Bilde av forfatter
Når du dykker inn i verden av datavitenskap og maskinlæring, er en av de grunnleggende ferdighetene du vil møte kunsten å lese data. Hvis du allerede har litt erfaring med det, er du sannsynligvis kjent med JSON (JavaScript Object Notation) – et populært format for både lagring og utveksling av data.
Tenk på hvordan NoSQL-databaser som MongoDB elsker å lagre data i JSON, eller hvordan REST API-er ofte reagerer i samme format.
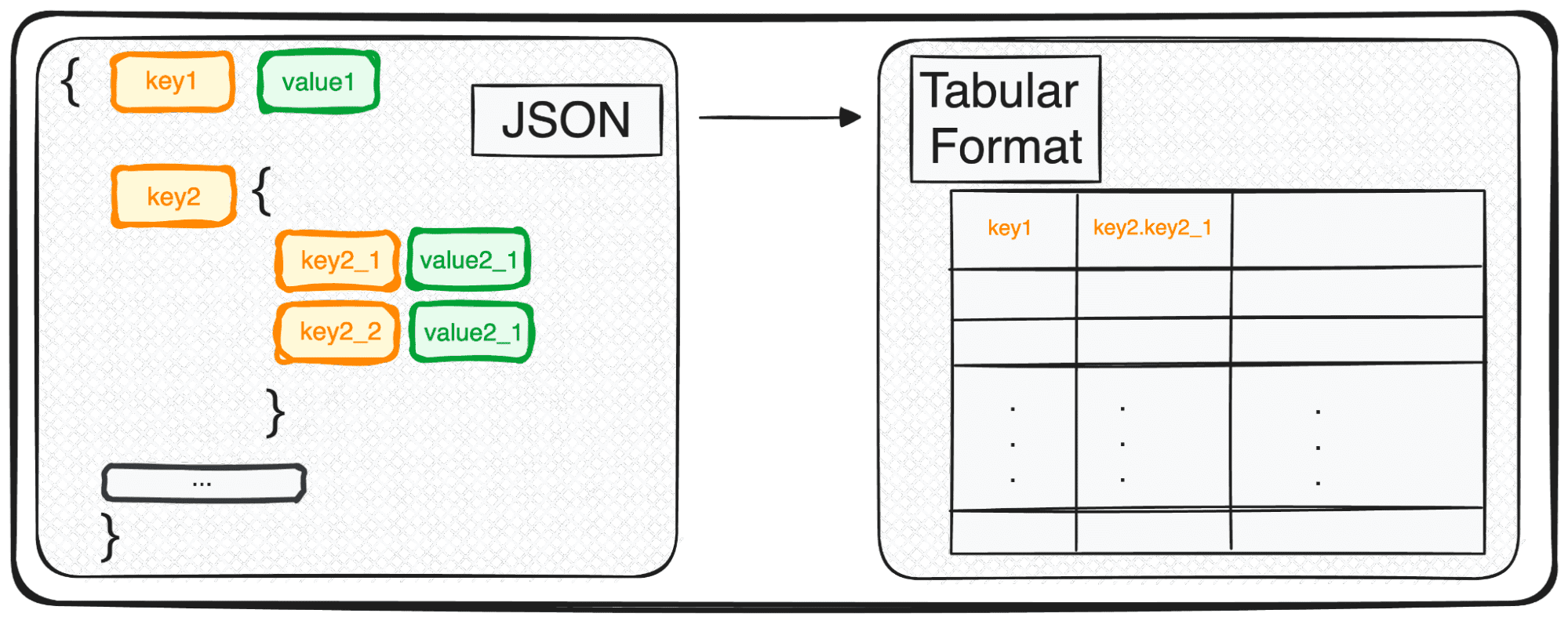
Selv om JSON er perfekt for lagring og utveksling, er imidlertid ikke helt klar for dybdeanalyse i sin rå form. Det er her vi forvandler det til noe mer analytisk vennlig – et tabellformat.
Så, enten du har å gjøre med et enkelt JSON-objekt eller en herlig rekke av dem, i Pythons termer, håndterer du i hovedsak en dict eller en liste over dicts.
La oss sammen utforske hvordan denne transformasjonen utfolder seg, noe som gjør dataene våre modne for analyse ????
I dag skal jeg forklare en magisk kommando som lar oss enkelt analysere enhver JSON til et tabellformat på sekunder.
Og det er... pd.json_normalize()
Så la oss se hvordan det fungerer med forskjellige typer JSON-er.
Den første typen JSON vi kan jobbe med er JSON-er på ett nivå med noen få nøkler og verdier. Vi definerer våre første enkle JSON-er som følger:
Kode etter forfatter
Så la oss simulere behovet for å jobbe med disse JSON. Vi vet alle at det ikke er mye å gjøre i deres JSON-format. Vi må transformere disse JSON-ene til et eller annet lesbart og modifiserbart format ... som betyr Pandas DataFrames!
