på Første del av denne tredelte serien, presenterte vi en løsning som demonstrerer hvordan du kan automatisere oppdagelse av dokumentmanipulering og svindel i stor skala ved å bruke AWS AI og maskinlæringstjenester (ML) for en boliglånsgaranti.
I dette innlegget presenterer vi en tilnærming for å utvikle en dyp læringsbasert datasynsmodell for å oppdage og fremheve forfalskede bilder i boliglånsforsikring. Vi gir veiledning om å bygge, trene og distribuere dyplæringsnettverk på Amazon SageMaker.
I del 3 viser vi hvordan du implementerer løsningen på Amazon-svindeldetektor.
Løsningsoversikt
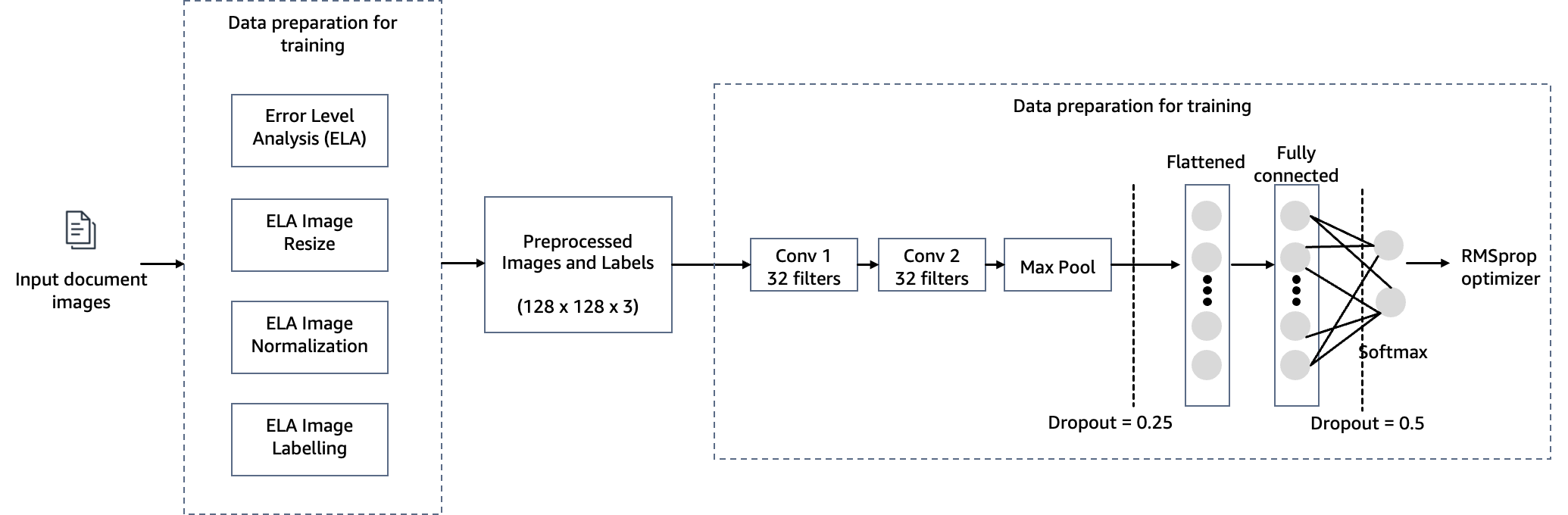
For å imøtekomme målet om å oppdage dokumenttukling i boliglånsgarantien, bruker vi en datasynsmodell som ligger hos SageMaker for vår løsning for oppdagelse av bildeforfalskning. Denne modellen mottar et testbilde som input og genererer en sannsynlighetsprediksjon av forfalskning som utdata. Nettverksarkitekturen er som vist i følgende diagram.
Bildeforfalskning involverer hovedsakelig fire teknikker: skjøting, kopiering-flytting, fjerning og forbedring. Avhengig av egenskapene til forfalskningen, kan ulike ledetråder brukes som grunnlag for deteksjon og lokalisering. Disse ledetrådene inkluderer JPEG-komprimeringsartefakter, kantinkonsekvenser, støymønstre, fargekonsistens, visuell likhet, EXIF-konsistens og kameramodell.
Gitt det vidstrakte området for gjenkjenning av bildeforfalskning, bruker vi algoritmen Error Level Analysis (ELA) som en illustrativ metode for å oppdage forfalskninger. Vi valgte ELA-teknikken for dette innlegget av følgende grunner:
- Det er raskere å implementere og kan enkelt fange opp manipulering av bilder.
- Det fungerer ved å analysere komprimeringsnivåene til forskjellige deler av et bilde. Dette gjør det mulig å oppdage inkonsekvenser som kan indikere manipulering - for eksempel hvis ett område ble kopiert og limt inn fra et annet bilde som hadde blitt lagret på et annet komprimeringsnivå.
- Den er god til å oppdage mer subtil eller sømløs tukling som kan være vanskelig å oppdage med det blotte øye. Selv små endringer i et bilde kan introdusere påvisbare kompresjonsavvik.
- Den er ikke avhengig av å ha det originale umodifiserte bildet for sammenligning. ELA kan identifisere manipulasjonstegn bare i selve bildet. Andre teknikker krever ofte den umodifiserte originalen å sammenligne med.
- Det er en lettvektsteknikk som kun er avhengig av å analysere kompresjonsartefakter i de digitale bildedataene. Det er ikke avhengig av spesialisert maskinvare eller rettsmedisinsk ekspertise. Dette gjør ELA tilgjengelig som et førstegangsanalyseverktøy.
- Utdata-ELA-bildet kan tydelig fremheve forskjeller i komprimeringsnivåer, noe som gjør manipulerte områder synlige. Dette gjør at selv en ikke-ekspert kan gjenkjenne tegn på mulig manipulasjon.
- Det fungerer på mange bildetyper (som JPEG, PNG og GIF) og krever bare selve bildet for å analysere. Andre rettsmedisinske teknikker kan være mer begrenset i formater eller krav til originalbilde.
