I den moderne verden er de fleste bedrifter avhengige av kraften til big data og analyser for å drive vekst, strategiske investeringer og kundeengasjement. Big data er den underliggende konstanten i den målrettede reklamen, personlig tilpasset markedsføring, produktanbefalinger, generering av innsikt, prisoptimalisering, sentimentanalyse, prediktiv analyse og mye mer.
Data samles ofte inn fra flere kilder, transformeres, lagres og behandles på datainnsjøer on-prem eller on-cloud. Mens det første inntaket av data er relativt trivielt og kan oppnås gjennom tilpassede skript utviklet internt eller tradisjonelle ETL (Extract Transform Load)-verktøy, blir problemet raskt uoverkommelig komplekst og dyrt å løse ettersom selskapene må:
- Administrer hele datalivssyklusen – for husholdnings- og overholdelsesformål
- Optimaliser lagring – for å redusere tilknyttede kostnader
- Forenkle arkitektur – gjennom gjenbruk av datainfrastruktur
- Behandle data trinnvis – gjennom kraftig statlig styring
- Bruk de samme retningslinjene på batch- og strømdata – uten dobbeltarbeid
- Migrer mellom On-prem og Cloud – med minst mulig innsats
Det er hvor Apache Gobblin, et åpen kildekode-databehandlings- og integreringssystem kommer inn. Apache Gobblin gir enestående muligheter som kan brukes helt eller delvis avhengig av virksomhetens behov.
