Introduksjon
Store språkmodeller (LLMs) og Generativ AI representerer et transformativt gjennombrudd innen kunstig intelligens og naturlig språkbehandling. De kan forstå og generere menneskelig språk og produsere innhold som tekst, bilder, lyd og syntetiske data, noe som gjør dem svært allsidige i ulike applikasjoner. Generativ AI har enorm betydning i virkelige applikasjoner ved å automatisere og forbedre innholdsskaping, tilpasse brukeropplevelser, strømlinjeforme arbeidsflyter og fremme kreativitet. I denne artikkelen vil vi fokusere på hvordan bedrifter kan integreres med åpne LLM-er ved å jorde ledetekstene effektivt ved å bruke Enterprise Knowledge Graphs.
Læringsmål
- Skaff deg kunnskap om jording og rask bygging mens du samhandler med LLM-er/Gen-AI-systemer.
- Forstå bedriftsrelevansen til jording, forretningsverdien av integrasjon med åpne Gen-AI-systemer med et eksempel.
- Analyserer to store jording konkurrerende løsninger kunnskapsgrafer og Vector lagrer på ulike fronter og forstår hva som passer når.
- Studer et eksempel på bedriftsdesign av jording og rask bygging, bruk kunnskapsgrafer, lær datamodellering og grafmodellering i JAVA for et personlig anbefalingskundescenario.
Denne artikkelen ble publisert som en del av Data Science Blogathon.
Innholdsfortegnelse
Hva er store språkmodeller?
En stor språkmodell er en avansert AI-modell trent ved hjelp av dyplæringsteknikker på enorme mengder tekst|ustrukturerte data. Disse modellene er i stand til å samhandle med menneskelig språk, generere menneskelignende tekst, bilder og lyd, og utføre ulike naturlig språkbehandling oppgaver.
I motsetning til dette refererer definisjonen av en språkmodell til å tildele sannsynligheter til ordsekvenser basert på analyse av tekstkorpus. En språkmodell kan variere fra enkle n-gram-modeller til mer sofistikerte nevrale nettverksmodeller. Begrepet "stor språkmodell" refererer imidlertid vanligvis til modeller som bruker dyplæringsteknikker og har et stort antall parametere, som kan variere fra millioner til milliarder. Disse modellene kan fange opp komplekse mønstre i språk og produsere tekst som ofte ikke kan skilles fra den som er skrevet av mennesker.
Hva er en ledetekst?
En melding til enhver LLM eller et lignende chatbot AI-system er en tekstbasert inndata eller melding du gir for å starte en samtale eller interaksjon med AI. LLM-er er allsidige, trent med et bredt utvalg av store data, og kan brukes til ulike oppgaver; derfor påvirker konteksten, omfanget, kvaliteten og klarheten til forespørselen i betydelig grad svarene du mottar fra LLM-systemene.
Hva er jording/RAG?
Jording, AKA Retrieval-Augmented Generation (RAG), i sammenheng med naturlig språk LLM-behandling, refererer til å berike ledeteksten med kontekst, ekstra metadata og omfang vi gir til LLM-er for å forbedre og hente mer skreddersydde og nøyaktige svar. Denne tilkoblingen hjelper AI-systemer med å forstå og tolke dataene på en måte som stemmer overens med det nødvendige omfanget og konteksten. Forskning på LLM-er viser at kvaliteten på svaret deres avhenger av kvaliteten på forespørselen.
Det er et grunnleggende konsept i AI, ettersom det bygger bro mellom rådata og AIs evne til å behandle og tolke disse dataene på en måte som samsvarer med menneskelig forståelse og kontekst. Det forbedrer kvaliteten og påliteligheten til AI-systemer og deres evne til å levere nøyaktig og nyttig informasjon eller svar.
Hva er ulempene med LLM-er?
Store språkmodeller (LLM), som GPT-3, har fått betydelig oppmerksomhet og bruk i ulike applikasjoner, men de har også flere ulemper eller ulemper. Noen av de viktigste ulempene med LLM inkluderer:
1. Bias og rettferdighet: LLM-er arver ofte skjevheter fra treningsdataene. Dette kan resultere i generering av partisk eller diskriminerende innhold, som kan forsterke skadelige stereotyper og opprettholde eksisterende skjevheter.
2. Hallusinasjoner: LLM-er forstår ikke virkelig innholdet de genererer; de genererer tekst basert på mønstre i treningsdataene. Dette betyr at de kan produsere faktisk ukorrekt eller useriøs informasjon, noe som gjør dem uegnet for kritiske applikasjoner som medisinsk diagnose eller juridisk rådgivning.
