I dette innlegget viser vi hvordan du bruker nevral arkitektursøk (NAS) basert strukturell beskjæring for å komprimere en finjustert BERT-modell for å forbedre modellytelsen og redusere slutningstider. Forhåndsutdannede språkmodeller (PLMer) gjennomgår rask kommersiell og bedriftsadopsjon innen områdene produktivitetsverktøy, kundeservice, søk og anbefalinger, automatisering av forretningsprosesser og innholdsskaping. Utplassering av PLM-slutningsendepunkter er vanligvis forbundet med høyere ventetid og høyere infrastrukturkostnader på grunn av beregningskravene og redusert beregningseffektivitet på grunn av det store antallet parametere. Beskjæring av en PLM reduserer størrelsen og kompleksiteten til modellen samtidig som den beholder dens prediktive evner. Beskjærte PLM-er oppnår et mindre minnefotavtrykk og lavere ventetid. Vi demonstrerer at ved å beskjære en PLM og bytte av parameterantall og valideringsfeil for en spesifikk måloppgave, og er i stand til å oppnå raskere responstider sammenlignet med basis-PLM-modellen.
Multi-objektiv optimalisering er et område for beslutningstaking som optimaliserer mer enn én objektiv funksjon, som minneforbruk, treningstid og dataressurser, for å bli optimalisert samtidig. Strukturell beskjæring er en teknikk for å redusere størrelsen og beregningskravene til PLM ved å beskjære lag eller nevroner/noder mens man forsøker å bevare modellens nøyaktighet. Ved å fjerne lag oppnår strukturell beskjæring høyere kompresjonshastigheter, noe som fører til maskinvarevennlig strukturert sparsomhet som reduserer kjøretider og responstider. Bruk av en strukturell beskjæringsteknikk på en PLM-modell resulterer i en lettere modell med et lavere minnefotavtrykk som, når den er vert som et sluttpunkt i SageMaker, gir forbedret ressurseffektivitet og reduserte kostnader sammenlignet med den originale finjusterte PLM.
Konseptene illustrert i dette innlegget kan brukes på applikasjoner som bruker PLM-funksjoner, for eksempel anbefalingssystemer, sentimentanalyse og søkemotorer. Spesifikt kan du bruke denne tilnærmingen hvis du har dedikerte maskinlærings- (ML) og datavitenskapsteam som finjusterer sine egne PLM-modeller ved hjelp av domenespesifikke datasett og distribuerer et stort antall inferensendepunkter ved å bruke Amazon SageMaker. Et eksempel er en nettforhandler som distribuerer et stort antall slutningsendepunkter for tekstoppsummering, produktkatalogklassifisering og produktfeedback-sentimentklassifisering. Et annet eksempel kan være en helsepersonell som bruker PLM-slutningsendepunkter for klinisk dokumentklassifisering, navngitt enhetsgjenkjenning fra medisinske rapporter, medisinske chatbots og pasientrisikostratifisering.
Løsningsoversikt
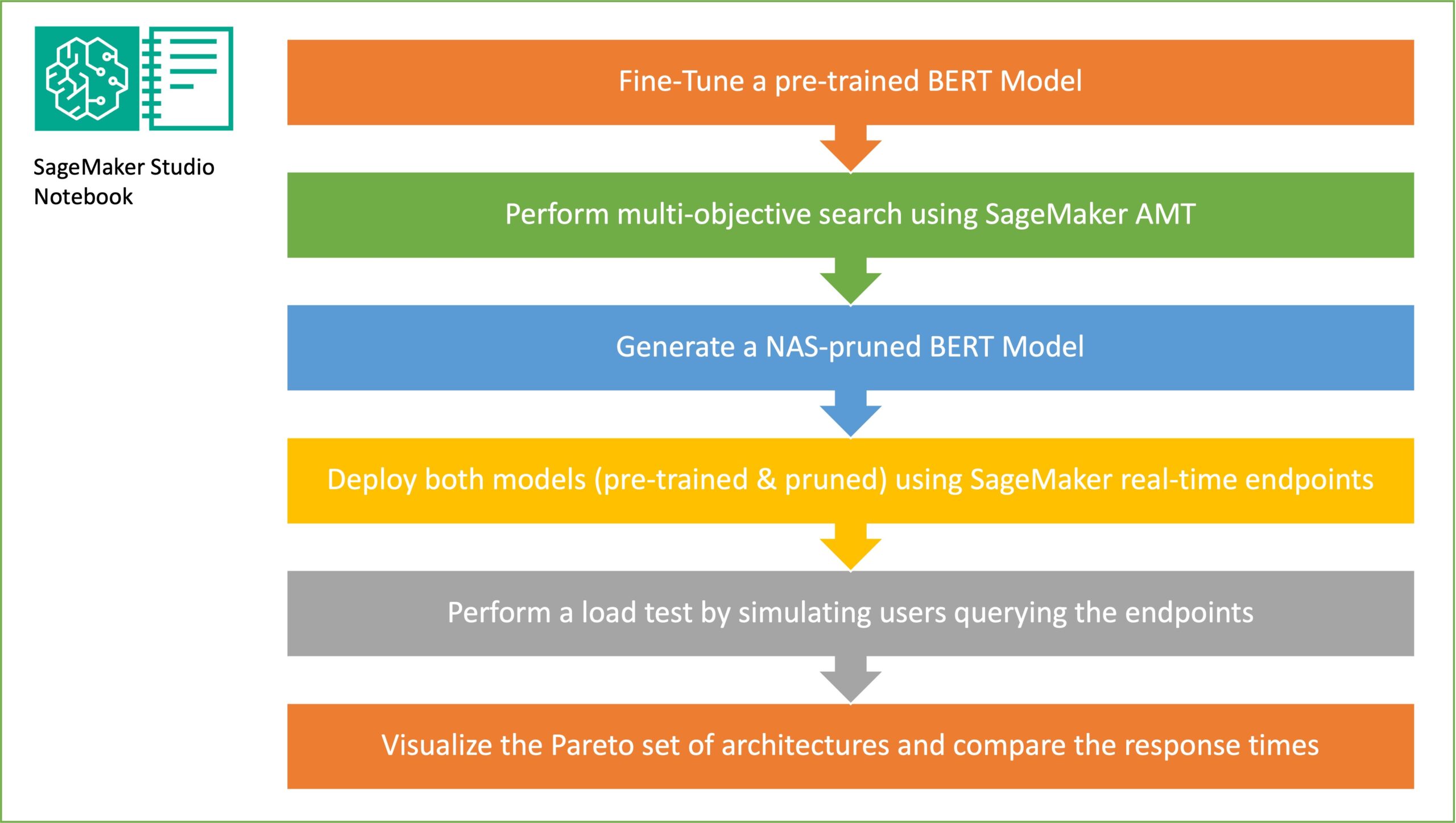