I denne delen vil vi fordype oss i de ulike egenskapene til Apache Gobblin som hjelper til med å takle utfordringene som er skissert tidligere.
Administrere full datalivssyklus
Apache Gobblin tilbyr en rekke muligheter for å konstruere datapipelines som støtter hele pakken av datalivssyklusoperasjoner på datasett.
- Ta inn data – fra flere kilder til synker, alt fra databaser, Rest API-er, FTP/SFTP-servere, Filers, CRM-er som Salesforce og Dynamics, og mer.
- Repliker data – mellom flere datainnsjøer med spesialiserte muligheter for Hadoop Distribuert filsystem via Distcp-NG.
- Rens data – ved å bruke oppbevaringspolicyer som tidsbasert, nyeste K, versjonert eller en kombinasjon av policyer.
Gobblins logiske pipeline består av en 'Kilde' som bestemmer fordelingen av arbeid og skaper 'Workunits'. Disse 'Workunits' blir deretter plukket opp for utførelse som 'Tasks', som inkluderer utvinning, konvertering, kvalitetskontroll og skriving av data til destinasjonen. Det siste trinnet, 'Data Publish', validerer den vellykkede utførelsen av rørledningen og atomisk forplikter utdataene, hvis destinasjonen støtter det.
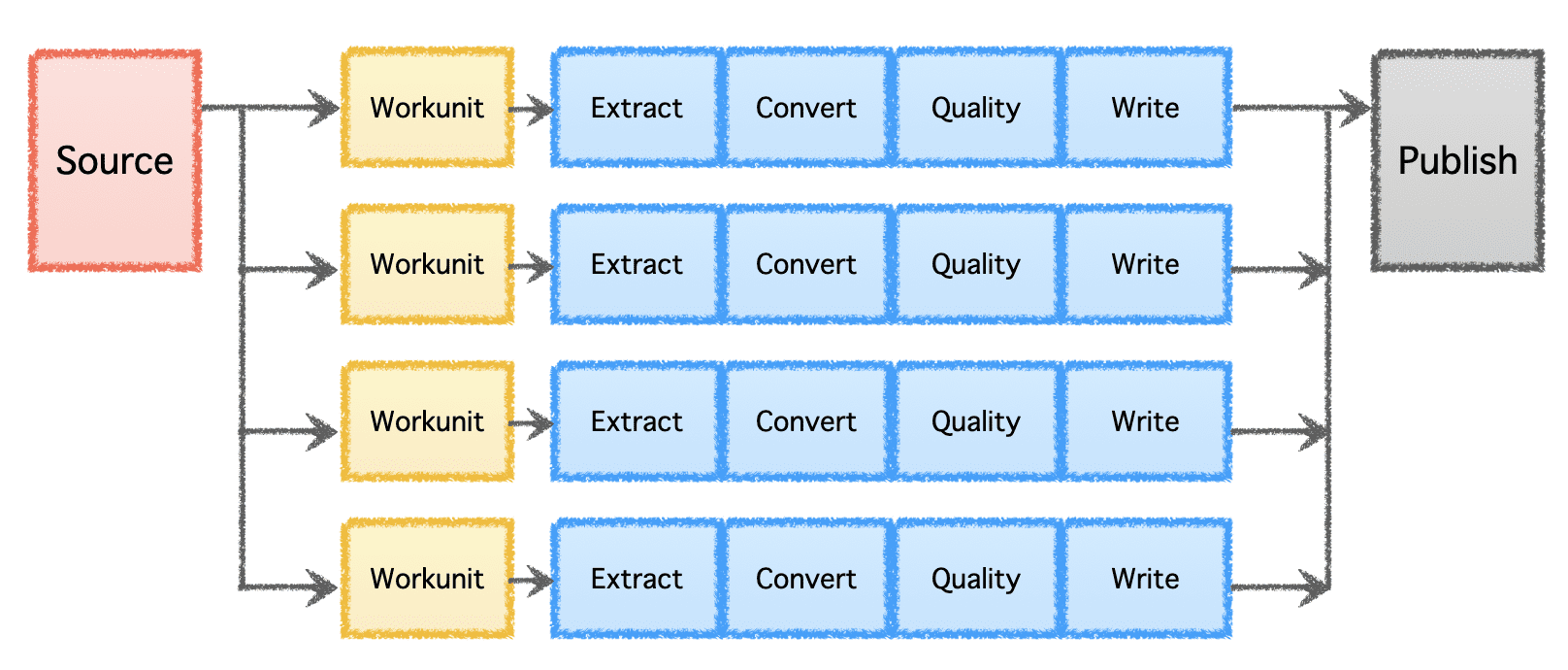
Bilde av forfatter
Optimaliser lagring
Apache Gobblin kan bidra til å redusere mengden lagring som trengs for data gjennom etterbehandling av data etter inntak eller replikering gjennom komprimering eller formatkonvertering.
