Amazon OpenSearch-tjeneste nylig introdusert Multi-AZ med standby, et distribusjonsalternativ designet for å gi bedrifter økt tilgjengelighet og konsistent ytelse for kritiske arbeidsbelastninger. Med denne funksjonen kan administrerte klynger oppnå 99.99 % tilgjengelighet mens de forblir motstandsdyktige mot soneinfrastrukturfeil.
I dette innlegget utforsker vi hvordan søk og indeksering fungerer med Multi-AZ med Standby og dykker ned i de underliggende mekanismene som bidrar til påliteligheten, enkelheten og feiltoleransen.
Bakgrunn
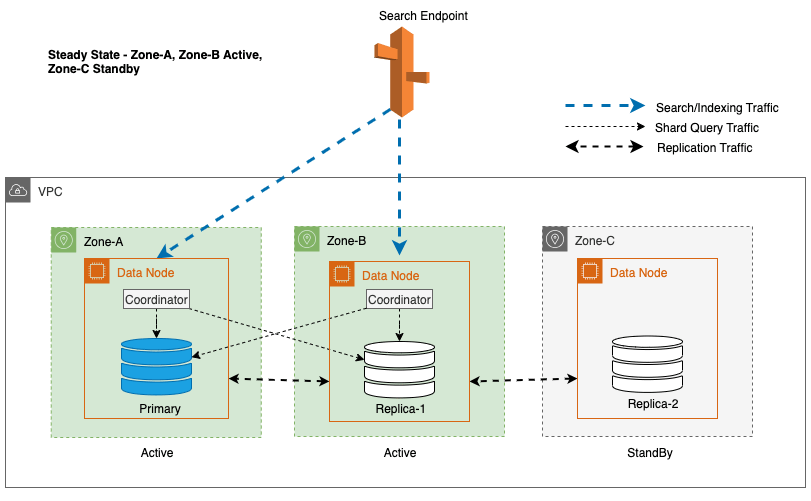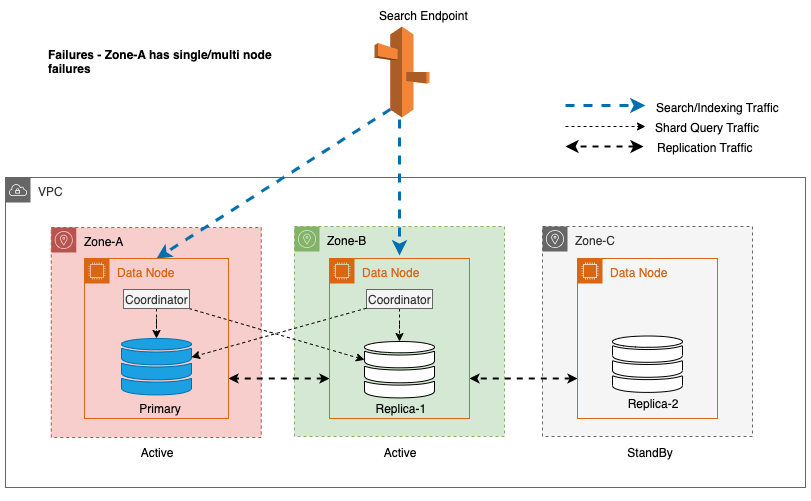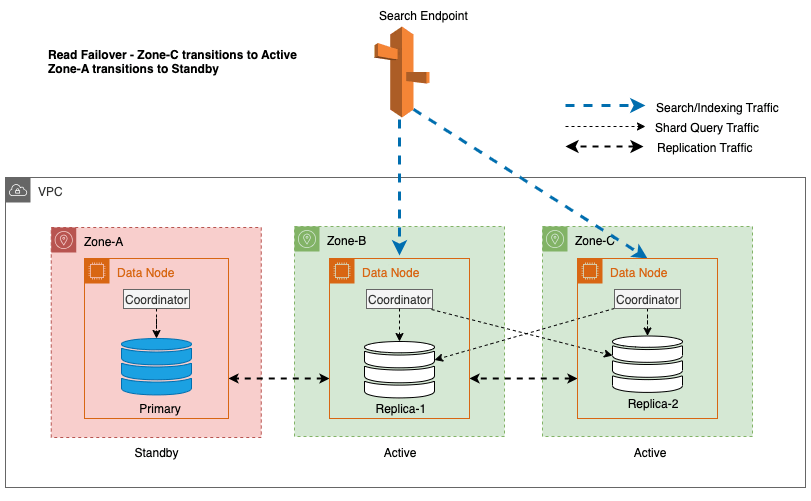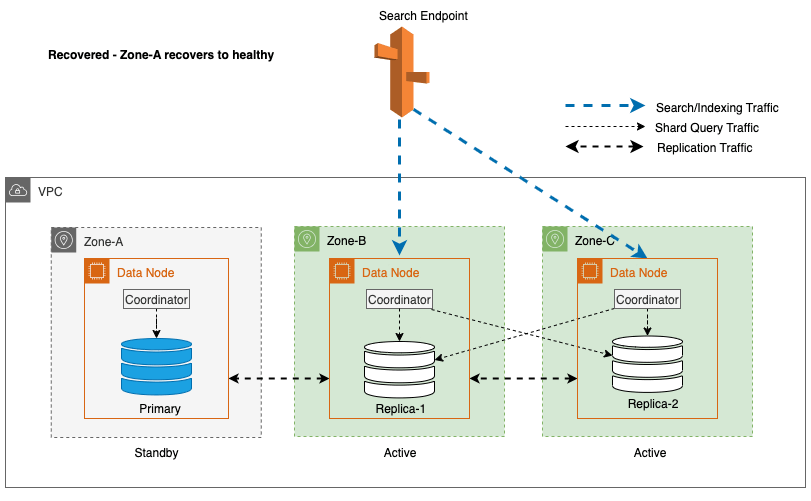
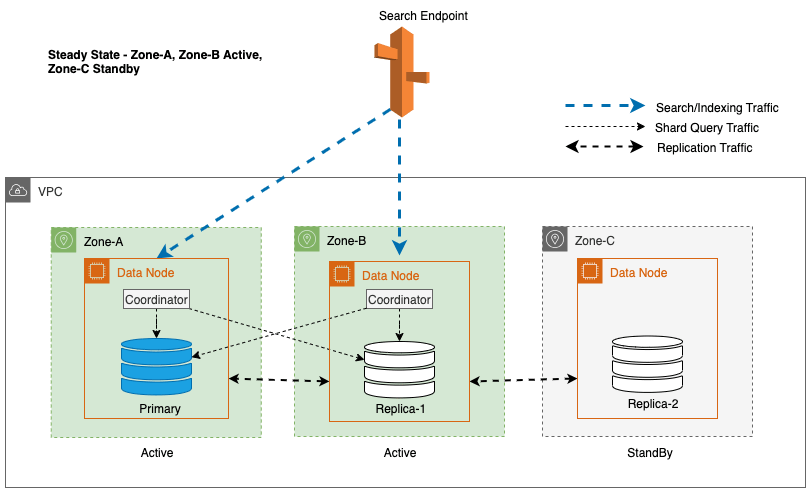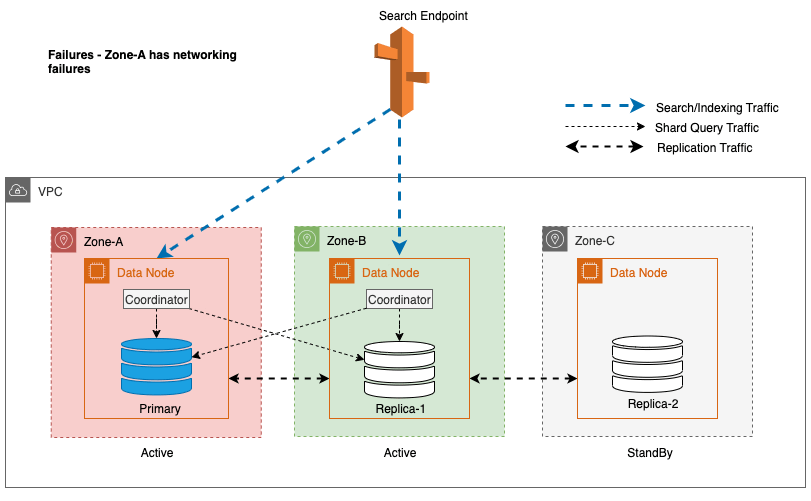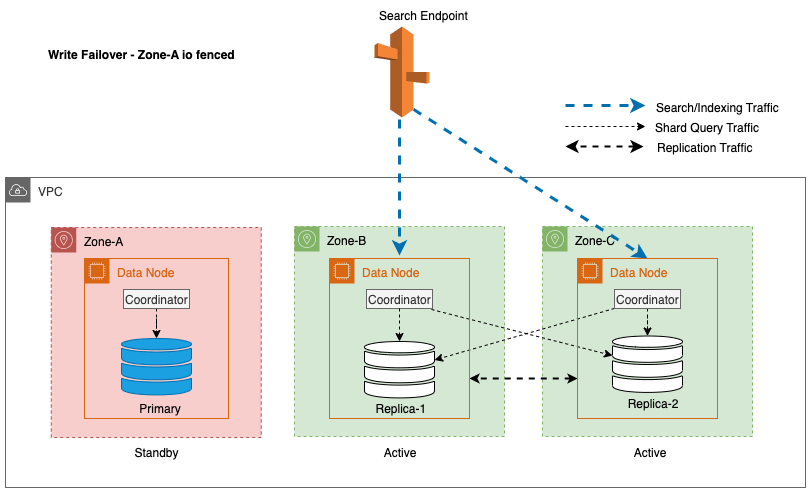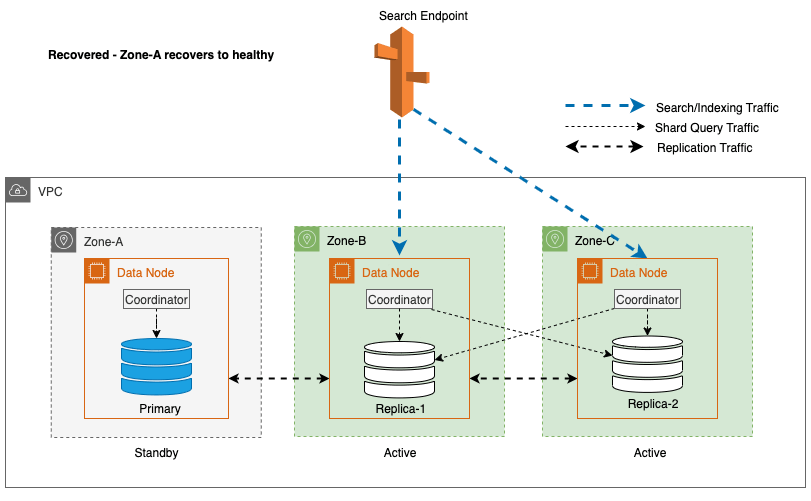
Multi-AZ med Standby distribuerer OpenSearch Service-domeneforekomster på tvers av tre tilgjengelighetssoner, med to soner utpekt som aktive og én som