3. Beregningsressurser: Trening og kjøring av LLM-er krever enorme beregningsressurser, inkludert spesialisert maskinvare som GPU-er og TPU-er. Dette gjør dem dyre å utvikle og vedlikeholde.
4. Datas personvern og sikkerhet: LLM-er kan generere overbevisende falskt innhold, inkludert tekst, bilder og lyd. Dette risikerer personvern og sikkerhet for data, ettersom de kan utnyttes til å lage uredelig innhold eller etterligne personer.
5. Etiske bekymringer: Bruk av LLM-er i ulike applikasjoner, for eksempel deepfakes eller automatisert innholdsgenerering, reiser etiske spørsmål om deres potensial for misbruk og innvirkning på samfunnet.
6. Regulatoriske utfordringer: Den raske utviklingen av LLM-teknologi har gått utover regulatoriske rammeverk, noe som gjør det utfordrende å etablere hensiktsmessige retningslinjer og forskrifter for å håndtere potensielle risikoer og utfordringer knyttet til LLM.
Det er viktig å merke seg at mange av disse ulempene ikke er iboende for LLM, men snarere gjenspeiler hvordan de utvikles, distribueres og brukes. Arbeidet pågår for å dempe disse ulempene og gjøre LLM-er mer ansvarlige og fordelaktige for samfunnet. Det er her jording og maskering kan utnyttes og være til stor fordel for bedriftene.
Bedriftsrelevans for jording
Bedrifter trives med å indusere store språkmodeller (LLM) i sine virksomhetskritiske applikasjoner. De forstår den potensielle verdien som LLM-er kan ha nytte av på tvers av ulike domener. Å bygge LLM-er, forhåndstrene og finjustere dem er ganske dyrt og tungvint for dem. Snarere kan de bruke de åpne AI-systemene som er tilgjengelige i bransjen med jording og maskering av spørsmål rundt bedriftsbruk.
Derfor er jording et ledende hensyn for bedrifter og er mer relevant og nyttig for dem både når det gjelder å forbedre kvaliteten på svarene og overvinne bekymringen for hallusinasjoner, datasikkerhet og samsvar, ettersom det kan drive utrolig forretningsverdi ut av det åpne. LLM-er tilgjengelig på markedet for en rekke brukstilfeller som de har en utfordring med å automatisere i dag.
Fordeler for bedrifter
Det er flere fordeler for bedrifter ved å implementere jording med LLM-er:
1. Forbedret troverdighet: Ved å sikre at informasjonen og innholdet som genereres av LLM-er er forankret i verifiserte datakilder, kan bedrifter øke troverdigheten til deres kommunikasjon, rapporter og innhold. Dette kan bidra til å bygge tillit hos kunder, klienter og interessenter.
2. Forbedret beslutningstaking: I bedriftsapplikasjoner, spesielt de som er relatert til dataanalyse og beslutningsstøtte, kan bruk av LLM-er med datajording gi mer pålitelig innsikt. Dette kan føre til bedre informert beslutningstaking, noe som er avgjørende for strategisk planlegging og forretningsvekst.
3. Overholdelse av regelverk: Mange bransjer er underlagt regulatoriske krav for datanøyaktighet og samsvar. Datajording med LLM-er kan hjelpe til med å oppfylle disse samsvarsstandardene, og redusere risikoen for juridiske eller regulatoriske problemer.
4. Generering av kvalitetsinnhold: LLM-er brukes ofte i innholdsskaping, for eksempel for markedsføring, kundestøtte og produktbeskrivelser. Datajording sikrer at det genererte innholdet er faktisk nøyaktig, noe som reduserer risikoen for å spre falsk eller villedende informasjon eller hallusinasjoner.
5. Reduksjon i feilinformasjon: I en tid med falske nyheter og feilinformasjon kan datajording hjelpe bedrifter med å bekjempe spredningen av falsk informasjon ved å sikre at innholdet de genererer eller deler er basert på validerte datakilder.
6. Kundetilfredshet: Å gi kundene nøyaktig og pålitelig informasjon kan øke deres tilfredshet og tillit til en bedrifts produkter eller tjenester.
7. Risikoreduserende tiltak: Datajording kan bidra til å redusere risikoen for å ta beslutninger basert på unøyaktig eller ufullstendig informasjon, noe som kan føre til økonomisk skade eller skade på omdømmet.
