
September 20, 2023
Grunnleggende modeller (FM-er) markerer begynnelsen på en ny æra i maskinlæring (ML) og kunstig intelligens (AI), som fører til raskere utvikling av AI som kan tilpasses et bredt spekter av nedstrømsoppgaver og finjusteres for en rekke applikasjoner.
Med den økende betydningen av å behandle data der arbeid utføres, muliggjør visning av AI-modeller på bedriftskanten nesten sanntidsprediksjoner, samtidig som de overholder datasuverenitets- og personvernkrav. Ved å kombinere IBM watsonx data- og AI-plattformfunksjoner for FM-er med edge computing, kan bedrifter kjøre AI-arbeidsmengder for FM-finjustering og slutninger på den operasjonelle kanten. Dette gjør det mulig for bedrifter å skalere AI-distribusjoner på kanten, noe som reduserer tiden og kostnadene for å distribuere med raskere responstider.
Sørg for å sjekke ut alle avdragene i denne serien med blogginnlegg om edge computing:
Hva er grunnleggende modeller?
Grunnleggende modeller (FM), som er trent på et bredt sett av umerkede data i stor skala, driver state-of-the-art kunstig intelligens (AI)-applikasjoner. De kan tilpasses et bredt spekter av nedstrømsoppgaver og finjusteres for en rekke bruksområder. Moderne AI-modeller, som utfører spesifikke oppgaver i et enkelt domene, viker for FM-er fordi de lærer mer generelt og fungerer på tvers av domener og problemer. Som navnet antyder, kan en FM være grunnlaget for mange anvendelser av AI-modellen.
FM-er tar opp to hovedutfordringer som har hindret bedrifter i å skalere AI-adopsjon. For det første produserer bedrifter en enorm mengde umerkede data, bare en brøkdel av disse er merket for AI-modellopplæring. For det andre er denne merkings- og kommentaroppgaven ekstremt menneskeintensiv, og krever ofte flere hundre timer av en fageksperts (SME) tid. Dette gjør det uoverkommelig å skalere på tvers av brukstilfeller siden det vil kreve hærer av SMB og dataeksperter. Ved å innta enorme mengder umerkede data og bruke selvovervåkede teknikker for modelltrening, har FM-er fjernet disse flaskehalsene og åpnet muligheten for bred bruk av AI i hele bedriften. Disse enorme datamengdene som finnes i hver virksomhet venter på å bli sluppet løs for å gi innsikt.
