Et av de mest nyttige applikasjonsmønstrene for generative AI-arbeidsbelastninger er Retrieval Augmented Generation (RAG). I RAG-mønsteret finner vi deler av referanseinnhold relatert til en input-forespørsel ved å utføre likhetssøk på innebygginger. Innebygginger fanger opp informasjonsinnholdet i tekster, slik at modeller for naturlig språkbehandling (NLP) kan jobbe med språk i en numerisk form. Innebygginger er bare vektorer av flyttall, så vi kan analysere dem for å svare på tre viktige spørsmål: Er referansedataene våre i endring over tid? Forandrer spørsmålene brukerne stiller seg over tid? Og til slutt, hvor godt dekker referansedataene våre spørsmålene som stilles?
I dette innlegget vil du lære om noen av hensynene for å bygge inn vektoranalyse og oppdage signaler om innebyggingsdrift. Fordi embeddings er en viktig kilde til data for NLP-modeller generelt og generative AI-løsninger spesielt, trenger vi en måte å måle om vår embeddings endrer seg over tid (drifting). I dette innlegget vil du se et eksempel på å utføre driftdeteksjon på innebygde vektorer ved å bruke en klyngeteknikk med store språkmodeller (LLMS) distribuert fra Amazon SageMaker JumpStart. Du vil også kunne utforske disse konseptene gjennom to gitte eksempler, inkludert en ende-til-ende eksempelapplikasjon eller, eventuelt, en undergruppe av applikasjonen.
Oversikt over RAG
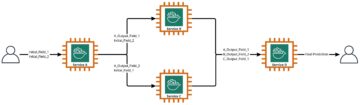
De RAG mønster lar deg hente kunnskap fra eksterne kilder, for eksempel PDF-dokumenter, wiki-artikler eller samtaleavskrifter, og deretter bruke denne kunnskapen til å utvide instruksjonsmeldingen som sendes til LLM. Dette gjør at LLM kan referere til mer relevant informasjon når den genererer et svar. Hvis du for eksempel spør en LLM hvordan man lager sjokoladekjeks, kan det inneholde informasjon fra ditt eget oppskriftsbibliotek. I dette mønsteret blir oppskriftsteksten konvertert til embedding-vektorer ved hjelp av en embedding-modell, og lagret i en vektordatabase. Innkommende spørsmål konverteres til innebygginger, og deretter kjører vektordatabasen et likhetssøk for å finne relatert innhold. Spørsmålet og referansedataene går deretter inn i ledeteksten for LLM.
La oss ta en nærmere titt på de innebygde vektorene som blir opprettet og hvordan du utfører driftanalyse på disse vektorene.
Analyse på innebygde vektorer
Innebyggingsvektorer er numeriske representasjoner av dataene våre, så analyse av disse vektorene kan gi innsikt i referansedataene våre som senere kan brukes til å oppdage potensielle signaler om drift. Innebyggingsvektorer representerer et element i n-dimensjonalt rom, hvor n ofte er stor. For eksempel lager GPT-J 6B-modellen, brukt i dette innlegget, vektorer med størrelse 4096. For å måle drift, anta at applikasjonen vår fanger opp innebyggingsvektorer for både referansedata og innkommende meldinger.