I virkelige scenarier der du kan ha en kombinasjon av inndatadokumenter (JPEG, PNG, GIF, TIFF, PDF), anbefaler vi imidlertid å bruke ELA sammen med forskjellige andre metoder, som f.eks. oppdage inkonsistens i kanter, støymønstre, ensartet farge, EXIF-datakonsistens, identifikasjon av kameramodellog ensartet skrift. Vi tar sikte på å oppdatere koden for dette innlegget med ytterligere forfalskningsdeteksjonsteknikker.
ELAs underliggende forutsetning forutsetter at inngangsbildene er i JPEG-format, kjent for sin tapsgivende komprimering. Likevel kan metoden fortsatt være effektiv selv om inndatabildene opprinnelig var i et tapsfritt format (som PNG, GIF eller BMP) og senere konvertert til JPEG under manipuleringsprosessen. Når ELA brukes på originale tapsfrie formater, indikerer det vanligvis konsistent bildekvalitet uten noen forringelse, noe som gjør det vanskelig å finne endrede områder. I JPEG-bilder er den forventede normen at hele bildet har lignende komprimeringsnivåer. Men hvis en bestemt seksjon i bildet viser et markant annet feilnivå, tyder det ofte på at en digital endring er gjort.
ELA fremhever forskjeller i JPEG-komprimeringshastigheten. Regioner med jevn farge vil sannsynligvis ha et lavere ELA-resultat (for eksempel en mørkere farge sammenlignet med høykontrastkanter). Tingene du bør se etter for å identifisere tukling eller modifikasjon inkluderer følgende:
- Lignende kanter bør ha lignende lysstyrke i ELA-resultatet. Alle kanter med høy kontrast skal ligne hverandre, og alle kanter med lav kontrast skal se like ut. Med et originalt bilde bør kanter med lav kontrast være nesten like lyse som kanter med høy kontrast.
- Lignende teksturer bør ha lignende farge under ELA. Områder med flere overflatedetaljer, for eksempel et nærbilde av en basketball, vil sannsynligvis ha et høyere ELA-resultat enn en jevn overflate.
- Uavhengig av faktisk farge på overflaten, bør alle flate overflater ha omtrent samme farge under ELA.
JPEG-bilder bruker et komprimeringssystem med tap. Hver omkoding (gjenlagring) av bildet gir mer kvalitetstap til bildet. Nærmere bestemt opererer JPEG-algoritmen på et rutenett på 8×8 piksler. Hver 8×8 firkant komprimeres uavhengig. Hvis bildet er fullstendig umodifisert, bør alle 8×8 ruter ha lignende feilpotensialer. Hvis bildet er umodifisert og lagret på nytt, bør hver rute forringes med omtrent samme hastighet.
ELA lagrer bildet på et spesifisert JPEG-kvalitetsnivå. Denne gjenlagringen introduserer en kjent mengde feil over hele bildet. Det gjenlagrede bildet sammenlignes deretter med originalbildet. Hvis et bilde er modifisert, bør hver 8×8-rute som ble berørt av modifikasjonen ha et høyere feilpotensial enn resten av bildet.
Resultatene fra ELA er direkte avhengig av bildekvaliteten. Det kan være lurt å vite om noe ble lagt til, men hvis bildet kopieres flere ganger, kan det hende at ELA bare tillater å oppdage gjenlagringene. Prøv å finne den beste kvalitetsversjonen av bildet.
Med opplæring og øvelse kan ELA også lære å identifisere bildeskalering, kvalitet, beskjæring og gjenlagring av transformasjoner. For eksempel, hvis et ikke-JPEG-bilde inneholder synlige rutenettlinjer (1 piksel bred i 8×8 ruter), betyr det at bildet startet som en JPEG og ble konvertert til ikke-JPEG-format (som PNG). Hvis noen områder av bildet mangler rutenett eller rutenettlinjene skifter, betyr det en skjøt eller tegnet del i ikke-JPEG-bildet.
I de følgende delene viser vi trinnene for konfigurering, opplæring og distribusjon av datamaskinsynsmodellen.
Forutsetninger
For å følge med på dette innlegget, fullfør følgende forutsetninger:
- Har en AWS-konto.
- Sett opp Amazon SageMaker Studio. Du kan raskt starte SageMaker Studio ved å bruke standard forhåndsinnstillinger, noe som muliggjør en rask lansering. For mer informasjon, se Amazon SageMaker forenkler Amazon SageMaker Studio-oppsettet for individuelle brukere.
- Åpne SageMaker Studio og start en systemterminal.
- Kjør følgende kommando i terminalen:
git clone https://github.com/aws-samples/document-tampering-detection.git - Den totale kostnaden for å kjøre SageMaker Studio for én bruker og konfigurasjonene av notebookmiljøet er $7.314 USD per time.
Sett opp modelltreningsnotisboken
Fullfør følgende trinn for å konfigurere treningsnotatboken:
- Åpne
tampering_detection_training.ipynbfil fra katalogen for dokumentmanipulering-deteksjon. - Sett opp notebookmiljøet med bildet TensorFlow 2.6 Python 3.8 CPU eller GPU Optimized.
Du kan få problemer med utilstrekkelig tilgjengelighet eller treffe kvotegrensen for GPU-forekomster i AWS-kontoen din når du velger GPU-optimaliserte forekomster. For å øke kvoten, gå til Service Quotas-konsollen og øke tjenestegrensen for den spesifikke forekomsttypen du trenger. Du kan også bruke et CPU-optimalisert bærbart miljø i slike tilfeller. - Til Kernel, velg Python3.
- Til Forekomsttype, velg ml.m5d.24xlarge eller andre store forekomster.
Vi valgte en større instanstype for å redusere treningstiden til modellen. Med et ml.m5d.24xlarge notebookmiljø er kostnaden per time $7.258 USD per time.
Kjør treningsnotisboken
Kjør hver celle i notatboken tampering_detection_training.ipynb i rekkefølge. Vi diskuterer noen celler mer detaljert i de følgende avsnittene.