- Komprimering – etterbehandling av data for å deduplisere basert på alle feltene eller nøkkelfeltene i postene, trimming av dataene for å beholde bare én post med det siste tidsstempelet med samme nøkkel.
- Avro til ORC – som en spesialisert formatkonverteringsmekanisme for å konvertere det populære radbaserte Avro-formatet til et hyperoptimalisert kolonnebasert ORC-format.
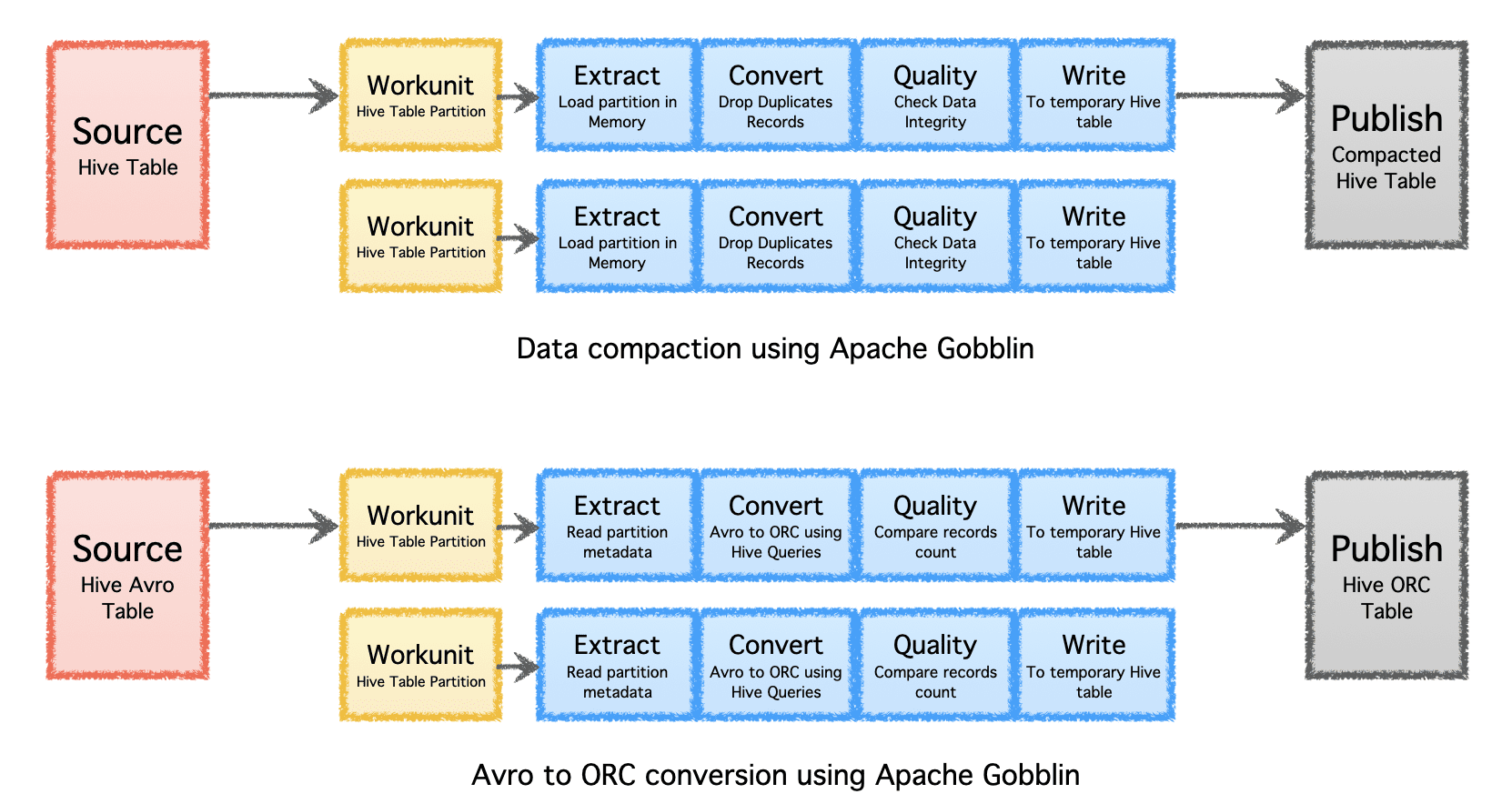
Bilde av forfatter
Forenkle arkitekturen
Avhengig av bedriftens stadium (oppstart til bedrift), skalakrav og deres respektive arkitektur, foretrekker bedrifter å sette opp eller utvikle datainfrastrukturen. Apache Gobblin er veldig fleksibel og støtter flere utførelsesmodeller.
- Frittstående modus – å kjøre som en frittstående prosess på en bar metallboks, dvs. en enkelt vert for enkle brukstilfeller og lite krevende situasjoner.
- MapReduce-modus – for å kjøre som en MapReduce-jobb på Hadoop-infrastruktur for big data-saker for å håndtere datasett i Petabytes-skala.
- Klyngemodus: Frittstående – for å kjøre som en klynge støttet av Apache Helix og Apache Zookeeper på et sett med bare metallmaskiner eller verter for å håndtere storskala uavhengig av Hadoop MR-rammeverket.
- Cluster Mode: Yarn – for å kjøre som en klynge på native Yarn uten Hadoop MR-rammeverket.
- Cluster Mode: AWS – å kjøre som en klynge på Amazons offentlige skytilbud, dvs. AWS for infrastrukturer som er vert på AWS.