Hva er store språkmodeller?
Store språkmodeller (LLM) er en klasse av grunnleggende modeller (FM) som består av lag av nevrale nettverk som har blitt trent på disse enorme mengdene umerkede data. De bruker selvstyrte læringsalgoritmer for å utføre en rekke naturlig språkbehandling (NLP) oppgaver på måter som ligner på hvordan mennesker bruker språk (se figur 1).
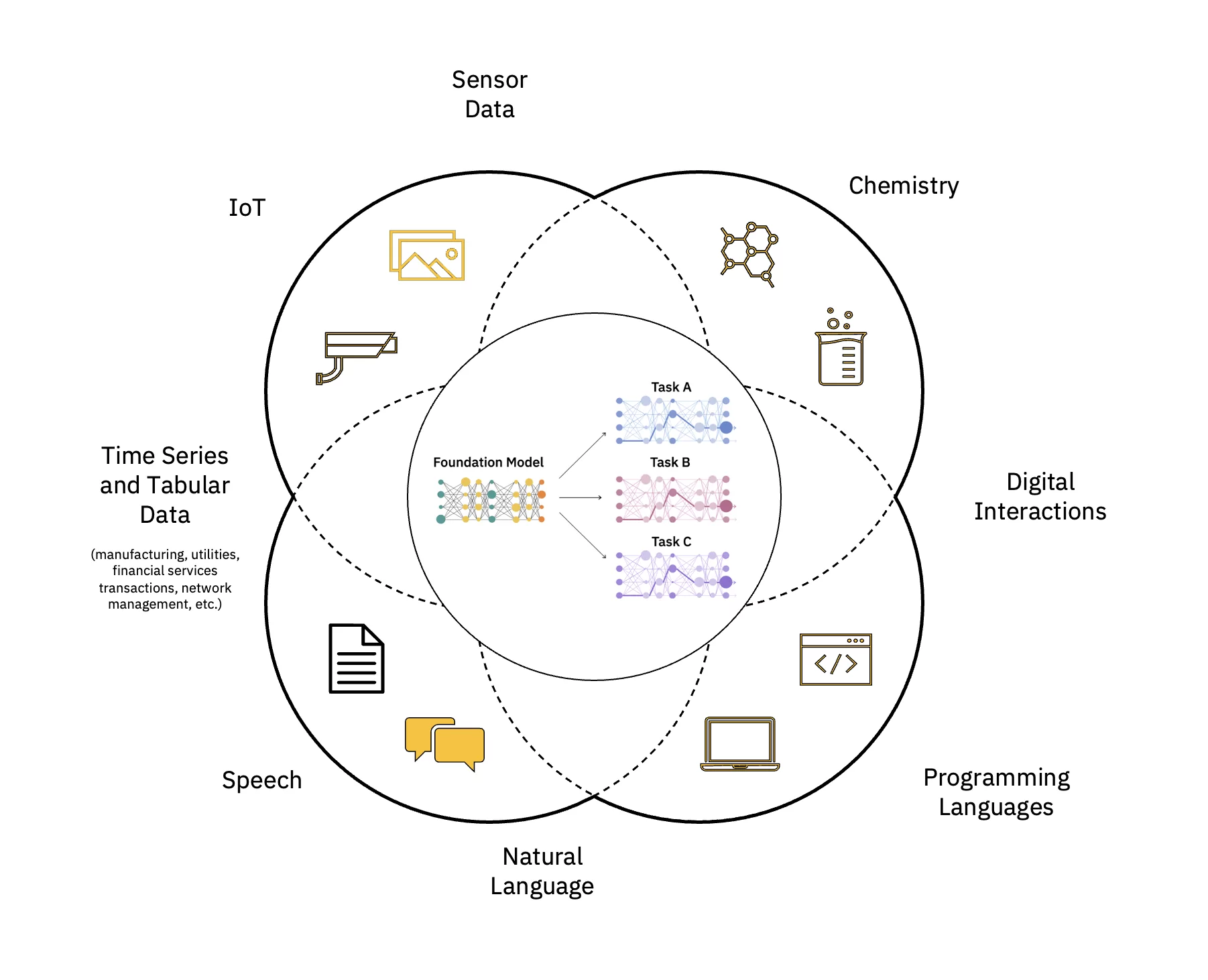
Skaler og akselerer virkningen av AI
Det er flere trinn for å bygge og distribuere en grunnleggende modell (FM). Disse inkluderer datainntak, datavalg, dataforbehandling, FM-foropplæring, modellinnstilling til én eller flere nedstrømsoppgaver, slutningsservering og data- og AI-modellstyring og livssyklusstyring – som alle kan beskrives som FMOps.
For å hjelpe med alt dette, tilbyr IBM bedrifter de nødvendige verktøyene og mulighetene for å utnytte kraften til disse FM-ene via IBM watsonx, en bedriftsklar AI- og dataplattform designet for å multiplisere virkningen av AI på tvers av en bedrift. IBM watsonx består av følgende:
- IBM watsonx.ai bringer nytt generativ AI funksjoner – drevet av FM-er og tradisjonell maskinlæring (ML) – til et kraftig studio som strekker seg over AI-livssyklusen.
- IBM watsonx.data er et egnet datalager bygget på en åpen innsjø-arkitektur for å skalere AI-arbeidsmengder for alle dataene dine, hvor som helst.
- IBM watsonx.governance er en ende-til-ende automatisert AI-livssyklusstyringsverktøysett som er bygget for å muliggjøre ansvarlige, transparente og forklarbare AI-arbeidsflyter.
En annen nøkkelvektor er den økende betydningen av databehandling på bedriftskanten, for eksempel industrielle lokasjoner, produksjonsgulv, detaljbutikker, telco edge-steder, etc. Mer spesifikt muliggjør AI på bedriftskanten behandling av data der arbeid utføres for nær sanntidsanalyse. Bedriftsfordelen er der store mengder bedriftsdata genereres og hvor AI kan gi verdifull, tidsriktig og handlingsdyktig forretningsinnsikt.