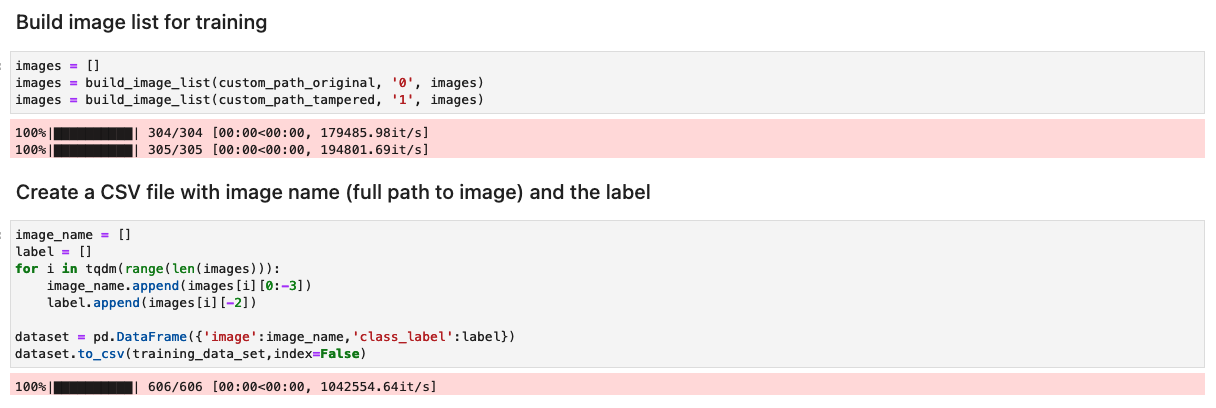
Forbered datasettet med en liste over originale og manipulerte bilder
Før du kjører følgende celle i notatboken, klargjør du et datasett med originale og manipulerte dokumenter basert på dine spesifikke forretningskrav. For dette innlegget bruker vi et eksempeldatasett med tuklet lønnsslipper og kontoutskrifter. Datasettet er tilgjengelig i bildekatalogen til GitHub repository.

Notatboken leser de originale og manipulerte bildene fra images/training katalogen.
Datasettet for opplæring lages ved hjelp av en CSV-fil med to kolonner: banen til bildefilen og etiketten for bildet (0 for originalbildet og 1 for manipulert bilde).
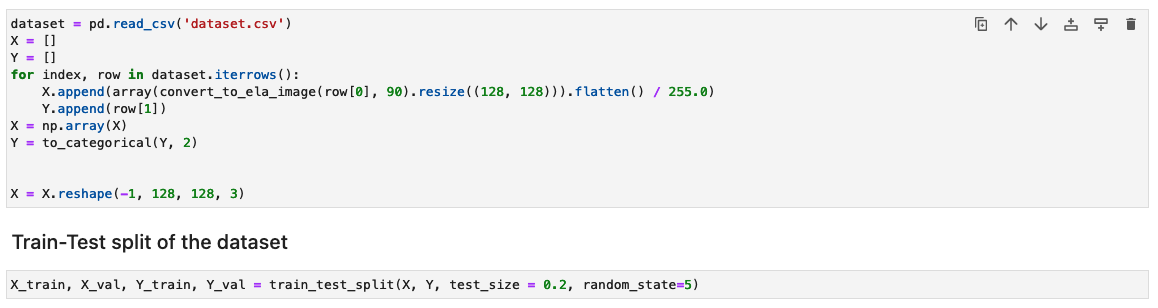
Behandle datasettet ved å generere ELA-resultatene for hvert treningsbilde
I dette trinnet genererer vi ELA-resultatet (med 90 % kvalitet) av inndatatreningsbildet. Funksjonen convert_to_ela_image tar to parametere: bane, som er banen til en bildefil, og kvalitet, som representerer kvalitetsparameteren for JPEG-komprimering. Funksjonen utfører følgende trinn:
- Konverter bildet til RGB-format og lagre bildet på nytt som en JPEG-fil med den angitte kvaliteten under navnet tempresaved.jpg.
- Beregn forskjellen mellom originalbildet og det gjenlagrede JPEG-bildet (ELA) for å bestemme den maksimale forskjellen i pikselverdier mellom de originale og lagrede bildene.
- Beregn en skaleringsfaktor basert på maksimal forskjell for å justere lysstyrken til ELA-bildet.
- Forbedre lysstyrken til ELA-bildet ved å bruke den beregnede skaleringsfaktoren.
- Endre størrelsen på ELA-resultatet til 128x128x3, der 3 representerer antall kanaler for å redusere inngangsstørrelsen for trening.
- Returner ELA-bildet.
I bildeformater med tap som JPEG, fører den første lagringsprosessen til betydelig fargetap. Men når bildet lastes inn og deretter omkodes i det samme tapsformatet, er det generelt mindre ekstra fargeforringelse. ELA-resultater understreker bildeområdene som er mest utsatt for fargedegradering ved gjenlagring. Vanligvis vises endringer fremtredende i områder som viser høyere potensial for nedbrytning sammenlignet med resten av bildet.
Deretter behandles bildene til en NumPy-array for trening. Vi deler deretter inndatasettet tilfeldig i trenings- og test- eller valideringsdata (80/20). Du kan ignorere eventuelle advarsler når du kjører disse cellene.
Avhengig av størrelsen på datasettet, kan det ta tid å kjøre disse cellene. For eksempeldatasettet vi ga i dette depotet, kan det ta 5–10 minutter.
Konfigurer CNN-modellen
I dette trinnet konstruerer vi en minimal versjon av VGG-nettverket med små konvolusjonsfiltre. VGG-16 består av 13 konvolusjonslag og tre fullt sammenkoblede lag. Følgende skjermbilde illustrerer arkitekturen til vår Convolutional Neural Network (CNN)-modell.