I denne delen presenterer vi den overordnede arbeidsflyten og forklarer tilnærmingen. Først bruker vi en Amazon SageMaker Studio bærbare å finjustere en forhåndstrent BERT-modell på en måloppgave ved å bruke et domenespesifikt datasett. BERTI (Bidirectional Encoder Representations from Transformers) er en ferdigtrent språkmodell basert på transformatorarkitektur brukes til naturlig språkbehandling (NLP) oppgaver. Nevral architecture search (NAS) er en tilnærming for å automatisere utformingen av kunstige nevrale nettverk og er nært knyttet til hyperparameteroptimalisering, en mye brukt tilnærming innen maskinlæring. Målet med NAS er å finne den optimale arkitekturen for et gitt problem ved å søke over et stort sett med kandidatarkitekturer ved å bruke teknikker som gradientfri optimalisering eller ved å optimalisere de ønskede metrikkene. Ytelsen til arkitekturen måles vanligvis ved hjelp av beregninger som valideringstap. SageMaker Automatisk modellinnstilling (AMT) automatiserer den kjedelige og komplekse prosessen med å finne de optimale kombinasjonene av hyperparametre i ML-modellen som gir best modellytelse. AMT bruker intelligente søkealgoritmer og iterative evalueringer ved å bruke en rekke hyperparametre som du angir. Den velger hyperparameterverdiene som skaper en modell som gir best ytelse, målt ved ytelsesmålinger som nøyaktighet og F-1-poengsum.
Finjusteringsmetoden beskrevet i dette innlegget er generisk og kan brukes på ethvert tekstbasert datasett. Oppgaven som er tildelt BERT PLM kan være en tekstbasert oppgave som sentimentanalyse, tekstklassifisering eller spørsmål og svar. I denne demoen er måloppgaven et binært klassifiseringsproblem der BERT brukes til å identifisere, fra et datasett som består av en samling av par med tekstfragmenter, om betydningen av det ene tekstfragmentet kan utledes fra det andre fragmentet. Vi bruker Gjenkjenner datasett for tekstlig engasjement fra GLUE benchmarking suite. Vi utfører et multi-objektiv søk ved å bruke SageMaker AMT for å identifisere undernettverkene som tilbyr optimale avveininger mellom parametertelling og prediksjonsnøyaktighet for måloppgaven. Når vi utfører et multi-objektiv søk, starter vi med å definere nøyaktigheten og parameterantallet som målene vi ønsker å optimalisere.
Innenfor BERT PLM-nettverket kan det være modulære, selvstendige undernettverk som lar modellen ha spesialiserte evner som språkforståelse og kunnskapsrepresentasjon. BERT PLM bruker et flerhodet selvoppmerksomhet-undernettverk og et feed-forward-undernettverk. Et flerhodet, selvoppmerksomhetslag lar BERT relatere forskjellige posisjoner av en enkelt sekvens for å beregne en representasjon av sekvensen ved å la flere hoder ivareta flere kontekstsignaler. Inndataene er delt opp i flere underrom og selvoppmerksomhet påføres hver av underrommene separat. Flere hoder i en transformator PLM lar modellen i fellesskap ivareta informasjon fra forskjellige representasjonsunderrom. Et feed-forward-undernettverk er et enkelt nevralt nettverk som tar utdata fra det flerhodede selvoppmerksomhetsundernettverket, behandler dataene og returnerer de endelige koderrepresentasjonene.
