Mange organisasjoner, små og store, jobber med å migrere og modernisere analysearbeidsmengdene sine på Amazon Web Services (AWS). Det er mange grunner for kunder til å migrere til AWS, men en av hovedårsakene er muligheten til å bruke fullt administrerte tjenester i stedet for å bruke tid på å vedlikeholde infrastruktur, patching, overvåking, sikkerhetskopier og mer. Leder- og utviklingsteam kan bruke mer tid på å optimalisere nåværende løsninger og til og med eksperimentere med nye brukstilfeller, i stedet for å vedlikeholde den nåværende infrastrukturen.
Med muligheten til å bevege seg raskt på AWS, må du også være ansvarlig for dataene du mottar og behandler mens du fortsetter å skalere. Disse forpliktelsene inkluderer å være i samsvar med lover og forskrifter for personvern og ikke lagre eller avsløre sensitive data som personlig identifiserbar informasjon (PII) eller beskyttet helseinformasjon (PHI) fra oppstrømskilder.
I dette innlegget går vi gjennom en arkitektur på høyt nivå og en spesifikk brukssak som demonstrerer hvordan du kan fortsette å skalere organisasjonens dataplattform uten å måtte bruke store mengder utviklingstid for å ta opp bekymringer om personvern. Vi bruker AWS Lim for å oppdage, maskere og redigere PII-data før de lastes inn Amazon OpenSearch-tjeneste.
Løsningsoversikt
Følgende diagram illustrerer løsningsarkitekturen på høyt nivå. Vi har definert alle lag og komponenter i designet vårt i tråd med AWS velarkitektert rammeverksdataanalyseobjektiv.
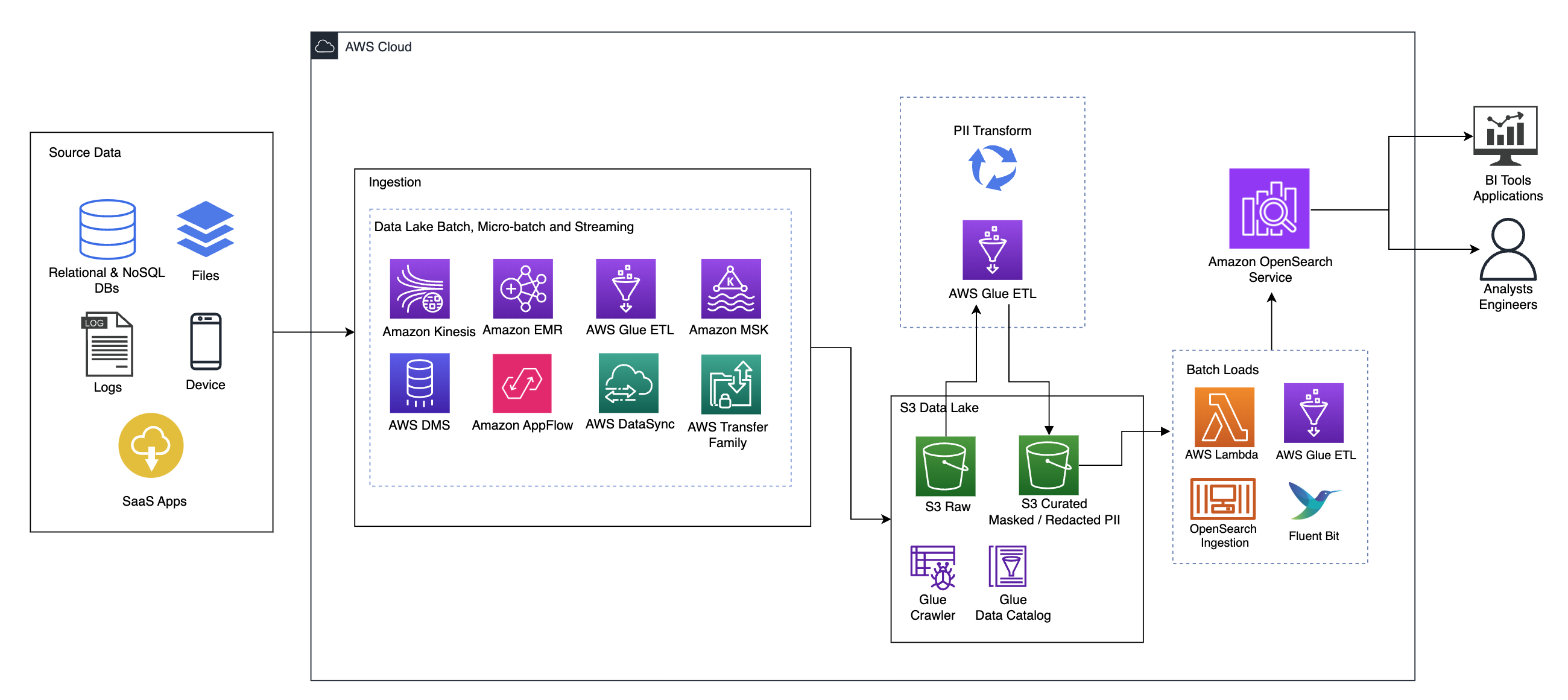
Arkitekturen består av en rekke komponenter:
Kilde data
Data kan komme fra mange titalls til hundrevis av kilder, inkludert databaser, filoverføringer, logger, programvare som en tjeneste (SaaS)-applikasjoner og mer. Organisasjoner har kanskje ikke alltid kontroll over hvilke data som kommer gjennom disse kanalene og inn i deres nedstrømslagring og applikasjoner.
Svelging: Datainnsjø-batch, mikro-batch og streaming
Mange organisasjoner lander kildedataene sine i datasjøen på forskjellige måter, inkludert batch-, mikrobatch- og streamingjobber. For eksempel, Amazon EMR, AWS Limog AWS Database Migration Service (AWS DMS) kan alle brukes til å utføre batch- og/eller streamingoperasjoner som synker til en datainnsjø på Amazon enkel lagringstjeneste (Amazon S3). Amazon App Flow kan brukes til å overføre data fra forskjellige SaaS-applikasjoner til en datainnsjø. AWS DataSync og AWS overføringsfamilie kan hjelpe med å flytte filer til og fra en datainnsjø over en rekke forskjellige protokoller. Amazon Kinesis og Amazon MSK har også muligheter til å streame data direkte til en datainnsjø på Amazon S3.