standby. Denne konfigurasjonen sikrer konsistent ytelse, selv i tilfelle sonefeil, ved å opprettholde samme kapasitet på tvers av alle soner. Det er viktig at denne beredskapssonen følger en statisk stabil design, eliminerer behovet for kapasitetsforsyning eller dataflytting under feil.
Under vanlig drift håndterer den aktive sonen koordinatortrafikk for både lese- og skriveforespørsler, samt shard-spørringstrafikk. Standby-sonen mottar derimot bare replikeringstrafikk. OpenSearch Service bruker en synkron replikeringsprotokoll for skriveforespørsler. Dette gjør det mulig for tjenesten å umiddelbart fremme en standby-sone til aktiv status i tilfelle feil (gjennomsnittlig tid til failover <= 1 minutt), kjent som en sonal failover. Den tidligere aktive sonen blir deretter degradert til standby-modus, og gjenopprettingsoperasjoner starter for å gjenopprette sin sunne tilstand.
Ruting av søketrafikk og failover for å garantere høy tilgjengelighet
I et OpenSearch Service-domene, en koordinator er enhver node som håndterer HTTP(S)-forespørsler, spesielt indeksering og søkeforespørsler. I et Multi-AZ med standby-domene fungerer datanodene i den aktive sonen som koordinatorer for søkeforespørsler.
Under spørringsfasen av en søkeforespørsel, bestemmer koordinatoren hvilke shards som skal søkes og sender en forespørsel til datanoden som er vert for shard-kopien. Spørringen kjøres lokalt på hvert shard og samsvarende dokumenter returneres til koordinatornoden. Koordinatornoden, som er ansvarlig for å sende forespørselen til noder som inneholder shard kopier, kjører prosessen i to trinn. Først oppretter den en iterator som definerer rekkefølgen som noder må spørres etter en shard kopi slik at trafikken er jevnt fordelt over shard kopier. Deretter sendes forespørselen til de aktuelle nodene.
For å lage en ordnet liste over noder som skal søkes etter en shard kopi, bruker koordinatornoden ulike algoritmer. Disse algoritmene inkluderer round-robin-valg, adaptivt replikavalg, preferansebasert shard-ruting og vektet round-robin.
