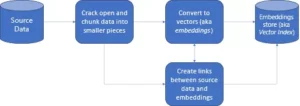
Introduksjon
I det raskt utviklende landskapet til generativ AI, har den sentrale rollen til vektordatabaser blitt stadig tydeligere. Denne artikkelen dykker ned i den dynamiske synergien mellom vektordatabaser og generative AI-løsninger, og utforsker hvordan disse teknologiske grunnfjellene former fremtiden for kreativitet med kunstig intelligens. Bli med oss på en reise gjennom forviklingene i denne kraftige alliansen, og lås opp innsikt i den transformative effekten som vektordatabaser bringer i forkant av innovative AI-løsninger.
Læringsmål
Denne artikkelen hjelper deg å forstå aspektene ved Vector Database nedenfor.
- Betydningen av vektordatabaser og dens nøkkelkomponenter
- Detaljert studie av vektordatabasesammenligning med tradisjonell database
- Utforskning av Vector Embeddings fra et applikasjonssynspunkt
- Vektordatabasebygging ved hjelp av Pincone
- Implementering av Pinecone Vector-database ved bruk av langchain LLM-modell
Denne artikkelen ble publisert som en del av Data Science Blogathon.
Innholdsfortegnelse
Hva er vektordatabase?
En vektordatabase er en form for datainnsamling lagret i verdensrommet. Likevel, her er det lagret i matematiske representasjoner siden formatet som er lagret i databasene gjør det lettere for åpne AI-modeller å huske inngangene og lar vår åpne AI-applikasjon bruke kognitivt søk, anbefalinger og tekstgenerering for ulike brukstilfeller i de digitalt transformerte industrien. Lagring av data og gjenfinning kalles "Vector Embeddings" eller "Embeddings." Dessuten er dette representert i et numerisk matriseformat. Søking er mye enklere enn tradisjonelle databaser som brukes for AI-perspektiver med massive, indekserte funksjoner.
Kjennetegn ved vektordatabaser
- Den utnytter kraften til disse vektorinnbyggingene, noe som fører til indeksering og søk på tvers av et massivt datasett.
- Kompakterbar med alle dataformater (bilder, tekst eller data).
- Siden den tilpasser innbyggingsteknikker og svært indekserte funksjoner, kan den tilby en komplett løsning for å administrere data og input for det gitte problemet.
- En vektordatabase organiserer data gjennom høydimensjonale vektorer som inneholder hundrevis av dimensjoner. Vi kan konfigurere dem veldig raskt.
- Hver dimensjon tilsvarer en spesifikk funksjon eller egenskap til dataobjektet den representerer.
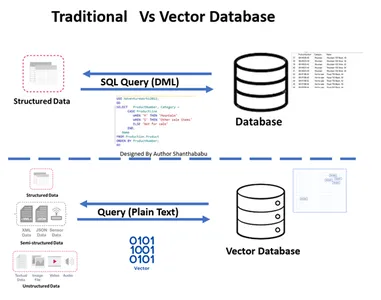
Tradisjonell vs. Vektordatabase
- Bildet viser den tradisjonelle arbeidsflyten og vektordatabasen på høyt nivå
- Formelle databaseinteraksjoner skjer gjennom SQL utsagn og data lagret i radbasert og tabellformat.
- I Vector-databasen skjer interaksjoner gjennom ren tekst (f.eks. engelsk) og data lagret i matematiske representasjoner.
Likhet til tradisjonelle og vektordatabaser
Vi må vurdere hvordan Vector-databaser skiller seg fra tradisjonelle. La oss diskutere dette her. En rask forskjell jeg kan gi er den i konvensjonelle databaser. Data lagres nøyaktig som de er; vi kan legge til litt forretningslogikk for å justere dataene og slå sammen eller dele dataene basert på forretningskravene eller -kravene. Imidlertid har vektordatabasen en massiv transformasjon, og dataene blir en kompleks vektorrepresentasjon.
Her er et kart for din forståelse og klarhet perspektiv med relasjonsdatabaser mot vektordatabaser. Bildet nedenfor er selvforklarende for å forstå vektordatabaser med tradisjonelle databaser. Kort sagt, vi kan utføre innsettinger og slettinger i vektordatabaser, ikke oppdateringssetninger.