1.1 Håndtere enkle JSON-strukturer
Først må vi importere pandas-biblioteket, og deretter kan vi bruke kommandoen pd.json_normalize(), som følger:
import pandas as pd
pd.json_normalize(json_string)
Ved å bruke denne kommandoen på en JSON med en enkelt post, får vi den mest grunnleggende tabellen. Men når dataene våre er litt mer komplekse og presenterer en liste over JSON-er, kan vi fortsatt bruke den samme kommandoen uten ytterligere komplikasjoner, og utdataene vil tilsvare en tabell med flere poster.

Bilde av forfatter
Enkelt... ikke sant?
Det neste naturlige spørsmålet er hva som skjer når noen av verdiene mangler.
1.2 Håndtere nullverdier
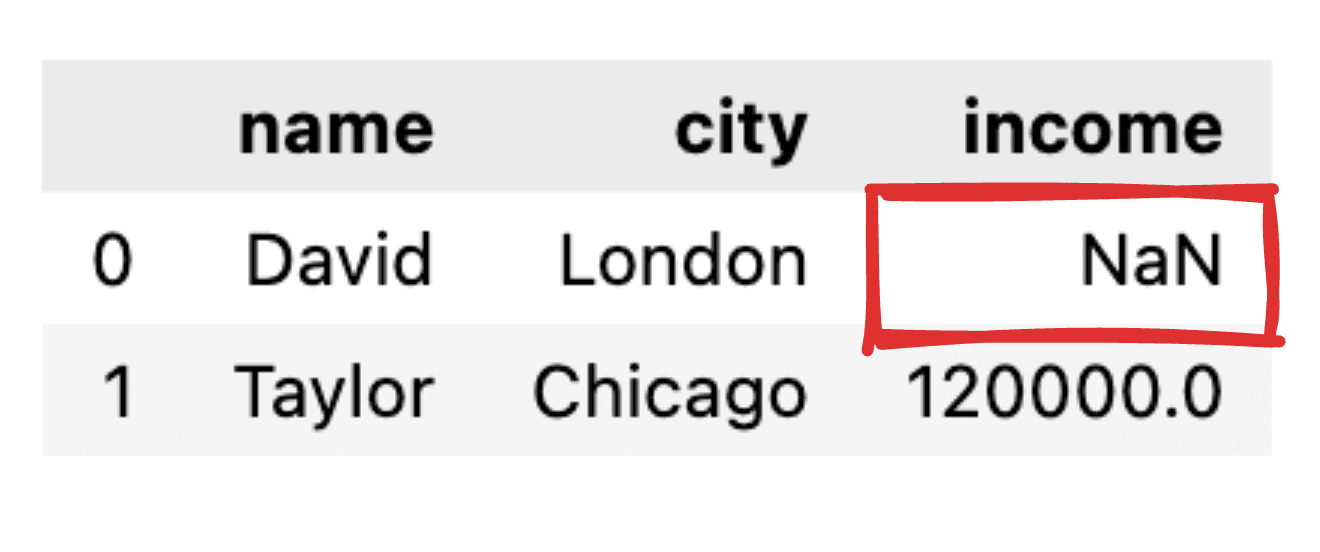
Tenk deg at noen av verdiene ikke er informert, som for eksempel at inntektsrekorden for David mangler. Når vi transformerer vår JSON til en enkel panda-dataramme, vil den tilsvarende verdien vises som NaN.
Bilde av forfatter
Og hva om jeg bare ønsker å få noen av feltene?
1.3 Velge kun de kolonnene av interesse
I tilfelle vi bare ønsker å transformere noen spesifikke felt til en tabellformet pandas DataFrame, lar ikke kommandoen json_normalize() oss velge hvilke felt som skal transformeres.
Derfor bør en liten forhåndsbehandling av JSON utføres der vi filtrerer bare de kolonnene som er av interesse.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Så la oss gå til en mer avansert JSON-struktur.
Når vi har å gjøre med JSON-er med flere nivåer, befinner vi oss med nestede JSON-er innenfor forskjellige nivåer. Prosedyren er den samme som før, men i dette tilfellet kan vi velge hvor mange nivåer vi vil transformere. Som standard vil kommandoen alltid utvide alle nivåer og generere nye kolonner som inneholder det sammenkoblede navnet på alle de nestede nivåene.
Så hvis vi normaliserer følgende JSON-er.