For Multi-AZ med Standby brukes den vektede round-robin-algoritmen for valg av shard copy. I denne tilnærmingen tildeles aktive soner vekten 1, og standby-sonen tildeles vekten 0. Dette sikrer at ingen lesetrafikk sendes til datanoder i standby-tilgjengelighetssonen.
Vektene lagres i klyngetilstandsmetadata som et JSON-objekt:
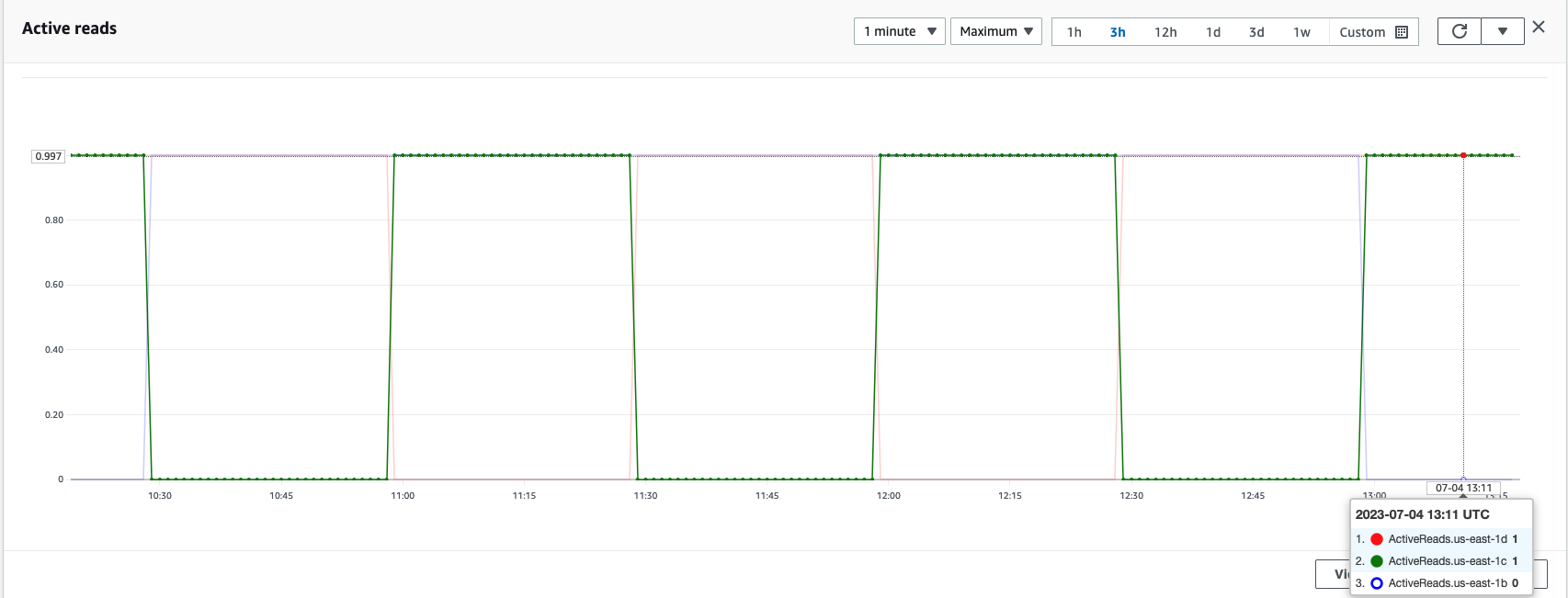
Som vist i følgende skjermbilde, er us-east-1b Region har sin sonestatus som StandBy, som indikerer at datanodene i denne tilgjengelighetssonen er i standby-tilstand og ikke mottar søke- eller indekseringsforespørsler fra lastbalanseren.

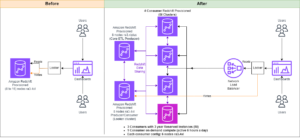
For å opprettholde steady-state operasjoner, roteres standby-tilgjengelighetssonen hvert 30. minutt, noe som sikrer at alle nettverksdeler er dekket på tvers av tilgjengelighetssoner. Denne proaktive tilnærmingen verifiserer tilgjengeligheten av leseveier, og forbedrer systemets motstandskraft ytterligere under potensielle feil. Følgende diagram illustrerer denne arkitekturen.