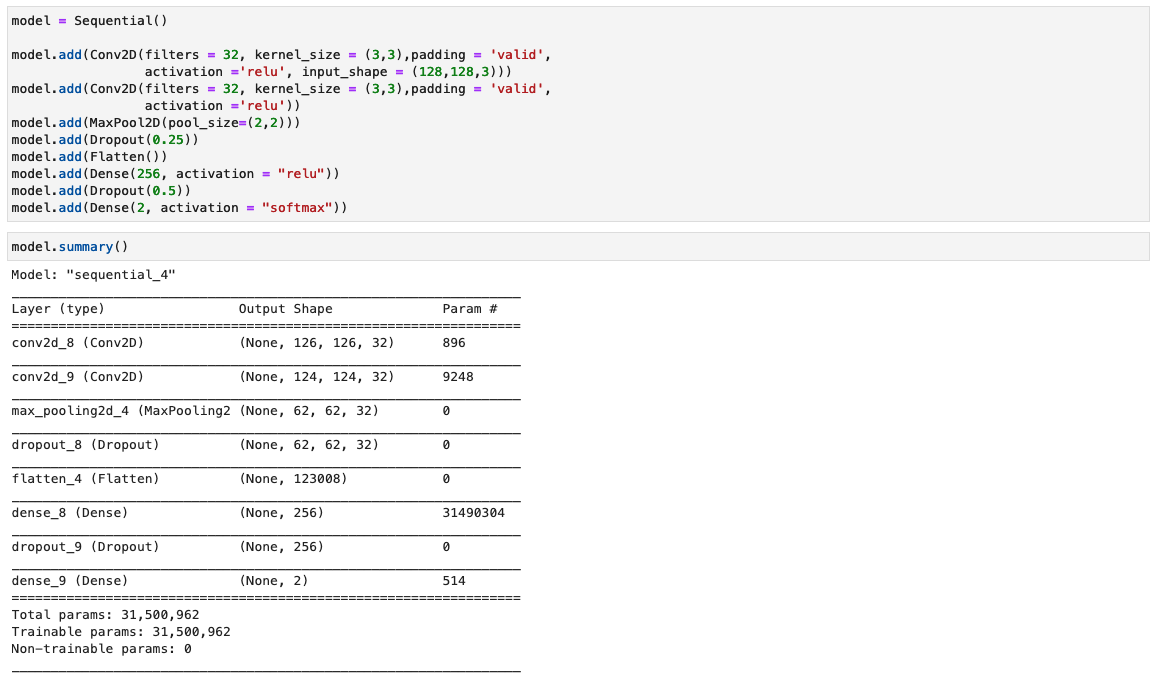
Legg merke til følgende konfigurasjoner:
- Input – Modellen tar inn en bildestørrelse på 128x128x3.
- Konvolusjonslag – Konvolusjonslagene bruker et minimalt mottakelig felt (3×3), den minste mulige størrelsen som fortsatt fanger opp/ned og venstre/høyre. Dette etterfølges av en utrettet lineær enhet (ReLU) aktiveringsfunksjon som reduserer treningstiden. Dette er en lineær funksjon som vil sende ut inngangen hvis den er positiv; ellers er utgangen null. Konvolusjonsskrittet er fastsatt som standard (1 piksel) for å beholde den romlige oppløsningen etter konvolusjon (skritt er antall pikselskift over inngangsmatrisen).
- Fullt tilkoblede lag – Nettverket har to fullt sammenkoblede lag. Det første tette laget bruker ReLU-aktivering, og det andre bruker softmax for å klassifisere bildet som originalt eller manipulert.
Du kan ignorere eventuelle advarsler når du kjører disse cellene.
Lagre modellartefakter
Lagre den trente modellen med et unikt filnavn – for eksempel basert på gjeldende dato og klokkeslett – i en katalog kalt modell.

Modellen lagres i Keras-format med utvidelsen .keras. Vi lagrer også modellartefaktene som en katalog kalt 1 som inneholder serialiserte signaturer og tilstanden som trengs for å kjøre dem, inkludert variable verdier og vokabularer for å distribuere til en SageMaker-runtime (som vi diskuterer senere i dette innlegget).
Mål modellens ytelse
Følgende tapskurve viser progresjonen av modellens tap over treningsepoker (iterasjoner).
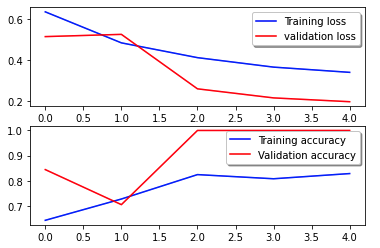
Tapsfunksjonen måler hvor godt modellens spådommer samsvarer med de faktiske målene. Lavere verdier indikerer bedre justering mellom spådommer og sanne verdier. Avtagende tap over epoker betyr at modellen er i forbedring. Nøyaktighetskurven illustrerer modellens nøyaktighet over treningsepoker. Nøyaktighet er forholdet mellom riktige spådommer og det totale antallet spådommer. Høyere nøyaktighet indikerer en modell som gir bedre resultater. Vanligvis øker nøyaktigheten under trening ettersom modellen lærer mønstre og forbedrer sin prediksjonsevne. Disse vil hjelpe deg å finne ut om modellen er overtilpasset (yter bra på treningsdata, men dårlig på usett data) eller undertilpasser (lærer ikke nok av treningsdataene).
Følgende forvirringsmatrise viser visuelt hvor godt modellen nøyaktig skiller mellom de positive (smidde bildet, representert som verdi 1) og negative (uforfalsket bilde, representert som verdi 0) klassene.
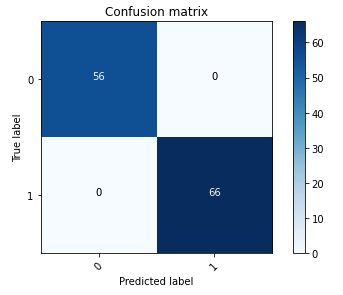
Etter modellopplæringen innebærer neste trinn å distribuere datamaskinsynsmodellen som et API. Denne API-en vil bli integrert i forretningsapplikasjoner som en komponent i underwritingsarbeidsflyten. For å oppnå dette bruker vi Amazon SageMaker Inference, en fullstendig administrert tjeneste. Denne tjenesten integreres sømløst med MLOps-verktøy, noe som muliggjør skalerbar modelldistribusjon, kostnadseffektiv slutning, forbedret modellstyring i produksjon og redusert operasjonell kompleksitet. I dette innlegget distribuerer vi modellen som et endepunkt for sanntidsslutning. Det er imidlertid viktig å merke seg at, avhengig av arbeidsflyten til forretningsapplikasjonene dine, kan modellimplementeringen også skreddersys som batchbehandling, asynkron håndtering eller gjennom en serverløs distribusjonsarkitektur.