Kode etter forfatter
Vi vil få følgende tabell med 3 kolonner under feltferdighetene:
- skills.python
- ferdigheter.SQL
- ferdigheter.GCP
og 4 kolonner under feltrollene
- roller.prosjektleder
- roller.dataingeniør
- roller.dataforsker
- roller.dataanalytiker

Bilde av forfatter
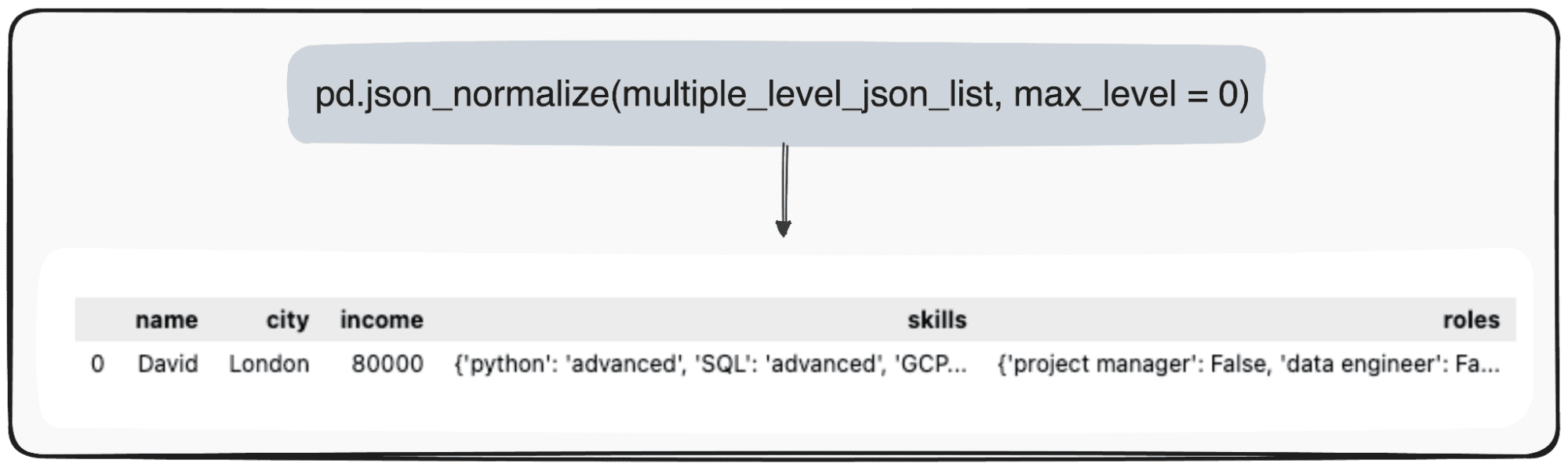
Tenk deg imidlertid at vi bare ønsker å transformere toppnivået vårt. Vi kan gjøre det ved å spesifikt definere parameteren max_level til 0 (max_level vi ønsker å utvide).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
De ventende verdiene vil bli opprettholdt innenfor JSON-er innenfor vår pandas DataFrame.
Bilde av forfatter
Det siste tilfellet vi kan finne er å ha en nestet liste i et JSON-felt. Så vi definerer først JSONene våre som skal brukes.
Kode etter forfatter
Vi kan effektivt administrere disse dataene ved å bruke Pandas i Python. Funksjonen pd.json_normalize() er spesielt nyttig i denne sammenhengen. Den kan flate ut JSON-dataene, inkludert den nestede listen, til et strukturert format som er egnet for analyse. Når denne funksjonen brukes på JSON-dataene våre, produserer den en normalisert tabell som inkorporerer den nestede listen som en del av feltene.
Dessuten tilbyr Pandas muligheten til å avgrense denne prosessen ytterligere. Ved å bruke record_path-parameteren i pd.json_normalize(), kan vi styre funksjonen til å spesifikt normalisere den nestede listen.
Denne handlingen resulterer i en dedikert tabell eksklusivt for listens innhold. Som standard vil denne prosessen bare utfolde elementene i listen. For å berike denne tabellen med ekstra kontekst, for eksempel å beholde en tilknyttet ID for hver post, kan vi imidlertid bruke metaparameteren.

Bilde av forfatter
Oppsummert er transformasjonen av JSON-data til CSV-filer ved hjelp av Pythons Pandas-bibliotek enkel og effektiv.
JSON er fortsatt det vanligste formatet i moderne datalagring og -utveksling, spesielt i NoSQL-databaser og REST APIer. Det gir imidlertid noen viktige analytiske utfordringer når man håndterer data i sitt råformat.
Den sentrale rollen til Pandas' pd.json_normalize() fremstår som en flott måte å håndtere slike formater på og konvertere dataene våre til pandas DataFrame.
Jeg håper denne veiledningen var nyttig, og neste gang du arbeider med JSON, kan du gjøre det på en mer effektiv måte.