S3 datainnsjø
Å bruke Amazon S3 for datainnsjøen er i tråd med den moderne datastrategien. Det gir rimelig lagring uten å ofre ytelse, pålitelighet eller tilgjengelighet. Med denne tilnærmingen kan du overføre data til dataene dine etter behov og kun betale for kapasiteten den trenger for å kjøre.
I denne arkitekturen kan rådata komme fra en rekke kilder (interne og eksterne), som kan inneholde sensitive data.
Ved å bruke AWS Glue-crawlere kan vi oppdage og katalogisere dataene, som vil bygge tabellskjemaene for oss, og til slutt gjøre det enkelt å bruke AWS Glue ETL med PII-transformasjonen for å oppdage og maskere eller og redigere alle sensitive data som kan ha landet i datasjøen.
Forretningskontekst og datasett
For å demonstrere verdien av vår tilnærming, la oss forestille oss at du er en del av et dataingeniørteam for en finansiell tjenesteorganisasjon. Kravene dine er å oppdage og maskere sensitive data når de tas inn i organisasjonens skymiljø. Dataene vil bli konsumert av nedstrøms analytiske prosesser. I fremtiden vil brukerne dine trygt kunne søke i historiske betalingstransaksjoner basert på datastrømmer samlet inn fra interne banksystemer. Søkeresultater fra driftsteam, kunder og grensesnittapplikasjoner må maskeres i sensitive felt.
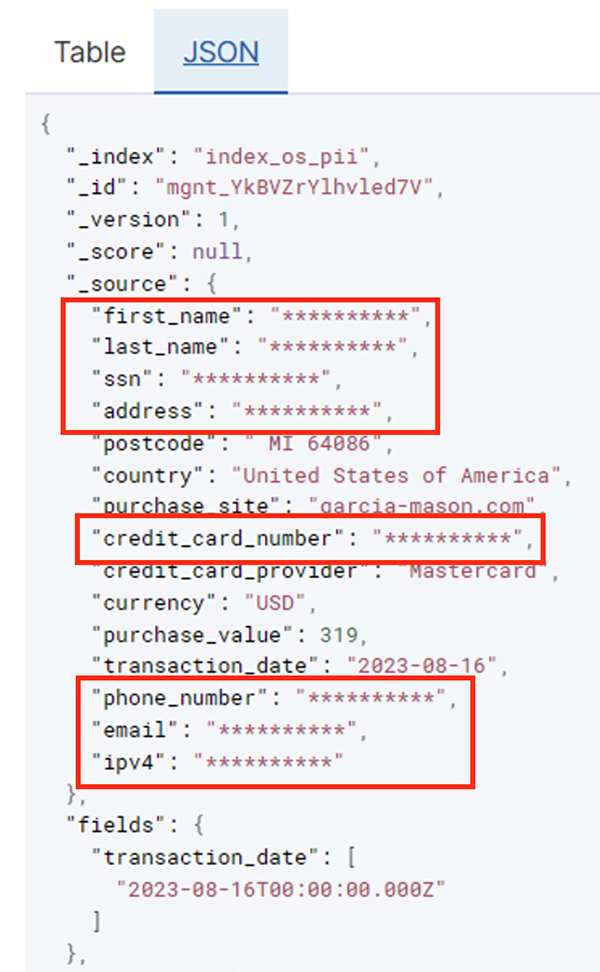
Tabellen nedenfor viser datastrukturen som brukes for løsningen. For klarhetens skyld har vi kartlagt rå til kuraterte kolonnenavn. Du vil legge merke til at flere felt i dette skjemaet anses som sensitive data, for eksempel fornavn, etternavn, personnummer (SSN), adresse, kredittkortnummer, telefonnummer, e-post og IPv4-adresse.
| Rå kolonnenavn | Navn på kurert kolonne | typen |
| c0 | fornavn | string |
| c1 | etternavn | string |
| c2 | ssn | string |
| c3 | adresse | string |
| c4 | postnummer | string |
| c5 | land | string |
| c6 | kjøpsside | string |
| c7 | Kreditt kort nummer | string |
| c8 | kredittkortleverandør | string |
| c9 | valuta | string |
| c10 | kjøpsverdi | heltall |
| c11 | Transaksjonsdato | data |
| c12 | telefonnummer | string |
| c13 | emalje | string |
| c14 | ipv4 | string |
Brukstilfelle: PII-batchdeteksjon før lasting til OpenSearch Service
Kunder som implementerer følgende arkitektur har bygget sin datainnsjø på Amazon S3 for å kjøre forskjellige typer analyser i stor skala. Denne løsningen er egnet for kunder som ikke trenger innføring i sanntid til OpenSearch Service og planlegger å bruke dataintegrasjonsverktøy som kjører etter en tidsplan eller utløses gjennom hendelser.
