I dag er vi glade for å kunngjøre at Lamavakt modellen er nå tilgjengelig for kunder som bruker Amazon SageMaker JumpStart. Llama Guard gir inngangs- og utdatasikringer i distribusjon av store språkmodeller (LLM). Det er en av komponentene under Purple Llama, Metas initiativ med åpne tillits- og sikkerhetsverktøy og evalueringer for å hjelpe utviklere med å bygge ansvarlig med AI-modeller. Purple Llama samler verktøy og evalueringer for å hjelpe samfunnet med å bygge ansvarlig med generative AI-modeller. Den første utgivelsen inkluderer et fokus på cybersikkerhet og LLM-inn- og utgangssikringer. Komponenter i Purple Llama-prosjektet, inkludert Llama Guard-modellen, er lisensiert tillatt, noe som muliggjør både forskning og kommersiell bruk.
Nå kan du bruke Llama Guard-modellen i SageMaker JumpStart. SageMaker JumpStart er knutepunktet for maskinlæring (ML). Amazon SageMaker som gir tilgang til grunnmodeller i tillegg til innebygde algoritmer og ende-til-ende løsningsmaler for å hjelpe deg raskt å komme i gang med ML.
I dette innlegget går vi gjennom hvordan du distribuerer Llama Guard-modellen og bygger ansvarlige generative AI-løsninger.
Llama Guard modell
Llama Guard er en ny modell fra Meta som gir inngangs- og utgangsrekkverk for LLM-utplasseringer. Llama Guard er en åpent tilgjengelig modell som yter konkurransedyktig på vanlige åpne benchmarks og gir utviklere en forhåndsopplært modell for å hjelpe til med å forsvare seg mot å generere potensielt risikable utganger. Denne modellen har blitt trent på en blanding av offentlig tilgjengelige datasett for å muliggjøre oppdagelse av vanlige typer potensielt risikabelt eller krenkende innhold som kan være relevant for en rekke brukertilfeller for utviklere. Til syvende og sist er modellens visjon å gjøre det mulig for utviklere å tilpasse denne modellen for å støtte relevante brukstilfeller og gjøre det enkelt å ta i bruk beste praksis og forbedre det åpne økosystemet.
Llama Guard kan brukes som et tilleggsverktøy for utviklere for å integrere i sine egne avbøtende strategier, for eksempel for chatbots, innholdsmoderering, kundeservice, overvåking av sosiale medier og utdanning. Ved å sende brukergenerert innhold gjennom Llama Guard før de publiserer eller svarer på det, kan utviklere flagge usikkert eller upassende språk og iverksette tiltak for å opprettholde et trygt og respektfullt miljø.
La oss utforske hvordan vi kan bruke Llama Guard-modellen i SageMaker JumpStart.
Fundamentmodeller i SageMaker
SageMaker JumpStart gir tilgang til en rekke modeller fra populære modellhuber, inkludert Hugging Face, PyTorch Hub og TensorFlow Hub, som du kan bruke i ML-utviklingsarbeidsflyten i SageMaker. Nylige fremskritt innen ML har gitt opphav til en ny klasse modeller kjent som grunnmodeller, som vanligvis er trent på milliarder av parametere og kan tilpasses en bred kategori av brukstilfeller, for eksempel tekstoppsummering, digital kunstgenerering og språkoversettelse. Fordi disse modellene er dyre å trene, ønsker kundene å bruke eksisterende forhåndstrente fundamentmodeller og finjustere dem etter behov, i stedet for å trene disse modellene selv. SageMaker gir en kurert liste over modeller som du kan velge mellom på SageMaker-konsollen.