Sett opp modelldistribusjonsnotisboken
Fullfør følgende trinn for å konfigurere din modelldistribusjonsnotisbok:
- Åpne
tampering_detection_model_deploy.ipynbfil fra katalogen for dokumentmanipulering-deteksjon. - Sett opp notatbokmiljøet med bildet Data Science 3.0.
- Til Kernel, velg Python3.
- Til Forekomsttype, velg mlt3 medium.
Med et ml.t3.medium notebook-miljø er kostnaden per time $0.056 USD.
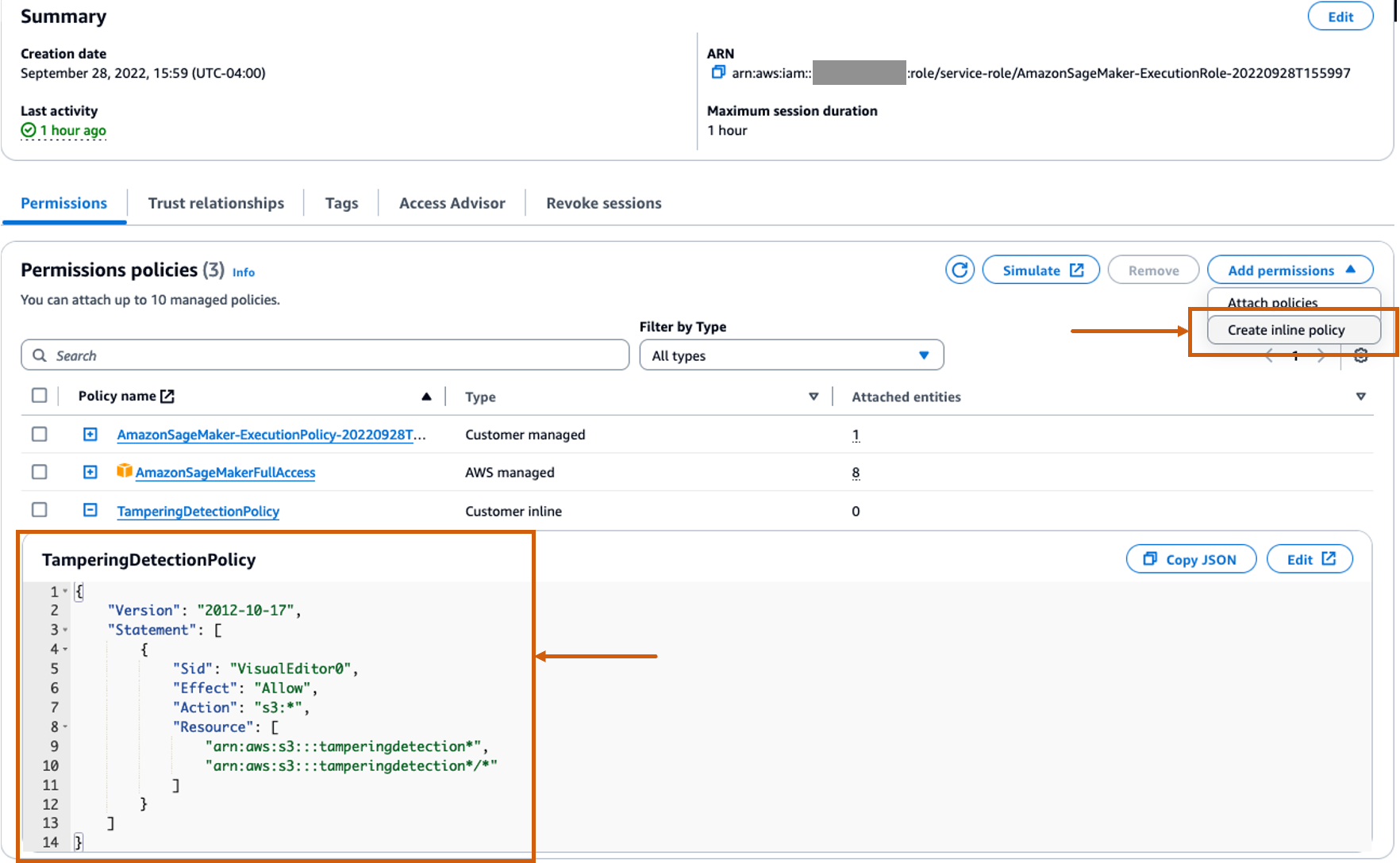
Lag en egendefinert innebygd policy for SageMaker-rollen for å tillate alle Amazon S3-handlinger
De AWS identitets- og tilgangsadministrasjon (IAM) rolle for SageMaker vil være i formatet AmazonSageMaker- ExecutionRole-<random numbers>. Sørg for at du bruker riktig rolle. Rollenavnet finner du under brukerdetaljene i SageMaker-domenekonfigurasjonene.

Oppdater IAM-rollen for å inkludere en innebygd policy for å tillate alle Amazon enkel lagringstjeneste (Amazon S3) handlinger. Dette vil være nødvendig for å automatisere oppretting og sletting av S3-bøtter som vil lagre modellartefakter. Du kan begrense tilgangen til spesifikke S3-bøtter. Merk at vi brukte et jokertegn for S3-bøttenavnet i IAM-policyen (tamperingdetection*).
Kjør distribusjonsnotatboken
Kjør hver celle i notatboken tampering_detection_model_deploy.ipynb i rekkefølge. Vi diskuterer noen celler mer detaljert i de følgende avsnittene.
Lag en S3-bøtte
Kjør cellen for å lage en S3-bøtte. Bøtten vil få navn tamperingdetection<current date time> og i samme AWS-region som ditt SageMaker Studio-miljø.