Vi starter med å utføre dimensjonsreduksjon ved hjelp av Principal Component Analysis (PCA). PCA prøver å redusere antall dimensjoner samtidig som det bevarer mesteparten av variansen i dataene. I dette tilfellet prøver vi å finne antall dimensjoner som bevarer 95 % av variansen, som skal fange opp alt innenfor to standardavvik.
Deretter bruker vi K-Means for å identifisere et sett med klyngesentre. K-Means prøver å gruppere punkter i klynger slik at hver klynge er relativt kompakt og klyngene er så fjernt fra hverandre som mulig.
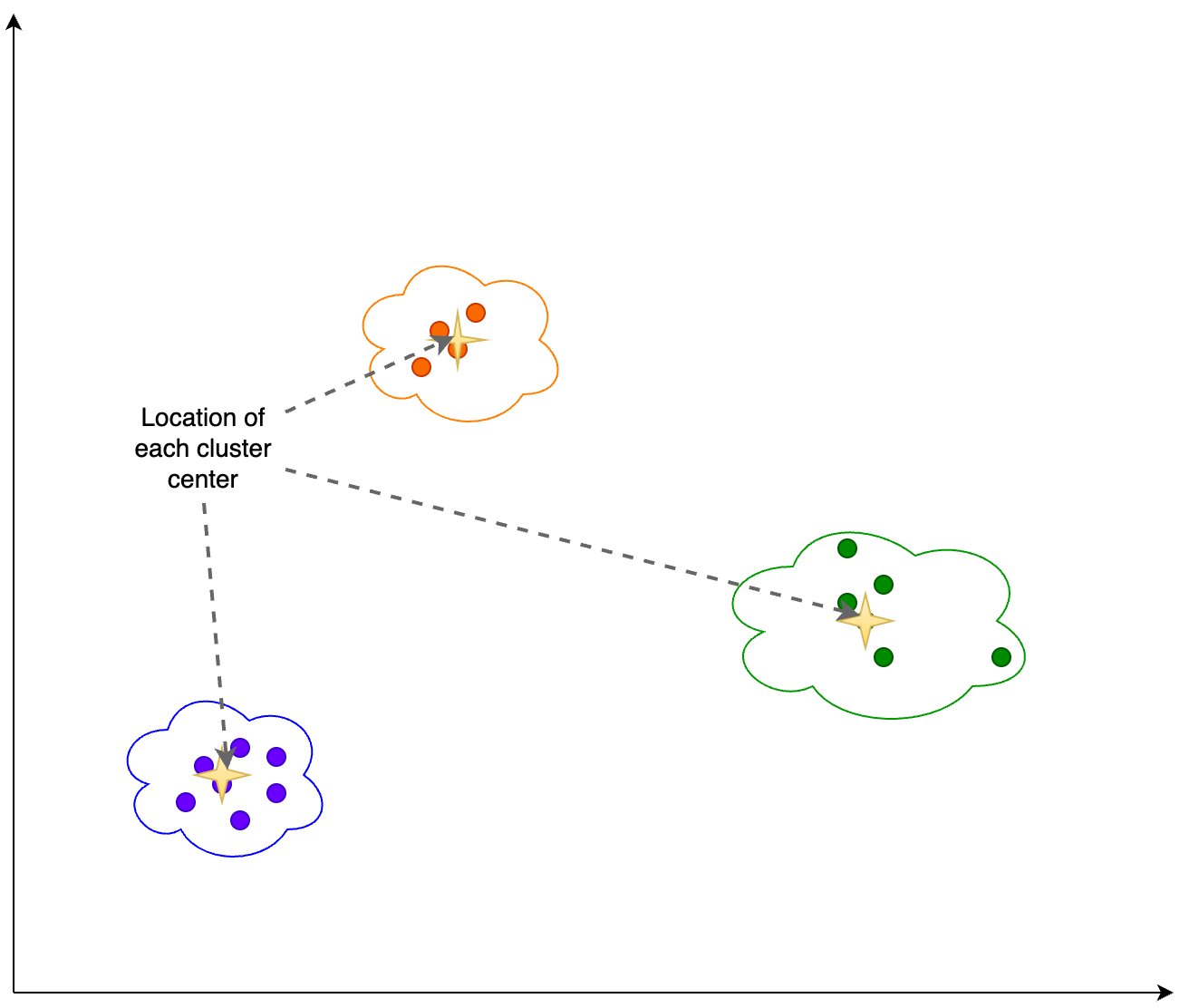
Vi beregner følgende informasjon basert på klyngeutgangen vist i følgende figur:
- Antall dimensjoner i PCA som forklarer 95 % av variansen
- Plasseringen av hvert klyngesenter, eller tyngdepunkt
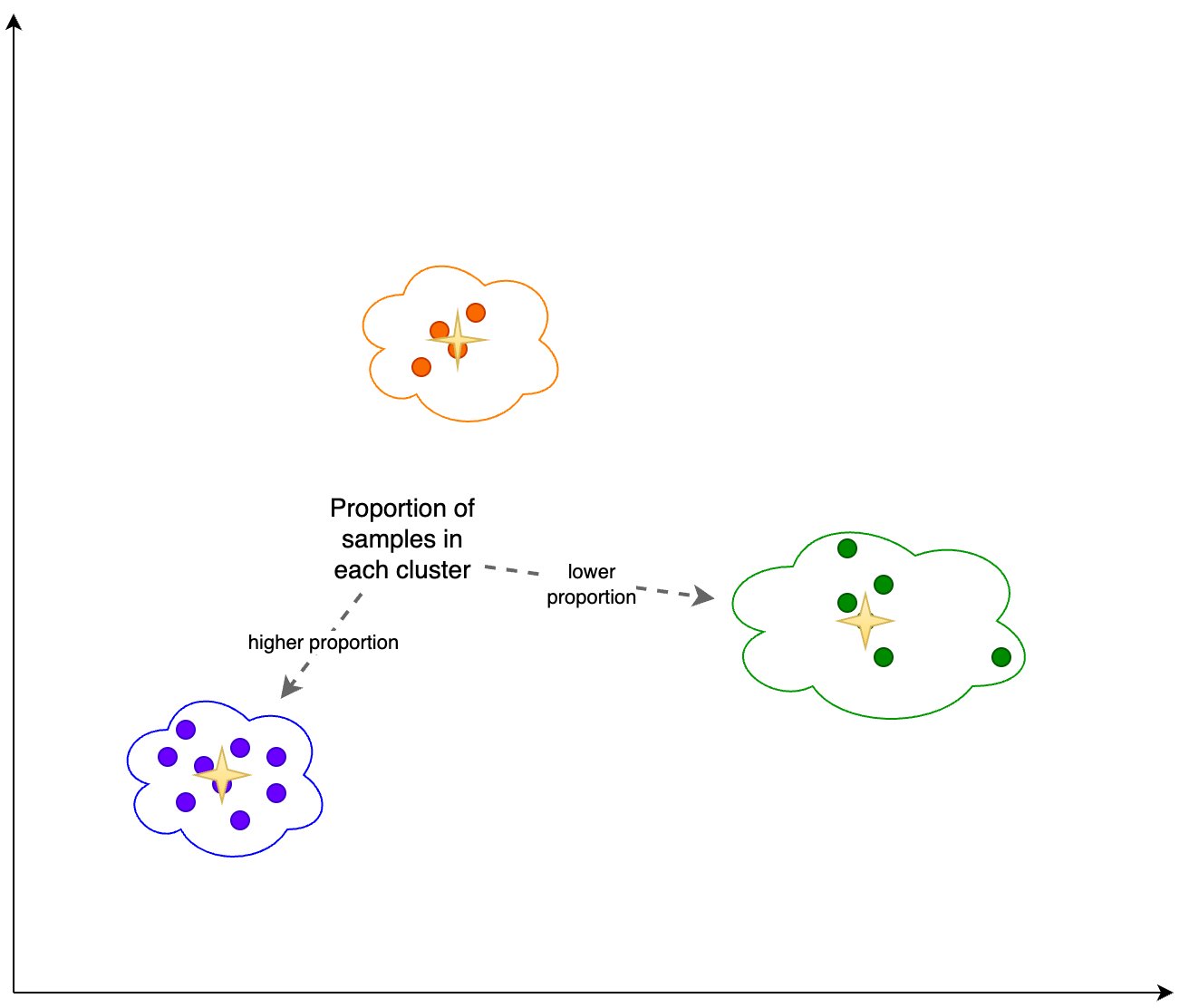
I tillegg ser vi på andelen (høyere eller lavere) av prøver i hver klynge, som vist i følgende figur.
Til slutt bruker vi denne analysen til å beregne følgende:
- Treghet – Treghet er summen av kvadrerte avstander til cluster centroids, som måler hvor godt dataene ble gruppert ved bruk av K-Means.
- Silhouette score – Silhouette-skåren er et mål for validering av konsistensen i klynger, og varierer fra -1 til 1. En verdi nær 1 betyr at punktene i en klynge er nær de andre punktene i samme klynge og langt fra punktene til de andre klyngene. En visuell representasjon av silhuettskåren kan sees i følgende figur.

Vi kan med jevne mellomrom fange denne informasjonen for øyeblikksbilder av innebyggingene for både kildereferansedataene og ledetekstene. Å fange disse dataene lar oss analysere potensielle signaler om innebyggingsdrift.
Oppdager innebyggingsdrift
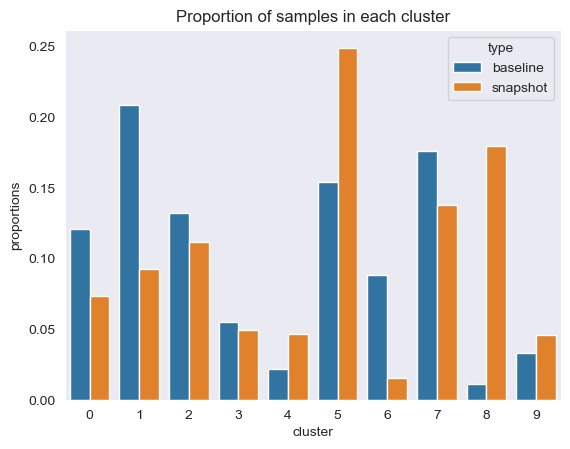
Med jevne mellomrom kan vi sammenligne klyngeinformasjonen gjennom øyeblikksbilder av dataene, som inkluderer referansedatainnbyggingene og ledetekstene. Først kan vi sammenligne antall dimensjoner som trengs for å forklare 95 % av variasjonen i innebyggingsdataene, tregheten og silhuettpoengsummen fra klyngejobben. Som du kan se i tabellen nedenfor, sammenlignet med en grunnlinje, krever det siste øyeblikksbildet av innebygginger 39 flere dimensjoner for å forklare variansen, noe som indikerer at dataene våre er mer spredt. Tregheten har gått opp, noe som indikerer at prøvene er samlet lenger unna klyngesentrene deres. I tillegg har silhuettpoengsummen gått ned, noe som indikerer at klyngene ikke er like godt definert. For raske data kan det tyde på at spørsmålstypene som kommer inn i systemet dekker flere emner.