Eksempel: Scenario for kundeanbefaling
La oss se hvordan datajording kan hjelpe for bedrifter som bruker openAI chatGPT
Grunnleggende spørsmål
Generate a short email adding coupons on recommended products to customer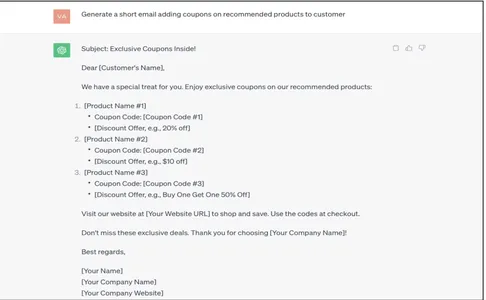
Responsen generert av ChatGPT er veldig generisk, ikke-kontekstualisert og rå. Dette må manuelt oppdateres/kartlegges med riktig bedriftskundedata, noe som er dyrt. La oss se hvordan dette kan automatiseres med datajordingsteknikker.
La oss si at bedriften allerede har bedriftens kundedata og et intelligent anbefalingssystem som kan generere kuponger og anbefalinger for kundene; vi kunne godt grunnet oppfordringen ovenfor ved å berike den med de riktige metadataene slik at den genererte e-postteksten fra chatGPT ville være nøyaktig den samme som vi ønsker den skal være og meget vel kan automatiseres til å sende e-post til kunden uten manuell intervensjon.
La oss anta at vår jordingsmotor henter de riktige berikelsesmetadataene fra kundedata og oppdaterer ledeteksten nedenfor. La oss se hvordan ChatGPT-svaret for den jordede forespørselen ville være.
Jordet ledetekst
Generate a short email adding below coupons and products to customer Taylor and wish him a Happy holiday season from Team Aatagona, Atagona.com
Winter Jacket Mens - [https://atagona.com/men/winter/jackets/123.html] - 20% off
Rodeo Beanie Men’s - [https://atagona.com/men/winter/beanies/1234.html] - 15% off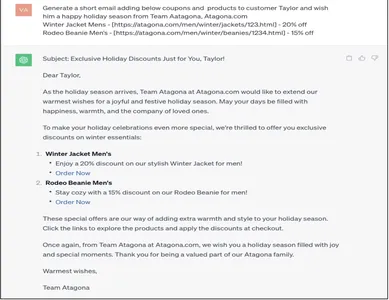
Svaret som genereres med bakkemeldingen er nøyaktig hvordan bedriften ønsker at kunden skal varsles. De berikede kundedataene som legges inn i et e-postsvar fra Gen AI er en automatisering som ville vært bemerkelsesverdig for å skalere opp og opprettholde bedrifter.
Enterprise LLM jordingsløsninger for programvaresystemer
Det er flere måter å jorde data på i bedriftssystemer, og en kombinasjon av disse teknikkene kan brukes for effektiv datajording og rask generering spesifikt for brukstilfellet. De to primære utfordrerne som potensielle løsninger for å implementere utvidet gjenvinning (jording) er
- Applikasjonsdata|Kunnskapsgrafer
- Vektorinnbygginger og semantisk søk
Bruken av disse løsningene vil avhenge av brukstilfellet og jordingen du ønsker å bruke. For eksempel kan vektorlagre gitte svar være unøyaktige og vage, mens kunnskapsgrafer vil returnere presise, nøyaktige og lagret i et menneskelig lesbart format.
Noen få andre strategier som kan blandes på toppen av det ovennevnte kan være
- Kobling til eksterne APIer, søkemotorer
- Datamaskering og overholdelsessystemer
- Integrering med interne datalagre, systemer
- Samle data i sanntid fra flere kilder
I denne bloggen, la oss se på et eksempel på programvaredesign om hvordan du kan oppnå med datagrafer for bedriftsapplikasjoner.
Enterprise Knowledge Graphs
En kunnskapsgraf kan representere semantisk informasjon om ulike enheter og relasjoner mellom dem. I Enterprise-verdenen lagrer de kunnskap om kunder, produkter og mer. Bedriftskundegrafer ville være et kraftig verktøy for å jorde data effektivt og generere berikede spørsmål. Kunnskapsgrafer muliggjør grafbasert søk, slik at brukere kan utforske informasjon gjennom koblede konsepter og enheter, noe som kan føre til mer presise og mangfoldige søkeresultater.