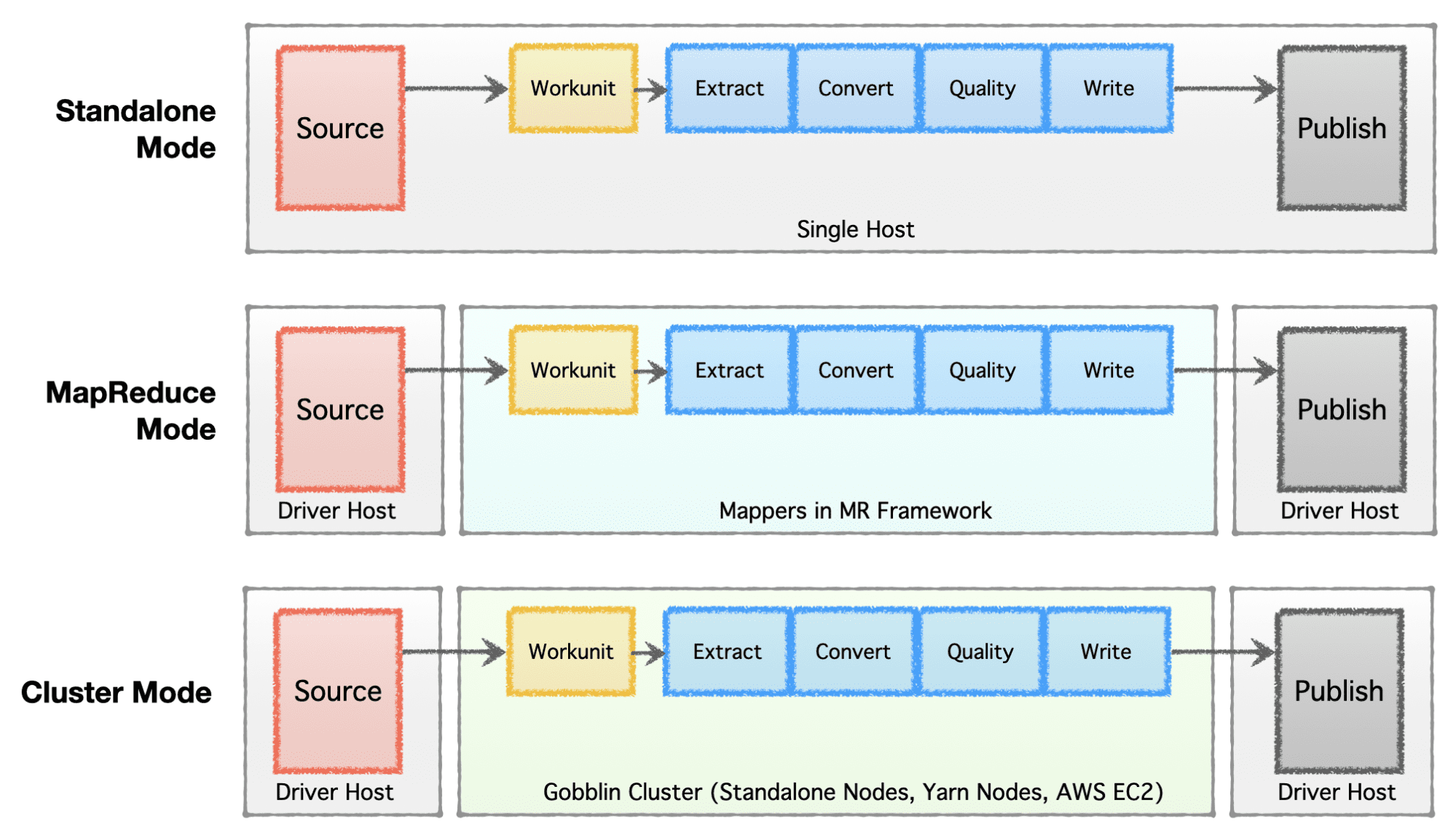
Bilde av forfatter
Behandle data trinnvis
I en betydelig skala med flere datapipelines og høyt volum, må data behandles i batcher og over tid. Derfor er det nødvendig med sjekkpunkter slik at datarørledningene kan fortsette fra der de slapp sist og fortsette videre. Apache Gobblin støtter lave og høye vannmerker og støtter robust semantikk for tilstandsadministrasjon via State Store på HDFS, AWS S3, MySQL og mer transparent.
