Hvor ofte oppnår maskinlæringsprosjekter vellykket implementering? Ikke ofte nok. Det er rikelig of industri forskning viser at ML-prosjekter vanligvis ikke gir avkastning, men dyrebare få har målt forholdet mellom fiasko og suksess fra dataforskernes perspektiv – folkene som utvikler selve modellene disse prosjektene er ment å distribuere.
Oppfølging en dataforskerundersøkelse som jeg dirigerte med KDnuggets i fjor, årets bransjeledende Data Science Survey drevet av ML-konsulentfirmaet Rexer Analytics tok opp spørsmålet – delvis fordi Karl Rexer, selskapets grunnlegger og president, lot dere virkelig delta, noe som førte til inkluderingen av spørsmål om implementeringssuksess (en del av arbeidet mitt under et ettårig analytisk professorat jeg hadde ved UVA Darden).
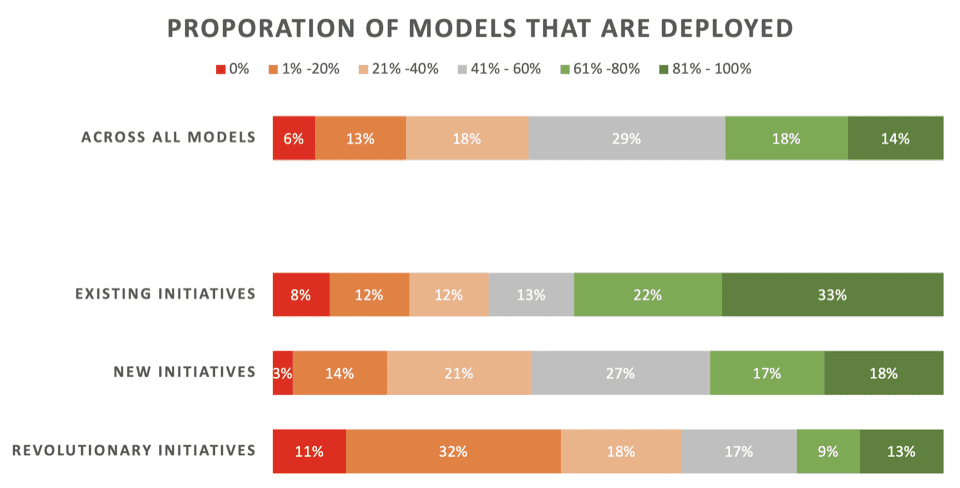
Nyhetene er ikke gode. Bare 22 % av dataforskerne sier at deres "revolusjonerende" initiativer – modeller utviklet for å muliggjøre en ny prosess eller kapasitet – vanligvis implementeres. 43 % sier at 80 % eller mer mislykkes i å distribuere.
På tvers alle typer ML-prosjekter – inkludert forfriskende modeller for eksisterende distribusjoner – bare 32 % sier at modellene deres vanligvis distribueres.
Her er de detaljerte resultatene av den delen av undersøkelsen, presentert av Rexer Analytics, som deler opp distribusjonshastigheter på tvers av tre typer ML-initiativer:
Nøkkel:
- Eksisterende initiativ: Modeller utviklet for å oppdatere/oppdatere en eksisterende modell som allerede er implementert
- Nye initiativ: Modeller utviklet for å forbedre en eksisterende prosess som ingen modell allerede var utplassert for
- Revolusjonære initiativ: Modeller utviklet for å muliggjøre en ny prosess eller evne
Etter mitt syn stammer denne kampen for å distribuere fra to viktigste medvirkende faktorer: endemisk underplanlegging og forretningsinteressenter som mangler konkret synlighet. Mange datafagfolk og bedriftsledere har ikke innsett at MLs tiltenkte operasjonalisering må planlegges i detalj og forfølges aggressivt fra starten av hvert ML-prosjekt.
Faktisk har jeg skrevet en ny bok om nettopp det: The AI Playbook: Mastering the Rare Art of Machine Learning Deployment. I denne boken introduserer jeg en distribusjonsfokusert, seks-trinns praksis for å innlede maskinlæringsprosjekter fra unnfangelse til utplassering som jeg kaller bizML (forhåndsbestill innbundet eller e-bok og motta en gratis avansert kopi av lydbokversjonen med en gang).