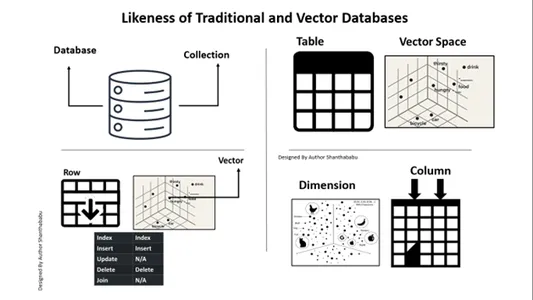
Enkel analogi for å forstå vektordatabaser
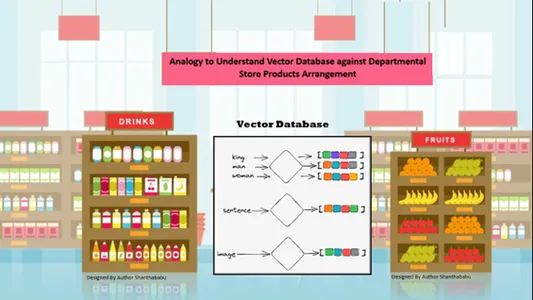
Data blir automatisk ordnet romlig etter innholdslikheten i den lagrede informasjonen. Så, la oss vurdere varehuset for vektordatabaseanalogi; alle produktene er ordnet på hyllen basert på natur, formål, produksjon, bruk og mengde-base. I en lignende oppførsel er dataene
automatisk arrangert i vektordatabasen på lignende måte, selv om sjangeren ikke var godt definert under lagring eller tilgang til dataene.
Vektordatabasene tillater en fremtredende granularitet og dimensjoner på de spesifikke likhetene, slik at kunden søker etter ønsket produkt, produsent og kvantitet og beholder varen i handlekurven. Vector database lagrer alle data i en perfekt lagringsstruktur; her trenger maskinlæring og AI-ingeniører ikke å merke eller merke det lagrede innholdet manuelt.
Essensielle teorier bak Vector Databases
- Vector Embeddings og deres omfang
- Indekseringskrav
- Forstå semantisk og likhetssøk
Vector Embedding og deres omfang
En vektorinnbygging er en vektorrepresentasjon når det gjelder de numeriske verdiene. I et komprimert format fanger innbygginger opp de iboende egenskapene og assosiasjonene til de originale dataene, noe som gjør dem til en stift i brukstilfeller av kunstig intelligens og maskinlæring. Å designe innbygginger for å kode relevant informasjon om de originale dataene til et rom med lavere dimensjoner sikrer høy gjenfinningshastighet, beregningseffektivitet og effektiv lagring.
Å fange essensen av data på en mer identisk strukturert måte er prosessen med vektorinnbygging, og danner en "innebyggingsmodell". Til syvende og sist vurderer disse modellene alle dataobjekter, trekker ut meningsfulle mønstre og relasjoner i datakilden og transformerer dem til vektorinnbygginger. Deretter utnytter algoritmer disse vektorinnbyggingene for å utføre ulike oppgaver. Tallrike høyt utviklede innbyggingsmodeller, tilgjengelige online som enten gratis eller betal-som-du-go, forenkler gjennomføringen av vektorinnbygging.
Omfang av vektorinnbygginger fra et applikasjonssynspunkt
Disse innebyggingene er kompakte, inneholder kompleks informasjon, arver relasjoner mellom dataene som er lagret i en vektordatabase, muliggjør en effektiv databehandlingsanalyse for å lette forståelse og beslutningstaking, og bygger dynamisk ulike innovative dataprodukter på tvers av enhver organisasjon.
Teknikker for innbygging av vektorer er avgjørende for å koble gapet mellom lesbare data og komplekse algoritmer. Med datatyper som numeriske vektorer, var vi i stand til å frigjøre potensialet for et stort utvalg av generative AI-applikasjoner sammen med tilgjengelige Open AI-modeller.