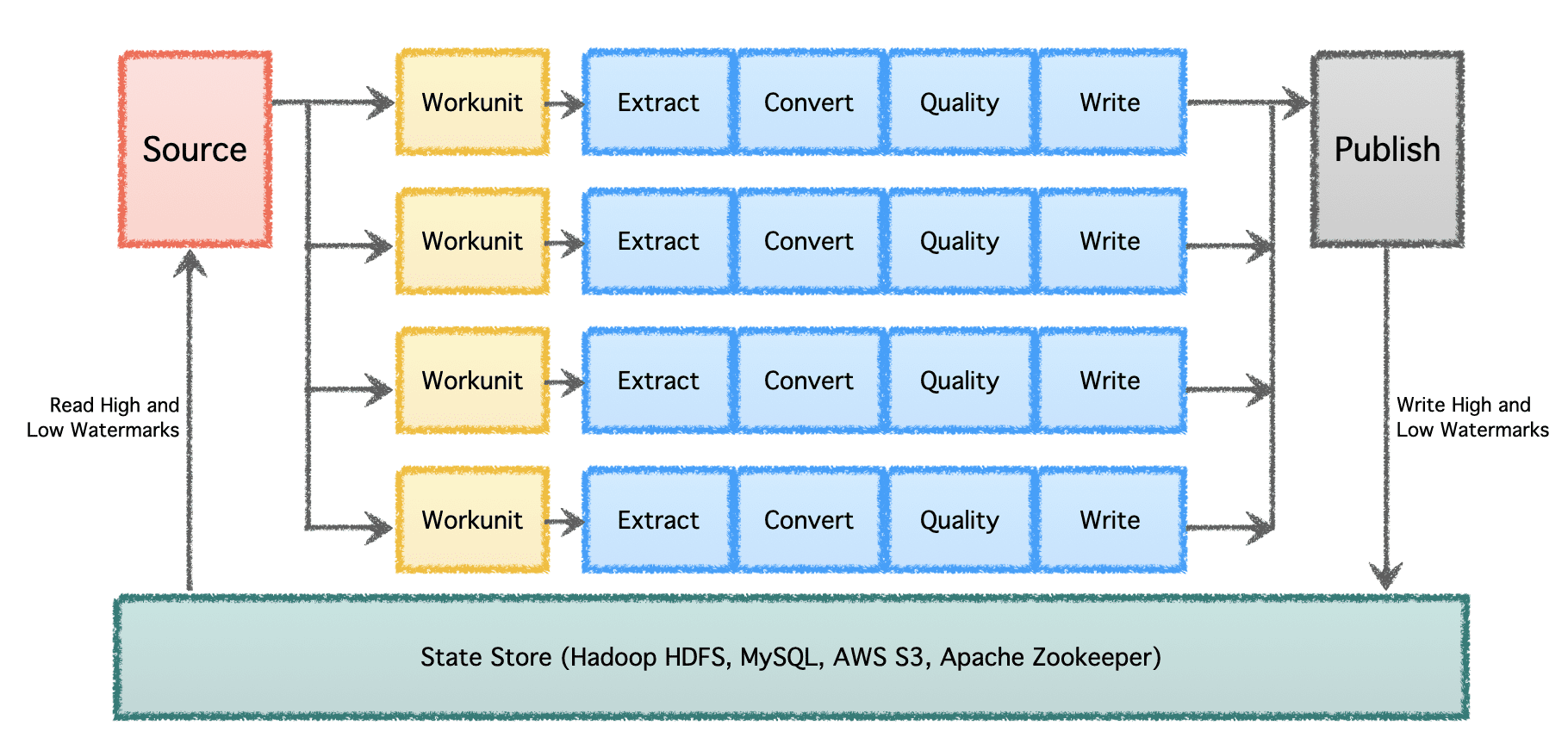
Bilde av forfatter
Samme retningslinjer for batch- og strømdata
De fleste datarørledninger i dag må skrives to ganger, én gang for batchdata og igjen for nærlinjedata eller strømmedata. Den dobler innsatsen og introduserer inkonsekvenser i retningslinjer og algoritmer som brukes på forskjellige typer rørledninger. Apache Gobblin løser dette ved å la brukere lage en pipeline én gang og kjøre den på både batch- og strømdata hvis den brukes i Gobblin Cluster-modus, Gobblin på AWS-modus eller Gobblin på garn-modus.
Migrer mellom On-prem og Cloud
På grunn av de allsidige modusene som kan kjøres lokalt på en enkelt boks, en klynge med noder eller skyen – kan Apache Gobblin distribueres og brukes på stedet og i skyen. Derfor lar brukere skrive datapipelines én gang og migrere dem sammen med Gobblin-implementeringer enkelt mellom on-prem og sky, basert på spesifikke behov.
På grunn av sin svært fleksible arkitektur, kraftige funksjoner og den ekstreme skalaen av datavolumer som den kan støtte og behandle, brukes Apache Gobblin i produksjonsinfrastrukturen til store teknologiselskaper og er et must-have for all distribusjon av stordatainfrastruktur i dag.