Sammenligning med vektordatabaser
Å velge jordingsløsningen vil være bruksspesifikk. Imidlertid er det flere fordeler med grafer fremfor vektorer som
| Kriterier | Graf jording | Vektorjording |
| Analytiske spørringer | Datagrafer er egnet for strukturerte data og analytiske spørringer, og gir nøyaktige resultater på grunn av deres abstrakte graflayout. | Vektordatalagre fungerer kanskje ikke like godt med analytiske spørringer, da de for det meste opererer på ustrukturerte data, semantisk søk med vektorinnbygging og er avhengig av likhetsscoring. |
| Nøyaktighet og troverdighet | Kunnskapsgrafer bruker noder og relasjoner til å lagre data, og returnerer bare den informasjonen som er tilstede. De unngår ufullstendige eller irrelevante resultater. | Vektordatabaser kan gi ufullstendige eller irrelevante resultater, hovedsakelig på grunn av deres avhengighet av likhetspoeng og forhåndsdefinerte resultatgrenser. |
| Korrigering av hallusinasjoner | Kunnskapsgrafer er transparente med en menneskelesbar representasjon av data. De hjelper til med å identifisere og korrigere feilinformasjon, spore sporet til spørringen og gjøre korrigeringer i den, og forbedre LLM (Large Language Model) nøyaktighet. | Vektordatabaser blir ofte sett på som svarte bokser som ikke er lagret i lesbart format og gjør det kanskje ikke lettere å identifisere og korrigere feilinformasjon. |
| Sikkerhet og styring | Kunnskapsgrafer gir bedre kontroll over datagenerering, styring og overholdelse av overholdelse, inkludert forskrifter som GDPR. | Vektordatabaser kan møte utfordringer med å pålegge restriksjoner og styring på grunn av deres ugjennomsiktige natur. |
Design på høyt nivå
La oss se på et meget høyt nivå hvordan systemet kan se ut for en bedrift som bruker kunnskapsgrafer og åpne LLM-er for jording.
Grunnlaget er der bedriftskundedata og metadata lagres på tvers av ulike databaser, datavarehus og datainnsjøer. Det kan være en tjeneste som bygger datakunnskapsgrafene ut av disse dataene og lagrer dem i en graf db. Det kan være mange bedriftstjenester|mikrotjenester i en distribuert skybasert verden som vil samhandle med disse datalagrene. Over disse tjenestene kan det være ulike applikasjoner som vil utnytte den underliggende infraen.
Applikasjoner kan ha mange brukstilfeller for å bygge inn AI i sine scenarier eller intelligente automatiserte kundestrømmer, som krever samhandling med interne og eksterne AI-systemer. Når det gjelder generative AI-scenarier, la oss ta et enkelt eksempel på en arbeidsflyt der en bedrift ønsker å målrette kunder via en e-post som tilbyr noen få rabatter på personlig tilpassede anbefalte produkter i løpet av høytiden. De kan oppnå dette med førsteklasses automatisering, og utnytte AI mer effektivt.
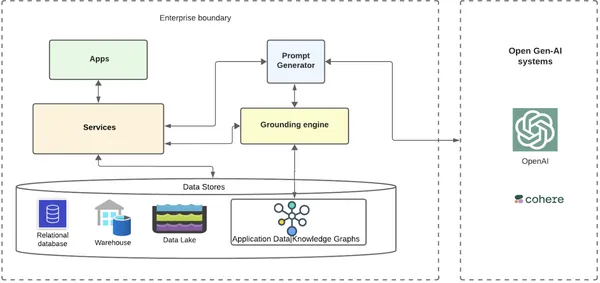
Arbeidsflyten
- Arbeidsflyt som ønsker å sende en e-post kan ta hjelp av åpne Gen-AI-systemer ved å sende en jordet melding med kundekontekstualiserte data.
- Arbeidsflytapplikasjonen ville sende en forespørsel til sin backend-tjeneste for å få tak i e-postteksten som utnytter GenAI-systemer.
- Backend-tjenesten vil rute tjenesten til en prompt generatortjeneste, som ruter til en jordingsmotor.
- Jordingsmotoren henter alle kundens metadata fra en av sine tjenester og henter kundedatakunnskapsgrafen.
- Jordingsmotoren krysser grafen over nodene og relevante relasjoner trekker ut den ultimate informasjonen som kreves, og sender den tilbake til promptgeneratoren.
- Spørringsgeneratoren legger til jordede data med en forhåndseksisterende mal for brukstilfellet og sender den jordede ledeteksten til de åpne AI-systemene bedriften velger å integrere med (f.eks. OpenAI/Cohere).
- Åpne GenAI-systemer returnerer et mye mer relevant og kontekstualisert svar til bedriften, sendt til kunden via e-post.
La oss dele dette inn i to deler og forstå i detalj:
1. Generering av kundekunnskapsgrafer
Designet nedenfor passer til eksemplet ovenfor, modellering kan gjøres på forskjellige måter i henhold til kravet.