Lag modellartefaktarkivet og last opp til Amazon S3
Lag en tar.gz-fil fra modellartefakter. Vi har lagret modellartefaktene som en katalog kalt 1, som inneholder serialiserte signaturer og tilstanden som trengs for å kjøre dem, inkludert variable verdier og vokabularer for å distribuere til SageMaker runtime. Du kan også inkludere en egendefinert slutningsfil kalt inference.py i kodemappen i modellartefakten. Den tilpassede slutningen kan brukes til forbehandling og etterbehandling av inndatabildet.
![]()
Opprett et SageMaker-slutningsendepunkt
Cellen for å lage et SageMaker-slutningsendepunkt kan ta noen minutter å fullføre.
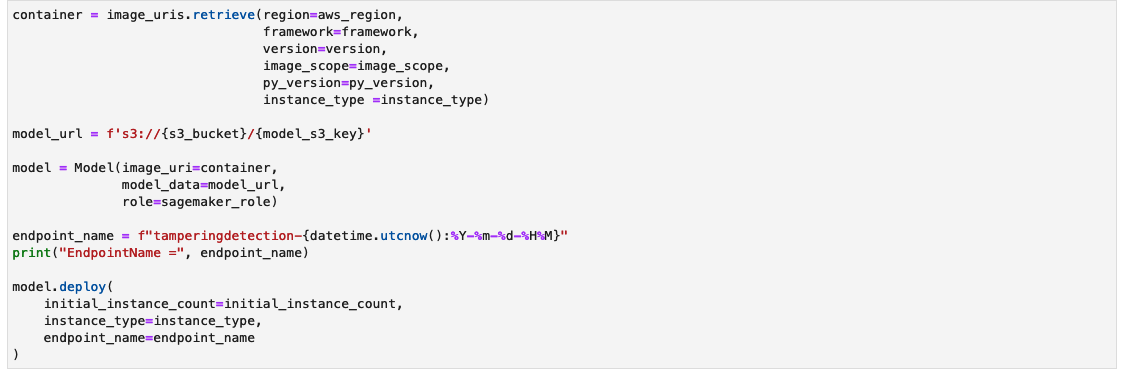
Test slutningsendepunktet
Funksjonen check_image forhåndsbehandler et bilde som et ELA-bilde, sender det til et SageMaker-endepunkt for slutning, henter og behandler modellens spådommer og skriver ut resultatene. Modellen tar en NumPy-array av inngangsbildet som et ELA-bilde for å gi spådommer. Spådommene sendes ut som 0, som representerer et umanipulert bilde, og 1, som representerer et forfalsket bilde.

La oss påkalle modellen med et umanipulert bilde av en betalingsslipp og sjekke resultatet.

Modellen gir ut klassifiseringen som 0, som representerer et umanipulert bilde.
La oss nå påkalle modellen med et manipulert bilde av en betalingsslipp og sjekke resultatet.

Modellen gir ut klassifiseringen som 1, som representerer et forfalsket bilde.
Begrensninger
Selv om ELA er et utmerket verktøy for å hjelpe med å oppdage modifikasjoner, er det en rekke begrensninger, for eksempel følgende:
- En enkelt pikselendring eller mindre fargejustering vil kanskje ikke generere en merkbar endring i ELA fordi JPEG opererer på et rutenett.
- ELA identifiserer bare hvilke regioner som har forskjellige komprimeringsnivåer. Hvis et bilde av lavere kvalitet spleises til et bilde av høyere kvalitet, kan bildet av lavere kvalitet vises som et mørkere område.
- Skalering, nyfarging eller tilføyelse av støy til et bilde vil endre hele bildet, og skape et høyere feilnivåpotensial.
- Hvis et bilde lagres på nytt flere ganger, kan det være helt på et minimumsfeilnivå, der flere gjenlagringer ikke endrer bildet. I dette tilfellet vil ELA returnere et svart bilde og ingen modifikasjoner kan identifiseres ved hjelp av denne algoritmen.
- Med Photoshop kan den enkle handlingen å lagre bildet automatisk gjøre teksturer og kanter skarpere, og skape et høyere feilnivåpotensial. Denne artefakten identifiserer ikke tilsiktet modifikasjon; den identifiserer at et Adobe-produkt ble brukt. Teknisk sett fremstår ELA som en modifikasjon fordi Adobe automatisk utførte en modifikasjon, men modifikasjonen var ikke nødvendigvis tilsiktet av brukeren.
Vi anbefaler å bruke ELA sammen med andre teknikker som tidligere er omtalt i bloggen for å oppdage et større utvalg av bildemanipulasjonstilfeller. ELA kan også tjene som et uavhengig verktøy for visuelt å undersøke bildeforskjeller, spesielt når trening av en CNN-basert modell blir utfordrende.
Rydd opp
For å fjerne ressursene du opprettet som en del av denne løsningen, fullfør følgende trinn:
- Kjør notatbokcellene under Opprydding seksjon. Dette vil slette følgende:
- SageMaker slutningspunkt – Inferensendepunktets navn vil være
tamperingdetection-<datetime>. - Gjenstander i S3-bøtten og selve S3-bøtten – Bøttenavnet blir
tamperingdetection<datetime>.
- SageMaker slutningspunkt – Inferensendepunktets navn vil være
- Slå SageMaker Studios bærbare ressurser.
konklusjonen
I dette innlegget presenterte vi en ende-til-ende-løsning for å oppdage dokumenttukling og svindel ved hjelp av dyp læring og SageMaker. Vi brukte ELA til å forhåndsbehandle bilder og identifisere avvik i komprimeringsnivåer som kan indikere manipulasjon. Deretter trente vi en CNN-modell på dette bearbeidede datasettet for å klassifisere bilder som originale eller manipulerte.