Flere jobber med Vector Embedding
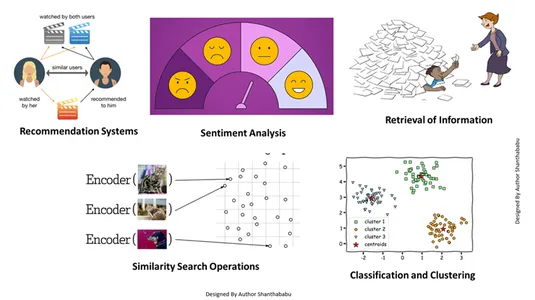
Denne vektorinnbyggingen hjelper oss å gjøre flere jobber:
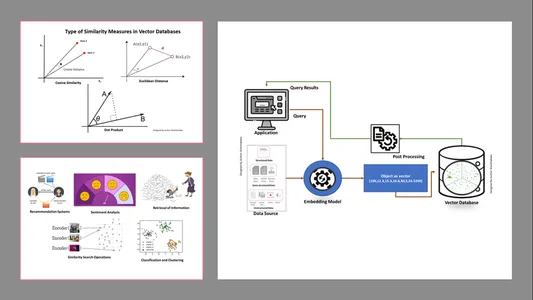
- Henting av informasjon: Ved hjelp av disse kraftige teknikkene kan vi bygge innflytelsesrike søkemotorer som kan hjelpe oss å finne svar basert på brukerforespørsler fra lagrede filer, dokumenter eller medier
- Likhetssøkeoperasjoner: Dette er godt organisert og indeksert; det hjelper oss å finne likheten mellom ulike forekomster i vektordataene.
- Klassifisering og gruppering: Ved å bruke disse innebyggingsteknikkene kan vi utføre disse modellene for å trene opp relevante maskinlæringsalgoritmer og gruppere og klassifisere dem.
- Anbefalingssystemer: Siden innebyggingsteknikkene er organisert riktig, fører det til anbefalingssystemer som nøyaktig relaterer produkter, medier og artikler basert på historiske data.
- Sentimentanalyse: Denne innbyggingsmodellen hjelper oss med å kategorisere og utlede sentimentløsninger.
Indekseringskrav
Som vi vet, vil indeksen forbedre søkedataene fra tabellen i tradisjonelle databaser, lik vektordatabaser, og sørge for indekseringsfunksjonene.
Vektordatabaser gir "Flatte indekser", som er den direkte representasjonen av vektorinnbyggingen. Søkemuligheten er omfattende, og denne bruker ikke ferdigtrente klynger. Den utfører spørringsvektoren utføres på tvers av hver enkelt vektorinnbygging, og K avstander beregnes for hvert par.
- På grunn av den enkle denne indeksen, kreves minimal beregning for å lage de nye indeksene.
- Faktisk kan en flat indeks håndtere forespørsler effektivt og gi raske gjenfinningstider.
Forstå semantisk og likhetssøk
Vi utfører to forskjellige søk i vektordatabaser: semantiske og likhetssøk.
- Semantisk søk: Mens du søker etter informasjon, i stedet for å søke etter nøkkelord, kan du finne dem basert på meningsfull samtalemetodikk. Rask ingeniørarbeid spiller en viktig rolle for å overføre input til systemet. Dette søket tillater utvilsomt søk av høyere kvalitet og resultater som kan mates for innovative applikasjoner, SEO, tekstgenerering og oppsummering.
- Likhetssøk: Alltid i dataanalyse åpner likhetssøket for ustrukturerte, mye bedre gitte datasett. Når det gjelder vektordatabaser, må vi finne ut hvor nært to vektorer er og hvordan de ligner hverandre: tabeller, tekst, dokumenter, bilder, ord og lydfiler. I prosessen med å forstå avsløres likheten mellom vektorer som likheten mellom dataobjektene i det gitte datasettet. Denne øvelsen hjelper oss å forstå interaksjon, identifisere mønstre, trekke ut innsikt og ta beslutninger fra applikasjonsperspektiver. Semantic and Similarity-søket vil hjelpe oss å bygge applikasjonene nedenfor for bransjefordeler.
- Informasjonsinnhenting: Ved å bruke åpne AI- og vektordatabaser ville vi bygge søkemotorer for informasjonsinnhenting ved å bruke forretningsbrukeres eller sluttbrukeres søk og indekserte dokumenter inne i vektor-DB.
- Klassifisering og gruppering:Klassifisering eller gruppering av lignende datapunkter eller grupper av objekter innebærer å tilordne dem til flere kategorier basert på delte egenskaper.
- Anomalideteksjon: Oppdage avvik fra vanlige mønstre ved å måle likheten mellom datapunkter og oppdage uregelmessigheter.