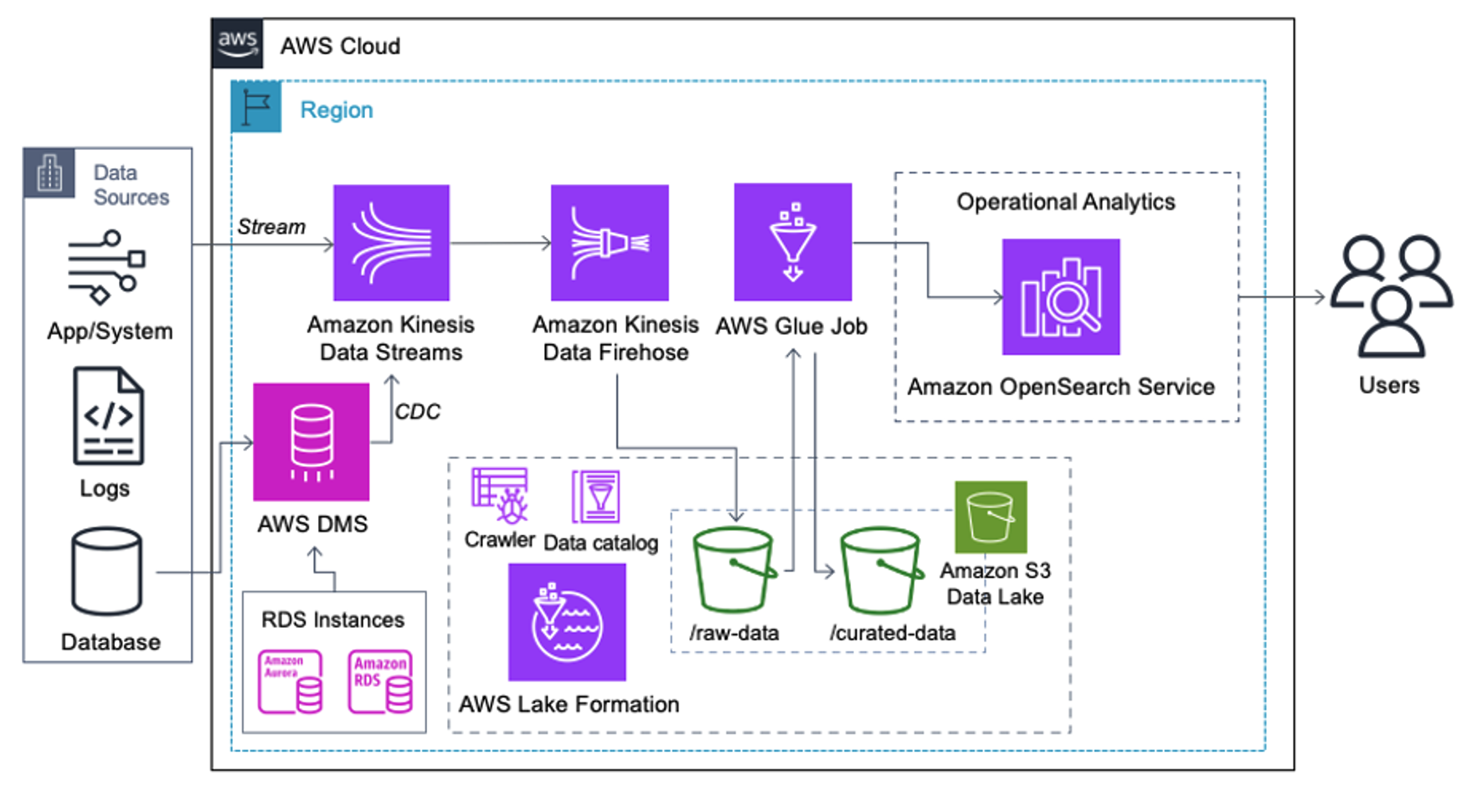
Før dataposter lander på Amazon S3, implementerer vi et inntakslag for å bringe alle datastrømmer pålitelig og sikkert til datasjøen. Kinesis Data Streams er distribuert som et inntakslag for akselerert inntak av strukturerte og semistrukturerte datastrømmer. Eksempler på disse er endringer i relasjonsdatabaser, applikasjoner, systemlogger eller klikkstrømmer. For brukstilfeller for endringsdatafangst (CDC), kan du bruke Kinesis Data Streams som et mål for AWS DMS. Applikasjoner eller systemer som genererer strømmer som inneholder sensitive data, sendes til Kinesis-datastrømmen via en av de tre støttede metodene: Amazon Kinesis Agent, AWS SDK for Java eller Kinesis Producer Library. Som et siste skritt, Amazon Kinesis Data Firehose hjelper oss på en pålitelig måte å laste nesten-sanntidsbatcher med data til vår S3-datainnsjø-destinasjon.
Følgende skjermbilde viser hvordan data flyter gjennom Kinesis datastrømmer via Dataviser og henter eksempeldata som lander på det rå S3-prefikset. For denne arkitekturen fulgte vi datalivssyklusen for S3-prefikser som anbefalt i Data lake foundation.
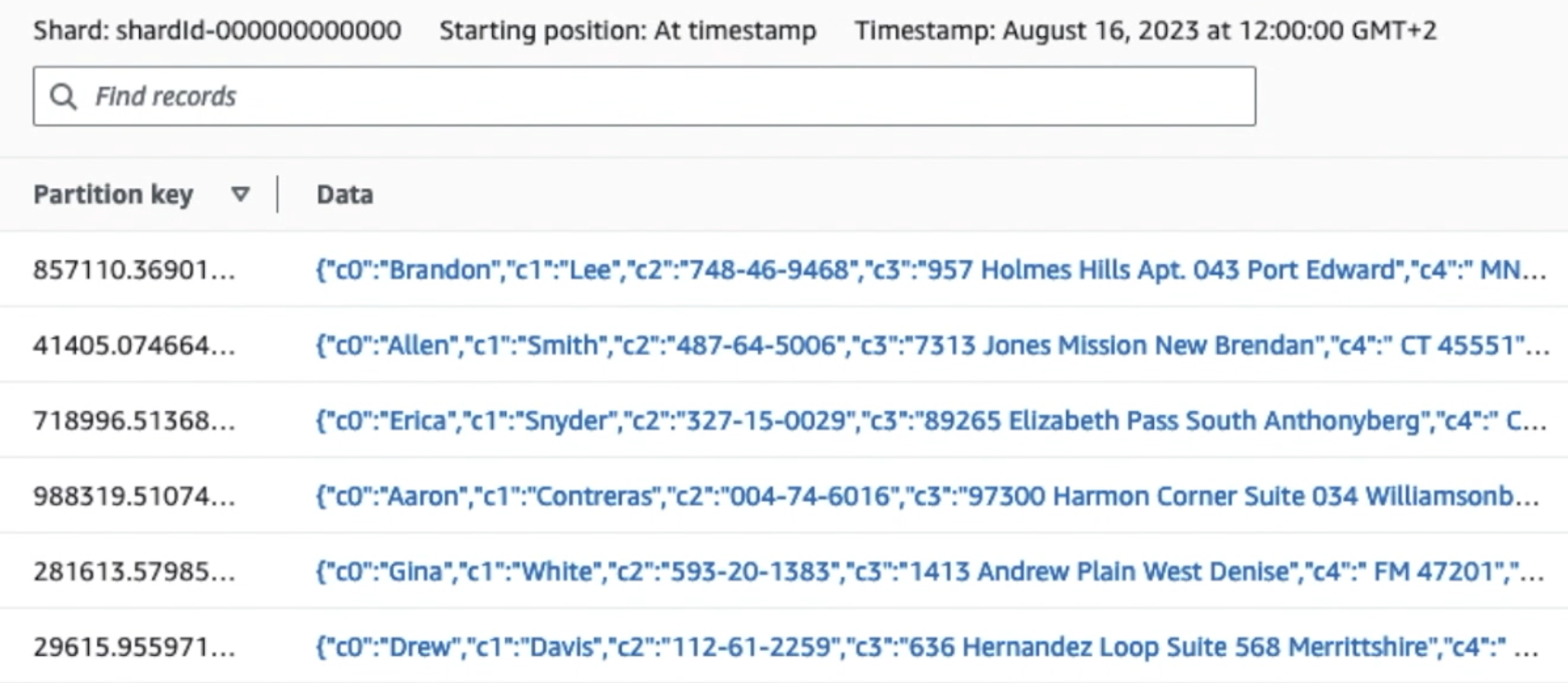
Som du kan se fra detaljene til den første posten i følgende skjermbilde, følger JSON-nyttelasten det samme skjemaet som i forrige seksjon. Du kan se de uredigerte dataene strømme inn i Kinesis-datastrømmen, som vil bli tilslørt senere i påfølgende stadier.