Å betjene AI-modeller på kanten muliggjør spådommer i nesten sanntid samtidig som de overholder datasuverenitets- og personvernkrav. Dette reduserer forsinkelsen som ofte er forbundet med innhenting, overføring, transformasjon og behandling av inspeksjonsdata betydelig. Ved å jobbe på kanten kan vi beskytte sensitive bedriftsdata og redusere kostnadene for dataoverføring med raskere responstider.
Å skalere AI-distribusjoner på kanten er imidlertid ikke en lett oppgave blant data (heterogenitet, volum og regulatoriske) og begrensede ressurser (databehandling, nettverkstilkobling, lagring og til og med IT-ferdigheter) relaterte utfordringer. Disse kan grovt beskrives i to kategorier:
- Tid/kostnad å distribuere: Hver distribusjon består av flere lag med maskinvare og programvare som må installeres, konfigureres og testes før distribusjon. I dag kan en servicetekniker ta opptil en uke eller to å installere på hvert sted, begrenser hvor raskt og kostnadseffektivt bedrifter kan skalere opp distribusjoner på tvers av organisasjonen.
- Dag 2 ledelse: Det store antallet distribuerte kanter og den geografiske plasseringen av hver distribusjon kan ofte gjøre det uoverkommelig dyrt å tilby lokal IT-støtte på hvert sted for å overvåke, vedlikeholde og oppdatere disse distribusjonene.
Edge AI-implementeringer
IBM utviklet en edge-arkitektur som takler disse utfordringene ved å bringe en integrert maskinvare/programvare (HW/SW) enhetsmodell til avanserte AI-distribusjoner. Den består av flere nøkkelparadigmer som hjelper skalerbarheten til AI-implementeringer:
- Policybasert, null-touch-klargjøring av hele programvarestabelen.
- Kontinuerlig overvåking av kantsystemets helse
- Evner til å administrere og pushe programvare-/sikkerhets-/konfigurasjonsoppdateringer til en rekke kantplasseringer – alt fra et sentralt skybasert sted for dag-2-administrasjon.