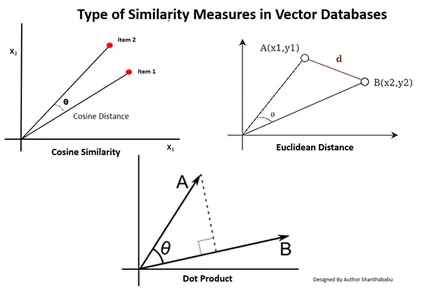
Typer likhetstiltak i vektordatabaser
Målemetodene avhenger av arten av dataene og den applikasjonsspesifikke. Vanligvis brukes tre metoder for å måle likheten og fortroligheten med maskinlæring.
Euklidisk avstand
Enkelt sagt er avstanden mellom de to vektorene den rettlinjede avstanden mellom de to vektorpunktene som måler st.
Punktprodukt
Dette hjelper oss å forstå justeringen mellom to vektorer, og indikerer om de peker i samme retning, motsatte retninger eller er vinkelrett på hverandre.
Cosine-likhet
Den vurderer likheten mellom to vektorer ved å bruke vinkelen mellom dem, som vist på figuren. I dette tilfellet er verdiene og størrelsen på vektorene ubetydelige og påvirker ikke resultatene; kun vinkelen tas med i beregningen.
Tradisjonelle databaser Søk etter nøyaktige SQL-setningstreff og hent dataene i tabellformat. Samtidig arbeider vi med vektordatabaser som søker etter den vektoren som ligner mest på inputspørringen på vanlig engelsk ved hjelp av Prompt Engineering-teknikker. Databasen bruker søkealgoritmen Approximate Nearest Neighbour (ANN) for å finne lignende data. Gi alltid rimelig nøyaktige resultater med høy ytelse, nøyaktighet og responstid.
Arbeidsmekanisme
- Vektordatabaser konverterer først data til innebygde vektorer, lagrer dem i vektordatabaser og lager indeksering for raskere søk.
- En spørring fra applikasjonen vil samhandle med den innebygde vektoren, søke etter nærmeste nabo eller lignende data i vektordatabasen ved hjelp av en indeks og hente resultatene som sendes til applikasjonen.
- Basert på forretningskravene, vil de hentede dataene bli finjustert, formatert og vist til sluttbrukersiden eller feeden for spørringen eller handlingen.
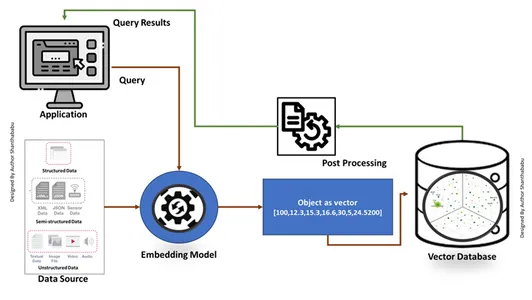
Opprette en vektordatabase
La oss få kontakt med Pinecone.
Du kan koble til Pinecone ved hjelp av Google, GitHub eller Microsoft ID.
Opprett en ny brukerpålogging for din bruk.
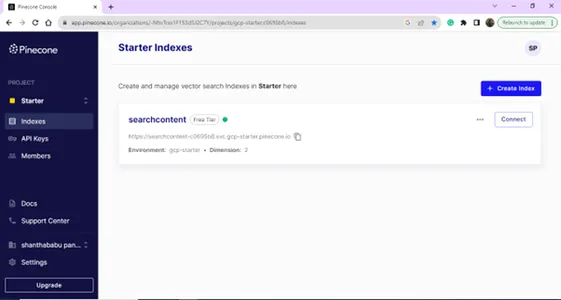
Etter vellykket pålogging vil du lande på indekssiden; du kan lage en indeks for din Vector Database-formål. Klikk på knappen Opprett indeks.
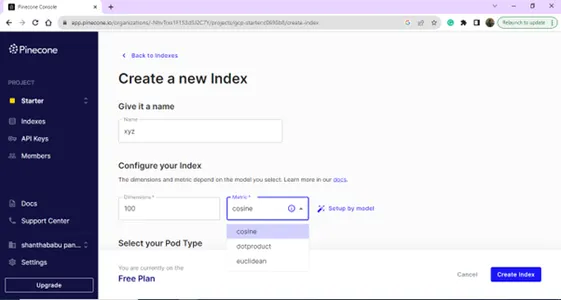
Opprett din nye indeks ved å oppgi navn og dimensjoner.