Målet med tilfeldig delnettverksprøvetaking er å trene mindre BERT-modeller som kan prestere godt nok på måloppgaver. Vi prøver 100 tilfeldige undernettverk fra den finjusterte base BERT-modellen og evaluerer 10 nettverk samtidig. De trente undernettverkene blir evaluert for de objektive beregningene og den endelige modellen velges basert på avveiningene som er funnet mellom de objektive beregningene. Vi visualiserer Pareto foran for de samplede undernettverkene, som inneholder den beskjærte modellen som gir den optimale avveiningen mellom modellnøyaktighet og modellstørrelse. Vi velger kandidatundernettverket (NAS-beskåret BERT-modell) basert på modellstørrelsen og modellnøyaktigheten som vi er villige til å bytte. Deretter er vi vert for endepunktene, den forhåndstrente BERT-basismodellen og den NAS-beskjærte BERT-modellen ved hjelp av SageMaker. For å utføre lasttesting bruker vi Locust, et åpen kildekode-lasttestverktøy som du kan implementere ved hjelp av Python. Vi kjører belastningstesting på begge endepunktene ved hjelp av Locust og visualiserer resultatene ved å bruke Pareto-fronten for å illustrere avveiningen mellom responstider og nøyaktighet for begge modellene. Følgende diagram gir en oversikt over arbeidsflyten som er forklart i dette innlegget.
Forutsetninger
For dette innlegget kreves følgende forutsetninger:
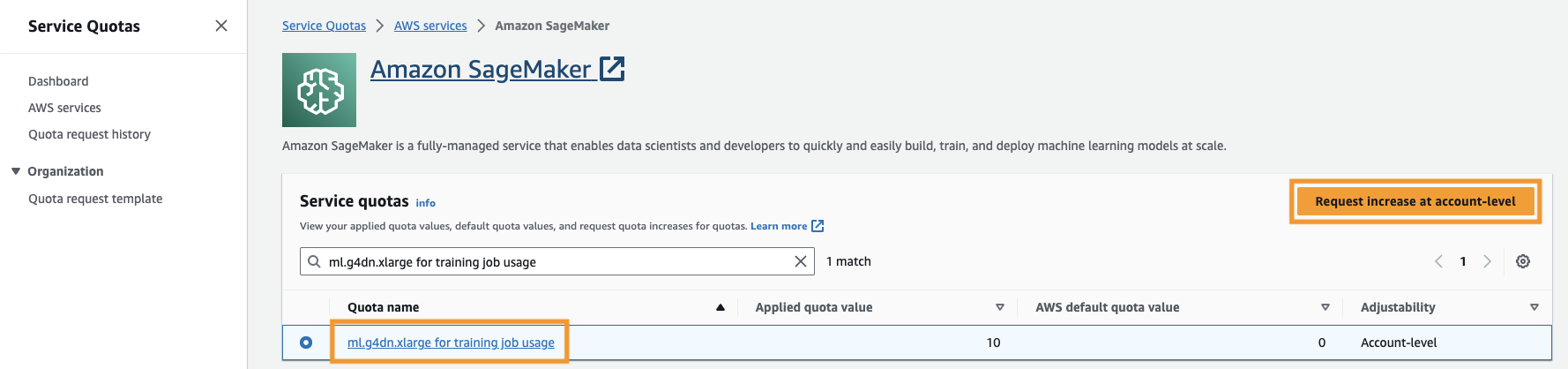
Du må også øke tjenestekvote for å få tilgang til minst tre forekomster av ml.g4dn.xlarge-forekomster i SageMaker. Forekomsttypen ml.g4dn.xlarge er den kostnadseffektive GPU-forekomsten som lar deg kjøre PyTorch native. For å øke tjenestekvoten, fullfør følgende trinn:
- Naviger til Tjenestekvoter på konsollen.
- Til Administrer kvoter, velg Amazon SageMaker, velg deretter Se kvoter.

- Søk etter "ml-g4dn.xlarge for treningsjobbbruk" og velg kvoteelementet.
- Velg Be om økning på kontonivå.
- Til Øk kvoteverdien, skriv inn en verdi på 5 eller høyere.
- Velg Be.
Den forespurte kvotegodkjenningen kan ta litt tid å fullføre, avhengig av kontotillatelsene.

- Åpne SageMaker Studio fra SageMaker-konsollen.

- Velg Systemterminal etter Verktøy og filer.

- Kjør følgende kommando for å klone GitHub repo til SageMaker Studio-forekomsten:
- naviger til
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Åpne filen
nas_for_llm_with_amt.ipynb. - Sett opp miljøet med en
ml.g4dn.xlargeeksempel og velg Plukke ut.

Sett opp den ferdigtrente BERT-modellen
I denne delen importerer vi datasettet Recognizing Textual Entailment fra datasettbiblioteket og deler opp datasettet i opplærings- og valideringssett. Dette datasettet består av setningspar. Oppgaven til BERT PLM er å gjenkjenne, gitt to tekstfragmenter, om betydningen av ett tekstfragment kan utledes fra det andre fragmentet. I det følgende eksempelet kan vi utlede betydningen av den første setningen fra den andre setningen:
Vi laster inn det tekstlig gjenkjennende innholdsdatasettet fra LIM benchmarking suite via datasettbibliotek fra Hugging Face i treningsskriptet vårt (./training.py). Vi deler det originale treningsdatasettet fra GLUE inn i et trenings- og valideringssett. I vår tilnærming finjusterer vi basis BERT-modellen ved å bruke treningsdatasettet, deretter utfører vi et multi-objektiv søk for å identifisere settet med undernettverk som balanserer optimalt mellom de objektive beregningene. Vi bruker treningsdatasettet utelukkende til å finjustere BERT-modellen. Imidlertid bruker vi valideringsdata for multi-objektsøket ved å måle nøyaktigheten på holdout-valideringsdatasettet.