En distribuert hub-and-spoke-arkitektur kan brukes til å skalere enterprise AI-distribusjoner på kanten, der en sentral sky eller bedriftsdatasenter fungerer som en hub og edge-in-a-box-enheten fungerer som en eiker på et kantsted. Denne nav- og eikermodellen, som strekker seg på tvers av hybride sky- og kantmiljøer, illustrerer best balansen som er nødvendig for å optimalt utnytte ressursene som trengs for FM-operasjoner (se figur 2).
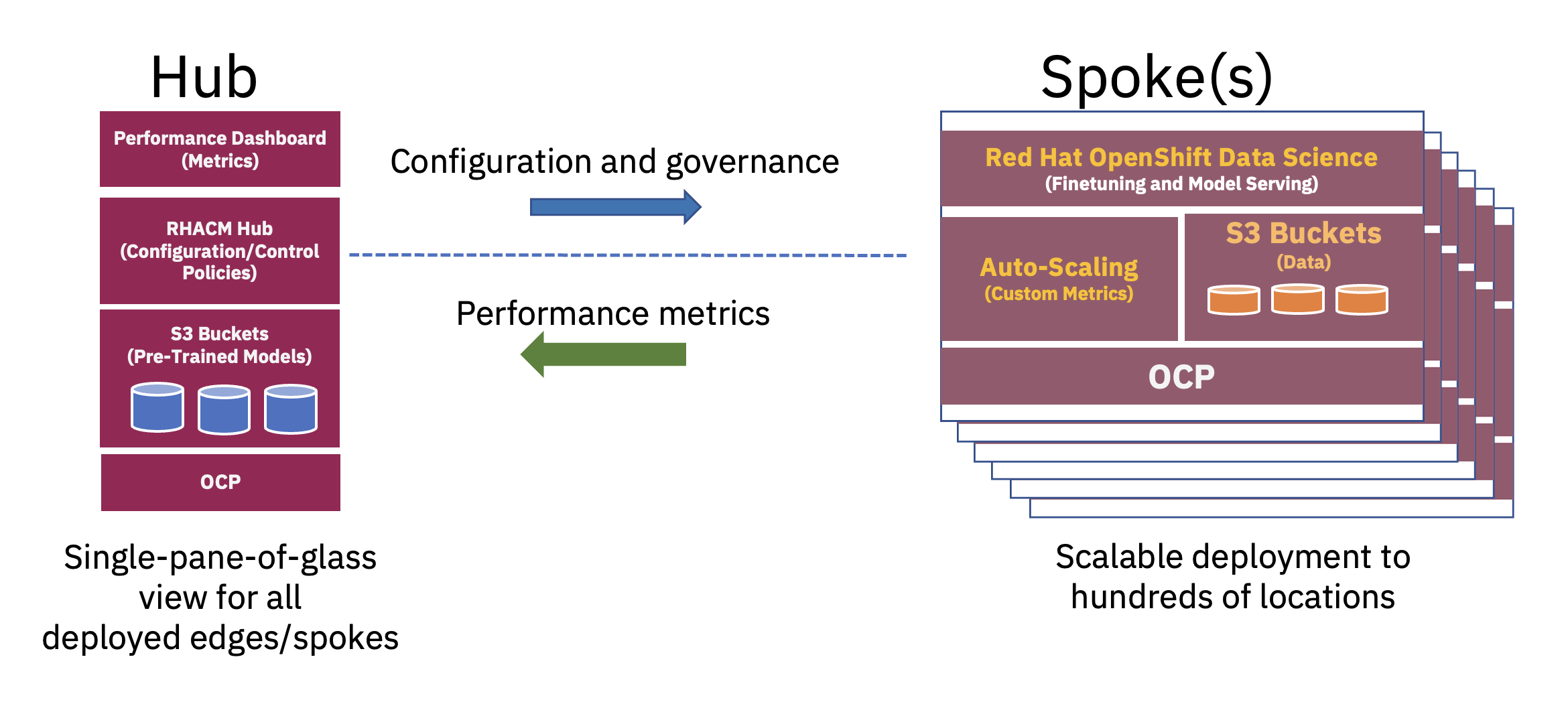
Foropplæring av disse grunnleggende store språkmodellene (LLM) og andre typer grunnmodeller ved bruk av selvovervåkede teknikker på enorme umerkede datasett krever ofte betydelige beregningsressurser (GPU) og utføres best i et knutepunkt. De praktisk talt ubegrensede dataressursene og store databunkene som ofte er lagret i skyen, muliggjør forhåndstrening av store parametermodeller og kontinuerlig forbedring av nøyaktigheten til disse grunnfundamentmodellene.
På den annen side kan innstilling av disse base-FM-ene for nedstrømsoppgaver – som bare krever noen få titalls eller hundrevis av merkede dataeksempler og slutningsservering – oppnås med bare noen få GPU-er på bedriftskanten. Dette gjør det mulig for sensitive merkede data (eller bedriftens kronjuveldata) å holde seg trygt innenfor bedriftens driftsmiljø, samtidig som det reduserer dataoverføringskostnadene.
Ved å bruke en full-stack-tilnærming for å distribuere applikasjoner til kanten, kan en dataforsker utføre finjustering, testing og distribusjon av modellene. Dette kan oppnås i et enkelt miljø samtidig som utviklingslivssyklusen for visning av nye AI-modeller for sluttbrukere reduseres. Plattformer som Red Hat OpenShift Data Science (RHODS) og den nylig annonserte Red Hat OpenShift AI gir verktøy for raskt å utvikle og distribuere produksjonsklare AI-modeller i distribuert sky og kantmiljøer.
Til slutt, å betjene den finjusterte AI-modellen på bedriftskanten reduserer ventetiden betraktelig forbundet med innhenting, overføring, transformasjon og behandling av data. Å koble fra før-treningen i skyen fra finjustering og inferencing på kanten reduserer de totale driftskostnadene ved å redusere tiden som kreves og dataoverføringskostnadene forbundet med enhver inferensoppgave (se figur 3).