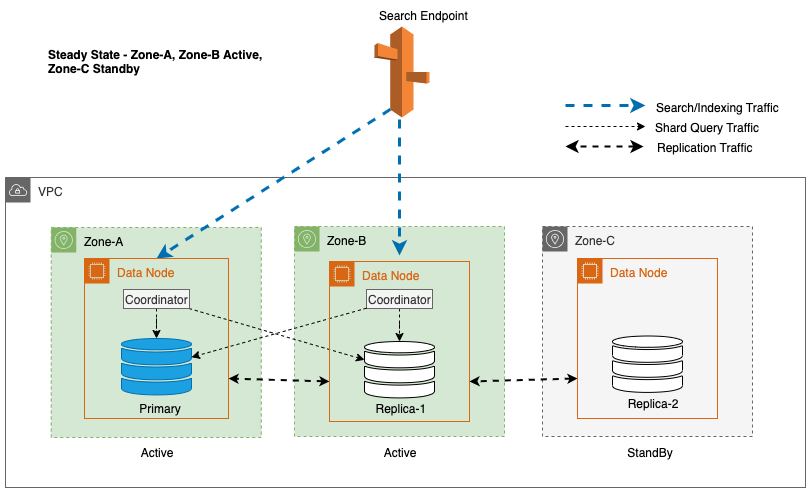
I det foregående diagrammet har Zone-C en vektet round-robin-vekt satt til null. Dette sikrer at datanodene i standby-sonen ikke mottar noen indeksering eller søketrafikk. Når koordinatoren spør om datanoder for fragmenterte kopier, bruker den en vektet round-robin-vekt for å bestemme rekkefølgen i hvilke noder som skal spørres. Fordi vekten er null for standby-tilgjengelighetssonen, sendes ikke koordinatorforespørsler.
I en OpenSearch Service-klynge kan de aktive sonene og standby-sonene sjekkes når som helst ved å bruke Tilgjengelighetssone-rotasjonsberegninger, som vist i følgende skjermbilde.
Under soneavbrudd bytter standby-tilgjengelighetssonen sømløst til feilåpningsmodus for søkeforespørsler. Dette betyr at trafikken for shard-spørringen rutes til alle tilgjengelighetssoner, selv de i standby, når en sunn shard kopi ikke er tilgjengelig i den aktive tilgjengelighetssonen. Denne feilåpne tilnærmingen sikrer søkeforespørsler mot avbrudd under feil, og sikrer kontinuerlig service. Følgende diagram illustrerer denne arkitekturen.
I det foregående diagrammet, under stabil tilstand, sendes shard-spørringstrafikken til datanoden i de aktive tilgjengelighetssonene (sone-A og sone-B). På grunn av nodefeil i sone-A, klarer ikke standby-tilgjengelighetssonen (Zone-C) å åpne for å ta shard-spørringstrafikk slik at det ikke er noen innvirkning på søkeforespørslene. Til slutt oppdages Zone-A som usunn og lesefailoveren bytter standby til Zone-A.
Hvordan failover sikrer høy tilgjengelighet under skrivenedsettelse
OpenSearch Service-replikeringsmodellen følger en primær sikkerhetskopimodell, karakterisert ved sin synkrone natur, der bekreftelse fra alle shard kopier er nødvendig før en skriveforespørsel kan bekreftes til brukeren. En bemerkelsesverdig ulempe med denne replikeringsmodellen er dens mottakelighet for nedganger i tilfelle noen svekkelse i skrivebanen. Disse systemene er avhengige av en aktiv ledernode for å identifisere feil eller forsinkelser og deretter kringkaste denne informasjonen til alle noder. Varigheten det tar å oppdage disse problemene (gjennomsnittlig tid å oppdage) og deretter løse dem (gjennomsnittlig tid å reparere) avgjør i stor grad hvor lenge systemet vil fungere i en svekket tilstand. I tillegg kan enhver nettverkshendelse som påvirker kommunikasjon mellom soner betydelig hindre skriveforespørsler på grunn av replikeringens synkrone natur.
OpenSearch Service bruker en intern node-til-node kommunikasjonsprotokoll for å replikere skrivetrafikk og koordinere metadataoppdateringer gjennom en valgt leder. Følgelig ville det ikke effektivt løse problemet med skriveforringelse å sette sonen som opplever stress i standby.
Zonal skrive-failover: Kutt av inter-sone replikasjonstrafikk
For Multi-AZ med Standby, for å redusere potensielle ytelsesproblemer forårsaket under uforutsette hendelser som sonefeil og nettverkshendelser, er sonal write failover en effektiv tilnærming. Denne tilnærmingen innebærer en grasiøs fjerning av noder i den berørte sonen fra klyngen, og effektivt kuttet inn- og utgående trafikk mellom sonene. Ved å avbryte replikasjonstrafikken mellom sonene, kan virkningen av sonefeil holdes innenfor den berørte sonen. Dette gir en mer forutsigbar opplevelse for kundene og sikrer at systemet fortsetter å fungere pålitelig.