Modellen kan oppnå sterk ytelse, med en nøyaktighet på over 95 % med et datasett (smidd og original) som er egnet for bedriftens krav. Dette indikerer at den pålitelig kan oppdage forfalskede dokumenter som lønnsslipper og kontoutskrifter. Den trente modellen er distribuert til et SageMaker-endepunkt for å muliggjøre inferens med lav latens i skala. Ved å integrere denne løsningen i arbeidsflyter for boliglån, kan institusjoner automatisk flagge mistenkelige dokumenter for videre etterforskning av svindel.
Selv om det er kraftig, har ELA noen begrensninger når det gjelder å identifisere visse typer mer subtil manipulasjon. Som neste trinn kan modellen forbedres ved å inkludere ytterligere rettsmedisinske teknikker i opplæring og ved å bruke større, mer varierte datasett. Totalt sett viser denne løsningen hvordan du kan bruke dyp læring og AWS-tjenester til å bygge effektive løsninger som øker effektiviteten, reduserer risiko og forhindrer svindel.
I del 3 viser vi hvordan du implementerer løsningen på Amazon Fraud Detector.
Om forfatterne
 Anup Ravindranath er Senior Solutions Architect hos Amazon Web Services (AWS) med base i Toronto, Canada og jobber med Financial Services-organisasjoner. Han hjelper kunder med å transformere virksomhetene sine og innovere på skyen.
Anup Ravindranath er Senior Solutions Architect hos Amazon Web Services (AWS) med base i Toronto, Canada og jobber med Financial Services-organisasjoner. Han hjelper kunder med å transformere virksomhetene sine og innovere på skyen.
 Vinnie Saini er Senior Solutions Architect hos Amazon Web Services (AWS) med base i Toronto, Canada. Hun har hjulpet Financial Services-kunder med å transformere seg på skyen, med AI- og ML-drevne løsninger lagt på sterke grunnpilarer for Architectural Excellence.
Vinnie Saini er Senior Solutions Architect hos Amazon Web Services (AWS) med base i Toronto, Canada. Hun har hjulpet Financial Services-kunder med å transformere seg på skyen, med AI- og ML-drevne løsninger lagt på sterke grunnpilarer for Architectural Excellence.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 056
- 1
- 100
- 13
- 195
- 258
- 408
- 75
- 8
- 95%
- a
- evne
- Om oss
- adgang
- tilgjengelig
- Logg inn
- nøyaktighet
- nøyaktig
- Oppnå
- tvers
- Handling
- handlinger
- Aktivering
- faktiske
- la til
- legge
- Ytterligere
- Legger
- justere
- Justering
- Adobe
- Etter
- mot
- AI
- sikte
- algoritme
- innretting
- Alle
- tillate
- tillater
- nesten
- langs
- sammen
- også
- endret
- Amazon
- Amazon-svindeldetektor
- Amazon SageMaker
- Amazon SageMaker Studio
- Amazon Web Services
- Amazon Web Services (AWS)
- beløp
- an
- analyse
- analysere
- analyserer
- og
- En annen
- noen
- api
- vises
- vises
- søknader
- anvendt
- tilnærming
- ca
- arkitektonisk
- arkitektur
- Arkiv
- ER
- AREA
- områder
- Array
- AS
- antar
- At
- automatisere
- automatisk
- tilgjengelighet
- tilgjengelig
- AWS
- Bank
- basert
- basketball
- BE
- fordi
- blir
- vært
- BEST
- Bedre
- mellom
- Svart
- Blogg
- øke
- Bright
- bygge
- Bygning
- virksomhet
- Business Applications
- bedrifter
- men
- by
- beregnet
- som heter
- rom
- CAN
- Canada
- fanger
- saken
- saker
- Catch
- celle
- Celler
- viss
- utfordrende
- endring
- Endringer
- kanaler
- egenskaper
- sjekk
- Velg
- klasser
- klassifisering
- Klassifisere
- klart
- Cloud
- CNN
- kode
- farge
- kolonner
- kombinasjon
- sammenligne
- sammenlignet
- sammenligning
- fullføre
- helt
- kompleksitet
- komponent
- datamaskin
- Datamaskin syn
- konfigurering
- forvirring
- sammen
- tilkoblet
- betydelig
- konsistent
- består
- Konsoll
- konstruere
- inneholder
- konvertere
- konvertert
- convolutional nevralt nettverk
- korrigere
- Kostnad
- kunne
- prosessor
- skape
- opprettet
- Opprette
- skaperverket
- Gjeldende
- skjøger
- skikk
- Kunder
- mørkere
- dato
- datavitenskap
- datasett
- Dato
- avtagende
- dyp
- dyp læring
- Misligholde
- demonstrere
- demonstrerer
- betegner
- tett
- avhenge
- avhengig
- avhengig
- utplassere
- utplassert
- utplasserings
- distribusjon
- detalj
- detaljer
- oppdage
- Gjenkjenning
- Bestem
- utvikle
- diagram
- forskjell
- forskjeller
- forskjellig
- digitalt
- direkte
- diskutere
- diskutert
- skjermer
- Skiller
- diverse
- do
- dokument
- dokumenter
- ikke
- domene
- trukket
- drevet
- under
- hver enkelt
- lett
- Edge
- Effektiv
- effektivitet
- understreke
- ansette
- muliggjøre
- muliggjør
- ende til ende
- Endpoint
- forbedret
- ekstrautstyr
- nok
- Hele
- fullstendig
- Miljø
- epoker
- feil
- feil
- spesielt
- Eter (ETH)
- Selv
- Hver
- undersøke
- eksempel
- Excellence
- utmerket
- viser
- utviser
- ekspansiv
- forventet
- ekspertise
- forlengelse
- øye
- tilrettelegging
- faktor
- Noen få
- felt
- filet
- filtre
- finansiell
- finansielle tjenester
- Finn
- Først
- fikset
- flate
- følge
- fulgt
- etter
- Til
- Rettsmedisinsk
- etterforskning
- smidd
- format
- funnet
- Fundament
- grunn
- fire
- svindel
- fra
- fullt
- funksjon
- videre
- generelt
- generere
- genererer
- genererer
- gif
- gå
- god
- GPU
- større
- Grid
- veiledning
- HAD
- Håndtering
- Hard
- maskinvare
- Ha
- å ha
- he
- hjelpe
- hjelpe
- hjelper
- høyere
- Uthev
- striper
- hit
- vert
- vert
- time
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- IAM
- identifisert
- identifiserer
- identifisere
- identifisering
- Identitet
- IEEE
- if
- ignorere
- illustrerer
- bilde
- bilder
- innflytelsesrik
- iverksette
- viktig
- forbedrer
- bedre
- in
- inkludere
- Inkludert
- uoverensstemmelser
- innlemme
- Øke
- øker
- uavhengig
- uavhengig av hverandre
- indikerer
- indikerer
- individuelt
- informasjon
- innledende
- initiere
- innovere
- inngang
- f.eks
- forekomster
- institusjoner
- integrert
- Integrerer
- Integrering
- Tilsiktet
- inn
- introdusere
- Introduserer
- etterforskning
- innebærer
- utstedelse
- IT
- gjentakelser
- DET ER
- selv
- jpg
- Hold
- hard
- Vet
- kjent
- Etiketten
- maling
- stor
- større
- seinere
- lansere
- lag
- lag
- Fører
- LÆRE
- læring
- mindre
- Nivå
- nivåer
- lettvekt
- i likhet med
- sannsynligheten
- Sannsynlig
- BEGRENSE
- begrensninger
- lineær
- linjer
- Liste
- Lokalisering
- Se
- tap
- lavere
- maskin
- maskinlæring
- laget
- hovedsakelig
- gjøre
- GJØR AT
- Making
- fikk til
- ledelse
- Manipulasjon
- mange
- Match
- Matrix
- maksimal
- Kan..