Indekslisteside,
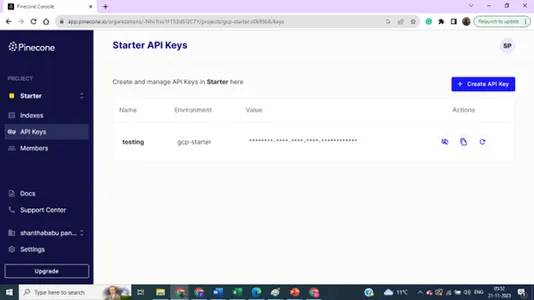
Indeksdetaljer – Navn, Region og Miljø – Vi trenger alle disse detaljene for å koble vektordatabasen vår fra modellbyggekoden.
Prosjektinnstillinger detaljer,
Du kan oppgradere innstillingene dine for flere indekser og nøkler for prosjektformål.
Så langt har vi diskutert å lage vektordatabaseindeksen og innstillingene i Pinecone.
Vektordatabaseimplementering ved hjelp av Python
La oss gjøre litt koding nå.
Importerer biblioteker
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAITilbyr API-nøkkel for OpenAI og Vector database
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Starte LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Starter Pinecone
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Laster .csv-fil for å bygge vektordatabase
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Del teksten i biter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Finne teksten i text_chunk
text_chunksProduksjon
[Dokument(page_content='navn: 100% Brannmfr: Nntype: Cnkalorier: 70nprotein: 4nfett: 1natrium: 130nfiber: 10nkarbo: 5nsukker: 6npotass: 280nvitaminer: 25nnatt: 3n1nnatt: 0.33n68.402973n: 100n: 0n: XNUMXn: XNUMXn: XNUMXn XNUMXnanbefaling: Kids', metadata={ 'kilde': 'XNUMX % kli', 'rad': XNUMX}), , …..
Bygge innbygging
embeddings = OpenAIEmbeddings()Lag en Pinecone-forekomst for vektordatabase fra 'data'
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Opprett en retriever for å spørre vektordatabasen.
retriever = vectordb.as_retriever(score_threshold = 0.7)Henter data fra vektordatabase
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsBruk Spør og hent dataene
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
La oss spørre etter dataene.
chain('Can you please provide cereal recommendation for Kids?')Utdata fra spørring
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]konklusjonen
Håper du kan forstå hvordan vektordatabaser fungerer, deres komponenter, arkitektur og egenskaper til vektordatabaser i generative AI-løsninger. Forstå hvordan vektordatabasen er forskjellig fra tradisjonell database og sammenligning med konvensjonelle databaseelementer. Faktisk hjelper analogien deg bedre å forstå vektordatabasen. Pinecone vektordatabase og indekseringstrinn vil hjelpe deg med å lage en vektordatabase og ta med nøkkelen for følgende kodeimplementering.
Nøkkelfunksjoner
- Kompakterbar med strukturerte, ustrukturerte og semistrukturerte data.
- Den tilpasser innbyggingsteknikker og svært indekserte funksjoner.
- Interaksjonene skjer gjennom ren tekst ved hjelp av en ledetekst (f.eks. engelsk). Og data lagret i matematiske representasjoner.
- Likhet kalibreres i vektordatabaser gjennom – Euklidisk avstand, Cosinuslikhet og Punktprodukt.
Ofte Stilte Spørsmål
A. En vektordatabase lagrer en samling av data i rommet. Det holder dataene i matematiske representasjoner. siden formatet som er lagret i databasene gjør det lettere for åpne AI-modeller å huske de tidligere inngangene og lar vår åpne AI-applikasjon bruke kognitivt søk, anbefalinger og presis tekstgenerering for ulike brukssaker i digitalt transformerte bransjer.
A. Noen av egenskapene er: 1. Det utnytter kraften til disse vektorinnbyggingene, noe som fører til indeksering og søk på tvers av et massivt datasett. 2. Kompakterbar med strukturerte, ustrukturerte og semistrukturerte data. 3. En vektordatabase organiserer data gjennom høydimensjonale vektorer som inneholder hundrevis av dimensjoner
A. Database ==> Samlinger
Tabell==> Vektorrom
Rad==>Cector
Kolonne==>Dimensjon
Innsetting og sletting er mulig i Vector-databaser, akkurat som i en tradisjonell database.