Grasiøs skrive-failover
Orkestreringen av en skrivefailover i OpenSearch Service utføres av den valgte ledernoden gjennom en veldefinert mekanisme. Denne mekanismen innebærer en konsensusprotokoll for klyngestatspublisering, som sikrer enstemmig enighet mellom alle noder om å utpeke en enkelt sone (til enhver tid) for avvikling. Viktigere er at metadata relatert til den berørte sonen replikeres på tvers av alle noder for å sikre at den holder seg, selv under en fullstendig omstart i tilfelle avbrudd.
Videre sørger ledernoden for en jevn og grasiøs overgang ved først å plassere nodene i de berørte sonene i beredskap i en varighet på 5 minutter før I/O-gjerde settes i gang. Denne bevisste tilnærmingen forhindrer ny koordinatortrafikk eller shard-spørringstrafikk fra å bli dirigert til nodene innenfor den berørte sonen. Dette lar igjen disse nodene fullføre sine pågående oppgaver elegant og gradvis håndtere eventuelle forespørsler om fly før de tas ut av drift. Følgende diagram illustrerer denne arkitekturen.
I prosessen med å implementere en skrivefailover for en ledernode, følger OpenSearch Service disse nøkkeltrinnene:
- Lederabdikasjon – Hvis ledernoden tilfeldigvis befinner seg i en sone som er planlagt for skrivefailover, sikrer systemet at ledernoden frivillig trekker seg fra sin lederrolle. Denne abdikasjonen utføres på en kontrollert måte, og hele prosessen overføres til en annen kvalifisert node, som deretter tar ansvar for de nødvendige handlingene.
- Forhindre gjenvalg av leder som skal tas ut – For å forhindre gjenvalg av en leder fra en sone merket for skrivefailover, når den kvalifiserte ledernoden starter skrivefailoverhandlingen, iverksetter den tiltak for å sikre at eventuelle ledernoder som skal avvikles ikke deltar i ytterligere valg. Dette oppnås ved å ekskludere ledernoden som skal avvikles fra stemmekonfigurasjonen, og effektivt forhindre den fra å stemme under enhver kritisk fase av klyngens drift.
Metadata relatert til skrivefeilsonen lagres i klyngetilstanden, og denne informasjonen publiseres til alle noder i den distribuerte OpenSearch Service-klyngen som følger:
Følgende skjermbilde viser at under en nettverksbremsing i en sone, hjelper skrivefeil med å gjenopprette tilgjengeligheten.
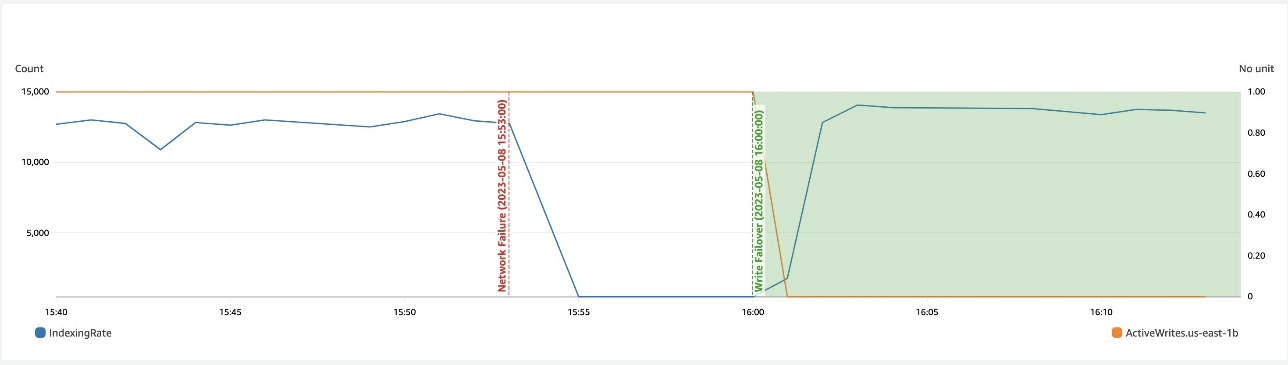
Zonegjenoppretting etter skrivefeil
Prosessen med sonal recommissioning spiller en avgjørende rolle i gjenopprettingsfasen etter en sonal skrivefailover. Etter at den berørte sonen er gjenopprettet og anses som stabil, vil nodene som tidligere ble tatt ut av drift, slutte seg til klyngen igjen. Denne gjenoppstarten skjer vanligvis innen en tidsramme på 2 minutter etter at sonen har blitt tatt i bruk igjen.