- midler
- målinger
- medium
- Møt
- metode
- metoder
- minimal
- minimum
- mindre
- minutter
- ML
- MLOps
- modell
- modifikasjoner
- modifisert
- modifisere
- mer
- Boliglån
- mest
- flere
- navn
- oppkalt
- nødvendigvis
- Trenger
- nødvendig
- negativ
- nettverk
- nettverk
- neural
- nevrale nettverket
- likevel
- neste
- Nei.
- Bråk
- note
- bærbare
- Antall
- følelsesløs
- Målet
- Åpenbare
- of
- ofte
- on
- ONE
- bare
- opererer
- operasjonell
- optimalisert
- or
- rekkefølge
- organisasjoner
- original
- opprinnelig
- Annen
- ellers
- vår
- utfall
- produksjon
- utganger
- enn
- samlet
- parameter
- parametere
- del
- Spesielt
- deler
- banen
- mønstre
- for
- ytelse
- utført
- utfører
- utfører
- bilde
- photoshop
- bilde
- søyler
- pixel
- plato
- Platon Data Intelligence
- PlatonData
- plott
- politikk
- del
- positiv
- mulig
- Post
- potensiell
- potensialer
- kraftig
- praksis
- prediksjon
- Spådommer
- prediktiv
- Forbered
- forutsetninger
- presentere
- presentert
- bevart
- forebygge
- tidligere
- utskrifter
- prosess
- behandlet
- Prosesser
- prosessering
- Produkt
- Produksjon
- progresjon
- gi
- forutsatt
- Python
- kvalitet
- avhørt
- raskere
- tilfeldig
- område
- rask
- Sats
- ratio
- virkelige verden
- sanntids
- riket
- grunner
- mottar
- gjenkjenne
- anbefaler
- utbedret
- redusere
- Redusert
- reduserer
- referere
- region
- regioner
- gjenopptakelse
- avhengige
- fjerning
- fjerne
- gjengivelse
- Repository
- representert
- representerer
- representerer
- krever
- påkrevd
- Krav
- Krever
- oppløsning
- Ressurser
- REST
- begrenset
- resultere
- Resultater
- retur
- RGB
- Risiko
- Rolle
- Kjør
- rennende
- sagemaker
- SageMaker Inference
- samme
- Eksempel på datasett
- Spar
- lagret
- besparende
- skalerbar
- Skala
- skalering
- scenarier
- Vitenskap
- sømløs
- sømløst
- Sekund
- Seksjon
- seksjoner
- valgt
- velge
- sender
- senior
- Serien
- betjene
- server~~POS=TRUNC
- tjeneste
- Tjenester
- sett
- oppsett
- hun
- skift
- Skift
- bør
- Viser
- signaturer
- betyr
- Skilt
- lignende
- Enkelt
- forenkler
- enkelt
- Størrelse
- liten
- glatter
- løsning
- Solutions
- noen
- noe
- romlig
- spesialisert
- spesifikk
- spesielt
- spesifisert
- splittet
- Spot
- kvadrat
- firkanter
- startet
- Tilstand
- uttalelser
- Trinn
- Steps
- Still
- lagring
- oppbevare
- skrittlengde
- sterk
- studio
- I ettertid
- slik
- foreslår
- sikker
- overflaten
- utsatt
- mistenkelig
- raskt
- system
- skreddersydd
- Ta
- tar
- mål
- teknisk sett
- teknikk
- teknikker
- tensorflow
- terminal
- test
- Testing
- enn
- Det
- De
- Staten
- deres
- Dem
- deretter
- Der.
- Disse
- ting
- denne
- tre
- Gjennom
- tid
- ganger
- til
- verktøy
- verktøy
- toronto
- Totalt
- berørt
- Tog
- trent
- Kurs
- Transform
- transformasjoner
- sant
- prøve
- to
- typen
- typer
- typisk
- etter
- underliggende
- writing
- unik
- enhet
- Oppdater
- upon
- USD
- bruke
- bruk sak
- brukt
- Bruker
- bruker
- ved hjelp av
- validering
- verdi
- Verdier
- variabel
- ulike
- versjon
- synlig
- syn
- Besøk
- visuell
- visuelt
- ønsker
- var
- we
- web
- webtjenester
- VI VIL
- var
- Hva
- når
- hvilken
- bred
- vil
- med
- innenfor
- uten
- arbeidsflyt
- arbeidsflyt
- arbeid
- virker
- du
- Din
- zephyrnet
- null