
- Kan..
- MBA
- Møt
- Minne
- metoder
- Metrics
- Michigan
- microservices
- Middle
- ML
- MLOps
- modell
- modeller
- moduser
- Overvåke
- mer
- mye
- flere
- må
- innfødt
- fritt
- nødvendig
- Trenger
- nødvendig
- behov
- Ny
- New York
- New York City
- Nei.
- normal
- ingenting
- nå
- skyggelegging
- mange
- få
- of
- ofte
- on
- bare
- åpen
- åpen kildekode
- alternativer
- or
- organisasjons
- organisasjoner
- Annen
- ut
- produksjon
- enn
- samlet
- egen
- del
- Mønster
- mønstre
- Betale
- Ansatte
- utføre
- ytelse
- utfører
- bilde
- Pillar
- rørledning
- sentral
- fly
- planlegging
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- plugins
- stillinger
- Post
- praksis
- praksis
- Forbered
- presentert
- forebygge
- Principal
- prioritering
- prosessering
- Produkt
- produktledelse
- prosjekter
- ledetekster
- gi
- offentlig
- formål
- sette
- spørsmål
- fille
- RAM
- spenner
- raskt
- Sats
- heller
- utvinning
- referere
- referanse
- Uansett
- region
- regioner
- i slekt
- relevant
- pålitelighet
- pålitelig
- replikering
- Krav
- resiliens
- spenstig
- ressurs
- Ressurser
- svar
- begrense
- gjenfinning
- risikoer
- Rolle
- Kjør
- rennende
- går
- SaaS
- sagemaker
- samme
- sier
- scenarier
- Søk
- søker
- sikkerhet
- sikkerhetsrisiko
- senior
- tjeneste
- Tjenester
- flere
- skjæring
- hun
- felling
- bør
- Enkelt
- enkelt
- Størrelse
- ferdigheter
- So
- Software
- programvare som en tjeneste
- programvareutvikling
- software engineering
- løsning
- Solutions
- noen
- kilde
- Kilder
- Rom
- Snakker
- spesialist
- Stabilitet
- stabil
- stable
- Stabler
- Tilstand
- Still
- lagring
- oppbevare
- strategier
- Strategi
- strukturert
- slik
- støtte
- sikker
- system
- Systemer
- Ta
- tar
- taksonomi
- tech
- Teknisk
- teknikker
- Teknologi
- enn
- Det
- De
- Kilden
- deres
- Dem
- Der.
- Disse
- de
- tror
- denne
- De
- trusler
- tre
- Gjennom
- nivået
- tid
- til
- verktøy
- verktøy
- temaer
- spore
- Sporing
- tradisjonelle
- Kurs
- prøve
- to
- typen
- typer
- typisk
- typisk
- forståelse
- Uventet
- unik
- universitet
- University of Michigan
- ubegrenset
- uforutsigbare
- bruke
- brukt
- Bruker
- Brukererfaring
- Brukere
- ved hjelp av
- VALIDERE
- Verdifull
- variasjon
- Kjøretøy
- Se
- syn
- ønsker
- Vei..
- måter
- we
- web
- webtjenester
- VI VIL
- Hva
- når
- om
- hvilken
- vil
- med
- Dame
- kvinner i teknologi
- Arbeid
- arbeidet
- arbeid
- skriving
- york
- du
- Din
- zephyrnet