Flere detaljer om Apache Gobblin og hvordan du bruker den finner du på https://gobblin.apache.org
Abhishek Tiwari er Senior Manager hos LinkedIn, og leder selskapets Big Data Pipelines-organisasjon. Han er også visepresident for Apache Gobblin ved Apache Software Foundation og stipendiat i British Computer Society.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- oppnådd
- adressering
- Annonse
- Etter
- Aid
- algoritmer
- Alle
- tillate
- beløp
- analyse
- analytics
- og
- Apache
- APIer
- anvendt
- arkitektur
- assosiert
- forfatter
- AWS
- Backed
- basert
- blir
- mellom
- Stor
- Store data
- Eske
- British
- virksomhet
- bedrifter
- evner
- saker
- utfordringer
- kontroll
- Cloud
- Cluster
- kombinasjon
- Selskaper
- Selskapet
- komplekse
- samsvar
- datamaskin
- databehandling
- konstant
- konstruere
- fortsette
- Konvertering
- konvertere
- skaper
- skikk
- kunde
- Kundedeltakelse
- dato
- datainfrastruktur
- Dataledelse
- databaser
- datasett
- avhengig
- utplassert
- distribusjon
- distribusjoner
- destinasjonen
- detaljer
- bestemmes
- utviklet
- forskjellig
- distribueres
- distribusjon
- dynamikk
- lett
- innsats
- engasjement
- Enterprise
- Eter (ETH)
- utvikle seg
- gjennomføring
- dyrt
- trekke ut
- utdrag
- ekstrem
- Egenskaper
- kar
- Felt
- filet
- slutt~~POS=TRUNC
- fleksibel
- format
- funnet
- Fundament
- Rammeverk
- fra
- Brensel
- fullt
- generasjonen
- Vekst
- Hadoop
- håndtere
- hjelpe
- Høy
- svært
- vert
- vert
- Hvordan
- Hvordan
- HTTPS
- in
- inkludere
- uavhengig
- Infrastruktur
- infrastruktur
- innledende
- innsikt
- integrering
- Introduserer
- Investeringer
- IT
- Jobb
- KDnuggets
- Hold
- nøkkel
- stor
- Siste
- siste
- ledende
- laste
- Lav
- maskiner
- ledelse
- leder
- Marketing
- mekanisme
- metall
- migrere
- Mote
- modeller
- Moderne
- moduser
- mer
- mest
- flere
- Må-ha
- MySQL
- innfødt
- nødvendig
- behov
- Nyeste
- noder
- tilby
- ONE
- åpen kildekode
- Drift
- organisasjon
- skissert
- deler
- Personlig
- plukket
- rørledning
- plato
- Platon Data Intelligence
- PlatonData
- Politikk
- Populær
- makt
- kraftig
- Prediktiv Analytics
- trekker
- president
- tidligere
- pris
- Problem
- prosess
- Produkt
- Produksjon
- gir
- offentlig
- Offentlig sky
- publisere
- kvalitet
- raskt
- spenner
- anbefalinger
- rekord
- poster
- redusere
- relativt
- replikering
- Krav
- de
- REST
- gjenoppta
- oppbevaring
- robust
- Kjør
- Salesforce
- samme
- Skala
- skalering
- skript
- Seksjon
- semantikk
- senior
- sentiment
- sett
- signifikant
- Enkelt
- enkelt
- situasjoner
- So
- Samfunnet
- Software
- LØSE
- løser
- kilde
- Kilder
- spesialisert
- spesifikk
- Scene
- stående
- oppstart
- Tilstand
- Trinn
- lagring
- oppbevare
- lagret
- Strategisk
- stream
- streaming
- vellykket
- suite
- støtte
- Støtter
- system
- målrettet
- oppgaver
- Teknologi
- De
- deres
- derfor
- Gjennom
- tid
- tidsstempel
- til
- i dag
- verktøy
- tradisjonelle
- Transform
- forvandlet
- typer
- underliggende
- enestående
- bruke
- Brukere
- ulike
- allsidig
- av
- Vice President
- volum
- volumer
- hvilken
- mens
- vil
- uten
- Arbeid
- verden
- skrive
- skriving
- skrevet
- zephyrnet