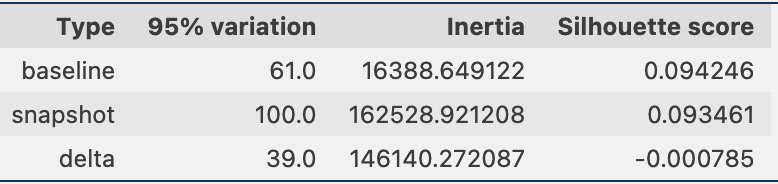
Deretter kan vi i den følgende figuren se hvordan andelen prøver i hver klynge har endret seg over tid. Dette kan vise oss om våre nyere referansedata er stort sett lik det forrige settet, eller dekker nye områder.
Til slutt kan vi se om klyngesentrene beveger seg, noe som vil vise drift i informasjonen i klyngene, som vist i følgende tabell.

Referansedatadekning for innkommende spørsmål
Vi kan også vurdere hvor godt referansedataene våre stemmer overens med de innkommende spørsmålene. For å gjøre dette, tilordner vi hver ledetekst-innbygging til en referansedataklynge. Vi beregner avstanden fra hver ledetekst til dens tilsvarende senter, og ser på gjennomsnittet, medianen og standardavviket for disse avstandene. Vi kan lagre den informasjonen og se hvordan den endrer seg over tid.
Følgende figur viser et eksempel på å analysere avstanden mellom ledetekstinnbygging og referansedatasentre over tid.

Som du kan se, synker gjennomsnitts-, median- og standardavviksavstandsstatistikken mellom prompt-innbygginger og referansedatasentre mellom den opprinnelige grunnlinjen og det siste øyeblikksbildet. Selv om den absolutte verdien av avstanden er vanskelig å tolke, kan vi bruke trendene til å avgjøre om den semantiske overlappingen mellom referansedata og innkommende spørsmål blir bedre eller verre over tid.
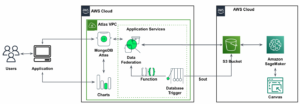
Eksempel på søknad
For å samle de eksperimentelle resultatene som ble diskutert i forrige seksjon, bygde vi en eksempelapplikasjon som implementerer RAG-mønsteret ved å bruke innbyggings- og generasjonsmodeller distribuert gjennom SageMaker JumpStart og vert på Amazon SageMaker endepunkter i sanntid.
Applikasjonen har tre kjernekomponenter:
- Vi bruker en interaktiv flyt, som inkluderer et brukergrensesnitt for å fange opp meldinger, kombinert med et RAG-orkestreringslag, ved bruk av LangChain.
- Databehandlingsflyten trekker ut data fra PDF-dokumenter og lager innbygginger som blir lagret i Amazon OpenSearch-tjeneste. Vi bruker også disse i den endelige innbyggingsdriftanalysekomponenten i applikasjonen.
- Innstøpingene fanges opp i Amazon enkel lagringstjeneste (Amazon S3) via Amazon Kinesis Data Firehose, og vi kjører en kombinasjon av AWS Lim trekke ut, transformere og laste (ETL)-jobber og Jupyter-notatbøker for å utføre innbyggingsanalysen.
Følgende diagram illustrerer ende-til-ende-arkitekturen.
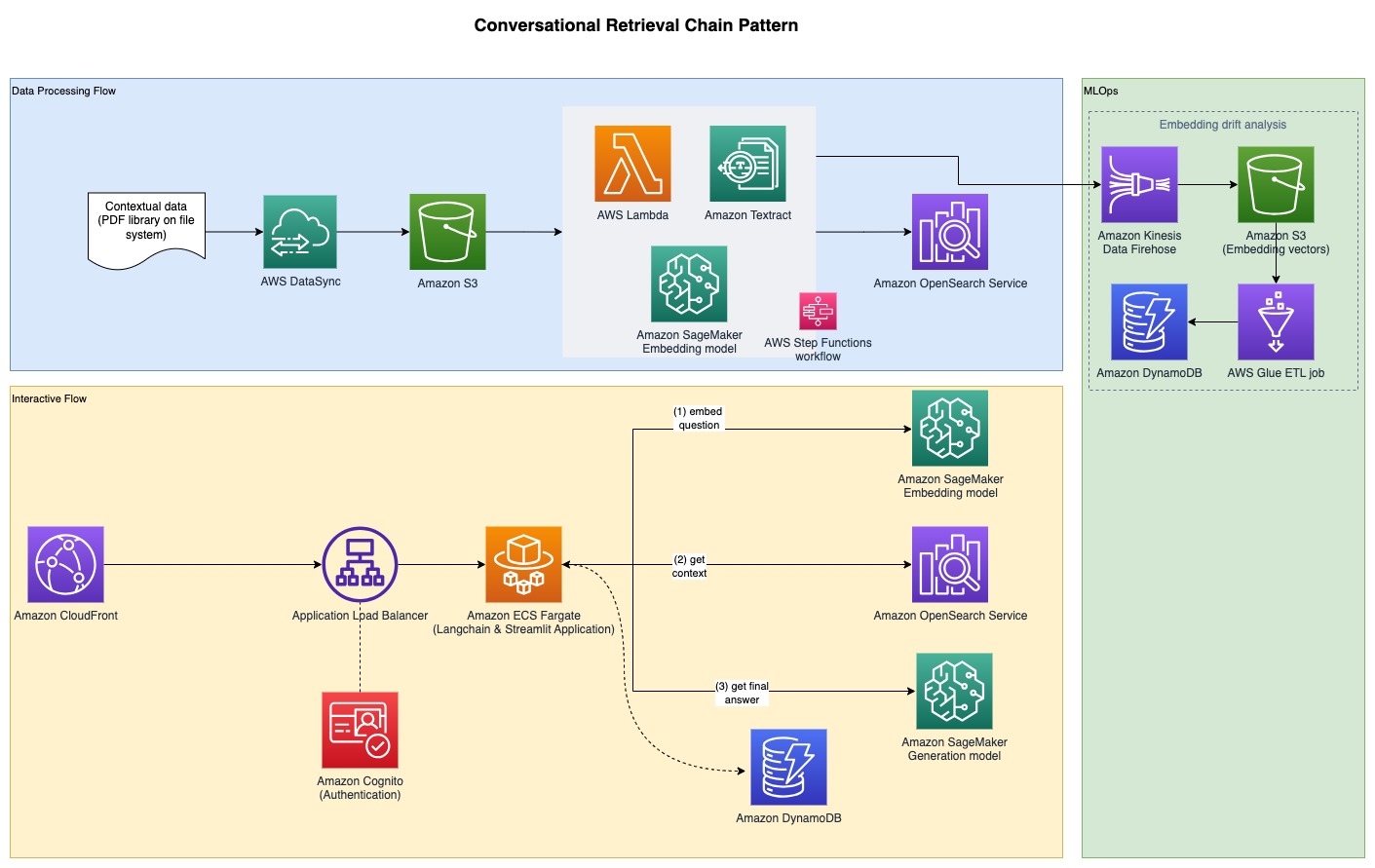
Den fullstendige prøvekoden er tilgjengelig på GitHub. Den medfølgende koden er tilgjengelig i to forskjellige mønstre:
- Prøv full-stack-applikasjon med en Streamlit frontend – Dette gir en ende-til-ende-applikasjon, inkludert et brukergrensesnitt som bruker Streamlit for å fange opp meldinger, kombinert med RAG-orkestreringslaget, ved å bruke LangChain som kjører på Amazon Elastic Container Service (Amazon ECS) med AWS Fargate
- Backend-applikasjon – For de som ikke vil distribuere hele applikasjonsstabelen, kan du velge å bare distribuere backend AWS skyutviklingssett (AWS CDK) stabel, og bruk deretter Jupyter-notatboken som følger med for å utføre RAG-orkestrering ved hjelp av LangChain
For å lage de oppgitte mønstrene er det flere forutsetninger som er beskrevet i de følgende delene, og starter med å distribuere de generative modellene og tekstinnbyggingsmodellene og deretter gå videre til de ekstra forutsetningene.