Finjuster BERT PLM ved å bruke et domenespesifikt datasett
De typiske brukstilfellene for en rå BERT-modell inkluderer neste setningsprediksjon eller maskert språkmodellering. For å bruke basis BERT-modellen for nedstrømsoppgaver som tekstgjenkjenning, må vi finjustere modellen ytterligere ved å bruke et domenespesifikt datasett. Du kan bruke en finjustert BERT-modell for oppgaver som sekvensklassifisering, spørsmålssvar og tokenklassifisering. For formålet med denne demoen bruker vi imidlertid den finjusterte modellen for binær klassifisering. Vi finjusterer den forhåndstrente BERT-modellen med treningsdatasettet som vi forberedte tidligere, ved å bruke følgende hyperparametre:
Vi lagrer sjekkpunktet til modellopplæringen til en Amazon enkel lagringstjeneste (Amazon S3) bøtte, slik at modellen kan lastes under det NAS-baserte multi-objektivet søk. Før vi trener modellen, definerer vi beregningene som epoke, treningstap, antall parametere og valideringsfeil:
Etter at finjusteringsprosessen starter, tar treningsjobben rundt 15 minutter å fullføre.
Utfør et multi-objektiv søk for å velge undernettverk og visualisere resultatene
I neste trinn utfører vi et multi-objektiv søk på den finjusterte base BERT-modellen ved å prøve tilfeldige undernettverk ved å bruke SageMaker AMT. For å få tilgang til et undernettverk innenfor supernettverket (den finjusterte BERT-modellen), maskerer vi alle komponentene i PLM som ikke er en del av undernettverket. Maskering av et supernettverk for å finne undernettverk i en PLM er en teknikk som brukes til å isolere og identifisere mønstre for modellens oppførsel. Merk at Hugging Face-transformatorer trenger at den skjulte størrelsen er et multiplum av antall hoder. Den skjulte størrelsen i en transformator PLM kontrollerer størrelsen på det skjulte tilstandsvektorrommet, noe som påvirker modellens evne til å lære komplekse representasjoner og mønstre i dataene. I en BERT PLM har den skjulte tilstandsvektoren en fast størrelse (768). Vi kan ikke endre den skjulte størrelsen, og derfor må antallet hoder være i [1, 3, 6, 12].
I motsetning til enkelt-objektiv optimalisering, i multi-målsettingen, har vi vanligvis ikke en enkelt løsning som samtidig optimaliserer alle mål. I stedet tar vi sikte på å samle et sett med løsninger som dominerer alle andre løsninger i minst ett mål (som valideringsfeil). Nå kan vi starte multi-objektsøket gjennom AMT ved å angi beregningene som vi ønsker å redusere (valideringsfeil og antall parametere). De tilfeldige undernettverkene er definert av parameteren max_jobs og antall samtidige jobber er definert av parameteren max_parallel_jobs. Koden for å laste modellsjekkpunktet og evaluere undernettverket er tilgjengelig i evaluate_subnetwork.py skript.
AMT-innstillingsjobben tar omtrent 2 timer og 20 minutter å kjøre. Etter at AMT-innstillingsjobben er fullført, analyserer vi jobbhistorikken og samler inn undernettverkets konfigurasjoner, for eksempel antall hoder, antall lag, antall enheter og tilsvarende beregninger som valideringsfeil og antall parametere. Følgende skjermbilde viser sammendraget av en vellykket AMT-tunerjobb.
Deretter visualiserer vi resultatene ved å bruke et Pareto-sett (også kjent som Pareto-grense eller Pareto-optimalsett), som hjelper oss med å identifisere optimale sett med undernettverk som dominerer alle andre undernettverk i den objektive metrikken (valideringsfeil):
Først samler vi inn dataene fra AMT-innstillingsjobben. Så plotter vi Pareto-settet ved hjelp av matplotlob.pyplot med antall parametere i x-aksen og valideringsfeil i y-aksen. Dette innebærer at når vi flytter fra ett undernettverk av Pareto-settet til et annet, må vi enten ofre ytelse eller modellstørrelse, men forbedre den andre. Til syvende og sist gir Pareto-settet oss fleksibiliteten til å velge det undernettverket som passer best for våre preferanser. Vi kan bestemme hvor mye vi vil redusere størrelsen på nettverket vårt og hvor mye ytelse vi er villige til å ofre.

Distribuer den finjusterte BERT-modellen og den NAS-optimaliserte undernettverksmodellen ved å bruke SageMaker
Deretter distribuerer vi den største modellen i Pareto-settet vårt som fører til den minste mengde ytelsesdegenerasjon til en SageMaker endepunkt. Den beste modellen er den som gir en optimal avveining mellom valideringsfeilen og antall parametere for vårt brukstilfelle.