Du kan nå finne fundamentmodeller fra forskjellige modellleverandører i SageMaker JumpStart, slik at du raskt kan komme i gang med fundamentmodeller. Du kan finne fundamentmodeller basert på ulike oppgaver eller modellleverandører, og enkelt gjennomgå modellens egenskaper og bruksvilkår. Du kan også prøve ut disse modellene ved å bruke en test UI-widget. Når du vil bruke en grunnmodell i stor skala, kan du gjøre det enkelt uten å forlate SageMaker ved å bruke forhåndsbygde notatbøker fra modellleverandører. Fordi modellene er vert og distribuert på AWS, kan du være trygg på at dataene dine, enten de brukes til å evaluere eller bruke modellen i stor skala, aldri deles med tredjeparter.
La oss utforske hvordan vi kan bruke Llama Guard-modellen i SageMaker JumpStart.
Oppdag Llama Guard-modellen i SageMaker JumpStart
Du kan få tilgang til Code Llama foundation-modeller gjennom SageMaker JumpStart i SageMaker Studio UI og SageMaker Python SDK. I denne delen går vi gjennom hvordan du oppdager modellene i Amazon SageMaker Studio.
SageMaker Studio er et integrert utviklingsmiljø (IDE) som gir et enkelt nettbasert visuelt grensesnitt der du kan få tilgang til spesialbygde verktøy for å utføre alle ML-utviklingstrinn, fra å forberede data til å bygge, trene og distribuere ML-modellene dine. For mer informasjon om hvordan du kommer i gang og konfigurerer SageMaker Studio, se Amazon SageMaker Studio.
I SageMaker Studio kan du få tilgang til SageMaker JumpStart, som inneholder ferdigtrente modeller, bærbare datamaskiner og forhåndsbygde løsninger, under Forhåndsbygde og automatiserte løsninger.
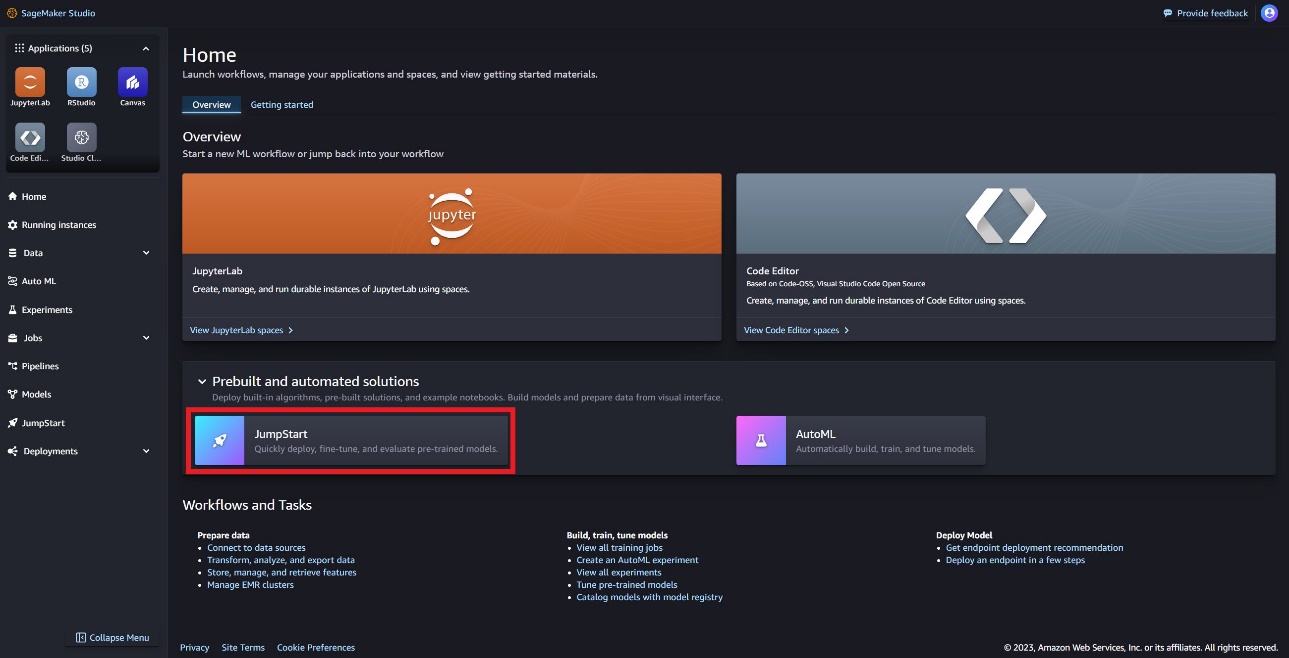
På SageMaker JumpStart-landingssiden kan du finne Llama Guard-modellen ved å velge Meta-huben eller søke etter Llama Guard.