Distribuer modeller gjennom SageMaker JumpStart
Begge mønstrene forutsetter utplassering av en innebyggingsmodell og en generativ modell. For dette vil du distribuere to modeller fra SageMaker JumpStart. Den første modellen, GPT-J 6B, brukes som innbyggingsmodell og den andre modellen, Falcon-40b, brukes til tekstgenerering.
Du kan distribuere hver av disse modellene gjennom SageMaker JumpStart fra AWS-administrasjonskonsoll, Amazon SageMaker Studio, eller programmatisk. For mer informasjon, se Slik bruker du JumpStart-fundamentmodeller. For å forenkle distribusjonen kan du bruke medfølgende notatbok avledet fra notatbøker automatisk opprettet av SageMaker JumpStart. Denne notatboken henter modellene fra SageMaker JumpStart ML-huben og distribuerer dem til to separate SageMaker sanntidsendepunkter.
Eksempelnotisboken har også en oppryddingsdel. Ikke kjør den delen ennå, fordi den vil slette endepunktene som nettopp er distribuert. Du vil fullføre oppryddingen på slutten av gjennomgangen.
Etter å ha bekreftet vellykket distribusjon av endepunktene, er du klar til å distribuere hele prøveprogrammet. Men hvis du er mer interessert i å utforske bare backend- og analysenotatbøkene, kan du eventuelt distribuere bare det, som er dekket i neste avsnitt.
Alternativ 1: Implementer kun backend-applikasjonen
Dette mønsteret lar deg bare distribuere backend-løsningen og samhandle med løsningen ved hjelp av en Jupyter-notisbok. Bruk dette mønsteret hvis du ikke vil bygge ut hele grensesnittet.
Forutsetninger
Du bør ha følgende forutsetninger:
- Et endepunkt fra SageMaker JumpStart-modellen er utplassert – Distribuer modellene til SageMaker sanntidsendepunkter ved hjelp av SageMaker JumpStart, som tidligere skissert
- Implementeringsparametere – Registrer følgende:
- Tekstmodellens endepunktnavn – Endepunktnavnet til tekstgenereringsmodellen som er distribuert med SageMaker JumpStart
- Navn på endepunkt for innebyggingsmodell – Endepunktnavnet til innebyggingsmodellen som er distribuert med SageMaker JumpStart
Distribuer ressursene ved å bruke AWS CDK
Bruk distribusjonsparameterne som er nevnt i forrige avsnitt for å distribuere AWS CDK-stakken. For mer informasjon om AWS CDK-installasjon, se Komme i gang med AWS CDK.
Sørg for at Docker er installert og kjører på arbeidsstasjonen som skal brukes til AWS CDK-distribusjon. Referere til Skaff deg Docker for ytterligere veiledning.
Alternativt kan du angi kontekstverdiene i en fil som heter cdk.context.json i pattern1-rag/cdk katalog og kjør cdk deploy BackendStack --exclusively.
Utrullingen vil skrive ut utdata, hvorav noen vil være nødvendig for å kjøre den bærbare datamaskinen. Før du kan begynne med spørsmål og svar, må du bygge inn referansedokumentene, som vist i neste avsnitt.
Legg inn referansedokumenter
For denne RAG-tilnærmingen blir referansedokumenter først innebygd med en tekstinnbyggingsmodell og lagret i en vektordatabase. I denne løsningen er det bygget en inntakspipeline som tar inn PDF-dokumenter.
An Amazon Elastic Compute Cloud (Amazon EC2)-forekomst er opprettet for PDF-dokumentet og en Amazon elastisk filsystem (Amazon EFS) filsystem er montert på EC2-forekomsten for å lagre PDF-dokumentene. An AWS DataSync oppgaven kjøres hver time for å hente PDF-dokumenter som finnes i EFS-filsystembanen og laste dem opp til en S3-bøtte for å starte tekstinnbyggingsprosessen. Denne prosessen bygger inn referansedokumentene og lagrer innebyggingene i OpenSearch Service. Den lagrer også et innebyggingsarkiv til en S3-bøtte gjennom Kinesis Data Firehose for senere analyse.
For å innta referansedokumentene, fullfør følgende trinn:
- Hent eksempel-EC2-forekomst-IDen som ble opprettet (se AWS CDK-utdata
JumpHostId) og koble til ved hjelp av Session Manager, en evne til AWS systemansvarlig. For instruksjoner, se Koble til Linux-instansen din med AWS Systems Manager Session Manager. - Gå til katalogen
/mnt/efs/fs1, som er der EFS-filsystemet er montert, og lag en mappe kaltingest: - Legg til dine referanse PDF-dokumenter til
ingestkatalogen.
DataSync-oppgaven er konfigurert til å laste opp alle filene som finnes i denne katalogen til Amazon S3 for å starte innbyggingsprosessen.
DataSync-oppgaven kjører på en timeplan; du kan eventuelt starte oppgaven manuelt for å starte innbyggingsprosessen umiddelbart for PDF-dokumentene du har lagt til.
- For å starte oppgaven, finn oppgave-ID-en fra AWS CDK-utgangen
DataSyncTaskIDog starte oppgaven med standardinnstillinger.