Modellsammenligning
Vi tok en forhåndstrent base BERT-modell, finjusterte den ved å bruke et domenespesifikt datasett, kjørte et NAS-søk for å identifisere dominerende undernettverk basert på objektive beregninger, og distribuerte den beskjærte modellen på et SageMaker-endepunkt. I tillegg tok vi den forhåndstrente BERT-basismodellen og distribuerte basismodellen på et andre SageMaker-endepunkt. Deretter løp vi belastningstesting ved å bruke Locust på begge inferensendepunkter og evaluerte ytelsen i form av responstid.
Først importerer vi de nødvendige Locust- og Boto3-bibliotekene. Deretter konstruerer vi en forespørselsmetadata og registrerer starttiden som skal brukes til lasttesting. Deretter sendes nyttelasten til SageMaker-endepunktoppkallings-APIen via BotoClient for å simulere ekte brukerforespørsler. Vi bruker Locust for å få flere virtuelle brukere til å sende forespørsler parallelt og måle endepunktytelsen under belastningen. Tester kjøres ved å øke antall brukere for henholdsvis hvert av de to endepunktene. Etter at testene er fullført, sender Locust ut en CSV-fil for forespørselsstatistikk for hver av de utplasserte modellene.
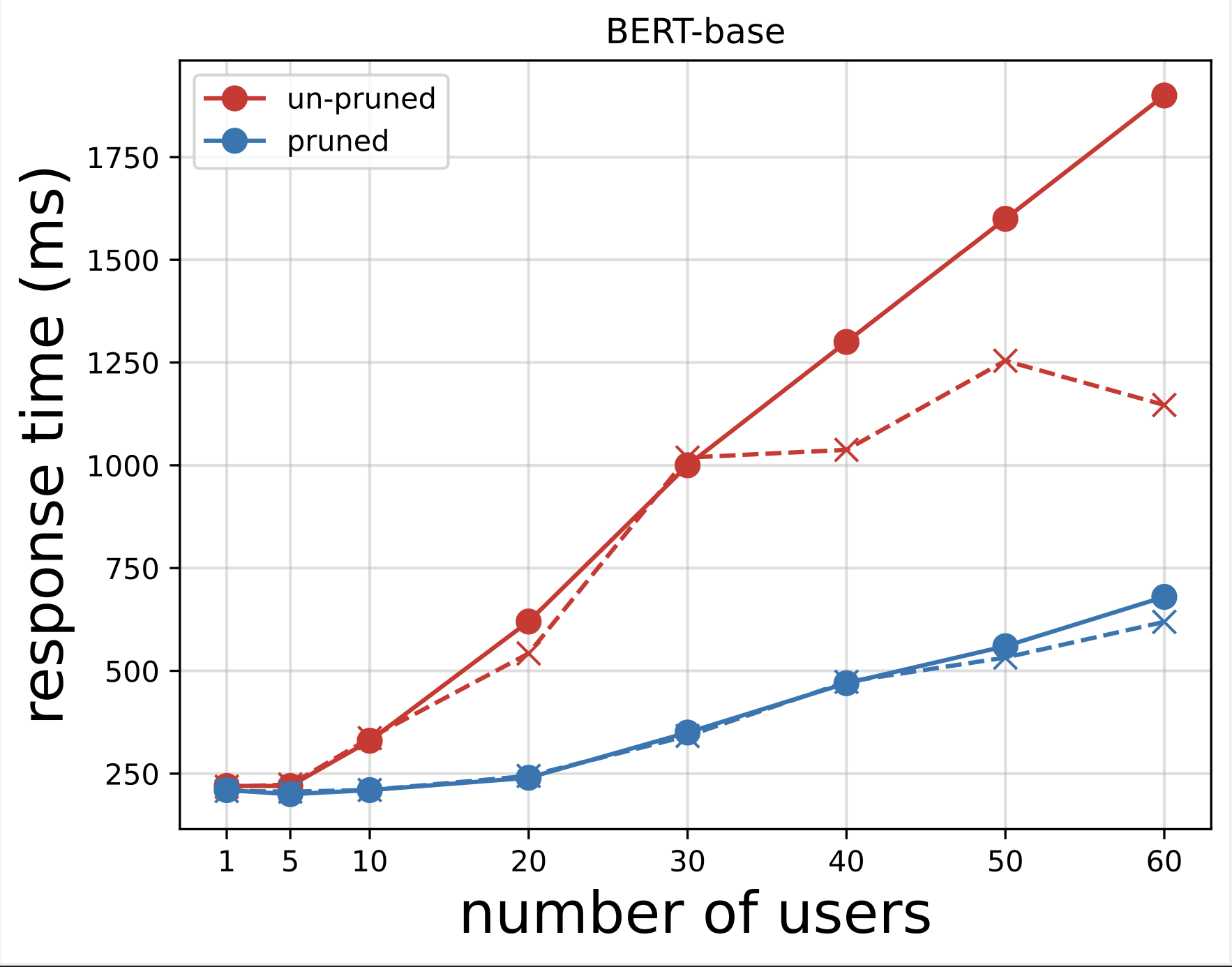
Deretter genererer vi responstidsplottene fra CSV-filene som er lastet ned etter å ha kjørt testene med Locust. Hensikten med å plotte responstiden vs. antall brukere er å analysere belastningstestresultatene ved å visualisere effekten av responstiden til modellens endepunkter. I det følgende diagrammet kan vi se at det NAS-beskjærte modellendepunktet oppnår en lavere responstid sammenlignet med base BERT-modellendepunktet.