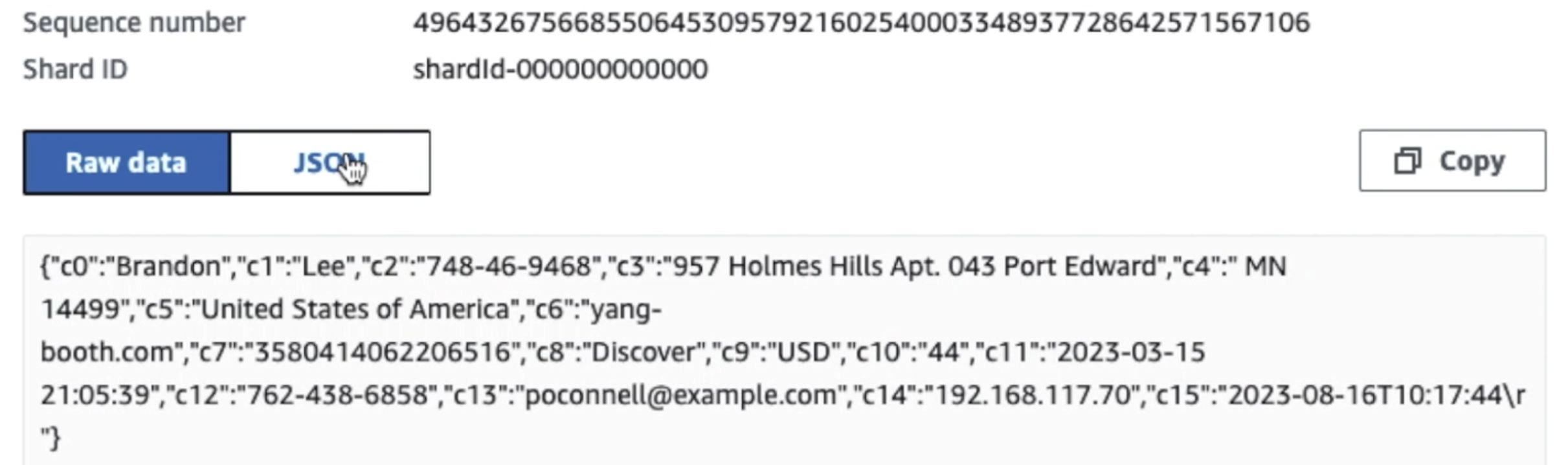
Etter at dataene er samlet inn og inntatt i Kinesis Data Streams og levert til S3-bøtten ved hjelp av Kinesis Data Firehose, tar prosesseringslaget til arkitekturen over. Vi bruker AWS Glue PII-transformasjonen for å automatisere deteksjon og maskering av sensitive data i vår pipeline. Som vist i følgende arbeidsflytdiagram, tok vi en visuell ETL-tilnærming uten kode for å implementere transformasjonsjobben vår i AWS Glue Studio.
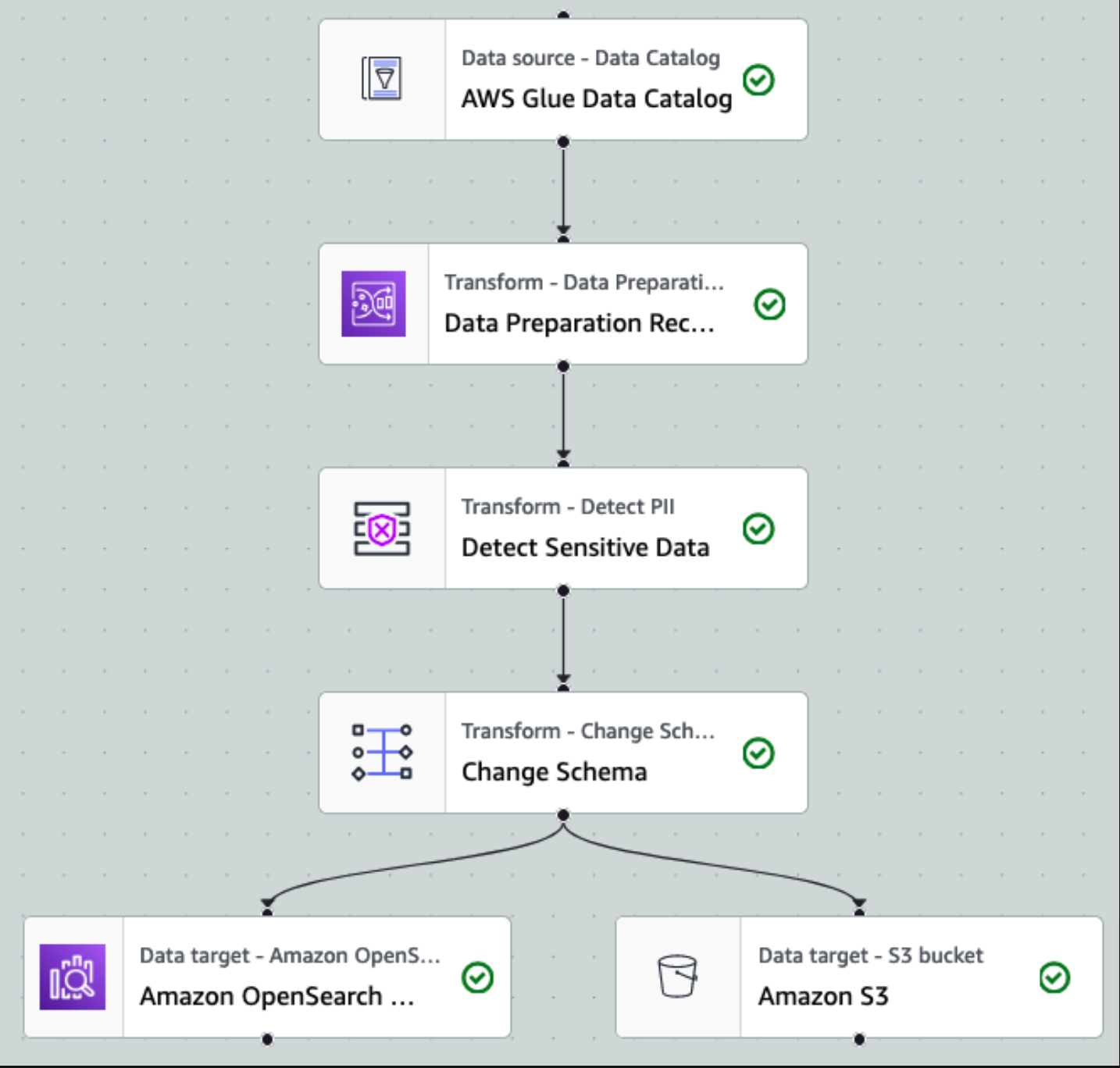
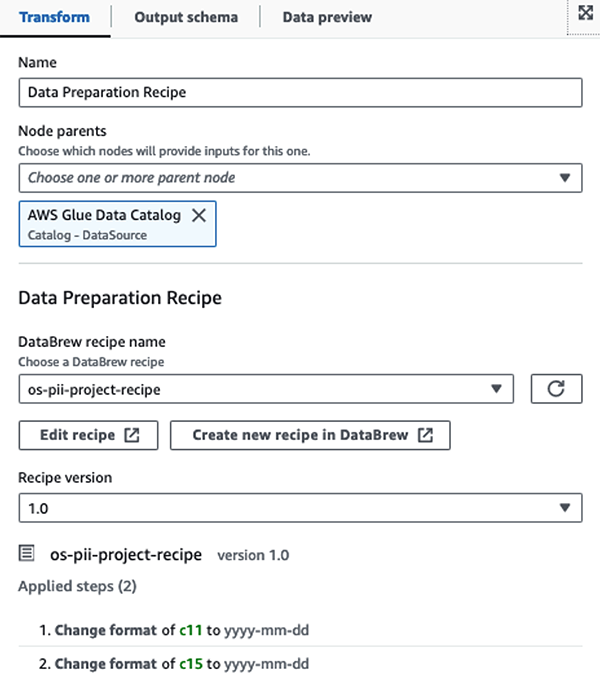
Først får vi tilgang til kildedatakatalogtabellen rå fra pii_data_db database. Tabellen har skjemastrukturen presentert i forrige avsnitt. For å holde styr på de råbehandlede dataene brukte vi jobb bokmerker.