Et ML-prosjekts nøkkelinteressenter – personen som er ansvarlig for den operasjonelle effektiviteten målrettet for forbedring, for eksempel en linje-of-business manager – trenger innsyn i nøyaktig hvordan ML vil forbedre sin drift og hvor mye verdi forbedringen forventes å gi. De trenger dette for til syvende og sist å gi grønt lys for en modells utrulling, så vel som for å, før det, veie inn i prosjektets utførelse gjennom pre-distribusjonsstadiene.
Men MLs ytelse blir ofte ikke målt! Da Rexer-undersøkelsen spurte: "Hvor ofte måler din bedrift/organisasjon ytelsen til analytiske prosjekter?" bare 48 % av dataforskerne sa «Alltid» eller «Mesteparten av tiden». Det er ganske vilt. Det burde være mer som 99% eller 100%.
Og når ytelse måles, er det i form av tekniske beregninger som er mystiske og for det meste irrelevante for forretningsinteressenter. Dataforskere vet bedre, men følger vanligvis ikke – delvis siden ML-verktøy vanligvis bare tjener tekniske beregninger. I følge undersøkelsen rangerer dataforskere forretnings-KPIer som avkastning og inntekter som de viktigste beregningene, men de lister opp tekniske beregninger som løft og AUC som de som oftest måles.
Tekniske ytelsesmålinger er "fundamentalt ubrukelige for og frakoblet virksomhetens interessenter," ifølge Harvard Data Science Review. Her er grunnen: De forteller deg bare slektning ytelsen til en modell, for eksempel hvordan den sammenlignes med gjetting eller en annen grunnlinje. Forretningsmålinger forteller deg absolutte forretningsverdi modellen forventes å levere – eller, ved evaluering etter implementering, at den har vist seg å levere. Slike beregninger er avgjørende for distribusjonsfokuserte ML-prosjekter.
Utover tilgang til forretningsberegninger, må bedriftens interessenter også øke. Da Rexer-undersøkelsen spurte: "Er lederne og beslutningstakerne i organisasjonen din som må godkjenne modelldistribusjon generelt kunnskapsrike nok til å ta slike beslutninger på en velinformert måte?" bare 49 % av respondentene svarte «Mesteparten av tiden» eller «Alltid».
Her er det jeg tror skjer. Dataforskerens "klient", forretningsinteressenten, får ofte kalde føtter når det kommer ned til å godkjenne distribusjon, siden det ville bety en betydelig operasjonell endring av selskapets brød og smør, dets største prosesser. De har ikke det kontekstuelle rammeverket. For eksempel lurer de på: "Hvordan skal jeg forstå hvor mye denne modellen, som yter langt sjenert for krystallkule-perfeksjon, faktisk vil hjelpe?" Dermed dør prosjektet. Så, kreativt sett en slags positiv spinn på "innsikten oppnådd" tjener til å feie feilen under teppet. AI-hypen forblir intakt selv om den potensielle verdien, formålet med prosjektet, går tapt.
Om dette emnet – for å øke interessentene – skal jeg koble til min nye bok, AI Playbook, bare en gang til. Samtidig som den dekker bizML-praksisen, oppgraderer boken også forretningsfolk ved å levere en viktig, men vennlig dose semi-teknisk bakgrunnskunnskap som alle interessenter trenger for å lede eller delta i maskinlæringsprosjekter, fra ende til annen. Dette setter forretnings- og datafagfolk på samme side slik at de kan samarbeide dypt og i fellesskap etablere nøyaktig hva maskinlæring er bedt om å forutsi, hvor godt det forutsier, og hvordan dets spådommer blir fulgt opp for å forbedre driften. Disse grunnleggende tingene utgjør eller bryter hvert initiativ – å få dem riktig baner vei for maskinlærings verdidrevne distribusjon.
Det er trygt å si at det er steinete der ute, spesielt for nye, første forsøk ML-initiativer. Ettersom selve kraften til AI-hypen mister evnen til kontinuerlig å gjøre opp for
mindre realisert verdi enn lovet, vil det bli mer og mer press for å bevise MLs operasjonelle verdi.? Så jeg sier, kom deg i forkant av dette nå – begynn å skape en mer effektiv kultur for samarbeid på tvers av bedrifter og distribusjonsorientert prosjektledelse!