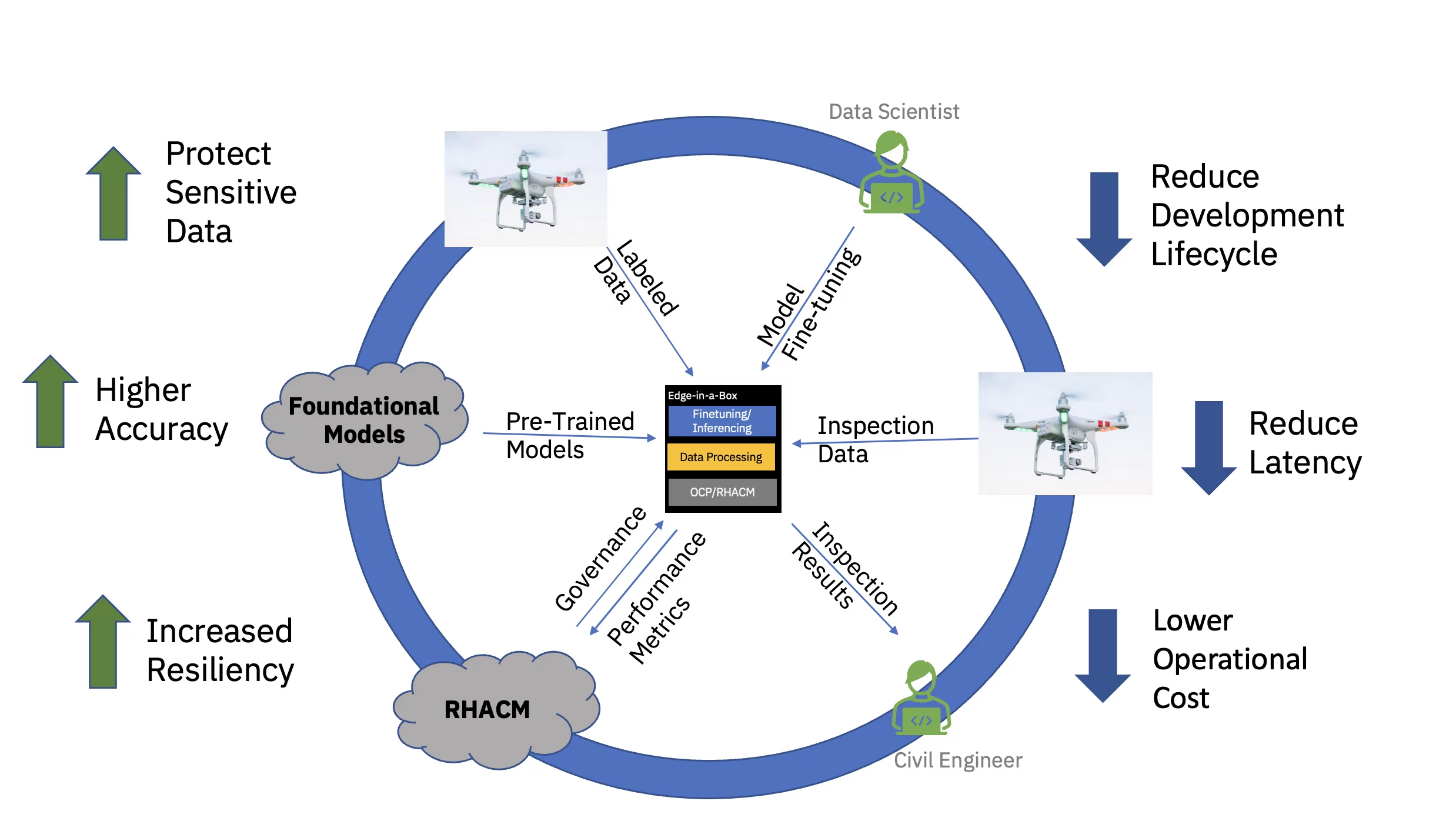
For å demonstrere dette verdiforslaget ende-til-ende, ble en eksemplarisk visjonstransformatorbasert grunnmodell for sivil infrastruktur (forhåndsutdannet ved bruk av offentlige og tilpassede bransjespesifikke datasett) finjustert og distribuert for slutninger på en kant med tre noder (ekte) klynge. Programvarestabelen inkluderte Red Hat OpenShift Container Platform og Red Hat OpenShift Data Science. Denne kantklyngen var også koblet til en forekomst av Red Hat Advanced Cluster Management for Kubernetes (RHACM)-hub som kjørte i skyen.