Du kan gå og sjekke den tilsvarende Jupyter Notebook i følger GitHub repo.
Josep Ferrer er en analyseingeniør fra Barcelona. Han ble uteksaminert i fysikkingeniør og jobber for tiden i Data Science-feltet brukt på menneskelig mobilitet. Han er en deltidsinnholdsskaper med fokus på datavitenskap og teknologi. Du kan kontakte ham på Linkedin, Twitter or Medium.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :er
- :ikke
- :hvor
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- Om oss
- Handling
- Ytterligere
- avansert
- Alle
- tillate
- tillater
- allerede
- alltid
- an
- analyse
- analytiker
- analytisk
- analytics
- og
- noen
- APIer
- vises
- anvendt
- påføring
- ER
- Array
- Kunst
- AS
- assosiert
- barcelona
- grunnleggende
- BE
- før du
- Bit
- både
- men
- by
- CAN
- evne
- saken
- utfordringer
- sjekk
- Velg
- City
- kolonner
- Felles
- komplekse
- komplikasjoner
- kontakt
- innhold
- innhold
- kontekst
- konvertere
- konvertering
- tilsvare
- Tilsvarende
- skaperen
- I dag
- dato
- data analytiker
- dataingeniør
- datavitenskap
- dataforsker
- datalagring
- databaser
- David
- håndtering
- dedikert
- Misligholde
- definere
- definere
- herlig
- DIKT
- forskjellig
- direkte
- do
- gjør
- hver enkelt
- lett
- lett
- Effektiv
- effektivt
- elementer
- framgår
- møte
- ingeniør
- Ingeniørarbeid
- berike
- hovedsak
- utveksling
- utveksling
- utelukkende
- Expand
- erfaring
- forklare
- utforske
- kjent
- Noen få
- felt
- Felt
- Filer
- filtrere
- Finn
- Først
- fokuserte
- etter
- følger
- Til
- skjema
- format
- vennlig
- fra
- funksjon
- fundamental
- videre
- GCP
- generere
- få
- GitHub
- Go
- flott
- veilede
- håndtere
- Håndtering
- skjer
- Ha
- å ha
- he
- ham
- håp
- Hvordan
- Men
- HTTPS
- menneskelig
- i
- JEG VIL
- ID
- if
- forestille
- importere
- viktig
- in
- dyptgående
- inkludere
- Inkludert
- Inntekt
- inkorporerer
- informert
- f.eks
- interesse
- inn
- er n
- IT
- DET ER
- Javascript
- JSON
- Jupyter Notebook
- bare
- KDnuggets
- nøkkel
- nøkler
- Vet
- Siste
- læring
- Nivå
- nivåer
- Bibliotek
- i likhet med
- Liste
- lite
- ll
- elsker
- maskin
- maskinlæring
- magi
- opprettholdt
- Making
- administrer
- leder
- mange
- midler
- Meta
- mangler
- mobilitet
- Moderne
- MongoDB
- mer
- mest
- flytte
- mye
- flere
- navn
- Naturlig
- Trenger
- nestet
- Ny
- neste
- Nei.
- spesielt
- bærbare
- objekt
- få
- of
- Tilbud
- ofte
- on
- ONE
- bare
- or
- vår
- oss selv
- produksjon
- pandaer
- parameter
- del
- spesielt
- påvente
- perfekt
- utført
- Fysikk
- sentral
- plato
- Platon Data Intelligence
- PlatonData
- Populær
- gaver
- sannsynligvis
- prosedyren
- prosess
- produserer
- prosjekt
- Python
- spørsmål
- ganske
- Raw
- RE
- Lesning
- klar
- rekord
- poster
- avgrense
- Svare
- REST
- Resultater
- støttemur
- ikke sant
- Rolle
- s
- samme
- Vitenskap
- Vitenskap og teknologi
- Forsker
- sekunder
- se
- velge
- bør
- Enkelt
- simulere
- enkelt
- ferdigheter
- liten
- So
- noen
- noe
- spesifikk
- spesielt
- SQL
- Still
- lagring
- oppbevare
- struktur
- strukturert
- slik
- egnet
- SAMMENDRAG
- T
- bord
- Teknologi
- vilkår
- Det
- De
- verden
- deres
- Dem
- deretter
- Disse
- denne
- De
- tid
- til
- sammen
- topp
- Transform
- Transformation
- transformere
- typen
- typer
- etter
- us
- bruke
- nyttig
- ved hjelp av
- utnytte
- verdi
- Verdier
- ønsker
- var
- Vei..
- we
- Hva
- når
- om
- hvilken
- mens
- vil
- med
- innenfor
- Arbeid
- arbeid
- virker
- verden
- ville
- du
- zephyrnet