Dette gjør dem i stand til å synkronisere med sine noder og initierer gjenopprettingsprosessen for replikaskår, og gjenoppretter effektivt klyngen til ønsket tilstand.
konklusjonen
Introduksjonen av OpenSearch Service Multi-AZ med Standby gir bedrifter en kraftig løsning for å oppnå høy tilgjengelighet og konsistent ytelse for kritiske arbeidsbelastninger. Med dette distribusjonsalternativet kan bedrifter forbedre infrastrukturens motstandskraft, forenkle klyngekonfigurasjon og -administrasjon og håndheve beste praksis. Med funksjoner som vektet round-robin shard copy-valg, proaktive failover-mekanismer og fail-open standby Availability Zones, sikrer OpenSearch Service Multi-AZ med Standby en pålitelig og effektiv søkeopplevelse for krevende bedriftsmiljøer.
For mer informasjon om Multi-AZ med Standby, se Amazon OpenSearch Service Under the Hood: Multi-AZ med standby.
om forfatteren
 Anshu Agarwal er en senior programvareingeniør som jobber med AWS OpenSearch hos Amazon Web Services. Hun brenner for å løse problemer knyttet til å bygge skalerbare og svært pålitelige systemer.
Anshu Agarwal er en senior programvareingeniør som jobber med AWS OpenSearch hos Amazon Web Services. Hun brenner for å løse problemer knyttet til å bygge skalerbare og svært pålitelige systemer.
 Rishab Nahata er en programvareingeniør som jobber med OpenSearch hos Amazon Web Services. Han er fascinert av å løse problemer i distribuerte systemer. Han er aktiv bidragsyter til OpenSearch.
Rishab Nahata er en programvareingeniør som jobber med OpenSearch hos Amazon Web Services. Han er fascinert av å løse problemer i distribuerte systemer. Han er aktiv bidragsyter til OpenSearch.
 Bukhtawar Khan er en hovedingeniør som jobber med Amazon OpenSearch Service. Han er interessert i distribuerte og autonome systemer. Han er en aktiv bidragsyter til OpenSearch.
Bukhtawar Khan er en hovedingeniør som jobber med Amazon OpenSearch Service. Han er interessert i distribuerte og autonome systemer. Han er en aktiv bidragsyter til OpenSearch.
 Ranjith Ramachandra er en ingeniørsjef som jobber med Amazon OpenSearch Service hos Amazon Web Services.
Ranjith Ramachandra er en ingeniørsjef som jobber med Amazon OpenSearch Service hos Amazon Web Services.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- : har
- :er
- :ikke
- :hvor
- 1
- 10
- 100
- 12
- 30
- 501
- a
- Om oss
- Oppnå
- oppnådd
- erkjente
- tvers
- Handling
- Handling
- handlinger
- aktiv
- adaptive
- I tillegg
- adresse
- påvirkes
- Etter
- Avtale
- algoritme
- algoritmer
- Alle
- tillate
- Amazon
- Amazon Web Services
- blant
- an
- og
- En annen
- noen
- tilnærming
- arkitektur
- ER
- AS
- tildelt
- At
- autonom
- autonome systemer
- tilgjengelighet
- bevissthet
- AWS
- Backup
- swing
- BE
- fordi
- vært
- før du
- være
- BEST
- beste praksis
- mellom
- både
- kringkaste
- Bygning
- bedrifter
- by
- CAN
- Kapasitet
- gjennomført
- forårsaket
- karakterisert
- kostnad
- sjekket
- Cluster
- Kommunikasjon
- kommunikasjon
- fullføre
- Konfigurasjon
- Konsensus
- Følgelig
- ansett
- konsistent
- Konsoll
- inneholdt
- fortsetter
- kontinuerlig
- bidra
- bidragsyter
- kontrolleres
- koordinerende
- Koordinator
- koordinatorer
- kopier
- dekket
- skape
- skaper
- kritisk
- avgjørende
- Kunder
- skjæring
- dato
- bestemme
- dyp
- dypdykk
- definerer
- forsinkelser
- dybden
- krevende
- distribusjon
- Distribueres
- utpekt
- designet
