Bilde av redaktør
Nøkkelfunksjoner
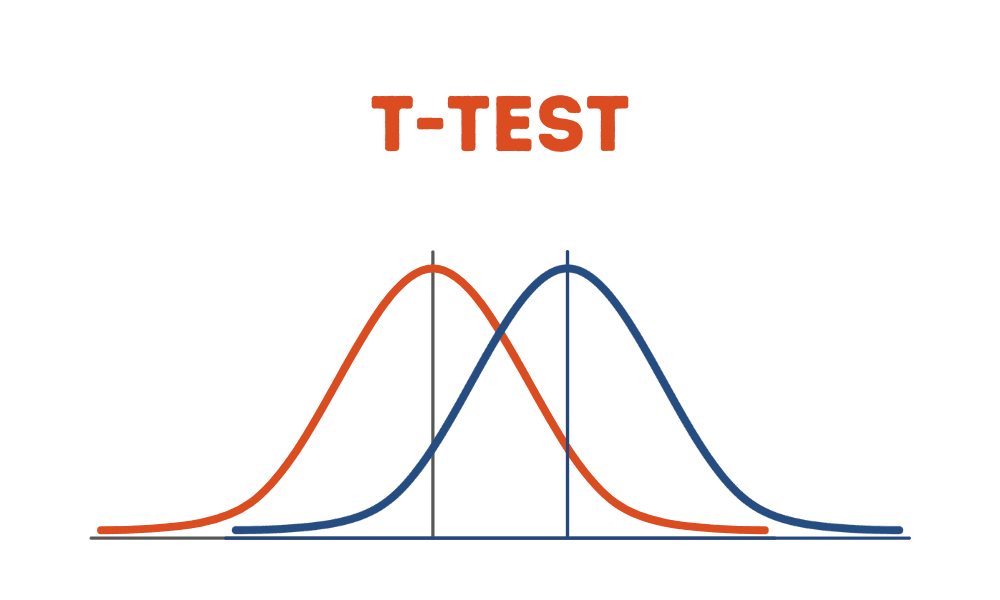
- T-testen er en statistisk test som kan brukes til å bestemme om det er en signifikant forskjell mellom middelverdiene til to uavhengige utvalg av data.
- Vi illustrerer hvordan en t-test kan brukes ved å bruke iris-datasettet og Pythons Scipy-bibliotek.
T-testen er en statistisk test som kan brukes til å bestemme om det er en signifikant forskjell mellom middelverdiene til to uavhengige utvalg av data. I denne opplæringen illustrerer vi den mest grunnleggende versjonen av t-testen, hvor vi vil anta at de to prøvene har like varianser. Andre avanserte versjoner av t-testen inkluderer Welchs t-test, som er en tilpasning av t-testen, og er mer pålitelig når de to prøvene har ulik varians og muligens ulik prøvestørrelse.
t-statistikken eller t-verdien beregnes som følger:
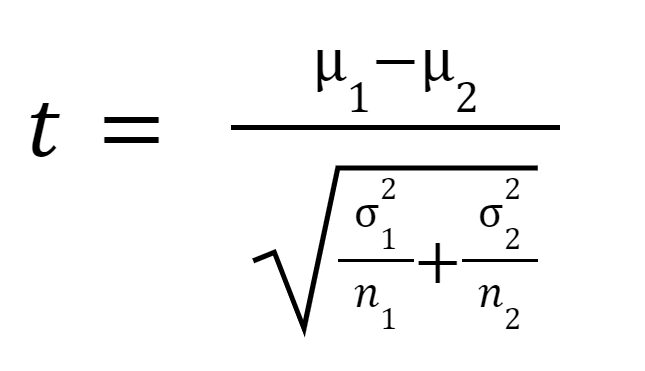
hvor
er gjennomsnittet av prøve 1,
er gjennomsnittet av prøve 2,
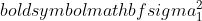 er variansen til prøve 1,
er variansen til prøve 1, 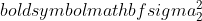 er variansen til prøve 2,
er variansen til prøve 2, 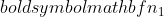 er prøvestørrelsen til prøve 1, og
er prøvestørrelsen til prøve 1, og 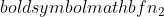 er prøvestørrelsen til prøve 2.
er prøvestørrelsen til prøve 2.