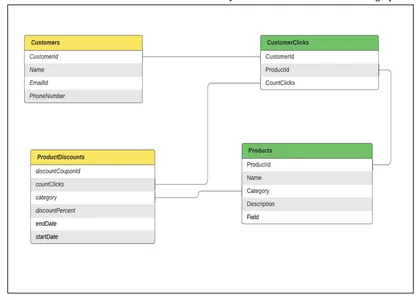
Datamodellering: Anta at vi har forskjellige tabeller som er modellert som noder i en graf og kobler mellom tabeller som relasjoner mellom noder. For eksempelet ovenfor trenger vi
- en tabell som inneholder kundens data,
- en tabell som inneholder produktdata,
- en tabell som inneholder kundeinteresser(klikk)-data for personlig tilpassede anbefalinger
- en tabell som inneholder produktrabattdataene
Det er bedriftens ansvar å få alle disse dataene inntatt fra flere datakilder og oppdatert regelmessig for å nå kunder effektivt.
La oss se hvordan disse tabellene kan modelleres og hvordan de kan transformeres til en kundegraf.
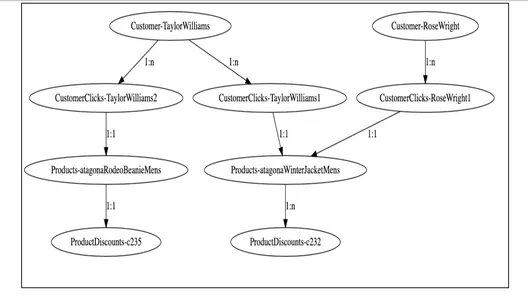
2. Grafmodellering
Fra grafvisualiseringen ovenfor kan vi se hvordan kundenoder er relatert til ulike produkter basert på deres klikkengasjementdata og videre til rabattnodene. Det er enkelt for jordingstjenesten å spørre etter disse kundegrafene, krysse disse nodene gjennom relasjoner og skaffe den nødvendige informasjonen om rabatter som er kvalifisert for respektive kunder.
En eksempelgrafnode og relasjons-JAVA POJO-er for ovennevnte kan se ut som det nedenfor
public class KnowledgeGraphNode implements Serializable { private final GraphNodeType graphNodeType; private final GraphNode nodeMetadata;
} public interface GraphNode {
} public class CustomerGraphNode implements GraphNode { private final String name; private final String customerId; private final String phone; private final String emailId;
}
public class ClicksGraphNode implements GraphNode { private final String customerId; private final int clicksCount;
} public class ProductGraphNode implements GraphNode { private final String productId; private final String name; private final String category; private final String description; private final int price;
} public class ProductDiscountNode implements GraphNode { private final String discountCouponId; private final int clicksCount; private final String category; private final int discountPercent; private final DateTime startDate; private final DateTime endDate;
}
public class KnowledgeGraphRelationship implements Serializable { private final RelationshipCardinality Cardinality; } public enum RelationshipCardinality { ONE_TO_ONE, ONE_TO_MANY }Et eksempel på en rå graf i dette scenariet kan se ut som nedenfor
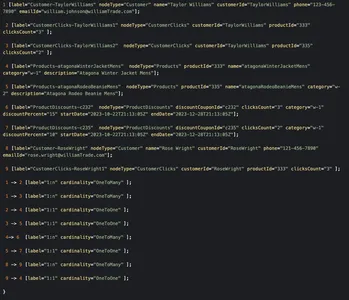
Å gå gjennom grafen fra kundenoden 'Taylor Williams' ville løse problemet for oss og hente de riktige produktanbefalingene og kvalifiserte rabattene.
3. Populære Graph-butikker i industrien
Det er mange grafbutikker tilgjengelig på markedet som kan passe bedriftsarkitekturer. Neo4j, TigerGraph, Amazon Neptune og OrientDB er mye brukt som grafdatabaser.
Vi introduserer det nye paradigmet til Graph Data Lakes, som muliggjør grafforespørsler på tabelldata (strukturerte data i innsjøer, varehus og innsjøer). Dette oppnås med nye løsninger oppført nedenfor, uten behov for å hydrere eller vedvare data i grafdatalagre, ved å utnytte Zero-ETL.
- PuppyGraph (Graph Data Lake)
- Timbr.ai
Overholdelse og etiske hensyn
Data Protection: Bedrifter må være ansvarlige for å lagre og bruke kundedata i samsvar med GDPR og annen PII-overholdelse. Data som er lagret må styres og renses før behandling og gjenbruk for innsikt eller bruk AI.
Hallusinasjoner og forsoning: Bedrifter kan også legge til avstemmingstjenester som vil identifisere feilinformasjon i data, spore sporet til spørringen og foreta korrigeringer i den, noe som kan bidra til å forbedre LLM-nøyaktigheten. Med kunnskapsgrafer, siden dataene som lagres er transparente og lesbare for mennesker, bør dette være relativt enkelt å oppnå.