Oppdatering og bli med er ikke innenfor omfanget.
– Henting av informasjon for massiv datainnsamling raskt.
– Semantiske og likhetssøkeoperasjoner fra store dokumenter.
– Klassifiserings- og klyngeapplikasjon.
– Systemer for anbefaling og sentimentanalyse.
A5: Nedenfor er de tre metodene for å måle likheten:
– Euklidisk avstand
– Cosinus likhet
– Punktprodukt
Mediene vist i denne artikkelen eies ikke av Analytics Vidhya og brukes etter forfatterens skjønn.
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- : har
- :er
- :ikke
- $OPP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- I stand
- Om oss
- Tilgang
- nøyaktighet
- nøyaktig
- nøyaktig
- tvers
- tilpasser
- legge til
- påvirke
- AI
- AI-modeller
- algoritme
- algoritmer
- innretting
- Alle
- Allianse
- tillate
- tillater
- langs
- alltid
- blant
- an
- analyse
- analytics
- Analytics Vidhya
- og
- besvare
- noen
- api
- tilsynelatende
- Søknad
- applikasjonsspesifikk
- søknader
- tilnærmet
- arkitektur
- ER
- anordnet
- Array
- Artikkel
- artikler
- kunstig
- kunstig intelligens
- Kunstig intelligens og maskinlæring
- AS
- aspekter
- Vurderer
- foreninger
- At
- lyd
- automatisk
- tilgjengelig
- basert
- BE
- bli
- blir
- atferd
- bak
- være
- under
- Fordeler
- Bedre
- mellom
- bloggathon
- bringe
- bygge
- Bygning
- virksomhet
- knapp
- by
- beregnet
- beregningen
- som heter
- CAN
- evner
- evne
- fangst
- saken
- saker
- kategorier
- kjede
- kjeder
- egenskaper
- klarhet
- klassifisering
- Klassifisere
- klikk
- gruppering
- kode
- Koding
- kognitiv
- samling
- vanligvis
- kompakt
- sammenligne
- sammenligning
- fullføre
- komplekse
- komponenter
- omfattende
- beregningen
- beregnings
- Koble
- Tilkobling
- Vurder
- ansett
- inneholde
- innhold
- kontekst
- konvensjonell
- Samtale
- konvertere
- tilsvarer
- kunne
- skape
- Opprette
- kreativitet
- kunde
- dato
- dataanalyse
- datapunkter
- databehandling
- Database
- databaser
- datasett
- avtale
- Beslutningstaking
- avgjørelser
- krav
- Derive
- utforme
- ønsket
- detaljer
- Gjenkjenning
- utviklet
- avvike
- forskjell
- forskjellig
- digitalt
- Dimensjon
- dimensjoner
- direkte
- retning
- retninger
- oppdage
- skjønn
- diskutere
- diskutert
- vises
- avstand
- do
- dokumenter
- gjør
- Don
- DOT
- dynamisk
- dynamisk
- e
- hver enkelt
- lette
- enklere
- effektivt
- effektivitet
- effektiv
- enten
- elementer
- embedding
- muliggjøre
- slutt
- Ingeniørarbeid
- Ingeniører
- Motorer
- Engelsk
- sikrer
- Miljø
- essens
- avgjørende
- Eter (ETH)
- Selv
- utvikling
- henrette
- Øvelse
- Utforske
- trekke ut
- legge til rette
- Familiær
- langt
- Trekk
- Egenskaper
- Fed
- Figur
- filet
- Filer
- Finn
- Først
- flate
- etter
- Til
- teten
- skjema
- format
- Gratis
- fra
- framtid
- mellomrom
- generere
- generasjonen
- generative
- Generativ AI
- genre
- GitHub
- Gi
- gitt
- Gruppe
- Gruppens
- håndtere
- skje
- Ha
- hjelpe
- hjelper
- her.