Null-touch-klargjøring
Policybasert, null-touch-klargjøring ble gjort med Red Hat Advanced Cluster Management for Kubernetes (RHACM) via policyer og plasseringskoder, som binder spesifikke kantklynger til et sett med programvarekomponenter og konfigurasjoner. Disse programvarekomponentene – som strekker seg over hele stabelen og dekker databehandling, lagring, nettverk og AI-arbeidsmengden – ble installert ved hjelp av forskjellige OpenShift-operatører, levering av nødvendige applikasjonstjenester og S3 Bucket (lagring).
Den forhåndstrente grunnmodellen (FM) for sivil infrastruktur ble finjustert via en Jupyter Notebook i Red Hat OpenShift Data Science (RHODS) ved å bruke merkede data for å klassifisere seks typer defekter funnet på betongbroer. Inferensservering av denne finjusterte FM-en ble også demonstrert ved bruk av en Triton-server. Videre ble overvåking av helsen til dette kantsystemet muliggjort ved å aggregere observerbarhetsmålinger fra maskinvare- og programvarekomponentene via Prometheus til det sentrale RHACM-dashbordet i skyen. Sivile infrastrukturbedrifter kan distribuere disse FM-ene på sine kantplasseringer og bruke dronebilder for å oppdage defekter i nesten sanntid – noe som akselererer tiden til innsikt og reduserer kostnadene ved å flytte store volumer med høyoppløselig data til og fra skyen.
Oppsummering
Kombinere IBM watsonx data- og AI-plattformfunksjoner for grunnmodeller (FM-er) med en edge-in-a-box-enhet gjør at bedrifter kan kjøre AI-arbeidsmengder for FM-finjustering og slutninger på den operasjonelle kanten. Denne enheten kan håndtere komplekse brukssaker rett ut av esken, og den bygger hub-and-spoke-rammeverket for sentralisert administrasjon, automatisering og selvbetjening. Edge FM-distribusjoner kan reduseres fra uker til timer med repeterbar suksess, høyere robusthet og sikkerhet.
Lær mer om grunnleggende modeller
Sørg for å sjekke ut alle avdragene i denne serien med blogginnlegg om edge computing:
Mer fra Cloud




- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.ibm.com/blog/foundational-models-at-the-edge/
- : har
- :er
- :ikke
- :hvor
- $OPP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- Om oss
- akselerere
- adgang
- oppnådd
- nøyaktighet
- oppkjøp
- tvers
- handlinger
- tilpasset
- I tillegg
- adresse
- adresser
- Adopsjon
- avansert
- fremskritt
- Annonsering
- AI
- AI adopsjon
- AI-modeller
- AI-plattform
- Aid
- algoritmer
- Alle
- tillate
- tillater
- også
- Amid
- beløp
- beløp
- amp
- an
- analyse
- analytics
- og
- annonsert
- noen
- hvor som helst
- Søknad
- søknader
- tilnærming
- arkitektur
- ER
- Array
- Artikkel
- kunstig
- kunstig intelligens
- Kunstig intelligens (AI)
- AS
- assosiert
- At
- forfatter
- Automatisert
- Automatisering
- tilgjengelig
- Avenue
- tilbake
- Balansere
- Bank
- Banker
- basen
- BE
- fordi
- bli
- bli
- vært
- Begynnelsen
- være
- tro
- BEST
- binde
- Blogg
- Blogginnlegg
- blogger
- både
- Eske
- broer
- Bringe
- Bringer
- bred
- bredt
- Bygning