Retningslinjer for restriktiv oppbevaring: For å overholde databeskyttelsen og forhindre misbruk av kundedata mens de samhandler med åpne LLM-systemer, er det svært viktig å ha null oppbevaringsregler, slik at de eksterne systemene bedrifter samhandler med ikke vil ha de forespurte dataene for ytterligere analytiske eller forretningsformål.
konklusjonen
Avslutningsvis representerer store språkmodeller (LLM) et bemerkelsesverdig fremskritt innen kunstig intelligens og naturlig språkbehandling. De kan transformere ulike bransjer og applikasjoner, fra naturlig språkforståelse og generering til å bistå med komplekse oppgaver. Suksessen og ansvarlig bruk av LLM krever imidlertid et sterkt fundament og forankring på ulike nøkkelområder.
Nøkkelfunksjoner
- Bedrifter kan dra stor nytte av effektiv jording og spørsmål mens de bruker LLM-er for ulike scenarier.
- Kunnskapsgrafer og Vector-butikker er populære jordingsløsninger, og valg av en vil avhenge av formålet med løsningen.
- Kunnskapsgrafer kan ha mer nøyaktig og pålitelig informasjon i forhold til vektorlagre, noe som gir en fordel for Enterprise-brukstilfeller uten å måtte legge til ytterligere sikkerhets- og samsvarslag.
- Transform den tradisjonelle datamodelleringen med enheter og relasjoner til Kunnskapsgrafer med noder og kanter.
- Integrer bedriftskunnskapsgrafene med ulike datakilder med eksisterende store datalagringsbedrifter.
- Kunnskapsgrafer er ideelle for analytiske spørringer. Grafdatainnsjøer gjør det mulig å søke etter tabelldata som grafer i bedriftsdatalagring.
Ofte Stilte Spørsmål
A. LLM er en AI-algoritme som bruker DL-teknikker og massivt store datasett for å forstå, oppsummere, generere og forutsi nytt innhold.
A. En applikasjonsdatagraf er en datastruktur som lagrer data i form av noder og kanter. Modeller dem som relasjonene mellom forskjellige datanoder.
A. En vektordatabase lagrer og administrerer ustrukturerte data som tekst, lyd og video. Den utmerker seg i rask indeksering og gjenfinning for applikasjoner som anbefalingsmotorer, maskinlæring og Gen-AI.
A. I et vektorlager er innebygginger numeriske representasjoner av objekter, ord eller datapunkter i et høydimensjonalt vektorrom. Disse innebyggingene fanger opp semantiske relasjoner og likheter mellom elementer, og muliggjør effektiv dataanalyse, likhetssøk og maskinlæringsoppgaver.
A. Strukturerte data er godt organisert med definerte tabeller og skjema. Ustrukturerte data, som tekst, bilder, lyd eller video, er vanskeligere å analysere på grunn av mangel på format.
Mediene vist i denne artikkelen eies ikke av Analytics Vidhya og brukes etter forfatterens skjønn.
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2023/11/the-role-of-enterprise-knowledge-graphs-in-llms/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 11
- 12
- 13
- 15%
- 19
- 22
- 49
- 500
- 52
- 53
- 750
- 8
- 9
- a
- evne
- Om oss
- ovenfor
- ABSTRACT
- Ifølge
- nøyaktighet
- nøyaktig
- Oppnå
- oppnådd
- tvers
- legge til
- legge
- Ytterligere
- adresse
- Legger
- overholde
- binding
- fester seg
- vedtatt
- avansert
- forfremmelse
- Fordel
- fordeler
- råd
- AI
- AI-systemer
- aka
- algoritme
- Justerer
- Alle
- tillate
- allerede
- også
- utrolig
- Amazon
- Amazon Neptun
- blant
- beløp
- an
- analyse
- Analytisk
- analytics
- Analytics Vidhya
- analysere
- og
- noen
- APIer
- Søknad
- søknader
- Påfør
- påføring
- hensiktsmessig
- ER
- områder
- rundt
- Artikkel
- kunstig
- kunstig intelligens
- AS
- bistå
- bistå
- assosiert
- anta
- At
- oppmerksomhet
- lyd
- augmented
- Automatisert