I det andre diagrammet, som er en forlengelse av det første diagrammet, observerer vi at etter rundt 70 brukere, begynner SageMaker å strupe base BERT-modellens endepunkt og kaster et unntak. For den NAS-beskjærte modellens endepunkt skjer imidlertid strupingen mellom 90–100 brukere og med lavere responstid.

Fra de to diagrammene observerer vi at den beskjærte modellen har en raskere responstid og skalerer bedre sammenlignet med den ubeskjærte modellen. Etter hvert som vi skalerer antallet inferensendepunkter, slik tilfellet er med brukere som distribuerer et stort antall inferensendepunkter for sine PLM-applikasjoner, begynner kostnadsfordelene og ytelsesforbedringen å bli ganske betydelig.
Rydd opp
For å slette SageMaker-endepunktene for den finjusterte BERT-basismodellen og den NAS-beskjærte modellen, fullfør følgende trinn:
- Velg på SageMaker-konsollen slutning og endepunkter i navigasjonsruten.
- Velg endepunktet og slett det.
Alternativt, fra SageMaker Studio-notisboken, kjør følgende kommandoer ved å oppgi endepunktnavnene:
konklusjonen
I dette innlegget diskuterte vi hvordan du bruker NAS til å beskjære en finjustert BERT-modell. Vi trente først en basis BERT-modell ved å bruke domenespesifikke data og distribuerte den til et SageMaker-endepunkt. Vi utførte et multi-objektiv søk på den finjusterte base BERT-modellen ved å bruke SageMaker AMT for en måloppgave. Vi visualiserte Pareto-fronten og valgte Pareto-optimal NAS-beskåret BERT-modell og distribuerte modellen til et andre SageMaker-endepunkt. Vi utførte lasttesting med Locust for å simulere brukere som spør etter begge endepunktene, og målte og registrerte responstidene i en CSV-fil. Vi plottet responstiden vs. antall brukere for begge modellene.
Vi observerte at den beskjærte BERT-modellen presterte betydelig bedre både i responstid og forekomst av strupingsterskel. Vi konkluderte med at den NAS-beskjærte modellen var mer motstandsdyktig mot økt belastning på endepunktet, og opprettholdt en lavere responstid selv om flere brukere stresset systemet sammenlignet med basis BERT-modellen. Du kan bruke NAS-teknikken beskrevet i dette innlegget på enhver stor språkmodell for å finne en beskjært modell som kan utføre måloppgaven med betydelig lavere responstid. Du kan optimalisere tilnærmingen ytterligere ved å bruke latens som en parameter i tillegg til valideringstap.
Selv om vi bruker NAS i dette innlegget, er kvantisering en annen vanlig tilnærming som brukes for å optimalisere og komprimere PLM-modeller. Kvantisering reduserer presisjonen til vektene og aktiveringene i et trent nettverk fra 32-bits flytende punkt til lavere bitbredder som 8-bits eller 16-biters heltall, noe som resulterer i en komprimert modell som genererer raskere inferens. Kvantisering reduserer ikke antall parametere; i stedet reduserer det presisjonen til de eksisterende parameterne for å få en komprimert modell. NAS-beskjæring fjerner redundante nettverk i en PLM, noe som skaper en sparsom modell med færre parametere. Vanligvis brukes NAS-beskjæring og kvantisering sammen for å komprimere store PLM-er for å opprettholde modellnøyaktighet, redusere valideringstap samtidig som ytelsen forbedres og modellstørrelsen reduseres. De andre ofte brukte teknikkene for å redusere størrelsen på PLM-er inkluderer kunnskapsdestillasjon, matrisefaktoriseringog destillasjonskaskader.
Tilnærmingen som er foreslått i blogginnlegget er egnet for team som bruker SageMaker til å trene og finjustere modellene ved å bruke domenespesifikke data og distribuere endepunktene for å generere inferens. Hvis du ser etter en fullstendig administrert tjeneste som tilbyr et utvalg av høyytende fundamentmodeller som trengs for å bygge generative AI-applikasjoner, bør du vurdere å bruke Amazonas grunnfjell. Hvis du ser etter forhåndsopplærte, åpen kildekode-modeller for et bredt spekter av forretningsbruk og ønsker tilgang til løsningsmaler og eksempelnotatbøker, bør du vurdere å bruke Amazon SageMaker JumpStart. En forhåndsopplært versjon av Hugging Face BERT-modellen med baseomslag som vi brukte i dette innlegget, er også tilgjengelig fra SageMaker JumpStart.
Om forfatterne
 Aparajithan Vaidyanathan er hovedarkitekt for bedriftsløsninger hos AWS. Han er en skyarkitekt med 24+ års erfaring med å designe og utvikle store og distribuerte programvaresystemer. Han spesialiserer seg på generativ AI og maskinlæringsdatateknikk. Han er en aspirerende maratonløper og hobbyene hans inkluderer fotturer, sykling og tilbringe tid med kona og to gutter.