Etter at innbyggingene er opprettet, kan du starte RAG-spørsmålet og svaret gjennom en Jupyter-notisbok, som vist i neste avsnitt.
Spørsmål og svar ved hjelp av en Jupyter-notisbok
Fullfør følgende trinn:
- Hent navnet på SageMaker notatbokforekomsten fra AWS CDK-utdata
NotebookInstanceNameog koble til JupyterLab fra SageMaker-konsollen. - Gå til katalogen
fmops/full-stack/pattern1-rag/notebooks/. - Åpne og kjør notatboken
query-llm.ipynbi den bærbare forekomsten for å utføre spørsmål og svar ved å bruke RAG.
Sørg for å bruke conda_python3 kjerne for den bærbare datamaskinen.
Dette mønsteret er nyttig for å utforske backend-løsningen uten å måtte sørge for ytterligere forutsetninger som kreves for fullstack-applikasjonen. Den neste delen dekker implementeringen av en fullstack-applikasjon, inkludert både frontend- og backend-komponentene, for å gi et brukergrensesnitt for samhandling med din generative AI-applikasjon.
Alternativ 2: Implementer prøveapplikasjonen i full stack med en Streamlit-frontend
Dette mønsteret lar deg distribuere løsningen med et brukergrensesnitt for spørsmål og svar.
Forutsetninger
For å distribuere eksempelapplikasjonen må du ha følgende forutsetninger:
- SageMaker JumpStart-modellendepunkt utplassert – Distribuer modellene til dine SageMaker sanntidsendepunkter ved å bruke SageMaker JumpStart, som beskrevet i forrige avsnitt, ved å bruke de medfølgende notatbøkene.
- Amazon Route 53 vertssone - Lag en Amazon Route 53 offentlig vertssone å bruke for denne løsningen. Du kan også bruke en eksisterende rute 53 offentlig vertssone, som f.eks
example.com. - AWS Certificate Manager-sertifikat – Bestemmelse an AWS Certificate Manager (ACM) TLS-sertifikat for domenenavnet for Route 53 hosted sone og dets gjeldende underdomener, som f.eks.
example.comog*.example.comfor alle underdomener. For instruksjoner, se Be om offentlig attest. Dette sertifikatet brukes til å konfigurere HTTPS på Amazon CloudFront og original lastbalanser. - Implementeringsparametere – Registrer følgende:
- Egendefinert domenenavn for grensesnittapplikasjon – Et tilpasset domenenavn som brukes for å få tilgang til frontend-eksempelapplikasjonen. Domenenavnet som er oppgitt brukes til å lage en Route 53 DNS-post som peker til frontend CloudFront-distribusjonen; for eksempel,
app.example.com. - Lastbalanseropprinnelse tilpasset domenenavn – Et tilpasset domenenavn som brukes for opprinnelsen til CloudFront-distribusjonslastbalanser. Domenenavnet som er oppgitt brukes til å opprette en Route 53 DNS-post som peker til opprinnelseslastbalanseren; for eksempel,
app-lb.example.com. - Rute 53 vert sone ID – Route 53-verts sone-ID for å være vert for de tilpassede domenenavnene som er oppgitt; for eksempel,
ZXXXXXXXXYYYYYYYYY. - Rute 53 vert sonenavn – Navnet på den vertsbaserte sonen for Route 53 for å være vert for de tilpassede domenenavnene som er oppgitt; for eksempel,
example.com. - ACM-sertifikat ARN – ARN for ACM-sertifikatet som skal brukes med det tilpassede domenet som er oppgitt.
- Tekstmodellens endepunktnavn – Endepunktnavnet til tekstgenereringsmodellen som er distribuert med SageMaker JumpStart.
- Navn på endepunkt for innebyggingsmodell – Endepunktnavnet til innebyggingsmodellen som er distribuert med SageMaker JumpStart.
- Egendefinert domenenavn for grensesnittapplikasjon – Et tilpasset domenenavn som brukes for å få tilgang til frontend-eksempelapplikasjonen. Domenenavnet som er oppgitt brukes til å lage en Route 53 DNS-post som peker til frontend CloudFront-distribusjonen; for eksempel,
Distribuer ressursene ved å bruke AWS CDK
Bruk distribusjonsparameterne du noterte i forutsetningene for å distribuere AWS CDK-stakken. For mer informasjon, se Komme i gang med AWS CDK.
Sørg for at Docker er installert og kjører på arbeidsstasjonen som skal brukes for AWS CDK-distribusjonen.
I den foregående koden representerer -c en kontekstverdi, i form av de nødvendige forutsetningene, gitt ved inndata. Alternativt kan du angi kontekstverdiene i en fil som heter cdk.context.json i pattern1-rag/cdk katalog og kjør cdk deploy --all.
Merk at vi spesifiserer regionen i filen bin/cdk.ts. Konfigurering av ALB-tilgangslogger krever en spesifisert region. Du kan endre denne regionen før distribusjon.
Utrullingen vil skrive ut URL-en for å få tilgang til Streamlit-applikasjonen. Før du kan begynne å stille spørsmål og svare, må du bygge inn referansedokumentene, som vist i neste avsnitt.
Bygg inn referansedokumentene
For en RAG-tilnærming blir referansedokumenter først innebygd med en tekstinnbyggingsmodell og lagret i en vektordatabase. I denne løsningen er det bygget en inntakspipeline som tar inn PDF-dokumenter.
Som vi diskuterte i det første distribusjonsalternativet, har en eksempel EC2-forekomst blitt opprettet for PDF-dokumentet, og et EFS-filsystem er montert på EC2-forekomsten for å lagre PDF-dokumentene. En DataSync-oppgave kjøres hver time for å hente PDF-dokumenter som finnes i EFS-filsystembanen og laste dem opp til en S3-bøtte for å starte tekstinnbyggingsprosessen. Denne prosessen bygger inn referansedokumentene og lagrer innebyggingene i OpenSearch Service. Den lagrer også et innebyggingsarkiv til en S3-bøtte gjennom Kinesis Data Firehose for senere analyse.
For å innta referansedokumentene, fullfør følgende trinn:
- Hent eksempel-EC2-forekomst-IDen som ble opprettet (se AWS CDK-utdata
JumpHostId) og koble til ved hjelp av Session Manager. - Gå til katalogen
/mnt/efs/fs1, som er der EFS-filsystemet er montert, og lag en mappe kaltingest: - Legg til dine referanse PDF-dokumenter til
ingestkatalogen.
DataSync-oppgaven er konfigurert til å laste opp alle filene som finnes i denne katalogen til Amazon S3 for å starte innbyggingsprosessen.
DataSync-oppgaven kjører på en timeplan. Du kan eventuelt starte oppgaven manuelt for å starte innbyggingsprosessen umiddelbart for PDF-dokumentene du la til.
- For å starte oppgaven, finn oppgave-ID-en fra AWS CDK-utgangen
DataSyncTaskIDog starte oppgaven med standardinnstillinger.