- Automatisere
- Automatisering
- tilgjengelig
- unngå
- tilbake
- Backend
- basen
- basert
- BE
- før du
- under
- gunstig
- nytte
- Fordeler
- Bedre
- mellom
- Beyond
- forutinntatt
- skjevheter
- Stor
- Store data
- stor datalagring
- milliarder
- Svart
- Blogg
- både
- bokser
- Break
- gjennombrudd
- broer
- bygge
- bygge tillit
- Bygning
- virksomhet
- men
- by
- CAN
- stand
- fangst
- saken
- saker
- Kategori
- utfordre
- utfordringer
- utfordrende
- chatbot
- ChatGPT
- velge
- klarhet
- klasse
- klienter
- Cloud
- sky innfødte
- COM
- bekjempe
- kombinasjon
- Kom
- kommunikasjon
- komplekse
- samsvar
- beregnings
- konsept
- konsepter
- Bekymring
- konklusjon
- tilkobling
- Ulemper
- hensyn
- konsistent
- innhold
- innholdsskaping
- kontekst
- kontrast
- kontroll
- Samtale
- korrigere
- Korreksjoner
- kunne
- skape
- skaperverket
- kreativitet
- Troverdighet
- kritisk
- avgjørende
- tungvint
- kunde
- kunde Data
- Kundeservice
- Kunder
- dato
- dataanalyse
- Data Lake
- datapunkter
- personvern
- Datas personvern og sikkerhet
- databeskyttelse
- datasikkerhet
- datasett
- datalagring
- datavarehus
- Database
- databaser
- dato tid
- avgjørelse
- Beslutningstaking
- avgjørelser
- dyp
- dyp læring
- deepfakes
- definert
- definisjon
- leverer
- avhenger
- utplassert
- beskrivelse
- utforming
- detalj
- utvikle
- utviklet
- Utvikling
- diagnose
- forskjell
- forskjellig
- rabatter
- skjønn
- distribueres
- diverse
- do
- domener
- gjort
- ulemper
- stasjonen
- to
- under
- e
- lett
- Edge
- Effektiv
- effektivt
- effektiv
- innsats
- kvalifisert
- emalje
- embed
- embedding
- muliggjøre
- muliggjør
- muliggjør
- engasjement
- Motor
- Motorer
- forbedre
- forbedret
- Forbedrer
- styrke
- enorm
- anriket
- berikende
- sikrer
- sikrer
- Enterprise
- bedrifter
- enheter
- Era
- spesielt
- etablere
- Eter (ETH)
- etisk
- nøyaktig
- eksempel
- eksisterende
- dyrt
- Erfaringer
- Exploited
- utforske
- utvendig
- ekstrakter
- Face
- legge til rette
- forfalskning
- falske nyheter
- falsk
- Noen få
- slutt~~POS=TRUNC
- finansiell
- Flows
- Fokus
- Til
- skjema
- format
- fostre
- Fundament
- rammer
- uredelig
- fra
- fundamental
- videre
- fikk
- mellomrom
- GDPR
- Gen
- generere
- generert
- genererer
- generasjonen
- generative
- Generativ AI
- generator
- gir
- styresett
- styrt
- GPU
- grabs
- graf
- grafer
- Ground
- Vekst
- retningslinjer
- lykkelig
- hardere
- maskinvare
- skade
- skadelig
- Ha
- å ha
- hjelpe
- nyttig
- hjelper
- derav
- her.
- Høy
- høyt nivå
- svært
- ham
- hold
- holder
- ferie
- Hvordan
- Men
- HTML
- HTTPS
- stort
- Enormt
- menneskelig
- lesbar
- Mennesker
- ideell
- Identifikasjon
- identifisere
- bilder
- enorme
- Påvirkning
- implementere
- redskaper
- betydning
- viktig
- pålegge
- forbedre
- bedre
- in
- unøyaktig
- inkludere
- Inkludert
- individer
- bransjer
- industri
- påvirke
- informasjon
- iboende
- initiere
- inngang
- innsikt
- integrere
- integrering
- Intelligens
- Intelligent
- samhandle
- samhandler
- interaksjon
- Interface
- intern
- intervensjon
- inn
- introdusere
- saker
- IT
- varer
- DET ER
- Java
- bli medlem
- jpg
- nøkkel
- Nøkkelområder
- kunnskap
- maling
- innsjø
- innsjøer
- Språk
- stor
- lag
- lag
- Layout
- føre
- ledende
- læring
- Lovlig
- Nivå
- Leverage
- utnyttet
- utnytte
- i likhet med
- grenser
- knyttet
- oppført
- Se
- ser ut som
- maskin
- maskinlæring
- Hoved
- hovedsakelig
- vedlikeholde
- større
- gjøre
- GJØR AT
- Making
- forvalter
- håndbok
- manuelt
- mange
- marked
- Marketing
- massive
- massivt
- max bredde
- Kan..