- Høy
- høyt nivå
- svært
- historisk
- Hvordan
- Men
- HTTPS
- stort
- Hundrevis
- i
- ID
- identifisere
- if
- bilder
- Påvirkning
- gjennomføring
- importere
- forbedre
- in
- stadig
- indeks
- indeksert
- indekser
- indikerer
- Indekser
- bransjer
- industri
- Innflytelsesrik
- informasjon
- iboende
- innovative
- inngang
- innganger
- Setter inn
- innsiden
- innsikt
- f.eks
- i stedet
- Intelligens
- samhandle
- interaksjon
- interaksjoner
- inn
- forviklinger
- innebærer
- IT
- DET ER
- Jobb
- bli medlem
- Bli med oss
- reise
- bare
- nøkkel
- nøkler
- nøkkelord
- kids
- Vet
- Etiketten
- Tomt
- landskap
- stor
- ledende
- Fører
- læring
- Leverage
- utnytter
- i likhet med
- Liste
- loader
- logikk
- Logg inn
- maskin
- maskinlæring
- større
- gjøre
- GJØR AT
- Making
- administrerende
- måte
- manuelt
- Produsent
- kart
- massive
- fyrstikker
- matematiske
- meningsfylt
- måle
- målinger
- måling
- mekanisme
- Media
- Flett
- metodikk
- metoder
- Microsoft
- minimal
- modell
- modeller
- mer
- Videre
- mest
- mye
- flere
- må
- navn
- Natur
- Trenger
- Ny
- nå
- mange
- objekt
- gjenstander
- of
- tilby
- on
- ONE
- seg
- på nett
- bare
- åpen
- OpenAI
- Drift
- motsatt
- or
- organisasjonen
- Organisert
- organiserer
- original
- OS
- Annen
- vår
- eide
- side
- par
- del
- bestått
- Passerer
- mønstre
- perfekt
- utføre
- ytelse
- utført
- utfører
- perspektiv
- prospektet
- bilde
- sentral
- Plain
- plato
- Platon Data Intelligence
- PlatonData
- spiller
- vær så snill
- Point
- poeng
- mulig
- potensiell
- makt
- kraftig
- Praktisk
- praktiske anvendelser
- presis
- nettopp
- preferanser
- forrige
- Problem
- prosess
- Produkt
- Produkter
- prosjekt
- fremtredende
- ledetekster
- riktig
- egenskaper
- eiendom
- gi
- gi
- forsyning
- publisert
- puffs
- formål
- formål
- kvantitet
- spørsmål
- spørsmål
- Rask
- raskere
- raskt
- raskt
- Anbefaling
- anbefalinger
- om
- region
- relasjoner
- Relasjoner
- relevant
- representasjon
- representert
- representerer
- påkrevd
- Krav
- svar
- svar
- resultere
- Resultater
- Avslørt
- Rolle
- RAD
- s
- samme
- Vitenskap
- omfang
- Søk
- Søkemotorer
- søk
- søker
- sentiment
- SEO
- innstillinger
- Form
- forme
- delt
- Hylle
- Kort
- vist
- Viser
- side
- lignende
- likheter
- Enkelt
- siden
- enkelt
- Størrelse
- So
- løsning
- Solutions
- noen
- kilde
- Rom
- spesifikk
- fart
- splittet
- spotting
- SQL
- Tilstand
- Uttalelse
- uttalelser
- Steps
- Still
- lagring
- oppbevare
- lagret
- butikker
- struktur
- strukturert
- Studer
- I ettertid
- vellykket
- synergi
- system
- Systemer
- T
- bord
- TAG
- oppgaver
- teknikker
- teknologisk
- vilkår
- tekst
- tekstgenerering
- enn
- Det
- De
- Fremtiden
- deres
- Dem
- Disse
- de
- denne
- tre
- Gjennom
- tid
- ganger
- til
- tradisjonelle
- Tog
- Transform
- Transformation
- transformative
- forvandlet
- prøve
- to
- typer
- Til syvende og sist
- forstå
- forståelse
- utvilsomt
- låse opp
- opplåsing
- Oppdater
- oppgradering
- us
- bruk
- bruke
- brukt
- Bruker
- bruker
- ved hjelp av
- vanlig
- Verdier
- variasjon
- ulike
- veldig
- vital
- vs
- var
- we
- webp
- veldefinerte
- var
- Hva
- Hva er
- om
- hvilken
- mens
- vil
- med
- innenfor
- ord
- Arbeid
- arbeid
- ville
- du
- Din
- zephyrnet