Du kan velge mellom en rekke Llama-modellvarianter, inkludert Llama Guard, Llama-2 og Code Llama.

Du kan velge modellkortet for å se detaljer om modellen, for eksempel lisens, data som brukes til å trene, og hvordan du bruker den. Du finner også en Distribuer alternativet, som tar deg til en destinasjonsside der du kan teste slutninger med et eksempel på nyttelast.

Distribuer modellen med SageMaker Python SDK
Du kan finne koden som viser utplasseringen av Llama Guard på Amazon JumpStart og et eksempel på hvordan du bruker den utplasserte modellen i denne GitHub notatbok.
I følgende kode spesifiserer vi SageMaker modell hub modell ID og modellversjon som skal brukes når du distribuerer Llama Guard:
Du kan nå distribuere modellen ved å bruke SageMaker JumpStart. Følgende kode bruker standardforekomsten ml.g5.2xlarge for slutningsendepunktet. Du kan distribuere modellen på andre forekomsttyper ved å sende den instance_type i JumpStartModel klasse. Utrullingen kan ta noen minutter. For en vellykket distribusjon må du manuelt endre accept_eula argument i modellens distribusjonsmetode til True.
Denne modellen er distribuert ved hjelp av tekstgenerasjonsinferens (TGI) dyplæringsbeholder. Inferensforespørsler støtter mange parametere, inkludert følgende:
- maks lengde – Modellen genererer tekst til utdatalengden (som inkluderer inndatakontekstlengden) når
max_length. Hvis det er spesifisert, må det være et positivt heltall. - max_new_tokens – Modellen genererer tekst til utdatalengden (ekskludert inndatakontekstlengden) når
max_new_tokens. Hvis det er spesifisert, må det være et positivt heltall. - antall_bjelker – Dette indikerer antall stråler som brukes i det grådige søket. Hvis spesifisert, må det være et heltall større enn eller lik
num_return_sequences. - no_repeat_ngram_size – Modellen sikrer at en sekvens av ord av
no_repeat_ngram_sizegjentas ikke i utgangssekvensen. Hvis det er spesifisert, må det være et positivt heltall større enn 1. - temperatur – Denne parameteren kontrollerer tilfeldigheten i utgangen. En høyere
temperatureresulterer i en utdatasekvens med ord med lav sannsynlighet, og en laveretemperatureresulterer i en utdatasekvens med høysannsynlighetsord. Hvistemperatureer 0, resulterer det i grådig dekoding. Hvis spesifisert, må det være en positiv flyte. - tidlig_stopping - Hvis
True, er tekstgenereringen fullført når alle strålehypotesene når slutten av setningstokenet. Hvis det er spesifisert, må det være boolsk. - do_sample - Hvis
True, modellen prøver neste ord i henhold til sannsynligheten. Hvis det er spesifisert, må det være boolsk. - topp_k – I hvert trinn av tekstgenerering prøver modellen kun fra
top_kmest sannsynlige ord. Hvis det er spesifisert, må det være et positivt heltall. - topp_s – I hvert trinn av tekstgenerering prøver modellen fra det minste mulige settet med ord med kumulativ sannsynlighet
top_p. Hvis spesifisert, må det være en flyte mellom 0–1. - return_full_text - Hvis
True, vil inndatateksten være en del av den utdatagenererte teksten. Hvis det er spesifisert, må det være boolsk. Standardverdien erFalse. - stoppe – Hvis det er spesifisert, må det være en liste over strenger. Tekstgenerering stopper hvis en av de angitte strengene genereres.