- bygger
- bygget
- virksomhet
- by
- CAN
- evner
- hovedstad
- fange
- karbon
- kort
- Kort
- saker
- CAT
- kategorier
- Årsak
- sentrum
- sentral
- Central Bank
- sentralbank digitale valutaer
- sentralisert
- kjede
- utfordringer
- endring
- endring
- sjekk
- valg
- sirkler
- CIS
- sivil
- klasse
- Klassifisere
- fjerne
- klienter
- tett
- Cloud
- Cluster
- farge
- fargerikt
- kombinere
- konkurranse
- komplekse
- kompleksitet
- samsvar
- komponenter
- Beregn
- databehandling
- Konfigurasjon
- konfigurert
- tilkoblet
- Tilkobling
- består
- Container
- fortsette
- kontroll
- Kostnad
- Kostnader
- kunne
- dekker
- cryptocurrency
- CSS
- valutaer
- skikk
- kunde
- kundeopplevelse
- Kunder
- dashbord
- dato
- Datasenter
- Dataplattform
- datavitenskap
- dataforsker
- datasett
- Dato
- dedikert
- Misligholde
- definisjoner
- leverer
- demonstrere
- demonstrert
- utplassere
- utplassert
- utplasserings
- distribusjon
- distribusjoner
- beskrevet
- beskrivelse
- designet
- utvikle
- utviklet
- Utvikling
- digitalt
- digitale valutaer
- digitalisering
- Avbrudd
- forstyrrende
- forstyrrende
- distribueres
- distrikt
- domene
- domener
- gjort
- stasjonen
- kjøring
- drone
- hver enkelt
- lett
- økosystem
- Edge
- kanten beregning
- Hev
- forhøyet
- muliggjøre
- muliggjør
- slutt
- ende til ende
- ingeniør
- Ingeniørarbeid
- Enter
- Enterprise
- bedrifter
- innkommende
- Miljø
- miljøer
- Era
- spesielt
- etc
- Eter (ETH)
- Selv
- hendelser
- Hver
- utviklet seg
- undersøke
- eksempler
- henrette
- eksisterer
- Utgang
- dyrt
- erfaring
- eksperter
- Forklarbar AI
- forklare
- strekker
- ekstremt
- faktorer
- FAST
- raskere
- Noen få
- felt
- Figur
- finansiell
- Finansinstitusjoner
- finansiering
- Først
- gulv
- følge
- etter
- fonter
- Til
- teten
- funnet
- Fundament
- brøkdel
- Rammeverk
- fra
- fullt
- Full stabel
- Dess
- generelt
- generert
- generator
- geografiske
- geopolitikk
- Giving
- Global
- global handel
- styresett
- GPU
- GPU
- Grid
- hånd
- håndtere
- maskinvare
- hatt
- Ha
- Helse
- høyde
- hjelpe
- hjelpe
- hjelper
- høy oppløsning
- høyere
- svært
- historie
- vert
- TIMER
- Hvordan
- Hvordan
- Men
- HTTPS
- Hub
- Mennesker
- Hundrevis
- Hybrid
- hybrid sky
- IBM
- IBM Cloud
- ICO
- ICON
- illustrerer
- bilde
- Påvirkning
- betydning
- forbedring
- in
- inkludere
- inkludert
- økende
- stadig
- indeks
- industriell
- bransjer
- industri
- bransjespesifikke
- inflasjon
- bøyning
- Bøyepunkt
- påvirket
- Infrastruktur
- Initiative
- Innovasjon
- innovative
- innganger
- innsikt
- f.eks
- institusjoner
- integrert
- Intelligens
- egenverdi
- innføre
- IT
- IT Support
- Journeys
- jpg
- hoppe
- Jupyter Notebook
- bare
- bare én
- holdt
- nøkkel
- Kubernetes
- merking
- Språk
- stor
- i stor grad
- Ventetid
- siste
- lag
- ledende
- LÆRE
- læring
- Leverage
- Livssyklus
- i likhet med
- grenseløs
- linux
- lokal
- lokale
- plassering
- steder
- Lang
- Se
- maskin
- maskinlæring
- laget
- vedlikeholde
- gjøre
- GJØR AT
- administrer