For å illustrere bruken av t-testen vil vi vise et enkelt eksempel ved bruk av iris-datasettet. Anta at vi observerer to uavhengige prøver, f.eks. blomsterbegerbladlengder, og vi vurderer om de to prøvene ble tatt fra samme populasjon (f.eks. samme blomsterart eller to arter med lignende begerbladkarakteristikker) eller to forskjellige populasjoner.
T-testen kvantifiserer forskjellen mellom de aritmetiske gjennomsnittene til de to prøvene. P-verdien kvantifiserer sannsynligheten for å oppnå de observerte resultatene, forutsatt at nullhypotesen (at prøvene er trukket fra populasjoner med samme populasjonsmiddelverdi) er sann. En p-verdi større enn en valgt terskel (f.eks. 5 % eller 0.05) indikerer at vår observasjon ikke er så usannsynlig at den har skjedd ved en tilfeldighet. Derfor aksepterer vi nullhypotesen om like populasjonsmidler. Hvis p-verdien er mindre enn terskelen vår, så har vi bevis mot nullhypotesen om like populasjonsmidler.
T-testinngang
Inndataene eller parameterne som er nødvendige for å utføre en t-test er:
- To matriser a og b som inneholder dataene for prøve 1 og prøve 2
T-test utganger
T-testen returnerer følgende:
- Den beregnede t-statistikken
- P-verdien
Importer nødvendige biblioteker
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Last inn Iris-datasett
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Beregn utvalgets gjennomsnitt og utvalgets varians
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Gjennomfør t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
Produksjon
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
Produksjon
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
Produksjon
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Observasjoner
Vi observerer at bruken av "true" eller "false" for parameteren "equal-var" ikke endrer t-testresultatene så mye. Vi observerer også at utveksling av rekkefølgen til prøvematrisene a_1 og b_1 gir en negativ t-testverdi, men endrer ikke størrelsen på t-testverdien, som forventet. Siden den beregnede p-verdien er mye større enn terskelverdien på 0.05, kan vi forkaste nullhypotesen om at forskjellen mellom gjennomsnittet av prøve 1 og prøve 2 er signifikant. Dette viser at begerbladlengdene for prøve 1 og prøve 2 ble trukket fra samme populasjonsdata.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Beregn utvalgets gjennomsnitt og utvalgets varians