Vi bruker AWS Glue DataBrew-oppskrifter i AWS Glue Studio visuelle ETL-jobb å transformere to datoattributter for å være kompatible med OpenSearch forventet formater. Dette lar oss ha en fullstendig uten kode-opplevelse.
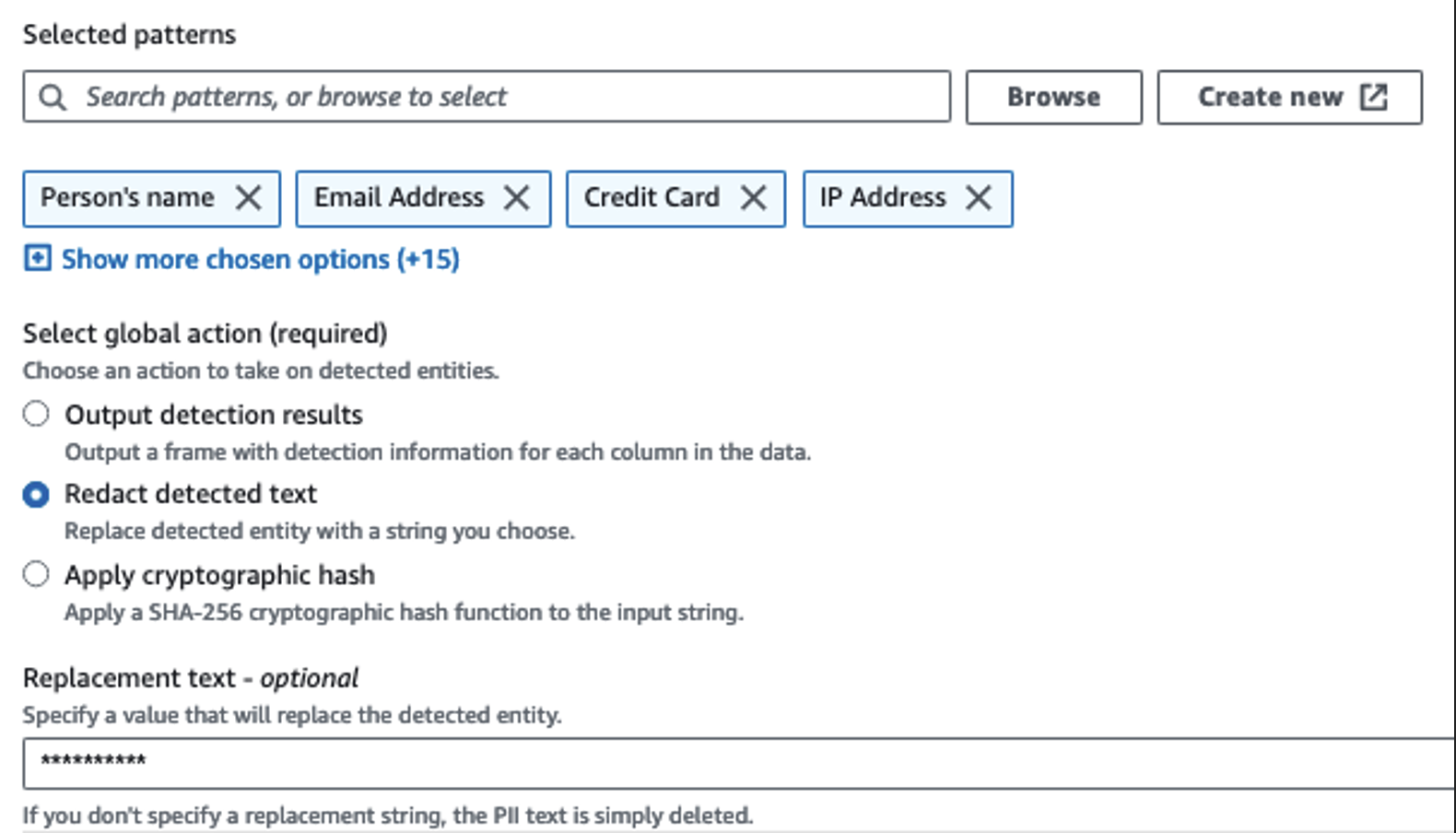
Vi bruker handlingen Oppdag PII for å identifisere sensitive kolonner. Vi lar AWS Glue bestemme dette basert på utvalgte mønstre, deteksjonsterskel og prøvedel av rader fra datasettet. I vårt eksempel brukte vi mønstre som gjelder spesifikt for USA (som SSN-er) og som kanskje ikke oppdager sensitive data fra andre land. Du kan se etter tilgjengelige kategorier og plasseringer som gjelder for ditt bruk eller bruke regulære uttrykk (regex) i AWS Glue for å opprette deteksjonsenheter for sensitive data fra andre land.