- ledelse
- produksjon
- mange
- merking
- massive
- Master
- Saken
- max bredde
- mekanismer
- metoder
- Metrics
- minutter
- minimere
- minutter
- ML
- Mobil
- modell
- modeller
- Moderne
- modernisering
- modern
- Overvåke
- overvåking
- mer
- bevegelse
- flytting
- navn
- Navigasjon
- Nær
- nødvendig
- Trenger
- nødvendig
- behov
- nettverk
- Ny
- neste
- nlp
- bærbare
- ingenting
- nå
- Antall
- mange
- of
- tilby
- ofte
- on
- ONE
- bare
- åpen
- åpnet
- operasjonell
- Drift
- operatører
- optimalisert
- or
- organisasjon
- Annen
- vår
- ut
- samlet
- pakker
- side
- parameter
- betaling
- betalingsmetoder
- betalinger
- utføre
- utført
- PHP
- plassering
- plattform
- Plattformer
- plato
- Platon Data Intelligence
- PlatonData
- plugg inn
- Point
- Politikk
- politikk
- posisjon
- mulig
- Post
- innlegg
- potensiell
- makt
- kraftig
- Spådommer
- Før
- privatliv
- privat
- problemer
- prosessering
- produsere
- profesjonell
- proposisjoner
- gi
- offentlig
- Skyv
- område
- raskt
- Lesning
- sanntids
- nylig
- rekord
- innspilling
- Rød
- Red Hat
- redusere
- Redusert
- reduserer
- redusere
- forskrifter
- Regulatorer
- regulatorer
- i slekt
- fjernet
- repeterbar
- krever
- påkrevd
- Krav
- nødvendig
- forskning
- Ressurser
- svar
- ansvarlig
- responsive
- detaljhandel
- Rise
- roboter
- Kjør
- rennende
- trygt
- samme
- skalerbarhet
- Skala
- skala ai
- skalering
- Vitenskap
- Forsker
- Skjerm
- skript
- Sekund
- sikkert
- sikkerhet
- se
- se
- utvalg
- Selvbetjening
- sensitive
- SEO
- September
- Serien
- server
- tjeneste
- Tjenester
- servering
- Session
- sesjoner
- sett
- flere
- Del
- Vis
- signifikant
- betydelig
- lignende
- siden
- Singapore
- enkelt
- enkelt miljø
- nettstedet
- Nettsteder
- SIX
- ferdigheter
- liten
- EMS
- SMB
- Software
- programvarekomponenter
- løsning
- suverenitet
- Rom
- Spenning
- spesifikk
- spesielt
- Sponset
- stable
- Begynn
- state-of-the-art
- opphold
- Steps
- lagring
- oppbevare
- lagret
- butikker
- Storm
- studio
- emne
- suksess
- slik
- foreslår
- levere
- forsyningskjeden
- støtte
- sikker
- system
- Ta
- tatt
- Oppgave
- oppgaver
- teknikker
- Teknologi
- Telco
- Temenos
- titus
- terra
- testet
- Testing
- Det
- De
- deres
- tema
- Der.
- Disse
- de
- denne
- Gjennom
- tid
- rettidig
- ganger
- Tittel
- til
- i dag
- sammen
- verktøykasse
- verktøy
- topp
- handel
- tradisjonelle
- Tog
- trent
- Kurs
- overføre
- Transform
- Transformation
- transformasjoner
- gjennomsiktig
- Triton
- to
- typen
- typer
- sluppet løs
- Oppdater
- oppdateringer
- URL
- us
- bruke
- brukt
- Brukere
- ved hjelp av
- bruke
- benyttes
- Verdifull
- verdi
- verdivurdering
- variasjon
- ulike
- enorme
- av
- Se
- nesten
- volum
- volumer
- W
- venter
- lommebok
- var
- Wave
- Vei..
- måter
- we
- uke
- uker
- Hva
- Hva er
- når
- hvilken
- mens
- HVEM
- hvorfor
- bred
- Bred rekkevidde
- med
- innenfor
- kvinne
- WordPress
- Arbeid
- arbeidsflyt
- arbeid
- ville
- skrevet
- Din
- zephyrnet