Påkalle et SageMaker-endepunkt
Du kan programmatisk hente eksempler på nyttelast fra JumpStartModel gjenstand. Dette vil hjelpe deg raskt å komme i gang ved å observere forhåndsformaterte instruksjoner som Llama Guard kan innta. Se følgende kode:
Etter at du har kjørt det foregående eksemplet, kan du se hvordan input og output vil bli formatert av Llama Guard:
I likhet med Llama-2 bruker Llama Guard spesielle tokens for å indikere sikkerhetsinstruksjoner til modellen. Generelt bør nyttelasten følge formatet nedenfor:
Brukerledetekst vist som {user_prompt} ovenfor, kan videre inkludere seksjoner for innholdskategoridefinisjoner og samtaler, som ser slik ut:
I neste avsnitt diskuterer vi de anbefalte standardverdiene for oppgave-, innholdskategori- og instruksjonsdefinisjoner. Samtalen skal veksle mellom User og Agent tekst som følger:
Moderer en samtale med Llama-2 Chat
Du kan nå distribuere et Llama-2 7B Chat-endepunkt for samtalechat og deretter bruke Llama Guard til å moderere inn- og uttekst fra Llama-2 7B Chat.
Vi viser deg eksempelet på Llama-2 7B chat-modellens input og output moderert gjennom Llama Guard, men du kan bruke Llama Guard for moderering med hvilken som helst LLM du ønsker.
Distribuer modellen med følgende kode:
Du kan nå definere oppgavemalen for Lamavakten. De usikre innholdskategoriene kan justeres etter ønske for din spesifikke brukssituasjon. Du kan i ren tekst definere betydningen av hver innholdskategori, inkludert hvilket innhold som skal flagges som usikkert og hvilket innhold som skal tillates som trygt. Se følgende kode:
Deretter definerer vi hjelpefunksjoner format_chat_messages og format_guard_messages for å formatere forespørselen for chat-modellen og for Llama Guard-modellen som krevde spesielle tokens:
Du kan deretter bruke disse hjelpefunksjonene på et eksempel på meldingsinntasting for å kjøre eksempelinndata gjennom Llama Guard for å finne ut om meldingsinnholdet er trygt:
Følgende utgang indikerer at meldingen er trygg. Du kan legge merke til at forespørselen inkluderer ord som kan være assosiert med vold, men i dette tilfellet er Llama Guard i stand til å forstå konteksten med hensyn til instruksjonene og usikre kategoridefinisjonene vi ga tidligere, og fastslå at det er en sikker forespørsel og ikke knyttet til vold.
Nå som du har bekreftet at inndatateksten er fastslått å være trygg med hensyn til innholdskategoriene dine i Llama Guard, kan du overføre denne nyttelasten til den utplasserte Llama-2 7B-modellen for å generere tekst:
Følgende er svaret fra modellen:
Til slutt kan det være lurt å bekrefte at svarteksten fra modellen er bestemt til å inneholde sikkert innhold. Her utvider du LLM-utgangsresponsen til inngangsmeldingene og kjører hele denne samtalen gjennom Llama Guard for å sikre at samtalen er trygg for applikasjonen din:
Du kan se følgende utgang, som indikerer at svaret fra chat-modellen er trygt:
Rydd opp
Etter at du har testet endepunktene, sørg for at du sletter SageMaker-slutningsendepunktene og modellen for å unngå kostnader.
konklusjonen
I dette innlegget viste vi deg hvordan du kan moderere innganger og utganger ved å bruke Llama Guard og sette rekkverk for innganger og utganger fra LLM-er i SageMaker JumpStart.