Spørsmål og svar
Etter at referansedokumentene er innebygd, kan du starte RAG-spørsmålet og svaret ved å gå til URL-en for å få tilgang til Streamlit-applikasjonen. An Amazon Cognito autentiseringslag brukes, så det krever å opprette en brukerkonto i Amazon Cognito-brukerpoolen distribuert via AWS CDK (se AWS CDK-utdata for brukerpoolnavnet) for førstegangstilgang til applikasjonen. For instruksjoner om hvordan du oppretter en Amazon Cognito-bruker, se Opprette en ny bruker i AWS Management Console.
Legg inn driftanalyse
I denne delen viser vi deg hvordan du utfører driftanalyse ved først å lage en grunnlinje for referansedatainnbyggingene og ledetekstinnbyggingene, og deretter lage et øyeblikksbilde av innebyggingene over tid. Dette lar deg sammenligne grunnlinjeinnbyggingene med øyeblikksbildeinnbyggingene.
Opprett en innbyggingsgrunnlinje for referansedataene og ledeteksten
For å opprette en innbyggingsgrunnlinje for referansedataene, åpne AWS Glue-konsollen og velg ETL-jobben embedding-drift-analysis. Still inn parameterne for ETL-jobben som følger og kjør jobben:
- Sett
--job_typetilBASELINE. - Sett
--out_tabletil Amazon DynamoDB tabell for referanse for innebyggingsdata. (Se AWS CDK-utgangenDriftTableReferencefor tabellnavnet.) - Sett
--centroid_tabletil DynamoDB-tabellen for referansesenterdata. (Se AWS CDK-utgangenCentroidTableReferencefor tabellnavnet.) - Sett
--data_pathtil S3-bøtta med prefikset; for eksempel,s3:///embeddingarchive/. (Se AWS CDK-utgangenBucketNamefor bøttenavnet.)
På samme måte bruker ETL-jobben embedding-drift-analysis, opprett en innbyggingsgrunnlinje for ledetekstene. Still inn parameterne for ETL-jobben som følger og kjør jobben:
- Sett
--job_typetilBASELINE - Sett
--out_tabletil DynamoDB-tabellen for rask innebygging av data. (Se AWS CDK-utgangenDriftTablePromptsNamefor tabellnavnet.) - Sett
--centroid_tabletil DynamoDB-tabellen for prompte sentroiddata. (Se AWS CDK-utgangenCentroidTablePromptsfor tabellnavnet.) - Sett
--data_pathtil S3-bøtta med prefikset; for eksempel,s3:///promptarchive/. (Se AWS CDK-utgangenBucketNamefor bøttenavnet.)
Opprett et innebygd øyeblikksbilde for referansedataene og ledeteksten
Etter at du har lagt inn tilleggsinformasjon i OpenSearch Service, kjører du ETL-jobben embedding-drift-analysis igjen for å ta et øyeblikksbilde av referansedatainnbyggingene. Parametrene vil være de samme som ETL-jobben som du kjørte for å opprette innbyggingsgrunnlinjen for referansedataene som vist i forrige avsnitt, med unntak av å angi --job_type parameter til SNAPSHOT.
På samme måte, for å ta et øyeblikksbilde av ledetekstinnbyggingene, kjør ETL-jobben embedding-drift-analysis en gang til. Parametrene vil være de samme som ETL-jobben du kjørte for å opprette innbyggingsgrunnlinjen for ledetekstene som vist i forrige seksjon, med unntak av å angi --job_type parameter til SNAPSHOT.
Sammenlign grunnlinjen med øyeblikksbildet
For å sammenligne innbyggingsgrunnlinjen og øyeblikksbildet for referansedata og ledetekster, bruk den medfølgende notatboken pattern1-rag/notebooks/drift-analysis.ipynb.
For å se på innbyggingssammenligning for referansedata eller ledetekster, endre DynamoDB-tabellnavnvariablene (tbl og c_tbl) i den bærbare datamaskinen til den aktuelle DynamoDB-tabellen for hver kjøring av den.
Notebook-variabelen tbl bør endres til riktig drifttabellnavn. Følgende er et eksempel på hvor variabelen skal konfigureres i notatboken.

Tabellnavnene kan hentes frem som følger:
- For referanseinnbyggingsdata, hent drifttabellnavnet fra AWS CDK-utdata
DriftTableReference - For spørsmål om innebyggingsdata, hent drifttabellnavnet fra AWS CDK-utdata
DriftTablePromptsName
I tillegg er den bærbare variabelen c_tbl bør endres til riktig tyngdepunktstabellnavn. Følgende er et eksempel på hvor variabelen skal konfigureres i notatboken.

Tabellnavnene kan hentes frem som følger:
- For referanseinnbyggingsdata, hent tyngdepunktstabellnavnet fra AWS CDK-utgangen
CentroidTableReference - Hent tyngdepunktstabellnavnet fra AWS CDK-utdata for spørsmål om innebygging
CentroidTablePrompts
Analyser forespørselsavstanden fra referansedataene
Kjør først AWS Glue-jobben embedding-distance-analysis. Denne jobben vil finne ut hvilken klynge, fra K-Means-evalueringen av referansedatainnbyggingene, som hver prompt tilhører. Den beregner deretter gjennomsnittet, medianen og standardavviket for avstanden fra hver ledetekst til midten av den tilsvarende klyngen.
Du kan kjøre notatboken pattern1-rag/notebooks/distance-analysis.ipynb for å se trendene i avstandsberegningene over tid. Dette vil gi deg en følelse av den generelle trenden i fordelingen av de raske innbyggingsavstandene.
Notatboken pattern1-rag/notebooks/prompt-distance-outliers.ipynb er en AWS Glue-notisbok som ser etter uteliggere, som kan hjelpe deg med å identifisere om du får flere meldinger som ikke er relatert til referansedataene.
Overvåk likhetspoeng
Alle likhetspoeng fra OpenSearch Service er pålogget Amazon CloudWatch under rag navneområde. Dashbordet RAG_Scores viser gjennomsnittlig poengsum og totalt antall inntatt poengsum.
Rydd opp
For å unngå fremtidige kostnader, slett alle ressursene du har opprettet.
Slett de utplasserte SageMaker-modellene
Referer til oppryddingsdelen av gitt eksempel notatbok for å slette de utplasserte SageMaker JumpStart-modellene, eller du kan slette modellene på SageMaker-konsollen.