Det er viktig å velge riktig prøvetakingsmetode som AWS Glue tilbyr. I dette eksemplet er det kjent at dataene som kommer inn fra strømmen har sensitive data i hver rad, så det er ikke nødvendig å sample 100 % av radene i datasettet. Hvis du har et krav der ingen sensitive data er tillatt til nedstrømskilder, bør du vurdere å prøve å prøve 100 % av dataene for mønstrene du valgte, eller skanne hele datasettet og handle på hver enkelt celle for å sikre at alle sensitive data blir oppdaget. Fordelen du får fra prøvetaking er reduserte kostnader fordi du ikke trenger å skanne så mye data.

Handlingen Oppdag PII lar deg velge en standardstreng når du maskerer sensitive data. I vårt eksempel bruker vi strengen **********.
Vi bruker bruk kartleggingsoperasjonen for å gi nytt navn og fjerne unødvendige kolonner som f.eks ingestion_year, ingestion_monthog ingestion_day. Dette trinnet lar oss også endre datatypen til en av kolonnene (purchase_value) fra streng til heltall.

Fra dette tidspunktet deler jobben seg i to utdatamål: OpenSearch Service og Amazon S3.
Vår klargjorte OpenSearch-tjenesteklynge er koblet til via OpenSearch innebygd kobling for lim. Vi spesifiserer OpenSearch-indeksen vi vil skrive til, og koblingen håndterer legitimasjonen, domenet og porten. I skjermbildet nedenfor skriver vi til den angitte indeksen index_os_pii.
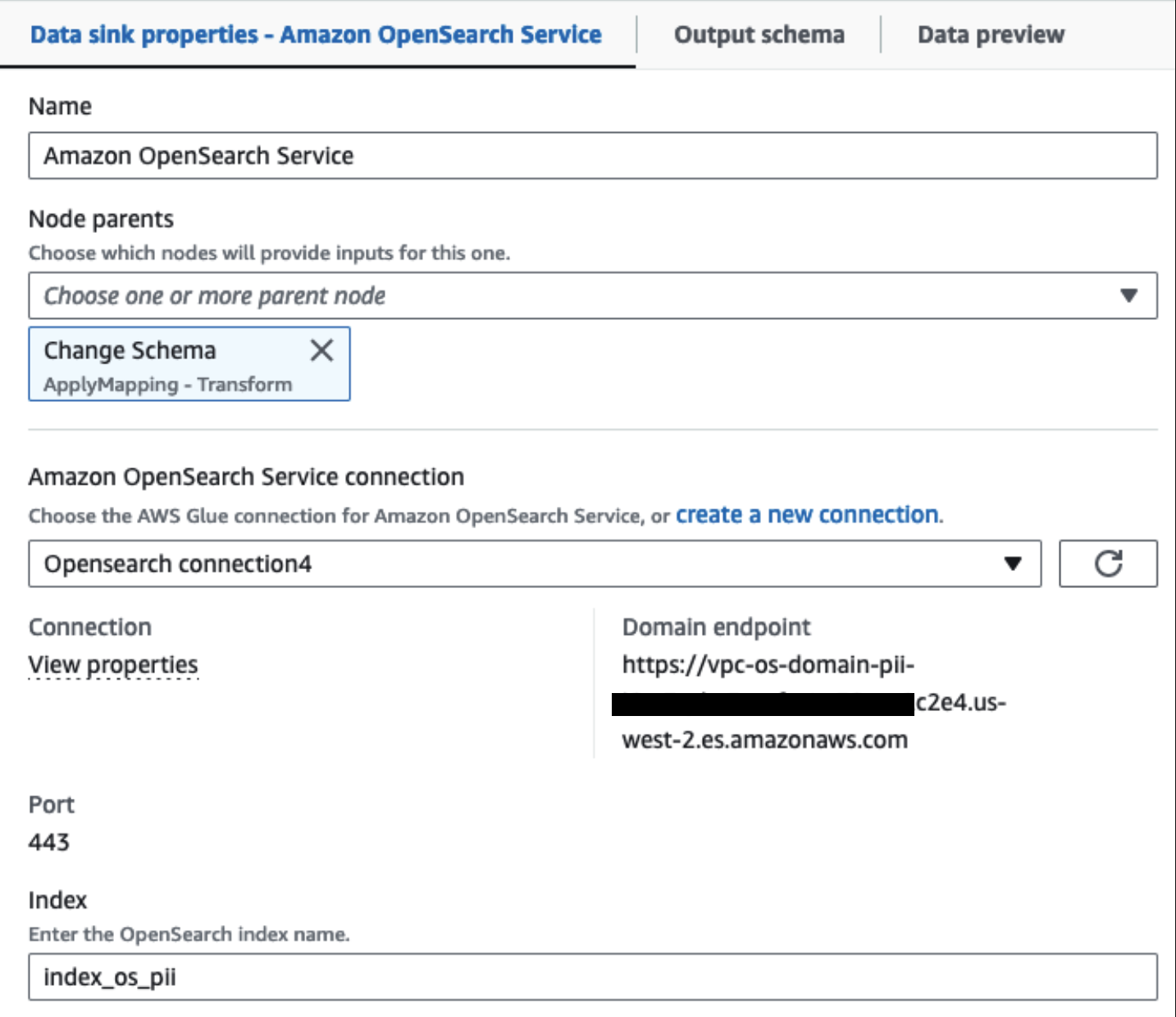
Vi lagrer det maskerte datasettet i det kurerte S3-prefikset. Der har vi data normalisert til et spesifikt brukstilfelle og trygt forbruk av dataforskere eller for ad hoc-rapporteringsbehov.