Aparajithan Vaidyanathan er hovedarkitekt for bedriftsløsninger hos AWS. Han er en skyarkitekt med 24+ års erfaring med å designe og utvikle store og distribuerte programvaresystemer. Han spesialiserer seg på generativ AI og maskinlæringsdatateknikk. Han er en aspirerende maratonløper og hobbyene hans inkluderer fotturer, sykling og tilbringe tid med kona og to gutter.
 Aaron Klein er en Sr Applied Scientist ved AWS som jobber med automatiserte maskinlæringsmetoder for dype nevrale nettverk.
Aaron Klein er en Sr Applied Scientist ved AWS som jobber med automatiserte maskinlæringsmetoder for dype nevrale nettverk.
 Jacek Golebiowski er en Sr Applied Scientist ved AWS.
Jacek Golebiowski er en Sr Applied Scientist ved AWS.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- : har
- :er
- :ikke
- :hvor
- ][s
- $OPP
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- evne
- I stand
- adgang
- Logg inn
- nøyaktighet
- Oppnå
- oppnår
- aktiveringer
- tillegg
- Adopsjon
- Etter
- AI
- sikte
- Sikter
- algoritmer
- Alle
- tillate
- tillate
- tillater
- også
- Amazon
- Amazon Web Services
- beløp
- an
- analyse
- analytics
- analysere
- og
- En annen
- besvare
- noen
- api
- søknader
- anvendt
- Påfør
- påføring
- tilnærming
- godkjenning
- ca
- arkitektur
- ER
- AREA
- områder
- argumenter
- rundt
- kunstig
- kunstige nevrale nettverk
- AS
- håper
- tildelt
- assosiert
- At
- forsøker
- delta
- Automatisert
- automatisert maskinlæring
- automatiserer
- Automatisk
- Automatisere
- Automatisering
- tilgjengelig
- AWS
- Axis
- Balansere
- basen
- basert
- BE
- bli
- før du
- atferd
- referansemåling
- Fordeler
- BEST
- Bedre
- mellom
- Bit
- kroppen
- både
- bygge
- virksomhet
- Forretningsprosess
- Automatisering av forretningsprosesser
- men
- by
- CAN
- kandidat
- evner
- saken
- saker
- katalog
- endring
- Figur
- Topplisten
- chatbots
- valg
- Velg
- valgt ut
- klasse
- klassifisering
- Klinisk
- tett
- Cloud
- kode
- samle
- samling
- kombinasjoner
- kommersiell
- Felles
- vanligvis
- sammenlignet
- fullføre
- Terminado
- komplekse
- kompleksitet
- komponenter
- beregnings
- Beregn
- konsepter
- konkluderte
- Vurder
- består
- Konsoll
- begrensninger
- konstruere
- forbruk
- inneholder
- innhold
- innholdsskaping
- kontekst
- fortsette
- kontrast
- kontroller
- Tilsvarende
- Kostnad
- Kostnader
- telle
- skape
- skaper
- skaperverket
- kunde
- Kundeservice
- dato
- datavitenskap
- datasett
- dato tid
- bestemme
- Beslutningstaking
- dedikert
- dyp
- dype nevrale nettverk
- definere
- definert
- definere
- Demo
- demonstrere
- avhengig
- utplassere
- utplassert
- utplasserings
- Distribueres
- beskrevet
- utforming
- utforme
- ønsket
- utvikle
- forskjellig
- diskutert
- distribueres
- dokument
- ikke
- dominerende
- dominerer
- ikke
- to
- under
- e
- hver enkelt
- effektivitet
- effektiv
- enten
- Endpoint
- endepunkter
- Ingeniørarbeid
- Motorer
- nok
- Enter
- Enterprise
- virksomhetsadopsjon
- Enterprise Solutions
- enhet
- entry
- Miljø
- epoke
- feil
- Eter (ETH)
- evaluere
- evaluert
- evalueringer
- Selv
- hendelser
- eksempel
- Unntatt
- unntak
- utelukkende
- eksisterende
- erfaring
- Forklar
- forklarte
- forlengelse
- Face
- falsk
- raskere
- Egenskaper
- tilbakemelding
- færre
- felt
- filet
- Filer
- slutt~~POS=TRUNC
- Finn
- finne
- Først
- fikset
- fleksibilitet
- flytende
- etter
- Fotspor
- Til
- funnet
- Fundament
- fra
- foran
- Frontier
- fullt
- funksjon
- videre
- generere
- genererer
- generative
- Generativ AI
- få
- gitt
- mål
- GPU
- grå
- skjer
- Ha
- he
- hode
- .
- helsetjenester
- hjelper
- skjult
- høytytende
- høyere
- vandreturer
- hans
- historie
- Hobbyer
- vert
- vert
- TIMER
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- Klem ansikt
- Optimalisering av hyperparameter
- Innstilling av hyperparameter
- i
- identifisere
- iDX
- if
- illustrere
- Påvirkning
- Konsekvenser
- iverksette
- importere
- forbedre
- forbedret
- forbedring
- bedre
- in
- inkludere
- Øke
- økt
- økende
- informasjon
- Infrastruktur
- inngang
- f.eks
- forekomster
- i stedet
- Intelligent
- inn
- IT
- DET ER
- Jobb
- Jobb
- jpg
- JSON
- kunnskap
- kjent
- Språk
- stor
- storskala
- største
- Ventetid
- lag
- lag
- Fører
- LÆRE
- læring
- minst
- la
- bibliotekene
- Bibliotek
- linje
- laste
- logg
- logging
- ser
- tap
- tap
- lavere
- maskin
- maskinlæring
- vedlikeholde
- opprettholde
- mann
- fikk til
- Marathon
- maske
- matplotlib
- maksimal
- Kan..