Ettersom AI fortsetter å utvikle seg, er det avgjørende å prioritere ansvarlig utvikling og distribusjon. Verktøy som Purple Llama’s CyberSecEval og Llama Guard er medvirkende til å fremme sikker innovasjon, og tilbyr tidlig risikoidentifikasjon og reduserende veiledning for språkmodeller. Disse bør være forankret i AI-designprosessen for å utnytte dets fulle potensiale til LLM-er etisk fra dag 1.
Prøv ut Llama Guard og andre grunnmodeller i SageMaker JumpStart i dag og gi oss tilbakemeldingen din!
Denne veiledningen er kun til informasjonsformål. Du bør fortsatt utføre din egen uavhengige vurdering, og iverksette tiltak for å sikre at du overholder dine egne spesifikke kvalitetskontrollpraksiser og standarder, og de lokale reglene, lovene, forskriftene, lisensene og bruksvilkårene som gjelder deg, innholdet ditt, og tredjepartsmodellen det refereres til i denne veiledningen. AWS har ingen kontroll eller autoritet over tredjepartsmodellen det refereres til i denne veiledningen, og gir ingen representasjoner eller garantier for at tredjepartsmodellen er sikker, virusfri, operativ eller kompatibel med ditt produksjonsmiljø og standarder. AWS gir ingen representasjoner, garantier eller garanterer at informasjon i denne veiledningen vil resultere i et bestemt resultat eller resultat.
Om forfatterne
 Dr. Kyle Ulrich er en anvendt vitenskapsmann med Amazon SageMaker innebygde algoritmer team. Hans forskningsinteresser inkluderer skalerbare maskinlæringsalgoritmer, datasyn, tidsserier, Bayesianske ikke-parametriske og Gaussiske prosesser. Hans doktorgrad er fra Duke University og han har publisert artikler i NeurIPS, Cell og Neuron.
Dr. Kyle Ulrich er en anvendt vitenskapsmann med Amazon SageMaker innebygde algoritmer team. Hans forskningsinteresser inkluderer skalerbare maskinlæringsalgoritmer, datasyn, tidsserier, Bayesianske ikke-parametriske og Gaussiske prosesser. Hans doktorgrad er fra Duke University og han har publisert artikler i NeurIPS, Cell og Neuron.
 Evan Kravitz er programvareingeniør hos Amazon Web Services, og jobber med SageMaker JumpStart. Han er interessert i sammenløpet av maskinlæring med cloud computing. Evan fikk sin lavere grad fra Cornell University og mastergrad fra University of California, Berkeley. I 2021 presenterte han et papir om adversarielle nevrale nettverk på ICLR-konferansen. På fritiden liker Evan å lage mat, reise og løpe i New York City.
Evan Kravitz er programvareingeniør hos Amazon Web Services, og jobber med SageMaker JumpStart. Han er interessert i sammenløpet av maskinlæring med cloud computing. Evan fikk sin lavere grad fra Cornell University og mastergrad fra University of California, Berkeley. I 2021 presenterte han et papir om adversarielle nevrale nettverk på ICLR-konferansen. På fritiden liker Evan å lage mat, reise og løpe i New York City.
 Rachna Chadha er en hovedløsningsarkitekt AI/ML i strategiske kontoer hos AWS. Rachna er en optimist som tror at etisk og ansvarlig bruk av AI kan forbedre samfunnet i fremtiden og bringe økonomisk og sosial velstand. På fritiden liker Rachna å tilbringe tid med familien, gå på tur og høre på musikk.
Rachna Chadha er en hovedløsningsarkitekt AI/ML i strategiske kontoer hos AWS. Rachna er en optimist som tror at etisk og ansvarlig bruk av AI kan forbedre samfunnet i fremtiden og bringe økonomisk og sosial velstand. På fritiden liker Rachna å tilbringe tid med familien, gå på tur og høre på musikk.
 Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker innebygde algoritmer og hjelper til med å utvikle maskinlæringsalgoritmer. Han fikk sin doktorgrad fra University of Illinois Urbana-Champaign. Han er en aktiv forsker innen maskinlæring og statistisk inferens, og har publisert mange artikler på NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP-konferanser.
Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker innebygde algoritmer og hjelper til med å utvikle maskinlæringsalgoritmer. Han fikk sin doktorgrad fra University of Illinois Urbana-Champaign. Han er en aktiv forsker innen maskinlæring og statistisk inferens, og har publisert mange artikler på NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP-konferanser.
 Karl Albertsen leder produkt, ingeniørfag og vitenskap for Amazon SageMaker Algorithms og JumpStart, SageMakers maskinlæringssenter. Han brenner for å bruke maskinlæring for å låse opp forretningsverdi.
Karl Albertsen leder produkt, ingeniørfag og vitenskap for Amazon SageMaker Algorithms og JumpStart, SageMakers maskinlæringssenter. Han brenner for å bruke maskinlæring for å låse opp forretningsverdi.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 1
- 10
- 100
- 11
- 12
- 13
- 2021
- 39
- 7
- 8
- 9
- a
- I stand
- Om oss
- ovenfor
- Aksepterer
- adgang
- Ifølge
- kontoer
- Handling
- Handling
- handlinger
- aktiv
- Aktiviteter
- faktiske
- tillegg
- justert
- adoptere
- avansere
- fremskritt
- motstandere
- råd
- mot
- Agent
- AI
- AI-modeller
- AI / ML
- Alkohol
- algoritmer
- Alle
- også
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- an
- og
- Kunngjøre
- besvare
- noen
- Søknad
- anvendt
- Påfør
- påføring
- hensiktsmessig
- ER
- argument
- argumenter
- Kunst
- AS
- evaluering
- bistå
- Assistent
- assosiert
- trygg
- At
- myndighet
- Automatisert
- tilgjengelig
- unngå
- AWS
- basert
- grunnleggende
- Bayesiansk
- BE
- Beam
- fordi
- vært
- før du
- begynne
- atferd
- mener
- under
- benchmarks
- Berkeley
- BEST
- beste praksis
- mellom
- milliarder
- kroppen
- både
- bringe
- Bringer
- bygge
- Bygning
- innebygd
- virksomhet
- men
- by
- california
- CAN
- cannabis
- kort
- saken
- saker
- kategorier
- Kategori
- celle
- utfordringer
- sjanse
- endring
- egenskaper
- avgifter
- chatte
- chatbots
- sjekk
- kjemisk
- valg
- Velg
- velge
- City
- klasse
- ren
- Cloud
- cloud computing
- kode
- farge
- kommer
- kommersiell
- forpliktet
- Felles
- samfunnet
- kompatibel
- overholde
- komponenter
- sammensetning
- datamaskin
- Datamaskin syn
- databehandling
- Konferanse
- konferanser
- Bekrefte
- BEKREFTET
- sammenløp
- Konsoll
- forbruk
- inneholde
- Container
- inneholder
- innhold
- innholdsmoderasjon
- kontekst
- fortsetter
- kontroll
- kontrolleres
- kontroller
- Samtale
- conversational
- samtaler
- matlaging
- cornell
- kunne
- skape
- skaperverket
- forbrytelser
- Criminal
- kritisk
- kuratert
- kunde