Slett AWS CDK-ressursene
Hvis du skrev inn parametrene dine i en cdk.context.json fil, rydd opp som følger:
Hvis du skrev inn parametrene dine på kommandolinjen og bare distribuerte backend-applikasjonen (backend AWS CDK-stakken), ryd opp som følger:
Hvis du skrev inn parameterne dine på kommandolinjen og implementerte den fullstendige løsningen (frontend og backend AWS CDK-stablene), ryd opp som følger:
konklusjonen
I dette innlegget ga vi et fungerende eksempel på en applikasjon som fanger opp innebyggingsvektorer for både referansedata og ledetekster i RAG-mønsteret for generativ AI. Vi viste hvordan man utfører klyngeanalyse for å finne ut om referanse- eller promptdata driver over tid, og hvor godt referansedataene dekker typene spørsmål brukere stiller. Hvis du oppdager drift, kan det gi et signal om at miljøet har endret seg og modellen din får nye input som den kanskje ikke er optimalisert for å håndtere. Dette gir mulighet for proaktiv evaluering av gjeldende modell mot endrede input.
Om forfatterne
 Abdullahi Olaoye er Senior Solutions Architect hos Amazon Web Services (AWS). Abdullahi har en MSC i Computer Networking fra Wichita State University og er en publisert forfatter som har hatt roller på tvers av ulike teknologidomener som DevOps, modernisering av infrastruktur og AI. Han er for tiden fokusert på Generativ AI og spiller en nøkkelrolle i å hjelpe bedrifter med å designe og bygge banebrytende løsninger drevet av Generativ AI. Utenfor teknologiens rike finner han glede i kunsten å utforske. Når han ikke lager AI-løsninger, liker han å reise med familien for å utforske nye steder.
Abdullahi Olaoye er Senior Solutions Architect hos Amazon Web Services (AWS). Abdullahi har en MSC i Computer Networking fra Wichita State University og er en publisert forfatter som har hatt roller på tvers av ulike teknologidomener som DevOps, modernisering av infrastruktur og AI. Han er for tiden fokusert på Generativ AI og spiller en nøkkelrolle i å hjelpe bedrifter med å designe og bygge banebrytende løsninger drevet av Generativ AI. Utenfor teknologiens rike finner han glede i kunsten å utforske. Når han ikke lager AI-løsninger, liker han å reise med familien for å utforske nye steder.
 Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han jobbet med datasyn for autonome kjøretøy. Han har også en MBA fra Colorado State University. Randy har hatt en rekke stillinger innen teknologiområdet, alt fra programvareutvikling til produktadministrasjon. In gikk inn i Big Data-området i 2013 og fortsetter å utforske det området. Han jobber aktivt med prosjekter i ML-området og har presentert på en rekke konferanser inkludert Strata og GlueCon.
Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han jobbet med datasyn for autonome kjøretøy. Han har også en MBA fra Colorado State University. Randy har hatt en rekke stillinger innen teknologiområdet, alt fra programvareutvikling til produktadministrasjon. In gikk inn i Big Data-området i 2013 og fortsetter å utforske det området. Han jobber aktivt med prosjekter i ML-området og har presentert på en rekke konferanser inkludert Strata og GlueCon.
 Shelbee Eigenbrode er en hovedarkitekt for AI og maskinlæringsløsninger hos Amazon Web Services (AWS). Hun har vært innen teknologi i 24 år og spenner over flere bransjer, teknologier og roller. Hun fokuserer for tiden på å kombinere sin DevOps- og ML-bakgrunn i MLOps-domenet for å hjelpe kunder med å levere og administrere ML-arbeidsmengder i stor skala. Med over 35 patenter gitt på tvers av ulike teknologidomener, har hun en lidenskap for kontinuerlig innovasjon og bruk av data for å drive forretningsresultater. Shelbee er medskaper og instruktør for spesialiseringen Practical Data Science på Coursera. Hun er også meddirektør for Women In Big Data (WiBD), kapittel i Denver. På fritiden liker hun å tilbringe tid med familie, venner og overaktive hunder.
Shelbee Eigenbrode er en hovedarkitekt for AI og maskinlæringsløsninger hos Amazon Web Services (AWS). Hun har vært innen teknologi i 24 år og spenner over flere bransjer, teknologier og roller. Hun fokuserer for tiden på å kombinere sin DevOps- og ML-bakgrunn i MLOps-domenet for å hjelpe kunder med å levere og administrere ML-arbeidsmengder i stor skala. Med over 35 patenter gitt på tvers av ulike teknologidomener, har hun en lidenskap for kontinuerlig innovasjon og bruk av data for å drive forretningsresultater. Shelbee er medskaper og instruktør for spesialiseringen Practical Data Science på Coursera. Hun er også meddirektør for Women In Big Data (WiBD), kapittel i Denver. På fritiden liker hun å tilbringe tid med familie, venner og overaktive hunder.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/monitor-embedding-drift-for-llms-deployed-from-amazon-sagemaker-jumpstart/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 2%
- 2013
- 24
- 35%
- 39
- 4
- 53
- 62
- 7
- 9
- 90
- 95%
- a
- I stand
- Om oss
- Absolute
- adgang
- Logg inn
- ACM
- tvers
- aktivt
- la til
- tillegg
- Ytterligere
- Tilleggsinformasjon
- I tillegg
- en gang til
- mot
- aggregat
- AI
- Justerer
- Alle
- tillate
- tillater
- også
- Selv
- Amazon
- Amazon Cognito
- Amazon EC2
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- Amazon Web Services (AWS)
- an
- analyse
- analysere
- analyserer
- og
- besvare
- besvare
- hva som helst
- aktuelt
- Søknad
- tilnærming
- hensiktsmessig
- arkitektur
- Arkiv
- ER
- AREA
- områder
- Kunst
- artikler
- AS
- spør
- spør
- bistå
- anta
- At
- øke
- augmented
- Autentisering
- forfatter
- automatisk
- autonom
- autonome kjøretøyer
- tilgjengelig
- gjennomsnittlig
- unngå
- borte
- AWS
- AWS Lim
- Backend
- bakgrunn
- swing
- basert
- Baseline
- BE
- fordi
- vært
- før du
- være
- tilhører
- Bedre
- mellom
- Beyond
- Stor
- Store data
- organer
- både
- bredt
- bygge
- bygget
- virksomhet
- by
- beregne
- beregner
- ring
- som heter