- betyr
- måle
- målte
- måling
- medisinsk
- Møt
- Minne
- metadata
- metoder
- metrisk
- Metrics
- kunne
- minimere
- minutter
- ML
- modell
- modellering
- modeller
- modulære
- mer
- flytte
- mye
- flere
- må
- navn
- oppkalt
- navn
- ved
- Naturlig
- Naturlig språk
- Natural Language Processing
- Naviger
- Navigasjon
- nødvendig
- Trenger
- nødvendig
- behov
- nettverk
- nettverk
- neural
- nevrale nettverket
- nevrale nettverk
- neste
- nlp
- none
- note
- bærbare
- notatbøker
- nå
- Antall
- objekt
- Målet
- mål
- observere
- observerte
- of
- off
- tilby
- Tilbud
- on
- ONE
- på nett
- nettbutikk
- bare
- åpen
- åpen kildekode
- optimal
- optimalisering
- Optimalisere
- optimalisert
- Optimaliserer
- optimalisere
- or
- rekkefølge
- original
- Annen
- vår
- ut
- produksjon
- utganger
- enn
- samlet
- oversikt
- egen
- par
- brød
- Parallel
- parameter
- parametere
- Pareto
- del
- bestått
- banen
- pasient
- mønstre
- utføre
- ytelse
- utført
- utfører
- utfører
- tillatelser
- plato
- Platon Data Intelligence
- PlatonData
- Point
- poeng
- stillinger
- Post
- Precision
- prediksjon
- prediktiv
- Predictor
- preferanser
- forberedt
- forutsetninger
- presentere
- tidligere
- Principal
- Problem
- prosess
- Prosessautomatisering
- Prosesser
- prosessering
- Produkt
- produktivitet
- Produktivitetsverktøy
- foreslått
- leverandør
- gir
- gi
- trekke
- Trekker
- formål
- formål
- Python
- pytorch
- Q & A
- spørsmål
- ganske
- tilfeldig
- område
- rask
- priser
- Raw
- ekte
- anerkjennelse
- gjenkjenne
- gjenkjenne
- Anbefaling
- anbefalinger
- rekord
- registrert
- Rød
- redusere
- Redusert
- reduserer
- regresjon
- i slekt
- Fjerner
- fjerne
- Rapporter
- representasjon
- anmode
- Forespurt
- forespørsler
- påkrevd
- Krav
- spenstig
- ressurs
- Ressurser
- henholdsvis
- svar
- Resultater
- forhandler
- støttemur
- avkastning
- riding
- Risiko
- RAD
- Kjør
- runner
- rennende
- går
- s
- ofre
- sagemaker
- SageMaker Inference
- Spar
- Skala
- vekter
- Vitenskap
- Forsker
- Resultat
- script
- Søk
- Søkemotorer
- søker
- Sekund
- Seksjon
- se
- velg
- valgt
- SELV
- send
- dømme
- sentiment
- Sequence
- tjeneste
- Tjenester
- Session
- sett
- sett
- innstilling
- Viser
- signaler
- betydelig
- Enkelt
- samtidig
- samtidig
- enkelt
- Størrelse
- mindre
- So
- Software
- løsning
- Solutions
- noen
- kilde
- Rom
- Gyte
- spesialisert
- spesialisert
- spesifikk
- spesielt
- utgifter
- splittet
- Begynn
- starter
- Tilstand
- statistikk
- Trinn
- Steps
- lagring
- strukturell
- strukturert
- studio
- betydelig
- vellykket
- vellykket
- slik
- egnet
- suite
- SAMMENDRAG
- system
- Systemer
- T
- Ta
- tar
- Target
- Oppgave
- oppgaver
- lag
- teknikk
- teknikker
- maler
- vilkår
- Testing
- tester
- tekst
- Tekstklassifisering
- tekstlig
- enn
- Det
- De
- deres
- deretter
- Der.
- derfor
- Disse
- denne
- tre
- terskel
- Gjennom
- tid
- ganger
- til
- sammen
- token
- tok
- verktøy
- verktøy
- handel
- trading
- Tog
- trent
- Kurs
- transformator
- transformers
- sant
- prøve
- to
- typen
- typer
- typisk
- typisk
- Til syvende og sist
- etter
- gjennomgår
- forståelse
- lomper
- us
- bruke
- bruk sak
- brukt
- Bruker
- Brukere
- bruker
- ved hjelp av
- validering
- verdi
- Verdier
- versjon
- av
- virtuelle
- visualisere
- vs
- ønsker
- var
- we
- web
- webtjenester
- VI VIL
- når
- om
- hvilken
- mens
- HVEM
- bred
- Bred rekkevidde
- allment
- kone
- Wikipedia
- vil
- villig
- med
- innenfor
- Arbeid
- arbeidsflyt
- arbeid
- X
- år
- Utbytte
- du
- Din
- zephyrnet