- Kundeservice
- Kunder
- tilpasse
- cyber
- cybersikkerhet
- syklus
- dato
- datasett
- dag
- Dekoding
- dyp
- dyp læring
- Misligholde
- definere
- definisjoner
- Grad
- utplassere
- utplassert
- utplasserings
- distribusjon
- distribusjoner
- utforming
- design prosess
- ønske
- ønsket
- detaljert
- detaljer
- Gjenkjenning
- Bestem
- bestemmes
- utvikle
- Utvikler
- utviklere
- Utvikling
- DIKT
- forskjellig
- digitalt
- digital kunst
- Uførhet
- oppdage
- Diskriminering
- diskutere
- do
- gjør
- Narkotika
- Duke
- duke universitetet
- e
- hver enkelt
- Tidligere
- Tidlig
- lett
- økonomisk
- økosystem
- Kunnskap
- effekter
- uanstrengt
- muliggjøre
- muliggjør
- oppmuntre
- slutt
- ende til ende
- Endpoint
- endepunkter
- engasjere
- ingeniør
- Ingeniørarbeid
- sikre
- sikrer
- Miljø
- lik
- spesielt
- Eter (ETH)
- etisk
- evaluere
- evalueringer
- hendelser
- eksempel
- Unntatt
- unntak
- opphisset
- Eksklusiv
- gjennomføring
- eksisterende
- dyrt
- utforske
- ekspress
- utvide
- Face
- møtt
- falsk
- familie
- Featuring
- Noen få
- finansiell
- økonomiske forbrytelser
- Finn
- skytevåpen
- Først
- flaggede
- Flyte
- Fokus
- følge
- fulgt
- etter
- følger
- Til
- format
- fostre
- Fundament
- Gratis
- fra
- fullt
- funksjoner
- videre
- framtid
- Kjønn
- general
- generere
- generert
- genererer
- genererer
- generasjonen
- generative
- Generativ AI
- få
- GitHub
- gitt
- Giving
- Go
- skal
- fikk
- større
- Greedy
- garantier
- Guard
- veiledning
- GUNS
- skade
- seletøy
- hater
- Ha
- he
- Helse
- hjelpe
- hjelper
- her
- her.
- høyere
- vandreturer
- hans
- historisk
- vert
- Hvordan
- Hvordan
- HTML
- HTTPS
- Hub
- huber
- i
- ICLR
- ID
- Identifikasjon
- Identitet
- if
- ulovlig
- Illinois
- umiddelbart
- importere
- forbedre
- in
- inkludere
- inkluderer
- Inkludert
- uavhengig
- indikerer
- indikerer
- indikerer
- informasjon
- Informativ
- inngrodd
- innledende
- Initiative
- Innovasjon
- inngang
- innganger
- f.eks
- instruksjoner
- instrumental
- integrere
- integrert
- interessert
- interesser
- Interface
- inn
- involverer
- IT
- DET ER
- jpg
- Drepe
- Vet
- kjent
- Kyle
- landing
- destinasjonssiden
- Språk
- stor
- Siste
- Lover
- Fører
- læring
- forlater
- Lengde
- la
- Tillatelse
- Licensed
- lisenser
- i likhet med
- sannsynligheten
- Sannsynlig
- liker
- Begrenset
- linje
- linux
- Liste
- Lytting
- Llama
- lokal
- UTSEENDE
- lavere
- maskin
- maskinlæring
- vedlikeholde
- gjøre
- manuelt
- produsert
- mange
- mestere
- Kan..
- betyr
- målinger
- Media
- mental
- Mental Helse
- melding
- meldinger
- Meta
- metode
- metoder
- kunne
- minutter
- skadebegrensning
- bland
- ML
- modell
- modeller
- moderat
- moderasjon
- overvåking
- mer
- mest
- musikk
- må
- Må lese
- nasjonal
- nødvendig
- nettverk
- neural
- nevrale nettverk
- NeurIPS
- aldri
- Ny
- New York
- New York City
- neste
- Nei.
- bærbare
- notatbøker
- Legge merke til..