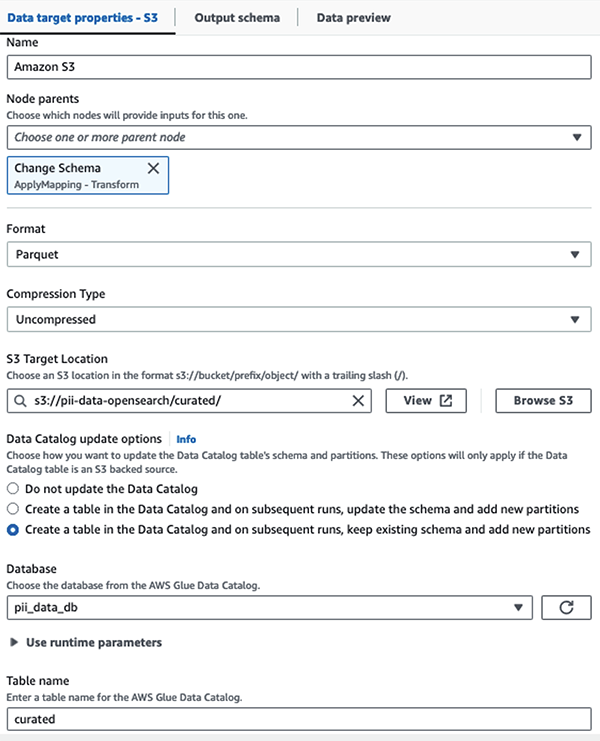
For enhetlig styring, tilgangskontroll og revisjonsspor for alle datasett og datakatalogtabeller kan du bruke AWS Lake formasjon. Dette hjelper deg med å begrense tilgangen til AWS Glue Data Catalog-tabeller og underliggende data til kun de brukerne og rollene som har fått nødvendige tillatelser til å gjøre det.
Etter at batchjobben har kjørt vellykket, kan du bruke OpenSearch Service til å kjøre søk eller rapporter. Som vist i følgende skjermbilde, maskerte rørledningen sensitive felt automatisk uten kodeutvikling.

Du kan identifisere trender fra driftsdataene, for eksempel antall transaksjoner per dag filtrert av kredittkortleverandøren, som vist på forrige skjermbilde. Du kan også bestemme plasseringene og domenene der brukerne foretar kjøp. De transaction_date attributt hjelper oss å se disse trendene over tid. Følgende skjermbilde viser en post med all transaksjonsinformasjon redigert på riktig måte.
For alternative metoder for hvordan du laster data inn i Amazon OpenSearch, se Laster strømmedata til Amazon OpenSearch Service.
Videre kan sensitive data også oppdages og maskeres ved hjelp av andre AWS-løsninger. Du kan for eksempel bruke Amazon Macie for å oppdage sensitive data inne i en S3-bøtte, og deretter bruke Amazon Comprehend for å redigere de sensitive dataene som ble oppdaget. For mer informasjon, se Vanlige teknikker for å oppdage PHI- og PII-data ved hjelp av AWS Services.
konklusjonen
Dette innlegget diskuterte viktigheten av å håndtere sensitive data i miljøet ditt og ulike metoder og arkitekturer for å forbli kompatible samtidig som organisasjonen din kan skaleres raskt. Du bør nå ha en god forståelse av hvordan du oppdager, maskerer eller redigerer og laster dataene dine inn i Amazon OpenSearch Service.
Om forfatterne
 Michael Hamilton er en Sr Analytics Solutions Architect som fokuserer på å hjelpe bedriftskunder med å modernisere og forenkle analysearbeidsmengdene sine på AWS. Han liker å sykle på terreng og tilbringe tid med kona og tre barn når han ikke jobber.
Michael Hamilton er en Sr Analytics Solutions Architect som fokuserer på å hjelpe bedriftskunder med å modernisere og forenkle analysearbeidsmengdene sine på AWS. Han liker å sykle på terreng og tilbringe tid med kona og tre barn når han ikke jobber.
 Daniel Rozo er en senior løsningsarkitekt med AWS som støtter kunder i Nederland. Hans lidenskap er å utvikle enkle data- og analyseløsninger og hjelpe kunder med å gå over til moderne dataarkitekturer. Utenom jobben liker han å spille tennis og sykle.