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Gjennomfør t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
Produksjon
stats.ttest_ind(a_1, b_1, equal_var = False)Observasjoner
Vi observerer at bruk av prøver med ulik størrelse ikke endrer t-statistikken og p-verdien signifikant.
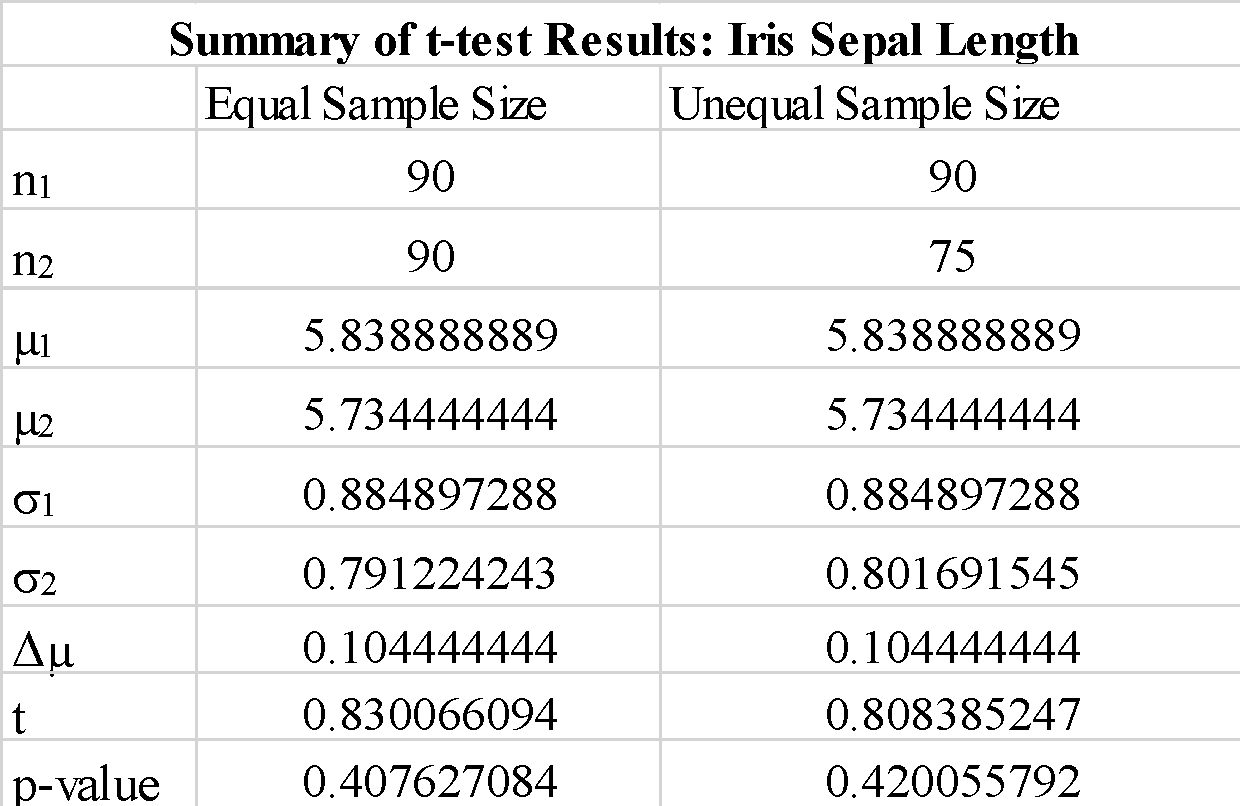
Oppsummert har vi vist hvordan en enkel t-test kan implementeres ved å bruke scipy-biblioteket i python.
Benjamin O. Tayo er fysiker, datavitenskapspedagog og forfatter, samt eier av DataScienceHub. Tidligere underviste Benjamin i ingeniørfag og fysikk ved U. of Central Oklahoma, Grand Canyon U., og Pittsburgh State U.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Aksepterer
- avansert
- mot
- og
- anvendt
- grunnleggende
- Benjamin
- mellom
- beregnet
- sentral
- sjanse
- endring
- egenskaper
- valgt ut
- vurderer
- kunne
- dato
- datavitenskap
- datasett
- Bestem
- forskjell
- forskjellig
- trukket
- Ingeniørarbeid
- bevis
- eksempel
- forventet
- blomst
- etter
- følger
- fra
- Hvordan
- HTTPS
- implementert
- importere
- in
- inkludere
- uavhengig
- indikerer
- KDnuggets
- større
- Bibliotek
- matplotlib
- midler
- mer
- mest
- nødvendig
- negativ
- følelsesløs
- observere
- å skaffe seg
- forekom
- Oklahoma
- rekkefølge
- Annen
- eieren
- parameter
- parametere
- utfører
- Fysikk
- Pittsburgh
- plato
- Platon Data Intelligence
- PlatonData
- befolkningen
- populasjoner
- tidligere
- sannsynlighet
- Python
- pålitelig
- Resultater
- avkastning
- samme
- Vitenskap
- Vis
- vist
- Viser
- signifikant
- betydelig
- lignende
- Enkelt
- siden
- Størrelse
- størrelser
- mindre
- So
- Tilstand
- statistisk
- stats
- SAMMENDRAG
- Undervisning
- test
- De
- derfor
- terskel
- til
- sant
- tutorial
- bruke
- verdi
- versjon
- om
- hvilken
- vil
- forfatter
- rentene
- zephyrnet