- ønsket
- oppdage
- oppdaget
- bestemmes
- regissert
- Avbrudd
- distribueres
- distribuerte systemer
- dykk
- do
- dokumenter
- domene
- domener
- ikke
- ned
- to
- varighet
- under
- hver enkelt
- Effektiv
- effektivt
- effektiv
- valgt
- Valg
- kvalifisert
- eliminere
- aktivert
- muliggjør
- håndheve
- ingeniør
- Ingeniørarbeid
- forbedre
- forbedret
- styrke
- sikre
- sikrer
- sikrer
- Enterprise
- Hele
- miljøer
- spesielt
- Eter (ETH)
- Selv
- Event
- hendelser
- etter hvert
- Hver
- Eksklusiv
- erfaring
- opplever
- utforske
- mislykkes
- Failure
- feil
- Trekk
- Egenskaper
- fekting
- Først
- etter
- følger
- Til
- RAMME
- fra
- fullt
- videre
- gif
- Grasiøs
- gradvis
- garantere
- hånd
- håndtere
- Håndterer
- skjer
- he
- sunt
- hjelper
- Høy
- svært
- panser
- Hosting
- Hvordan
- http
- HTTPS
- identifisere
- if
- illustrerer
- Påvirkning
- påvirket
- svekkelse
- implementere
- viktigere
- in
- inkludere
- indikerer
- informasjon
- Infrastruktur
- i utgangspunktet
- Starter
- initiere
- forekomster
- interessert
- intern
- inn
- introdusert
- Introduksjon
- innebærer
- utstedelse
- saker
- IT
- DET ER
- jpg
- JSON
- nøkkel
- kjent
- i stor grad
- leder
- Ledelse
- i likhet med
- Liste
- laste
- lokalt
- ligger
- Lang
- vedlikeholde
- opprettholde
- fikk til
- ledelse
- leder
- måte
- merket
- matchet
- bety
- midler
- målinger
- mekanisme
- mekanismer
- metadata
- Metrics
- minutt
- minutter
- Minske
- Mote
- modell
- mer
- bevegelse
- Natur
- nødvendig
- Trenger
- nettverk
- nettverk
- Ny
- Nei.
- node
- noder
- bemerkelsesverdig
- objekt
- of
- off
- on
- ONE
- pågående
- bare
- åpen
- betjene
- drift
- Drift
- Alternativ
- or
- orkestre
- rekkefølge
- Annen
- ut
- brudd
- brudd
- enn
- delta
- deler
- lidenskapelig
- banen
- baner
- likemann
- ytelse
- utholdenhet
- fase
- plassering
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Post
- potensiell
- kraftig
- praksis
- forut
- Forutsigbar
- forebygge
- hindre
- forhindrer
- tidligere
- primære
- Principal
- Proaktiv
- problemer
- prosess
- fremme
- protokollen
- gi
- gir
- Utgivelse
- publisert
- Sette
- spørsmål
- Lese
- motta
- mottar
- nylig
- Gjenopprette
- utvinne
- utvinning
- referere
- region
- regelmessig
- i slekt
- relevant
- pålitelighet
- pålitelig
- avhengige
- gjenværende
- fjerning
- reparasjon
- svare
- replikert
- replikering
- anmode
- forespørsler
- påkrevd
- resiliens
- spenstig
- løse
- ansvarlig
- gjenopprette
- restaurert
- gjenopprette
- Rolle
- ruting
- Kjør
- går
- s
- sikringstiltak
- samme
- skalerbar
- planlagt
- sømløst
- Søk
- utvalg
- sending
- sender
- senior
- sendt
- tjeneste
- Tjenester
- sett
- hun
- vist
- betydelig
- enkelhet
- forenkle
- enkelt
- Ro ned
- bremser
- glatter
- So
- Software
- Software Engineer
- løsning
- løse
- stabil
- Tilstand
- status
- jevn
- Steps
- lagret
- stresset
- I ettertid
- vellykket
- mottakelighet
- system
- Systemer
- Ta
- tatt
- tar
- oppgaver
- Det
- De
- deres
- Dem
- deretter
- Der.
- Disse
- denne
- De
- tre
- Gjennom
- tid
- ganger
- til
- toleranse
- trafikk
- overgang
- SVING
- to
- typisk
- etter
- underliggende
- uforutsett
- oppdateringer
- brukt
- Bruker
- bruker
- ved hjelp av
- bruker
- ulike
- frivillig
- Stemmegivning
- we
- web
- webtjenester
- vekt
- VI VIL
- veldefinerte
- var
- når
- hvilken
- mens
- vil
- med
- innenfor
- arbeid
- virker
- skrive
- zephyrnet
- null
- soner