Daniel Rozo er en senior løsningsarkitekt med AWS som støtter kunder i Nederland. Hans lidenskap er å utvikle enkle data- og analyseløsninger og hjelpe kunder med å gå over til moderne dataarkitekturer. Utenom jobben liker han å spille tennis og sykle.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- : har
- :er
- :ikke
- :hvor
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- evne
- I stand
- akselerert
- adgang
- Handling
- Handling
- Ad
- adresse
- Agent
- Alle
- tillatt
- tillate
- tillater
- også
- alltid
- Amazon
- Amazon Kinesis
- Amazon Web Services
- Amazon Web Services (AWS)
- beløp
- beløp
- an
- Analytisk
- analytics
- og
- noen
- aktuelt
- søknader
- Påfør
- tilnærming
- hensiktsmessig
- arkitektur
- ER
- AS
- At
- attributter
- revisjon
- automatisere
- automatisk
- tilgjengelighet
- tilgjengelig
- AWS
- AWS Lim
- sikkerhetskopier
- Banking
- Banksystemer
- basert
- BE
- fordi
- vært
- før du
- være
- under
- nytte
- bringe
- bygge
- bygget
- innebygd
- men
- by
- CAN
- evner
- Kapasitet
- fangst
- kort
- saken
- saker
- katalog
- kategorier
- CDC
- celle
- endring
- Endringer
- kanaler
- Barn
- valgte
- klarhet
- Cloud
- Cluster
- kode
- Kolonne
- kolonner
- Kom
- kommer
- kommer
- kompatibel
- kompatibel
- komponenter
- Omfattet
- Beregn
- bekymringer
- tilkoblet
- Vurder
- ansett
- forbrukes
- forbruk
- inneholde
- kontekst
- fortsette
- kontroll
- korrigere
- Kostnader
- kunne
- land
- skape
- Credentials
- kreditt
- kredittkort
- kuratert
- Gjeldende
- Kunder
- dato
- Data Analytics
- dataintegrasjon
- Data Lake
- Dataplattform
- personvern
- datastrategi
- Database
- databaser
- datasett
- Dato
- dag
- Misligholde
- definert
- levert
- demonstrere
- demonstrerer
- utplassert
- utforming
- destinasjonen
- destinasjoner
- detaljer
- oppdage
- oppdaget
- Gjenkjenning
- Bestem
- Utvikling
- utviklingsteam
- forskjellig
- direkte
- oppdage
- oppdaget
- diskutert
- do
- domene
- domener
- ikke
- hver enkelt
- innsats
- emalje
- Ingeniørarbeid
- sikre
- Enterprise
- bedriftskunder
- Hele
- enheter
- Miljø
- Eter (ETH)
- Selv
- hendelser
- Hver
- eksempel
- eksempler
- forventet
- erfaring
- uttrykkene
- utvendig
- FAST
- Felt
- filet
- Filer
- finansiell
- finansielle tjenester
- Først
- Rennende
- Flows
- fokusering
- fulgt
- etter
- følger
- Til
- Rammeverk
- fra
- fullt
- fullt
- framtid
- genererer
- få
- god
- styresett
- innvilget
- Håndterer
- Håndtering
- Ha
- he
- Helse
- helseinformasjon
- hjelpe
- hjelpe
- hjelper
- høyt nivå
- hans
- historisk
- Hvordan
- Hvordan
- HTML
- http
- HTTPS
- Hundrevis
- identifisere
- if
- illustrerer
- forestille
- iverksette
- betydning
- viktig
- in
- inkludere
- Inkludert
- indeks
- individuelt
- informasjon
- Infrastruktur
- innsiden
- integrering
- intern
- inn
- IT
- Java
- Jobb
- Jobb
- jpg
- JSON
- Hold
- Kinesis Data brannslange
- Kinesis datastrømmer
- kjent
- innsjø
- Tomt
- lander
- stor
- Siste
- seinere
- Lover
- Lover og forskrifter
- lag
- lag
- Ledelse
- la
- Bibliotek
- Livssyklus
- i likhet med
- linje
- laste
- lasting
- steder
- Se
- lave kostnader
- Hoved
- opprettholde
- gjøre
- fikk til
- mange
- kartlegging
- maske
- Kan..
- metode
- metoder
- migrere
- migrasjon
- Moderne
- modern
- overvåking
- mer
- fjell
- flytte
- flytting
- mye
- flere
- må
- navn
- navn
- nødvendig
- Trenger
- nødvendig
- trenger
- behov
- Nederland
- Ny
- Nei.
- noder
- Legge merke til..
- nå
- Antall
- of
- Tilbud
- on
- ONE
- bare
- drift
- operasjonell
- Drift
- optimalisere
- alternativer
- or
- organisasjon
- organisasjoner
- Annen
- vår
- produksjon
- utenfor
- enn
- del
- lidenskap
- patching
- mønstre
- Betale
- betaling
- for
- utføre
- ytelse
- tillatelser
- personlig
- telefon
- PII
- rørledning
- fly
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- Point
- del
- Post
- forut
- presentert
- forrige
- privatliv
- personvernlover
- behandlet
- Prosesser
- prosessering
- produsent
- beskyttet
- protokoller
- leverandør
- gir
- kjøp
- spørsmål
- raskt
- heller
- Raw
- rådata
- sanntids
- grunner
- mottak
- oppskrifter
- anbefales
- rekord
- poster
- Redusert
- referere
- regelmessig
- forskrifter
- pålitelighet
- forbli
- fjerne
- Rapportering
- Rapporter
- krever
- behov
- Krav
- ansvar
- ansvarlig
- begrense
- Resultater
- roller
- RAD
- Kjør
- går
- SaaS
- ofre
- trygge
- trygt
- samme
- Skala
- skanne
- planlegge
- forskere
- Skjerm
- SDK
- Søk
- Seksjon
- sikkert
- sikkerhet
- se
- velg
- valgt
- senior
- sensitive
- sendt
- tjeneste
- Tjenester
- shot
- bør
- vist
- Viser
- Enkelt
- forenkle
- liten
- So
- selskap
- Software
- programvare som en tjeneste
- løsning
- Solutions
- kilde
- Kilder
- spesifikk
- spesielt
- spesifisert
- bruke
- utgifter
- spagaten
- stadier
- Stater
- Trinn
- lagring
- oppbevare
- rett fram
- Strategi
- stream
- streaming
- bekker
- String
- struktur
- strukturert
- studio
- senere
- vellykket
- slik
- egnet
- Støttes
- Støtte
- system
- Systemer
- bord
- tar
- Target
- lag
- lag
- teknikker
- tennis
- titus
- enn
- Det
- De
- Fremtiden
- Nederland
- Kilden
- deres
- deretter
- Der.
- Disse
- denne
- De
- tre
- terskel
- Gjennom
- tid
- til
- tok
- verktøy
- spor
- Transaksjoner
- overføre
- overføringer
- Transform
- Transformation
- Trender
- utløst
- to
- typen
- typer
- Til syvende og sist
- underliggende
- forståelse
- enhetlig
- forent
- Forente Stater
- us
- bruke
- bruk sak
- brukt
- Brukere
- ved hjelp av
- verdi
- variasjon
- ulike
- av
- visuell
- gå
- var
- måter
- we
- web
- webtjenester
- Hva
- når
- hvilken
- mens
- HVEM
- kone
- vil
- med
- innenfor
- uten
- Arbeid
- arbeidsflyt
- arbeid
- skrive
- du
- Din
- zephyrnet