For mer detaljerte resultater fra 2023 Rexer Analytics Data Science Surveyklikk her.. Dette er den største undersøkelsen blant fagfolk innen datavitenskap og analyse i bransjen. Den består av omtrent 35 flervalgsspørsmål og åpne spørsmål som dekker mye mer enn bare suksessrater for distribusjon – syv generelle områder innen data mining vitenskap og praksis: (1) Felt og mål, (2) Algoritmer, (3) Modeller, ( 4) Verktøy (programvarepakker brukt), (5) Teknologi, (6) Utfordringer og (7) Fremtid. Det utføres som en tjeneste (uten bedriftssponsing) til datavitenskapsmiljøet, og resultatene kunngjøres vanligvis kl. konferansen Machine Learning Week og delt via fritt tilgjengelige sammendragsrapporter.
Denne artikkelen er et produkt av forfatterens arbeid mens han hadde en ettårig stilling som Bodily Bicentennial Professor in Analytics ved UVA Darden School of Business, som til slutt kulminerte med publiseringen av The AI Playbook: Mastering the Rare Art of Machine Learning Deployment (gratis lydboktilbud).
Eric Siegel, Ph.D., er en ledende konsulent og tidligere professor ved Columbia University som gjør maskinlæring forståelig og fengslende. Han er grunnleggeren av Prediktiv Analytics World og Deep Learning World konferanseserier, som har tjent mer enn 17,000 2009 deltakere siden XNUMX, instruktøren for det anerkjente kurset Maskinlæringsledelse og -praksis – ende-til-ende mestring, en populær foredragsholder som er bestilt for 100+ hovedtaler, og sjefredaktør for Maskinlæringstider. Han forfattet bestselgeren Prediktiv analyse: Kraften til å forutsi hvem som vil klikke, kjøpe, lyve eller dø, som har blitt brukt på kurs på mer enn 35 universiteter, og han vant undervisningspriser da han var professor ved Columbia University, hvor han sang pedagogiske sanger til studentene sine. Eric publiserer også meninger om analyse og sosial rettferdighet. Følg ham kl @predikanalytisk.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- : har
- :er
- :ikke
- :hvor
- $OPP
- 000
- 1
- 17
- 35%
- 7
- a
- evne
- Om oss
- adgang
- roste
- Ifølge
- tvers
- faktisk
- adressert
- avansert
- Etter
- aggressivt
- fremover
- AI
- algoritmer
- Alle
- tillatt
- allerede
- også
- alltid
- am
- an
- analytisk
- analytics
- og
- annonsert
- En annen
- godkjenne
- ca
- Arcane
- ER
- områder
- Kunst
- Artikkel
- AS
- At
- deltakere
- wow
- forfattet
- tilgjengelig
- premieringer
- borte
- bakgrunn
- Baseline
- BE
- fordi
- vært
- før du
- tro
- bestselger
- Bedre
- bok
- Brød
- Break
- Breaking
- virksomhet
- Bedriftsledere
- men
- kjøpe
- by
- ring
- som heter
- CAN
- evne
- fengslende
- utfordringer
- endring
- kostnad
- valg
- klikk
- kunde
- forkjølelse
- samarbeide
- samarbeid
- Columbia
- COM
- Kom
- kommer
- vanligvis
- samfunnet
- Selskapet
- Selskapets
- unnfangelse
- betong
- gjennomført
- Konferanse
- består
- konsulent
- konsulent
- kontekstuelle
- kontinuerlig
- medvirkende
- Bedriftens
- kurs
- kurs
- dekke
- dekker
- Kreativt
- cs
- Kultur
- dato
- data mining
- datavitenskap
- dataforsker
- beslutningstakere
- avgjørelser
- dypt
- leverer
- levere
- utplassere
- utplassert
- distribusjon
- distribusjoner
- detalj
- detaljert
- utvikle