- nå
- Antall
- objekt
- of
- tilby
- on
- ONE
- bare
- åpen
- åpenlyst
- operasjonell
- Alternativ
- alternativer
- or
- Origin
- Annen
- vår
- ut
- Utfallet
- produksjon
- utganger
- enn
- egen
- eierskap
- side
- Papir
- papirer
- parameter
- parametere
- del
- Spesielt
- parter
- passere
- Passerer
- lidenskapelig
- Ansatte
- for
- utføre
- utfører
- person
- personlig
- phd
- Plain
- fly
- planlegging
- plato
- Platon Data Intelligence
- PlatonData
- politikk
- Populær
- positiv
- mulig
- Post
- potensiell
- potensielt
- praksis
- forut
- Predictor
- forbereder
- presentert
- forebygge
- Principal
- Prioriter
- sannsynlighet
- prosess
- Prosesser
- Produkt
- Produksjon
- prosjekt
- ledetekster
- velstand
- gi
- forutsatt
- tilbydere
- gir
- offentlig
- publisert
- Publisering
- formål
- sette
- Python
- pytorch
- kvalitet
- raskt
- Race
- tilfeldig
- område
- heller
- å nå
- Når
- Lese
- mottatt
- nylig
- anbefales
- referere
- om
- regulert
- forskrifter
- i slekt
- slipp
- relevant
- religion
- gjentatt
- erstatte
- forespørsler
- påkrevd
- forskning
- forsker
- Ressurser
- respekt
- svare
- svar
- ansvarlig
- ansvarlig
- REST
- resultere
- Resultater
- retur
- anmeldelse
- Rise
- Risiko
- Risikabelt
- veikart
- Rolle
- roller
- regler
- Kjør
- går
- trygge
- sikringstiltak
- Sikkerhet
- sagemaker
- SageMaker Inference
- skalerbar
- Skala
- Vitenskap
- Forsker
- SDK
- Søk
- søker
- Sekund
- Seksjon
- seksjoner
- sikre
- sikkerhet
- se
- velg
- senior
- sensitive
- dømme
- følelser
- Sequence
- Serien
- tjeneste
- Tjenester
- sett
- Seksuell
- delt
- bør
- Vis
- viste
- viser
- vist
- enkelt
- So
- selskap
- sosiale medier
- Samfunnet
- Software
- Software Engineer
- løsning
- Solutions
- spesiell
- spesifikk
- spesifisert
- utgifter
- standarder
- startet
- Start
- statistisk
- statistikk
- Trinn
- Steps
- Still
- Stopper
- Strategisk
- strategier
- studio
- vellykket
- slik
- Suicide
- støtte
- Støtter
- sikker
- syntaks
- system
- Systemer
- Ta
- Oppgave
- oppgaver
- lag
- mal
- maler
- tensorflow
- vilkår
- test
- testet
- tekst
- tekstgenerering
- enn
- Det
- De
- Fremtiden
- informasjonen
- tyveri
- deres
- Dem
- seg
- deretter
- Der.
- Disse
- de
- Tredje
- tredjeparter
- tredjeparts
- denne
- De
- Gjennom
- tid
- Tidsserier
- til
- tobakk
- i dag
- sammen
- token
- tokens
- verktøy
- verktøy
- temaer
- menneskehandel
- Tog
- trent
- Kurs
- Oversettelse
- Traveling
- sant
- Stol
- prøve
- SVING
- typer
- typisk
- ui
- Til syvende og sist
- etter
- forstå
- universitet
- University of California
- låse opp
- til
- us
- bruk
- bruke
- bruk sak
- brukt
- Bruker
- bruker
- ved hjelp av
- verdi
- Verdier
- variasjon
- versjon
- Se
- krenket
- brudd
- syn
- visuell
- gå
- ønsker
- Vei..
- we
- Våpen
- web
- webtjenester
- Web-basert
- Hva
- når
- om
- hvilken
- HVEM
- hele
- bred
- vil
- med
- innenfor
- uten
- ord
- ord
- Arbeid
- arbeidsflyt
- arbeid
- ville
- york
- du
- Din
- zephyrnet