- CAN
- evne
- fangst
- fanget
- fanger
- fange
- saken
- CD
- sentrum
- Sentre
- sertifikat
- endring
- endret
- Endringer
- endring
- Kapittel
- avgifter
- chip
- Sjokolade
- Velg
- ren
- Lukke
- nærmere
- Cloud
- Cluster
- gruppering
- kode
- Colorado
- kombinasjon
- kombinert
- kombinere
- kommer
- kompakt
- sammenligne
- sammenlignet
- sammenligning
- fullføre
- komponent
- komponenter
- Beregn
- datamaskin
- Datamaskin syn
- konsepter
- konferanser
- konfigurert
- konfigurering
- Koble
- betraktninger
- konsistens
- Konsoll
- Container
- innhold
- kontekst
- fortsetter
- kontinuerlig
- konvertert
- cookies
- Kjerne
- Tilsvarende
- Coursera
- dekning
- dekket
- dekker
- dekker
- skape
- opprettet
- skaper
- Opprette
- Gjeldende
- I dag
- skikk
- Kunder
- skjærekant
- dashbord
- dato
- datasentre
- databehandling
- datavitenskap
- Database
- avtagende
- mislighold
- definert
- slette
- leverer
- Denver
- utplassere
- utplassert
- utplasserings
- distribusjon
- Distribueres
- Avledet
- ødelegge
- detaljert
- oppdage
- Gjenkjenning
- Bestem
- Utvikling
- avvik
- DevOps
- diagram
- forskjellig
- vanskelig
- Dimensjon
- dimensjoner
- diskutert
- fordelt
- avstand
- Fjern
- distribusjon
- dns
- do
- Docker
- dokument
- dokumenter
- hunder
- domene
- Domain Name
- DOMENENAVN
- domener
- ikke
- ned
- stasjonen
- hver enkelt
- embed
- innebygd
- embedding
- slutt
- ende til ende
- Endpoint
- endepunkter
- Ingeniørarbeid
- Enter
- kom inn
- bedrifter
- Miljø
- Eter (ETH)
- evaluere
- evaluering
- Hver
- eksempel
- eksempler
- unntak
- eksisterende
- eksperimentell
- Forklar
- leting
- utforske
- Utforske
- utvendig
- trekke ut
- ekstrakter
- familie
- langt
- Figur
- filet
- Filer
- slutt~~POS=TRUNC
- Endelig
- Finn
- funn
- Først
- flytende
- flyten
- fokuserte
- fokusering
- etter
- følger
- Til
- skjema
- funnet
- Fundament
- venner
- fra
- Frontend
- fullt
- framtid
- samle
- general
- genererer
- generasjonen
- generative
- Generativ AI
- generativ modell
- få
- få
- Gi
- Go
- borte
- innvilget
- Gruppe
- veiledning
- håndtere
- Ha
- he
- Held
- hjelpe
- her
- høyere
- hans
- holder
- vert
- vert
- time
- Hvordan
- Hvordan
- Men
- HTML
- http
- HTTPS
- Hub
- ID
- identifisere
- if
- illustrerer
- umiddelbart
- gjennomføring
- redskaper
- viktig
- in
- inkludere
- inkluderer
- Inkludert
- Innkommende
- indikerer
- indikerer
- bransjer
- treghet
- informasjon
- Infrastruktur
- innledende
- Innovasjon
- inngang
- innganger
- innsikt
- installasjon
- f.eks
- instruksjoner
- samhandle
- samhandler
- interaktiv
- interessert
- Interface
- inn
- IT
- DET ER
- Jobb
- Jobb
- glede
- jpg
- Jupyter Notebook
- bare
- nøkkel
- Kinesis Data brannslange
- kunnskap
- Språk
- stor
- seinere
- siste
- lag
- LÆRE
- læring
- Lar
- Bibliotek
- liker
- linje
- linux
- llm
- laste
- plassering
- logget
- Se
- UTSEENDE
- lavere
- maskin
- maskinlæring
- gjøre
- administrer
- ledelse
- leder
- manuelt
- Kan..
- MBA
- bety
- midler
- måle
- målinger
- Metrics
- Michigan
- kunne
- ML
- MLOps
- modell
- modeller
- modernisering
- Overvåke
- mer
- mest
- flytting
- flere
- må
- navn
- navn
- Naturlig
- Naturlig språk
- Natural Language Processing
- Trenger
- nødvendig
- trenger
- nettverk
- Ny
- nyere
- neste
- nlp
- bærbare
- notatbøker
- bemerket
- Antall
- tall
- mange
- of
- ofte
- on
- bare
- åpen
- optimalisert
- Alternativ
- or
- orkestre
- rekkefølge
- Origin
- Annen
- vår
- ut
- utfall
- skissert
- produksjon
- utganger
- enn
- samlet
- overlapping
- egen
- parameter
- parametere
- Spesielt
- lidenskap
- Patenter
- banen
- Mønster
- mønstre
- utføre
- utfører
- stykker
- rørledning
- steder
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Point
- poeng
- basseng
- stillinger
- mulig
- Post
- potensiell
- powered
- Praktisk
- forut
- forutsetninger
- presentert
- bevarer
- bevarer
- forrige
- tidligere
- Principal
- Skrive ut
- Proaktiv
- prosess
- prosessering
- Produkt
- produktledelse
- prosjekter
- ledetekster
- Andelen
- gi
- forutsatt
- gir
- forsyning
- offentlig
- publisert
- Trekker
- spørsmål
- spørsmål
- fille
- serier
- spenner
- klar
- sanntids
- riket
- .
- rekord
- redusere
- reduksjon
- referere
- referanse
- region
- i slekt
- relativt
- relevant
- representere
- representasjon
- representerer
- påkrevd
- Krever
- Ressurser
- svar
- Resultater
- gjenfinning
- Rolle
- roller
- Rute
- Kjør
- rennende
- går
- sagemaker
- samme
- Spar
- Skala
- planlegge
- Vitenskap
- Resultat
- score
- Søk
- søk
- Sekund
- Seksjon
- seksjoner
- se
- sett
- velg
- semantisk
- senior
- forstand
- sendt
- separat
- tjeneste
- Tjenester
- Session
- sett
- innstilling
- flere
- hun
- bør
- Vis
- viste
- vist
- Viser
- Signal
- signaler
- lignende
- Enkelt
- forenkle
- Størrelse
- Snapshot
- So
- Software
- software engineering
- løsning
- Solutions
- noen
- kilde
- Kilder
- Rom
- Spenning
- spesialist
- spesifisert
- bruke
- squared
- stable
- Stabler
- Standard
- Begynn
- startet
- Start
- Tilstand
- statistikk
- Steps
- lagring
- oppbevare
- lagret
- vellykket
- slik
- sum
- sikker
- system
- Systemer
- bord
- Ta
- Oppgave
- teknikk
- Technologies
- Teknologi
- tekst
- tekstgenerering
- Det
- De
- informasjonen
- Kilden
- deres
- Dem
- deretter
- Der.
- Disse
- denne
- De
- tre
- Gjennom
- tid
- TLS
- til
- sammen
- temaer
- Totalt
- Transform
- Traveling
- Trend
- Trender
- prøver
- prøve
- to
- typer
- etter
- universitet
- University of Michigan
- URL
- us
- bruke
- brukt
- nyttig
- Bruker
- Brukergrensesnitt
- Brukere
- ved hjelp av
- validering
- verdi
- Verdier
- variabel
- variabler
- variasjon
- ulike
- vektor
- vektorer
- Kjøretøy
- av
- syn
- visuell
- walkthrough
- ønsker
- var
- Vei..
- we
- web
- webtjenester
- VI VIL
- når
- om
- hvilken
- mens
- vil
- med
- innenfor
- uten
- Dame
- Arbeid
- arbeidet
- arbeid
- arbeidsstasjon
- verre
- ville
- år
- ennå
- du
- Din
- zephyrnet
- sonen