- utviklet
- frakoblet
- do
- gjør
- Don
- ikke
- dose
- ned
- kjøring
- under
- hver enkelt
- redaktør
- Effektiv
- effektivitet
- muliggjøre
- slutt
- ende til ende
- endemisk
- forbedre
- nok
- eric
- spesielt
- avgjørende
- Nedbør
- etablere
- Eter (ETH)
- evaluere
- Selv
- Hver
- eksempel
- gjennomføring
- utøvende
- eksisterende
- forventet
- Faktisk
- faktorer
- FAIL
- Failure
- langt
- Feet
- Noen få
- felt
- følge
- Til
- Tving
- Tidligere
- Grunnleggeren
- Rammeverk
- Gratis
- fritt
- vennlig
- fra
- framtid
- fikk
- general
- generelt
- få
- få
- Mål
- flott
- Skjer
- Ha
- he
- Held
- hjelpe
- ham
- hans
- Hvordan
- HTML
- http
- HTTPS
- Hype
- i
- IBM
- viktig
- forbedre
- forbedring
- in
- begynnelse
- Inkludert
- inkludering
- industri
- bransjeledende
- Initiative
- initiativer
- innsikt
- tiltenkt
- inn
- introdusere
- er n
- IT
- DET ER
- bare
- bare én
- karl
- KDnuggets
- nøkkel
- Keynote
- Type
- Vet
- kunnskap
- mangler
- største
- Siste
- I fjor
- føre
- ledere
- Ledelse
- ledende
- læring
- løgn
- i likhet med
- Liste
- ll
- taper
- tapte
- maskin
- maskinlæring
- Hoved
- gjøre
- GJØR AT
- Making
- leder
- Ledere
- måte
- mange
- Maste
- bety
- ment
- måle
- målte
- Metrics
- Gruvedrift
- MIT
- ML
- modell
- modeller
- mer
- mest
- for det meste
- mye
- flere
- må
- my
- Trenger
- behov
- Ny
- nyheter
- Nei.
- nå
- of
- ofte
- on
- ONE
- seg
- bare
- operasjonell
- Drift
- or
- rekkefølge
- organisasjon
- ut
- pakker
- side
- del
- delta
- Paves
- perfeksjon
- ytelse
- utfører
- person
- perspektiv
- planlagt
- plato
- Platon Data Intelligence
- PlatonData
- støpsel
- Populær
- posisjon
- positiv
- potensiell
- makt
- praksis
- pre-order
- Dyrebar
- nettopp
- forutsi
- Spådommer
- spår
- presentert
- president
- press
- pen
- prosess
- Prosesser
- Produkt
- fagfolk
- Professor
- prosjekt
- prosjekter
- lovet
- Bevis
- utprøvd
- Utgivelse
- utgir
- formål
- setter
- Sette
- spørsmål
- spørsmål
- Rampe
- ramping
- rangerer
- SJELDEN
- priser
- ratio
- å nå
- realisert
- gjenkjenne
- forblir
- Rapporter
- respondentene
- Resultater
- avkastning
- inntekter
- revolusjonær
- ikke sant
- steinete
- ROI
- rutinemessig
- Kjør
- s
- trygge
- Sa
- samme
- sier
- Skala
- Skole
- Vitenskap
- Forsker
- forskere
- Serien
- betjene
- servert
- serverer
- tjeneste
- syv
- delt
- signifikant
- siden
- So
- selskap
- Software
- noen
- Høyttaler
- Snurre rundt
- sponsoravtale
- stadier
- interessent
- interessenter
- Begynn
- stammer
- Still
- Struggle
- Studenter
- suksess
- vellykket
- vellykket
- slik
- SAMMENDRAG
- Survey /Inspeksjonsfartøy
- Sweep
- T
- målrettet
- Undervisning
- Teknisk
- Teknologi
- fortelle
- vilkår
- enn
- Det
- De
- deres
- Dem
- deretter
- Der.
- Disse
- de
- denne
- tre
- hele
- Dermed
- tid
- til
- verktøy
- Tema
- virkelig
- to
- Til syvende og sist
- etter
- forstå
- forståelig
- universiteter
- universitet
- upon
- brukt
- innvarsling
- vanligvis
- verdi
- Ve
- veldig
- av
- Se
- synlighet
- vital
- var
- Vei..
- uke
- veie
- VI VIL
- Hva
- når
- hvilken
- mens
- HVEM
- hvorfor
- Wild
- vil
- med
- uten
- Vant
- lurer
- Arbeid
- ville
- skrevet
- år
- ennå
- du
- Din
- zephyrnet