- midler
- Media
- medisinsk
- møte
- melding
- metadata
- millioner
- feil~~POS=TRUNC
- villedende
- misbruk
- Minske
- skadebegrensning
- modell
- modellering
- modeller
- mer
- for det meste
- mye
- flere
- må
- navn
- innfødt
- Naturlig
- Naturlig språk
- Natural Language Processing
- Naturlig språkforståelse
- Natur
- Trenger
- behov
- Neptune
- nettverk
- neural
- nevrale nettverket
- Ny
- nye løsninger
- nyheter
- node
- noder
- note
- Antall
- mange
- gjenstander
- få
- of
- off
- tilby
- tilby
- ofte
- on
- ONE
- pågående
- bare
- åpen
- OpenAI
- betjene
- or
- Annen
- vår
- ut
- enn
- overvinne
- eide
- paradigmet
- parametere
- del
- deler
- pathway
- mønstre
- utføre
- utfører
- Personlig
- telefon
- PII
- planlegging
- plato
- Platon Data Intelligence
- PlatonData
- poeng
- Politikk
- Populær
- potensiell
- kraftig
- presis
- forutsi
- presentere
- forebygge
- pris
- primære
- privatliv
- Personvern og sikkerhet
- privat
- Problem
- prosess
- prosessering
- produsere
- Produkt
- Produkter
- beskyttelse
- gi
- forutsatt
- gi
- offentlig
- publisert
- formål
- formål
- kvalitet
- spørsmål
- spørsmål
- Rask
- ganske
- hever
- område
- rask
- heller
- Raw
- rådata
- å nå
- Lese
- virkelige verden
- motta
- Anbefaling
- anbefalinger
- anbefales
- avstemming
- redusere
- redusere
- refererer
- reflektere
- regelmessig
- forskrifter
- regulatorer
- forsterke
- i slekt
- forholdet
- Relasjoner
- relativt
- relevans
- relevant
- pålitelighet
- pålitelig
- avhengighet
- avhengige
- bemerkelsesverdig
- Rapporter
- representere
- representasjon
- anmode
- Forespurt
- krever
- påkrevd
- behov
- Krav
- Krever
- forskning
- Ressurser
- de
- svar
- svar
- ansvar
- ansvarlig
- restriksjoner
- resultere
- Resultater
- oppbevaring
- retur
- retur
- ikke sant
- Risiko
- risikoer
- Rolle
- Rute
- ruter
- rennende
- samme
- tilfredshet
- Skala
- scenario
- scenarier
- Vitenskap
- omfang
- scoring
- Søk
- søk
- Årstid
- sikkerhet
- se
- sett
- send
- sending
- sender
- sendt
- tjeneste
- Tjenester
- sett
- flere
- Del
- Kort
- bør
- vist
- Viser
- signifikant
- betydelig
- lignende
- likheter
- Enkelt
- siden
- So
- Samfunnet
- Software
- løsning
- Solutions
- LØSE
- noen
- sofistikert
- Kilder
- Rom
- spesialisert
- spesifikk
- spre
- interessenter
- standarder
- lagring
- oppbevare
- lagret
- butikker
- Strategisk
- strategier
- effektivisering
- String
- sterk
- struktur
- strukturert
- strukturerte og ustrukturerte data
- emne
- suksess
- slik
- Dress
- egnet
- oppsummere
- støtte
- syntetisk
- syntetiske data
- system
- Systemer
- bord
- skreddersydd
- Ta
- Target
- oppgaver
- taylor
- lag
- teknikker
- Teknologi
- mal
- begrep
- tekst
- Det
- De
- Grafen
- informasjonen
- deres
- Dem
- Der.
- Disse
- de
- denne
- De
- Thrive
- Gjennom
- til
- i dag
- verktøy
- topp
- spore
- tradisjonelle
- trent
- Kurs
- Transform
- transformative
- forvandlet
- gjennomsiktig
- traversere
- virkelig
- Stol
- to
- ultimate
- underliggende
- forstå
- forståelse
- Oppdater
- oppdatert
- us
- bruke
- bruk sak
- brukt
- nyttig informasjon
- Bruker
- Brukere
- bruker
- ved hjelp av
- vanligvis
- validert
- verdi
- variasjon
- ulike
- verifisert
- allsidig
- veldig
- av
- video
- ønsker
- ønsker
- var
- Vei..
- måter
- we
- webp
- VI VIL
- Hva
- Hva er
- når
- mens
- hvilken
- mens
- bred
- allment
- vil
- Vinter
- med
- uten
- ord
- arbeidsflyt
- arbeidsflyt
- verden
- ville
- skrevet
- du
- Din
- zephyrnet
- null